Table of Contents
Overview: What Coherence can do for you...
Cluster your objects and your data
Overview
Coherence is an essential ingredient for building reliable, high-scale clustered applications. The term clustering refers to the use of more than one server to run an application, usually for reliability and scalability purposes. Coherence provides all of the necessary capabilities for applications to achieve the maximum possible availability, reliability, scalability and performance. Virtually any clustered application will benefit from using Coherence.
One of primary uses of Coherence is to cluster an application's objects and data. In the simplest sense, this means that all of the objects and data that an application delegates to Coherence is automatically available to and accessible by all servers in the application cluster, and none of those objects and none of that data will be lost in the event of server failure.
By clustering the application's objects and data, Coherence solves many of the difficult problems related to achieving availability, reliability, scalability, performance, serviceability and manageability of clustered applications.
Availability
Availability refers to the percentage of time that an application is operating. High Availability refers to achieving availability close to 100%. Coherence is used to achieve High Availability in several different ways:
Supporting redundancy in Java applications
Coherence makes it possible for an application to run on more than one server, which means that the servers are redundant. Using a load balancer, for example, an application running on redundant servers will be available as long as one server is still operating. Coherence enables redundancy by allowing an application to share, coordinate access to, update and receive modification events for critical runtime information across all of the redundant servers. Most applications cannot operate in a redundant server environment unless they are architected to run in such an environment; Coherence is a key enabler of such an architecture.
Enabling dynamic cluster membership
Coherence tracks exactly what servers are available at any given moment. When the application is started on an additional server, Coherence is instantly aware of that server coming online, and automatically joins it into the cluster. This allows redundancy (and thus availability) to be dynamically increased by adding servers.
Exposing knowledge of server failure
Coherence reliably detects most types of server failure in less than a second, and immediately fails over all of the responsibilities of the failed server without losing any data. As a result, server failure does not impact availability.
Part of an availability management is Mean Time To Recovery (MTTR), which is a measurement of how much time it takes for an unavailable application to become available. Since server failure is detected and handled in less than a second, and since redundancy means that the application is available even when that server goes down, the MTTR due to server failure is zero from the point of view of application availability, and typically sub-second from the point of view of a load-balancer re-routing an incoming request.
Eliminating other Single Points Of Failure (SPOFs)
Coherence provides insulation against failures in other infrastructure tiers. For example, Coherence write-behind caching and Coherence distributed parallel queries can insulate an application from a database failure; in fact, using these capabilities, two different Coherence customers have had database failure during operational hours, yet their production Coherence-based applications maintained their availability and their operational status.
Providing support for Disaster Recovery (DR) and Continuancy Planning
Coherence can even insulate against failure of an entire data center, by clustering across multiple data centers and failing over the responsibilities of an entire data center. Again, this capability has been proven in production, with a Coherence customer running a mission-critical real-time financial system surviving a complete data center outage.
Reliability
Reliability refers to the percentage of time that an application is able to process correctly. In other words, an application may be available, yet unreliable if it cannot correctly handle the application processing. An example that we use to illustrate high availability but low reliability is a mobile phone network: While most mobile phone networks have very high uptimes (referring to availability), dropped calls tend to be relatively common (referring to reliability).
Coherence is explicitly architected to achieve very high levels of reliability. For example, server failure does not impact "in flight" operations, since each operation is atomically protected from server failure, and will internally re-route to a secondary node based on a dynamic pre-planned recovery strategy. In other words, every operation has a backup plan ready to go!
Coherence is architected based on the assumption that failures are always about to occur. As a result, the algorithms employed by Coherence are carefully designed to assume that each step within a operation could fail due to a network, server, operating system, JVM or other resource outage. An example of how Coherence plans for these failures is the synchronous manner in which it maintains redundant copies of data; in other words, Coherence does not gamble with the application's data, and that ensures that the application will continue to work correctly, even during periods of server failure.
Scalability
Scalability refers to the ability of an application to predictably handle more load. An application exhibits linear scalability if the maximum amount of load that an application can sustain is directly proportional to the hardware resources that the application is running on. For example, if an application running on 2 servers can handle 2000 requests per second, then linear scalability would imply that 10 servers would handle 10000 requests per second.
Linear scalability is the goal of a scalable architecture, but it is difficult to achieve. The measurement of how well an application scales is called the scaling factor (SF). A scaling factor of 1.0 represents linear scalability, while a scaling factor of 0.0 represents no scalability. Coherence provides a number of capabilities designed to help applications achieve linear scalability.
When planning for extreme scale, the first thing to understand is that application scalability is limited by any necessary shared resource that does not exhibit linear scalability. The limiting element is referred to as a bottleneck, and in most applications, the bottleneck is the data source, such as a database or an EIS.
Coherence helps to solve the scalability problem by targeting obvious bottlenecks, and by completely eliminating bottlenecks whenever possible. It accomplishes this through a variety of capabilities, including:
Distributed Caching
Coherence uses a combination of replication, distribution, partitioning and invalidation to reliably maintain data in a cluster in such a way that regardless of which server is processing, the data that it obtains from Coherence is the same. In other words, Coherence provides a distributed shared memory implementation, also referred to as Single System Image (SSI) and Coherent Clustered Caching.
Any time that an application can obtain the data it needs from the application tier, it is eliminating the data source as the Single Point Of Bottleneck (SPOB).
Partitioning
Partitioning refers to the ability for Coherence to load-balance data storage, access and management across all of the servers in the cluster. For example, when using Coherence data partitioning, if there are four servers in a cluster then each will manage 25% of the data, and if another server is added, each server will dynamically adjust so that each of the five servers will manage 20% of the data, and this data load balancing will occur without any application interruption and without any lost data or operations. Similarly, if one of those five servers were to die, each of the remaining four servers would be managing 25% of the data, and this data load balancing will occur without any application interruption and without any lost data or operations – including the 20% of the data that was being managed on the failed server.
Coherence accomplishes failover without data loss by synchronously maintaining a configurable number of copies of the data within the cluster. Just as the data management responsibility is spread out over the cluster, so is the responsibility for backing up data, so in the previous example, each of the remaining four servers would have roughly 25% of the failed server's data backed up on it. This mesh architecture guarantees that on server failure, no particular remaining server is inundated with a massive amount of additional responsibility.
Coherence prevents loss of data even when multiple instances of the application are running on a single physical server within the cluster. It does so by ensuring that backup copies of data are being managed on different physical servers, so that if a physical server fails or is disconnected, all of the the data being managed by the failed server has backups ready to go on a different server.
Lastly, partitioning supports linear scalability of both data capacity and throughput. It accomplishes the scalability of data capacity by evenly balancing the data across all servers, so four servers can naturally manage two times as much data as two servers. Scalability of throughput is also a direct result of load-balancing the data across all servers, since as servers are added, each server is able to utilize its full processing power to manage a smaller and smaller percentage of the overall data set. For example, in a ten-server cluster each server has to manage 10% of the data operations, and – since Coherence uses a peer-to-peer architecture – 10% of those operations are coming from each server. With ten times that many servers (i.e. 100 servers), each server is managing only 1% of the data operations, and only 1% of those operations are coming from each server – but there are ten times as many servers, so the cluster is accomplishing ten times the total number of operations! In the 10-server example, if each of the ten servers was issuing 100 operations per second, they would each be sending 10 of those operations to each of the other servers, and the result would be that each server was receiving 100 operations (10x10) that it was responsible for processing. In the 100-server example, each would still be issuing 100 operations per second, but each would be sending only one operation to each of the other servers, so the result would be that each server was receiving 100 operations (100x1) that it was responsible for processing. This linear scalability is made possible by modern switched network architectures that provide backplanes that scale linearly to the number of ports on the switch, providing each port with dedicated fully-duplexed (upstream and downstream) bandwidth. Since each server is only sending and receiving 100 operations (in both the 10-server and 100-server examples), the network bandwidth utilization is roughly constant per port regardless of the number of servers in the cluster.
Session Management
One common use case for Coherence clustering is to manage user sessions (conversational state) in the cluster. This capability is provided by the Coherence*Web module, which is a built-in feature of Coherence. Coherence*Web provides linear scalability for HTTP Session Management in clusters of hundreds of production servers. It can achieve this linear scalability because at its core it is built on Coherence dynamic partitioning.
Session management highlights the scalability problem that typifies shared data sources: If an application could not share data across the servers, it would have to delegate that data management entirely to the shared store, which is typically the application's database. If the HTTP session were stored in the database, each HTTP request (in the absence of sticky load-balancing) would require a read from the database, causing the desired reads-per-second from the database to increase linearly with the size of the server cluster. Further, each HTTP request causes an update of its corresponding HTTP session, so regardless of sticky load balancing, to ensure that HTTP session data is not lost when a server fails the desired writes-per-second to the database will also increase linearly with the size of the server cluster. In both cases, the actual reads and writes per second that a database is capable of does not scale in relation to the number of servers requesting those reads and writes, and the database quickly becomes a bottleneck, forcing availability, reliability (e.g. asynchronous writes) and performance compromises. Additionally, related to performance, each read from a database has an associated latency, and that latency increases dramatically as the database experiences increasing load.
Coherence*Web, on the other hand, has the same latency in a 2-server cluster as it has in a 200-server cluster, since all HTTP session read operations that cannot be handled locally (e.g. locality as the result of to sticky load balancing) are spread out evenly across the rest of the cluster, and all update operations (which must be handled remotely to ensure survival of the HTTP sessions) are likewise spread out evently across the rest of the cluster. The result is linear scalability with constant latency, regardless of the size of the cluster.
Performance
Performance is the inverse of latency, and latency is the measurement of how long something takes to complete. If increasing performance is the goal, then getting rid of anything that has any latency is the solution. Obviously, it is impossible to get rid of all latencies, since the High Availability and reliability aspects of an application are counting on the underlying infrastructure, such as Coherence, to maintain reliable up-to-date back-ups of important information, which means that some operations (such as data modifications and pessimistic transactions) have unavoidable latencies. On the other hand, every remaining operation that could possibly have any latency needs to be targeted for elimination, and Coherence provides a large number of capabilities designed to do just that:
Replication
Just like partitioning dynamically load-balances data evenly across the entire server cluster, replication ensures that a desired set of data is up-to-date on every single server in the cluster at all times. Replication allows operations running on any server to obtain the data that they need locally, at basically no cost, because that data has already been replicated to that server. In other words, replication is a tool to guarantee locality of reference, and the end result is zero-latency access to replicated data.
Near Caching
Since replication works best for data that should be on all servers, it follows that replication is inefficient for data that an application would want to avoid copying to all servers. For example, data that changes all of the time and very large data sets are both poorly suited to replication, but both are excellently suited to partitioning, since it exhibits linear scale of data capacity and throughput.
The only downside of partitioning is that it introduces latency for data access, and in most applications the data access rate far out-weighs the data modification rate. To eliminate the latency associated with partitioned data access, near caching maintains frequently- and recently-used data from the partitioned cache on the specific servers that are accessing that data, and it keeps that data coherent by means of event-based invalidation. In other words, near caching keeps the most-likely-to-be-needed data near to where it will be used, thus providing good locality of access, yet backed up by the linear scalability of partitioning.
Write-Behind, Write-Coalescing and Write-Batching
Since the transactional throughput in the cluster is linearly scalable, the cost associated with data changes can be a fixed latency, typically in the range of a few milliseconds, and the total number of transactions per second is limited only by the size of the cluster. In one application, Coherence was able to achieve transaction rates close to a half-million transactions per second – and that on a cluster of commodity two-CPU servers.
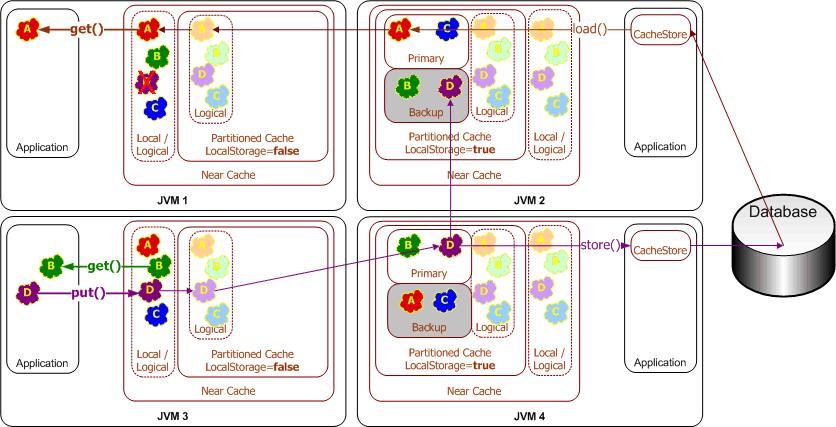
Often, the data being managed by Coherence is actually a temporary copy of data that exists in an official System Of Record (SOR), such as a database. To avoid having the database become a transaction bottleneck, and to eliminate the latency of database updates, Coherence provides a Write-Behind capability, which allows the application to change data in the cluster, and those changes are asynchronously replayed to the application's database (or EIS). By managing the changes in a clustered cache (which has all of the High Availability, reliability and scalability attributes described previously,) the pending changes are immune to server failure and the total rate of changes scales linearly with the size of the cluster.
The Write-Behind functionality is implemented by queueing each data change; the queue contains a list of what changes needs to be written to the System Of Record. The duration of an item within the queue is configurable, and is referred to as the Write-Behind Delay. When data changes, it is added to the write-behind queue (if it is not already in the queue), and the queue entry is set to ripen after the configured Write-Behind Delay has passed. When the queue entry has ripened, the latest copy of the corresponding data is written to the System Of Record.
To avoid overwhelming the System Of Record, Coherence will replay only the latest copies of data to the database, thus coalescing many updates that occur to the same piece data into a single database operation. The longer the Write-Behind Delay, the more coalescing may occur. Additionally, if many different pieces of data have changed, all of those updates can be batched (e.g. using JDBC statement batching) into a single database operation. In this way, a massive breadth of changes (number of pieces of data changed) and depth of changes (number of times each was changed) can be bundled into a single database operation, which results in dramatically reduced load on the database. The batching is also fully configurable; one option, called the Write Batch Factor, even allows some of the queue entries that have not yet ripened to be included in the batched update.
Serviceability
Serviceability refers to the ease and extent of changes that can be affected without affecting availability. Coherence helps to increase an application's serviceability by allowing servers to be taken off-line without impacting the application availability. Those servers can be serviced and brought back online without any end-user or processing interruptions. Many configuration changes related to Coherence can also be made on a node-by-node basis in the same manner. With careful planning, even major application changes can be rolled into production – again, one node at a time – without interrupting the application.
Manageability
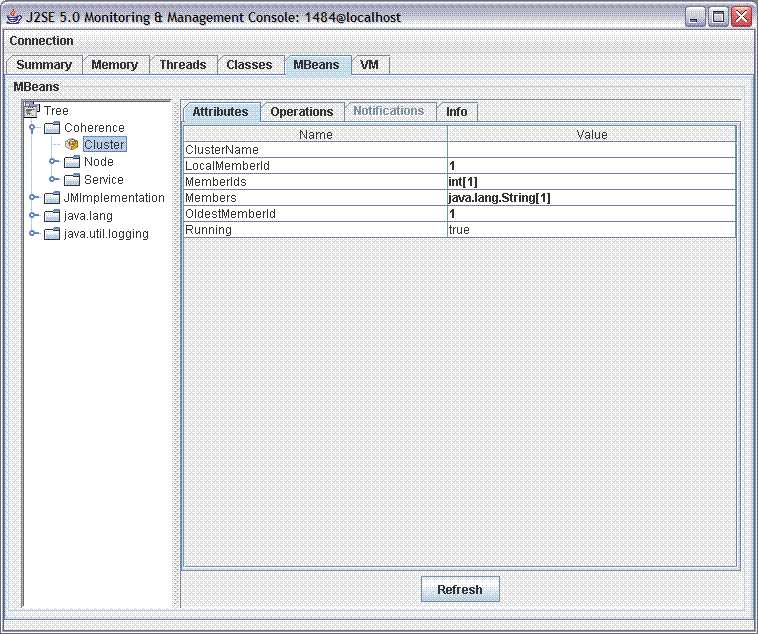
Manageability refers to the level of information that a running system provides, and the capability to tweak settings related to that information. For example, Coherence provides a cluster-wide view of management information via the standard JMX API, so that the entire cluster can be managed from a single server. The information provided includes hit and miss rates, cace sizes, read-, write- and write-behind statistics, and detailed information all the way down to the network packet level.
Additionally, Coherence allows applications to place their own management information – and expose their own tweakable settings – through the same clustered JMX implementation. The result is an application infrastructure that makes managing and monitoring a clustered application as simple as managing and monitoring a single server, and all through Java's standard management API.
Summary
There are a lot of challenges in building a highly available application that exhibits scalable performance and is both serviceable and manageable. While there are many ways to build distributed applications, only Coherence reliably clusters objects and data. Once objects and data are clustered by Coherence, all the servers in the cluster can access and modify those objects and that data, and the objects and data managed by Coherence will not be effected if and when servers fail. By providing a variety of advanced capabilities, each of which is configurable, and application can achieve the optimal balance of redundancy, scalability and performance, and do so within a manageable and serviceable environment.
Deliver events for changes as they occur
Overview
Coherence provides cache events using the JavaBean Event model. It is extremely simple to receive the events that you need, where you need them, regardless of where the changes are actually occurring in the cluster. Developers with any experience with the JavaBean model will have no difficulties working with events, even in a complex cluster.
Listener interface and Event object
In the JavaBeans Event model, there is an EventListener interface that all listeners must extend. Coherence provides a MapListener interface, which allows application logic to receive events when data in a Coherence cache is added, modified or removed:
public interface MapListener
extends EventListener
{
/**
* Invoked when a map entry has been inserted.
*
* @param evt the MapEvent carrying the insert information
*/
public void entryInserted(MapEvent evt);
/**
* Invoked when a map entry has been updated.
*
* @param evt the MapEvent carrying the update information
*/
public void entryUpdated(MapEvent evt);
/**
* Invoked when a map entry has been removed.
*
* @param evt the MapEvent carrying the delete information
*/
public void entryDeleted(MapEvent evt);
}
An application object that implements the MapListener interface can sign up for events from any Coherence cache or class that implements the ObservableMap interface, simply by passing an instance of the application's MapListener implementation to one of the addMapListener() methods.
The MapEvent object that is passed to the MapListener carries all of the necessary information about the event that has occurred, including the source (ObservableMap) that raised the event, the identity (key) that the event is related to, what the action was against that identity (insert, update or delete), what the old value was and what the new value is:
public class MapEvent
extends EventObject
{
/**
* Return an ObservableMap object on which this event has actually
* occured.
*
* @return an ObservableMap object
*/
public ObservableMap getMap()
/**
* Return this event's id. The event id is one of the ENTRY_*
* enumerated constants.
*
* @return an id
*/
public int getId()
/**
* Return a key associated with this event.
*
* @return a key
*/
public Object getKey()
/**
* Return an old value associated with this event.
* <p>
* The old value represents a value deleted from or updated in a map.
* It is always null for "insert" notifications.
*
* @return an old value
*/
public Object getOldValue()
/**
* Return a new value associated with this event.
* <p>
* The new value represents a new value inserted into or updated in
* a map. It is always null for "delete" notifications.
*
* @return a new value
*/
public Object getNewValue()
/**
* Return a String representation of this MapEvent object.
*
* @return a String representation of this MapEvent object
*/
public String toString()
/**
* This event indicates that an entry has been added to the map.
*/
public static final int ENTRY_INSERTED = 1;
/**
* This event indicates that an entry has been updated in the map.
*/
public static final int ENTRY_UPDATED = 2;
/**
* This event indicates that an entry has been removed from the map.
*/
public static final int ENTRY_DELETED = 3;
}
Caches and classes that support events
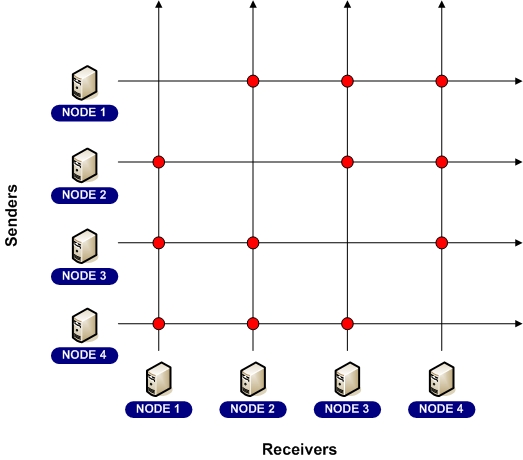
All Coherence caches implement ObservableMap; in fact, the NamedCache interface that is implemented by all Coherence caches extends the ObservableMap interface. That means that an application can sign up to receive events from any cache, regardless of whether that cache is local, partitioned, near, replicated, using read-through, write-through, write-behind, overflow, disk storage, etc.
 |
Regardless of the cache topology and the number of servers, and even if the modifications are being made by other servers, the events will be delivered to the application's listeners. |
In addition to the Coherence caches (those objects obtained through a Coherence cache factory), several other supporting classes in Coherence also implement the ObservableMap interface:
- ObservableHashMap
- LocalCache
- OverflowMap
- NearCache
- ReadWriteBackingMap
- AbstractSerializationCache, SerializationCache and SerializationPagedCache
- WrapperObservableMap, WrapperConcurrentMap and WrapperNamedCache
For a full list of published implementing classes, see the Coherence JavaDoc for ObservableMap.
Signing up for all events
To sign up for events, simply pass an object that implements the MapListener interface to one of the addMapListener methods on ObservableMap:
public void addMapListener(MapListener listener);
public void addMapListener(MapListener listener, Object oKey, boolean fLite);
public void addMapListener(MapListener listener, Filter filter, boolean fLite);
Let's create an example MapListener implementation:
/**
* A MapListener implementation that prints each event as it receives
* them.
*/
public static class EventPrinter
extends Base
implements MapListener
{
public void entryInserted(MapEvent evt)
{
out(evt);
}
public void entryUpdated(MapEvent evt)
{
out(evt);
}
public void entryDeleted(MapEvent evt)
{
out(evt);
}
}
Using this implementation, it is extremely simple to print out all events from any given cache (since all caches implement the ObservableMap interface):
cache.addMapListener(new EventPrinter());
Of course, to be able to later remove the listener, it is necessary to hold on to a reference to the listener:
Listener listener = new EventPrinter();
cache.addMapListener(listener);
m_listener = listener;
Later, to remove the listener:
Listener listener = m_listener;
if (listener != null)
{
cache.removeMapListener(listener);
m_listener = null; }
Each addMapListener method on the ObservableMap interface has a corresponding removeMapListener method. To remove a listener, use the removeMapListener method that corresponds to the addMapListener method that was used to add the listener.
Using an inner class as a MapListener
When creating an an inner class to use as a MapListener, or when implementing a MapListener that only listens to one or two types of events (inserts, updates or deletes), you can use the AbstractMapListener base class. For example, the following anonymous inner class prints out only the insert events for the cache:
cache.addMapListener(new AbstractMapListener()
{
public void entryInserted(MapEvent evt)
{
out(evt);
}
});
Another helpful base class for creating a MapListener is the MultiplexingMapListener, which routes all events to a single method for handling. For example, the EventPrinter example could be simplified to:
public static class EventPrinter
extends MultiplexingMapListener
{
public void onMapEvent(MapEvent evt)
{
out(evt);
}
}
Since only one method needs to be implemented to capture all events, the MultiplexingMapListener can also be very useful when creating an an inner class to use as a MapListener.
Configuring a MapListener for a Cache
If the listener should always be on a particular cache, then place it into the cache configuration using the listener element and Coherence will automatically add the listener when it configures the cache.
Signing up for Events on specific identities
Signing up for events that occur against specific identities (keys) is just as simple. For example, to print all events that occur against the Integer key "5":
cache.addMapListener(new EventPrinter(), new Integer(5), false);
So the following code would only trigger an event when the Integer key "5" is inserted or updated:
for (int i = 0; i < 10; ++i)
{
Integer key = new Integer(i);
String value = "test value for key " + i;
cache.put(key, value);
}
Filtering Events
Similar to listening to a particular key, it is possible to listen to particular events. Consider the following example:
public class DeletedFilter
implements Filter, Serializable
{
public boolean evaluate(Object o)
{
MapEvent evt = (MapEvent) o;
return evt.getId() == MapEvent.ENTRY_DELETED;
}
}
cache.addMapListener(new EventPrinter(), new DeletedFilter(), false);
 | Filtering events versus filtering cached data
When building a Filter for querying, the object that will be passed to the evaluate method of the Filter will be a value from the cache, or – if the Filter implements the EntryFilter interface – the entire Map.Entry from the cache. When building a Filter for filtering events for a MapListener, the object that will be passed to the evaluate method of the Filter will always be of type MapEvent.
For more information on how to use a query filter to listen to cache events, see the section below titled Advanced: Listening to Queries. |
The listener is added to the cache with a filter that allows the listener to only receive delete events. For example, if the following sequence of calls were made:
cache.put("hello", "world");
cache.put("hello", "again");
cache.remove("hello");
The result would be:
For more information, see the Advanced: Listening to Queries section below.
"Lite" Events
By default, Coherence provides both the old and the new value as part of an event. Consider the following example:
MapListener listener = new MultiplexingMapListener()
{
public void onMapEvent(MapEvent evt)
{
out("event has occurred: " + evt);
out("(the wire-size of the event would have been "
+ ExternalizableHelper.toBinary(evt).length()
+ " bytes.)");
}
};
cache.addMapListener(listener);
cache.put("test", new byte[1024]);
cache.put("test", new byte[2048]);
cache.remove("test");
The output from running the test shows that the first event carries the 1KB inserted value, the second event carries both the replaced 1KB value and the new 2KB value, and the third event carries the removed 2KB value:
When an application does not require the old and the new value to be included in the event, it can indicate that by requesting only "lite" events. When adding a listener, you can request lite events by using one of the two addMapListener methods that takes an additional boolean fLite parameter. In the above example, the only change would be:
cache.addMapListener(listener, (Filter) null, true);
|
Obviously, a lite event's old value and new value may be null. However, even if you request lite events, the old and the new value may be included if there is no additional cost to generate and deliver the event. In other words, requesting that a MapListener receive lite events is simply a hint to the system that the MapListener does not need to know the old and new values for the event. |
Advanced: Listening to Queries
All Coherence caches support querying by any criteria. When an application queries for data from a cache, the result is a point-in-time snapshot, either as a set of identities ("keySet") or a set of identity/value pairs ("entrySet"). The mechanism for determining the contents of the resulting set is referred to as filtering, and it allows an application developer to construct queries of arbitrary complexity using a rich set of out-of-the-box filters (e.g. equals, less-than, like, between, etc.), or to provide their own custom filters (e.g. XPath).
The same filters that are used to query a cache can be used to listen to events from a cache. For example, in a trading system it is possible to query for all open "Order" objects for a particular trader:
NamedCache mapTrades = ...
Filter filter = new AndFilter(new EqualsFilter("getTrader", traderid),
new EqualsFilter("getStatus", Status.OPEN));
Set setOpenTrades = mapTrades.entrySet(filter);
To receive notifications of new trades being opened for that trader, closed by that trader or reassigned to or from another trader, the application can use the same filter:
trades.addMapListener(listener, new MapEventFilter(filter), true);
The MapEventFilter converts a query filter into an event filter.
| Filtering events versus filtering cached data
When building a Filter for querying, the object that will be passed to the evaluate method of the Filter will be a value from the cache, or – if the Filter implements the EntryFilter interface – the entire Map.Entry from the cache. When building a Filter for filtering events for a MapListener, the object that will be passed to the evaluate method of the Filter will always be of type MapEvent.
The MapEventFilter converts a Filter that is used to do a query into a Filter that is used to filter events for a MapListener. In other words, the MapEventFilter is constructed from a Filter that queries a cache, and the resulting MapEventFilter is a filter that evaluates MapEvent objects by converting them into the objects that a query Filter would expect. |
The MapEventFilter has a number of very powerful options, allowing an application listener to receive only the events that it is specifically interested in. More importantly for scalability and performance, only the desired events have to be communicated over the network, and they are communicated only to the servers and clients that have expressed interest in those specific events! For example:
nMask = MapEventFilter.E_ALL;
trades.addMapListener(listener, new MapEventFilter(nMask, filter), true);
nMask = MapEventFilter.E_UPDATED_LEFT | MapEventFilter.E_DELETED;
trades.addMapListener(listener, new MapEventFilter(nMask, filter), true);
nMask = MapEventFilter.E_INSERTED | MapEventFilter.E_UPDATED_ENTERED;
trades.addMapListener(listener, new MapEventFilter(nMask, filter), true);
nMask = MapEventFilter.E_INSERTED;
trades.addMapListener(listener, new MapEventFilter(nMask, filter), true);
For more information on the various options supported, see the API documentation for MapEventFilter.
Advanced: Synthetic Events
Events usually reflect the changes being made to a cache. For example, one server is modifying one entry in a cache while another server is adding several items to a cache while a third server is removing an item from the same cache, all while fifty threads on each and every server in the cluster is accessing data from the same cache! All the modifying actions will produce events that any server within the cluster can choose to receive. We refer to these actions as client actions, and the events as being dispatched to clients, even though the "clients" in this case are actually servers. This is a natural concept in a true peer-to-peer architecture, such as a Coherence cluster: Each and every peer is both a client and a server, both consuming services from its peers and providing services to its peers. In a typical Java Enterprise application, a "peer" is an application server instance that is acting as a container for the application, and the "client" is that part of the application that is directly accessing and modifying the caches and listening to events from the caches.
Some events originate from within a cache itself. There are many examples, but the most common cases are:
- When entries automatically expire from a cache;
- When entries are evicted from a cache because the maximum size of the cache has been reached;
- When entries are transparently added to a cache as the result of a Read-Through operation;
- When entries in a cache are transparently updated as the result of a Read-Ahead or Refresh-Ahead operation.
Each of these represents a modification, but the modifications represent natural (and typically automatic) operations from within a cache. These events are referred to as synthetic events.
When necessary, an application can differentiate between client-induced and synthetic events simply by asking the event if it is synthetic. This information is carried on a sub-class of the MapEvent, called CacheEvent. Using the previous EventPrinter example, it is possible to print only the synthetic events:
public static class EventPrinter
extends MultiplexingMapListener
{
public void onMapEvent(MapEvent evt)
{
if (evt instanceof CacheEvent && ((CacheEvent) evt).isSynthetic())
{
out(evt);
)
}
}
For more information on this feature, see the API documentation for CacheEvent.
Advanced: Backing Map Events
While it is possible to listen to events from Coherence caches, each of which presents a local view of distributed, partitioned, replicated, near-cached, continuously-queried, read-through/write-through and/or write-behind data, it is also possible to peek behind the curtains, so to speak. Normally, the advice from the Wizard of Oz is sufficient:
 | "Pay no attention to the man behind the curtain!"
|
For some advanced use cases, it may be necessary to pay attention the man behind the curtain – or more correctly, to "listen to" the "map" behind the "service". Replication, partitioning and other approaches to managing data in a distributed environment are all distribution services. The service still has to have something in which to actually manage the data, and that something is called a "backing map".
Backing maps are configurable. If all the data for a particular cache should be kept in object form on the heap, then use an unlimited and non-expiring LocalCache (or a SafeHashMap if statistics are not required). If only a small number of items should be kept in memory, use a LocalCache. If data are to be read on demand from a database, then use a ReadWriteBackingMap (which knows how to read and write through an application's DAO implementation), and in turn give the ReadWriteBackingMap a backing map such as a SafeHashMap or a LocalCache to store its data in.
Some backing maps are observable. The events coming from these backing maps are not usually of direct interest to the appication. Instead, Coherence translates them into actions that must be taken (by Coherence) to keep data in sync and properly backed up, and it also translates them when appropriate into clustered events that are delivered throughout the cluster as requested by application listeners. For example, if a partitioned cache has a LocalCache as its backing map, and the local cache expires an entry, that event causes Coherence to expire all of the backup copies of that entry. Furthermore, if any listeners have been registered on the partitioned cache, and if the event matches their event filter(s), then that event will be delivered to those listeners on the servers where those listeners were registered.
In some advanced use cases, an application needs to process events on the server where the data are being maintained, and it needs to do so on the structure (backing map) that is actually managing the data. In these cases, if the backing map is an observable map, a listener can be configured on the backing map or one can be programmatically added to the backing map. (If the backing map is not observable, it can be made observable by wrapping it in an WrapperObservableMap.)
For more information on this feature, see the API documentation for BackingMapManager.
Advanced: Synchronous Event Listeners
Some events are delivered asynchronously, so that application listeners do not disrupt the cache services that are generating the events. In some rare scenarios, asynchronous delivery can cause ambiguity of the ordering of events compared to the results of ongoing operations. To guarantee that the cache API operations and the events are ordered as if the local view of the clustered system were single-threaded, a MapListener must implement the SynchronousListener marker interface.
One example in Coherence itself that uses synchronous listeners is the Near Cache, which can use events to invalidate locally cached data ("Seppuku").
For more information on this feature, see the API documentation for SynchronousListener.
Summary
Coherence provides an extremely rich event model for caches, providing the means for an application to request the specific events it requires, and the means to have those events delivered only to those parts of the application that require them.
Automatically manage dynamic cluster membership
Overview
Coherence manages cluster membership, automatically adding new servers to the cluster when they start up and automatically detecting their departure when they are shut down or fail. Applications have full access to this information, and can sign up to receive event notifications when members join and leave the cluster. Coherence also tracks all the services that each member is providing and consuming, and uses this information to plan for service resiliency in case of server failure, and to load-balance data management and other responsibilities across all members of the cluster.
Cluster and Service objects
From any cache, the application can obtain a reference to the local representation of a cache's service. From any service, the application can obtain a reference to the local representation of the cluster.
CacheService service = cache.getCacheService();
Cluster cluster = service.getCluster();
From the Cluster object, the application can determine the set of services that are running in the cluster:
for (Enumeration enum = cluster.getServiceNames(); enum.hasMoreElements(); )
{
String sName = (String) enum.nextElement();
ServiceInfo info = cluster.getServiceInfo(sName);
}
The ServiceInfo object provides information about the service, including its name, type, version and membership.
For more information on this feature, see the API documentation for NamedCache, CacheService, Service, ServiceInfo and Cluster.
Member object
The primary information that an application can determine about each member in the cluster is:
- The Member's IP address
- What date/time the Member joined the cluster
As an example, if there are four servers in the cluster with each server running one copy ("instance") of the application and all four instances of the application are clustered together, then the cluster is composed of four Members. From the Cluster object, the application can determine what the local Member is:
Member memberThis = cluster.getLocalMember();
From the Cluster object, the application can also determine the entire set of cluster members:
Set setMembers = cluster.getMemberSet();
From the ServiceInfo object, the application can determine the set of cluster members that are participating in that service:
ServiceInfo info = cluster.getServiceInfo(sName);
Set setMembers = info.getMemberSet();
For more information on this feature, see the [API documentation for Member.
Listener interface and Event object
To listen to cluster and/or service membership changes, the application places a listener on the desired Service. As discussed before, the Service can come from a cache:
Service service = cache.getCacheService();
The Service can also be looked up by its name:
Service service = cluster.getService(sName);
To receive membership events, the application implements a MemberListener. For example, the following listener example prints out all the membership events that it receives:
public class MemberEventPrinter
extends Base
implements MemberListener
{
public void memberJoined(MemberEvent evt)
{
out(evt);
}
public void memberLeaving(MemberEvent evt)
{
out(evt);
}
public void memberLeft(MemberEvent evt)
{
out(evt);
}
}
The MemberEvent object carries information about the event type (joined / leaving / left), the member that generated the event, and the service that acts as the source of the event. Additionally, the event provides a method, isLocal(), that indicates to the application that it is this member that is joining or leaving the cluster. This is useful for recognizing soft restarts in which an application automatically rejoins a cluster after a failure occurs. For example:
public class RejoinEventPrinter
extends Base
implements MemberListener
{
public void memberJoined(MemberEvent evt)
{
if (evt.isLocal())
{
out("this member just rejoined the cluster: " + evt);
}
}
public void memberLeaving(MemberEvent evt)
{
}
public void memberLeft(MemberEvent evt)
{
}
}
For more information on these feature, see the [API documentation for Service, MemberListener and MemberEvent.
Provide a Queryable Data Fabric
Overview
Oracle invented the concept of a data fabric with the introduction of the Coherence partitioned data management service in 2002. Since then, Forrester Research has labeled the combination of data virtualization, transparent and distributed EIS integration, queryability and uniform accessibility found in Coherence as an information fabric. The term fabric comes from a 2-dimensional illustration of interconnects, as in a switched fabric. The purpose of a fabric architecture is that all points within a fabric have a direct interconnect with all other points.
Data Fabric
An information fabric, or the more simple form called a data fabric or data grid, uses a switched fabric concept as the basis for managing data in a distributed environment. Also referred to as a dynamic mesh architecture, Coherence automatically and dynamically forms a reliable, increasingly resilient switched fabric composed of any number of servers within a grid environment. Consider the attributes and benefits of this architecture:
- The aggregate data throughput of the fabric is linearly proportional to the number of servers;
- The in-memory data capacity and data-indexing capacity of the fabric is linearly proportional to the number of servers;
- The aggregate I/O throughput for disk-based overflow and disk-based storage of data is linearly proportional to the number of servers;
- The resiliency of the fabric increases with the extent of the fabric, resulting in each server being responsible for only 1/n of the failover responsibility for a fabric with an extent of n servers;
- If the fabric is servicing clients, such as trading systems, the aggregage maximum number of clients that can be served is linearly proportional to the number of servers.
Coherence accomplishes these technical feats through a variety of algorithms:
- Coherence dynamically partitions data across all data fabric nodes;
- Since each data fabric node has a configurable maximum amount of data that it will manage, the capacity of the data fabric is linearly proportional to the number of data fabric nodes;
- Since the partitioning is automatic and load-balancing, each data fabric node ends up with its fair share of the data management responsibilities, allowing the throughput (in terms of network throughput, disk I/O throughput, query throughput, etc.) to scale linearly with the number of data fabric nodes;
- Coherence maintains a configurable level of redundancy of data, automatically eliminating single points of failure (SPOFs) by ensuring that data is kept synchronously up-to-date in multiple data fabric nodes;
- Coherence spreads out the responsibility for data redundancy in a dynamically load-balanced manner so that each server backs up a small amount of data from many other servers, instead of backing up all of the data from one particular server, thus amortizing the impact of a server failure across the entire data fabric;
- Each data fabric node can handle a large number of client connections, which can be load-balanced by a hardware load balancer.
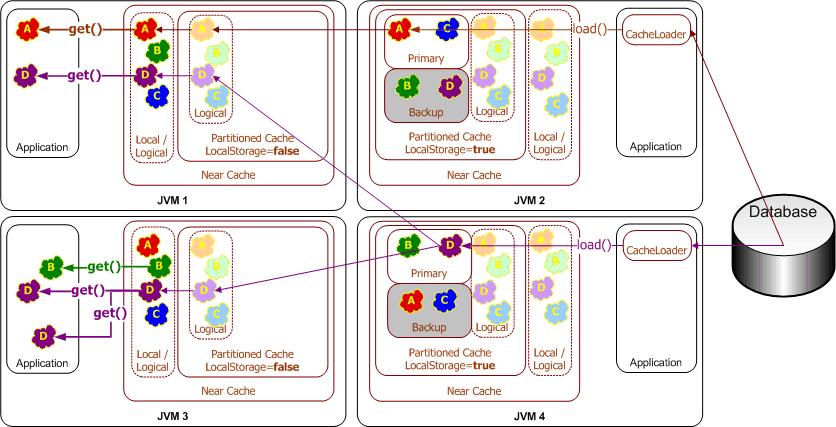
EIS and Database Integration
The Coherence information fabric can automatically load data on demand from an underlying database or EIS using automatic read-through functionality. If data in the fabric are modified, the same functionality allows that data to be synchronously updated in the database, or queued for asynchronous write-behind.
Coherence automatically partitions data access across the data fabric, resulting in load-balanced data accesses and efficient use of database and EIS connectivity. Furthermore, the read-ahead and write-behind capabilities can cut data access latencies to near-zero levels and insulate the application from temporary database and EIS failures.
| Coherence solves the data bottleneck for large-scale compute grids
In large-scale compute grids, such as in DataSynapse financial grids and biotech grids, the bottleneck for most compute processes is in loading a data set and making it available to the compute engines that require it. By layering a Coherence data fabric onto (or beside) a compute grid, these data sets can be maintained in memory at all times, and Coherence can feed the data in parallel at close to wire speed to all of the compute nodes. In a large-scale deployment, Coherence can provide several thousand times the aggregate data throughput of the underlying data source. |
Queryable
The Coherence information fabric supports querying from any server in the fabric or any client of the fabric. The queries can be performed using any criteria, including custom criteria such as XPath queries and full text searches. When Coherence partitioning is used to manage the data, the query is processed in parallel across the entire fabric (i.e. the query is also partitioned), resulting in an data query engine that can scale its throughput up to fabrics of thousands of servers. For example, in a trading system it is possible to query for all open "Order" objects for a particular trader:
NamedCache mapTrades = ...
Filter filter = new AndFilter(new EqualsFilter("getTrader", traderid),
new EqualsFilter("getStatus", Status.OPEN));
Set setOpenTrades = mapTrades.entrySet(filter);
When an application queries for data from the fabric, the result is a point-in-time snapshot. Additionally, the query results can be kept up-to-date by placing a listener on the query itself or by using the Coherence Continuous Query feature.
Continuous Query
While it is possible to obtain a point in time query result from a Coherence data fabric, and it is possible to receive events that would change the result of that query, Coherence provides a feature that combines a query result with a continuous stream of related events that maintain the query result in a real-time fashion. This capability is called Continuous Query, because it has the same effect as if the desired query had zero latency and the query were repeated several times every millisecond!
Coherence implements Continuous Query using a combination of its data fabric parallel query capability and its real-time event-filtering and streaming. The result is support for thousands of client application instances, such as trading desktops. Using the previous trading system example, it can be converted to a Continuous Query with only one a single line of code changed:
NamedCache mapTrades = ...
Filter filter = new AndFilter(new EqualsFilter("getTrader", traderid),
new EqualsFilter("getStatus", Status.OPEN));
NamedCache mapOpenTrades = new ContinuousQueryCache(mapTrades, filter);
The result of the Continuous Query is maintained locally, and optionally all of corresponding data can be cached locally as well.
Summary
Coherence is successfully deployed as a large-scale data fabric for many of the world's largest financial, telecommunications, logistics, travel and media organizations. With unlimited scalability, the highest levels of availability, close to zero latency, an incredibly rich set of capabilities and a sterling reputation for quality, Coherence is the Information Fabric of choice.
Provide a Data Grid
Overview
Coherence provides the ideal infrastructure for building Data Grid services, as well as the client and server-based applications that utilize a Data Grid. At a basic level, Coherence can manage an immense amount of data across a large number of servers in a grid; it can provide close to zero latency access for that data; it supports parallel queries across that data; and it supports integration with database and EIS systems that act as the system of record for that data. For more information on the infrastructure for the Data Grid features in Coherence, refer to the discussion on Data Fabric capabilities. Additionally, Coherence provides a number of services that are ideal for building effective data grids.
| All of the Data Grid capabilities described below are features of Coherence Enterprise Edition and higher.
|
Targeted Execution
Coherence provides for the ability to execute an agent against an entry in any map of data managed by the Data Grid:
In the case of partitioned data, the agent executes on the grid node that owns the data to execute against. This means that the queueing, concurrency management, agent execution, data access by the agent and data modification by the agent all occur on that grid node. (Only the synchronous backup of the resultant data modification, if any, requires additional network traffic.) For many processing purposes, it is much more efficient to move the serialized form of the agent (usually only a few hundred bytes, at most) than to handle distributed concurrency control, coherency and data updates.
For request/response processing, the agent returns a result:
Object oResult = map.invoke(key, agent);
In other words, Coherence as a Data Grid will determine the location to execute the agent based on the configuration for the data topology, move the agent there, execute the agent (automatically handling concurrency control for the item while executing the agent), back up the modifications if any, and return a result.
Parallel Execution
Coherence additionally provides for the ability to execute an agent against an entire collection of entries. In a partitioned Data Grid, the execution occurs in parallel, meaning that the more nodes that are in the grid, the broader the work is load-balanced across the Data Grid:
map.invokeAll(collectionKeys, agent);
For request/response processing, the agent returns one result for each key processed:
Map mapResults = map.invokeAll(collectionKeys, agent);
In other words, Coherence determines the optimal location(s) to execute the agent based on the configuration for the data topology, moves the agent there, executes the agent (automatically handling concurrency control for the item(s) while executing the agent), backing up the modifications if any, and returning the coalesced results.
Query-Based Execution
As discussed in the queryable data fabric topic, Coherence supports the ability to query across the entire data grid. For example, in a trading system it is possible to query for all open "Order" objects for a particular trader:
NamedCache map = CacheFactory.getCache("trades");
Filter filter = new AndFilter(new EqualsFilter("getTrader", traderid),
new EqualsFilter("getStatus", Status.OPEN));
Set setOpenTradeIds = mapTrades.keySet(filter);
By combining this feature with Parallel Execution in the data grid, Coherence provides for the ability to execute an agent against a query. As in the previous section, the execution occurs in parallel, and instead of returning the identities or entries that match the query, Coherence executes the agents against the entries:
map.invokeAll(filter, agent);
For request/response processing, the agent returns one result for each key processed:
Map mapResults = map.invokeAll(filter, agent);
In other words, Coherence combines its Parallel Query and its Parallel Execution together to achieve query-based agent invocation against a Data Grid.
Data-Grid-Wide Execution
Passing an instance of AlwaysFilter (or a null) to the invokeAll method will cause the passed agent to be executed against all entries in the InvocableMap:
map.invokeAll((Filter) null, agent);
As with the other types of agent invocation, request/response processing is supported:
Map mapResults = map.invokeAll((Filter) null, agent);
In other words, with a single line of code, an application can process all the data spread across a particular map in the Data Grid.
Agents for Targeted, Parallel and Query-Based Execution
An agent implements the EntryProcessor interface, typically by extending the AbstractProcessor class.
A number of agents are included with Coherence, including:
- AbstractProcessor - an abstract base class for building an EntryProcessor
- ExtractorProcessor - extracts and returns a specific value (such as a property value) from an object stored in an InvocableMap
- CompositeProcessor - bundles together a collection of EntryProcessor objects that are invoked sequentially against the same Entry
- ConditionalProcessor - conditionally invokes an EntryProcessor if a Filter against the Entry-to-process evaluates to true
- PropertyProcessor - an abstract base class for EntryProcessor implementations that depend on a PropertyManipulator
- NumberIncrementor - pre- or post-increments any property of a primitive integral type, as well as Byte, Short, Integer, Long, Float, Double, BigInteger, BigDecimal
- NumberMultiplier - multiplies any property of a primitive integral type, as well as Byte, Short, Integer, Long, Float, Double, BigInteger, BigDecimal, and returns either the previous or new value
The EntryProcessor interface (contained within the InvocableMap interface) contains only two methods:
/**
* An invocable agent that operates against the Entry objects within a
* Map.
*/
public interface EntryProcessor
extends Serializable
{
/**
* Process a Map Entry.
*
* @param entry the Entry to process
*
* @return the result of the processing, if any
*/
public Object process(Entry entry);
/**
* Process a Set of InvocableMap Entry objects. This method is
* semantically equivalent to:
* <pre>
* Map mapResults = new ListMap();
* for (Iterator iter = setEntries.iterator(); iter.hasNext(); )
* {
* Entry entry = (Entry) iter.next();
* mapResults.put(entry.getKey(), process(entry));
* }
* return mapResults;
* </pre>
*
* @param setEntries a read-only Set of InvocableMap Entry objects to
* process
*
* @return a Map containing the results of the processing, up to one
* entry for each InvocableMap Entry that was processed, keyed
* by the keys of the Map that were processed, with a
* corresponding value being the result of the processing for
* each key
*/
public Map processAll(Set setEntries);
}
(The AbstractProcessor implements the processAll method as described in the JavaDoc above.)
The InvocableMap.Entry that is passed to an EntryProcessor is an extension of the Map.Entry interface that allows an EntryProcessor implementation to obtain the necessary information about the entry and to make the necessary modifications in the most efficient manner possible:
/**
* An InvocableMap Entry contains additional information and exposes
* additional operations that the basic Map Entry does not. It allows
* non-existent entries to be represented, thus allowing their optional
* creation. It allows existent entries to be removed from the Map. It
* supports a number of optimizations that can ultimately be mapped
* through to indexes and other data structures of the underlying Map.
*/
public interface Entry
extends Map.Entry
{
/**
* Return the key corresponding to this entry. The resultant key does
* not necessarily exist within the containing Map, which is to say
* that <tt>InvocableMap.this.containsKey(getKey)</tt> could return
* false. To test for the presence of this key within the Map, use
* {@link #isPresent}, and to create the entry for the key, use
* {@link #setValue}.
*
* @return the key corresponding to this entry; may be null if the
* underlying Map supports null keys
*/
public Object getKey();
/**
* Return the value corresponding to this entry. If the entry does
* not exist, then the value will be null. To differentiate between
* a null value and a non-existent entry, use {@link #isPresent}.
* <p/>
* <b>Note:</b> any modifications to the value retrieved using this
* method are not guaranteed to persist unless followed by a
* {@link #setValue} or {@link #update} call.
*
* @return the value corresponding to this entry; may be null if the
* value is null or if the Entry does not exist in the Map
*/
public Object getValue();
/**
* Store the value corresponding to this entry. If the entry does
* not exist, then the entry will be created by invoking this method,
* even with a null value (assuming the Map supports null values).
*
* @param oValue the new value for this Entry
*
* @return the previous value of this Entry, or null if the Entry did
* not exist
*/
public Object setValue(Object oValue);
/**
* Store the value corresponding to this entry. If the entry does
* not exist, then the entry will be created by invoking this method,
* even with a null value (assuming the Map supports null values).
* <p/>
* Unlike the other form of {@link #setValue(Object) setValue}, this
* form does not return the previous value, and as a result may be
* significantly less expensive (in terms of cost of execution) for
* certain Map implementations.
*
* @param oValue the new value for this Entry
* @param fSynthetic pass true only if the insertion into or
* modification of the Map should be treated as a
* synthetic event
*/
public void setValue(Object oValue, boolean fSynthetic);
/**
* Extract a value out of the Entry's value. Calling this method is
* semantically equivalent to
* <tt>extractor.extract(entry.getValue())</tt>, but this method may
* be significantly less expensive because the resultant value may be
* obtained from a forward index, for example.
*
* @param extractor a ValueExtractor to apply to the Entry's value
*
* @return the extracted value
*/
public Object extract(ValueExtractor extractor);
/**
* Update the Entry's value. Calling this method is semantically
* equivalent to:
* <pre>
* Object oTarget = entry.getValue();
* updater.update(oTarget, oValue);
* entry.setValue(oTarget, false);
* </pre>
* The benefit of using this method is that it may allow the Entry
* implementation to significantly optimize the operation, such as
* for purposes of delta updates and backup maintenance.
*
* @param updater a ValueUpdater used to modify the Entry's value
*/
public void update(ValueUpdater updater, Object oValue);
/**
* Determine if this Entry exists in the Map. If the Entry is not
* present, it can be created by calling {@link #setValue} or
* {@link #setValue}. If the Entry is present, it can be destroyed by
* calling {@link #remove}.
*
* @return true iff this Entry is existent in the containing Map
*/
public boolean isPresent();
/**
* Remove this Entry from the Map if it is present in the Map.
* <p/>
* This method supports both the operation corresponding to
* {@link Map#remove} as well as synthetic operations such as
* eviction. If the containing Map does not differentiate between
* the two, then this method will always be identical to
* <tt>InvocableMap.this.remove(getKey())</tt>.
*
* @param fSynthetic pass true only if the removal from the Map
* should be treated as a synthetic event
*/
public void remove(boolean fSynthetic);
}
Data Grid Aggregation
While the above agent discussion correspond to scalar agents, the InvocableMap interface also supports aggregation:
/**
* Perform an aggregating operation against the entries specified by the
* passed keys.
*
* @param collKeys the Collection of keys that specify the entries within
* this Map to aggregate across
* @param agent the EntryAggregator that is used to aggregate across
* the specified entries of this Map
*
* @return the result of the aggregation
*/
public Object aggregate(Collection collKeys, EntryAggregator agent);
/**
* Perform an aggregating operation against the set of entries that are
* selected by the given Filter.
* <p/>
* <b>Note:</b> calling this method on partitioned caches requires a
* Coherence Enterprise Edition (or higher) license.
*
* @param filter the Filter that is used to select entries within this
* Map to aggregate across
* @param agent the EntryAggregator that is used to aggregate across
* the selected entries of this Map
*
* @return the result of the aggregation
*/
public Object aggregate(Filter filter, EntryAggregator agent);
A simple EntryAggregator processes a set of InvocableMap.Entry objects to achieve a result:
/**
* An EntryAggregator represents processing that can be directed to occur
* against some subset of the entries in an InvocableMap, resulting in a
* aggregated result. Common examples of aggregation include functions
* such as min(), max() and avg(). However, the concept of aggregation
* applies to any process that needs to evaluate a group of entries to
* come up with a single answer.
*/
public interface EntryAggregator
extends Serializable
{
/**
* Process a set of InvocableMap Entry objects in order to produce an
* aggregated result.
*
* @param setEntries a Set of read-only InvocableMap Entry objects to
* aggregate
*
* @return the aggregated result from processing the entries
*/
public Object aggregate(Set setEntries);
}
For efficient execution in a Data Grid, an aggregation process must be designed to operate in a parallel manner. The
/**
* A ParallelAwareAggregator is an advanced extension to EntryAggregator
* that is explicitly capable of being run in parallel, for example in a
* distributed environment.
*/
public interface ParallelAwareAggregator
extends EntryAggregator
{
/**
* Get an aggregator that can take the place of this aggregator in
* situations in which the InvocableMap can aggregate in parallel.
*
* @return the aggregator that will be run in parallel
*/
public EntryAggregator getParallelAggregator();
/**
* Aggregate the results of the parallel aggregations.
*
* @return the aggregation of the parallel aggregation results
*/
public Object aggregateResults(Collection collResults);
}
Coherence comes with all of the natural aggregation functions, including:
Node-Based Execution
Coherence provides an Invocation Service which allows execution of single-pass agents (called Invocable objects) anywhere within the grid. The agents can be executed on any particular node of the grid, in parallel on any particular set of nodes in the grid, or in parallel on all nodes of the grid.
An invocation service is configured using the invocation-scheme element in the cache configuration file. Using the name of the service, the application can easily obtain a reference to the service:
InvocationService service = CacheFactory.getInvocationService("agents");
Agents are simply runnable classes that are part of the application. The simplest example is a simple agent that is designed to request a GC from the JVM:
/**
* Agent that issues a garbage collection.
*/
public class GCAgent
extends AbstractInvocable
{
public void run()
{
System.gc();
}
}
To execute that agent across the entire cluster, it takes one line of code:
service.execute(new GCAgent(), null, null);
Here is an example of an agent that supports a grid-wide request/response model:
/**
* Agent that determines how much free memory a grid node has.
*/
public class FreeMemAgent
extends AbstractInvocable
{
public void run()
{
Runtime runtime = Runtime.getRuntime();
int cbFree = runtime.freeMemory();
int cbTotal = runtime.totalMemory();
setResult(new int[] {cbFree, cbTotal});
}
}
To execute that agent across the entire grid and retrieve all the results from it, it still takes only one line of code:
Map map = service.query(new FreeMemAgent(), null);
While it is easy to do a grid-wide request/response, it takes a bit more code to print out the results:
Iterator iter = map.entrySet().iterator();
while (iter.hasNext())
{
Map.Entry entry = (Map.Entry) iter.next();
Member member = (Member) entry.getKey();
int[] anInfo = (int[]) entry.getValue();
if (anInfo != null) System.out.println("Member " + member + " has "
+ anInfo[0] + " bytes free out of "
+ anInfo[1] + " bytes total");
}
The agent operations can be stateful, which means that their invocation state is serialized and transmitted to the grid nodes on which the agent is to be run.
/**
* Agent that carries some state with it.
*/
public class StatefulAgent
extends AbstractInvocable
{
public StatefulAgent(String sKey)
{
m_sKey = sKey;
}
public void run()
{
String sKey = m_sKey;
}
private String m_sKey;
}
Work Manager
Coherence provides a grid-enabled implementation of the IBM and BEA CommonJ Work Manager, which is the basis for JSR-237. Once JSR-237 is complete, Oracle has committed to support the standardized J2EE API for Work Manager as well.
Using a Work Manager, an application can submit a collection of work that needs to be executed. The Work Manager distributes that work in such a way that it is executed in parallel, typically across the grid. In other words, if there are ten work items submitted and ten servers in the grid, then each server will likely process one work item. Further, the distribution of work items across the grid can be tailored, so that certain servers (e.g. one that acts as a gateway to a particular mainframe service) will be the first choice to run certain work items, for sake of efficiency and locality of data.
The application can then wait for the work to be completed, and can provide a timeout for how long it is willing to wait. The API for this purpose is quite powerful, allowing an application to wait for the first work item to complete, or for a specified set of the work items to complete. By combining methods from this API, it is possible to do things like "Here are 10 items to execute; for these 7 unimportant items, wait no more than 5 seconds, and for these 3 important items, wait no more than 30 seconds":
Work[] aWork = ...
Collection collBigItems = new ArrayList();
Collection collAllItems = new ArrayList();
for (int i = 0, c = aWork.length; i < c; ++i)
{
WorkItem item = manager.schedule(aWork[i]);
if (i < 3)
{
collBigItems.add(item);
}
collAllItems.add(item);
}
Collection collDone = manager.waitForAll(collAllItems, 5000L);
if (!collDone.containsAll(collBigItems))
{
manager.waitForAll(collBigItems, 25000L);
}
Of course, the best descriptions come from real-world production usage:
Our primary use case for the Work Manager is to allow our application to serve coarse-grained service requests using our blade infrastructure in a standards-based way. We often have what appears to be a simple request, like "give me this family's information." In reality, however, this request expands into a large number of requests to several diverse back-end data sources consisting of web services, RDMBS calls, etc. This use case expands into two different but related problems that we are looking to the distributed version of the work manager to solve.
1. How do we take a coarse-grained request that expands into several fine-grained requests and execute them in parallel to avoid blocking the caller for an unreasonable time? In the above example, we may have to make upwards of 100 calls to various places to retrieve the information. Since J2EE has no legal threading model, and since the threading we observed when trying a message-based approach to this was unacceptable, we decided to use the Coherence Work Manager implementation.
2. Given that we want to make many external system calls in parallel while still leveraging low-cost blades, we are hoping that fanning the required work across many dual processor (logically 4-processor because of hyperthreading) machines allows us to scale an inherently vertical scalability problem with horizontal scalability at the hardware level. We think this is reasonable because the cost to marshall the request to a remote Work Manager instance is small compared to the cost to execute the service, which usually involves dozens or hundreds of milliseconds.
For more information on the Work Manager Specification and API, see Timer and Work Manager for Application Servers on the BEA dev2dev web site and JSR 237.
Summary
Coherence provides an extensive set of capabilities that make Data Grid services simple, seamless and seriously scalable. While the data fabric provides an entire unified view of the complete data domain, the Data Grid features enable applications to take advantage of the partitioning of data that Coherence provides in a scale-out environment.
Real Time Client - RTC
Overview
The Coherence Real Time Client provides secure and scalable client access from desktop applications into a Coherence Data Grid. Coherence RTC extends the Data Grid to the Desktop, providing the same core API as the rest of the Coherence product line. As of Coherence 3.2, Coherence RTC is licensed as Coherence Real Time Client.
Connectivity into the Coherence Data Grid is achieved via Coherence*Extend technology, which enables a client application to connect to a particular server within the Data Grid. Since the connections are load-balanced across all of the servers in the Data Grid, this approach to connectivity can scale to support tens of thousands of desktop systems.
Uses
The primary use case for Coherence RTC is to provide desktop clients with read-only/read-mostly access to data held in a Coherence cluster. Clients can query clustered caches and receive real-time updates as the data changes. Clients may also initiate server-side data manipulation tasks, including aggregations (using com.tangosol.util.InvocableMap.EntryAggregator) and processing (using com.tangosol.util.InvocableMap.EntryProcessor).
Cache Access
Normally, desktop applications are granted only read access to the data being managed by the Data Grid (delegating cache updates to Data Grid Agents), although it is possible to enable direct read/write access.
Local Caches
While the desktop application can directly access the caches managed by the Data Grid, that may be inefficient depending on the network infrastructure. For efficiency, the desktop application can use both Near Caching and Continuous Query Caching to maintain cache data locally.
Event Notification
Using the standard Coherence event model, data changes that occur within the Data Grid are visible to the desktop application. Since the desktop application indicates the exact events that it is interested in, only those events are actually delivered over the wire, resulting in efficient use of network bandwidth and client processing.
Agent Invocation
Since the desktop application will likely only have read-only access, any manipulation of data is done within the Data Grid itself; the mechanism for this is the Data Grid Agent, which is supported by the InvocableMap API.
Desktops may invoke tasks, aggregators and processors for server-side cached objects using InvocableMap.
Connection Failover
If the server to which the desktop application is attached happens to fail, the connection is automatically re-established to another server, and then any locally cached data is re-synced with the cluster.
Using Coherence and BEA WebLogic Portal
Introduction
Coherence integrates closely with BEATM WebLogicTM Portal to provide WAN-capable clustered session management and caching for portal applications. Specifically, Coherence includes the following integration points:
- Coherence*Web support for WebLogic Portal
- P13N CacheProvider SPI implementation
- A blueprint for efficiently sharing data between WSRP-federated portals that leverages Coherence and the WebLogic Portal Custom Data Transfer mechanism
| Requires WebLogic Portal 8.1.6
Please note that these features require WebLogic Portal 8.1.6. Additionally for Coherence*Web to work correctly with WebLogic Portal, a patch for issue CR314006 must be applied to all WebLogic Portal installations that will be running Coherence*Web. You can request this patch from your BEA sales representative. After installing this patch, you must add the following system properties to all WebLogic Portal instances, including the admin server:
-Dcom.bea.p13n.servlet.wrapper=com.tangosol.coherence.servlet.api22.ServletWrapper
-Dcom.bea.p13n.servlet.wrapper.param=coherence-servlet-class
|
Coherence*Web for WebLogic Portal
When Coherence*Web is installed into a WebLogic Portal web application, everything that the portal framework and portlets place into the HttpSession will be managed by Coherence. This has several benefits as described in the following article:
http://dev2dev.bea.com/pub/a/2005/05/session_management.html
Additionally, combining Coherence*Web and WebLogic Portal gives you extreme flexibility in your choice of a session management cache topology. For example, if you find that your Portal servers are bumping into the 4GB heap limit (on 32-bit JVMs) or are experiencing slow GC times, you can leverage a cache client/server topology to move all HttpSession state out of your Portal JVMs and into one or more dedicated Coherence cache servers, thus reducing your Portal JVM heap size and GC times. Also, you can leverage the Coherence Management Framework to closely monitor HttpSession-specific statistics to better tune your Coherence*Web and session management cache settings.
For details on installing Coherence*Web into a WebLogic Portal web application, please see Installing Coherence*Web Session Management Module.
P13N CacheProvider SPI Implementation
Internally, WebLogic Portal uses its own caching service to cache portal, personalization, and commerce data as described here:
http://e-docs.bea.com/wlp/docs81/javadoc/com/bea/p13n/cache/package-summary.html
WebLogic Portal 8.1.6 includes an SPI for the P13N caching service that can be implemented by third party cache vendors. Coherence includes a P13N CacheProvider SPI implementation that - when installed into a WebLogic Portal application - has the same benefits for serializable WebLogic Portal data as Coherence*Web has for HttpSession state, all without requiring code changes. Additionally, the Coherence CacheProvider allows your portlets to leverage Coherence caching services simply by using the standard P13N Cache API.
To install the Coherence P13N CacheProvider, simply copy the coherence-wlp.jar, coherence.jar and tangosol.jar libraries included in the lib directory of the Coherence installation to the APP-INF/lib directory of your WebLogic Portal application. On startup, WebLogic Portal will automatically discover the Coherence CacheProvider and transparently use it to cache data.
Please see the JavaDoc for the PortalCacheProvider class for details on configuring the Coherence CacheProvider and Coherence caches used by the provider. Additionally, please see the following document for a list of some of the caches used by WebLogic Portal:
http://e-docs.bea.com/wlp/docs81/perftune/apenB.html
Sharing Data Between WSRP-Federated Portals Using Coherence
The Web Services for Remote Portlets (WSRP) protocol was designed to support the federation of portals hosted by arbitrary portal servers and server clusters. Developers use WSRP to aggregate content and the user interface (UI) from various portlets hosted by other remote portals. By itself, though, WSRP does not address the challenge of implementing scalable, reliable, and high-performance federated portals that create, access, and manage the lifecycle of data shared by distributed portlets. Fortunately, BEA WebLogic Portal provides an extension to the WSRP specification that — when coupled with Oracle Coherence — allows WSRP Consumers and Producers to create, view, modify, and control concurrent access to shared, scoped data in a scalable, reliable, and highly performant manner.
See the following document for complete details:
http://dev2dev.bea.com/pub/a/2005/11/federated-portal-cache.html
Using Coherence and Hibernate
Introduction
Hibernate and Coherence can be used together in several combinations. This document discusses the various options, including when and each one is appropriate, along with usage instructions. These options including using Coherence as a Hibernate plug-in, using Hibernate as a Coherence plug-in via the CacheStore interface and bulk-loading Coherence caches from a Hibernate query. Most applications that use Coherence and Hibernate use a mixture of these approaches. The Hibernate API features powerful management of entities and relationships, and the Coherence API delivers maximum performance and scalability.
Conventions
This document refers to the following Java classes and interfaces:
com.tangosol.coherence.hibernate.CoherenceCache
com.tangosol.coherence.hibernate.CoherenceCacheProvider
com.tangosol.coherence.hibernate.HibernateCacheLoader
com.tangosol.coherence.hibernate.HibernateCacheStore
com.tangosol.net.NamedCache (extends java.util.Map)
com.tangosol.net.cache.CacheLoader
com.tangosol.net.cache.CacheStore
org.hibernate.Query
org.hibernate.Session
org.hibernate.SessionFactory
As the CacheStore interface extends CacheLoader, the term "CacheStore" will be used generically to refer to both interfaces (the appropriate interface being determined by whether read-only or read-write support is required). Similarly, "HibernateCacheStore" will refer to both implementations.
The Coherence cache configuration file is referred to as coherence-cache-config.xml (the default name) and the Hibernate root configuration file is referred to as hibernate.cfg.xml (the default name).
Selecting a Caching Strategy
Overview
Generally, the Hibernate API is the optimal choice for accessing data held in a relational database where performance is not the dominant factor. For application state (or any type of data that fits naturally into the Map interface) use the Coherence API. For performance-sensitive operations, specifically those that may benefit from Coherence-specific features like write-behind caching or cache queries, use the Coherence API.
Hibernate API
The Hibernate API provides flexible queries and relational management features including referential integrity, cascading deletes and child object fetching. While these features may be implemented using Coherence, this involves development effort which may not be worthwhile in cases where performance is not an issue.
Coherence NamedCache API
There are many Coherence features that require direct access to the Coherence NamedCache API, including:
- Write-Behind Caching (low-latency, high-throughput database updates)
- Distributed Queries (low-latency, high-throughput search queries)
- Cache Transactions (application-tier transactions)
- InvocableMap (stored procedures, aggregations)
- Invocation Service (messaging and remote invocation)
- Cache Listeners (event-based processing)
Direct access to these features may be critical for achieving the highest levels of scalable performance.
Coherence CacheStore Integration
CacheStore modules are useful for transparently keeping cache and database synchronized. They are also more efficient than independently updating the cache and database as updates are routed through Coherence's partitioning facilities, minimizing locking.
CacheStore modules give very high performance for caching that can be expressed via a Map interface, that is a key-value pair. The NamedCache interface is a much simpler and by extension much lower-overhead API than the Hibernate query API. Additionally, in some cases (where complex queries can be mapped into a key-based pattern), very complex queries can be answered by a simple cache retrieval.
One final reason for using CacheStore is that it provides a means of coordinating all database (or other backend) access through a single API (NamedCache) and through a controlled set of JVMs (server machines). This is because the nodes which are responsible for managing cache partitions are the same machines responsible for synchronizing with the database server.
Using Coherence as the Hibernate L2 Cache
Introduction
Hibernate supports three primary forms of caching:
- Session cache
- L2 cache
- Query cache
The Session cache is responsible for caching records within a Session (a Hibernate transaction, potentially spanning multiple database transactions, and typically scoped on a per-thread basis). As a non-clustered cache (by definition), the Session cache is managed entirely by Hibernate. The L2 and Query caches span multiple transactions, and support the use of Coherence as a cache provider. The L2 cache is responsible for caching records across multiple sessions (for primary key lookups). The query cache caches the result sets generated by Hibernate queries. Hibernate manages data in an internal representation in the L2 and Query caches, meaning that these caches are usable only by Hibernate. For more details, see the Hibernate Reference Documentation (shipped with Hibernate), specifically the section on the Second Level Cache.
Configuration and Tuning
To use the Coherence Caching Provider for Hibernate, specify the Coherence provider class in the "hibernate.cache.provider_class" property. Typically this is configured in the default Hibernate configuration file, hibernate.cfg.xml.
<property name="hibernate.cache.provider_class">com.tangosol.coherence.hibernate.CoherenceCacheProvider</property>
The file coherence-hibernate.jar (found in the lib/ subdirectory) must be added to the application classpath.
Hibernate provides the configuration property hibernate.cache.use_minimal_puts, which optimizes cache access for clustered caches by increasing cache reads and decreasing cache updates. This is enabled by default by the Coherence Cache Provider. Setting this property to false may increase overhead for cache management and also increase the number of transaction rollbacks.
The Coherence Caching Provider includes a setting for how long a lock acquisition should be attempted before timing out. This may be specified by the Java property tangosol.coherence.hibernate.lockattemptmillis. The default is one minute.
Specifying a Coherence Cache Topology
By default, the Coherence Caching Provider uses a custom cache configuration located in coherence-hibernate.jar named config/hibernate-cache-config.xml to define cache mappings for Hibernate L2 caches. If desired, an alternative cache configuration resource may be specified for Hibernate L2 caches via the tangosol.coherence.hibernate.cacheconfig Java property. It is possible to configure this property to point to the application's main coherence-cache-config.xml file if mappings are properly configured. It may be beneficial to use dedicated cache service(s) to manage Hibernate-specific caches to ensure that any CacheStore modules don't cause re-entrant calls back into Coherence-managed Hibernate L2 caches.
In conjunction with the scheme mapping section of the Coherence cache configuration file, the hibernate.cache.region_prefix property may be used to specify a cache topology. For example, if the cache configuration file includes a wildcard mapping for "near-*", and the Hibernate region prefix property is set to "near-", then all Hibernate caches will be named using the "near-" prefix, and will use the cache scheme mapping specified for the "near-*" cache name pattern.
It is possible to specify a cache topology per entity by creating a cache mapping based on the combined prefix and qualified entity name (e.g. "near-com.company.EntityName"); or equivalently, by providing an empty prefix and specifying a cache mapping for each qualified entity name.
Also, L2 caches should be size-limited to avoid excessive memory usage. Query caches in particular must be size-limited as the Hibernate API does not provide any means of controlling the query cache other than a complete eviction.
Cache Concurrency Strategies
Hibernate generally emphasizes the use of optimistic concurrency for both cache and database. With optimistic concurrency in particular, transaction processing depends on having accurate data available to the application at the beginning of the transaction. If the data is inaccurate, the commit processing will detect that the transaction was dependent on incorrect data, and the transaction will fail to commit. While most optimistic transactions must cope with changes to underlying data by other processes, the use of caching adds the possibility of the cache itself being stale. Hibernate provides a number of cache concurrency strategies to control updates to the L2 cache. While this is less of an issue for Coherence due to support for cluster-wide coherent caches, appropriate selection of cache concurrency strategy will aid application efficiency.
Note that cache configuration strategies may be specified at the table level. Generally, the strategy should be specified in the mapping file for the class.
For mixed read-write activity, the read-write strategy is recommended. The transactional strategy is implemented similarly to the nonstrict-read-write strategy, and relies on the optimistic concurrency features of Hibernate. Note that nonstrict-read-write may deliver better performance if its impact on optimistic concurrency is acceptable.
For read-only caching, use the nonstrict-read-write strategy if the underlying database data may change, but slightly stale data is acceptable. If the underlying database data never changes, use the read-only strategy.
Query Cache
To cache query results, set the hibernate.cache.use_query_cache property to "true". Then whenever issuing a cacheable query, use Query.setCacheable(true) to enable caching of query results. As org.hibernate.cache.QueryKey instances in Hibernate may not be binary-comparable (due to non-deterministic serialization of unordered data members), use a size-limited Local or Replicated cache to store query results (which will force the use of hashcode()/equals() to compare keys). The default query cache name is "org.hibernate.cache.StandardQueryCache" (unless a default region prefix is provided, in which case "[prefix]." will be prepended to the cache name). Use the cache configuration file to map this cache name to a Local/Replicated topology, or explicitly provide an appropriately-mapped region name when querying.
Fault-Tolerance
The Hibernate L2 cache protocol supports full fault-tolerance during client or server failure. With the read-write cache concurrency strategy, Hibernate will lock items out of the cache at the start of an update transaction, meaning that client-side failures will simply result in uncached entities and an uncommitted transaction. Server-side failures are handled transparently by Coherence (dependent on the specified data backup count).
Deployment
When used with application servers that do not have a unified class loader, the Coherence Cache Provider must be deployed as part of the application so that it can use the application-specific class loader (required to serialize-deserialize objects).
Using the Coherence HibernateCacheStore
Overview
Coherence includes a default entity-based CacheStore implementation, HibernateCacheStore (and a corresponding CacheLoader implementation, HibernateCacheLoader). More detailed technical information may be found in the JavaDoc for the implementing classes.
Configuration
The examples below show a simple HibernateCacheStore constructor, accepting only an entity name. This will configure Hibernate using the default configuration path, which looks for a hibernate.cfg.xml file in the classpath. There is also the ability to pass in a resource name or file specification for the hibernate.cfg.xml file as the second <init-param> (set the <param-type> element to java.lang.String for a resource name and java.io.File for a file specification). See the class JavaDoc for more details.
The following is a simple coherence-cache-config.xml file used to define a NamedCache called "TableA" which caches instances of a Hibernate entity (com.company.TableA). To add additional entity caches, add additional <cache-mapping> elements.
<?xml version="1.0"?>
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
<cache-config>
<caching-scheme-mapping>
<cache-mapping>
<cache-name>TableA</cache-name>
<scheme-name>distributed-hibernate</scheme-name>
<init-params>
<init-param>
<param-name>entityname</param-name>
<param-value>com.company.TableA</param-value>
</init-param>
</init-params>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<distributed-scheme>
<scheme-name>distributed-hibernate</scheme-name>
<backing-map-scheme>
<read-write-backing-map-scheme>
<internal-cache-scheme>
<local-scheme></local-scheme>
</internal-cache-scheme>
<cachestore-scheme>
<class-scheme>
<class-name>
com.tangosol.coherence.hibernate.HibernateCacheStore
</class-name>
<init-params>
<init-param>
<param-type>java.lang.String</param-type>
<param-value>{entityname}</param-value>
</init-param>
</init-params>
</class-scheme>
</cachestore-scheme>
</read-write-backing-map-scheme>
</backing-map-scheme>
</distributed-scheme>
</caching-schemes>
</cache-config>
It is also possible to use the pre-defined {cache-name} macro to eliminate the need for the <init-params> portion of the cache mapping:
<?xml version="1.0"?>
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
<cache-config>
<caching-scheme-mapping>
<cache-mapping>
<cache-name>TableA</cache-name>
<scheme-name>distributed-hibernate</scheme-name>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<distributed-scheme>
<scheme-name>distributed-hibernate</scheme-name>
<backing-map-scheme>
<read-write-backing-map-scheme>
<internal-cache-scheme>
<local-scheme></local-scheme>
</internal-cache-scheme>
<cachestore-scheme>
<class-scheme>
<class-name>
com.tangosol.coherence.hibernate.HibernateCacheStore
</class-name>
<init-params>
<init-param>
<param-type>java.lang.String</param-type>
<param-value>com.company.{cache-name}</param-value>
</init-param>
</init-params>
</class-scheme>
</cachestore-scheme>
</read-write-backing-map-scheme>
</backing-map-scheme>
</distributed-scheme>
</caching-schemes>
</cache-config>
And, if naming conventions allow, the mapping may be completely generalized to allow a cache mapping for any qualified class name (entity name):
<?xml version="1.0"?>
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
<cache-config>
<caching-scheme-mapping>
<cache-mapping>
<cache-name>com.company.*</cache-name>
<scheme-name>distributed-hibernate</scheme-name>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<distributed-scheme>
<scheme-name>distributed-hibernate</scheme-name>
<backing-map-scheme>
<read-write-backing-map-scheme>
<internal-cache-scheme>
<local-scheme></local-scheme>
</internal-cache-scheme>
<cachestore-scheme>
<class-scheme>
<class-name>
com.tangosol.coherence.hibernate.HibernateCacheStore
</class-name>
<init-params>
<init-param>
<param-type>java.lang.String</param-type>
<param-value>{cache-name}</param-value>
</init-param>
</init-params>
</class-scheme>
</cachestore-scheme>
</read-write-backing-map-scheme>
</backing-map-scheme>
</distributed-scheme>
</caching-schemes>
</cache-config>
Configuration Requirements
Hibernate entities accessed via the HibernateCacheStore module must use the "assigned" ID generator and also have a defined ID property.
Be sure to disable the "hibernate.hbm2ddl.auto" property in the hibernate.cfg.xml used by the HibernateCacheStore, as this may cause excessive schema updates (and possible lockups).
JDBC Isolation Level
In cases where all access to a database is through Coherence, CacheStore modules will naturally enforce ANSI-style Repeatable Read isolation as reads and writes are executed serially on a per-key basis (via the Partitioned Cache Service). Increasing database isolation above Repeatable Read will not yield increased isolation as CacheStore operations may span multiple Partitioned Cache nodes (and thus multiple database transactions). Using database isolation levels below Repeatable Read will not result in unexpected anomalies, and may reduce processing load on the database server.
Fault-Tolerance
For single-cache-entry updates, CacheStore operations are fully fault-tolerant in that the cache and database are guaranteed to be consistent during any server failure (including failures during partial updates). While the mechanisms for fault-tolerance vary, this is true for both write-through and write-behind caches.
Coherence does not support two-phase CacheStore operations across multiple CacheStore instances. In other words, if two cache entries are updated, triggering calls to CacheStore modules sitting on separate servers, it is possible for one database update to succeed and for the other to fail. In this case, it may be preferable to use a cache-aside architecture (updating the cache and database as two separate components of a single transaction) in conjunction with the application server transaction manager. In many cases it is possible to design the database schema to prevent logical commit failures (but obviously not server failures). Write-behind caching avoids this issue as "puts" are not affected by database behavior (and the underlying issues will have been addressed earlier in the design process).
Extending HibernateCacheStore
In some cases, it may be desired to extend the HibernateCacheStore with application-specific functionality. The most obvious reason for this is to leverage a pre-existing programmatically-configured SessionFactory instance.
Creating a Hibernate CacheStore
Introduction
While the provided HibernateCacheStore module provides a solution for most entity-based caches, there may be cases where an application-specific CacheStore module is necessary. For example, providing parameterized queries or including or post-processing of query results.
Re-entrant Calls
In a CacheStore-backed cache implementation, when the application thread accesses cached data, the cache operations may trigger a call to the associated CacheStore implementation via the managing CacheService. The CacheStore must not call back into the CacheService API. This implies, indirectly, that Hibernate should not attempt to access cache data. Therefore, all methods in CacheLoader/CacheStore should be careful to call Session.setCacheMode(CacheMode.IGNORE) to disable cache access. Alternatively, the Hibernate configuration may be cloned (either programmatically or via hibernate.cfg.xml), with CacheStore implementations using the version with the cache disabled.
It is important that a CacheStore implementation does not call back into the hosting cache service. Therefore, in addition to avoiding calls to NamedCache methods, you should also ensure that Hibernate itself does not use any cache services. To do this, call Session.setCacheMode(CacheMode.IGNORE) each time a session is used. Alternatively, the Hibernate configuration may be cloned (either programmatically or via hibernate.cfg.xml), with CacheStore implementations using the version with the cache disabled.
Fully Cached DataSets
Distributed Queries
Distributed queries offer the potential for lower latency, higher throughput and less database server load compared to executing queries on the database server. For set-oriented queries, the dataset must be entirely cached to produce correct query results. More precisely, for a query issued against the cache to produce correct results, the query must not depend on any uncached data.
This means that you can create hybrid caches. For example, it is possible to combine two uses of a NamedCache: a fully cached size-limited dataset for querying (e.g. the data for the most recent week), and a partially cached historical dataset used for singleton reads. This is a good approach to avoid data duplication and minimize memory usage.
While fully cached datasets are usually bulk-loaded during application startup (or on a periodic basis), CacheStore integration may be used to ensure that both cache and database are kept fully synchronized.
Detached Processing
Another reason for using fully-cached datasets is to provide the ability to continue application processing even if the underlying database goes down. Using write-behind caching extends this mode of operation to support full read-write applications. With write-behind, the cache becomes (in effect) the temporary system of record. Should the database fail, updates will be queued in Coherence until the connection is restored, at which point all cache changes will be sent to the database.
Architecture
Overview for Implementors
Basic Concepts
Audience
This document is targeted at software developers and architects who need a very quick overview of Coherence features. This document outlines product capabilities, usage possibilities, and provides a brief overview of how one would go about implementing particular features. This document bridges the more abstract Coherence white-papers and the more concrete developer documentation (Oracle Coherence User Guide and the Coherence API documentation).
Clustered Data Management
At the core of Coherence is the concept of clustered data management. This implies the following goals:
- A fully coherent, single system image (SSI)
- Scalability for both read and write access
- Fast, transparent failover and failback
- Linear scalability for storage and processing
- No Single-Points-of-Failure (SPOFs)
- Cluster-wide locking and transactions
Built on top of this foundation are the various services that Coherence provides, including database caching, HTTP session management, grid agent invocation and distributed queries. Before going into detail about these features, some basic aspects of Coherence should be discussed.
A single API for the logical layer, XML configuration for the physical layer
Coherence supports many topologies for clustered data management. Each of these topologies has trade-offs in terms of performance and fault-tolerance. By using a single API, the choice of topology can be deferred until deployment if desired. This allows developers to work with a consistent logical view of Coherence, while providing flexibility during tuning or as application needs change.
Caching Strategies
Coherence provides several cache implementations:
- Local - Local on-heap caching for non-clustered caching.
- Replicated - Perfect for small, read-heavy caches.
- Partitioned - True linear scalability for both read and write access. Data is automatically, dynamically and transparently partitioned across nodes. The distribution algorithm minimizes network traffic and avoids service pauses by incrementally shifting data.
- Near Cache - Provides the performance of local caching with the scalability of distributed caching. Several different near-cache strategies provide varying tradeoffs between performance and synchronization guarantees.
In-process caching provides the highest level of raw performance, since objects are managed within the local JVM. This benefit is most directly realized by the Local, Replicated, Optimistic and Near Cache implementations.
Out-of-process (client-server) caching provides the option of using dedicated cache servers. This can be helpful when you wish to partition workloads (to avoid stressing the application servers). This is accomplished by using the Partitioned cache implementation and simply disabling local storage on client nodes via a single command-line option or a one-line entry in the XML configuration.
Tiered caching (using the NearCache functionality) allows you to couple local caches on the application server with larger, partitioned caches on the cache servers, combining the raw performance of local caching with the scalability of partitioned caching. This is useful for both dedicated cache servers as well as co-located caching (cache partitions stored within the application server JVMs).
Data Storage Options
While most customers use on-heap storage combined with dedicated cache servers, Coherence has several options for data storage:
- On-heap - The fastest option, though it can affect JVM garbage collection times.
- NIO RAM - No impact on garbage collection, though it does require serialization/deserialization.
- NIO Disk - Similar to NIO RAM, but using memory-mapped files.
- File-based - Uses a special disk-optimized storage system to optimize speed and minimize I/O.
It should be noted that Coherence storage is transient – the disk-based storage options are for managing cached data only. If long-term persistence of data is required, Coherence provides snapshot functionality to persist an image to disk. This is especially useful when the external data sources used to build the cache are extremely expensive. By using the snapshot, the cache can be rebuilt from an image file (rather than reloading from a very slow external datasource).
Serialization Options
Because serialization is often the most expensive part of clustered data management, Coherence provides three options for serializing/deserializing data:
- java.io.Serializable - The simplest, but slowest option.
- java.io.Externalizable - This requires developers to implement serialization manually, but can provide significant performance benefits. Compared to java.io.Serializable, this can cut serialized data size by a factor of two or more (especially helpful with Distributed caches, as they generally cache data in serialized form). Most importantly, CPU usage is dramatically reduced.
- com.tangosol.io.ExternalizableLite - This is very similar to java.io.Externalizable, but offers better performance and less memory usage by using a more efficient I/O stream implementation. The com.tangosol.run.xml.XmlBean class provides a default implementation of this interface (see the section on XmlBean for more details).
Configurability and Extensibility
Coherence's API provides access to all Coherence functionality. The most commonly used subset of this API is exposed via simple XML options to minimize effort for typical use cases. There is no penalty for mixing direct configuration via the API with the easier XML configuration.
Coherence is designed to allow the replacement of its modules as needed. For example, the local "backing maps" (which provide the actual physical data storage on each node) can be easily replaced as needed. The vast majority of the time, this is not required, but it is there for the situations that require it. The general guideline is that 80% of tasks are easy, and the remaining 20% of tasks (the special cases) require a little more effort, but certainly can be done without significant hardship.
Namespace Hierarchy
Coherence is organized as set of services. At the root is the "Cluster" service. A cluster is defined as a set of Coherence instances (one instance per JVM, with one or more JVMs on each physical machine). A cluster is defined by the combination of multicast address and port. A TTL (network packet time-to-live; i.e., the number of network hops) setting can be used to restrict the cluster to a single machine, or the machines attached to a single switch.
Under the cluster service are the various services that comprise the Coherence API. These include the various caching services (Replicated, Distributed, etc.) as well as the Invocation Service (for deploying agents to various nodes of the cluster). Each instance of a service is named, and there is typically a default service instance for each type.
The cache services contain NamedCaches ( com.tangosol.net.NamedCache), which are analogous to database tables – that is, they typically contain a set of related objects.
Read/Write Caching
NamedCache
The following source code will return a reference to a NamedCache instance. The underlying cache service will be started if necessary.
import com.tangosol.net.*;
...
NamedCache cache = CacheFactory.getCache("MyCache");
Coherence will scan the cache configuration XML file for a name mapping for MyCache. NamedCache name mapping is similar to Servlet name mapping in a web container's web.xml file. Coherence's cache configuration file contains (in the simplest case) a set of mappings (from cache name to cache strategy) and a set of cache strategies.
By default, Coherence will use the coherence-cache-config.xml file found at the root of coherence.jar. This can be overridden on the JVM command-line with -Dtangosol.coherence.cacheconfig=file.xml. This argument can reference either a file system path, or a Java resource path.
The com.tangosol.net.NamedCache interface extends a number of other interfaces:
- java.util.Map - basic Map methods such as get(), put(), remove().
- com.tangosol.util.QueryMap - methods for querying the cache.
- com.tangosol.util.ConcurrentMap - methods for concurrent access such as lock() and unlock().
- com.tangosol.util.ObservableMap - methods for listening to cache events.
- com.tangosol.util.InvocableMap - methods for server-side processing of cache data.
| Requirements for cached objects
Cache keys and values must be serializable (e.g. java.io.Serializable). Furthermore, cache keys must provide an implementation of the hashCode() and equals() methods, and those methods must return consistent results across cluster nodes. This implies that the implementation of hashCode() and equals() must be based solely on the object's serializable state (i.e. the object's non-transient fields); most built-in Java types, such as String, Integer and Date, meet this requirement. Some cache implementations (specifically the partitioned cache) use the serialized form of the key objects for equality testing, which means that keys for which equals() returns true must serialize identically; most built-in Java types meet this requirement as well. |
NamedCache Usage Patterns
There are two general approaches to using a NamedCache:
- As a clustered implementation of java.util.Map with a number of added features (queries, concurrency), but with no persistent backing (a "side" cache).
- As a means of decoupling access to external data sources (an "inline" cache). In this case, the application uses the NamedCache interface, and the NamedCache takes care of managing the underlying database (or other resource).
Typically, an inline cache is used to cache data from:
- a database - The most intuitive use of a cache – simply caching database tables (in the form of Java objects).
- a service - Mainframe, web service, service bureau – any service that represents an expensive resource to access (either due to computational cost or actual access fees).
- calculations - Financial calculations, aggregations, data transformations. Using an inline cache makes it very easy to avoid duplicating calculations. If the calculation is already complete, the result is simply pulled from the cache. Since any serializable object can be used as a cache key, it's a simple matter to use an object containing calculation parameters as the cache key.
Write-back options:
- write-through - Ensures that the external data source always contains up-to-date information. Used when data must be persisted immediately, or when sharing a data source with other applications.
- write-behind - Provides better performance by caching writes to the external data source. Not only can writes be buffered to even out the load on the data source, but multiple writes can be combined, further reducing I/O. The trade-off is that data is not immediately persisted to disk; however, it is immediately distributed across the cluster, so the data will survive the loss of a server. Furthermore, if the entire data set is cached, this option means that the application can survive a complete failure of the data source temporarily as both cache reads and writes do not require synchronous access the the data source.
To implement a read-only inline cache, you simply implement two methods on the com.tangosol.net.cache.CacheLoader interface, one for singleton reads, the other for bulk reads. Coherence provides an abstract class com.tangosol.net.cache.AbstractCacheLoader which provides a default implementation of the bulk method, which means that you need only implement a single method: public Object load(Object oKey);
This method accepts an arbitrary cache key and returns the appropriate value object.
If you want to implement read-write caching, you need to extend com.tangosol.net.cache.AbstractCacheStore (or implement the interface com.tangosol.net.cache.CacheStore), which adds the following methods:
public void erase(Object oKey);
public void store(Object oKey, Object oValue);
The method erase() should remove the specified key from the external data source. The method store() should update the specified item in the data source if it already exists, or insert it if it does not presently exist.
Once the CacheLoader/CacheStore is implemented, it can be connected via the coherence-cache-config.xml file.
Querying the Cache
Coherence provides the ability to query cached data. With partitioned caches, the queries are indexed and parallelized. This means that adding servers to a partitioned cache not only increases throughput (total queries per second) but also reduces latency, with queries taking less user time. To query against a NamedCache, all objects should implement a common interface (or base class). Any field of an object can be queried; indexes are optional, and used to increase performance. With a replicated cache, queries are performed locally, and do not use indexes.
To add an index to a NamedCache, you first need a value extractor (which accepts as input a value object and returns an attribute of that object). Indexes can be added blindly (duplicate indexes are ignored). Indexes can be added at any time, before or after inserting data into the cache.
It should be noted that queries apply only to cached data. For this reason, queries should not be used unless the entire data set has been loaded into the cache, unless additional support is added to manage partially loaded sets.
Developers have the option of implementing additional custom filters for queries, thus taking advantage of query parallelization. For particularly performance-sensitive queries, developers may implement index-aware filters, which can access Coherence's internal indexing structures.
Coherence includes a built-in optimizer, and will apply indexes in the optimal order. Because of the focused nature of the queries, the optimizer is both effective and efficient. No maintenance is required.
Example code to create an index:
NamedCache cache = CacheFactory.getCache("MyCache");
ValueExtractor extractor = new ReflectionExtractor("getAttribute");
cache.addIndex(extractor, true, null);
Example code to query a NamedCache (returns the keys corresponding to all of the value objects with an "Attribute" greater than 5):
NamedCache cache = CacheFactory.getCache("MyCache");
Filter filter = new GreaterFilter("getAttribute", 5);
Set keySet = cache.keySet(filter);
Transactions
Coherence supports local transactions against the cache through both a direct API, as well as through J2CA adapters for J2EE containers. Transactions support either pessimistic or optimistic concurrency strategies, as well as the Read Committed, Repeatable Read, Serializable isolation levels.
HTTP Session Management
Coherence*Web is an HTTP session-management module with support for a wide range of application servers. Using Coherence session management does not require any changes to the application.
Coherence*Web uses the NearCache technology to provide fully fault-tolerant caching, with almost unlimited scalability (to several hundred cluster nodes without issue).
Invocation Service
The Coherence Invocation service can be used to deploy computational agents to various nodes within the cluster. These agents can be either execute-style (deploy and asynchronously listen) or query-style (deploy and wait for results).
The Invocation service is accessed through the interface com.tangosol.net.InvocationService through the two following methods:
public void execute(Invocable task, Set setMembers, InvocationObserver observer);
public Map query(Invocable task, Set setMembers);
An instance of the service can be retrieved from the com.tangosol.net.CacheFactory class.
Coherence implements the WorkManager API for task-centric processing.
Events
All NamedCache instances in Coherence implement the com.tangosol.util.ObservableMap interface, which allows the option of attaching a cache listener implementation (of com.tangosol.util.MapListener). It should be noted that applications can observe events as logical concepts regardless of which physical machine caused the event. Customizable server-side filters and lightweight events can be used to minimize network traffic and processing. Cache listeners follow the JavaBean paradigm, and can distinguish between system cache events (e.g., eviction) and application cache events (e.g., get/put operations).
Continuous Query functionality provides the ability to maintain a client-side "materialized view".
Similarly, any service can be watched for members joining and leaving, including the cluster service as well as the cache and invocation services.
Object-Relational Mapping Integration
Most ORM products support Coherence as an "L2" caching plug-in. These solutions cache entity data inside Coherence, allowing application on multiple servers to share cached data.
C++/.NET Integration
Traditionally, customers wishing to access Coherence from C++ applications and .NET applications have used integration technologies from CodeMesh and JNBridge. This integration takes the form of local proxy objects that control remote Coherence objects within the JVM.
In the interest of streamlining multi-platform development, Coherence 3.2 introduced support for any cross-platform client that adheres to the Coherence*Extend wire protocol. Coherence 3.2 includes a Java client implementation; subsequent releases are scheduled to add support for .NET and C++ clients.
Management and Monitoring
Coherence offers management and monitoring facilities via Java Management Extensions (JMX). A detailed set of statistics and commands is maintained in the API documentation for com.tangosol.net.management.Registry.
Managing an Object Model
Overview
This document describes best practices for managing an object model whose state is managed in a collection of Coherence named caches. Given a set of entity classes, and a set of entity relationships, what is the best means of expressing and managing the object model across a set of Coherence named caches?
Cache Usage Paradigms
The value of a clustered caching solution depends on how it is used. Is it simply caching database data in the application tier, keeping it ready for instant access? Is it taking the next step to move transactional control into the application tier? Or does it go a step further by aggressively optimizing transactional control?
Simple Data Caching
Simple data caches are common, especially in situations where concurrency control is not required (e.g. content caching) or in situations where transactional control is still managed by the database (e.g. plug-in caches for Hibernate and JDO products). This approach has minimal impact on application design, and is often implemented transparently by the Object/Relational Mapping (ORM) layer or the application server (EJB container, Spring, etc). However, it still does not completely solve the issue of overloading the database server; in particular, while non-transactional reads are handled in the application tier, all transactional data management still requires interaction with the database.
It is important to note that caching is not an orthogonal concern once data access requirements go beyond simple access by primary key. In other words, to truly benefit from caching, applications must be designed with caching in mind.
Transactional Caching
Applications that need to scale and operate independently of the database must start to take greater responsibility for data management. This includes using Coherence features for read access (read-through caching, cache queries, aggregations), features for minimizing database transactions (write-behind), and features for managing concurrency (locking, cache transactions).
Transaction Optimization
Applications that need to combine fault-tolerance, low latency and high scalability will generally need to optimize transactions even further. Using traditional transaction control, an application might need to specify SERIALIZABLE isolation when managing an Order object. In a distributed environment, this can be a very expensive operation. Even in non-distributed environments, most databases and caching products will often use a table lock to achieve this. This places a hard limit on scalability regardless of available hardware resources; in practice, this may limit transaction rate to hundreds of transactions per second, even with exotic hardware. However, locking "by convention" can help – for example, requiring that all acessors lock only the "parent" Order object. Doing this can reduce the scope of the lock from table-level to order-level, enabling far higher scalability. (Of course, some applications already achieve similar results by partitioning event processing across multiple JMS queues to avoid the need for explicit concurrency control.) Further optimizations include using an EntryProcessor to avoid the need for clustered coordination, which can dramatically increase the transaction rate for a given cache entry.
Managing the Object Model
Overview
The term "relationships" refers to how objects are related to each other. For example, an Order object may contain (exclusively) a set of LineItem objects. It may also refer to a Customer object that is associated with the Order object.
The data access layer can generally be broken down into two key components, Data Access Objects (DAOs) and Data Transfer Objects (DTOs) (in other words, behavior and state). DAOs control the behavior of data access, and generally will contain the logic that manages the database or cache. DTOs contain data for use with DAOs, for example, an Order record. Also, note that a single object may (in some applications) act as both a DTO and DAO. These terms describe patterns of usage; these patterns will vary between applications, but the core principles will be applicable. For simplicity, the examples in this document follow a "Combined DAO/DTO" approach (behaviorally-rich Object Model).
Managing entity relationships can be a challenging task, especially when scalability and transactionality are required. The core challenge is that the ideal solution must be capable of managing the complexity of these inter-entity relationships with a minimum of developer involvement. Conceptually, the problem is one of taking the relationship model (which could be represented in any of a number of forms, including XML or Java source) and providing runtime behavior which adheres to that description.
Present solutions can be categorized into a few groups:
- Code generation (.java or .class files)
- Runtime byte-code instrumentation (ClassLoader interception)
- Predefined DAO methods
Code Generation
Code generation is a popular option, involving the generation of .java or .class files. This approach is commonly used with a number of Management and Monitoring, AOP and ORM tools (AspectJ, Hibernate). The primary challenges with this approach are the generation of artifacts, which may need to be managed in a software configuration management (SCM) system.
Byte-code instrumentation
This approach uses ClassLoader interception to instrument classes as they are loaded into the JVM. This approach is commonly used with AOP tools (AspectJ, JBossCacheAop, TerraCotta) and some ORM tools (very common with JDO implementations). Due to the risks (perceived or actual) associated with run-time modification of code (including a tendency to break the hot-deploy options on application servers), this option isn't viable for many organizations and as such is a non-starter.
Developer-implemented classes
The most flexible option is to have a runtime query engine. ORM products shift most of this processing off onto the database server. The alternative is to provide the query engine inside the application tier; but again, this leads toward the same complexity that limits the manageability and scalability of a full-fledged database server.
The recommended practice for Coherence is to map out DAO methods explicitly. This provides deterministic behavior (avoiding dynamically evaluated queries), with some added effort of development. This effort will be directly proportional to the complexity of the relationship model. For small- to mid-size models (up to ~50 entity types managed by Coherence), this will be fairly modest development effort. For larger models (or for those with particularly complicated relationships), this may be a substantial development effort.
As a best practice, all state, relationships and atomic transactions should be handled by the Object Model. For more advanced transactional control, there should be an additional Service Layer which coordinates concurrency (allowing for composable transactions).
| Composable Transactions
The Java language does not directly support composable transactions (the ability to combine multiple transactions into a single transaction). The core Coherence API, based on standard JavaSE patterns, does not either. Locking and synchronization operations support only non-composable transactions.
To quote from the Microsoft Research Paper titled "Composable Memory Transactions (PDF)":
Perhaps the most fundamental objection, though, is that lock-based programs do not compose: correct fragments may fail when combined. For example, consider a hash table with thread-safe insert and delete operations. Now suppose that we want to delete one item A from table t1, and insert it into table t2; but the intermediate state (in which neither table contains the item) must not be visible to other threads. Unless the implementor of the hash table anticipates this need, there is simply no way to satisfy this requirement. [...] In short, operations that are individually correct (insert, delete) cannot be composed into larger correct operations.
—Tim Harris et al, "Composable Memory Transactions", Section 2
This is one reason that "transparent clustering" (or any form of clustering that relies on the basic Java language features) only works for non-composable transactions. Applications may use the (composable) TransactionMap to enable composite transactions. Alternatively, applications may use transactional algorithms such as ordered locking to more efficiently support desired levels of isolation and atomicity. The "Service Layer" section below will go into more detail on the latter. |
Domain Model
Basics
A NamedCache should contain one type of entity (in the same way that a database table contains one type of entity). The only common exception to this are directory-type caches, which often may contain arbitrary values.
Each additional NamedCache consumes only a few dozen bytes of memory per participating cluster member. This will vary, based on the backing map. Caches configured with the <read-write-backing-map-scheme> for transparent database integration will consume additional resources if write-behind caching is enabled, but this will not be a factor until there are hundreds of named caches.
If possible, cache layouts should be designed so that business transactions map to a single cache entry update. This simplifies transactional control and can result in much greater throughput.
Most caches should use meaningful keys (as opposed to the "meaningless keys" commonly used in relational systems whose only purpose is to manage identity). The one drawback to this is limited query support (as Coherence queries at present apply only to the entry value, not the entry key); to query against key attributes, the value must duplicate the attributes.
Coherence Best Practices
DAO objects must implement the getter/setter/query methods in terms of NamedCache access. The NamedCache API makes this very simple for the most types of operations, especially primary key lookups and simple search queries.
public class Order
implements Serializable
{
public static Order getOrder(OrderId orderId)
{
return (Order)m_cacheOrders.get(orderId);
}
public Customer getCustomer()
{
return (Customer)m_cacheCustomers.get(m_customerId);
}
public Collection getLineItems()
{
return ((Map)m_cacheLineItems.getAll(m_lineItemIds)).values();
}
private CustomerId m_customerId;
private Collection lineItemIds;
private static final NamedCache m_cacheCustomers = CacheFactory.getCache("customers");
private static final NamedCache m_cacheOrders = CacheFactory.getCache("orders");
private static final NamedCache m_cacheLineItems = CacheFactory.getCache("orderlineitems");
}
Service Layer
Overview
Applications that require composite transactions should use a Service Layer. This accomplishes two things. First, it allows for proper composing of multiple entities into a single transaction without compromising ACID characteristics. Second, it provides a central point of concurrency control, allowing aggressively optimized transaction management.
Automatic Transaction Management
Basic transaction management consists of ensuring clean reads (based on the isolation level) and consistent, atomic updates (based on the concurrency strategy). The TransactionMap API (accessible either through the J2CA adapter or programmatically) will handle these issues automatically.
Explicit Transaction Management
Unfortunately, the transaction characteristics common with database transactions (described as a combination of isolation level and concurrency strategy for the entire transaction) provide very coarse-grained control. This coarse-grained control is often unsuitable for caches, which are generally subject to far greater transaction rates. By manually controlling transactions, applications can gain much greater control over concurrency and therefore dramatically increase efficiency.
The general pattern for pessimistic transactions is "lock -> read -> write -> unlock". For optimistic transactions, the sequence is "read -> lock & validate -> write -> unlock". When considering a two-phase commit, "locking" is the first phase, and "writing" is the second phase. Locking individual objects will ensure REPEATABLE_READ isolation semantics. Dropping the locks will be equivalent to READ_COMMITTED isolation.
By mixing isolation and concurrency strategies, applications can achieve higher transaction rates. For example, an overly pessimistic concurrency strategy will reduce concurrency, but an overly optimistic strategy may cause excessive transaction rollbacks. By intelligently deciding which entities will be managed pessimistically, and which optimistically, applications can balance the tradeoffs. Similarly, many transactions may require strong isolation for some entities, but much weaker isolation for other entities. Using only the necessary degree of isolation can minimize contention, and thus improve processing throughput.
Optimized Transaction Processing
There are a number of advanced transaction processing techniques that can best be applied in the Service Layer. Proper use of these techniques can dramatically improve throughput, latency and fault-tolerance, at the expense of some added effort.
The most common solution relates to minimizing the need for locking. Specifically, using an ordered locking algorithm can reduce the number of locks required, and also eliminate the possibility of deadlock. The most common example is to lock a parent object prior to locking child object. In some cases, the Service Layer can depend on locks against the parent object to protect the child objects. This effectively makes locks coarse-grained (slightly increasing contention) and substantially minimizes the lock count.
public class OrderService
{
public void executeOrderIfLiabilityAcceptable(Order order)
{
OrderId orderId = order.getId();
m_cacheOrders.lock(orderId, -1);
try
{
BigDecimal outstanding = new BigDecimal(0);
Collection lineItems = order.getLineItems();
for (Iterator iter = lineItems.iterator(); iter.hasNext(); )
{
LineItem item = (LineItem)iter.next();
outstanding = outstanding.add(item.getAmount());
}
Customer customer = order.getCustomer();
if (customer.isAcceptableOrderSize(outstanding))
{
order.setStatus(Order.REJECTED);
}
else
{
order.setStatus(Order.EXECUTED);
}
m_cacheOrders.put(order);
}
finally
{
m_cacheOrders.unlock(orderId);
}
}
}
Relationship Patterns
Managing Collections of Child Objects
Shared Child Objects
For shared child objects (e.g. two parent objects may both refer to the same child object), the best practice is to maintain a list of child object identifiers (aka foreign keys) in the parent object. Then use the NamedCache.get() or NamedCache.getAll() methods to access the child objects. In many cases, it may make sense to use a Near cache for the parent objects and a Replicated cache for the referenced objects (especially if they are read-mostly or read-only).
If the child objects are read-only (or stale data is acceptable), and the entire object graph is often required, then including the child objects in the parent object may be beneficial in reducing the number of cache requests. This is less likely to make sense if the referenced objects are already local, as in a Replicated, or in some cases, Near cache, as local cache requests are very efficient. Also, this makes less sense if the child objects are large. On the other hand, if fetching the child objects from another cache is likely to result in additional network operations, the reduced latency of fetching the entire object graph at once may outweigh the cost of inlining the child objects inside the parent object.
Owned Child Objects
If the objects are owned exclusively, then there are a few additional options. Specifically, it is possible to manage the object graph "top-down" (the normal approach), "bottom-up", or both. Generally, managing "top-down" is the simplest and most efficient approach.
If the child objects are inserted into the cache before the parent object is updated (an "ordered update" pattern), and deleted after the parent object's child list is updated, the application will never see missing child objects.
Similarly, if all Service Layer access to child objects locks the parent object first, SERIALIZABLE-style isolation can be provided very inexpensively (with respect to the child objects).
Bottom-Up Management of Child Objects
To manage the child dependencies "bottom-up", tag each child with the parent identifier. Then use a query (semantically, "find children where parent = ?") to find the child objects (and then modify them if needed). Note that queries, while very fast, are slower than primary key access. The main advantage to this approach is that it reduces contention for the parent object (within the limitations of READ_COMMITTED isolation). Of course, efficient management of a parent-child hierarchy could also be achieved by combining the parent and child objects into a single composite object, and using a custom "Update Child" EntryProcessor, which would be capable of hundreds of updates per second against each composite object.
Bi-Directional Management of Child Objects
Another option is to manage parent-child relationships bi-directionally. An advantage to this is that each child "knows" about its parent, and the parent "knows" about the child objects, simplifying graph navigation (e.g. allowing a child object to find its sibling objects). The biggest drawback is that the relationship state is redundant; for a given parent-child relationship, there is data in both the parent and child objects. This complicates ensuring resilient, atomic updates of the relationship information and makes transaction management more difficult. It also complicates ordered locking/update optimizations.
Colocating Owned Objects
Denormalization
Exclusively owned objects may be managed as normal relationships (wrapping getters/setters around NamedCache methods), or the objects may be embedded directly (roughly analogous to "denormalizing" in database terms). Note that by denormalizing, data is not being stored redundantly, only in a less flexible format. However, since the cache schema is part of the application, and not a persistent component, the loss of flexibility is a non-issue as long as there is not a requirement for efficient ad hoc querying. Using an application-tier cache allows for the cache schema to be aggressively optimized for efficiency, while allowing the persistent (database) schema to be flexible and robust (typically at the expense of some efficiency).
The decision to inline child objects is dependent on the anticipated access patterns against the parent and child objects. If the bulk of cache accesses are against the entire object graph (or a substantial portion thereof), it may be optimal to embed the child objects (optimizing the "common path").
To optimize access against a portion of the object graph (e.g. retrieving a single child object, or updating an attribute of the parent object), use an EntryProcessor to move as much processing to the server as possible, sending only the required data across the network.
Affinity
Partition Affinity can be used to optimize colocation of parent and child objects (ensuring that the entire object graph is always located within a single JVM). This will minimize the number of servers involved in processing a multiple-entity request (queries, bulk operations, etc.). Affinity offers much of the benefit of denormalization without having any impact on application design. However, denormalizing structures can further streamline processing (e.g., turning graph traversal into a single network operation).
Managing Shared Objects
Shared objects should be referenced via a typical "lazy getter" pattern. For read-only data, the returned object may be cached in a transient (non-serializable) field for subsequent access.
public class Order
{
public Customer getCustomer()
{
return (Customer)m_cacheCustomers.get(m_customerId);
}
}
As usual, multiple-entity updates (e.g. updating both the parent and a child object) should be managed by the service layer.
Refactoring Existing DAOs
Generally, when refactoring existing DAOs, the pattern is to split the existing DAO into an interface and two implementations (the original database logic and the new cache-aware logic). The application will continue to use the (extracted) interface. The database logic will be moved into a CacheStore module. The cache-aware DAO will access the NamedCache (backed by the database DAO). All DAO operations that can't be mapped onto a NamedCache will be passed directly to the database DAO.

All trademarks and registered trademarks are the property of their respective owners.
Getting Started
Introduction
Overview
This document is targeted at software developers and architects. This document provides detailed technical information for installing, configuring, developing with, and finally deploying Oracle Coherence.
For ease-of-reading, this document uses only the most basic formatting conventions. Code elements and file contents are printed with a fixed-width font. Multi-line code segments are also color-coded for easier reading.
Oracle Coherence is a JCache-compliant in-memory caching and data management solution for clustered J2EE applications and application servers. Coherence makes sharing and managing data in a cluster as simple as on a single server. It accomplishes this by coordinating updates to the data using cluster-wide concurrency control, replicating and distributing data modifications across the cluster using the highest performing clustered protocol available, and delivering notifications of data modifications to any servers that request them. Developers can easily take advantage of Coherence features using the standard Java collections API to access and modify data, and use the standard JavaBean event model to receive data change notifications. Functionality such as HTTP Session Management is available out-of-the-box for applications deployed to WebLogic, WebSphere, Tomcat, Jetty and other Servlet 2.2, 2.3 and 2.3 compliant application servers.
Terms
Overview
There are several terms which are used to describe the ability of multiple servers to work together to handle additional load or to survive the failure of a particular server:
- Failback
Failback is an extension to failover that allows a server to reclaim its responsibilities once it restarts. For example, "When the server came back up, the processes that it was running previously were failed back to it."
- Failover
Failover refers to the ability of a server to assume the responsibilities of a failed server. For example, "When the server died, its processes failed over to the backup server."
- Federated Server Model
A federated server model allows multiple servers to cooperate in a distributed manner as if they were a single server, while delegating responsibilities to certain specific servers within the federation. For example, in a federated database, servers from different database vendors can appear to an application to be a single server.
- Load Balancer
A load balancer is a hardware device or software program that delegates network requests to a number of servers, such as in a server farm or server cluster. Load balancers typically can detect server failure and optionally retry operations that were being processed by that server at the time of its failure. Load balancers typically attempt to keep the servers to which they delegate equally busy, hence the use of the term "balancer". Load balancer devices often have a high-availability option that uses a second load balancer, allowing one of the load balancer devices to die without affecting availability.
- Server Cluster
A server cluster is composed of multiple servers that are each aware of the other servers in the cluster, can directly communicate with each other, share responsibilities (load-balance), and are able to assume the responsibilities failed servers. Generally speaking, clustering usually implies a concept of shared resources or shared state.
- Server Farm
A server farm utilizes multiple servers to handle increased load and provide increased availability. It is common for a load-balancer to be used to assign work to the various servers in the server farm, and server farms often share back-end resources, such as database servers, but each server is typically unaware of other servers in the farm, and usually the load-balancer is responsible for failover.
- JCache
JCache (also known as JSR-107), is a caching API specification that is currently in progress. While the final version of this API has not been released yet, Oracle and other companies with caching products have been tracking the current status of the API. The API has been largely solidified at this point. Few significant changes are expected going forward.
It is worth noting that the terms federated server model, server clustering and server farming are often used loosely and interchangeably.
Oracle Coherence supports both homogenous server clusters and the federated server model. Any application or server process that is running the Coherence software is called a cluster node. All cluster nodes on the same network will automatically cluster together . Cluster nodes use a peer-to-peer protocol, which means that any cluster node can talk directly to any other cluster node.
Coherence is logically sub-divided into clusters, services and caches. A Coherence cluster is a group of cluster nodes that share a group address, which allows the cluster nodes to communicate. Generally, a cluster node will only join one cluster, but it is possible for a cluster node to join (be a member of) several different clusters, by using a different group address for each cluster.
Within a cluster, there exists any number of named services. A cluster node can participate in (join) any number of these services; when a cluster node joins a service, it automatically has all of the information from that service available to it; for example, if the service is a replicated cache service, then joining the service includes replicating the data of all the caches in the service. These services are all peer-to-peer, which means that a cluster node typically plays both the client and the server role through the service; furthermore, all of these services will failover in the event of cluster node failure without any data loss.
Installing Oracle Coherence
Downloading and Extracting Coherence
For Windows and any other OS supporting the .zip format, Coherence is downloadable as a .zip file. If prompted by your browser, choose to save the downloaded file. Once it has completed downloading, expand the .zip file (using WinZip or the unzip command-line utility) to the location of your choice. On Windows, you can expand it to your c:\ directory; on Unix, it is suggested that you expand it to the /opt directory. Expanding the .zip will create a coherence directory with several sub-directories.
Installing Coherence
If you are adding Coherence to an application server, you will need to make sure that tangosol.jar and coherence.jar libraries (found in coherence/lib/) are in the CLASSPATH (or the equivalent mechanism that your application server uses).
Alternatively, if your application server supports it, you can package the tangosol.jar and coherence.jar libraries into your application's .ear, .jar or .war file.
For purposes of compilation, you will need to make sure that tangosol.jar and coherence.jar libraries are in the CLASSPATH (or the equivalent mechanism that your compiler or IDE uses).
Verifying that multiple nodes and servers are able to form a cluster
Coherence includes a self-contained console application that can be used to verify that installation is successful and that all the servers that are meant to participate in the cluster are indeed capable of joining the cluster. We recommend that you perform this quick test when you first start using Coherence in a particular network and server environment, to verify that the nodes do indeed connect as expected. You can do that by repeating the following set of steps to start Coherence on each server (you can start multiple instances of Coherence on the same server as well):
- Change the current directory to the Coherence library directory (%COHERENCE_HOME%\lib on Windows and $COHERENCE_HOME/lib on Unix).
- Make sure that the paths are configured so that the Java command will run.
- Run the following command to start Coherence command line:
You should see something like this after you start the first member:
c:\coherence\lib>java -jar coherence.jar
2007-05-23 10:48:16.546 Oracle Coherence 3.3/387 (thread=main, member=n/a): Loaded operational configuration from
resource "jar:file:/C:/coherence/lib/coherence.jar!/tangosol-coherence.xml"
2007-05-23 10:48:16.562 Oracle Coherence 3.3/387 (thread=main, member=n/a): Loaded operational overrides from res
ource "jar:file:/C:/coherence/lib/coherence.jar!/tangosol-coherence-override-dev.xml"
2007-05-23 10:48:16.562 Oracle Coherence 3.3/387 (thread=main, member=n/a): Optional configuration override "/tango
sol-coherence-override.xml" is not specified
Oracle Coherence Version 3.3/387
Grid Edition: Development mode
Copyright (c) 2000-2007 Oracle. All rights reserved.
2007-05-23 10:48:17.203 Oracle Coherence GE 3.3/387 (thread=Cluster, member=n/a): Service Cluster joined the cluste
r with senior service member n/a
2007-05-23 10:48:20.453 Oracle Coherence GE 3.3/387 (thread=Cluster, member=n/a): Created a new cluster with Memb
er(Id=1, Timestamp=2007-05-23 10:48:17.0, Address=192.168.0.204:8088, MachineId=26828, Location=process:3292@localhost,
Edition=Grid Edition, Mode=Development, CpuCount=2, SocketCount=1) UID=0xC0A800CC00000112B968DF6868CC1F98
SafeCluster: Name=n/a
Group{Address=224.3.3.0, Port=33387, TTL=4}
MasterMemberSet
(
ThisMember=Member(Id=1, Timestamp=2007-05-23 10:48:17.0, Address=192.168.0.204:8088, MachineId=26828)
OldestMember=Member(Id=1, Timestamp=2007-05-23 10:48:17.0, Address=192.168.0.204:8088, MachineId=26828)
ActualMemberSet=MemberSet(Size=1, BitSetCount=2
Member(Id=1, Timestamp=2007-05-23 10:48:17.0, Address=192.168.0.204:8088, MachineId=26828)
)
RecycleMillis=120000
RecycleSet=MemberSet(Size=0, BitSetCount=0
)
)
Services
(
TcpRing{TcpSocketAccepter{State=STATE_OPEN, ServerSocket=192.168.0.204:8088}, Connections=[]}
ClusterService{Name=Cluster, State=(SERVICE_STARTED, STATE_JOINED), Id=0, Version=3.3, OldestMemberId=1}
)
Map (?):
2007-05-23 10:48:53.406 Oracle Coherence GE 3.3/387 (thread=Cluster, member=1): Member(Id=2, Timestamp=2007-05-23 1
0:48:53.218, Address=192.168.0.204:8089, MachineId=26828, Location=process:3356@localhost) joined Cluster with senior member 1
Map (?):
As you can see there is only one member listed in the ActualMemberSet. When the second member is started, you should see something similar to the following at its start up:
c:\coherence\lib>java -jar coherence.jar
2007-05-23 10:48:52.562 Oracle Coherence 3.3/387 (thread=main, member=n/a): Loaded operational configuration from
resource "jar:file:/C:/coherence/lib/coherence.jar!/tangosol-coherence.xml"
2007-05-23 10:48:52.562 Oracle Coherence 3.3/387 (thread=main, member=n/a): Loaded operational overrides from
resource "jar:file:/C:/coherence/lib/coherence.jar!/tangosol-coherence-override-dev.xml"
2007-05-23 10:48:52.578 Oracle Coherence 3.3/387 (thread=main, member=n/a): Optional configuration override
"/tangosol-coherence-override.xml" is not specified
Oracle Coherence Version 3.3/387
Grid Edition: Development mode
Copyright (c) 2000-2007 Oracle. All rights reserved.
2007-05-23 10:48:53.203 Oracle Coherence GE 3.3/387 (thread=Cluster, member=n/a): Service Cluster joined the cluste
r with senior service member n/a
2007-05-23 10:48:53.421 Oracle Coherence GE 3.3/387 (thread=Cluster, member=n/a): This Member(Id=2, Timestamp=200
7-05-23 10:48:53.218, Address=192.168.0.204:8089, MachineId=26828, Location=process:3356@localhost, Edition=Grid Edition,
Mode=Development, CpuCount=2, SocketCount=1) joined cluster with senior Member(Id=1, Timestamp=2007-05-23 10:48:17.0,
Address=192.168.0.204:8088, MachineId=26828, Location=process:3292@localhost, Edition=Grid Edition, Mode=Development,
CpuCount=2, SocketCount=1)
SafeCluster: Name=n/a
Group{Address=224.3.3.0, Port=33387, TTL=4}
MasterMemberSet
(
ThisMember=Member(Id=2, Timestamp=2007-05-23 10:48:53.218, Address=192.168.0.204:8089, MachineId=26828)
OldestMember=Member(Id=1, Timestamp=2007-05-23 10:48:17.0, Address=192.168.0.204:8088, MachineId=26828)
ActualMemberSet=MemberSet(Size=2, BitSetCount=2
Member(Id=1, Timestamp=2007-05-23 10:48:17.0, Address=192.168.0.204:8088, MachineId=26828)
Member(Id=2, Timestamp=2007-05-23 10:48:53.218, Address=192.168.0.204:8089, MachineId=26828)
)
RecycleMillis=120000
RecycleSet=MemberSet(Size=0, BitSetCount=0
)
)
Services
(
TcpRing{TcpSocketAccepter{State=STATE_OPEN, ServerSocket=192.168.0.204:8089}, Connections=[]}
ClusterService{Name=Cluster, State=(SERVICE_STARTED, STATE_JOINED), Id=0, Version=3.3, OldestMemberId=1}
)
Map (?):
2007-05-23 10:48:54.453 Oracle Coherence GE 3.3/387 (thread=TcpRingListener, member=2): TcpRing: connecting to
member 1 using TcpSocket{State=STATE_OPEN, Socket=Socket[addr=/192.168.0.204,port=1884,localport=8089]}
Map (?):
If you execute the who command at the Map(?): prompt of the first member after the second member is started, you should see the same two members:
Map (?): who
SafeCluster: Name=n/a
Group{Address=224.3.3.0, Port=33387, TTL=4}
MasterMemberSet
(
ThisMember=Member(Id=1, Timestamp=2007-05-23 10:48:17.0, Address=192.168.0.204:8088, MachineId=26828)
OldestMember=Member(Id=1, Timestamp=2007-05-23 10:48:17.0, Address=192.168.0.204:8088, MachineId=26828)
ActualMemberSet=MemberSet(Size=2, BitSetCount=2
Member(Id=1, Timestamp=2007-05-23 10:48:17.0, Address=192.168.0.204:8088, MachineId=26828)
Member(Id=2, Timestamp=2007-05-23 10:48:53.218, Address=192.168.0.204:8089, MachineId=26828)
)
RecycleMillis=120000
RecycleSet=MemberSet(Size=0, BitSetCount=0
)
)
Services
(
TcpRing{TcpSocketAccepter{State=STATE_OPEN, ServerSocket=192.168.0.204:8088}, Connections=[2]}
ClusterService{Name=Cluster, State=(SERVICE_STARTED, STATE_JOINED), Id=0, Version=3.3, OldestMemberId=1}
)
Map (?):
As more new members are started, you should see their addition reflected in the ActualMemberSet list. If you do not see new members being added, your network may not be properly configured for multicast traffic; you may use the Multicast Test to verify this.
Installing Coherence*Web Session Management Module
| Applies to Coherence 3.0 or later
Please note that the following installation documentation applies to the Coherence*Web module in Coherence release 3.0 or later. This Session Management Module is very different and much more comprehensive than the module provided with Coherence releases prior to Release 2.3. Since we chose to not include the previous version's module jars and documentation in release 2.3 to avoid confusion, if you are looking for information on how to install pre-Release 2.3 module, please refer to the documentation and the User Guide included with the doc directory of the software distribution for the release level you are installing. |
Coherence*Web Session Management Module: Supported Web Containers
The following table summarizes the web containers that are currently supported by the Coherence*Web Session Management Module and the installation information specific to each supported web container. For detailed installation instructions for a particular web container, click on its name.
Notes:
* The server type alias passed to the Coherence*Web installer via the -server command line option.
General Instructions for Installing Coherence*Web Session Management Module
To enable Coherence*Web in your J2EE application, you need to run a ready to deploy application (recommended) through the automated installer prior to deploying it. The automated installer prepares the application for deployment.
To install Coherence*Web for the J2EE application you are deploying:
- Make sure that the application directory, .ear file or .war file are not being used or accessed by another process.
- Change the current directory to the Coherence library directory (%COHERENCE_HOME%\lib on Windows and $COHERENCE_HOME/lib on Unix).
- Make sure that the paths are configured so that the Java command will run.
- Go through the application inspection step by running the following command and specifying the full path to your application and the name of your server found in the chart above (replacing the <app-path> and <server-type> with them in the command line below):
A successful result of this step is the creation (or an update, if it already exists) of the coherence-web.xml configuration descriptor file for your J2EE application in the directory where the application is located. This configuration descriptor contains the default Coherence*Web settings for your application that the installer suggests be used in the following install step. You may at this point proceed to the install step, or review and modify the settings to fit them to your requirements prior to running the install step (which would make the install step use your modified settings). For example, you can enable certain features by setting the "context-param" options in the coherence-web.xml configuration descriptor:
- Go through the Coherence*Web application installation step by running the following command and specifying the full path to your application (replacing the <app-path> with it in the command line below):
Please note that the installer expects to find the valid coherence-web.xml configuration descriptor for its use in the same directory the application is located.
- Deploy the updated application and verify that everything functions as expected, using the load balancer if necessary. Please remember that the load balancer is only intended for testing and should not be used in a production environment.
Installing Coherence*Web Session Management Module on BEATM WebLogicTM 8.x
The following are additional steps to take when installing the Coherence*Web Session Management Module into a BEA WebLogic 8.x server:
Installing Coherence*Web Session Management Module on BEATM WebLogicTM 9.x
The following are additional steps to take when installing the Coherence*Web Session Management Module into a BEA WebLogic 9.x server:
Installing Coherence*Web Session Management Module on BEATM WebLogicTM Portal 8.1.6+
The following are additional steps to take when installing the Coherence*Web Session Management Module into a BEA WebLogic Portal 8.1.6+ server:
Installing Coherence*Web Session Management Module on Caucho Resin® 3.0.x
The following are additional steps to take when installing the Coherence*Web Session Management Module into a Caucho Resin server:
Installing Coherence*Web Session Management Module on Oracle® OC4J 10.1.2.x
The following are additional steps to take when installing the Coherence*Web Session Management Module into a Oracle OC4J 10.1.2.x server:
How the Coherence*Web Installer instruments a J2EE application
During the inspect step, the Coherence*Web Installer performs the following tasks:
- Generate a template coherence-web.xml configuration file that contains basic information about the application and target web container along with a set of default Coherence*Web configuration context parameters appropriate for the target web container. If an existing coherence-web.xml configuration file exists (for example, from a previous run of the Coherence*Web Installer), the context parameters in the existing file are merged with those in the generated template.
- Enumerate the JSPs from each web application in the target J2EE application and add information about each JSP to the coherence-web.xml configuration file.
- Enumerate the TLDs from each web application in the target J2EE application and add information about each TLD to the coherence-web.xml configuration file.
During the install step, the Coherence*Web Installer performs the following tasks:
- Create a backup of the original J2EE application so that it can be restored during the uninstall step.
- Add the Coherence*Web configuration context parameters generated in step (1) of the inspect step to the web.xml descriptor of each web application contained in the target J2EE application.
- Unregister any application-specific ServletContextListener, ServletContextAttributeListener, ServletRequestListener, ServletRequestAttributeListener, HttpSessionListener, and HttpSessionAttributeListener classes (including those registered by TLDs) from each web application.
- Register a Coherence*Web ServletContextListener in each web.xml descriptor. At runtime, the Coherence*Web ServletContextListener will propagate each ServletContextEvent to each application-specific ServletContextListener.
- Register a Coherence*Web ServletContextAttributeListener in each web.xml descriptor. At runtime, the Coherence*Web ServletContextAttributeListener will propagate each ServletContextAttributeEvent to each application-specific ServletContextAttributeListener.
- Wrap each application-specific Servlet declared in each web.xml descriptor with a Coherence*Web SessionServlet. At runtime, each Coherence*Web SessionServlet will delegate to the wrapped Servlet.
- Add the following directive to each JSP enumerated in step (2) of the inspect step: <%@ page extends="com.tangosol.coherence.servlet.api22.JspServlet" %>
During the uninstall step, the Coherence*Web Installer replaces the instrumented J2EE application with the backup of the original version created in step (1) of the install process.
Testing HTTP session management (without a dedicated loadbalancer)
Coherence comes with a light-weight software load balancer; it is only intended for testing purposes. The load balancer is very useful when testing functionality such as Session Management and is very easy to use.
- Start multiple application server processes, on one or more server machines, each running your application on a unique IP address and port combination.
- Open a command (or shell) window.
- Change the current directory to the Coherence library directory (%COHERENCE_HOME%\lib on Windows and $COHERENCE_HOME/lib on Unix).
- Make sure that the paths are configured so that the Java command will run.
- Start the software load balancer with the following command lines (each of these command lines makes the application available on the default HTTP port, which is port 80):
To test load-balancing locally on one machine with two application server instances on ports 7001 and 7002:
To run the load-balancer locally on a machine named server1 that load balances to port 7001 on server1, server2 and server3:
Assuming the above command line, an application that previously was accessed with the URL http://server1:7001/my.jsp would now be accessed with the URL http://server1:80/my.jsp or just http://server1/my.jsp.
The following command line options are supported:
| -backlog |
Sets the TCP/ IP accept backlog option to the specified value, for example:
-backlog=64 |
| -threads |
Uses the specified number of request/ response thread pairs (so the total number of additional daemon threads will be two times the specified value), for example:
-threads=64 |
| -roundrobin |
Specifies the use of a round-robin load-balancing algorithm |
| -random |
Specifies the use of a random load-balancing algorithm (default) |
Make sure that your application uses only relative re-directs or the address or the load-balancer.
Using the Coherence*Web Installer Ant Task
Description
The Coherence*Web Installer Ant task allows you to run the Coherence*Web Installer from within your existing Ant build files. To use the Coherence*Web Installer Ant task, add the following task import statement to your Ant build file:
<taskdef name="cwi" classname="com.tangosol.coherence.misc.CoherenceWebAntTask">
<classpath>
<pathelement location="${coherence.home}/lib/webInstaller.jar"/>
</classpath>
</taskdef>
where ${coherence.home} refers to the root directory of your Coherence installation.
The basic process of installing Coherence*Web into a J2EE application from an Ant build is as follows:
- Build your J2EE application as you normally would
- Run the Coherence*Web Ant task with the operations attribute set to inspect
- Make any necessary changes to the generated Coherence*Web XML descriptor
- Run the Coherence*Web Ant task with the operations attribute set to install
If you are performing iterative development on your application (modifying JSPs, Servlets, static resources, etc.), the installation process would consist of the following steps:
- Run the Coherence*Web Ant task with the operations attribute set to uninstall, the failonerror attribute set to false, and the descriptor attribute set to the location of the previously generated Coherence*Web XML descriptor (from step 2 above)
- Build your J2EE application as you normally would
- Run the Coherence*Web Ant task with the operations attribute set to inspect, install and the descriptor attribute set to the location of the previously generated Coherence*Web XML descriptor (from step 2 above)
If you want to change the Coherence*Web configuration settings of a J2EE application that already has Coherence*Web installed:
- Run the Coherence*Web Ant task with the operations attribute set to uninstall and the descriptor attribute set to the location of the Coherence*Web XML descriptor for the J2EE application.
- Change the necessary configuration parameters in the Coherence*Web XML descriptor.
- Run the Coherence*Web Ant task with the operations attribute set to install and the descriptor attribute set to the location of the modified Coherence*Web XML descriptor (from step 2).
Parameters
| Attribute |
Description |
Required |
| app |
Path to the target J2EE application. This can be a path to a WAR file, an EAR file, an exploded WAR directory, or an exploded EAR directory. |
true, if the operations attribute is set to any value other than version |
| backup |
Path to a directory that will hold a backup of the original target J2EE application. This attribute defaults to the directory that contains the J2EE application. |
false |
| descriptor |
Path to the Coherence*Web XML descriptor. This attribute defaults to coherence-web.xml in the directory that contains the target J2EE application. |
false |
| failonerror |
Stop the Ant build if the Coherence*Web installer exits with a status other than 0. The default is true. |
false |
| nowarn |
Suppress warning messages. This attribute can be either true or false. The default is false. |
false |
| operations |
comma- or space-separated list of operations to perform; each operation must be one of inspect, install, uninstall, or version. |
true |
| server |
The alias of the target J2EE application server. |
false |
| touch |
Touch JSPs and TLDs that are modified by the Coherence*Web installer. This attribute can be either true, false, or 'M/d/y h:mm a'. The default is false. |
false |
| verbose |
Show verbose output. This attribute can be either true or false. The default is false. |
false |
Examples
Inspect the myWebApp.war web application and generate a Coherence*Web XML descriptor called my-coherence-web.xml in the current working directory:
<cwi app="myWebApp.war" operations="inspect" descriptor="my-coherence-web.xml"/>
Install Coherence*Web into the myWebApp.war web application using the Coherence*Web XML descriptor called my-coherence-web.xml found in the current working directory:
<cwi app="myWebApp.war" operations="install" descriptor="my-coherence-web.xml"/>
Uninstall Coherence*Web from the myWebApp.war web application:
<cwi app="myWebApp.war" operations="uninstall">
Install Coherence*Web into the myWebApp.war web application located in the /dev/myWebApp/build directory using the Coherence*Web XML descriptor called my-coherence-web.xml found in the /dev/myWebApp/src directory, and place a backup of the original web application in the /dev/myWebApp/work directory:
<cwi app="/dev/myWebApp/build/myWebApp.war" operations="install" descriptor="/dev/myWebApp/src/my-coherence-web.xml" backup="/dev/myWebApp/work"/>
Install Coherence*Web into the myWebApp.war web application located in the /dev/myWebApp/build directory using the Coherence*Web XML descriptor called coherence-web.xml found in the /dev/myWebApp/build directory. If the web application has not already been inspected (i.e. /dev/myWebApp/build/coherence-web.xml does not exists), inspect the web application prior to installing Coherence*Web:
<cwi app="/dev/myWebApp/build/myWebApp.war" operations="inspect,install"/>
Reinstall Coherence*Web into the myWebApp.war web application located in the /dev/myWebApp/build directory using the Coherence*Web XML descriptor called my-coherence-web.xml found in the /dev/myWebApp/src directory:
<cwi app="/dev/myWebApp/build/myWebApp.war" operations="uninstall,install" descriptor="/dev/myWebApp/src/my-coherence-web.xml"/>
Types of Caches in Coherence
Overview
The following is an overview of the types of caches offered by Coherence. More detail is provided in later sections.
Replicated
Data is fully replicated to every member in the cluster. Offers the fastest read performance. Clustered, fault-tolerant cache with linear performance scalability for reads, but poor scalability for writes (as writes must be processed by every member in the cluster). Because data is replicated to all machines, adding servers does not increase aggregate cache capacity.
Optimistic
OptimisticCache is a clustered cache implementation similar to the ReplicatedCache implementation, but without any concurrency control. This implementation has the highest possible throughput. It also allows to use an alternative underlying store for the cached data (for example, a MRU/MFU-based cache). However, if two cluster members are independently pruning or purging the underlying local stores, it is possible that a cluster member may have a different store content than that held by another cluster member.
Distributed (Partitioned)
Clustered, fault-tolerant cache with linear scalability. Data is partitioned among all the machines of the cluster. For fault-tolerance, partitioned caches can be configured to keep each piece of data on one, two or more unique machines within a cluster.
Near
A hybrid cache; fronts a fault-tolerant, scalable partitioned cache with a local cache. Near cache invalidates front cache entries, using configurable invalidation strategy, and provides excellent performance and synchronization. Near cache backed by a partitioned cache offers zero-millisecond local access for repeat data access, while enabling concurrency and ensuring coherency and fail-over, effectively combining the best attributes of replicated and partitioned caches.
Summary of Cache Types
Numerical Terms:
JVMs = number of JVMs
DataSize = total size of cached data (measured without redundancy)
Redundancy = number of copies of data maintained
LocalCache = size of local cache (for near caches)
| |
Replicated Cache |
Optimistic Cache |
Partitioned Cache |
Near Cache backed by partitioned cache |
VersionedNearCache backed by partitioned cache |
LocalCache not clustered |
| Topology |
Replicated |
Replicated |
Partitioned Cache |
Local Caches + Partitioned Cache |
Local Caches + Partitioned Cache |
Local Cache |
| Fault Tolerance |
Extremely High |
Extremely High |
Configurable 4
Zero to Extremely High |
Configurable 4
Zero to Extremely High |
Configurable 4
Zero to Extremely High |
Zero |
| Read Performance |
Instant 5 |
Instant 5 |
Locally cached: instant 5
Remote: network speed 1 |
Locally cached: instant 5
Remote: network speed 1 |
Locally cached: instant 5
Remote: network speed 1 |
Instant 5 |
| Write Performance |
Fast 2 |
Fast 2 |
Extremely fast 3 |
Extremely fast 3 |
Extremely fast 3 |
Instant 5 |
| Memory Usage (Per JVM) |
DataSize |
DataSize |
DataSize/JVMs x Redundancy |
LocalCache + [DataSize / JVMs] |
LocalCache +
[DataSize/JVMs] |
DataSize |
| Memory Usage (Total) |
JVMs x DataSize |
JVMs x DataSize |
Redundancy x DataSize |
[Redundancy x DataSize] +
[JVMs x LocalCache] |
[Redundancy x DataSize] + [JVMs x LocalCache] |
n/a |
| Coherency |
fully coherent |
fully coherent |
fully coherent |
fully coherent 6 |
fully coherent |
n/a |
| Locking |
fully transactional |
none |
fully transactional |
fully transactional |
fully transactional |
fully transactional |
| Typical Uses |
Metadata |
n/a (see Near Cache) |
Read-write caches |
Read-heavy caches w/ access affinity |
n/a (see Near Cache) |
Local data |
Notes:
1 As a rough estimate, with 100mbit ethernet, network reads typically require ~20ms for a 100KB object. With gigabit ethernet, network reads for 1KB objects are typically sub-millisecond.
2 Requires UDP multicast or a few UDP unicast operations, depending on JVM count.
3 Requires a few UDP unicast operations, depending on level of redundancy.
4 Partitioned caches can be configured with as many levels of backup as desired, or zero if desired. Most installations use one backup copy (two copies total).
5 Limited by local CPU/memory performance, with negligible processing required (typically sub-millisecond performance).
6 Listener-based Near caches are coherent; expiry-based near caches are partially coherent for non-transactional reads and coherent for transactional access.
Cache Semantics
Overview
Coherence caches are used to cache value objects. These objects may represent data from any source, either internal (session data, transient data, etc...) or external (database, mainframe, etc...).
Objects placed in the cache must be capable of being serialized. The simplest approach to doing this is to implement java.io.Serializable. For higher performance, Coherence also supports the java.io.Externalizable and (even faster) com.tangosol.io.ExternalizableLite interfaces. The primary difference between Externalizable and ExternalizableLite is the I/O stream used. In most cases, porting from one to the other is a trivial exercise.
Any objects that implement com.tangosol.run.xml.XmlBean will automatically support ExternalizableLite. For more details, see the API JavaDoc for com.tangosol.run.xml.XmlBean.
As a reminder, when serializing an object, Java serialization automatically crawls every object visible (via object references, including collections like Map and List). As a result, cached objects should not refer to their parent objects directly (holding onto an identifying value like an integer is okay). Of course, objects that implement their own serialization routines do not need to worry about this.
Creating and Using Coherence Caches
Overview
The simplest and most flexible way to create caches in Coherence is to use the cache configuration descriptor to define attributes and names for your application's or cluster's caches, and to instantiate the caches in your application code referring to them by name that matches the names or patterns as defined in the descriptor.
This approach to configuring and using Coherence caches has a number of very important benefits. It separates the cache initialization and access logic for the cache in your application from its attributes and characteristics. This way your code is written in a way that is independent of the cache type that will be utilized in your application deployment and changing the characteristics of each cache (such as cache type, cache eviction policy, and cache type-specific attributes, etc.) can be done without making any changes to the code whatsoever. It allows you to create multiple configurations for the same set of named caches and to instruct your application to use the appropriate configuration at deployment time by specifying the descriptor to use in the java command line when the node JVM is started.
Creating a cache in your application.
To instantiate a cache in your application code, you need to:
- Make sure that coherence.jar and tangosol.jar are in your classpath.
- Use CacheFactory.getCache() to access the cache in your code.
Your code will look similar to the following:
import com.tangosol.net.CacheFactory;
import com.tangosol.net.NamedCache;
...
NamedCache cache = CacheFactory.getCache("VirtualCache");
Now you can retrieve and store objects in the cache, using the NamedCache API, which extends the standard java.util.Map interface, adding a number of additional capabilities that provide concurrency control (ConcurrentMap interface), ability to listen for cache changes (ObservableMap interface) and ability to query the cache (QueryMap interface).
The following is an example of typical cache operations:
String key = "key";
MyValue value = (MyValue) cache.get(key);
cache.put(key, value);
Configuring the caches
The cache attributes and settings are defined in the cache configuration descriptor. Cache attributes determine the cache type (what means and resources the cache will use for storing, distributing and synchronizing the cached data) and cache policies (what happens to the objects in the cache based on cache size, object longevity and other parameters).
The structure of the cache configuration descriptor (described in detail by the cache-config.dtd included in the coherence.jar) consists of two primary sections: caching-schemes section and caching-scheme-mapping section.
The caching-schemes section is where the attributes of a cache or a set of caches get defined. The caching schemes can be of a number of types, each with its own set of attributes. The caching schemes can be defined completely from scratch, or can incorporate attributes of other existing caching schemes, referring to them by their scheme-names (using a scheme-ref element) and optionally overriding some of their attributes to create new caching schemes. This flexibility enables you to create caching scheme structures that are easy to maintain, foster reuse and are very flexible.
The caching-scheme-mapping section is where the specific cache name or a naming pattern is attached to the cache scheme that defines the cache configuration to use for the cache that matches the name or the naming pattern.
So if we would like to define the cache descriptor for the cache we mentioned in the previous section (VirtualCache), it may look something like the following:
<?xml version="1.0"?>
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
<cache-config>
<caching-scheme-mapping>
<!--
Caches with any name will be created as default replicated.
-->
<cache-mapping>
<cache-name>*</cache-name>
<scheme-name>default-replicated</scheme-name>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<!--
Default Replicated caching scheme.
-->
<replicated-scheme>
<scheme-name>default-replicated</scheme-name>
<service-name>ReplicatedCache</service-name>
<backing-map-scheme>
<class-scheme>
<scheme-ref>default-backing-map</scheme-ref>
</class-scheme>
</backing-map-scheme>
</replicated-scheme>
<!--
Default backing map scheme definition used by all
The caches that do not require any eviction policies
-->
<class-scheme>
<scheme-name>default-backing-map</scheme-name>
<class-name>com.tangosol.util.SafeHashMap</class-name>
</class-scheme>
</caching-schemes>
</cache-config>
The above cache configuration descriptor specifies that all caches will be created (including our VirtualCache cache) utilizing the default-replicated caching scheme. It defines the default-replicated caching scheme as a replicated-scheme, utilizing a service named ReplicatedCache and utilizing the backing map named default-backing-map, which is defined as a class com.tangosol.util.SafeHashMap (the default backing map storage that Coherence uses when no eviction policies are required).
Then, at a later point, let's say we decide that, since the number of entries that our cache is holding is too large and updates to the objects too frequent to use a replicated cache, we want our VirtualCache cache to become a distributed cache instead (while keeping all other caches replicated). To accommodate these new circumstances, we can change the cache configuration by adding the following cache-scheme definition for the distributed cache to the caching-schemes section:
<!--
Default Distributed caching scheme.
-->
<distributed-scheme>
<scheme-name>default-distributed</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<class-scheme>
<scheme-ref>default-backing-map</scheme-ref>
</class-scheme>
</backing-map-scheme>
</distributed-scheme>
and then mapping the VirtualCache cache to it in the caching-schemes-mapping section:
<cache-mapping>
<cache-name>VirtualCache</cache-name>
<scheme-name>default-distributed</scheme-name>
</cache-mapping>
The resulting cache definition descriptor will look as follows:
<?xml version="1.0"?>
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
<cache-config>
<caching-scheme-mapping>
<!--
Caches with any name will be created as default replicated.
-->
<cache-mapping>
<cache-name>*</cache-name>
<scheme-name>default-replicated</scheme-name>
</cache-mapping>
<cache-mapping>
<cache-name>VirtualCache</cache-name>
<scheme-name>default-distributed</scheme-name>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<!--
Default Replicated caching scheme.
-->
<replicated-scheme>
<scheme-name>default-replicated</scheme-name>
<service-name>ReplicatedCache</service-name>
<backing-map-scheme>
<class-scheme>
<scheme-ref>default-backing-map</scheme-ref>
</class-scheme>
</backing-map-scheme>
</replicated-scheme>
<!--
Default Distributed caching scheme.
-->
<distributed-scheme>
<scheme-name>default-distributed</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<class-scheme>
<scheme-ref>default-backing-map</scheme-ref>
</class-scheme>
</backing-map-scheme>
</distributed-scheme>
<!--
Default backing map scheme definition used by all
The caches that do not require any eviction policies
-->
<class-scheme>
<scheme-name>default-backing-map</scheme-name>
<class-name>com.tangosol.util.SafeHashMap</class-name>
</class-scheme>
</caching-schemes>
</cache-config>
Once we revise and deploy the descriptor and restart the cluster, the VirtualCache cache will be a distributed cache instead of replicated, all without any changes to the code we wrote.
Cache Configuration Descriptor location
A few words about how to instruct Coherence where to find the cache configuration descriptor. Without specifying anything in the command java command line, Coherence will attempt to use the cache configuration descriptor named coherence-cache-config.xml that it finds in the classpath. Since Coherence ships with this file packaged into the coherence.jar, unless you place another file with the same name in the classpath location preceding coherence.jar, that is the one that Coherence will use. You can tell Coherence to use a different default descriptor by using the -Dtangosol.coherence.cacheconfig java command line property as follows:
The above command instructs Coherence to use my-config.xml file in /cfg directory as the default cache configuration descriptor. As you can see, this capability can give you the flexibility to modify the cache configurations of your applications without making any changes to the application code and by simply specifying different cache configuration descriptors at application deployment or start-up.
Putting it all together: your first Coherence cache example
Let's try walking through creating a working example cache using the caches and the cache configuration descriptor we described in the previous section. The easiest way to initially do that is to use the Coherence command line application. A couple of general comments regarding this example before we get started:
- In the examples we refer to the 'nodes' or 'JVMs'. We make no assumption as to where they will run - you can run all of them on the same machine multiple machines or a combination of multiple nodes per machine and multiple machines. To see the clustered cache in action you will need at least 2 nodes to see the JVMs sharing data (all the following examples were captured with 2 JVMs on a single machine).
- This example uses Windows conventions and commands but it will work equally well in any of the Unix environments (with the appropriate adjustments for the Unix commands and conventions) and we encourage you to try it on multiple machines with different operating systems, as this is the way Coherence is designed to function: on multiple platforms simultaneously.
Setting up your test environment
To set up the test environment, you will need install Coherence by unzipping the software distribution in the desired location on one or more machines.
The coherence/examples directory of the software contains the following examples that we will be making use of in this exercise:
- examples/config/explore-config.xml is the configuration descriptor we will use.
- examples/java/com/tangosol/examples/explore/SimpleCacheExplorer.java is the java class that demonstrates how you can access the cache from a command line.
To deploy and run it, you need to execute the following java command line (from the tangosol directory):
- In Windows:
- In Unix:
You should see something like the following when you bring it up:
T:\tangosol>java -cp ./lib/coherence.jar;./lib/tangosol.jar;./examples/java
-Dtangosol.coherence.cacheconfig=./examples/config/explore-config.xml
com.tangosol.examples.explore.SimpleCacheExplorer
2007-05-23 11:53:40.203 Oracle Coherence 3.3/387 (thread=main, member=n/a): Loaded operational configuration from
resource "jar:file:/C:/coherence/lib/coherence.jar!/tangosol-coherence.xml"
2007-05-23 11:53:40.203 Oracle Coherence 3.3/387 (thread=main, member=n/a): Loaded operational overrides from
resource "jar:file:/C:/coherence/lib/coherence.jar!/tangosol-coherence-override-dev.xml"
2007-05-23 11:53:40.203 Oracle Coherence 3.3/387 (thread=main, member=n/a): Optional configuration override
"/tangosol-coherence-override.xml" is not specified
Oracle Coherence Version 3.3/387
Grid Edition: Development mode
Copyright (c) 2000-2007 Oracle. All rights reserved.
2007-05-23 11:53:40.390 Oracle Coherence GE 3.3/387 (thread=main, member=n/a): Loaded cache configuration from
file "C:\coherence\examples\config\explore-config.xml"
2007-05-23 11:53:40.890 Oracle Coherence GE 3.3/387 (thread=Cluster, member=n/a): Service Cluster joined the
cluster with senior service member n/a
2007-05-23 11:53:44.140 Oracle Coherence GE 3.3/387 (thread=Cluster, member=n/a): Created a new cluster with
Member(Id=1, Timestamp=2007-05-23 11:53:40.687, Address=192.168.0.204:8088, MachineId=26828, Location=process:3976@localhost,
Edition=Grid Edition, Mode=Development, CpuCount=2, SocketCount=1) UID=0xC0A800CC00000112B9A4BE4F68CC1F98
2007-05-23 11:53:44.203 Oracle Coherence GE 3.3/387 (thread=ReplicatedCache, member=1): Service ReplicatedCache
joined the cluster with senior service member 1
Command: help
clear
get
keys
info
put
quit
remove
Command:
Typing in 'info' will show you the configuration and the other member information (please note that in the following example there are 2 cluster members active):
Command: info
>> VirtualCache cache is using a cache-scheme named 'default-replicated' defined as:
default-replicated
ReplicatedCache
default-backing-map
>> The following member nodes are currently active:
Member(Id=1, Timestamp=2007-05-23 11:53:40.687, Address=192.168.0.204:8088, MachineId=26828, Location=process:3976@localhost
) <-- this node
Member(Id=2, Timestamp=2007-05-23 11:56:04.125, Address=192.168.0.204:8089, MachineId=26828, Location=process:2216@localhost
)
You can also put a value into the cache:
Command: put 1 One
>> Put Complete
Command:
And retrieve a value from the cache:
Command: get 1
>> Value is One
Command:
Try these commands from multiple sessions and see the results.
The examples/jsp/explore/SimpleCacheExplorer.jsp is the JSP file that can be used with your favorite application server:
- To deploy and run it, you will need to deploy the JSP to the default web applications directory of your application server (along with the contents of the examples/jsp/images directory), modify the server start-up script to make sure that the classpath includes tangosol.jar and coherence.jar, and specify the location of the cache configuration file on the Java command line using the -Dtangosol.coherence.cacheconfig option (e.g. -Dtangosol.coherence.cacheconfig=$COHERENCE_HOME/examples/config/explore-config.xml).
- You can then start one or more instances of the application server (on different machines or different ports) and access the SimpleCacheExplorer.jsp from the browser. You should see something like the following when you bring it up:
As with the command line application please try adding, updating and removing entries from multiple instances of the application server. Also please notice the information about the cache configuration and cluster membership at the bottom of the page. As cluster members are added and removed, this information will change.
Modifying the cache configuration
Once you are comfortable with the test setup, let's change the cache configuration and test our changes, using this simple test harness. Please remember that after each cache configuration change all the cluster members need to be shut down and then restarted (whether you are using application server instances or just plain java JVMs). All our test are configured to use coherence/examples/config/explore-config.xml, so this the file that needs to be edited to make cache configuration changes.
Let's make the first change we described previously, changing the VirtualCache to be a distributed cache by adding the following (bolded) sections:
<?xml version="1.0"?>
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
<cache-config>
<caching-scheme-mapping>
<!--
Caches with any name will be created as default replicated.
-->
<cache-mapping>
<cache-name>*</cache-name>
<scheme-name>default-replicated</scheme-name>
</cache-mapping>
<cache-mapping>
<cache-name>VirtualCache</cache-name>
<scheme-name>default-distributed</scheme-name>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<!--
Default Replicated caching scheme.
-->
<replicated-scheme>
<scheme-name>default-replicated</scheme-name>
<service-name>ReplicatedCache</service-name>
<backing-map-scheme>
<class-scheme>
<scheme-ref>default-backing-map</scheme-ref>
</class-scheme>
</backing-map-scheme>
</replicated-scheme>
<!--
Default Distributed caching scheme.
-->
<distributed-scheme>
<scheme-name>default-distributed</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<class-scheme>
<scheme-ref>default-backing-map</scheme-ref>
</class-scheme>
</backing-map-scheme>
</distributed-scheme>
<!--
Default backing map scheme definition used by all
The caches that do not require any eviction policies
-->
<class-scheme>
<scheme-name>default-backing-map</scheme-name>
<class-name>com.tangosol.util.SafeHashMap</class-name>
</class-scheme>
</caching-schemes>
</cache-config>
After the changes are saved, the test intances are restarted and you have had a chance to do some test data entry to see how the cache behaves, you should see the following in the cache configuration section of the tests:
- SimpleCacheExplorer.java:
Command: info
>> VirtualCache cache is using a cache-scheme named 'default-distributed' defined as:
default-distributed
DistributedCache
default-backing-map
>> The following member nodes are currently active:
Member(Id=1, Timestamp=Mon Jun 27 09:49:37 EDT 2005, Address=192.168.0.247, Port=8088, MachineId=26871)
Member(Id=2, Timestamp=Mon Jun 27 09:49:43 EDT 2005, Address=192.168.0.247, Port=8089, MachineId=26871) <-- this node
Command:
- SimpleCacheExplorer.jsp:
As you can see, our VirtualCache cache is now distributed according to the cache configuration descriptor.
Now let's add an eviction policy for our default distributed cache, limiting it's size to 5 entries (per node) and setting the entry expiry to 60 seconds with an LRU eviction policy. To do that we need to make the following (bolded) changes to our descriptor:
<?xml version="1.0"?>
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
<cache-config>
<caching-scheme-mapping>
<!--
Caches with any name will be created as default replicated.
-->
<cache-mapping>
<cache-name>*</cache-name>
<scheme-name>default-replicated</scheme-name>
</cache-mapping>
<cache-mapping>
<cache-name>VirtualCache</cache-name>
<scheme-name>default-distributed</scheme-name>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<!--
Default Replicated caching scheme.
-->
<replicated-scheme>
<scheme-name>default-replicated</scheme-name>
<service-name>ReplicatedCache</service-name>
<backing-map-scheme>
<class-scheme>
<scheme-ref>default-backing-map</scheme-ref>
</class-scheme>
</backing-map-scheme>
</replicated-scheme>
<!--
Default Distributed caching scheme.
-->
<distributed-scheme>
<scheme-name>default-distributed</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<local-scheme>
<scheme-ref>default-eviction</scheme-ref>
<eviction-policy>LRU</eviction-policy>
<high-units>5</high-units>
<expiry-delay>60</expiry-delay>
</local-scheme>
</backing-map-scheme>
</distributed-scheme>
<!--
Default backing map scheme definition used by all
The caches that do not require any eviction policies
-->
<class-scheme>
<scheme-name>default-backing-map</scheme-name>
<class-name>com.tangosol.util.SafeHashMap</class-name>
</class-scheme>
<!--
Default eviction policy scheme.
-->
<local-scheme>
<scheme-name>default-eviction</scheme-name>
<eviction-policy>HYBRID</eviction-policy>
<high-units>0</high-units>
<expiry-delay>3600</expiry-delay>
</local-scheme>
</caching-schemes>
</cache-config>
Please note that we defined a general purpose local-scheme 'default-eviction' (with no size limit, 5 minute expiry and a HYBRID eviction policy) and then used it by reference (using scheme-ref) for our default-distributed scheme definition, overriding it's configuration settings to match our requirements.
After the changes are saved, the test intances are restarted and you have had a chance to do some test data entry to see how the cache behaves, you should see the following in the cache configuration section of the tests:
- SimpleCacheExplorer.java:
Command: info
>> VirtualCache cache is using a cache-scheme named 'default-distributed' defined as:
default-distributed
DistributedCache
default-eviction
LRU
5
60
>> The following member nodes are currently active:
Member(Id=1, Timestamp=Mon Jun 27 09:50:07 EDT 2005, Address=192.168.0.247, Port=8088, MachineId=26871)
Member(Id=2, Timestamp=Mon Jun 27 09:50:17 EDT 2005, Address=192.168.0.247, Port=8089, MachineId=26871) <-- this node
Command:
Try doing some puts and gets, carefully noting the time you last updated the specific entries. You should see that the number of entries does not exceed 5 entries per node (so if you have 2 nodes running the number of entries should not exceed 10, for 3 nodes - 15, and so on) and entries either expire after they have not been updated for 60 seconds, or when you add the 6th entry (with the least recently touched entries being 'evicted' from the cache first. (Hint: use the 'keys' command in the SimpleCacheExplorer.java to see the list of keys in the cache.)
These examples show you the general approach to modifying the cache configurations without making any code changes (as you no doubt noticed we did not touch our test application's code). Please refer to the cache-config.dtd, which can be found in the coherence.jar for full details on the available cache configuration descriptor settings and the explanation of their meaning and possible settings.
Configuring and Using Coherence*Extend
Overview
Coherence*ExtendTM extends the reach of the core Coherence TCMP cluster to a wider range of consumers, including desktops, remote servers and machines located across WAN connections. Typical uses of Coherence*Extend include providing desktop applications with access to Coherence caches (including support for Near Cache and Continuous Query) and Coherence cluster "bridges" that link together multiple Coherence clusters connected via a high-latency, unreliable WAN.
Coherence*Extend consists of two basic components: a client and a Coherence*Extend clustered service hosted by one or more DefaultCacheServer processes. The adapter library includes implementations of both the CacheService and InvocationService interfaces that route all requests to a Coherence*Extend clustered service instance running within the Coherence cluster. The Coherence*Extend clustered service in turn responds to client requests by delegating to an actual Coherence clustered service (for example, a Partitioned or Replicated cache service). The client adapter library and Coherence*Extend clustered service use a low-level messaging protocol to communicate with each other. Coherence*Extend includes the following transport bindings for this protocol:
- Extend-JMSTM: uses your existing JMS infrastructure as the means to connect to the cluster
- Extend-TCPTM: uses a high performance, scalable TCP/IP-based communication layer to connect to the cluster
The choice of a transport binding is configuration-driven and is completely transparent to the client application that uses Coherence*Extend. A Coherence*Extend service is retrieved just like a Coherence clustered service: via the CacheFactory class. Once it is obtained, a client uses the Coherence*Extend service in the same way as it would if it were part of the Coherence cluster. The fact that operations are being sent to a remote cluster node (over either JMS or TCP) is transparent to the client application.
General Instructions
Configuring and using Coherence*Extend requires four basic steps:
- Create a client-side Coherence cache configuration descriptor that includes one or more <remote-cache-scheme> and/or <remote-invocation-scheme> configuration elements
- Create a cluster-side Coherence cache configuration descriptor that includes one or more <proxy-scheme> configuration elements
- Launch one or more DefaultCacheServer processes
- Create a client application that uses one or more Coherence*Extend services
- Launch the client application
The following sections describe each of these steps in detail for the Extend-JMS and Extend-TCP transport bindings.
Configuring and Using Coherence*Extend-JMS
Client-side Cache Configuration Descriptor
A Coherence*Extend client that uses the Extend-JMS transport binding must define a Coherence cache configuration descriptor which includes a <remote-cache-scheme> and/or <remote-invocation-scheme> element with a child <jms-initiator> element containing various JMS-specific configuration information. For example:
<?xml version="1.0"?>
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
<cache-config>
<caching-scheme-mapping>
<cache-mapping>
<cache-name>dist-extend</cache-name>
<scheme-name>extend-dist</scheme-name>
</cache-mapping>
<cache-mapping>
<cache-name>dist-extend-near</cache-name>
<scheme-name>extend-near</scheme-name>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<near-scheme>
<scheme-name>extend-near</scheme-name>
<front-scheme>
<local-scheme>
<high-units>1000</high-units>
</local-scheme>
</front-scheme>
<back-scheme>
<remote-cache-scheme>
<scheme-ref>extend-dist</scheme-ref>
</remote-cache-scheme>
</back-scheme>
<invalidation-strategy>all</invalidation-strategy>
</near-scheme>
<remote-cache-scheme>
<scheme-name>extend-dist</scheme-name>
<service-name>ExtendJmsCacheService</service-name>
<initiator-config>
<jms-initiator>
<queue-connection-factory-name>jms/coherence/ConnectionFactory</queue-connection-factory-name>
<queue-name>jms/coherence/Queue</queue-name>
<connect-timeout>10s</connect-timeout>
</jms-initiator>
<outgoing-message-handler>
<request-timeout>5s</request-timeout>
</outgoing-message-handler>
</initiator-config>
</remote-cache-scheme>
<remote-cache-scheme>
<scheme-name>extend-invocation</scheme-name>
<service-name>ExtendJmsInvocationService</service-name>
<initiator-config>
<jms-initiator>
<queue-connection-factory-name>jms/coherence/ConnectionFactory</queue-connection-factory-name>
<queue-name>jms/coherence/Queue</queue-name>
<connect-timeout>10s</connect-timeout>
</jms-initiator>
<outgoing-message-handler>
<request-timeout>5s</request-timeout>
</outgoing-message-handler>
</initiator-config>
</remote-cache-scheme>
</caching-schemes>
</cache-config>
This cache configuration descriptor defines two caching schemes, one that uses Extend-JMS to connect to a remote Coherence cluster (<remote-cache-scheme>) and one that maintains an in-process size-limited near cache of remote Coherence caches (again, accessed via Extend-JMS). Additionally, the cache configuration descriptor defines a <remote-invocation-scheme> that allows the client application to execute tasks within the remote Coherence cluster. Both the <remote-cache-scheme> and <remote-invocation-scheme> elements have a <jms-initiator> child element which includes all JMS-specific information needed to connect the client with the Coherence*Extend clustered service running within the remote Coherence cluster.
When the client application retrieves a NamedCache via the CacheFactory using, for example, the name "dist-extend", the Coherence*Extend adapter library will connect to the Coherence cluster via a JMS Queue (retrieved via JNDI using the name "jms/coherence/Queue") and return a NamedCache implementation that routes requests to the NamedCache with the same name running within the remote cluster. Likewise, when the client application retrieves a InvocationService by calling CacheFactory.getConfigurableCacheFactory().ensureService("ExtendJmsInvocationService"), the Coherence*Extend adapter library will connect to the Coherence cluster via the same JMS Queue and return an InvocationService implementation that executes synchronous Invocable tasks within the remote clustered JVM to which the client is connected.
Cluster-side Cache Configuration Descriptor
In order for a Coherence*Extend-JMSTM client to connect to a Coherence cluster, one or more DefaultCacheServer processes must be running that use a Coherence cache configuration descriptor which includes a <proxy-scheme> element with a child <jms-acceptor> element containing various JMS-specific configuration information. For example:
<?xml version="1.0"?>
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
<cache-config>
<caching-scheme-mapping>
<cache-mapping>
<cache-name>dist-*</cache-name>
<scheme-name>dist-default</scheme-name>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<distributed-scheme>
<scheme-name>dist-default</scheme-name>
<lease-granularity>member</lease-granularity>
<backing-map-scheme>
<local-scheme/>
</backing-map-scheme>
<autostart>true</autostart>
</distributed-scheme>
<proxy-scheme>
<service-name>ExtendJmsProxyService</service-name>
<acceptor-config>
<jms-acceptor>
<queue-connection-factory-name>jms/coherence/ConnectionFactory</queue-connection-factory-name>
<queue-name>jms/coherence/Queue</queue-name>
</jms-acceptor>
</acceptor-config>
<autostart>true</autostart>
</proxy-scheme>
</caching-schemes>
</cache-config>
This cache configuration descriptor defines two clustered services, one that uses Extend-JMS to allow remote Extend-JMS clients to connect to the Coherence cluster and a standard Partitioned cache service. Since this descriptor is used by a DefaultCacheServer it is important that the <autostart> configuration element for each service is set to true so that clustered services are automatically restarted upon termination. The <proxy-scheme> element has a <jms-acceptor> child element which includes all JMS-specific information needed to accept client connection requests over JMS.
The Coherence*Extend clustered service will listen to a JMS Queue (retrieved via JNDI using the name "jms/coherence/Queue") for connection requests. When, for example, a client attempts to connect to a Coherence NamedCache called "dist-extend", the Coherence*Extend clustered service will proxy subsequent requests to the NamedCache with the same name which, in this case, will be a Parititioned cache. Note that Extend-JMS client connection requests will be load balanced across all DefaultCacheServer processes that are running a Coherence*Extend clustered service with the same configuration.
Configuring your JMS Provider
Coherence*Extend-JMS uses JNDI to obtain references to all JMS resources. To specify the JNDI properties that Coherence*Extend-JMS uses to create a JNDI InitialContext, create a file called jndi.properties that contains your JMS provider's configuration properties and add the directory that contains the file to both the client application and DefaultCacheServer classpaths.
For example, if you are using WebLogic Server as your JMS provider, your jndi.properties file would look something like the following:
Additionally, Coherence*Extend-JMS uses a JMS Queue to connect Extend-JMS clients to a Coherence*Extend clustered service instance. Therefore, you must deploy an appropriately configured JMS QueueConnectionFactory and Queue and register them under the JNDI names specified in the <jms-initiator> and <jms-acceptor> configuration elements.
For example, if you are using WebLogic Server, you can use the following Ant script to create and deploy these JMS resources:
ant create.domain -->
domain/startmydomain.cmd|sh -->
<project name="extend-jms-wls" default="create.domain" basedir=".">
<property name="weblogic.home" value="c:/opt/bea/weblogic8.1.5"/>
<property name="weblogic.jar" value="${weblogic.home}/server/lib/weblogic.jar"/>
<property name="server.user" value="system"/>
<property name="server.password" value="weblogic"/>
<property name="domain.dir" value="domain"/>
<property name="domain.name" value="mydomain"/>
<property name="server.name" value="myserver"/>
<property name="realm.name" value="myrealm"/>
<property name="server.host" value="localhost"/>
<property name="server.port" value="7001"/>
<property name="admin.url" value="t3://${server.host}:${server.port}"/>
<path id="project.classpath">
<pathelement location="${weblogic.jar}"/>
</path>
<taskdef name="wlserver"
classname="weblogic.ant.taskdefs.management.WLServer"
classpathref="project.classpath"/>
<taskdef name="wlconfig"
classname="weblogic.ant.taskdefs.management.WLConfig"
classpathref="project.classpath"/>
<target name="clean" description="Remove all build artifacts.">
<delete dir="${domain.dir}"/>
</target>
<target name="create.domain"
description="Create a WLS domain for use with Coherence*Extend-JMS.">
<delete dir="${domain.dir}"/>
<mkdir dir="${domain.dir}"/>
<wlserver weblogicHome="${weblogic.home}"
dir="${domain.dir}"
classpathref="project.classpath"
host="${server.host}"
port="${server.port}"
servername="${server.name}"
domainname="${domain.name}"
generateConfig="true"
username="${server.user}"
password="${server.password}"
action="start"/>
<antcall target="config.domain"/>
</target>
<target name="config.domain"
description="Configure a WLS domain for use with Coherence*Extend-JMS.">
<wlconfig url="${admin.url}"
username="${server.user}"
password="${server.password}">
<query domain="${domain.name}"
type="Server"
name="${server.name}"
property="server"/>
<create type="JMSTemplate" name="CoherenceTemplate" property="template"/>
<create type="JMSServer" name="MyJMSServer">
<set attribute="Targets" value="${server}"/>
<create type="JMSQueue" name="CoherenceQueue">
<set attribute="JNDIName" value="jms/coherence/Queue"/>
</create>
<set attribute="TemporaryTemplate" value="${template}"/>
</create>
<create type="JMSConnectionFactory" name="CoherenceConnectionFactory">
<set attribute="JNDIName"
value="jms/coherence/ConnectionFactory"/>
<set attribute="Targets" value="${server}"/>
</create>
</wlconfig>
</target>
</project>
Launching an Extend-JMS DefaultCacheServer Process
To start a DefaultCacheServer that uses the cluster-side Coherence cache configuration described earlier to allow Extend-JMS clients to connect to the Coherence cluster via JMS, you need to do the following:
- Change the current directory to the Coherence library directory (%COHERENCE_HOME%\lib on Windows and $COHERENCE_HOME/lib on Unix)
- Make sure that the paths are configured so that the Java command will run
- Start the DefaultCacheServer command line application with the directory that contains your jndi.properties file and your JMS provider's libraries on the classpath and the -Dtangosol.coherence.cacheconfig system property set to the location of the cluster-side Coherence cache configuration descriptor described earlier
For example, if you are using WebLogic server as your JMS provider, you would run the following command on Windows (note that it is broken up into multiple lines here only for formatting purposes; this is a single command typed on one line):
On Unix:
Launching an Extend-JMS Client Application
To start a client application that uses Extend-JMS to connect to a remote Coherence cluster via JMS, you need to do the following:
- Change the current directory to the Coherence library directory (%COHERENCE_HOME%\lib on Windows and $COHERENCE_HOME/lib on Unix)
- Make sure that the paths are configured so that the Java command will run
- Start your client application with the directory that contains your jndi.properties file and your JMS provider's libraries on the classpath and the -Dtangosol.coherence.cacheconfig system property set to the location of the client-side Coherence cache configuration descriptor described earlier
For example, if you are using WebLogic server as your JMS provider, you would run the following command on Windows (note that it is broken up into multiple lines here only for formatting purposes; this is a single command typed on one line):
On Unix:
Configuring and Using Coherence*Extend-TCP
Client-side Cache Configuration Descriptor
A Coherence*Extend client that uses the Extend-TCP transport binding must define a Coherence cache configuration descriptor which includes a <remote-cache-scheme> and/or <remote-invocation-scheme> element with a child <tcp-initiator> element containing various TCP/IP-specific configuration information. For example:
<?xml version="1.0"?>
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
<cache-config>
<caching-scheme-mapping>
<cache-mapping>
<cache-name>dist-extend</cache-name>
<scheme-name>extend-dist</scheme-name>
</cache-mapping>
<cache-mapping>
<cache-name>dist-extend-near</cache-name>
<scheme-name>extend-near</scheme-name>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<near-scheme>
<scheme-name>extend-near</scheme-name>
<front-scheme>
<local-scheme>
<high-units>1000</high-units>
</local-scheme>
</front-scheme>
<back-scheme>
<remote-cache-scheme>
<scheme-ref>extend-dist</scheme-ref>
</remote-cache-scheme>
</back-scheme>
<invalidation-strategy>all</invalidation-strategy>
</near-scheme>
<remote-cache-scheme>
<scheme-name>extend-dist</scheme-name>
<service-name>ExtendTcpCacheService</service-name>
<initiator-config>
<tcp-initiator>
<remote-addresses>
<socket-address>
<address>localhost</address>
<port>9099</port>
</socket-address>
</remote-addresses>
<connect-timeout>10s</connect-timeout>
</tcp-initiator>
<outgoing-message-handler>
<request-timeout>5s</request-timeout>
</outgoing-message-handler>
</initiator-config>
</remote-cache-scheme>
<remote-invocation-scheme>
<scheme-name>extend-invocation</scheme-name>
<service-name>ExtendTcpInvocationService</service-name>
<initiator-config>
<tcp-initiator>
<remote-addresses>
<socket-address>
<address>localhost</address>
<port>9099</port>
</socket-address>
</remote-addresses>
<connect-timeout>10s</connect-timeout>
</tcp-initiator>
<outgoing-message-handler>
<request-timeout>5s</request-timeout>
</outgoing-message-handler>
</initiator-config>
</remote-invocation-scheme>
</caching-schemes>
</cache-config>
This cache configuration descriptor defines two caching schemes, one that uses Extend-TCP to connect to a remote Coherence cluster (<remote-cache-scheme>) and one that maintains an in-process size-limited near cache of remote Coherence caches (again, accessed via Extend-TCP). Additionally, the cache configuration descriptor defines a <remote-invocation-scheme> that allows the client application to execute tasks within the remote Coherence cluster. Both the <remote-cache-scheme> and <remote-invocation-scheme> elements have a <tcp-initiator> child element which includes all TCP/IP-specific information needed to connect the client with the Coherence*Extend clustered service running within the remote Coherence cluster.
When the client application retrieves a NamedCache via the CacheFactory using, for example, the name "dist-extend", the Coherence*Extend adapter library will connect to the Coherence cluster via TCP/IP (using the address "localhost" and port 9099) and return a NamedCache implementation that routes requests to the NamedCache with the same name running within the remote cluster. Likewise, when the client application retrieves a InvocationService by calling CacheFactory.getConfigurableCacheFactory().ensureService("ExtendJmsInvocationService"), the Coherence*Extend adapter library will connect to the Coherence cluster via TCP/IP (again, using the address "localhost" and port 9099) and return an InvocationService implementation that executes synchronous Invocable tasks within the remote clustered JVM to which the client is connected.
Note that the <remote-addresses> configuration element can contain multiple <socket-address> child elements. The Coherence*Extend adapter library will attempt to connect to the addresses in a random order, until either the list is exhausted or a TCP/IP connection is established.
Cluster-side Cache Configuration Descriptor
In order for a Coherence*Extend-TCPTM client to connect to a Coherence cluster, one or more DefaultCacheServer processes must be running that use a Coherence cache configuration descriptor which includes a <proxy-scheme> element with a child <tcp-acceptor> element containing various TCP/IP-specific configuration information. For example:
<?xml version="1.0"?>
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
<cache-config>
<caching-scheme-mapping>
<cache-mapping>
<cache-name>dist-*</cache-name>
<scheme-name>dist-default</scheme-name>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<distributed-scheme>
<scheme-name>dist-default</scheme-name>
<lease-granularity>member</lease-granularity>
<backing-map-scheme>
<local-scheme/>
</backing-map-scheme>
<autostart>true</autostart>
</distributed-scheme>
<proxy-scheme>
<service-name>ExtendTcpProxyService</service-name>
<thread-count>5</thread-count>
<acceptor-config>
<tcp-acceptor>
<local-address>
<address>localhost</address>
<port>9099</port>
</local-address>
</tcp-acceptor>
</acceptor-config>
<proxy-config>
<cache-service-proxy>
<lock-enabled>true</lock-enabled>
</cache-service-proxy>
</proxy-config>
<autostart>true</autostart>
</proxy-scheme>
</caching-schemes>
</cache-config>
This cache configuration descriptor defines two clustered services, one that uses Extend-TCP to allow remote Extend-TCP clients to connect to the Coherence cluster and a standard Partitioned cache service. Since this descriptor is used by a DefaultCacheServer it is important that the <autostart> configuration element for each service is set to true so that clustered services are automatically restarted upon termination. The <proxy-scheme> element has a <tcp-acceptor> child element which includes all TCP/IP-specific information needed to accept client connection requests over TCP/IP.
The Coherence*Extend clustered service will listen to a TCP/IP ServerSocket (bound to address "localhost" and port 9099) for connection requests. When, for example, a client attempts to connect to a Coherence NamedCache called "dist-extend-direct", the Coherence*Extend clustered service will proxy subsequent requests to the NamedCache with the same name which, in this case, will be a Partitioned cache.
Launching an Extend-TCP DefaultCacheServer Process
To start a DefaultCacheServer that uses the cluster-side Coherence cache configuration described earlier to allow Extend-TCP clients to connect to the Coherence cluster via TCP/IP, you need to do the following:
- Change the current directory to the Coherence library directory (%COHERENCE_HOME%\lib on Windows and $COHERENCE_HOME/lib on Unix)
- Make sure that the paths are configured so that the Java command will run
- Start the DefaultCacheServer command line application with the -Dtangosol.coherence.cacheconfig system property set to the location of the cluster-side Coherence cache configuration descriptor described earlier
For example (note that the following command is broken up into multiple lines here only for formatting purposes; this is a single command typed on one line):
Launching an Extend-TCP Client Application
To start a client application that uses Extend-TCP to connect to a remote Coherence cluster via TCP/IP, you need to do the following:
- Change the current directory to the Coherence library directory (%COHERENCE_HOME%\lib on Windows and $COHERENCE_HOME/lib on Unix)
- Make sure that the paths are configured so that the Java command will run
- Start your client application with the -Dtangosol.coherence.cacheconfig system property set to the location of the client-side Coherence cache configuration descriptor described earlier
For example (note that the following command is broken up into multiple lines here only for formatting purposes; this is a single command typed on one line):
Example Coherence*Extend Client Application
The following example demonstrates how to retrieve and use a Coherence*Extend CacheService and InvocationService. This example increments an Integer value in a remote Partitioned cache and then retrieves the value by executing an Invocable on the clustered JVM to which the client is attached:
public static void main(String[] asArg)
throws Throwable
{
NamedCache cache = CacheFactory.getCache("dist-extend");
cache.lock("key", -1);
try
{
Integer IValue = (Integer) cache.get("key");
if (IValue == null)
{
IValue = new Integer(1);
}
else
{
IValue = new Integer(IValue.intValue() + 1);
}
cache.put("key", IValue);
}
finally
{
cache.unlock("key");
}
InvocationService service = (InvocationService)
CacheFactory.getConfigurableCacheFactory()
.ensureService("ExtendTcpInvocationService");
Map map = service.query(new AbstractInvocable()
{
public void run()
{
setResult(CacheFactory.getCache("dist-extend").get("key"));
}
}, null);
Integer IValue = (Integer) map.get(service.getCluster().getLocalMember());
}
Note that this example could also be run on a Coherence node (i.e. within the cluster) verbatum. The fact that operations are being sent to a remote cluster node (over either JMS or TCP) is completely transparent to the client application.
| Coherence*Extend InvocationService
Since, by definition, a Coherence*Extend client has no direct knowledge of the cluster and the members running within the cluster, the Coherence*Extend InvocationService only allows Invocable tasks to be executed on the JVM to which the client is connected. Therefore, you should always pass a null member set to the query() method. As a consequence of this, the single result of the execution will be keyed by the local Member, which will be null if the client is not part of the cluster. This Member can be retrieved by calling service.getCluster().getLocalMember(). Additionally, the Coherence*Extend InvocationService only supports synchronous task execution (i.e. the execute() method is not supported). |
Advanced Configuration
Network Filters
Like Coherence clustered services, Coherence*Extend services support pluggable network filters. Filters can be used to modify the contents of network traffic before it is placed "on the wire". Most standard Coherence network filters are supported, including the compression and symmetric encryption filters. For more information on configuring filters, see the Network Filters section.
To use network filters with Coherence*Extend, a <use-filters> element must be added to the <initiator-config> element in the client-side cache configuration descriptor and to the <acceptor-config> element in the cluster-side cache configuration descriptor.
For example, to encrypt network traffic exchanged between a Coherence*Extend client and the clustered service to which it is connected, configure the client-side <remote-cache-scheme> and <remote-invocation-scheme> elements like so (assuming the symmetric encryption filter has been named symmetric-encryption):
<remote-cache-scheme>
<scheme-name>extend-dist</scheme-name>
<service-name>ExtendTcpCacheService</service-name>
<initiator-config>
<tcp-initiator>
<remote-addresses>
<socket-address>
<address>localhost</address>
<port>9099</port>
</socket-address>
</remote-addresses>
<connect-timeout>10s</connect-timeout>
</tcp-initiator>
<outgoing-message-handler>
<request-timeout>5s</request-timeout>
</outgoing-message-handler>
<use-filters>
<filter-name>symmetric-encryption</filter-name>
</use-filters>
</initiator-config>
</remote-cache-scheme>
<remote-invocation-scheme>
<scheme-name>extend-invocation</scheme-name>
<service-name>ExtendTcpInvocationService</service-name>
<initiator-config>
<tcp-initiator>
<remote-addresses>
<socket-address>
<address>localhost</address>
<port>9099</port>
</socket-address>
</remote-addresses>
<connect-timeout>10s</connect-timeout>
</tcp-initiator>
<outgoing-message-handler>
<request-timeout>5s</request-timeout>
</outgoing-message-handler>
<use-filters>
<filter-name>symmetric-encryption</filter-name>
</use-filters>
</initiator-config>
</remote-invocation-scheme>
and the cluster-side <proxy-scheme> element like so:
<proxy-scheme>
<service-name>ExtendTcpProxyService</service-name>
<thread-count>5</thread-count>
<acceptor-config>
<tcp-acceptor>
<local-address>
<address>localhost</address>
<port>9099</port>
</local-address>
</tcp-acceptor>
<use-filters>
<filter-name>symmetric-encryption</filter-name>
</use-filters>
</acceptor-config>
<autostart>true</autostart>
</proxy-scheme>
|
The contents of the <use-filters> element must be the same in the client and cluster-side cache configuration descriptors. |
Connection Error Detection and Failover
When a Coherence*Extend service detects that the connection between the client and cluster has been severed (for example, due to a network, software, or hardware failure), the Coherence*Extend client service implementation (i.e. CacheService or InvocationService) will dispatch a MemberEvent.MEMBER_LEFT event to all registered MemberListeners and the service will be stopped. If the client application attempts to subsequently use the service, the service will automatically restart itself and attempt to reconnect to the cluster. If the connection is successful, the service will dispatch a MemberEvent.MEMBER_JOINED event; otherwise, a fatal exception will be thrown to the client application.
A Coherence*Extend service has several mechanisms for detecting dropped connections. Some mechanisms are inherit to the underlying protocol (i.e. a javax.jms.ExceptionListener in Extend-JMS and TCP/IP in Extend-TCP), whereas others are implemented by the service itself. The latter mechanisms are configured via the <outgoing-message-handler> configuration element.
The primary configurable mechanism used by a Coherence*Extend client service to detect dropped connections is a request timeout. When the service sends a request to the remote cluster and does not receive a response within the request timeout interval (see <request-timeout>), the service assumes that the connection has been dropped. The Coherence*Extend client and clustered services can also be configured to send a periodic heartbeat over the connection (see <heartbeat-interval> and <heartbeat-timeout>). If the service does not receive a response within the configured heartbeat timeout interval, the service assumes that the connection has been dropped.
|
You should always enable heartbeats when using a connectionless transport, as is the case with Extend-JMS. |
|
If you do not specify a <request-timeout/>, a Coherence*Extend service will use an infinite request timeout. In general, this is not a recommended configuration, as it could result in an unresponsive application. For most use cases, you should specify a reasonable finite request timeout. |
Read-only NamedCache Access
By default, the Coherence*Extend clustered service allows both read and write access to proxied NamedCache instances. If you would like to prohibit Coherence*Extend clients from modifying cached content, you may do so using the <cache-service-proxy> child configuration element. For example:
<proxy-scheme>
...
<proxy-config>
<cache-service-proxy>
<read-only>true</read-only>
</cache-service-proxy>
</proxy-config>
<autostart>true</autostart>
</proxy-scheme>
Client-side NamedCache Locking
By default, the Coherence*Extend clustered service disallows Coherence*Extend clients from acquiring NamedCache locks. If you would like to enable client-side locking, you may do so using the <cache-service-proxy> child configuration element. For example:
<proxy-scheme>
...
<proxy-config>
<cache-service-proxy>
<lock-enabled>true</lock-enabled>
</cache-service-proxy>
</proxy-config>
<autostart>true</autostart>
</proxy-scheme>
If you do enable client-side locking and your client application makes use of the NamedCache.lock() and unlock() methods, it is important that you specified the member-based rather than thread-based locking strategy for any Partitioned or Replicated cache services defined in your cluster-side Coherence cache configuration descriptor. The reason being is that the Coherence*Extend clustered service uses a pool of threads to execute client requests concurrently; therefore, it cannot be guaranteed that the same thread will execute subsequent requests from the same Coherence*Extend client.
To specify the member-based locking strategy for a Partitioned or Replicated cache service, use the <lease-granularity> configuration element. For example:
<distributed-scheme>
<scheme-name>dist-default</scheme-name>
<lease-granularity>member</lease-granularity>
<backing-map-scheme>
<local-scheme/>
</backing-map-scheme>
<autostart>true</autostart>
</distributed-scheme>
Technical Overview
Clustering
Overview
Coherence is built on a fully clustered architecture. Since "clustered" is an overused term in the industry, it is worth stating exactly what it means to say that Coherence is clustered. Coherence is based on a peer-to-peer clustering protocol, using a conference room model, in which servers are capable of:
- Speaking to Everyone: When a party enters the conference room, it is able to speak to all other parties in a conference room.
- Listening: Each party present in the conference room can hear messages that are intended for everyone, as well as messages that are intended for that particular party. It is also possible that a message is not heard the first time, thus a message may need to be repeated until it is heard by its intended recipients.
- Discovery: Parties can only communicate by speaking and listening; there are no other senses. Using only these means, the parties must determine exactly who is in the conference room at any given time, and parties must detect when new parties enter the conference room.
- Working Groups and Private Conversations: Although a party can talk to everyone, once a party is introduced to the other parties in the conference room (i.e. once discovery has completed), the party can communicate directly to any set of parties, or directly to an individual party.
- Death Detection: Parties in the conference room must quickly detect when parties leave the conference room – or die.
Using the conference room model provides the following benefits:
- There is no configuration required to add members to a cluster. Subject to configurable security restrictions, any JVM running Coherence will automatically join the cluster and be able to access the caches and other services provided by the cluster. This includes J2EE application servers, Cache Servers, dedicated cache loader processes, or any other JVM that is running with the Coherence software. When a JVM joins the cluster, it is called a cluster node, or alternatively, a cluster member.
- Since all cluster members are known, it is possible to provide redundancy within the cluster, such that the death of any one JVM or server machine does not cause any data to be lost.
- Since the death or departure of a cluster member is automatically and quickly detected, failover occurs very rapidly, and more importantly, it occurs transparently, which means that the application does not have to do any extra work to handle failover.
- Since all cluster members are known, it is possible to load balance responsibilities across the cluster. Coherence does this automatically with its Distributed Cache Service, for example. Load balancing automatically occurs to respond to new members joining the cluster, or existing members leaving the cluster.
- Communication can be very well optimized, since some communication is multi-point in nature (e.g. messages for everyone), and some is between two members.
Two of the terms used here describe processing for failed servers:
- Failover: Failover refers to the ability of a server to assume the responsibilities of a failed server. For example, "When the server died, its processes failed over to the backup server."
- Failback: Failback is an extension to failover that allows a server to reclaim its responsibilities once it restarts. For example, "When the server came back up, the processes that it was running previously were failed back to it."
All of the Coherence clustered services, including cache services and grid services, provide automatic and transparent failover and failback. While these features are transparent to the application, it should be noted that the application can sign up for events to be notified of all comings and goings in the cluster.
Cache Topologies
Overview
Coherence supports many different cache topologies, but generally they fall into a few general categories. Because Coherence uses the TCMP clustering protocol, Coherence can supports each of these without compromise. However, there are inherent advantages of each topology, and trade-offs between them.
Topology as a concept refers to where the data physically resides and how it is accessed in a distributed environment. It is important to understand that, regardless of where the data physically resides, and which topology is being used, every cluster participant has the same logical view of the data, and uses the same exact API to access the data. Generally, this means that the topology can be tuned or even selected at deployment time.
- Peer-to-Peer: For most purposes, a peer-to-peer topology is the easiest to configure and offers very good performance. A peer-to-peer topology is one in which each server both provides and consumes the same clustered services. For example, in a cluster of J2EE application servers, if those servers are all managing and consuming data, and the data are shared via replicated and/or distributed caches, that would be a peer-to-peer topology. This topology spreads the load evenly over as many servers as possible, minimizing configuration details and offering the cache services the greatest overall amounts of memory and CPU resources.
- Centralized (Cache Servers): In order to centralize cache management to a cluster of servers, yet provide access to other servers, a centralized cache topology is used. This has several benefits, including the ability to reduce the resource requirements of the servers that utilize the cache by completely offloading cache management from those servers. Additionally, the cache servers (those that actually manage the cache data) can be hosted on machines explicitly configured for that purpose, and those machines do not require a J2EE application server or any other software other than a standard JVM. The cluster of cache servers (so designated by their storage-enabled attribute) provides a unified cache image, such that this model could almost be described as a cache client/cache server architecture, with the exception being that the server part of it is composed of a cluster of any number of actual servers. The obvious benefits of the clustered cache server architecture is the transparent failover and failback, and the ability to provision new servers to expand the caching resources, both in terms of processing power and in-memory cache sizes. This topology uses the Coherence Distributed Cache Service, which is a cluster-partitioned cache.
- Multi-Tier (n-tier): While the Centralized topology is a two-tier architecture, it is possible to extend this topology to three or more tiers, by having each tier be a client of the tier behind it, and coupling these tiers either over a clustered protocol (such as TCMP) or via JMS in cases where real-time cache coherency is not required and communication protocols are limited (such as production server tiers in which only certain protocols are permitted.)
- Hybrid (Near Caching): To accelerate cache accesses for Centralized and Multi-Tier topologies, Coherence supports a hybrid topology using a Near Cache technology. A Near Cache provides local cache access to recently- and/or often-used data, backed by a centralized or multi-tiered cache that is used to load-on-demand for local cache misses. Near Caches have configurable levels of cache coherency, from the most basic expiry-based caches and invalidation-based caches, up to advanced data-versioning caches that can provide guaranteed coherency. The result is a tunable balance between the preservation of local memory resources and the performance benefits of truly local caches.
The extent of the cluster and of its tiers is fully definable in the tangosol-coherence.xml configuration file. This includes the ability to lock down the set of servers that can access and manage the cache for security purposes. The selection of which topology to use is typically driven by the cache configuration file, which by default is named coherence-cache-config.xml; however, the topology can also be driven entirely by the Coherence programmatic API, if the developer so chooses.
Cluster Services Overview
Overview
Coherence functionality is based on the concept of cluster services. Each cluster node can participate in (which implies both the ability to provide and to consume) any number of named services. These named services may already exist, which is to say that they may already be running on one or more other cluster nodes, or a cluster node can register new named services. Each named service has a service name that uniquely identifies the service within the cluster, and a service type, which defines what the service can do. There are several service types that are supported by Coherence:
- Cluster Service: This service is automatically started when a cluster node needs to join the cluster; each cluster node always has exactly one service of this type running. This service is responsible for the detection of other cluster nodes, for detecting the failure (death) of a cluster node, and for registering the availability of other services in the cluster. In other words, the Cluster Service keeps track of the membership and services in the cluster.
- Distributed Cache Service: This is the distributed cache service, which allows cluster nodes to distribute (partition) data across the cluster so that each piece of data in the cache is managed (held) by only one cluster node. The Distributed Cache Service supports pessimistic locking. Additionally, to support failover without any data loss, the service can be configured so that each piece of data will be backed up by one or more other cluster nodes. Lastly, some cluster nodes can be configured to hold no data at all; this is useful, for example, to limit the Java heap size of an application server process, by setting the application server processes to not hold any distributed data, and by running additional cache server JVMs to provide the distributed cache storage.
- Invocation Service: This service provides clustered invocation and supports grid computing architectures. Using the Invocation Service, application code can invoke agents on any node in the cluster, or any group of nodes, or across the entire cluster. The agent invocations can be request/response, fire and forget, or an asynchronous user-definable model.
- Optimistic Cache Service: This is the optimistic-concurrency version of the Replicated Cache Service, which fully replicates all of its data to all cluster nodes, and employs an optimization similar to optimistic database locking in order to maintain coherency. Coherency refers to the fact that all servers will end up with the same "current" value, even if multiple updates occur at the same exact time from different servers. The Optimistic Cache Service does not support pessimistic locking, so in general it should only be used for caching "most recently known" values for read-only uses.
- Replicated Cache Service: This is the synchronized replicated cache service, which fully replicates all of its data to all cluster nodes that are running the service. Furthermore, it supports pessimistic locking so that data can be modified in a cluster without encountering the classic missing update problem.
Regarding resources, a clustered service typically uses one daemon thread, and optionally has a thread pool that can be configured to provide the service with additional processing bandwidth. For example, the invocation service and the distributed cache service both fully support thread pooling in order to accelerate database load operations, parallel distributed queries, and agent invocations.
It is important to note that these are only the basic clustered services, and not the full set of types of caches provided by Coherence. By combining clustered services with cache features such as backing maps and overflow maps, Coherence can provide an extremely flexible, configurable and powerful set of options for clustered applications. For example, the Near Cache functionality uses a Distributed Cache as one of its components.
Within a cache service, there exists any number of named caches. A named cache provides the standard JCache API, which is based on the Java collections API for key-value pairs, known as java.util.Map. The Map interface is the same API that is implemented by the Java Hashtable class, for example.
Replicated Cache Service
Overview
The first type of cache that Coherence supported was the replicated cache, and it was an instant success due to its ability to handle data replication, concurrency control and failover in a cluster, all while delivering in-memory data access speeds. A clustered replicated cache is exactly what it says it is: a cache that replicates its data to all cluster nodes.
There are several challenges to building a reliable replicated cache. The first is how to get it to scale and perform well. Updates to the cache have to be sent to all cluster nodes, and all cluster nodes have to end up with the same data, even if multiple updates to the same piece of data occur at the same time. Also, if a cluster node requests a lock, it should not have to get all cluster nodes to agree on the lock, otherwise it will scale extremely poorly; yet in the case of cluster node failure, all of the data and lock information must be kept safely. Coherence handles all of these scenarios transparently, and provides the most scalable and highly available replicated cache implementation available for Java applications.
The best part of a replicated cache is its access speed. Since the data is replicated to each cluster node, it is available for use without any waiting. This is referred to as "zero latency access," and is perfect for situations in which an application requires the highest possible speed in its data access. Each cluster node (JVM) accesses the data from its own memory:
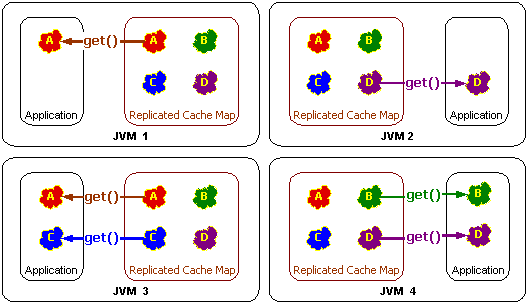
In contrast, updating a replicated cache requires pushing the new version of the data to all other cluster nodes:
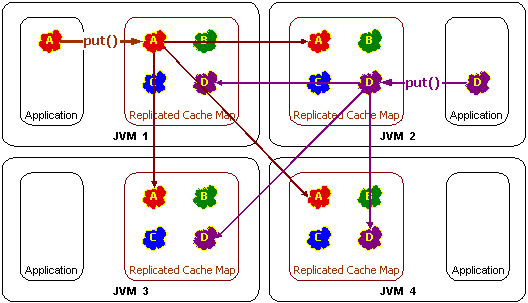
Coherence implements its replicated cache service in such a way that all read-only operations occur locally, all concurrency control operations involve at most one other cluster node, and only update operations require communicating with all other cluster nodes. The result is excellent scalable performance, and as with all of the Coherence services, the replicated cache service provides transparent and complete failover and failback.
The limitations of the replicated cache service should also be carefully considered. First, however much data is managed by the replicated cache service is on each and every cluster node that has joined the service. That means that memory utilization (the Java heap size) is increased for each cluster node, which can impact performance. Secondly, replicated caches with a high incidence of updates will not scale linearly as the cluster grows; in other words, the cluster will suffer diminishing returns as cluster nodes are added.
Partitioned Cache Service
Overview
To address the potential scalability limits of the replicated cache service, both in terms of memory and communication bottlenecks, Coherence has provided a distributed cache service since release 1.2. Many products have used the term distributed cache to describe their functionality, so it is worth clarifying exactly what is meant by that term in Coherence. Coherence defines a distributed cache as a collection of data that is distributed (or, partitioned) across any number of cluster nodes such that exactly one node in the cluster is responsible for each piece of data in the cache, and the responsibility is distributed (or, load-balanced) among the cluster nodes.
There are several key points to consider about a distributed cache:
- Partitioned: The data in a distributed cache is spread out over all the servers in such a way that no two servers are responsible for the same piece of cached data. This means that the size of the cache and the processing power associated with the management of the cache can grow linearly with the size of the cluster. Also, it means that operations against data in the cache can be accomplished with a "single hop," in other words, involving at most one other server.
- Load-Balanced: Since the data is spread out evenly over the servers, the responsibility for managing the data is automatically load-balanced across the cluster.
- Location Transparency: Although the data is spread out across cluster nodes, the exact same API is used to access the data, and the same behavior is provided by each of the API methods. This is called location transparency, which means that the developer does not have to code based on the topology of the cache, since the API and its behavior will be the same with a local JCache, a replicated cache, or a distributed cache.
- Failover: All Coherence services provide failover and failback without any data loss, and that includes the distributed cache service. The distributed cache service allows the number of backups to be configured; as long as the number of backups is one or higher, any cluster node can fail without the loss of data.
Access to the distributed cache will often need to go over the network to another cluster node. All other things equals, if there are n cluster nodes, (n - 1) / n operations will go over the network:
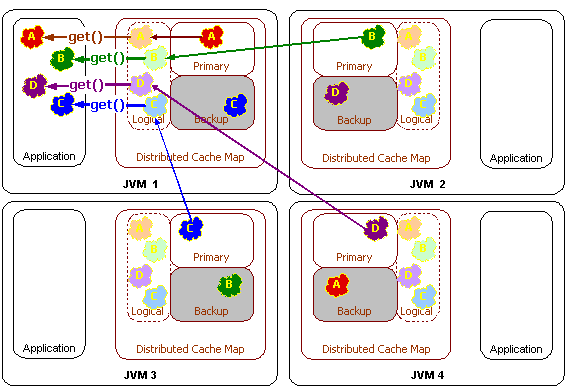
Since each piece of data is managed by only one cluster node, an access over the network is only a "single hop" operation. This type of access is extremely scalable, since it can utilize point-to-point communication and thus take optimal advantage of a switched network.
Similarly, a cache update operation can utilize the same single-hop point-to-point approach, which addresses one of the two known limitations of a replicated cache, the need to push cache updates to all cluster nodes:
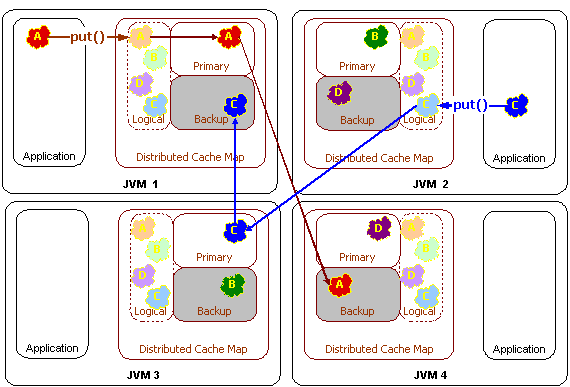
In figure 4, above, the data is being sent to a primary cluster node and a backup cluster node. This is for failover purposes, and corresponds to a backup count of one. (The default backup count setting is one.) If the cache data were not critical, which is to say that it could be re-loaded from disk, the backup count could be set to zero, which would allow some portion of the distributed cache data to be lost in the event of a cluster node failure. If the cache were extremely critical, a higher backup count, such as two, could be used. The backup count only affects the performance of cache modifications, such as those made by adding, changing or removing cache entries.
Modifications to the cache are not considered complete until all backups have acknowledged receipt of the modification. This means that there is a slight performance penalty for cache modifications when using the distributed cache backups; however it guarantees that if a cluster node were to unexpectedly fail, that data consistency is maintained and no data will be lost.
Failover of a distributed cache involves promoting backup data to be primary storage. When a cluster node fails, all remaining cluster nodes determine what data each holds in backup that the failed cluster node had primary responsible for when it died. Those data becomes the responsibility of whatever cluster node was the backup for the data:
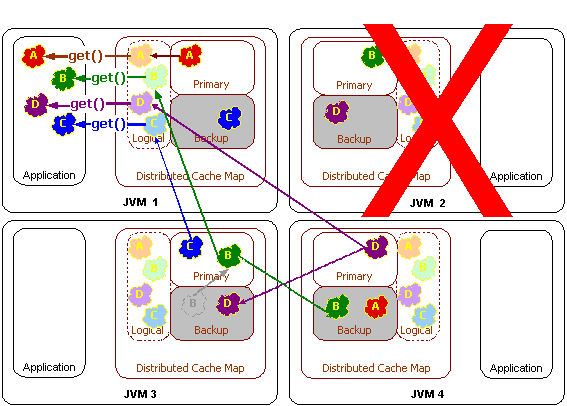
If there are multiple levels of backup, the first backup becomes responsible for the data; the second backup becomes the new first backup, and so on. Just as with the replicated cache service, lock information is also retained in the case of server failure, with the sole exception being that the locks for the failed cluster node are automatically released.
The distributed cache service also allows certain cluster nodes to be configured to store data, and others to be configured to not store data. The name of this setting is local storage enabled. Cluster nodes that are configured with the local storage enabled option will provide the cache storage and the backup storage for the distributed cache. Regardless of this setting, all cluster nodes will have the same exact view of the data, due to location transparency.
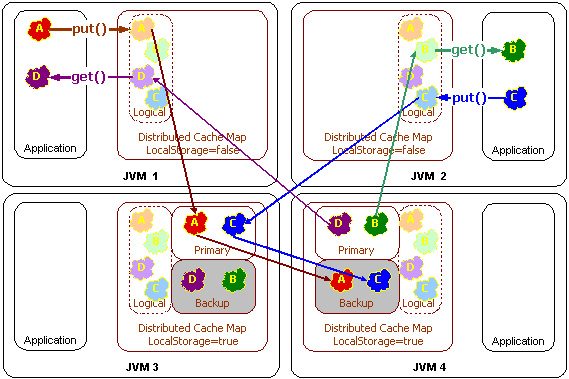
There are several benefits to the local storage enabled option:
- The Java heap size of the cluster nodes that have turned off local storage enabled will not be affected at all by the amount of data in the cache, because that data will be cached on other cluster nodes. This is particularly useful for application server processes running on older JVM versions with large Java heaps, because those processes often suffer from garbage collection pauses that grow exponentially with the size of the heap.
- Coherence allows each cluster node to run any supported version of the JVM. That means that cluster nodes with local storage enabled turned on could be running a newer JVM version that supports larger heap sizes, or Coherence's off-heap storage using the Java NIO features.
- The local storage enabled option allows some cluster nodes to be used just for storing the cache data; such cluster nodes are called Coherence cache servers. Cache servers are commonly used to scale up Coherence's distributed query functionality.
Local Storage
Overview
The Coherence architecture is modular, allowing almost any piece to be extended or even replaced with a custom implementation. One of the responsibilities of the Coherence system that is completely configurable, extendable and replaceable is local storage. Local storage refers to the data structures that actually store or cache the data that is managed by Coherence. For an object to provide local storage, it must support the same standard collections interface, java.util.Map. When a local storage implementation is used by Coherence to store replicated or distributed data, it is called a backing map, because Coherence is actually backed by that local storage implementation. The other common uses of local storage is in front of a distributed cache and as a backup behind the distributed cache.
Typically, Coherence uses one of the following local storage implementations:
- Safe HashMap: This is the default lossless implementation. A lossless implementation is one, like Java's Hashtable class, that is neither size-limited nor auto-expiring. In other words, it is an implementation that never evicts ("loses") cache items on its own. This particular HashMap implementation is optimized for extremely high thread-level concurrency. (For the default implementation, use class com.tangosol.util.SafeHashMap; when an implementation is required that provides cache events, use com.tangosol.util.ObservableHashMap. These implementations are thread-safe.)
- Local Cache: This is the default size-limiting and/or auto-expiring implementation. The local cache is covered in more detail below, but the primary points to remember about it are that it can limit the size of the cache, and it can automatically expire cache items after a certain period of time. (For the default implementation, use com.tangosol.net.cache.LocalCache; this implementation is thread safe and supports cache events, com.tangosol.net.CacheLoader, CacheStore and configurable/pluggable eviction policies.)
- Read/Write Backing Map: This is the default backing map implementation for caches that load from a database on a cache miss. It can be configured as a read-only cache (consumer model) or as either a write-through or a write-behind cache (for the consumer/producer model). The write-through and write-behind modes are intended only for use with the distributed cache service. If used with a near cache and the near cache must be kept in sync with the distributed cache, it is possible to combine the use of this backing map with a Seppuku-based near cache (for near cache invalidation purposes); however, given these requirements, it is suggested that the versioned implementation be used. (For the default implementation, use class com.tangosol.net.cache.ReadWriteBackingMap.)
- Versioned Backing Map: This is an optimized version of the read/write backing map that optimizes its handling of the data by utilizing a data versioning technique. For example, to invalidate near caches, it simply provides a version change notification, and to determine whether cached data needs to be written back to the database, it can compare the persistent (database) version information with the transient (cached) version information. The versioned implementation can provide very balanced performance in large scale clusters, both for read-intensive and write-intensive data. (For the default implementation, use class com.tangosol.net.cache.VersionedBackingMap; with this backing map, you can optionally use the com.tangosol.net.cache.VersionedNearCache as a near cache implementation.)
- Binary Map (Java NIO): This is a backing map implementation that can store its information in memory but outside of the Java heap, or even in memory-mapped files, which means that it does not affect the Java heap size and the related JVM garbage-collection performance that can be responsible for application pauses. This implementation is also available for distributed cache backups, which is particularly useful for read-mostly and read-only caches that require backup for high availability purposes, because it means that the backup does not affect the Java heap size yet it is immediately available in case of failover.
- Serialization Map: This is a backing map implementation that translates its data to a form that can be stored on disk, referred to as a serialized form. It requires a separate com.tangosol.io.BinaryStore object into which it stores the serialized form of the data; usually, this is the built-in LH disk store implementation, but the Serialization Map supports any custom implementation of BinaryStore. (For the default implementation of Serialization Map, use com.tangosol.net.cache.SerializationMap.)
- Serialization Cache: This is an extension of the SerializationMap that supports an LRU eviction policy. This can be used to limit the size of disk files, for example. (For the default implementation of Serialization Cache, use com.tangosol.net.cache.SerializationCache.)
- Overflow Map: An overflow map doesn't actually provide storage, but it deserves mention in this section because it can tie together two local storage implementations so that when the first one fills up, it will overflow into the second. (For the default implementation of OverflowMap, use com.tangosol.net.cache.OverflowMap.)
Local Cache
Overview
While it is not a clustered service, the Coherence local cache implementation is often used in combination with various Coherence clustered cache services. The Coherence local cache is just that: A cache that is local to (completely contained within) a particular cluster node. There are several attributes of the local cache that are particularly interesting:
- The local cache implements the same standard collections interface that the clustered caches implement, meaning that there is no programming difference between using a local or a clustered cache. Just like the clustered caches, the local cache is tracking to the JCache API, which itself is based on the same standard collections API that the local cache is based on.
- The local cache can be size-limited. This means that the local cache can restrict the number of entries that it caches, and automatically evict entries when the cache becomes full. Furthermore, both the sizing of entries and the eviction policies are customizable, for example allowing the cache to be size-limited based on the memory utilized by the cached entries. The default eviction policy uses a combination of Most Frequently Used (MFU) and Most Recently Used (MRU) information, scaled on a logarithmic curve, to determine what cache items to evict. This algorithm is the best general-purpose eviction algorithm because it works well for short duration and long duration caches, and it balances frequency versus recentness to avoid cache thrashing. The pure LRU and pure LFU algorithms are also supported, as well as the ability to plug in custom eviction policies.
- The local cache supports automatic expiration of cached entries, meaning that each cache entry can be assigned a time to live in the cache. Furthermore, the entire cache can be configured to flush itself on a periodic basis or at a preset time.
- The local cache is thread safe and highly concurrent, allowing many threads to simultaneously access and update entries in the local cache.
- The local cache supports cache notifications. These notifications are provided for additions (entries that are put by the client, or automatically loaded into the cache), modifications (entries that are put by the client, or automatically reloaded), and deletions (entries that are removed by the client, or automatically expired, flushed, or evicted.) These are the same cache events supported by the clustered caches.
- The local cache maintains hit and miss statistics. These runtime statistics can be used to accurately project the effectiveness of the cache, and adjust its size-limiting and auto-expiring settings accordingly while the cache is running.
The local cache is important to the clustered cache services for several reasons, including as part of Coherence's near cache technology, and with the modular backing map architecture.
Best Practices
Overview
Coherence supports several cache topologies, but these options cover the vast majority of use cases. All are fully coherent and support cluster-wide locking and transactions:
- Replicated - Each machine contains a full copy of the dataset. Read access is instantaneous.
- Partitioned (Distributed) - Each machine contains a unique partition of the dataset. Adding machines to the cluster will increase the capacity of the cache. Both read and write access involve network transfer and serialization/deserialization.
- Near - Each machine contains a small local cache which is synchronized with a larger Partitioned cache, optimizing read performance. There is some overhead involved with synchronizing the caches.
Data Access Patterns
Data access distribution (hot spots)
When caching a large dataset, typically a small portion of that dataset will be responsible for most data accesses. For example, in a 1000 object dataset, 80% of operations may be be against a 100 object subset. The remaining 20% of operations may be against the other 900 objects. Obviously the most effective return on investment will be gained by caching the 100 most active objects; caching the remaining 900 objects will provide 25% more effective caching while requiring a 900% increase in resources.
On the other hand, if every object is accessed equally often (for example in sequential scans of the dataset), then caching will require more resources for the same level of effectiveness. In this case, achieving 80% cache effectiveness would require caching 80% of the dataset versus 10%. (Note that sequential scans of partially cached data sets will generally defeat MRU, LFU and MRU-LFU eviction policies). In practice, almost all non-synthetic (benchmark) data access patterns are uneven, and will respond well to caching subsets of data.
In cases where a subset of data is active, and a smaller subset is particularly active, Near caching can be very beneficial when used with the "all" invalidation strategy (this is effectively a two-tier extension of the above rules).
Cluster-node affinity
Coherence's Near cache technology will transparently take advantage of cluster-node affinity, especially when used with the "present" invalidation strategy. This topology is particularly useful when used in conjunction with a sticky load-balancer. Note that the "present" invalidation strategy results in higher overhead (as opposed to "all") when the front portion of the cache is "thrashed" (very short lifespan of cache entries); this is due to the higher overhead of adding/removing key-level event listeners. In general, a cache should be tuned to avoid thrashing and so this is usually not an issue.
Read-write ratio and data sizes
Generally speaking, the following cache topologies are best for the following use cases:
Replicated cache - small amounts of read-heavy data (e.g. metadata)
Partitioned cache - large amounts of read-write data (e.g. large data caches)
Near cache - similar to Partitioned, but has further benefits from read-heavy tiered access patterns (e.g. large data caches with hotspots) and "sticky" data access (e.g. sticky HTTP session data). Depending on the synchronization method (expiry, asynchronous, synchronous), the worst case performance may range from similar to a Partitioned cache to considerably worse.
Interleaving
Interleaving refers to the number of cache reads between each cache write. The Partitioned cache is not affected by interleaving (as it is designed for 1:1 interleaving). The Replicated and Near caches by contrast are optimized for read-heavy caching, and prefer a read-heavy interleave (e.g. 10 reads between every write). This is because they both locally cache data for subsequent read access. Writes to the cache will force these locally cached items to be refreshed, a comparatively expensive process (relative to the near-zero cost of fetching an object off the local memory heap). Note that with the Near cache technology, worst-case performance is still similar to the Partitioned cache; the loss of performance is relative to best-case scenarios.
Note that interleaving is related to read-write ratios, but only indirectly. For example, a Near cache with a 1:1 read-write ratio may be extremely fast (all writes followed by all reads) or much slower (1:1 interleave, write-read-write-read...).
Heap Size Considerations
Using several small heaps
For large datasets, Partitioned or Near caches are recommended. As the scalability of the Partitioned cache is linear for both reading and writing, varying the number of Coherence JVMs will not significantly affect cache performance. On the other hand, JVM memory management routines show worse than linear scalability. For example, increasing JVM heap size from 512MB to 2GB may substantially increase garbage collection (GC) overhead and pauses.
For this reason, it is common to use multiple Coherence instances per physical machine. As a general rule of thumb, current JVM technology works well up to 512MB heap sizes. Thererfore, using a number of 512MB Coherence instances will provide optimal performance without a great deal of JVM configuration or tuning.
For performance-sensitive applications, experimentation may provide better tuning. When considering heap size, it is important to find the right balance. The lower bound is determined by per-JVM overhead (and also, manageability of a potentially large number of JVMs). For example, if there is a fixed overhead of 100MB for infrastructure software (e.g. JMX agents, connection pools, internal JVM structures), then the use of JVMs with 256MB heap sizes will result in close to 40% overhead for non-cache data. The upper bound on JVM heap size is governed by memory management overhead, specifically the maximum duration of GC pauses and the percentage of CPU allocated to GC (and other memory management tasks).
For Java 5 VMs running on commodity systems, the following rules generally hold true (with no JVM configuration tuning). With a heap size of 512MB, GC pauses will not exceed one second. With a heap size of 1GB, GC pauses are limited to roughly 2-3 seconds. With a heap size of 2GB, GC pauses are limited to roughly 5-6 seconds. It is important to note that GC tuning will have an enormous impact on GC throughput and pauses. In all configurations, initial (-Xms) and maximum (-Xmx) heap sizes should be identical. There are many variations that can substantially impact these numbers, including machine architecture, CPU count, CPU speed, JVM configuration, object count (object size), object access profile (short-lived versus long-lived objects).
For allocation-intensive code, GC can theoretically consume close to 100% of CPU usage. For both cache server and client configurations, most CPU resources will typically be consumed by application-specific code. It may be worthwhile to view verbose garbage collection statistics (e.g. -verbosegc). Use the profiling features of the JVM to get profiling information including CPU usage by GC (e.g. -Xprof).
Moving the cache out of the application heap
Using dedicated Coherence cache server instances for Partitioned cache storage will minimize the heap size of application JVMs as the data is no longer stored locally. As most Partitioned cache access is remote (with only 1/N of data being held locally), using dedicated cache servers does not generally impose much additional overhead. Near cache technology may still be used, and it will generally have a minimal impact on heap size (as it is caching an even smaller subset of the Partitioned cache). Many applications are able to dramatically reduce heap sizes, resulting in better responsiveness.
Local partition storage may be enabled (for cache servers) or disabled (for application server clients) with the tangosol.coherence.distributed.localstorage Java property (e.g. -Dtangosol.coherence.distributed.localstorage=false).
It may also be disabled by modifying the <local-storage> setting in the tangosol-coherence.xml (or tangosol-coherence-override.xml) file as follows:
<coherence>
<services>
<service>
<service-type>DistributedCache</service-type>
<service-component>DistributedCache</service-component>
<init-params>
<init-param>
<param-name>local-storage</param-name>
<param-value system-property="tangosol.coherence.distributed.localstorage">false<param-value>
</init-param>
</init-params>
</service>
</services>
</coherence>
At least one storage-enabled JVM must be started before any storage-disabled clients access the cache.
Network Protocols
Overview
Coherence uses TCMP, a clustered IP-based protocol, for server discovery, cluster management, service provisioning and data transmission. To ensure true scalability, the TCMP protocol is completely asychronous, meaning that communication is never blocking, even when many threads on a server are communicating at the same time. Further, the asynchronous nature also means that the latency of the network (for example, on a routed network between two different sites) does not affect cluster throughput, although it will affect the speed of certain operations.
TCMP uses a combination of UDP/IP multicast, UDP/IP unicast and TCP/IP as follows:
- Multicast
- Cluster discovery: Is there a cluster already running that a new member can join?
- Cluster heartbeat: The most senior member in the cluster issues a periodic heartbeat via multi-cast; the rate is configurable and defaults to once per second.
- Message delivery: Messages that need to be delivered to multiple cluster members will often be sent via multicast, instead of unicasting the message one time to each member.
- Unicast
- Direct member-to-member ("point-to-point") communication, including messages, asynchronous acknowledgements (ACKs), asynchronous negative acknowledgements (NACKs) and peer-to-peer heartbeats.
- Under some circumstances, a message may be sent via unicast even if the message is directed to multiple members. This is done to shape traffic flow and to reduce CPU load in very large clusters.
- TCP
- An optional TCP/IP ring is used as an additional "death detection" mechanism, to differentiate between actual node failure and an unresponsive node, such as when a JVM conducts a full GC.
- TCP/IP is not used as a data transfer mechanism due to the intrinsic overhead of the protocol and its synchronous nature.
Protocol Reliability
The TCMP protocol provides fully reliable, in-order delivery of all messages. Since the underlying UDP/IP protocol does not provide for either reliable or in-order delivery, TCMP utilizes a queued, fully asynchronous ACK- and NACK-based mechanism for reliable delivery of messages, with unique integral identity for guaranteed ordering of messages.
Protocol Resource Utilization
The TCMP protocol requires only two UDP/IP sockets (one multicast, one unicast) and four threads per JVM, regardless of the cluster size. This is a key element in the scalability of Coherence, in that regardless of the number of servers, each node in the cluster can still communicate either point-to-point or with collections of cluster members without requiring additional network connections.
The optional TCP/IP ring will use a few additional TCP/IP sockets, and a total of one additional thread.
Protocol Tunability
The TCMP protocol is very tunable to take advantage of specific network topologies, or to add tolerance for low-bandwidth and/or high-latency segments in a geographically distributed cluster. Coherence comes with a pre-set configuration, some of which is dynamically self-configuring at runtime, but all attributes of TCMP can be overridden and locked down for deployment purposes.
Multicast Scope
Multicast UDP/IP packets are configured with a time-to-live value (TTL) that designates how far those packets can travel on a network. The TTL is expressed in terms of how many "hops" a packet will survive; each network interface, router and managed switch is considered one hop. Coherence provides a TTL setting to limit the scope of multicast messages.
Disabling Multicast
In most WAN environments, and some LAN environments, multicast traffic is disallowed. To prevent Coherence from using multicast, configure a list of well-known-addresses (WKA). This will disable multicast discovery, and also disable multicast for all data transfer. Coherence is designed to use point-to-point communication as much as possible, so most application profiles will not see a substantial performance impact.
Patterns
Bulk Loading and Processing with Coherence
Bulk Writing to a Cache
A common scenario when using Coherence is to pre populate a cache before the application makes use of the cache. A simple way to do this would be:
public static void bulkLoad(NamedCache cache, Connection conn)
{
Statement s;
ResultSet rs;
try
{
s = conn.createStatement();
rs = s.executeQuery("select key, value from table");
while (rs.next())
{
Integer key = new Integer(rs.getInt(1));
String value = rs.getString(2);
cache.put(key, value);
}
...
}
catch (SQLException e)
{...}
}
This works, but each call to put may result in network traffic, especially for partitioned and replicated caches. Additionally, each call to put will return the object it just replaced in the cache (per the java.util.Map interface) which will add more unnecessary overhead. This can be made much more efficient by using putAll instead:
public static void bulkLoad(NamedCache cache, Connection conn)
{
Statement s;
ResultSet rs;
Map buffer = new HashMap();
try
{
int count = 0;
s = conn.createStatement();
rs = s.executeQuery("select key, value from table");
while (rs.next())
{
Integer key = new Integer(rs.getInt(1));
String value = rs.getString(2);
buffer.put(key, value);
if ((count++ % 1000) == 0)
{
cache.putAll(buffer);
buffer.clear();
}
}
if (!buffer.isEmpty())
{
cache.putAll(buffer);
}
...
}
catch (SQLException e)
{...}
}
Efficient processing of filter results
Coherence provides the ability to query caches based on criteria via the filter API. Here is an example (given entries with integers as keys and strings as values):
NamedCache c = CacheFactory.getCache("test");
Filter query = new LikeFilter(IdentityExtractor.INSTANCE, "c%", '\\', true);
Set results = c.entrySet(query);
for (Iterator i = results.iterator(); i.hasNext();)
{
Map.Entry e = (Map.Entry) i.next();
out("key: "+e.getKey() + ", value: "+e.getValue());
}
This example works for small data sets, but it may encounter problems if the data set is too large, such as running out of heap space. Here is a pattern to process query results in batches to avoid this problem:
public static void performQuery()
{
NamedCache c = CacheFactory.getCache("test");
Filter query = new LikeFilter(IdentityExtractor.INSTANCE, "c%", '\\', true);
Set keys = c.keySet(query);
final int BUFFER_SIZE = 100;
Set buffer = new HashSet(BUFFER_SIZE);
for (Iterator i = keys.iterator(); i.hasNext();)
{
buffer.add(i.next());
if (buffer.size() >= BUFFER_SIZE)
{
Map entries = c.getAll(buffer);
process(entries);
buffer.clear();
}
}
if (!buffer.isEmpty())
{
process(c.getAll(buffer));
}
}
public static void process(Map map)
{
for (Iterator ie = map.entrySet().iterator(); ie.hasNext();)
{
Map.Entry e = (Map.Entry) ie.next();
out("key: "+e.getKey() + ", value: "+e.getValue());
}
}
In this example, all keys for entries that match the filter are returned, but only BUFFER_SIZE (in this case, 100) entries are retrieved from the cache at a time.
Note that LimitFilter can be used to process results in parts, similar to the example above. However LimitFilter is meant for scenarios where the results will be paged, such as in a user interface. It is not an efficient means to process all data in a query result.
A Complete Example
Here is an example program that demonstrates the concepts described above. Note this can be downloaded from the forums.
package com.tangosol.examples;
import com.tangosol.net.CacheFactory;
import com.tangosol.net.NamedCache;
import com.tangosol.net.cache.NearCache;
import com.tangosol.util.Base;
import com.tangosol.util.Filter;
import com.tangosol.util.filter.LikeFilter;
import java.io.Serializable;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Random;
import java.util.Set;
import java.util.HashSet;
/**
* This sample application demonstrates the following:
* <ul>
* <li>
* <b>Obtaining a back cache from a near cache for populating a cache.</b>
* Since the near cache holds a limited subset of the data in a cache it is
* more efficient to bulk load data directly into the back cache instead of
* the near cache.
* </li>
* <li>
* <b>Populating a cache in bulk using <tt>putAll</tt>.</b>
* This is more efficient than <tt>put</tt> for a large amount of entries.
* </li>
* <li>
* <b>Executing a filter against a cache and processing the results in bulk.</b>
* This sample issues a query against the cache using a filter. The result is
* a set of keys that represent the query results. Instead of iterating
* through the keys and loading each item individually with a <tt>get</tt>,
* this sample loads entries from the cache in bulk using <tt>getAll</tt> which
* is more efficient.
* </li>
*
* @author cp, pperalta 2007.02.21
*/
public class PagedQuery
extends Base
{
/**
* Command line execution entry point.
*/
public static void main(String[] asArg)
{
NamedCache cacheContacts = CacheFactory.getCache("contacts",
Contact.class.getClassLoader());
populateCache(cacheContacts);
executeFilter(cacheContacts);
CacheFactory.shutdown();
}
/**
* Populate the cache with test data. This example shows how to populate
* the cache a chunk at a time using {@link NamedCache#putAll} which is more
* efficient than {@link NamedCache#put}.
*
* @param cacheDirect the cache to populate. Note that this should <b>not</b>
* be a near cache since that will thrash the cache
* if the load size exceeds the near cache max size.
*/
public static void populateCache(NamedCache cacheDirect)
{
if (cacheDirect.isEmpty())
{
Map mapBuffer = new HashMap();
for (int i = 0; i < 100000; ++i)
{
Contact contact = new Contact();
contact.setName(getRandomName() + ' ' + getRandomName());
contact.setPhone(getRandomPhone());
mapBuffer.put(new Integer(i), contact);
if ((i % 1000) == 0)
{
out("Adding "+mapBuffer.size()+" entries to cache");
cacheDirect.putAll(mapBuffer);
mapBuffer.clear();
}
}
if (!mapBuffer.isEmpty())
{
cacheDirect.putAll(mapBuffer);
}
}
}
/**
* Creates a random name.
*
* @return a random string between 4 to 11 chars long
*/
public static String getRandomName()
{
Random rnd = getRandom();
int cch = 4 + rnd.nextInt(7);
char[] ach = new char[cch];
ach[0] = (char) ('A' + rnd.nextInt(26));
for (int of = 1; of < cch; ++of)
{
ach[of] = (char) ('a' + rnd.nextInt(26));
}
return new String(ach);
}
/**
* Creates a random phone number
*
* @return a random string of integers 10 chars long
*/
public static String getRandomPhone()
{
Random rnd = getRandom();
return "("
+ toDecString(100 + rnd.nextInt(900), 3)
+ ") "
+ toDecString(100 + rnd.nextInt(900), 3)
+ "-"
+ toDecString(10000, 4);
}
/**
* Query the cache and process the results in batches. This example
* shows how to load a chunk at a time using {@link NamedCache#getAll}
* which is more efficient than {@link NamedCache#get}.
*
* @param cacheDirect the cache to issue the query against
*/
private static void executeFilter(NamedCache cacheDirect)
{
Filter query = new LikeFilter("getName", "C%");
final int CHUNK_COUNT = 100;
Set setKeys = cacheDirect.keySet(query);
Set setBuffer = new HashSet();
for (Iterator iter = setKeys.iterator(); iter.hasNext(); )
{
setBuffer.add(iter.next());
if (setBuffer.size() >= CHUNK_COUNT)
{
processContacts(cacheDirect.getAll(setBuffer));
setBuffer.clear();
}
}
if (!setBuffer.isEmpty())
{
processContacts(cacheDirect.getAll(setBuffer));
}
}
/**
* Process the map of contacts. In a real application some sort of
* processing for each map entry would occur. In this example each
* entry is logged to output.
*
* @param map the map of contacts to be processed
*/
public static void processContacts(Map map)
{
out("processing chunk of " + map.size() + " contacts:");
for (Iterator iter = map.entrySet().iterator(); iter.hasNext(); )
{
Map.Entry entry = (Map.Entry) iter.next();
out(" [" + entry.getKey() + "]=" + entry.getValue());
}
}
/**
* Sample object used to populate cache
*/
public static class Contact
extends Base
implements Serializable
{
public Contact() {}
public String getName()
{
return m_sName;
}
public void setName(String sName)
{
m_sName = sName;
}
public String getPhone()
{
return m_sPhone;
}
public void setPhone(String sPhone)
{
m_sPhone = sPhone;
}
public String toString()
{
return "Contact{"
+ "Name=" + getName()
+ ", Phone=" + getPhone()
+ "}";
}
public boolean equals(Object o)
{
if (o instanceof Contact)
{
Contact that = (Contact) o;
return equals(this.getName(), that.getName())
&& equals(this.getPhone(), that.getPhone());
}
return false;
}
public int hashCode()
{
int result;
result = (m_sName != null ? m_sName.hashCode() : 0);
result = 31 * result + (m_sPhone != null ? m_sPhone.hashCode() : 0);
return result;
}
private String m_sName;
private String m_sPhone;
}
}
Here are the steps to running the example:
- Save this file as com/tangosol/examples/PagedQuery.java
- Point the classpath to the Coherence libraries and the current directory
- Compile and run the example
$ export COHERENCE_HOME=[**Coherence install directory**]
$ export CLASSPATH=$COHERENCE_HOME/lib/tangosol.jar:$COHERENCE_HOME/lib/coherence.jar:.
$ javac com/tangosol/examples/PagedQuery.java
$ java com.tangosol.examples.PagedQuery
2007-05-23 12:19:44.156 Oracle Coherence 3.3/387 (thread=main, member=n/a): Loaded operational configuration from
resource "jar:file:/C:/coherence/lib/coherence.jar!/tangosol-coherence.xml"
2007-05-23 12:19:44.171 Oracle Coherence 3.3/387 (thread=main, member=n/a): Loaded operational overrides from
resource "jar:file:/C:/coherence/lib/coherence.jar!/tangosol-coherence-override-dev.xml"
2007-05-23 12:19:44.171 Oracle Coherence 3.3/387 (thread=main, member=n/a): Optional configuration override
"/tangosol-coherence-override.xml" is not specified
Oracle Coherence Version 3.3/387
Grid Edition: Development mode
Copyright (c) 2000-2007 Oracle. All rights reserved.
2007-05-23 12:19:44.812 Oracle Coherence GE 3.3/387 (thread=Cluster, member=n/a): Service Cluster joined the cluster
with senior service member n/a
2007-05-23 12:19:48.062 Oracle Coherence GE 3.3/387 (thread=Cluster, member=n/a): Created a new cluster with
Member(Id=1, Timestamp=2007-05-23 12:19:44.609, Address=192.168.0.204:8088, MachineId=26828, Edition=Grid Edition,
Mode=Development, CpuCount=2, SocketCount=1) UID=0xC0A800CC00000112B9BC9B6168CC1F98
Adding 1024 entries to cache
Adding 1024 entries to cache
...repeated many times...
Adding 1024 entries to cache
Adding 1024 entries to cache
Adding 1024 entries to cache
processing chunk of 100 contacts:
[25827]=Contact{Name=Cgkyleass Kmknztk, Phone=(285) 452-0000}
[4847]=Contact{Name=Cyedlujlc Ruexrtgla, Phone=(255) 296-0000}
...repeated many times
[33516]=Contact{Name=Cjfwlxa Wsfhrj, Phone=(683) 968-0000}
[71832]=Contact{Name=Clfsyk Dwncpr, Phone=(551) 957-0000}
processing chunk of 100 contacts:
[38789]=Contact{Name=Cezmcxaokf Kwztt, Phone=(725) 575-0000}
[87654]=Contact{Name=Cuxcwtkl Tqxmw, Phone=(244) 521-0000}
...repeated many times
[96164]=Contact{Name=Cfpmbvq Qaxty, Phone=(596) 381-0000}
[29502]=Contact{Name=Cofcdfgzp Nczpdg, Phone=(563) 983-0000}
...
processing chunk of 80 contacts:
[49179]=Contact{Name=Czbjokh Nrinuphmsv, Phone=(140) 353-0000}
[84463]=Contact{Name=Cyidbd Rnria, Phone=(571) 681-0000}
...
[2530]=Contact{Name=Ciazkpbos Awndvrvcd, Phone=(676) 700-0000}
[9371]=Contact{Name=Cpqo Rmdw, Phone=(977) 729-0000}
Production Planning and Troubleshooting
Production Checklist
Overview
| Warning
Deploying Coherence in a production environment is very different from using Coherence in a development environment.
Development environments do not reflect the challenges of a production environment. |
Coherence tends to be so simple to use in development that developers do not take the necessary planning steps and precautions when moving an application using Coherence into production. This article is intended to accomplish the following:
- Create a healthy appreciation for the complexities of deploying production software, particularly large-scale infrastructure software and enterprise applications;
- Enumerate areas that require planning when deploying Coherence;
- Define why production awareness should exist for each of those areas;
- Suggest or require specific approaches and solutions for each of those areas; and
- Provide a check-list to minimize risk when deploying to production.
Deployment recommendations are available for:
Network

|
During development, a Coherence-enabled application on a developer's local machine can accidentally form a cluster with the application running on other developers' machines.
Developers often use and test Coherence locally on their workstations. There are several ways in which they may accomplish this, including: By setting the multicast TTL to zero, by disconnecting from the network (and using the "loopback" interface), or by each developer using a different multi-cast address and port from all other developers. If one of these approaches is not used, then multiple developers on the same network will find that Coherence has clustered across different developers' locally running instances of the application; in fact, this happens relatively often and causes confusion when it is not understood by the developers.
Setting the TTL to zero on the command line is very simple: Add the following to the JVM startup parameters:
-Dtangosol.coherence.ttl=0
Starting with Coherence version 3.2, setting the TTL to zero for all developers is also very simple. Edit the tangosol-coherence-override-dev.xml in the coherence.jar file, changing the TTL setting as follows:
<time-to-live system-property="tangosol.coherence.ttl">0</time-to-live>
On some UNIX OSs, including some versions of Linux and Mac OS X, setting the TTL to zero may not be enough to isolate a cluster to a single machine. To be safe, assign a different cluster name for each developer, for example using the developer's email address as the cluster name. If the cluster communication does go across the network to other developer machines, then the different cluster name will cause an error on the node that is attempting to start up.
To ensure that the clusters are completely isolated, select a different multicast IP address and port for each developer. In some organizations, a simple approach is to use the developer's phone extension number as part of the multicast address and as the port number (or some part of it). For information on configuring the multicast IP address and port, see the section on multicast-listener configuration. |
|
During development, clustered functionality is often not being tested.
After the POC or prototype stage is complete, and until load testing begins, it is not out of the ordinary for the application to be developed and tested by engineers in a non-clustered form. This is dangerous, as testing primarily in the non-clustered configuration can hide problems with the application architecture and implementation that will show up later in staging – or even production.
Make sure that the application is being tested in a clustered configuration as development proceeds. There are several ways for clustered testing to be a natural part of the development process; for example:
- Developers can test with a locally clustered configuration (at least two instances running on their own machine). This works well with the TTL=0 setting, since clustering on a single machine works with the TTL=0 setting.
- Unit and regression tests can be introduced that run in a test environment that is clustered. This may help automate certain types of clustered testing that an individual developer would not always remember (or have the time) to do.
|

|
 What is the type and speed of the production network? What is the type and speed of the production network?
Most production networks are based on gigabit Ethernet, with a few still built on slower 100Mb Ethernet or faster ten-gigabit Ethernet. It is important to understand the topology of the production network, and what the full set of devices that will connect all of the servers that will be running Coherence. For example, if there are ten different switches being used to connect the servers, are they all the same type (make and model) of switch? Are they all the same speed? Do the servers support the network speeds that are available?
In general, all servers should share a reliable, fully switched network – this generally implies sharing a single switch (ideally, two parallel switches and two network cards per server for availability). There are two primary reasons for this. The first is that using more than one switch almost always results in a reduction in effective network capacity. The second is that multi-switch environments are more likely to have network "partitioning" events where a partial network failure will result in two or more disconnected sets of servers. While partitioning events are rare, Coherence cache servers ideally should share a common switch.
To demonstrate the impact of multiple switches on bandwidth, consider a number of servers plugged into a single switch. As additional servers are added, each server receives dedicated bandwidth from the switch backplane. For example, on a fully switched gigabit backplane, each server receives a gigabit of inbound bandwidth and a gigabit of outbound bandwidth for a total of 2Gbps "full duplex" bandwidth. Four servers would have an aggregate of 8Gbps bandwidth. Eight servers would have an aggregate of 16Gbps. And so on up to the limit of the switch (in practice, usually in the range of 160-192Gbps for a gigabit switch). However, consider the case of two switches connected by a 4Gbps (8Gbps full duplex) link. In this case, as servers are added to each switch, they will have full "mesh" bandwidth up to a limit of four servers on each switch (e.g all four servers on one switch can communicate at full speed with the four servers on the other switch). However, adding additional servers will potentially create a bottleneck on the inter-switch link. For example, if five servers on one switch send data to five servers on the other switch at 1Gbps per server, then the combined 5Gbps will be restricted by the 4Gbps link. Note that the actual limit may be much higher depending on the traffic-per-server and also the portion of traffic that actually needs to move across the link. Also note that other factors such as network protocol overhead and uneven traffic patterns may make the usable limit much lower from an application perspective.
Avoid mixing and matching network speeds: Make sure that all servers can and do connect to the network at the same speed, and that all of the switches and routers between those servers are running at that same speed or faster.
 Oracle strongly suggests GigE or faster: Gigabit Ethernet is supported by most servers built since 2004, and Gigabit switches are economical, available and widely deployed. Oracle strongly suggests GigE or faster: Gigabit Ethernet is supported by most servers built since 2004, and Gigabit switches are economical, available and widely deployed.
Before deploying an application, you must run the Datagram Test to test the actual network speed and determine its capability for pushing large amounts of data. Furthermore, the Datagram test must be run with an increasing ratio of publishers to consumers, since a network that appears fine with a single publisher and a single consumer may completely fall apart as the number of publishers increases, such as occurs with the default configuration of Cisco 6500 series switches. |
|
Will the production deployment use multicast?
The term "multicast" refers to the ability to send a packet of information from one server and to have that packet delivered in parallel by the network to many servers. Coherence supports both multicast and multicast-free clustering. Oracle suggests the use of multicast when possible because it is an efficient option for many servers to communicate. However, there are several common reasons why multicast cannot be used:
- Some organizations disallow the use of multicast.
- Multicast cannot operate over certain types of network equipment; for example, many WAN routers disallow or do not support multicast traffic.
- Multicast is occasionally unavailable for technical reasons; for example, some switches do not support multicast traffic.
First determine if multicast will be used. In other words, determine if the desired deployment configuration is to use multicast.
Before deploying an application that will use multicast, you must run the Multicast Test to verify that multicast is working and to determine the correct (the minimum) TTL value for the production environment.
Applications that cannot use multicast for deployment must use the WKA configuration. For more information, see the Network Protocols documentation. |
|
Are your network devices configured optimally?
If the above datagram and/or multicast tests have failed or returned poor results, it is possible that there are configuration problems with the network devices in use. Even if the tests passed without incident and the results were perfect, it is still possible that there are lurking issues with the configuration of the network devices.
Review the suggestions in the Network Infrastructure Settings section of the Performance Tuning documentation. |
See also:
Hardware
|
During development, developers can form unrealistic performance expectations.
Most developers have relatively fast workstations. Combined with test cases that are typically non-clustered and tend to represent single-user access (i.e. only the developer), the application may seem extraordinarily responsive.
Include as a requirement that realistic load tests be built that can be run with simulated concurrent user load.
Test routinely in a clustered configuration with simulated concurrent user load. |
|
During development, developer productivity can be adversely affected by inadequate hardware resources, and certain types of quality can also be affected negatively.
Coherence is compatible with all common workstation hardware. Most developers use PC or Apple hardware, including notebooks, desktops and workstations.
Developer systems should have a significant amount of RAM to run a modern IDE, debugger, application server, database and at least two cluster instances. Memory utilization varies widely, but to ensure productivity, the suggested minimum memory configuration for developer systems is 2GB. Desktop systems and workstations can often be configured with 4GB for minimal additional cost.
Developer systems should have two CPU cores or more. Although this will have the likely side-effect of making developers happier, the actual purpose is to increase the quality of code related to multi-threading, since many bugs related to concurrent execution of multiple threads will only show up on multi-CPU systems (systems that contain multiple processor sockets and/or CPU cores). |
|
What are the supported and suggested server hardware platforms for deploying Coherence on?
The short answer is that Oracle works to support the hardware that the customer has standardized on or otherwise selected for production deployment.
- Oracle has customers running on virtually all major server hardware platforms. The majority of customers use "commodity x86" servers, with a significant number deploying Sun Sparc (including Niagra) and IBM Power servers.
- Oracle continually tests Coherence on "commodity x86" servers, both Intel and AMD.
- Intel, Apple and IBM provide hardware, tuning assistance and testing support to Oracle.
- Oracle conducts internal Coherence certification on all IBM server platforms at least once a year.
- Oracle and Azul test Coherence regularly on Azul appliances, including the newly-announced 48-core "Vega 2" chip.
If the server hardware purchase is still in the future, the following are suggested for Coherence (as of December 2006):
The most cost-effective server hardware platform is "commodity x86", either Intel or AMD, with one to two processor sockets and two to four CPU cores per processor socket. If selecting an AMD Opteron system, it is strongly recommended that it be a two processor socket system, since memory capacity is usually halved in a single socket system. Intel "Woodcrest" and "Clovertown" Xeons are strongly recommended over the previous Intel Xeon CPUs due to significantly improved 64-bit support, much lower power consumption, much lower heat emission and far better performance. These new Xeons are currently the fastest commodity x86 CPUs, and can support a large memory capacity per server regardless of the processor socket count by using fully bufferred memory called "FB-DIMMs".
It is strongly recommended that servers be configured with a minimum of 4GB of RAM. For applications that plan to store massive amounts of data in memory – tens or hundreds of gigabytes, or more – it is recommended to evaluate the cost-effectiveness of 16GB or even 32GB of RAM per server. As of December, 2006, commodity x86 server RAM is readily available in a density of 2GB per DIMM, with higher densities available from only a few vendors and carrying a large price premium; this means that a server with 8 memory slots will only support 16GB in a cost-effective manner. Also note that a server with a very large amount of RAM will likely need to run more Coherence nodes (JVMs) per server in order to utilize that much memory, so having a larger number of CPU cores will help. Applications that are "data heavy" will require a higher ratio of RAM to CPU, while applications that are "processing heavy" will require a lower ratio. For example, it may be sufficient to have two dual-core Xeon CPUs in a 32GB server running 15 Coherence "Cache Server" nodes performing mostly identity-based operations (cache accesses and updates), but if an application makes frequent use of Coherence features such as indexing, parallel queries, entry processors and parallel aggregation, then it will be more effective to have two quad-core Xeon CPUs in a 16GB server – a 4:1 increase in the CPU:RAM ratio.
A minimum of 1000Mbps for networking (e.g. Gigabit Ethernet or better) is strongly recommended. NICs should be on a high bandwidth bus such as PCI-X or PCIe, and not on standard PCI. In the case of PCI-X having the NIC on an isolated or otherwise lightly loaded 133MHz bus may significantly improve performance. |
|
How many servers are optimal?
Coherence is primarily a scale-out technology. While Coherence can effectively scale-up on large servers by using multiple JVMs per server, the natural mode of operation is to span a number of small servers (e.g. 2-socket or 4-socket commodity servers). Specifically, failover and failback are more efficient in larger configurations. And the impact of a server failure is lessened. As a rule of thumb, a cluster should contain at least four physical servers. In most WAN configurations, each data center will have independent clusters (usually interconnected by Extend-TCP). This will increase the total number of discrete servers (four servers per data center, multiplied by the number of data centers).
Coherence is quite often deployed on smaller clusters (one, two or three physical servers) but this practice has increased risk if a server failure occurs under heavy load. As discussed in the network section of this document, Coherence clusters are ideally confined to a single switch (e.g. fewer than 96 physical servers). In some use cases, applications that are compute-bound or memory-bound applications (as opposed to network-bound) may run acceptably on larger clusters.
Also note that given the choice between a few large JVMs and a lot of small JVMs, the latter may be the better option. There are several production environments of Coherence that span hundreds of JVMs. Some care is required to properly prepare for clusters of this size, but smaller clusters of dozens of JVMs are readily achieved. Please note that disabling UDP multicast (via WKA) or running on slower networks (e.g. 100Mbps ethernet) will reduce network efficiency and make scaling more difficult. |
See also:
Operating System
|
During development, developers typically use a different operating system than the one that the application will be deployed to.
The top three operating systems for application development using Coherence are, in this order: Windows 2000/XP (~85%), Mac OS X (~10%) and Linux (~5%). The top four operating systems for production deployment are, in this order: Linux, Solaris, AIX and Windows. Thus, it is relatively unlikely that the development and deployment operating system will be the same.
Make sure that regular testing is occurring on the target operating system. |
|
What are the supported and suggested server operating systems for deploying Coherence on?
Oracle tests on and supports various Linux distributions (including customers that have custom Linux builds), Sun Solaris, IBM AIX, Windows 2000/XP/2003, Apple Mac OS X, OS/400 and z/OS. Additionally, Oracle supports customers running HP-UX and various BSD UNIX distributions.
If the server operating system decision is still in the future, the following are suggested for Coherence (as of December 2006):
For commodity x86 servers, Linux distributions based on the Linux 2.6 kernel are recommended. While it is expected that most 2.6-based Linux distributions will provide a good environment for running Coherence, the following are recommended by Oracle: RedHat Enterprise Linux (version 4 or later) and Suse Linux Enterprise (version 10 or later). Oracle also routinely tests using distributions such as RedHat Fedora Core 5 and even Knoppix "Live CD".
Review and follow the instructions in the "Deployment Considerations" document (from the list of links below) for the operating system that Coherence will be deployed on. |
|
Avoid using virtual memory (paging to disk).
In a Coherence-based application, primary data management responsibilities (e.g. Dedicated Cache Servers) are hosted by Java-based processes. Modern Java distributions do not work well with virtual memory. In particular, garbage collection (GC) operations may slow down by several orders of magnitude if memory is paged to disk. With modern commodity hardware and a modern JVM, a Java process with a reasonable heap size (512MB-2GB) will typically perform a full garbage collection in a few seconds if all of the process memory is in RAM. However, this may grow to many minutes if the JVM is partially resident on disk. During garbage collection, the node will appear unresponsive for an extended period of time, and the choice for the rest of the cluster is to either wait for the node (blocking a portion of application activity for a corresponding amount of time), or to mark the unresponsive node as "failed" and perform failover processing. Neither of these is a good option, and so it is important to avoid excessive pauses due to garbage collection. JVMs should be pinned into physical RAM, or at least configured so that the JVM will not be paged to disk.
Note that periodic processes (such as daily backup programs) may cause memory usage spikes that could cause Coherence JVMs to be paged to disk. |
See also:
JVM
|
During development, developers typically use the latest Sun JVM or a direct derivative such as the Mac OS X JVM.
The main issues related to using a different JVM in production are:
- Command line differences, which may expose problems in shell scripts and batch files;
- Logging and monitoring differences, which may mean that tools used to analyze logs and monitor live JVMs during development testing may not be available in production;
- Significant differences in optimal GC configuration and approaches to GC tuning;
- Differing behaviors in thread scheduling, garbage collection behavior and performance, and the performance of running code.
Make sure that regular testing is occurring on the JVM that will be used in production. |
|
Which JVM configuration options should be used?
JVM configuration options vary over versions and between vendors, but the following are generally suggested:
- Using the -server option will result in substantially better performance.
- Using identical heap size values for both -Xms and -Xmx will yield substantially better performance, as well as "fail fast" memory allocation.
- For naive tuning, a heap size of 512MB is a good compromise that balances per-JVM overhead and garbage collection performance.
- Larger heap sizes are allowed and commonly used, but may require tuning to keep garbage collection pauses manageable.
|
|
What are the supported and suggested JVMs for deploying Coherence on?
In terms of Oracle Coherence versions:
- Coherence 3.x versions are supported on the Sun JDK versions 1.4 and 1.5, and JVMs corresponding to those versions of the Sun JDK. Starting with Coherence 3.3 the 1.6 JVMs are also supported.
- Coherence version 2.x (currently at the 2.5.1 release level) is supported on the Sun JDK versions 1.2, 1.3, 1.4 and 1.5, and JVMs corresponding to those versions of the Sun JDK.
Often the choice of JVM is dictated by other software. For example:
- IBM only supports IBM WebSphere running on IBM JVMs. Most of the time, this is the IBM "Sovereign" or "J9" JVM, but when WebSphere runs on Sun Solaris/Sparc, IBM builds a JVM using the Sun JVM source code instead of its own.
- BEA WebLogic typically includes a JVM which is intended to be used with it. On some platforms, this is the BEA WebLogic JRockit JVM.
- Apple Mac OS X, HP-UX, IBM AIX and other operating systems only have one JVM vendor (Apple, HP and IBM respectively).
- Certain software libraries and frameworks have minimum Java version requirements because they take advantage of relatively new Java features.
On commodity x86 servers running Linux or Windows, the Sun JVM is recommended. Generally speaking, the recent update versions are recommended. For example:
- Oracle recommends testing and deploying using the latest supported Sun JVM based on your platform and Coherence version.
Basically, at some point before going to production, a JVM vendor and version should be selected and well tested, and absent any flaws appearing during testing and staging with that JVM, that should be the JVM that is used when going to production. For applications requiring continuous availability, a long-duration application load test (e.g. at least two weeks) should be run with that JVM before signing off on it.
Review and follow the instructions in the "Deployment Considerations" document (from the list of links below) for the JVM that Coherence will be deployed on. |
|
Must all nodes run the same JVM vendor and version?
No. Coherence is pure Java software and can run in clusters composed of any combination of JVM vendors and versions, and Oracle tests such configurations.
Note that it is possible for different JVMs to have slightly different serialization formats for Java objects, meaning that it is possible for an incompatibility to exist when objects are serialized by one JVM, passed over the wire, and a different JVM (vendor and/or version) attempts to deserialize it. Fortunately, the Java serialization format has been very stable for a number of years, so this type of issue is extremely unlikely. However, it is highly recommended to test mixed configurations for conistent serialization prior to deploying in a production environment. |
See also:
Application Instrumentation
|
Be cautious when using instrumented management and monitoring solutions.
Some Java-based management and monitoring solutions use instrumentation (e.g. bytecode-manipulation and ClassLoader substitution). While there are no known open issues with the latest versions of the primary vendors, Oracle has observed issues in the past. |
Coherence Editions and Modes
|
During development, use the development mode.
The Coherence download includes a fully functional Coherence product supporting all editions and modes. The default configuration is for Grid Edition in Development mode.
Coherence may be configured to operate in either development or production mode. These modes do not limit access to features, but instead alter some default configuration settings. For instance, development mode allows for faster cluster startup to ease the development process.
It is recommended to use the development mode for all pre-production activities, such as development and testing. This is an important safety feature, because Coherence automatically prevents these nodes from joining a production cluster. The production mode must be explicitly specified when using Coherence in a production environment.
Coherence may be configured to support a limited feature set, based on the customer license agreement.
Only the edition and the number of licensed CPUs specified within the customer license agreement can be used in a production environment.
When operating outside of the production environment it is allowable to run any Coherence edition. However, it is recommended that only the edition specified within the customer license agreement be utilized. This will protect the application from unknowingly making use of unlicensed features.
All nodes within a cluster must use the same license edition and mode. |
|
Starting with Oracle Coherence 3.3, customer-specific license keys are no longer part of product deployment.
Be sure to obtain enough licenses for the all the cluster members in the production environment. The servers hardware configuration (number or type of processor sockets, processor packages or CPU cores) may be verified using ProcessorInfo utility included with Coherence.
java -cp tangosol.jar com.tangosol.license.ProcessorInfo
If the result of the ProcessorInfo program differs from the licensed configuration, send the program's output and the actual configuration to the "support" email address at Oracle.
|
|
How are the edition and mode configured?
There is a <license-config> configuration section in tangosol-coherence.xml (located in coherence.jar) for edition and mode related information.
In addition to preventing mixed mode clustering, the license-mode also dictates the operational override file which will be used. When in "dev" mode the tangosol-coherence-override-dev.xml file will be utilized, whereas the tangosol-coherence-override-prod.xml file will be used when the "prod" mode is specified. As the mode controls which override file is used, the <license-mode> configuration element is only usable in the base tangosol-coherence.xml file and not within the override files.
These elements are defined by the corresponding coherence.dtd in coherence.jar. It is possible to specify this edition on the command line using the command line override feature:
-Dtangosol.coherence.edition=RTC
Valid values are:
| Value |
Coherence Edition |
Compatible Editions |
| GE |
Grid Edition |
RTC, DC |
| GE-DC |
Grid Edition (supporting only Data Clients) |
DC |
| EE |
Enterprise Edition |
DC |
| SE |
Standard Edition |
DC |
| RTC |
Real-Time Client |
GE |
| DC |
Data Client |
GE, GE-DC, EE, SE |
- Note: clusters running different editions may connect via the Coherence*Extend as a Data Client.
|
Coherence Operational Configuration
|
Operational configuration relates to the configuration of Coherence at the cluster level including such things as:
The operational aspects are normally configured via the tangosol-coherence-override.xml file.
The contents of this file will likely differ between development and production. It is recommended that that these variants be maintained independently due to the significant differences between these environments. The production operational configuration file should not be the responsibility of the application developers, instead it should fall under the jurisdiction of the systems administrators who are far more familiar with the workings of the production systems.
All cluster nodes should utilize the same operational configuration descriptor. A centralized configuration file may be maintained and accessed by specifying the file's location as a URL using the tangosol.coherence.override system property. Any node specific values may be specified via system properties.
The override file should contain only the subset of configuration elements which you wish to customize. This will not only make your configuration more readable, but will allow you to take advantage of updated defaults in future Coherence releases. All override elements should be copied exactly from the original tangosol-coherence.xml, including the id attribute of the element.
Member descriptors may be used to provide detailed identity information that is useful for defining the location and role of the cluster member. Specifying these items will aid in the management of large clusters by making it easier to identify the role of a remote nodes if issues arise. |
Coherence Cache Configuration
|
Cache configuration relates to the configuration of Coherence at a per-cache level including such things as:
The cache configuration aspects are normally configured via the coherence-cache-config.xml file.
The default coherence-cache-config.xml file included within coherence.jar is intended only as an example and is not suitable for production use. It is suggested that you produce your own cache configuration file with definitions tailored to your application needs.
All cluster nodes should utilize the same cache configuration descriptor. A centralized configuration file may be maintained and accessed by specifying the file's location as a URL using the tangosol.coherence.cacheconfig system property.
Choose the cache topology which is most appropriate for each cache's usage scenario.
It is important to size limit your caches based on the allocated JVM heap size. Even if you never expect to fully load the cache, having the limits in place will help protect your application from OutOfMemoryExceptions if your expectations are later negated.
For a 1GB heap that at most ¾ of the heap be allocated for cache storage. With the default one level of data redundancy this implies a per server cache limit of 375MB for primary data, and 375MB for backup data. The amount of memory allocated to cache storage should fit within the tenured heap space for the JVM. See Sun's GC tuning guide for details.
|
|
It is important to note that when multiple cache schemes are defined for the same cache service name the first to be loaded will dictate the service level parameters. Specifically the partition-count, backup-count and thread-count are shared by all caches of the same service.
For multiple caches which use the same cache service it is recommended that the service related elements be defined only once, and that they be inherited by the various cache-schemes which will use them.
If you desire different values for these items on a cache by cache basis then multiple services may be configured. |
|
For partitioned caches Coherence will evenly distribute the storage responsibilities to all cache servers, regardless of their cache configuration or heap size. For this reason it is recommended that all cache server processes be configured with the same heap size. For machines with additional resources multiple cache servers may be utilized to effectively make use of the machine's resources.
To ensure even storage responsibility across a partitioned cache the partition-count should be set to a prime number which is at least the square of the number of cache servers which will be used.
For caches which are backed by a cache store it is recommended that the parent service be configured with a thread pool as requests to the cache store may block on I/O. The pool is enabled via the thread-count element. For non-CacheStore-based caches more threads are unlikely to improve performance and should left disabled. |
Unless explicitly specified all cluster nodes will be storage enabled, i.e. will act as cache servers. It is important to control which nodes in your production environment will be storage enabled and storage disabled. The tangosol.coherence.distributed.localstorage system property may be utilized to control this, setting it to either true or false. Generally only dedicated cache servers, all other cluster nodes should be configured as storage disabled. This is especially important for short lived processes which may join the cluster perform some work, and exit the cluster, having these nodes as storage disable will introduce unneeded repartitioning.
Other Resources
Multicast Test
Multicast Test Utility
Included with Coherence is a Multicast Test utility, which helps you determine if multicast is enabled between two or more computers. This is a connectivity test, not a load test, each instance will by default only transmit a single multicast packet once every two seconds. For network load testing please see the Datagram Test.
Syntax
To run the Multicast Test utility use the following syntax from the command line:
Command Options
| Command |
Optional |
Description |
Default |
| -local |
True |
The address of the NIC to transmit on, specified as an IP address
|
localhost |
| -group |
True |
The multicast address to use, specified as IP:port.
|
237.0.0.1:9000 |
| -ttl |
True |
The time to live for multicast packets.
|
4 |
| -delay |
True |
The delay between transmitting packets, specified in seconds.
|
2 |
| -display |
True |
The number of bytes to dispaly from unexpected packets.
|
0 |
Usage Example
For ease of use, multicast-test.sh and multicast-test.cmd scripts are provided in the Coherence bin directory, and can be used to execute this test.
Note: prior to Coherence 3.1 the following syntax was used, and scripts were not provided:
Example
Let's say that we want to test if we can use multicast address 237.0.0.1, port 9000 (the test's defaults) to send messages between two servers - Server A with IP address 195.0.0.1 and Server B with IP address 195.0.0.2.
Starting with Server A, let's determine if it has multicast address 237.0.0.1 port 9000 available for 195.0.0.1 by first checking the machine or interface by itself as follows:
From a command session, type in:
After pressing ENTER, you should see the Multicast Test utility showing you how it is sending sequential multicast packets and receiving them as follows:
Once you have seen a number of these packets sent and received successfully, you can hit CTRL-C to stop further testing.
If you do not see something similar to the above, then multicast is not working. Also, please note that we specified a TTL of 0 to prevent the multicast packets from leaving Server A.
You can repeat the same test on Server B to assure that it too has the multicast enabled for it's port combination.
Now to test multicast communications between Server A and Server B. For this test we will use a non-zero TTL which will allow the packets to leave their respective servers. By default the test will use a TTL of 4, if you believe that there may be more network hops required to route packets between Server A and Server B, you may specify a higher TTL value.
Start the test on Server A and Server B by entering the following command into the command windows and pressing ENTER:
You should see something like the following on Server A:
and something like the following on Server B:
You can see that both Server A and Server B are issuing multicast packets and seeing their own and each other's packets. This indicates that multicast is functioning properly between these servers using the default multicast address and port.
Note: Server A sees only its own packets 1-4 until we start Server B and it receives packet 1 from Server B.
Troubleshooting
If you are unable to establish bidirectional multicast communication please try the following:
If multicast is not functioning properly, you will need to consult with your network administrator or sysadmin to determine the cause and to correct the situation.
(verifying multicast support)
Datagram Test
Datagram Test Utility
Included with Coherence is a Datagram Test utility which can be used to test and tune network performance between two or more machines. The Datagram test operates in one of three modes, either as a packet publisher, a packet listener, or both. When run a publisher will transmit UDP packets to the listener who will measure the throughput, success rate, and other statistics.
To achieve maximum performance it is suggested that you tune your environment based on the results of these tests.
Syntax
The Datagram test supports a large number of configuration options, though only a few are required for basic operation. To run the Datagram Test utility use the following synctax from the command line:
Command Options
| Command |
Optional |
Applicability |
Description |
Default |
| -local |
True |
Both |
The local address to bind to, specified as addr:port |
localhost:9999 |
| -packetSize |
True |
Both |
The size of packet to work with, specified in bytes. |
1468 |
| -processBytes |
True |
Both |
The number of bytes (in multiples of 4) of each packet to process. |
4 |
| -rxBufferSize |
True |
Listener |
The size of the receive buffer, specified in packets. |
1428 |
| -txBufferSize |
True |
Publisher |
The size of the transmit buffer, specified in packets. |
16 |
| -txRate |
True |
Publisher |
The rate at which to transmit data, specified in megabytes. |
unlimited |
| -txIterations |
True |
Publisher |
Specifies the number of packets to publish before exiting. |
unlimited |
| -txDurationMs |
True |
Publisher |
Specifies how long to publish before exiting. |
unlimited |
| -reportInterval |
True |
Both |
The interval at which to output a report, specified in packets. |
100000 |
| -tickInterval |
True |
Both |
The interval at which to output tick marks. |
1000 |
| -log |
True |
Listener |
The name of a file to save a tabular report of measured performance. |
none |
| -logInterval |
True |
Listener |
The interval at which to output a measurement to the log. |
100000 |
| -polite |
True |
Publisher |
Switch indicating if the publisher should wait for the listener to be contacted before publishing. |
off |
| arguments |
True |
Publisher |
Space separated list of addresses to publish to, specified as addr:port. |
none |
Usage Examples
Listener
Publisher
For ease of use, datagram-test.sh and datagram-test.cmd scripts are provided in the Coherence bin directory, and can be used to execute this test.
Example
Let's say that we want to test network performance between two servers servers - Server A with IP address 1{{95.0.0.1}} and Server B with IP address 195.0.0.2. One server will act as a packet publisher and the other as a packet listener, the publisher will transmit packets as fast as possible and the listener will measure and report performance statistics. First start the listener on Server A.
After pressing ENTER, you should see the Datagram Test utility showing you that it is ready to receive packets.
As you can see by default the test will try to allocate a network receive buffer large enough to hold 1428 packets, or about 2 MB. If it is unable to allocate this buffer it will report an error and exit. You can either decrease the requested buffer size using the -rxBufferSize parameter or increase you OS network buffer settings. For best performance it is recommended that you increase the OS buffers. See the following forum post for details on tuning your OS for Coherence.
Once the listener process is running you may start the publisher on Server B, directing it to publish to Server A.
After pressing ENTER, you should see the new Datagram test instance on Server B start both a listener and a publisher. Note in this configuration Server B's listener will not be used. The following output should appear in the Server B command window.
The series of "o" and "O" tick marks appear as data is (O)utput on the network. Each "o" represents 1000 packets, with "O" indicators at every 10,000 packets.
On Server A you should see a corresponding set of "i" and "I" tick marks, representing network (I)nput. This indicates that the two test instances are communicating.
Reporting
Periodically each side of the test will report performance statistics.
Publisher Statistics
The publisher simply reports the rate at which it is publishing data on the network. A typical report is as follows:
The report includes both the current transmit rate (since last report) and the lifetime transmit rate.
Listener Statistics
The listener reports more detailed statistics including:
| Element |
Description |
| Elapsed |
The time interval that the report covers. |
| Packet size |
The received packet size. |
| Throughput |
The rate at which packets are being received. |
| Received |
The number of packets received. |
| Missing |
The number of packets which were detected as lost. |
| Success rate |
The percentage of received packets out of the total packets sent. |
| Out of order |
The number of packets which arrived out of order. |
| Average offset |
An indicator of how out of order packets are. |
As with the publisher both current and lifetime statistics are report. A typical report is as follows:
The primary items of interest are the throughput and success rate. The goal is to find the highest throughput while maintaining a success rate as close to 1.0 as possible. On a 100 Mb network setup you should be able to achieve rates of around 10 MB/sec. On a 1 Gb network you should be able to achieve rates of around 100 MB/sec. Achieving these rates will likely require some tuning (see below).
Throttling
The publishing side of the test may be throttled to a specific datarate expressed in megabytes per second, by including the -txRate M parameter when M represents the maximum MB/sec the test should put on the network.
Bidirectional Testing
You may also run the test in a bidirectional mode where both servers act as publishers and listeners. To do this simply restart test instances, supplying the instance on Server A with Server B's address, by running the following on Server A.
And then run the same command as before on Server B. The -polite parameter instructs this test instance to not start publishing until it is starts to receive data.
Distributed Testing
You may also use more then two machines in testing, for instance you can setup two publishers to target a single listener. This style testing is far more realistic then simple one-to-one testing, and may identify bottlenecks in your network which you were not otherwise aware of.
Assuming you intend to construct a cluster consisting of four machines, you can run the datagram test amongst all of them as follows:
On servera:
On serverb:
On serverc:
On serverd:
This test sequence will cause all nodes to send a total of 100MB per second to all other nodes (i.e. 33MB/node/sec). On a fully switched network 1GbE network this should be achievable without packet loss.
To simplify the execution of the test all nodes can be started with an identical target list, they will obviously transmit to themselves as well, but this loopback data can easily be factored out. It is important to start all but the last node using the -polite switch, this will cause all other nodes to delay testing until the final node is started.
(network performance testing)
Performance Tuning
To achieve maximum performance with Coherence it is suggested that you test and tune your operating environment. Tuning recommendations are available for:
OS Tuning
Socket Buffer Sizes
To help minimization of packet loss, the OS socket buffers need to be large enough to handle the incoming network traffic while your Java application is paused during garbage collection. By default Coherence will attempt to allocate a socket buffer of 2MB. If your OS is not configured to allow for large buffers Coherence will utilize smaller buffers. Most versions of Unix have a very low default buffer limit, which should be increased to at least 2MB.
Starting with Coherence 3.1 you will receive the following warning if the OS failed to allocate the full size buffer.
UnicastUdpSocket failed to set receive buffer size to 1428 packets (2096304 bytes); actual size is 89 packets (131071 bytes). Consult your OS documentation regarding increasing the maximum socket buffer size. Proceeding with the actual value may cause sub-optimal performance.
Though it is safe to operate with the smaller buffers it is recommended that you configure your OS to allow for larger buffers.
On Linux execute (as root):
On Solaris execute (as root):
On AIX execute (as root):
| Note that AIX only supports specifying receive buffer sizes of 1MB, 4MB, and 8MB. Additionally there is an issue with IBM's 1.4.2, and 1.5 JVMs which may prevent them from allocating socket buffers larger then 64K. This issue has been addressed in IBM's 1.4.2 SR7 SDK and 1.5 SR3 SDK. |
On Windows:
Windows does not impose a buffer size restriction by default.
Other:
For information on increasing the buffer sizes for other OSs please refer to your OS's documentation.
You may configure Coherence to request alternate sized buffers via the coherence/cluster-config/packet-publisher/packet-buffer/maximum-packets and coherence/cluster-config/unicast-listener/packet-buffer/maximum-packets elements.
High Resolution timesource (Linux)
Linux has a number of high resolution timesources to choose from, the fastest TSC (Time Stamp Counter) unfortunately is not always reliable. Linux chooses TSC by default, and during boot checks for inconsistencies, if found it switches to a slower safe timesource. The slower time sources can be 10 to 30 times more expensive to query then the TSC timesource, and may have a measurable impact on Coherence performance. Note that Coherence and the underlying JVM are not aware of the timesource which the OS is utilizing. It is suggested that you check your system logs (/var/log/dmesg) to verify that the following is not present.
As the log messages suggest, this can be caused by a variable rate CPU (SpeedStep), having DMA disabled, or incorrect TSC synchronization on multi CPU machines. If present it is suggested that you work with your system administrator to identify the cause and allow the TSC timesource to be utilized.
Datagram size (Microsoft Windows)
Microsoft Windows supports a fast I/O path which is utilized when sending "small" datagrams. The default setting for what is considered a small datagram is 1024 bytes; increasing this value to match your network MTU (normally 1500) can significantly improve network performance.
To adjust this parameter:
- Run Registry Editor (regedit)
- Locate the following registry key
HKLM\System\CurrentControlSet\Services\AFD\Parameters
- Add the following new DWORD value
Name: FastSendDatagramThreshold
Value: 1500 (decimal)
- Reboot
| Note: Included in Coherence 3.1 and above is an optimize.reg script which will perform this change for you, it can be found in the coherence/bin directory of your installation. After running the script you must reboot your computer for the changes to take effect. |
For more details on this parameter see Appendix C of http://www.microsoft.com/technet/itsolutions/network/deploy/depovg/tcpip2k.mspx
Thread Scheduling (Microsoft Windows)
Windows (including NT, 2000 and XP) is optimized for desktop application usage. If you run two console (" DOS box ") windows, the one that has the focus can use almost 100% of the CPU, even if other processes have high-priority threads in a running state. To correct this imbalance, you must configure the Windows thread scheduling to less-heavily favor foreground applications.
- Open the Control Panel.
- Open System.
- Select the Advanced tab.
- Under Performance select Settings.
- Select the Advanced tab.
- Under Processor scheduling, choose{{Background services}}.
| Note: Coherence includes an optimize.reg script which will perform this change for you, it can be found in the coherence/bin directory of your installation. |
Swapping
Ensure that you have sufficient memory such that you are not making active use of swap space on your machines. You may monitor the swap rate using tools such as vmstat and top. If you find that you are actively moving through swap space this will likely have a significant impact on Coherence's performance. Often this will manifest itself as Coherence nodes being removed from the cluster due to long periods of unresponsiveness caused by them having been "swapped out".
Network Tuning
Network Interface Settings
Verify that your Network card (NIC) is configured to operate at it's maximum link speed and at full duplex. The process for doing this varies between OSs.
On Linux execute (as root):
See the man page on ethtool for further details and for information on adjust the interface settings.
On Solaris execute (as root):
This will display the link settings for interface 0. Items of interest are link_duplex (2 = full), and link_speed which is reported in Mbps. For further details on Solaris network tuning see this article from Prentice Hall.
| If running on Solaris 10, please review Sun issues 102712 and 102741 which relate to packet corruption and multicast disconnections. These will most often manifest as either EOFExceptions, "Large gap" warnings while reading packet data, or frequent packet timeouts. It is highly recommend that the patches for both issues be applied when using Coherence on Solaris 10 systems. |
On Windows:
- Open the Control Panel.
- Open Network Connections.
- Open the Properties dialog for desired network adapter.
- Select Configure.
- Select the Advanced tab.
- Locate the driver specific property for Speed & Duplex.
- Set it to either auto or to a specific speed and duplex setting.
Bus Considerations
For 1Gb and faster PCI network cards the system's bus speed may be the limiting factor for network performance. PCI and PCI-X busses are half-duplex, and all devices will run at the speed of the slowest device on the bus. Standard PCI buses have a maximum throughput of approximately 1Gb/sec and thus are not capable of fully utilizing a full-duplex 1Gb NIC. PCI-X has a much higher maximum throughput (1GB/sec), but can be hobbled by a single slow device on the bus. If you find that you are not able to achieve satisfactory bidirectional data rates it is suggested that you evaluate your machine's bus configuration. For instance simply relocating the NIC to a private bus may improve performance.
Network Infrastructure Settings
If you experience frequent multi-second communication pauses across multiple cluster nodes you may need to increase your switch's buffer space. These communication pauses can be identified by a series of Coherence log messages identifying communication delays with multiple nodes which are not attributable to local or remote GCs.
Experienced a 4172 ms communication delay (probable remote GC) with Member(Id=7, Timestamp=2006-10-20 12:15:47.511, Address=192.168.0.10:8089, MachineId=13838); 320 packets rescheduled, PauseRate=0.31, Threshold=512
Some switches such as the Cisco 6500 series support configuration the amount of buffer space available to each ethernet port or ASIC. In high load applications it may be necessary to increase the default buffer space. On Cisco this can be accomplished by executing:
fabric buffer-reserve high
See Cisco's documentation for additional details on this setting.
Path MTU
By default Coherence assumes a 1500 byte network MTU, and uses a default packet size of 1468 based on this assumption. Having a packet size which does not fill the MTU will result is an under utilized network. If your equipment uses a different MTU, you should configure Coherence accordingly, by specifying a packet size which is 32 bytes smaller then the network path's minimal MTU. The packet size may be specified in coherence/cluster-config/packet-publisher/packet-size/maximum-length and preferred-length configuration elements.
If you are unsure of your equpiment's MTU along the full path between nodes you can use either the standard ping or traceroute utility to determine it. To do this, execute a series of ping or traceroute operations between the two machines. With each attempt you will specify a different packet size, starting from a high value and progressively moving downward until the packets start to make it through without fragmentation. You will need to specify a particular packet size, and to not fragment the packets.
On Linux execute:
On Solaris execute:
On Windows execute:
On other OSs, consult the documentation for the ping or traceroute command to see how to disable fragmentation, and specify the packet size.
If you receive a message stating that packets must be fragmented then the specified size is larger then the path's MTU. Decrease the packet size until you find the point at which packets can be transmitted without fragmentation. If you find that you need to use packets smaller then 1468 you may wish to contact your network administrator to get the MTU increased to at least 1500.
JVM Tuning
Server Mode
It is recommended that you run all your Coherence JVMs in server mode, by specifying the "-server" on the JVM command line. This allows for a number of performance optimizations for long running applications.
Sizing the Heap
It is generally recommended that heap sizes be kept at 1GB or below as larger heaps will have a more significant impact on garbage collection times. On 1.5 and higher JVMs larger heaps are reasonable, but will likely require additional GC tuning.
Running with a fixed sized heap will save your JVM from having to grow the heap on demand and will result in improved performance. To specify a fixed size heap use the -Xms and -Xmx JVM options, setting them to the same value. For example:
Note that the JVM process will consume more system memory then the specified heap size, for instance a 1GB JVM will consume 1.3GB of memory. This should be taken into consideration when determining the maximum number of JVMs which you will run on a machine. The actual allocated size can be monitored with tools such as top. See Best Practices for additional details on heap size considerations.
GC Monitoring & Tuning
Frequent garbage collection pauses which are in the range of 100ms or more are likely to have a noticeable impact on network performance. During these pauses a Java application is unable to send or receive packets, and in the case of receiving, the OS buffered packets may be discarded and need to be retransmitted.
Specify "-verbose:gc" or "-Xloggc:" on the JVM command line to monitor the frequency and duration of garbage collection pauses.
See http://java.sun.com/docs/hotspot/gc5.0/gc_tuning_5.html for details on GC tuning.
Starting with Coherence 3.2 log messages will be generated when one cluster node detects that another cluster node has been unresponsive for a period of time, generally indicating that a target cluster node was in a GC cycle.
Experienced a 4172 ms communication delay (probable remote GC) with Member(Id=7, Timestamp=2006-10-20 12:15:47.511, Address=192.168.0.10:8089, MachineId=13838); 320 packets rescheduled, PauseRate=0.31, Threshold=512
The PauseRate indicates the percentage of time for which the node has been considered unresponsive since the stats were last reset. Nodes reported as unresponsive for more then a few percent of their lifetime may be worth investigating for GC tuning.
Coherence Network Tuning
Coherence includes configuration elements for throttling the amount of traffic it will place on the network; see the documentation for traffic-jam, flow-control and burst-mode, these settings are used to control the rate of packet flow within and between cluster nodes.
Validation
To determine how these settings are affecting performance you need to check if you're cluster nodes are experiencing packet loss and/or packet duplication. This can be obtained by looking at the following JMX stats on various cluster nodes:
- ClusterNodeMBean.PublisherSuccessRate - If less then 1.0, packets are being detected as lost and being resent. Rates below 0.98 may warrant investigation and tuning.
- ClusterNodeMBean.ReceiverSuccessRate - If less then 1.0, the same packet is being received multiple times (duplicates), likely due to the publisher being overly aggressive in declaring packets as lost.
- ClusterNodeMBean.WeakestChannel - Identifies the remote cluster node which the current node is having most difficulty communicating with.
For information on using JMX to monitor Coherence see Managing Coherence using JMX.
Management and Monitoring
Managing Coherence using JMX
Overview
Coherence includes facilities for managing and monitoring Coherence resources via the Java Management Extensions (JMX) API. JMX is a Java standard for managing and monitoring Java applications and services. It defines a management architecture, design patterns, APIs, and services for building general solutions to manage Java-enabled resources. This section assumes familiarity with JMX terminology. If you are new to JMX a good place to start is with this article.
To manage Coherence using JMX:
- Add JMX libraries to the Coherence classpath (if necessary)
- Configure the Coherence Management Framework
- View and manipulate Coherence MBeans using a JMX client of your choice
| JMX support
Coherence Enterprise Edition and higher support clustered JMX, allowing access to JMX statistics for the entire cluster from any member. Coherence Standard Edition provides only local JMX information. |
Adding JMX libraries to the Coherence classpath
If you would like to manage a Coherence cluster using JMX you will need to ensure that you have the necessary JMX 1.0 or later classes (javax.management.*) in the classpath of at least one Coherence cluster node, known as an MBeanServer host. The cluster nodes that are not MBeanServer hosts will be managed by the MBeanServer host(s) via the Coherence Invocation service.
All compliant J2SE 5.0 JREs and J2EE application servers supply a JMX 1.0 or later implementation; therefore, if the MBeanServer host node is running within a J2SE 5.0 JVM or J2EE application server, no additional actions are necessary. However, for standalone applications running within a pre-J2SE 5.0 JVM, you can download the necessary JMX libraries here and add them to the classpath.
Configuring the Coherence Management Framework
In the majority of cases, enabling JMX management can be done by simply setting a Java system property on all Coherence cluster nodes that are acting as MBeanServer hosts:
and the following Java system property on all cluster nodes:
Note that the use of dedicated JMX cluster members is a common pattern. This approach avoids loading JMX software into every single cluster member, while still providing fault-tolerance should a single JMX member run into issues.
In general, the Coherence Management Framework is configured by the management-configuration operational configuration element in the Coherence Operational Configuration deployment descriptor (tangosol-coherence.xml). The following sub-elements control the behavior of the Management Framework:
- domain-name
Specifies the name of the JMX domain used to register MBeans exposed by the Coherence Management Framework.
- managed-nodes
Specifies whether or not a cluster node's JVM has an in-process MBeanServer and if so, whether or not the node allows management of other nodes' managed objects. Valid values are none, local-only, remote-only and all. For example, if a node has an in-process MBeanServer and you'd like this node to manage other nodes' MBeans, set this attribute to all.
- allow-remote-management
Specifies whether or not this cluster node will register its MBeans in a remote MBeanServer(s).
- read-only
Specifies whether or not the MBeans exposed by this cluster node allow operations that modify run-time attributes.
For additional information on each of these attributes, please see the Operational Configuration Elements.
Accessing Coherence MBeans
Once you have configured the Coherence Management Framework and launched one or more Coherence cluster nodes (at least one being an MBeanServer host) you will be able to view and manipulate the Coherence MBeans registered by all cluster nodes using standard JMX API calls. See the JavaDoc for the Registry class for details on the various MBean types registered by Coherence clustered services.
Coherence ships with two examples that demonstrate accessing Coherence MBeans via JMX. The first uses the HttpAdapter that is shipped as part of the JMX reference implementation (jmxtools.jar). To run the example on a pre-J2SE 5.0 JVM, start the Coherence command line application using the following command on Windows (note that it is broken up into multiple lines here only for formatting purposes; this is a single command typed on one line):
On Unix:
Once the Coherence command line application has started, type "jmx 8082" and hit enter. This starts the HttpAdapter on http://localhost:8082 in the cluster node's JVM and makes the cluster node an MBeanServer host. You can now use the HttpAdapter web application to view and manipulate Coherence MBeans registered by all cluster nodes:
Alternatively, you can run this example with the Sun J2SE 5.0 JVM and use the JConsole utility included with the Sun J2SE 5.0 JDK to view and manipulate Coherence MBeans. To do so, start the Coherence command line application using the following command (note that it is broken up into multiple lines here only for formatting purposes; this is a single command typed on one line):
Once the Coherence command line application has started, launch the JConsole utility (located in the bin directory of the Sun J2SE 5.0 JDK distribution) and open a new connection to the JVM running the Coherence command line application:
The second example is a JSP page (JmxCacheExplorer.jsp) that displays basic information on each running Coherence cache using JMX API calls. You can find this example in the examples/jsp/explore directory under the root of your Coherence installation.
Additional JMX examples may be found on the Coherence Forums.
Using Coherence MBeanConnector
As of version 3.3, Coherence ships with a program to launch a cluster node as a dedicated MBeanServer host. This program provides access to Coherence MBeans via the JMX Remote API using RMI or the HTTP server provided by Sun's JMX RI. The RMI and HTTP ports are user configurable, allowing for access through a firewall. The server is started using the following command (note that it is broken up into multiple lines here only for formatting purposes; this is a single command typed on one line):
To allow access via JMX RMI, include the -rmi flag. To allow access via HTTP and a web browser, include the -http flag. Both flags may be included; however at least one must present for the node to start.
The following are optional properties that can be used for JMX RMI configuration:
| tangosol.coherence.management.remote.host |
The host that the JMX server will bind to. Default is localhost. (NOTE: on Redhat Linux this may have to be changed to the host name or IP address) |
| tangosol.coherence.management.remote.registryport |
The port used for the JMX RMI registry. Default is 9000. |
| tangosol.coherence.management.remote.connectionport |
The port used for the JMX RMI connection. Default is 3000. |
The following are optional properties that can be used for HTTP configuration. (NOTE: This flag requires Sun's JMX RI in the classpath):
| tangosol.coherence.management.remote.httpport |
The port used for the HTTP connection. Default is 8888. |
To connect via JConsole with default settings use the following command:
To connect via HTTP with default settings use the following URL:
Manage Custom MBeans within the Coherence Cluster
Introduction
In addition to Managing Coherence using JMX, Coherence provides the ability to manage and monitor "custom MBeans" (i.e. application-level MBeans) within the Coherence JMX Management and Monitoring framework. This allows you to manage and/or monitor any application-level MBean from any JVM/node/end-point within the cluster.
Example
In addition to the standard Coherence managed object types, any dynamic or standard MBean type may be registered using the com.tangosol.net.management.Registry interface.
For example, the following code registers a custom standard MBean using a globally-unique name:
Registry registry = CacheFactory.ensureCluster().getManagement();
CustomMBean bean = new Custom();
String sName = registry.ensureGlobalName("type=Custom");
registry.register(sName, bean);
The ensureGlobalName method appends a nodeId property to the name that differentiates the given MBean name from an otherwise identical MBean name registered by a different cluster node. For example, if registry.ensureGlobalName("type=Custom") is executed by node 1, it would return "type=Custom,nodeId=1".
Operational Configuration
Operational Configuration Elements
Operational Configuration Deployment Descriptor Elements
Description
The following sections describe the elements that control the operational and runtime settings used by Oracle Coherence to create, configure and maintain its clustering, communication, and data management services. These elements may be specified in either the tangosol-coherence.xml operational descriptor, or the tangosol-coherence-override.xml override file. For information on configuring caches see the cache configuration descriptor section.
Document Location
When deploying Coherence, it is important to make sure that the tangosol-coherence.xml descriptor is present and situated in the application classpath (like with any other resource, Coherence will use the first one it finds in the classpath). By default (as Oracle ships the software) tangosol-coherence.xml is packaged into in the coherence.jar.
Document Root
The root element of the operational descriptor is coherence, this is where you may begin configuring your cluster and services.
Document Format
Coherence Operational Configuration deployment descriptor should begin with the following DOCTYPE declaration:
<!DOCTYPE coherence PUBLIC "-//Oracle, Inc.//DTD Oracle Coherence 3.3//EN" "http://www.tangosol.com/dtd/coherence_3_3.dtd">
| When deploying Coherence into environments where the default character set is EBCDIC rather than ASCII, please make sure that this descriptor file is in ASCII format and is deployed into its runtime environment in the binary format. |
Operational Override File (tangosol-coherence-override.xml)
Though it is acceptable to supply an alternate definition of the default tangosol-coherence.xml file, the preferred approach to operational configuration is to specify an override file. The override file contains only the subset of the operational descriptor which you wish to adjust. The default name for the override file is tangosol-coherence-override.xml, and the first instance found in the classpath will be used. The format of the override file is the same as for the operational descriptor, except that all elements are optional, any missing element will simply be loaded from the operational descriptor.
Multiple levels of override files may also be configured, allowing for additional fine tuning between similar deployment environments such as staging and production. For example Coherence 3.2 and above utilize this feature to provide alternate configurations such as the logging verbosity based on the deployment type (evaluation, development, production). See the tangosol-coherence-override-eval.xml, tangosol-coherence-override-dev.xml, and tangosol-coherence-override-prod.xml, within coherence.jar for the specific customizations.
| It is recommended that you supply an override file rather then a custom operational descriptor, thus specifing only the settings you wish to adjust. |
Command Line Override
Oracle Coherence provides a very powerful Command Line Setting Override Feature, which allows for any element defined in this descriptor to be overridden from the Java command line if it has a system-property attribute defined in the descriptor. This feature allows you to use the same operational descriptor (and override file) across all cluster nodes, and provide per-node customizations as system properties.
Element Index
The following table lists all non-terminal elements which may be used from within the operational configuration.
Parameter Setttings
Parameter Settings for the Coherence Operational Configuration deployment descriptor init-param Element
This section describes the possible predefined parameter settings for the init-param element in a number of elements where parameters may be specified.
In the following tables, Parameter Name column refers to the value of the param-name element and Value Description column refers to the possible values for the corresponding param-value element.
For example when you see:
| Parameter Name |
Value Description |
| local-storage |
Specifies whether or not this member of the DistributedCache service enables the local storage.
Legal values are true or false.
Default value is true.
Preconfigured override is tangosol.coherence.distributed.localstorage |
it means that the init-params element may look as follows
<init-params>
<init-param>
<param-name>local-storage</param-name>
<param-value>false</param-value>
</init-param>
</init-params>
or as follows:
<init-params>
<init-param>
<param-name>local-storage</param-name>
<param-value>true</param-value>
</init-param>
</init-params>
Parameters
Used in: init-param.
The following table describes the specific parameter <param-name> - <param-value> pairs that can be configured for various elements.
ReplicatedCache Service Parameters
Description
ReplicatedCache service elements support the following parameters:
These settings may also be specified as part of the replicated-scheme element in the cache configuration descriptor.
Parameters
| Parameter Name |
Value Description |
| standard-lease-milliseconds |
Specifies the duration of the standard lease in milliseconds. Once a lease has aged past this number of milliseconds, the lock will automatically be released. Set this value to zero to specify a lease that never expires. The purpose of this setting is to avoid deadlocks or blocks caused by stuck threads; the value should be set higher than the longest expected lock duration (e.g. higher than a transaction timeout). It's also recommended to set this value higher then packet-delivery/timeout-milliseconds value.
Legal values are from positive long numbers or zero.
Default value is 0. |
| lease-granularity |
Specifies the lease ownership granularity. Available since release 2.3.
Legal values are:
A value of thread means that locks are held by a thread that obtained them and can only be released by that thread. A value of member means that locks are held by a cluster node and any thread running on the cluster node that obtained the lock can release it.
Default value is thread. |
| mobile-issues |
Specifies whether or not the lease issues should be transfered to the most recent lock holders.
Legal values are true or false.
Default value is false. |
DistributedCache Service Parameters
Description
DistributedCache service elements support the following parameters:
These settings may also be specified as part of the distributed-scheme element in the cache configuration descriptor.
Parameters
| Parameter Name |
Value Description |
| <thread-count> |
Specifies the number of daemon threads used by the distributed cache service.
If zero, all relevant tasks are performed on the service thread.
Legal values are from positive integers or zero.
Default value is 0.
Preconfigured override is tangosol.coherence.distributed.threads |
| <standard-lease-milliseconds> |
Specifies the duration of the standard lease in milliseconds. Once a lease has aged past this number of milliseconds, the lock will automatically be released. Set this value to zero to specify a lease that never expires. The purpose of this setting is to avoid deadlocks or blocks caused by stuck threads; the value should be set higher than the longest expected lock duration (e.g. higher than a transaction timeout). It's also recommended to set this value higher then packet-delivery/timeout-milliseconds value.
Legal values are from positive long numbers or zero.
Default value is 0. |
| <lease-granularity> |
Specifies the lease ownership granularity. Available since release 2.3.
Legal values are:
A value of thread means that locks are held by a thread that obtained them and can only be released by that thread. A value of member means that locks are held by a cluster node and any thread running on the cluster node that obtained the lock can release it.
Default value is thread. |
| <transfer-threshold> |
Specifies the threshold for the primary buckets distribution in kilo-bytes. When a new node joins the distributed cache service or when a member of the service leaves, the remaining nodes perform a task of bucket ownership re-destribution. During this process, the existing data gets re-balanced along with the ownership information. This parameter indicates a preferred message size for data transfer communications. Setting this value lower will make the distribution process take longer, but will reduce network bandwidth utilization during this activity.
Legal values are integers greater then zero.
Default value is 512 (0.5MB).
Preconfigured override is tangosol.coherence.distributed.transfer |
| <partition-count> |
Specifies the number of partitions that a distributed cache will be "chopped up" into. Each member running the distributed cache service that has the local-storage option set to true will manage a "fair" (balanced) number of partitions. The number of partitions should be larger than the square of the number of cluster members to achieve a good balance, and it is suggested that the number be prime. Good defaults include 257 and 1021 and prime numbers in-between, depending on the expected cluster size. A list of first 1,000 primes can be found at http://www.utm.edu/research/primes/lists/small/1000.txt
Legal values are prime numbers.
Default value is 257. |
| <local-storage> |
Specifies whether or not this member of the DistributedCache service enables the local storage.
| Normally this value should be left unspecified within the configuration file, and instead set on a per-process basis using the tangosol.coherence.distributed.localstorage system property. This allows cache clients and servers to use the same configuration descriptor. |
Legal values are true or false.
Default value is true.
Preconfigured override is tangosol.coherence.distributed.localstorage |
| <backup-count> |
Specifies the number of members of the DistributedCache service that hold the backup data for each unit of storage in the cache.
Value of 0 means that in the case of abnormal termination, some portion of the data in the cache will be lost. Value of N means that if up to N cluster nodes terminate at once, the cache data will be preserved.
To maintain the distributed cache of size M, the total memory usage in the cluster does not depend on the number of cluster nodes and will be in the order of M*(N+1).
Recommended values are 0, 1 or 2.
Default value is 1. |
| <backup-storage/type> |
Specifies the type of the storage used to hold the backup data.
Legal values are:
Default value is on-heap.
Preconfigured override is tangosol.coherence.distributed.backup |
| <backup-storage/initial-size> |
Only applicable with the off-heap and file-mapped types.
Specifies the initial buffer size in bytes.
The value of this element must be in the following format:
[\d]+[[.][\d]]?[K|k|M|m|G|g|T|t]?[B|b]?
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of mega is assumed.
Legal values are positive integers between 1 and Integer.MAX_VALUE - 1023.
Default value is 1MB. |
| <backup-storage/maximum-size> |
Only applicable with the off-heap and file-mapped types.
Specifies the maximum buffer size in bytes.
The value of this element must be in the following format:
[\d]+[[.][\d]]?[K|k|M|m|G|g|T|t]?[B|b]?
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of mega is assumed.
Legal values are positive integers between 1 and Integer.MAX_VALUE - 1023.
Default value is 1024MB. |
| <backup-storage/directory> |
Only applicable with the file-mapped type.
Specifies the pathname for the directory that the disk persistence manager ( com.tangosol.util.nio.MappedBufferManager) will use as "root" to store files in. If not specified or specifies a non-existent directory, a temporary file in the default location is used.
Default value is the default temporary directory designated by the Java runtime. |
| <backup-storage/class-name> |
Only applicable with the custom type.
Specifies a class name for the custom storage implementation. If the class implements com.tangosol.run.xml.XmlConfigurable interface then upon construction the setConfig method is called passing the entire backup-storage element. |
| <backup-storage/scheme-name> |
Only applicable with the scheme type.
Specifies a scheme name for the ConfigurableCacheFactory. |
| <key-associator/class-name> |
Specifies the name of a class that implements the com.tangosol.net.partition.KeyAssociator interface. This implementation must have a zero-parameter public constructor. |
| <key-partitioning/class-name> |
Specifies the name of a class that implements the com.tangosol.net.partition.KeyPartitioningStrategy interface. This implementation must have a zero-parameter public constructor. |
| <partition-listener/class-name> |
Specifies the name of a class that implements the com.tangosol.net.partition.PartitionListener interface. This implementation must have a zero-parameter public constructor. |
| <task-hung-threshold> |
Specifies the amount of time in milliseconds that a task can execute before it is considered "hung". Note: a posted task that has not yet started is never considered as hung. This attribute is applied only if the Thread pool is used (the "thread-count" value is positive).
Legal values are positive integers or zero (indicating no default timeout). |
| <task-timeout> |
Specifies the default timeout value in milliseconds for tasks that can be timed-out (e.g. implement the com.tangosol.net.PriorityTask interface), but don't explicitly specify the task execution timeout value. The task execution time is measured on the server side and does not include the time spent waiting in a service backlog queue before being started. This attribute is applied only if the thread pool is used (the "thread-count" value is positive).
Legal values are positive integers or zero (indicating no default timeout). |
| <request-timeout> |
Specifies the maximum amount of time a client will wait for a response before abandoning the original request. The request time is measured on the client side as the time elapsed from the moment a request is sent for execution to the corresponding server node(s) and includes the following:
(1) the time it takes to deliver the request to an executing node (server);
(2) the interval between the time the task is received and placed into a service queue until the execution starts;
(3) the task execution time;
(4) the time it takes to deliver a result back to the client.
Legal values are positive integers or zero (indicating no default timeout). |
InvocationService Parameters
Description
InvocationService service elements support the following parameters:
These settings may also be specified as part of the invocation-scheme element in the cache configuration descriptor.
Parameters
| Parameter Name |
Value Description |
| <thread-count> |
Specifies the number of daemon threads to be used by the invocation service.
If zero, all relevant tasks are performed on the service thread.
Legal values are from positive integers or zero.
Preconfigured override is tangosol.coherence.invocation.threads
Default value is 0. |
| <task-hung-threshold> |
Specifies the amount of time in milliseconds that a task can execute before it is considered "hung". Note: a posted task that has not yet started is never considered as hung. This attribute is applied only if the Thread pool is used (the "thread-count" value is positive). |
| <task-timeout> |
Specifies the default timeout value in milliseconds for tasks that can be timed-out (e.g. implement the com.tangosol.net.PriorityTask interface), but don't explicitly specify the task execution timeout value. The task execution time is measured on the server side and does not include the time spent waiting in a service backlog queue before being started. This attribute is applied only if the thread pool is used (the "thread-count" value is positive).
Legal values are positive integers or zero (indicating no default timeout). |
| <request-timeout> |
Specifies the default timeout value in milliseconds for requests that can time-out (e.g. implement the com.tangosol.net.PriorityTask interface), but don't explicitly specify the request timeout value. The request time is measured on the client side as the time elapsed from the moment a request is sent for execution to the corresponding server node(s) and includes the following:
(1) the time it takes to deliver the request to an executing node (server);
(2) the interval between the time the task is received and placed into a service queue until the execution starts;
(3) the task execution time;
(4) the time it takes to deliver a result back to the client.
Legal values are positive integers or zero (indicating no default timeout). |
ProxyService Parameters
Description
ProxyService service elements support the following parameters:
These settings may also be specified as part of the proxy-scheme element in the cache configuration descriptor.
Parameters
| Parameter Name |
Value Description |
| thread-count |
Specifies the number of daemon threads to be used by the proxy service.
If zero, all relevant tasks are performed on the service thread.
Legal values are from positive integers or zero.
Default value is 0. |
Preconfigured override is tangosol.coherence.proxy.threads
Compression Filter Parameters
The compression filter com.tangosol.net.CompressionFilter, supports the following parameters (see java.util.zip.Deflater for details):
Parameters
| Parameter Name |
Value Description |
| buffer-length |
Spesifies compression buffer length in bytes.
Legal values are from positive integers or zero.
Default value is 0. |
| strategy |
Specifies the compressions strategy.
Legal values are:
- gzip
- huffman-only
- filtered
- default
Default value is gzip. |
| level |
Specifies the compression level.
Legal values are:
- default
- compression
- speed
- none
Default value is default. |
Element Attributes
Element Attributes
The following table describes the attributes that can be used with some of the elements described above.
Used in: coherence, cluster-config, logging-config, configurable-cache-factory-config, unicast-listener, multicast-listener, tcp-ring-listener, shutdown-listener, packet-publisher, incoming-message-handler, authorized-hosts, host-range, services, filters, filter-name, init-param (operational).
| Attribute |
Required/Optional |
Description |
| xml-override |
Optional |
Allows the content of this elements to be fully or partially overridden with XML documents that are external to the base document.
Legal value of this attribute is the resource name of such an override document that should be accessible using the ClassLoader.getResourceAsStream(String name) by the classes contained in coherence.jar library. In general that means that resource name should be prefixed with '/' and located in the classpath.
The override XML document referred by this attribute does not have to exist. However, if it does exist then its root element must have the same name as the element it overrides.
In cases where there are multiple elements with the same name (e.g. <services>) the id attribute should be used to identify the base element that will be overridden as well as the override element itself. The elements of the override document that do not have a match in the base document are just appended to the base. |
| id |
Optional |
Used in conjunction with the xml-override attribute in cases where there are multiple elements with the same name (e.g. <services>) to identify the base element that will be overridden as well as the override element itself. The elements of the override document that do not have a match in the base document are just appended to the base. |
Command Line Setting Override Feature
Command Line Setting Override Feature
Both the Coherence Operational Configuration deployment descriptor and the Coherence Cache Configuration deployment descriptor support the ability to assign java command line option name to any element defined in the descriptor. Some of the elements already have these Command Line Setting Overrides defined. You can create your own or change the ones that are already defined.
This feature is very useful when you need to change the settings just for a single JVM, or be able to start different applications with different settings without making them use different descriptors. The most commonplace application is passing different multicast address and/or port to allow different applications to create separate clusters.
To create a Commmand Line Setting Override all you need to do is add system-property attribute specifying the string you would like to assign as the name for the java command line option to the element you want to create an override to. Then you just need to specify it in the java command line prepended with "-D".
For example:
Let's say that we want to create an override for the IP address of the multi-home server to avoid using the default localhost, and instead specify a specific the IP address of the interface we want Coherence to use (let's say it is 192.168.0.301). We would like to call this override tangosol.coherence.localhost.
In order to do that we first add a system-property to the cluster-config/unicast-listener/address element:
<address>localhost</address>
which will look as follows with the property we added:
<address system-property="tangosol.coherence.localhost">localhost</address>
Then we use it by modifying our java command line:
to specify our address 192.168.0.301 (instead of the default localhost specified in the configuration) as follows:
The following table details all the preconfigured overrides:
Operational Configuration Elements Reference
access-controller
Used in: security-config.
The following table describes the elements you can define within the access-controller element.
| Element |
Required/Optional |
Description |
| <class-name> |
Required |
Specifies the name of a Java class that implements com.tangosol.net.security.AccessController interface, which will be used by the Coherence Security Framework to check access rights for clustered resources and encrypt/decrypt node-to-node communications regarding those rights.
Default value is com.tangosol.net.security.DefaultController. |
| <init-params> |
Optional |
Contains one or more initialization parameter(s) for a class that implements the AccessController interface.
For the default AccessController implementation the parameters are the paths to the key store file and permissions description file, specified as follows:
<init-params>
<init-param id="1">
<param-type>java.io.File</param-type>
<param-value system-property="tangosol.coherence.security.keystore"></param-value>
</init-param>
<init-param id="2">
<param-type>java.io.File</param-type>
<param-value system-property="tangosol.coherence.security.permissions"></param-value>
</init-param>
</init-params>
Preconfigured overrides based on the default AccessController implementation and the default parameters as specified above are tangosol.coherence.security.keystore and tangosol.coherence.security.permissions.
For more information on the elements you can define within the init-param element, refer to init-param.
|
authorized-hosts
Used in: cluster-config.
Description
If specified, restricts cluster membership to the cluster nodes specified in the collection of unicast addresses, or address range. The unicast address is the address value from the authorized cluster nodes' unicast-listener element. Any number of host-address and host-range elements may be specified.
Elements
The following table describes the elements you can define within the authorized-hosts element.
| Element |
Required/Optional |
Description |
| <host-address> |
Optional |
Specifies an IP address or hostname. If any are specified, only hosts with specified host-addresses or within the specified host-ranges will be allowed to join the cluster.
The content override attributes id can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document. |
| <host-range> |
Optional |
Specifies a range of IP addresses. If any are specified, only hosts with specified host-addresses or within the specified host-ranges will be allowed to join the cluster.
The content override attributes id can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document. |
The content override attributes xml-override and id can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
burst-mode
Used in: packet-publisher.
Description
The burst-mode element is used to control the rate at which packets will transmitted on the network, by specificing the maximum number of packets to transmit without pausing. By default this feature is disabled and is typically only needed when flow-control is disabled, or when operating with heavy loads on a half-duplex network link. This setting only effects packets which are sent by the packet-speaker.
Elements
The following table describes the elements you can define within the burst-mode element.
| Element |
Required/Optional |
Description |
| <maximum-packets> |
Required |
Specifies the maximum number of packets that the will be sent in a row without pausing. Zero indicates no limit. By setting this value relatively low, Coherence is forced to hold back when sending a large number of packets, which may reduce collisions in some instances or allow incoming traffic to be more quickly processed.
Default value is 0. |
| <pause-milliseconds> |
Required |
Specifies the minimum number of milliseconds to delay between long bursts of packets. By increasing this value, Coherence is forced to hold back when sending a large number of packets, which may reduce collisions in some instances or allow incoming traffic to be more quickly processed.
Default value is 10. |
callback-handler
Used in: security-config.
The following table describes the elements you can define within the callback-handler element.
| Element |
Required/Optional |
Description |
| <class-name> |
Required |
Specifies the name of a Java class that provides the implementation for the javax.security.auth.callback.CallbackHandler interface. |
| <init-params> |
Optional |
Contains one or more initialization parameter(s) for a CallbackHandler implementation.
For more information on the elements you can define within the init-param element, refer to init-param. |
cluster-config
Used in: coherence.
Description
Contains the cluster configuration information, including communication and service parameters.
Elements
The following table describes the elements you can define within the cluster-config element.
| Element |
Required/Optional |
Description |
| <member-identity> |
Optional |
Specifies detailed identity information that is useful for defining the location and role of the cluster member. |
| <unicast-listener> |
Required |
Specifies the configuration information for the Unicast listener, used for receiving point-to-point network communications. |
| <multicast-listener> |
Required |
Specifies the configuration information for the Multicast listener, used for receiving point-to-multipoint network communications. |
| <shutdown-listener> |
Required |
Specifies the action to take upon receiving an external shutdown request. |
| <tcp-ring-listener> |
Required |
Specifies configuration information for the TCP Ring listener, used to death detection. |
| <packet-publisher> |
Required |
Specifies configuration information for the Packet publisher, used for managing network data transmission. |
| <packet-speaker> |
Required |
Specifies configuration information for the Packet speaker, used for network data transmission. |
| <incoming-message-handler> |
Required |
Specifies configuration information for the Incoming message handler, used for dispatching incoming cluster communications. |
| <outgoing-message-handler> |
Required |
Specifies configuration information for the Outgoing message handler, used for dispatching outgoing cluster communications. |
| <authorized-hosts> |
Optional |
Specifies the hosts which are allowed to join the cluster. |
| <services> |
Required |
Specifies the declarative data for all available Coherence services. |
| <filters> |
Optional |
Specifies data transformation filters, which can be used to perform custom transformations on data being transfered between cluster nodes. |
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
coherence
Description
The coherence element is the root element of the operational deployment descriptor.
Elements
The following table describes the elements you can define within the coherence element.
| Element |
Required/Optional |
Description |
| <cluster-config> |
Required |
Contains the cluster configuration information. This element is where most communication and service parameters are defined. |
| <logging-config> |
Required |
Contains the configuration information for the logging facility. |
| <configurable-cache-factory-config> |
Required |
Contains configuration information for the configurable cache factory. It controls where, from, and how the cache configuration settings are loaded. |
| <management-config> |
Required |
Contains the configuration information for the Coherence Management Framework. |
| <security-config> |
Optional |
Contains the configuration information for the Coherence Security Framework. |
| <license-config> |
Optional |
Contains the edition and operational mode configuration. |
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
configurable-cache-factory-config
Used in: coherence.
Elements
The following table describes the elements you can define within the configurable-cache-factory-config element.
| Element |
Required/Optional |
Description |
| <class-name> |
Required |
Specifies the name of a Java class that provides the cache configuration factory.
Default value is com.tangosol.net.DefaultConfigurableCacheFactory. |
| <init-params> |
Optional |
Contains one or more initialization parameter(s) for a cache configuration factory class which implements the com.tangosol.run.xml.XmlConfigurable interface.
For the default cache configuration factory class (DefaultConfigurableCacheFactory) the parameters are specified as follows:
<init-param>
<param-type>java.lang.String</param-type>
<param-value system-property="tangosol.coherence.cacheconfig">
coherence-cache-config.xml
</param-value>
</init-param>
Preconfigured override is tangosol.coherence.cacheconfig.
Unless an absolute or relative path is specified, such as with ./path/to/config.xml, the application's classpath will be used to find the specified descriptor. |
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
filters
Used in: cluster-config.
Description
Data transformation filters can be used by services to apply a custom transformation on data being transfered between cluster nodes. This can be used for instance to compress or encrypt Coherence network traffic.
Implementation
Data transformation filters are implementations of the com.tangosol.util.WrapperStreamFactory interface.
| Data transformation filters are not related to com.tangosol.util.Filter, which is part of the Coherence API for querying caches. |
Elements
The following table describes the elements you can define within each filter element.
| Element |
Required/Optional |
Description |
| <filter-name> |
Required |
Specifies the canonical name of the filter. This name is unique within the cluster.
For example: gzip.
The content override attributes id can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document. |
| <filter-class> |
Required |
Specifies the class name of the filter implementation. This class must have a zero-parameter public constructor and must implement the com.tangosol.util.WrapperStreamFactory interface. |
| <init-params> |
Optional |
Specifies initialization parameters, for configuring filters which implement the com.tangosol.run.xml.XmlConfigurable interface.
For example when using a com.tangosol.net.CompressionFilter the parameters are specified as follows:
<init-param>
<param-name>strategy</param-name>
<param-value>gzip</param-value>
</init-param>
<init-param>
<param-name>level</param-name>
<param-value>default</param-value>
</init-param>
For more information on the parameter values for the standard filters refer to, refer to Compression Filter Parameters, Symmetric Encryption Filter Parameters and PKCS Encryption Filter Parameters. |
The content override attributes xml-override and id can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
flow-control
Used in: packet-delivery.
Description
The flow-control element contains configuration information related to packet throttling and remote GC detection.
Remote GC Detection
Remote Pause detection allows Coherence to detect and react to a cluster node becoming unresponsive (likely due to a long GC). Once a node is marked as paused, packets addressed to it will be sent at a lower rate until the node resumes responding. This remote GC detection is used to avoid flooding a node while it is incapable of responding.
Packet Throttling
Flow control allows Coherence to dynamically adjust the rate at which packets are transmitted to a given cluster node based on point to point transmission statistics.
Elements
The following table describes the elements you can define within the flow-control element.
| Element |
Required/Optional |
Description |
| <enabled> |
Optional |
Specifies if flow control is enabled. Default is true |
| <pause-detection> |
Optional |
Defines the number of packets that will be resent to an unresponsive cluster node before assuming that the node is paused. |
| <outstanding-packets> |
Optional |
Defines the number of unconfirmed packets that will be sent to a cluster node before packets addressed to that node will be deferred. |
host-range
Used in: authorized-hosts.
Description
Specifies a range of unicast addresses of nodes which are allowed to join the cluster.
Elements
The following table describes the elements you can define within each host-range element.
| Element |
Required/Optional |
Description |
| <from-address> |
Required |
Specifies the starting IP address for a range of host addresses.
For example: 198.168.1.1. |
| <to-address> |
Required |
Specifies to-address element specifies the ending IP address (inclusive) for a range of hosts.
For example: 198.168.2.255. |
The content override attributes id can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
incoming-message-handler
Used in: cluster-config.
Description
The incoming-message-handler assembles UDP packets into logical messages and dispatches them to the appropriate Coherence service for processing.
Elements
The following table describes the elements you can define within the incoming-message-handler element.
| Element |
Required/Optional |
Description |
| <maximum-time-variance> |
Required |
Specifies the maximum time variance between sending and receiving broadcast Messages when trying to determine the difference between a new cluster Member's system time and the cluster time.
The smaller the variance, the more certain one can be that the cluster time will be closer between multiple systems running in the cluster; however, the process of joining the cluster will be extended until an exchange of Messages can occur within the specified variance.
Normally, a value as small as 20 milliseconds is sufficient, but with heavily loaded clusters and multiple network hops it is possible that a larger value would be necessary.
Default value is 16. |
| <use-nack-packets> |
Required |
Specifies whether the packet receiver will use negative acknowledgments (packet requests) to pro-actively respond to known missing packets. See notification-queueing for additional details and configuration.
Legal values are true or false.
Default value is true. |
| <priority> |
Required |
Specifies a priority of the incoming message handler execution thread.
Legal values are from 1 to 10.
Default value is 7. |
| <packet-pool> |
Required |
Specifies how many incoming packets Coherence will buffer before blocking. |
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
init-param
Used in: init-params.
Description
Defines an individual initialization parameter.
Elements
The following table describes the elements you can define within the init-param element.
| Element |
Required/Optional |
Description |
| <param-name> |
Optional |
Specifies the name of the parameter passed to the class. The param-type or param-name must be specified.
For example: thread-count.
For more information on the pre-defined parameter values available for the specific elements , refer to Parameters. |
| <param-type> |
Optional |
Specifies the data type of the parameter passed to the class. The param-type or param-name must be specified.
For example: int |
| <param-value> |
Required |
Specifies the value passed in the parameter.
For example: 8.
For more information on the pre-defined parameter values available for the specific elements, refer to Parameters. |
The content override attributes id can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
init-params
Used in: filters, services, configurable-cache-factory-config, access-controller and callback-handler.
Description
Defines a series of initialization parameters.
Elements
The following table describes the elements you can define within the init-params element.
| Element |
Required/Optional |
Description |
| <init-param> |
Optional |
Defines an individual initialization parameter. |
license-config
Used in: coherence.
The following table describes the elements you can define within the license-config element.
| Element |
Required/Optional |
Description |
| <edition-name> |
Optional |
Specifies the product edition that the member will utilize. This allows multiple product editions to be used within the same cluster, with each member specifying the edition that it will be using.
Valid values are: "GE" (Grid Edition), "GE-DC" (Grid Edition, supporting only Data Clients), "EE" (Enterprise Edition), "SE" (Standard Edition), "RTC" (Real-Time Client), "DC" (Data Client).
Default value is GE. |
| <license-mode> |
Optional |
Specifies whether the product is being used in an development or production mode.
Valid values are "prod" (Production), and "dev" (Development).
Note: This value cannot be overridden in tangosol-coherence-override.xml. It must be specified in tangosol-coherence.xml or (preferably) supplied as system property tangosol.coherence.mode on the java command line.
Default value is dev. |
logging-config
Used in: coherence.
Elements
The following table describes the elements you can define within the logging-config element.
| Element |
Required/Optional |
Description |
| <destination> |
Required |
Specifies the output device used by the logging system.
Legal values are:
stdout
stderr
jdk
log4j
a file name
Default value is stderr.
If jdk is specified as the destination, Coherence must be run using JDK 1.4 or later; likewise, if log4j is specified, the Log4j libraries must be in the classpath. In both cases, the appropriate logging configuration mechanism (system properties, property files, etc.) should be used to configure the JDK/Log4j logging libraries.
Preconfigured override is tangosol.coherence.log |
| <severity-level> |
Required |
Specifies which logged messages will be output to the log destination.
Legal values are:
0 - only output without a logging severity level specified will be logged
1 - all the above plus errors
2 - all the above plus warnings
3 - all the above plus informational messages
4-9 - all the above plus internal debugging messages (the higher the number, the more the messages)
-1 - no messages
Default value is 3.
Preconfigured override is tangosol.coherence.log.level |
| <message-format> |
Required |
Specifies how messages that have a logging level specified will be formatted before passing them to the log destination.
The value of the message-format element is static text with the following replaceable parameters:
{date} - the date/time format (to a millisecond) at which the message was logged
{version} - the Oracle Coherence exact version and build details
{level} - the logging severity level of the message
{thread} - the thread name that logged the message
{member} - the cluster member id (if the cluster is currently running)
{location} - the fully qualified cluster member id: cluster-name, site-name, rack-name, machine-name, process-name and member-name (if the cluster is currently running)
{role} - the specified role of the cluster member
{text} - the text of the message
Default value is:
{date} Oracle Coherence {version} <{level}> (thread={thread}, member={member}): {text} |
| <character-limit> |
Required |
Specifies the maximum number of characters that the logger daemon will process from the message queue before discarding all remaining messages in the queue. Note that the message that caused the total number of characters to exceed the maximum will NOT be truncated, and all messages that are discarded will be summarized by the logging system with a single log entry detailing the number of messages that were discarded and their total size. The truncation of the logging is only temporary, since once the queue is processed (emptied), the logger is reset so that subsequent messages will be logged.
The purpose of this setting is to avoid a situation where logging can itself prevent recovery from a failing condition. For example, with tight timings, logging can actually change the timings, causing more failures and probably more logging, which becomes a vicious cycle. A limit on the logging being done at any one point in time is a "pressure valve" that prevents such a vicious cycle from occurring. Note that logging occurs on a dedicated low-priority thread to even further reduce its impact on the critical portions of the system.
Legal values are positive integers or zero. Zero implies no limit.
Default value is 4096.
Preconfigured override is tangosol.coherence.log.limit |
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
management-config
Used in: coherence.
Elements
The following table describes the elements you can define within the management-config element.
| Element |
Required/Optional |
Description |
| <domain-name> |
Required |
Specifies the name of the JMX domain used to register MBeans exposed by the Coherence Management Framework. |
| <managed-nodes> |
Required |
Specifies whether or not a cluster node's JVM has an [in-process] MBeanServer and if so, whether or not this node allows management of other nodes' managed objects.
Legal values are:
Default value is none.
Preconfigured override is tangosol.coherence.management |
| <allow-remote-management> |
Required |
Specifies whether or not this cluster node exposes its managed objects to remote MBeanServer(s).
Legal values are: true or false.
Default value is false.
Preconfigured override is tangosol.coherence.management.remote |
| <read-only> |
Required |
Specifies whether or not the managed objects exposed by this cluster node allow operations that modify run-time attributes.
Legal values are: true or false.
Default value is false.
Preconfigured override is tangosol.coherence.management.readonly |
| <service-name> |
Required |
Specifies the name of the Invocation Service used for remote management.
This element is used only if allow-remote-management is set to true. |
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
member-identity
Used in: cluster-config.
The member-identity element contains detailed identity information that is useful for defining the location and role of the cluster member.
Elements
The following table describes the elements you can define within the member-identity element.
| Element |
Required/Optional |
Description |
| <cluster-name> |
Optional |
The cluster-name element contains the name of the cluster. In order to join the cluster all members must specify the same cluster name.
It is strongly suggested that cluster-name be specified for production systems, thus preventing accidental cluster discovery among applications.
Preconfigured override is tangosol.coherence.cluster |
| <site-name> |
Optional |
The site-name element contains the name of the geographic site that the member is hosted at. For WAN clustering, this value identifies the datacenter within which the member is located, and can be used as the basis for intelligent routing, load balancing and disaster recovery planning (i.e. the explicit backing up of data on separate geographic sites). The name is also useful for displaying management information (e.g. JMX) and interpreting log entries.
It is optional to provide a value for this element. Deployments that spread across more than one geographic site should specify a site-name value.
Preconfigured override is tangosol.coherence.site. |
| <rack-name> |
Optional |
The rack-name element contains the name of the location within a geographic site that the member is hosted at. This is often a cage, rack or bladeframe identifier, and can be used as the basis for intelligent routing, load balancing and disaster recovery planning (i.e. the explicit backing up of data on separate bladeframes). The name is also useful for displaying management information (e.g. JMX) and interpreting log entries.
It is optional to provide a value for this element. Large scale deployments should always specify a rack-name value.
Preconfigured override is tangosol.coherence.rack. |
| <machine-name> |
Optional |
The machine-name element contains the name of the physical server that the member is hosted on. This is often the same name as the server identifies itself as (e.g. its HOSTNAME, or its name as it appears in a DNS entry). If provided, the machine-name is used as the basis for creating a machine-id, which in turn is used to guarantee that data are backed up on different physical machines to prevent single points of failure (SPOFs). The name is also useful for displaying management information (e.g. JMX) and interpreting log entries.
It is optional to provide a value for this element. However, it is strongly encouraged that a name always be provided.
Preconfigured override is tangosol.coherence.machine. |
| <process-name> |
Optional |
The process-name element contains the name of the process (JVM) that the member is hosted on. This name makes it possible to easily differentiate among multiple JVMs running on the same machine. The name is also useful for displaying management information (e.g. JMX) and interpreting log entries.
It is optional to provide a value for this element. Often, a single member will exist per JVM, and in that situation this name would be redundant.
Preconfigured override is tangosol.coherence.process. |
| <member-name> |
Optional |
The member-name element contains the name of the member itself. This name makes it possible to easily differentiate among members, such as when multiple members run on the same machine (or even within the same JVM).The name is also useful for displaying management information (e.g. JMX) and interpreting log entries.
It is optional to provide a value for this element. However, it is strongly encouraged that a name always be provided.
Preconfigured override is tangosol.coherence.member. |
| <role-name> |
Optional |
The role-name element contains the name of the member role. This name allows an application to organize members into specialized roles, such as cache servers and cache clients. The name is also useful for displaying management information (e.g. JMX) and interpreting log entries.
It is optional to provide a value for this element. However, it is strongly encouraged that a name always be provided.
Preconfigured override is tangosol.coherence.role. |
| <priority> |
Optional |
The priority element specifies a priority of the corresponding member.
The priority is used as the basis for determining tie-breakers between members. If a condition occurs in which one of two members will be ejected from the cluster, and in the rare case that it is not possible to objectively determine which of the two is at fault and should be ejected, then the member with the lower priority will be ejected.
Valid values are from 1 to 10.
Preconfigured override is tangosol.coherence.priority. |
multicast-listener
Used in: cluster-config.
Description
Specifies the configuration information for the Multicast listener. This element is used to specify the address and port that a cluster will use for cluster wide and point-to-multipoint communications. All nodes in a cluster must use the same multicast address and port, whereas distinct clusters on the same network should use different multicast addresses.
Multicast-Free Clustering
By default Coherence uses a multicast protocol to discover other nodes when forming a cluster. If multicast networking is undesirable, or unavailable in your environment, the well-known-addresses feature may be used to eliminate the need for multicast traffic. If you are having difficulties in establishing a cluster via multicast, see the Multicast Test.
Elements
The following table describes the elements you can define within the multicast-listener element.
| Element |
Required/Optional |
Description |
| <address> |
Required |
Specifies the multicast IP address that a Socket will listen or publish on.
Legal values are from 224.0.0.0 to 239.255.255.255.
Default value depends on the release and build level and typically follows the convention of {build}.{major version}.{minor version}.{patch}. For example, for Coherence Release 2.2 build 255 it is 225.2.2.0.
Preconfigured override is tangosol.coherence.clusteraddress |
| <port> |
Required |
Specifies the port that the Socket will listen or publish on.
Legal values are from 1 to 65535.
Default value depends on the release and build level and typically follows the convention of {version}+{{{build}. For example, for Coherence Release 2.2 build 255 it is 22255.
Preconfigured override is tangosol.coherence.clusterport |
| <time-to-live> |
Required |
Specifies the time-to-live setting for the multicast. This determines the maximum number of "hops" a packet may traverse, where a hop is measured as a traversal from one network segment to another via a router.
Legal values are from from 0 to 255.
| For production use, this value should be set to the lowest integer value that works. On a single server cluster, it should work at 0; on a simple switched backbone, it should work at 1; on an advanced backbone with intelligent switching, it may require a value of 2 or more. Setting the value too high can use unnecessary bandwidth on other LAN segments and can even cause the OS or network devices to disable multicast traffic. While a value of 0 is meant to keep packets from leaving the originating machine, some OSs do not implement this correctly, and the packets may in fact be transmitted on the network. |
Default value is 4.
Preconfigured override is tangosol.coherence.ttl |
| <packet-buffer> |
Required |
Specifies how many incoming packets the OS will be requested to buffer. |
| <priority> |
Required |
Specifies a priority of the multicast listener execution thread.
Legal values are from 1 to 10.
Default value is 8. |
| <join-timeout-milliseconds> |
Required |
Specifies the number of milliseconds that a new member will wait without finding any evidence of a cluster before starting its own cluster and electing itself as the senior cluster member.
Legal values are from 1 to 1000000.
Note: For production use, the recommended value is 30000.
Default value is 6000. |
| <multicast-threshold-percent> |
Required |
Specifies the threshold percentage value used to determine whether a packet will be sent via unicast or multicast. It is a percentage value and is in the range of 1% to 100%. In a cluster of "n" nodes, a particular node sending a packet to a set of other (i.e. not counting self) destination nodes of size "d" (in the range of 0 to n-1), the packet will be sent multicast if and only if the following both hold true:
- The packet is being sent over the network to more than one other node, i.e. (d > 1).
- The number of nodes is greater than the threshold,i.e. (d > (n-1) * (threshold/100)).
Setting this value to 1 will allow the implementation to use multicast for basically all multi-point traffic. Setting it to 100 will force the implementation to use unicast for all multi-point traffic except for explicit broadcast traffic (e.g. cluster heartbeat and discovery) because the 100% threshold will never be exceeded. With the setting of 25 the implementation will send the packet using unicast if it is destined for less than one-fourth of all nodes, and send it using multicast if it is destined for the one-fourth or more of all nodes.
Note: This element is only used if the well-known-addresses element is empty.
Legal values are from 1 to 100.
Default value is 25.
|
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
notification-queueing
Used in: packet-publisher.
Description
The notification-queueing element is used to specificy the timing of notifications packets sent to other cluster nodes. Notification packets are used to acknowledge the receipt of packets which require confirmation.
Batched Acknowledgments
Rather then sending an individual ACK for each received packet which requires confirmation, Coherence will batch a series of acknowledgments for a given sender into a single ACK. The ack-delay-milliseconds specifies the maximum amount of time that an acknowledgment will be delayed before an ACK notification is sent. By batching the acknowledgments Coherence avoids wasting network bandwidth with many small ACK packets.
Negative Acknowledgments
When enabled cluster nodes will utilize packet ordering to perform early packet loss detection. This allows Coherence to identify a packet as likely being lost and retransmit it well before the packets scheduled resend time.
Elements
The following table describes the elements you can define within the notification-queueing element.
| Element |
Required/Optional |
Description |
| <ack-delay-milliseconds> |
Required |
Specifies the maximum number of milliseconds that the packet publisher will delay before sending an ACK packet. The ACK packet may be transmitted earlier if number of batched acknowledgments fills the ACK packet.
This value should be substantially lower then the remote node's packet-delivery resend timeout, to allow ample time for the ACK to be received and processed by the remote node before the resend timeout expires.
Default value is 64. |
| <nack-delay-milliseconds> |
Required |
Specifies the number of milliseconds that the packet publisher will delay before sending a NACK packet.
Default value is 1. |
outgoing-message-handler
Used in: cluster-config.
Description
The outgoing-message-handler splits logical messages into packets for transmission on the network, and enqueues them on the packet-publisher.
Elements
The following table describes the elements you can define within the outgoing-message-handler element.
| Element |
Required/Optional |
Description |
| <use-daemon> |
Optional |
Specifies whether or not a daemon thread will be created to perform the outgoing message handling.
Deprecated as of Coherence 3.2, splitting messages into packets is always performed on the message originators thread. |
| <use-filters> |
Optional |
Contains the list of filter names to be used by this outgoing message handler.
For example, specifying use-filter as follows
<use-filters>
<filter-name>gzip</filter-name>
</use-filters>
will activate gzip compression for all network messages, which can help substantially with WAN and low-bandwidth networks. |
| <priority> |
Required |
Specifies a priority of the outgoing message handler execution thread.
Deprecated as of Coherence 3.2. |
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
outstanding-packets
Used in: flow-control.
Description
Defines the number of unconfirmed packets that will be sent to a cluster node before packets addressed to that node will be deferred. This helps to prevent the sender from flooding the recipient's network buffers.
Auto Tunning
The value may be specified as either an explicit number via the maximum-packets element, or as a range by using both the maximum-packets and minimum-packets elements. When a range is specified, this setting will be dynamically adjusted based on network statistics.
Elements
The following table describes the elements you can define within the outstanding-packets element.
| Element |
Required/Optional |
Description |
| <maximum-packets> |
Optional |
The maximum number of unconfirmed packets that will be sent to a cluster node before packets addressed to that node will be deferred. It is recommended that this value not be set below 256. Default is 4096. |
| <minimum-packets> |
Optional |
The lower bound on the range for the number of unconfirmed packets that will be sent to a cluster node before packets addressed to that node will be deferred. It is recommended that this value not be set below 16. Default is 64. |
packet-buffer
Used in: unicast-listener, multicast-listener, packet-publisher.
Description
Specifies the size of the OS buffer for datagram sockets.
Performance Impact
Large inbound buffers help insulate the Coherence network layer from JVM pauses caused by the Java Garbage Collector. While the JVM is paused, Coherence is unable to dequeue packets from any inbound socket. If the pause is long enough to cause the packet buffer to overflow, the packet reception will be delayed as the the originating node will need to detect the packet loss and retransmit the packet(s).
It's just a hint
The OS will only treat the specified value as a hint, and is not required to allocate the specified amount. In the event that less space is allocated then requested Coherence will issue a warning and continue to operate with the constrained buffer, which may degrade performance. See http://forums.tangosol.com/thread.jspa?threadID=616 for details on configuring your OS to allow larger buffers.
Elements
The following table describes the elements you can define within the packet-buffer element.
| Element |
Required/Optional |
Description |
| <maximum-packets> |
Required |
For unicast-listener, multicast-listener and packet-publisher: Specifies the number of packets of maximum size that the datagram socket will be asked to size itself to buffer. See SO_SNDBUF and SO_RCVBUF. Actual buffer sizes may be smaller if the underlying socket implementation cannot support more than a certain size. Defaults are 32 for publishing, 64 for multicast listening, and 1428 for unicast listening. |
packet-delivery
Used in: packet-publisher.
Description
Specifies timing and transmission rate parameters related to packet delivery.
Death Detection
The timeout-milliseconds and heartbeat-milliseconds are used in detecting the death of other cluster nodes.
Elements
The following table describes the elements you can define within the packet-delivery element.
| Element |
Required/Optional |
Description |
| <resend-milliseconds> |
Required |
For packets which require confirmation, specifies the minimum amount of time in milliseconds to wait for a corresponding ACK packet, before resending a packet.
Default value is 200. |
| <timeout-milliseconds> |
Required |
For packets which require confirmation, specifies the maximum amount of time, in milliseconds, that a packet will be resent. After this timeout expires Coherence will make a determination if the recipient is to be considered "dead". This determination takes additional data into account, such as if other nodes are still able to communicate with the recipient.
Default value is 60000.
Note: For production use, the recommended value is the greater of 60000 and two times the maximum expected full GC duration. |
| <heartbeat-milliseconds> |
Required |
Specifies the interval between heartbeats. Each member issues a unicast heartbeat, and the most senior member issues the cluster heartbeat, which is a broadcast message. The heartbeat is used by the tcp-ring-listener as part of fast death detection.
Default value is 1000. |
| <flow-control> |
Optional |
Configures per-node packet throttling and remote GC detection. |
| <packet-bundling> |
Optional |
Configures how aggressively Coherence will attempt to maximize packet utilization. |
packet-pool
Used in: incoming-message-handler, packet-publisher.
Description
Specifies the number of packets which Coherence will internally maintain for use in tranmitting and receving UDP packets. Unlike the packet-buffers these buffers are managed by Coherence rather then the OS, and allocated on the JVM's heap.
Performance Impact
The packet pools are used as a reusable buffer between Coherence network services. For packet transmission, this defines the maximum number of packets which can be queued on the packet-speaker before the packet-publisher must block. For packet receiption, this defines the number of packets which can be queued on the incoming-message-handler before the unicast, and multicast must block.
Elements
The following table describes the elements you can define within the packet-pool element.
| Element |
Required/Optional |
Description |
| <maximum-packets> |
Required |
The maximum number of reusable packets to be utilized by the services responsible for publishing and receiving. The pools are intially small, and will grow on demand up to the specified limits. Defaults are 2048 for transmitting and receiving. |
packet-publisher
Used in: cluster-config.
Description
Specifies configuration information for the Packet publisher, which manages network data transmission.
Reliable packet delivery
The Packet publisher is responsible for ensuring that transmitted packets reach the destination cluster node. The publisher maintains a set of packets which are waiting to be acknowledged, and if the ACK does not arrive by the packet-delivery resend timeout, the packet will be retransmitted. The recipient node will delay the ACK, in order to batch a series of ACKs into a single response.
Throttling
The rate at which the publisher will accept and transmit packet may be controlled via the traffic-jam and packet-delivery/flow-control settings. Throttling may be necessary when dealing with slow networks, or small packet-buffers.
Elements
The following table describes the elements you can define within the packet-publisher element.
| Element |
Required/Optional |
Description |
| <packet-size> |
Required |
Specifies the UDP packet sizes to utilize. |
| <packet-delivery> |
Required |
Specifies timing parameters related to reliable packet delivery. |
| <notification-queueing> |
Required |
Contains the notification queue related configuration info. |
| <burst-mode> |
Required |
Specifies the maximum number of packets the publisher may transmit without pausing. |
| <traffic-jam> |
Required |
Specifies the maximum number of packets which can be enqueued on the publisher before client threads block. |
| <packet-buffer> |
Required |
Specifies how many outgoing packets the OS will be requested to buffer. |
| <packet-pool> |
Required |
Specifies how many outgoing packets Coherence will buffer before blocking. |
| <priority> |
Required |
Specifies a priority of the packet publisher execution thread.
Legal values are from 1 to 10.
Default value is 6. |
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
packet-size
Used in: packet-publisher.
Description
The packet-size element specifies the maximum and preferred UDP packet sizes. All cluster nodes must use identical maximum packet sizes. For optimal network utilization this value should be 32 bytes less then the network MTU.
| When specifying a UDP packet size larger then 1024 bytes on Microsoft Windows a registry setting must be adjusted to allow for optimal transmission rates. See the Performance Tuning guide for details. |
Elements
The following table describes the elements you can define within the packet-size element.
| Element |
Required/Optional |
Description |
| <maximum-length> |
Required |
Specifies the maximum size, in bytes, of the UDP packets that will be sent and received on the unicast and multicast sockets.
This value should be at least 512; recommended value is 1468 for 100Mb, and 1Gb Ethernet. This value must be identical on all cluster nodes.
Note: Some network equipment cannot handle packets larger than 1472 bytes (IPv4) or 1468 bytes (IPv6), particularly under heavy load. If you encounter this situation on your network, this value should be set to 1472 or 1468 respectively.
The recommended values is 32 bytes less then the network MTU setting.
Default value is 1468. |
| <preferred-length> |
Required |
Specifies the preferred size, in bytes, of UDP packets that will be sent and received on the unicast and multicast sockets.
This value should be at least 512 and cannot be greater than the maximum-length value; it is recommended to set the value to the same as the maximum-length value.
Default value is 1468. |
packet-speaker
Used in: cluster-config.
Description
Specifies configuration information for the Packet speaker, used for network data transmission.
Offloaded Transmission
The Packet speaker is responsible for sending packets on the network. The speaker is utilized when the Packet publisher detects that a network send operation is likely to block. This allows the Packet publisher to avoid blocking on IO and continue to prepare outgoing packets. The Publisher will dynamically choose whether or not to utilize the speaker as the packet load changes.
Elements
The following table describes the elements you can define within the packet-speaker element.
| Element |
Required/Optional |
Description |
| <volume-threshold> |
Optional |
Specifies the packet load which must be present for the speaker to be activated. |
| <priority> |
Required |
Specifies a priority of the packet speaker execution thread.
Legal values are from 1 to 10.
Default value is 8. |
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
pause-detection
Used in: flow-control.
Description
Remote Pause detection allows Coherence to detect and react to a cluster node becoming unresponsive (likely due to a long GC). Once a node is marked as paused, packets addressed to it will be sent at a lower rate until the node resumes responding. This remote GC detection is used to avoid flooding a node while it is incapable of responding.
Elements
The following table describes the elements you can define within the pause-detection element.
| Element |
Required/Optional |
Description |
| <maximum-packets> |
Optional |
The maximum number of packets that will be resent to an unresponsive cluster node before assuming that the node is paused. Specifying a value of 0 will disable pause detection. Default is 16. |
security-config
Used in: coherence.
Elements
The following table describes the elements you can define within the security-config element.
| Element |
Required/Optional |
Description |
| <enabled> |
Required |
Specifies whether the security features are enabled. All other configuration elements in the security-config group will be verified for validity and used if and only if the value of this element is true.
Legal values are true or false.
Default value is false.
Preconfigured override is tangosol.coherence.security |
| <login-module-name> |
Required |
Specifies the name of the JAAS LoginModule that should be used to authenticate the caller. This name should match a module in a configuration file will be used by the JAAS (for example specified via the -Djava.security.auth.login.config Java command line attribute).
For details please refer to the Sun Login Module Developer's Guide. |
| <access-controller> |
Required |
Contains the configuration information for the class that implements com.tangosol.net.security.AccessController interface, which will be used by the Coherence Security Framework to check access rights for clustered resources and encrypt/decrypt node-to-node communications regarding those rights. |
| <callback-handler> |
Optional |
Contains the configuration information for the class that implements javax.security.auth.callback.CallbackHandler interace which will be called if an attempt is made to access a protected clustered resource when there is no identity associated with the caller. |
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
services
Used in: cluster-config.
Description
Specifies the configuration for Coherence services.
Service Components
The types of services which can be configured includes:
- ReplicatedCache - A cach service which maintains copies of all cache entries on all cluster nodes which run the service.
- ReplicatedCache.Optimistic - A version of the ReplicatedCache which uses optimistic locking.
- DistributedCache - A cache service which evenly partitions cache entries across the cluster nodes which run the service.
- SimpleCache - A version of the ReplicatedCache which lacks concurrent control.
- LocalCache - A cache service for caches where all cache entries reside in a single cluster node.
- InvocationService - A service used for performing custom operations on remote cluster nodes.
Elements
The following table describes the elements you can define for each service element.
| Element |
Required/Optional |
Description |
| <service-type> |
Required |
Specifies the canonical name for a service, allowing the service to be referenced from the service-name element in cache configuration caching-schemes. |
| <service-component> |
Required |
Specifies either the fully qualified class name of the service or the relocatable component name relative to the base Service component.
Legal values are:
- ReplicatedCache
- ReplicatedCache.Optimistic
- DistributedCache
- SimpleCache
- LocalCache
- InvocationService
|
| <use-filters> |
Optional |
Contains the list of filter names to be used by this service.
For example, specifying use-filter as follows
<use-filters>
<filter-name>gzip</filter-name>
</use-filters>
will activate gzip compression for the network messages used by this service, which can help substantially with WAN and low-bandwidth networks. |
| <init-params> |
Optional |
Specifies the initialization parameters that are specific to each service-component.
For more service specific parameter information see:
|
The content override attributes xml-override and id can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
shutdown-listener
Used in: cluster-config.
Description
Specifies the action a cluster node should take upon receiving an external shutdown request. External shutdown includes the "kill" command on Unix and "Ctrl-C" on Windows and Unix.
Elements
The following table describes the elements you can define within the shutdown-listener element.
| Element |
Required/Optional |
Description |
| <enabled> |
Required |
Specifies the type of action to take upon an external JVM shutdown.
Legal Values:
- none - perform no explicit shutdown actions
- force - perform "hard-stop" the node by calling Cluster.stop()
- graceful - perform a "normal" shutdown by calling Cluster.shutdown()
- true - same as force
- false - same as none
Note: For production use, the suggested value is none unless testing has verified that the behavior on external shutdown is exactly what is desired.
Default value is force.
Preconfigured override is tangosol.coherence.shutdownhook |
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
socket-address
Used in: well-known-addresses, remote-addresses.
Elements
The following table describes the elements you can define within the socket-address element.
| Element |
Required/Optional |
Description |
| <address> |
Required |
Specifies the IP address that a Socket will listen or publish on.
Note: The localhost setting may not work on systems that define localhost as the loopback address; in that case, specify the machine name or the specific IP address. |
| <port> |
Required |
Specifies the port that the Socket will listen or publish on.
Legal values are from 1 to 65535. |
tcp-ring-listener
Used in: cluster-config.
Description
The TCP-ring provides a means for fast death detection of another node within the cluster. When enabled the cluster nodes form a single "ring" of TCP connections spanning the entire cluster. A cluster node is able to utilize the TCP connection to detect the death of another node within a heartbeat interval (default one second). If disabled the cluster node must rely on detecting that another node has stopped responding to UDP packets for a considerately longer interval. Once the death has been detected it is communicated to all other cluster nodes.
Elements
The following table describes the elements you can define within the tcp-ring-listener element.
| Element |
Required/Optional |
Description |
| <enabled> |
Required |
Specifies whether the tcp ring listener should be enabled to defect node failures faster.
Legal values are true and false.
Default value is true.
Preconfigured override is tangosol.coherence.tcpring |
| <maximum-socket-closed-exceptions> |
Required |
Specifies the maximum number of tcp ring listener exceptions that will be tolerated before a particular member is considered really gone and is removed from the cluster.
This value is used only if the value of tcp-ring-listener/enabled is true.
Legal values are integers greater than zero.
Default value is 2. |
| <priority> |
Required |
Specifies a priority of the tcp ring listener execution thread.
Legal values are from 1 to 10.
Default value is 6. |
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
traffic-jam
Used in: packet-publisher.
Description
The traffic-jam element is used to control the rate at which client threads enqueue packets for the Packet publisher to transmit on the network. Once the limit is exceeded any client thread will be forced to pause until the number of outstanding packets drops below the specified limit. To limit the rate at which the Publisher transmits packets see the flow-control, and burst-mode elements.
Tuning
Specifying a limit which is to low, or a pause which is to long may result in the publisher transmitting all pending packets, and being left without packets to send. An ideal value will ensure that the publisher is never left without work to do, but at the same time prevent the queue from growing uncontrollably. It is therefore recommended that the pause remain quite short (10ms or under), and that the limit on the number of packets be kept high (i.e. > 5000). As of Coherence 3.2 a warning will be periodically logged if this condition is detected.
Traffic Jam and Flow Control
When flow-control is enabled the traffic-jam operates in a point-to-point mode, only blocking a send if the recipient has too many packets outstanding. It is recommended that the traffic-jam/maximum-packets value be greater then the flow-control/outstanding-packets/maximum-packets value. When flow-control is disabled the traffic-jam will take all outstanding packets into account.
Elements
The following table describes the elements you can define within the traffic-jam element.
| Element |
Required/Optional |
Description |
| <maximum-packets> |
Required |
Specifies the maximum number of pending packets that the Publisher will tolerate before determining that it is clogged and must slow down client requests (requests from local non-system threads). Zero means no limit. This property prevents most unexpected out-of-memory conditions by limiting the size of the resend queue.
Default value is 8192. |
| <pause-milliseconds> |
Required |
Number of milliseconds that the Publisher will pause a client thread that is trying to send a message when the Publisher is clogged. The Publisher will not allow the message to go through until the clog is gone, and will repeatedly sleep the thread for the duration specified by this property.
Default value is 10. |
unicast-listener
Used in: cluster-config.
Description
Specifies the configuration information for the Unicast listener. This element is used to specify the address and port that a cluster node will bind to, in order to listen for point-to-point cluster communications.
Automatic Address Settings
By default Coherence will attempt to obtain the IP to bind to using the java.net.InetAddress.getLocalHost() call. On machines with multiple IPs or NICs you may need to explicitly specify the address. Additionally if the specified port is already in use, Coherence will by default auto increment the port number until the binding succeeds.
Multicast-Free Clustering
By default Coherence uses a multicast protocol to discover other nodes when forming a cluster. If multicast networking is undesirable, or unavailable in your environment, the well-known-addresses feature may be used to eliminate the need for multicast traffic. If you are having difficulties in establishing a cluster via multicast, see the Multicast Test.
Elements
The following table describes the elements you can define within the unicast-listener element.
| Element |
Required/Optional |
Description |
| <well-known-addresses> |
Optional |
Contains a list of "well known" addresses (WKA) that are used by the cluster discovery protocol in place of multicast broadcast. |
| <machine-id> |
Required |
Specifies an identifier that should uniquely identify each server machine. If not specified, a default value is generated from the address of the default network interface.
The machine id for each machine in the cluster can be used by cluster services to plan for failover by making sure that each member is backed up by a member running on a different machine. |
| <address> |
Required |
Specifies the IP address that a Socket will listen or publish on.
Note: The localhost setting may not work on systems that define localhost as the loopback address; in that case, specify the machine name or the specific IP address.
Default value is localhost.
Preconfigured override is tangosol.coherence.localhost |
| <port> |
Required |
Specifies the port that the Socket will listen or publish on.
Legal values are from 1 to 65535.
Default value is 8088.
Preconfigured override is tangosol.coherence.localport |
| <port-auto-adjust> |
Required |
Specifies whether or not the unicast port will be automatically incremented if the specified port cannot be bound to because it is already in use.
Legal values are true or false.
It is recommended that this value be configured to false for production environments.
Default value is true.
Preconfigured override is tangosol.coherence.localport.adjust |
| <packet-buffer> |
Required |
Specifies how many incoming packets the OS will be requested to buffer. |
| <priority> |
Required |
Specifies a priority of the unicast listener execution thread.
Legal values are from 1 to 10.
Default value is 8. |
| <ignore-socket-closed> |
Optional |
Specifies whether or not the unicast listener will ignore socket exceptions that indicate that a Member is unreachable.
Deprecated as of Coherence 3.2. |
| <maximum-socket-closed-exceptions> |
Optional |
Specifies the maximum number of unicast listener exceptions that will be tolerated before a particular member is considered really gone and is removed from the cluster.
Deprecated as of Coherence 3.2. |
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
volume-threshold
Used in: packet-speaker
Description
Specifies the minimum outgoing packet volume which must exist for the speaker daemon to be activated.
Performance Impact
When the packet load is relatively low it may be more efficient for the speaker's operations to be performed on the publisher's thread. When the packet load is high utilizing the speaker allows the publisher to continue preparing packets while the speaker transmits them on the network.
Elements
The following table describes the elements you can define within the packet-speaker element.
| Element |
Required/Optional |
Description |
| <minimum-packets> |
Required |
Specifies the minimum number of packets which must be ready to be sent for the speaker daemon to be activated. A value of 0 will force the speaker to always be used, while a very high value will cause it to never be used. If unspecified, it will be set to match the socket send buffer size, this is the default. |
well-known-addresses
Used in: unicast-listener.
| Use of the Well Known Addresses (WKA) feature is not supported by Caching Edition. If you are having difficulties in establishing a cluster via multicast, see the Multicast Test. |
Description
By default Coherence uses a multicast protocol to discover other nodes when forming a cluster. If multicast networking is undesirable, or unavailable in your environment, the Well Known Addresses feature may be used to eliminate the need for multicast traffic. When in use the cluster is configured with a relatively small list of nodes which are allowed to start the cluster, and which are likely to remain available over the cluster lifetime. There is no requirement for all WKA nodes to be simultaneously active at any point in time. This list is used by all other nodes to find their way into the cluster without the use of multicast, thus at least one well known node must be running for other nodes to be able to join.
| This is not a security-related feature, and does not limit the addresses which are allowed to join the cluster. See the authorized-hosts element for details on limiting cluster membership. |
Example
The following configuration specifies two well-known-addresses, with the default port.
<well-known-addresses>
<socket-address id="1">
<address>192.168.0.100</address>
<port>8088</port>
</socket-address>
<socket-address id="2">
<address>192.168.0.101</address>
<port>8088</port>
</socket-address>
</well-known-addresses>
Elements
The following table describes the elements you can define within the well-known-addresses element.
| Element |
Required/Optional |
Description |
| <socket-address> |
Required |
Specifies a list of "well known" addresses (WKA) that are used by the cluster discovery protocol in place of multicast broadcast. If one or more WKA is specified, for a member to join the cluster it will either have to be a WKA or there will have to be at least one WKA member running. Additionally, all cluster communication will be performed using unicast. If empty or unspecified multicast communications will be used.
Preconfigured overrides are tangosol.coherence.wka and tangosol.coherence.wka.port. |
The content override attribute xml-override can be optionally used to fully or partially override the contents of this element with XML document that is external to the base document.
Cache Configuration
Cache Configuration Elements
Cache Configuration Deployment Descriptor Elements
Description
The cache configuration deployment descriptor is used to specify the various types of caches which can be used within a cluster. For information on configuring cluster communication, and services see the operational descriptor section.
Document Location
The name and location of the descriptor is specified in the operational deployment descriptor and defaults to coherence-cache-config.xml. The default configuration descriptor (packaged in coherence.jar) will be used unless a custom one is found within the application's classpath. It is recommended that all nodes within a cluster use identical cache configuration descriptors.
Document Root
The root element of the configuration descriptor is cache-config, this is where you may begin configuring your caches.
Document Format
The Cache Configuration descriptor should begin with the following DOCTYPE declaration:
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
| Note:
When deploying Coherence into environments where the default character set is EBCDIC rather than ASCII, please make sure that this descriptor file is in ASCII format and is deployed into its runtime environment in the binary format. |
Command Line Override
Oracle Coherence provides a very powerful Command Line Setting Override Feature, which allows for any element defined in this descriptor to be overridden from the Java command line if it has a system-property attribute defined in the descriptor.
Examples
See the various sample cache configurations for usage examples.
Element Index
The following table lists all non-terminal elements which may be used from within a cache configuration.
| Element |
Used In: |
| acceptor-config |
proxy-scheme |
| async-store-manager |
external-scheme, paged-external-scheme |
| backup-storage |
distributed-scheme |
| bdb-store-manager |
external-scheme, paged-external-scheme, async-store-manager |
| cache-config |
root element |
| cache-mapping |
caching-scheme-mapping |
| cache-service-proxy |
proxy-config |
| caching-scheme-mapping |
cache-config |
| caching-schemes |
cache-config |
| class-scheme |
caching-schemes, local-scheme, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, overflow-scheme, read-write-backing-map-scheme, cachestore-scheme, listener |
| cachestore-scheme |
local-scheme, read-write-backing-map-scheme |
| custom-store-manager |
external-scheme, paged-external-scheme, async-store-manager |
| disk-scheme |
caching-schemes |
| distributed-scheme |
caching-schemes, near-scheme, overflow-scheme |
| external-scheme |
caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, overflow-scheme, read-write-backing-map-scheme |
| init-param |
init-params |
| init-params |
class-scheme |
| initiator-config |
remote-cache-scheme, remote-invocation-scheme |
| invocation-scheme |
caching-schemes |
| jms-acceptor |
acceptor-config |
| jms-initiator |
initiator-config |
| key-associator |
distributed-scheme |
| key-partitioning |
distributed-scheme |
| lh-file-manager |
external-scheme, paged-external-scheme, async-store-manager |
| listener |
local-scheme, disk-scheme, external-scheme, paged-external-scheme, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, overflow-scheme, read-write-backing-map-scheme |
| local-scheme |
caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, overflow-scheme, read-write-backing-map-scheme |
| near-scheme |
caching-schemes |
| nio-file-manager |
external-scheme, paged-external-scheme, async-store-manager |
| nio-memory-manager |
external-scheme, paged-external-scheme, async-store-manager |
| operation-bundling |
cachestore-scheme, distributed-scheme, remote-cache-scheme |
| optimistic-scheme |
caching-schemes, near-scheme, overflow-scheme |
| outgoing-message-handler |
acceptor-config, initiator-config |
| overflow-scheme |
caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme, read-write-backing-map-scheme |
| paged-external-scheme |
caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, overflow-scheme, read-write-backing-map-scheme |
| proxy-config |
proxy-scheme |
| proxy-scheme |
caching-schemes |
| read-write-backing-map-scheme |
caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme |
| remote-cache-scheme |
cachestore-scheme, caching-schemes, near-scheme |
| remote-invocation-scheme |
caching-schemes |
| replicated-scheme |
caching-schemes, near-scheme, overflow-scheme |
| tcp-acceptor |
acceptor-config |
| tcp-initiator |
initiator-config |
Parameter Macros
Parameter Macros
Cache Configuration Deployment Descriptor supports parameter 'macros' to minimize custom coding and enable specification of commonly used attributes when configuring class constructor parameters. The macros should be entered enclosed in curly braces as shown below without any quotes or spaces.
The following parameter macros may be specified:
| <param-type> |
<param-value> |
Description |
| java.lang.String |
{cache-name} |
Used to pass the current cache name as a constructor parameter
For example:
<class-name>com.mycompany.cache.CustomCacheLoader</class-name>
<init-params>
<init-param>
<param-type>java.lang.String</param-type>
<param-value>{cache-name}</param-value>
</init-param>
</init-params>
|
| java.lang.ClassLoader |
{class-loader} |
Used to pass the current classloader as a constructor parameter.
For example:
<class-name>com.mycompany.cache.CustomCacheLoader</class-name>
<init-params>
<init-param>
<param-type>java.lang.ClassLoader</param-type>
<param-value>{class-loader}</param-value>
</init-param>
</init-params>
|
| com.tangosol.net.BackingMapManagerContext |
{manager-context} |
Used to pass the current BackingMapManagerContext object as a constructor parameter.
For example:
<class-name>com.mycompany.cache.CustomCacheLoader</class-name>
<init-params>
<init-param>
<param-type>com.tangosol.net.BackingMapManagerContext</param-type>
<param-value>{manager-context}</param-value>
</init-param>
</init-params>
|
| {scheme-ref} |
scheme name |
Instantiates an object defined by the <class-scheme>, <local-scheme> or <file-scheme> with the specified <scheme-name> value and uses it as a constructor parameter.
For example:
<class-scheme>
<scheme-name>dbconnection</scheme-name>
<class-name>com.mycompany.dbConnection</class-name>
<init-params>
<init-param>
<param-name>driver</param-name>
<param-type>String</param-type>
<param-value>org.gjt.mm.mysql.Driver</param-value>
</init-param>
<init-param>
<param-name>url</param-name>
<param-type>String</param-type>
<param-value>jdbc:mysql://dbserver:3306/companydb</param-value>
</init-param>
<init-param>
<param-name>user</param-name>
<param-type>String</param-type>
<param-value>default</param-value>
</init-param>
<init-param>
<param-name>password</param-name>
<param-type>String</param-type>
<param-value>default</param-value>
</init-param>
</init-params>
</class-scheme>
...
<class-name>com.mycompany.cache.CustomCacheLoader</class-name>
<init-params>
<init-param>
<param-type>{scheme-ref}</param-type>
<param-value>dbconnection</param-value>
</init-param>
</init-params>
|
Sample Cache Configurations
Sample Cache Configurations
This page provides a series of simple cache scheme configurations. The samples build upon one another and will often utilize a scheme-ref element to reuse other samples as nested schemes. Cache schemes are specified in the caching-schemes element of the cache configuration descriptor. These samples only specify a minimum number of settings, follow the embedded links to the scheme's documentation to see the full set of options.
Contents
Local caches (accessible from a single JVM)
In-memory cache
NIO in-memory cache
In-memory cache with expiring entries
Size limited in-memory cache
Cache on disk
Size limited cache on disk
Persistent cache on disk
In-memory cache with disk based overflow
Cache of a database
Clustered caches (accessible from multiple JVMs)
Replicated cache
Replicated cache with overflow
Partitioned cache
Partitioned cache with overflow
Partitioned cache of a database
Local cache of a partitioned cache (Near cache)
Local caches
This section defines a series of local cache schemes. In this context "local" means that the cache is only directly accessible by a single JVM. Later in this document local caches will be used as building blocks for clustered caches.
In-memory cache
This sample uses a local-scheme to define an in-memory cache. The cache will store as much as the JVM heap will allow.
<local-scheme>
<scheme-name>SampleMemoryScheme</scheme-name>
</local-scheme>
NIO in-memory cache
This sample uses an external-scheme to define an in-memory cache using an nio-memory-manager. The advantage of an NIO memory based cache is that it allows for large in-memory cache storage while not negatively impacting the JVM's GC times. The size of the cache is limited by the maximum size of the NIO memory region.
<external-scheme>
<scheme-name>SampleNioMemoryScheme</scheme-name>
<nio-memory-manager/>
</external-scheme>
Size limited in-memory cache
Adding a high-units element to the local-scheme limits the size of the cache. Here the cache is size limited to one thousand entries. Once the limit is exceeded, the scheme's eviction policy will determine which elements to evict from the cache.
<local-scheme>
<scheme-name>SampleMemoryLimitedScheme</scheme-name>
<high-units>1000</high-units>
</local-scheme>
In-memory cache with expiring entries
Adding a expiry-delay element to the local-scheme will cause cache entries to automatically expire, if they are not updated for a given time interval. Once expired the cache will invalidate the entry, and remove it from the cache.
<local-scheme>
<scheme-name>SampleMemoryExpirationScheme</scheme-name>
<expiry-delay>5m</expiry-delay>
</local-scheme>
Cache on disk
This sample uses an external-scheme to define an on-disk cache. The cache will store as much as the file system will allow.
| This example uses the lh-file-manager for its on-disk storage implementation. See the external-scheme documentation for additional external storage options. |
<external-scheme>
<scheme-name>SampleDiskScheme</scheme-name>
<lh-file-manager/>
</external-scheme>
Size limited cache on disk
Adding a [high-units|local-cache#high-units element to external-scheme limits the size of the cache. The cache is size limited to one million entries. Once the limit is exceeded, LRU eviction is used determine which elements to evict from the cache. Refer to the paged-external-scheme for an alternate size limited external caching approach.
<external-scheme>
<scheme-name>SampleDiskLimitedScheme</scheme-name>
<lh-file-manager/>
<high-units>1000000</high-units>
</external-scheme>
Persistent cache on disk
This sample uses an external-scheme to implement a cache suitable for use as long-term storage for a single JVM.
External caches are generally used for temporary storage of large data sets, and are automatically deleted on JVM shutdown. An external-cache can be used for long-term storage in non-clustered caches when using either the lh-file-manager or bdb-store-manager storage managers. For clustered persistence see the "Partitioned cache of a database" sample.
The {cache-name} macro is used to specify the name of the file the data will be stored in.
<external-scheme>
<scheme-name>SampleDiskPersistentScheme</scheme-name>
<lh-file-manager>
<directory>/my/storage/directory</directory>
<file-name>{cache-name}.store</file-name>
</lh-file-manager>
</external-scheme>
Or to use Berkeley DB rather then LH.
<external-scheme>
<scheme-name>SampleDiskPersistentScheme</scheme-name>
<bdb-store-manager>
<directory>/my/storage/directory</directory>
<store-name>{cache-name}.store</store-name>
</bdb-store-manager>
</external-scheme>
In-memory cache with disk based overflow
This sample uses an overflow-scheme to define a size limited in-memory cache, once the in-memory (front-scheme) size limit is reached, a portion of the cache contents will be moved to the on-disk (back-scheme). The front-scheme's eviction policy will determine which elements to move from the front to the back.
Note this sample reuses the "Size limited in-memory cache" and "Cache on disk" samples to implement the front and back of the cache.
<overflow-scheme>
<scheme-name>SampleOverflowScheme</scheme-name>
<front-scheme>
<local-scheme>
<scheme-ref>SampleMemoryLimitedScheme</scheme-ref>
</local-scheme>
</front-scheme>
<back-scheme>
<external-scheme>
<scheme-ref>SampleDiskScheme</scheme-ref>
</external-scheme>
</back-scheme>
</overflow-scheme>
Cache of a database
This sample uses a read-write-backing-map-scheme to define a cache of a database. This scheme maintains local cache cache of a portion of the database contents. Cache misses will read-through to the database, and cache writes will be written back to the database.
The cachestore-scheme element is configured with a custom class implementing either the com.tangosol.net.cache.CacheLoader or com.tangosol.net.cache.CacheStore interface. This class is responsible for all operations against the database, such as reading and writing cache entries. See the sample cache store implementation for an example of writing a cache store.
The {cache-name} macro is used to inform the cache store implementation of the name of the cache it will back.
<read-write-backing-map-scheme>
<scheme-name>SampleDatabaseScheme</scheme-name>
<internal-cache-scheme>
<local-scheme>
<scheme-ref>SampleMemoryScheme</scheme-ref>
</local-scheme>
</internal-cache-scheme>
<cachestore-scheme>
<class-scheme>
<class-name>com.tangosol.examples.coherence.DBCacheStore</class-name>
<init-params>
<init-param>
<param-type>java.lang.String</param-type>
<param-value>{cache-name}</param-value>
</init-param>
</init-params>
</class-scheme>
</cachestore-scheme>
</read-write-backing-map-scheme>
Clustered caches
This section defines a series of clustered cache examples. Clustered caches are accessible from multiple JVMs (any cluster node running the same cache service). The internal cache storage (backing-map) on each cluster node is defined using local caches. The cache service provides the capability to access local caches from other cluster nodes.
Replicated cache
This sample uses the replicated-scheme to define a clustered cache in which a copy of each cache entry will be stored on all cluster nodes.
The "In-memory cache" sample is used to define the cache storage on each cluster node. The size of the cache is only limited by the cluster node with the smallest JVM heap.
<replicated-scheme>
<scheme-name>SampleReplicatedScheme</scheme-name>
<backing-map-scheme>
<local-scheme>
<scheme-ref>SampleMemoryScheme</scheme-ref>
</local-scheme>
</backing-map-scheme>
</replicated-scheme>
Replicated cache with overflow
The backing-map-scheme element could just as easily specify any of the other local cache samples. For instance if it had used the "In-memory cache with disk based overflow" each cluster node would have a local overflow cache allowing for much greater storage capacity.
<replicated-scheme>
<scheme-name>SampleReplicatedOverflowScheme</scheme-name>
<backing-map-scheme>
<overflow-scheme>
<scheme-ref>SampleOverflowScheme</scheme-ref>
</overflow-scheme>
</backing-map-scheme>
</replicated-scheme>
Partitioned cache
This sample uses the distributed-scheme to define a clustered cache in which cache storage is partitioned across all cluster nodes.
The "In-memory cache" sample is used to define the cache storage on each cluster node. The total storage capacity of the cache is the sum of all storage-enabled cluster nodes running the partitioned cache service.
<distributed-scheme>
<scheme-name>SamplePartitionedScheme</scheme-name>
<backing-map-scheme>
<local-scheme>
<scheme-ref>SampleMemoryScheme</scheme-ref>
</local-scheme>
</backing-map-scheme>
</distributed-scheme>
Partitioned cache with overflow
The backing-map-scheme element could just as easily specify any of the other local cache samples. For instance if it had used the "In-memory cache with disk based overflow" each storage-enabled cluster node would have a local overflow cache allowing for much greater storage capacity. Note that the cache's backup storage also uses the same overflow scheme which allows for backup data to be overflowed to disk.
<distributed-scheme>
<scheme-name>SamplePartitionedOverflowScheme</scheme-name>
<backing-map-scheme>
<overflow-scheme>
<scheme-ref>SampleOverflowScheme</scheme-ref>
</overflow-scheme>
</backing-map-scheme>
<backup-storage>
<type>scheme</type>
<scheme-name>SampleOverflowScheme</scheme-name>
</backup-storage>
</distributed-scheme>
Partitioned cache of a database
Switching the [backing-map|distributed-cache#backing-map-scheme element to use a read-write-backing-map-scheme allows the cache to load and store entries against an external source such as a database.
This sample reuses the "Cache of a database" sample to define the database access.
<distributed-scheme>
<scheme-name>SamplePartitionedDatabaseScheme</scheme-name>
<backing-map-scheme>
<read-write-backing-map-scheme>
<scheme-ref>SampleDatabaseScheme</scheme-ref>
</read-write-backing-map-scheme>
</backing-map-scheme>
</distributed-scheme>
Local cache of a partitioned cache (Near cache)
This sample uses the near-scheme to define a local in-memory cache of a subset of a partitioned cache. The result is that any cluster node accessing the partitioned cache will maintain a local copy of the elements it frequently accesses. This offers read performance close to the replicated-scheme based caches, while offering the high scalability of a distributed-scheme based cache.
The "Size limited in-memory cache" sample is reused to define the "near" front-scheme cache, while the "Partitioned cache" sample is reused to define the back-scheme.
Note that the size limited configuration of the front-scheme specifies the limit on how much of the back-scheme cache is locally cached.
<near-scheme>
<scheme-name>SampleNearScheme</scheme-name>
<front-scheme>
<local-scheme>
<scheme-ref>SampleLimitedMemoryScheme</scheme-ref>
</local-scheme>
</front-scheme>
<back-scheme>
<distributed-scheme>
<scheme-ref>SamplePartitionedScheme</scheme-ref>
</distributed-scheme>
</back-scheme>
</near-scheme>
Cache Configuration Elements Reference
acceptor-config
Used in: proxy-scheme.
Description
The acceptor-config element specifies the configuration info for a protocol-specific connection acceptor used by a proxy service to enable Coherence*Extend clients to connect to the cluster and use the services offered by the cluster without having to join the cluster.
The acceptor-config element must contain exactly one protocol-specific connection acceptor configuration element (either jms-acceptor or tcp-acceptor).
Elements
The following table describes the elements you can define within the acceptor-config element.
| Element |
Required/Optional |
Description |
| <jms-acceptor> |
Optional |
Specifies the configuration info for a connection acceptor that enables Coherence*Extend clients to connect to the cluster over JMS. |
| <tcp-acceptor> |
Optional |
Specifies the configuration info for a connection acceptor that enables Coherence*Extend clients to connect to the cluster over TCP/IP. |
| <outgoing-message-handler> |
Optional |
Specifies the configuration info used by the connection acceptor to detect dropped client-to-cluster connections. |
| <use-filters> |
Optional |
Contains the list of filter names to be used by this connection acceptor.
For example, specifying use-filter as follows
<use-filters>
<filter-name>gzip</filter-name>
</use-filters>
will activate gzip compression for all network messages, which can help substantially with WAN and low-bandwidth networks. |
| <serializer> |
Optional |
Specifies the class configuration info for a Serializer implementation used by the connection acceptor to serialize and deserialize user types.
For example, the following configures a ConfigurablePofContext that uses the my-pof-types.xml POF type configuration file to deserialize user types to and from a POF stream:
<serializer>
<class-name>com.tangosol.io.pof.ConfigurablePofContext</class-name>
<init-params>
<init-param>
<param-type>string</param-type>
<param-value>my-pof-types.xml</param-value>
</init-param>
</init-params>
</serializer>
|
async-store-manager
Used in: external-scheme, paged-external-scheme.
Description
The async-store-manager element adds asynchronous write capabilities to other store manager implementations.
Supported store managers include:
Implementation
This store manager is implemented by the com.tangosol.io.AsyncBinaryStoreManager class.
Elements
The following table describes the elements you can define within the async-store-manager element.
| Element |
Required/Optional |
Description |
| <class-name> |
Optional |
Specifies a custom implementation of the async-store-manager.
Any custom implementation must extend the com.tangosol.io.AsyncBinaryStoreManager class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom async-store-manager implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <custom-store-manager> |
Optional |
Configures the external cache to use a custom storage manager implementation. |
| <bdb-store-manager> |
Optional |
Configures the external cache to use Berkeley Database JE on-disk databases for cache storage. |
| <lh-file-manager> |
Optional |
Configures the external cache to use a Coherence LH on-disk database for cache storage. |
| <nio-file-manager> |
Optional |
Configures the external cache to use a memory-mapped file for cache storage. |
| <nio-memory-manager> |
Optional |
Configures the external cache to use an off JVM heap, memory region for cache storage. |
| <async-limit> |
Optional |
Specifies the maximum number of bytes that will be queued to be written asynchronously. Setting the value to zero does not disable the asynchronous writes; instead, it indicates that the implementation default for the maximum number of bytes should be used.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceeding decimal value should be multiplied:
- K (kilo, 210)
- M (mega, 220)
If the value does not contain a factor, a factor of one is assumed.
Valid values are any positive memory sizes and {{zero.
Default value is 4MB. |
backup-storage
Used in: distributed-scheme.
Description
The backup-storage element specifies the type and configuration of backup storage for a partitioned cache.
Elements
The following table describes the elements you can define within the backup-storage element.
| Element |
Required/Optional |
Description |
| <type> |
Required |
Specifies the type of the storage used to hold the backup data.
Legal values are:
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <initial-size> |
Optional |
Only applicable with the off-heap and file-mapped types.
Specifies the initial buffer size in bytes.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of mega is assumed.
Legal values are positive integers between 1 and Integer.MAX_VALUE - 1023.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <maximum-size> |
Optional |
Only applicable with the off-heap and file-mapped types.
Specifies the initial buffer size in bytes.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of mega is assumed.
Legal values are positive integers between 1 and Integer.MAX_VALUE - 1023.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <directory> |
Optional |
Only applicable with the file-mapped type.
Specifies the pathname for the directory that the disk persistence manager ( com.tangosol.util.nio.MappedBufferManager) will use as "root" to store files in. If not specified or specifies a non-existent directory, a temporary file in the default location is used.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <class-name> |
Optional |
Only applicable with the custom type.
Specifies a class name for the custom storage implementation. If the class implements com.tangosol.run.xml.XmlConfigurable interface then upon construction the setConfig method is called passing the entire backup-storage element.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <scheme-name> |
Optional |
Only applicable with the scheme type.
Specifies a scheme name for the ConfigurableCacheFactory.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
bdb-store-manager
Used in: external-scheme, paged-external-scheme, async-store-manager.
| Berkeley Database JE Java class libraries are required to utilize a bdb-store-manager, visit the Berkeley Database JE product page for additional information. |
Description
The BDB store manager is used to define external caches which will use Berkeley Database JE on-disk embedded databases for storage. See the persistent disk cache and overflow cache samples for examples of Berkeley based store configurations.
Implementation
This store manager is implemented by the com.tangosol.io.bdb.BerkeleyDBBinaryStoreManager class, and produces BinaryStore objects implemened by the com.tangosol.io.bdb.BerkeleyDBBinaryStore class.
Elements
The following table describes the elements you can define within the bdb-store-manager element.
| Element |
Required/Optional |
Description |
| <class-name> |
Optional |
Specifies a custom implementation of the Berkeley Database BinaryStoreManager.
Any custom implementation must extend the com.tangosol.io.bdb.BerkeleyDBBinaryStoreManager class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies additional Berkeley DB configuration settings. See Berkeley DB Configuration.
Also used to specify initialization parameters, for use in custom implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <directory> |
Optional |
Specifies the pathname for the root directory that the Berkeley Database JE store manager will use to store files in. If not specified or specifies a non-existent directory, a temporary directory in the default location will be used. |
| <store-name> |
Optional |
Specifies the name for a database table that the Berkely Database JE store manager will use to store data in. Specifying this parameter will cause the bdb-store-manager to use non-temporary (persistent) database instances. This is intended only for local caches that are backed by a cache loader from a non-temporary store, so that the local cache can be pre-populated from the disk on startup. When specified it is recommended that it utilize the {cache-name} macro.
Normally this parameter should be left unspecified, indicating that temporary storage is to be used. |
acceptor-config
Used in: proxy-scheme.
Description
The acceptor-config element specifies the configuration info for a protocol-specific connection acceptor used by a proxy service to enable Coherence*Extend clients to connect to the cluster and use the services offered by the cluster without having to join the cluster.
The acceptor-config element must contain exactly one protocol-specific connection acceptor configuration element (either jms-acceptor or tcp-acceptor).
Elements
The following table describes the elements you can define within the acceptor-config element.
| Element |
Required/Optional |
Description |
| <jms-acceptor> |
Optional |
Specifies the configuration info for a connection acceptor that enables Coherence*Extend clients to connect to the cluster over JMS. |
| <tcp-acceptor> |
Optional |
Specifies the configuration info for a connection acceptor that enables Coherence*Extend clients to connect to the cluster over TCP/IP. |
| <outgoing-message-handler> |
Optional |
Specifies the configuration info used by the connection acceptor to detect dropped client-to-cluster connections. |
| <use-filters> |
Optional |
Contains the list of filter names to be used by this connection acceptor.
For example, specifying use-filter as follows
<use-filters>
<filter-name>gzip</filter-name>
</use-filters>
will activate gzip compression for all network messages, which can help substantially with WAN and low-bandwidth networks. |
| <serializer> |
Optional |
Specifies the class configuration info for a Serializer implementation used by the connection acceptor to serialize and deserialize user types.
For example, the following configures a ConfigurablePofContext that uses the my-pof-types.xml POF type configuration file to deserialize user types to and from a POF stream:
<serializer>
<class-name>com.tangosol.io.pof.ConfigurablePofContext</class-name>
<init-params>
<init-param>
<param-type>string</param-type>
<param-value>my-pof-types.xml</param-value>
</init-param>
</init-params>
</serializer>
|
async-store-manager
Used in: external-scheme, paged-external-scheme.
Description
The async-store-manager element adds asynchronous write capabilities to other store manager implementations.
Supported store managers include:
Implementation
This store manager is implemented by the com.tangosol.io.AsyncBinaryStoreManager class.
Elements
The following table describes the elements you can define within the async-store-manager element.
| Element |
Required/Optional |
Description |
| <class-name> |
Optional |
Specifies a custom implementation of the async-store-manager.
Any custom implementation must extend the com.tangosol.io.AsyncBinaryStoreManager class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom async-store-manager implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <custom-store-manager> |
Optional |
Configures the external cache to use a custom storage manager implementation. |
| <bdb-store-manager> |
Optional |
Configures the external cache to use Berkeley Database JE on-disk databases for cache storage. |
| <lh-file-manager> |
Optional |
Configures the external cache to use a Coherence LH on-disk database for cache storage. |
| <nio-file-manager> |
Optional |
Configures the external cache to use a memory-mapped file for cache storage. |
| <nio-memory-manager> |
Optional |
Configures the external cache to use an off JVM heap, memory region for cache storage. |
| <async-limit> |
Optional |
Specifies the maximum number of bytes that will be queued to be written asynchronously. Setting the value to zero does not disable the asynchronous writes; instead, it indicates that the implementation default for the maximum number of bytes should be used.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceeding decimal value should be multiplied:
- K (kilo, 210)
- M (mega, 220)
If the value does not contain a factor, a factor of one is assumed.
Valid values are any positive memory sizes and {{zero.
Default value is 4MB. |
backup-storage
Used in: distributed-scheme.
Description
The backup-storage element specifies the type and configuration of backup storage for a partitioned cache.
Elements
The following table describes the elements you can define within the backup-storage element.
| Element |
Required/Optional |
Description |
| <type> |
Required |
Specifies the type of the storage used to hold the backup data.
Legal values are:
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <initial-size> |
Optional |
Only applicable with the off-heap and file-mapped types.
Specifies the initial buffer size in bytes.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of mega is assumed.
Legal values are positive integers between 1 and Integer.MAX_VALUE - 1023.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <maximum-size> |
Optional |
Only applicable with the off-heap and file-mapped types.
Specifies the initial buffer size in bytes.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of mega is assumed.
Legal values are positive integers between 1 and Integer.MAX_VALUE - 1023.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <directory> |
Optional |
Only applicable with the file-mapped type.
Specifies the pathname for the directory that the disk persistence manager ( com.tangosol.util.nio.MappedBufferManager) will use as "root" to store files in. If not specified or specifies a non-existent directory, a temporary file in the default location is used.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <class-name> |
Optional |
Only applicable with the custom type.
Specifies a class name for the custom storage implementation. If the class implements com.tangosol.run.xml.XmlConfigurable interface then upon construction the setConfig method is called passing the entire backup-storage element.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <scheme-name> |
Optional |
Only applicable with the scheme type.
Specifies a scheme name for the ConfigurableCacheFactory.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
bdb-store-manager
Used in: external-scheme, paged-external-scheme, async-store-manager.
| Berkeley Database JE Java class libraries are required to utilize a bdb-store-manager, visit the Berkeley Database JE product page for additional information. |
Description
The BDB store manager is used to define external caches which will use Berkeley Database JE on-disk embedded databases for storage. See the persistent disk cache and overflow cache samples for examples of Berkeley based store configurations.
Implementation
This store manager is implemented by the com.tangosol.io.bdb.BerkeleyDBBinaryStoreManager class, and produces BinaryStore objects implemened by the com.tangosol.io.bdb.BerkeleyDBBinaryStore class.
Elements
The following table describes the elements you can define within the bdb-store-manager element.
| Element |
Required/Optional |
Description |
| <class-name> |
Optional |
Specifies a custom implementation of the Berkeley Database BinaryStoreManager.
Any custom implementation must extend the com.tangosol.io.bdb.BerkeleyDBBinaryStoreManager class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies additional Berkeley DB configuration settings. See Berkeley DB Configuration.
Also used to specify initialization parameters, for use in custom implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <directory> |
Optional |
Specifies the pathname for the root directory that the Berkeley Database JE store manager will use to store files in. If not specified or specifies a non-existent directory, a temporary directory in the default location will be used. |
| <store-name> |
Optional |
Specifies the name for a database table that the Berkely Database JE store manager will use to store data in. Specifying this parameter will cause the bdb-store-manager to use non-temporary (persistent) database instances. This is intended only for local caches that are backed by a cache loader from a non-temporary store, so that the local cache can be pre-populated from the disk on startup. When specified it is recommended that it utilize the {cache-name} macro.
Normally this parameter should be left unspecified, indicating that temporary storage is to be used. |
cache-config
Description
The cache-config element is the root element of the cache configuration descriptor.
At a high level a cache configuration consists of cache schemes and cache scheme mappings. Cache schemes describe a type of cache, for instance a database backed, distributed cache. Cache mappings define what scheme to use for a given cache name.
Elements
The following table describes the elements you can define within the cache-config element.
| Element |
Required/Optional |
Description |
| <caching-scheme-mapping> |
Required |
Specifies the cacheing-scheme that will be used for caches, based on the cache's name. |
| <caching-schemes> |
Required |
Defines the available caching-schemes for use in the cluster. |
cache-mapping
Used in: caching-scheme-mapping
Description
Each cache-mapping element specifyies the cache-scheme which is to be used for a given cache name or pattern.
Elements
The following table describes the elements you can define within the cache-mapping element.
| Element |
Required/Optional |
Description |
| <cache-name> |
Required |
Specifies a cache name or name pattern. The name is unique within a cache factory.
The following cache name patterns are supported:
- exact match, i.e. "MyCache"
- prefix match, i.e. "My*" that matches to any cache name starting with "My"
- any match "*", that matches to any cache name
The patterns get matched in the order of specificity (more specific definition is selected whenever possible). For example, if both "MyCache" and "My*" mappings are specified, the scheme from the "MyCache" mapping will be used to configure a cache named "MyCache". |
| <scheme-name> |
Required |
Contains the caching scheme name. The name is unique within a configuration file.
Caching schemes are configured in the caching-schemes section. |
| <init-params> |
Optional |
Allows specifying replaceable cache scheme parameters.
During cache scheme parsing, any occurrence of any replaceable parameter in format "{parameter-name}" is replaced with the corresponding parameter value.
Consider the following cache mapping example:
<cache-mapping>
<cache-name>My*</cache-name>
<scheme-name>my-scheme</scheme-name>
<init-params>
<init-param>
<param-name>cache-loader</param-name>
<param-value>com.acme.MyCacheLoader</param-value>
</init-param>
<init-param>
<param-name>size-limit</param-name>
<param-value>1000</param-value>
</init-param>
</init-params>
</cache-mapping>
For any cache name match "My*", any occurrence of the literal "{cache-loader}" in any part of the corresponding cache-scheme element will be replaced with the string "com.acme.MyCacheLoader" and any occurrence of the literal "{size-limit}" will be replaced with the value of "1000".
Since Coherence 3.0 |
cache-service-proxy
Used in: proxy-config
Description
The cache-service-proxy element contains the configuration info for a clustered cache service proxy managed by a proxy service.
Elements
The following table describes the elements you can define within the cache-service-proxy element.
| Element |
Required/Optional |
Description |
| <lock-enabled> |
Optional |
Specifies whether or not lock requests from remote clients are permitted on a proxied cache.
Legal values are true or false.
Default value is false. |
| <read-only> |
Optional |
Specifies whether or not requests from remote clients that update a cache are prohibited on a proxied cache.
Legal values are true or false.
Default value is false. |
caching-scheme-mapping
Used in: cache-config
Description
Defines mappings between cache names, or name patterns, and caching-schemes. For instance you may define that caches whose names start with "accounts-" will use a distributed caching scheme, while caches starting with the name "rates-" will use a replicated caching scheme.
Elements
The following table describes the elements you can define within the caching-scheme-mapping element.
| Element |
Required/Optional |
Description |
| <cache-mapping> |
Optional |
Contains a single binding between a cache name and the caching scheme this cache will use. |
caching-schemes
Used in: cache-config
Description
The caching-schemes element defines a series of cache scheme elements. Each cache scheme defines a type of cache, for instance a database backed partitioned cache, or a local cache with an LRU eviction policy. Scheme types are bound to actual caches using cache-scheme-mappings.
Scheme Types and Names
Each of the cache scheme element types is used to describe a different type of cache, for instance distributed, versus replicated. Multiple instances of the same type may be defined so long as each has a unique scheme-name.
For example the following defines two different distributed schemes:
<distributed-scheme>
<scheme-name>DistributedInMemoryCache</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<local-scheme/>
</backing-map-scheme>
</distributed-scheme>
<distributed-scheme>
<scheme-name>DistributedOnDiskCache</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<external-scheme>
<nio-file-manager>
<initial-size>8MB</initial-size>
<maximum-size>512MB</maximum-size>
<directory></directory>
</nio-file-manager>
</external-scheme>
</backing-map-scheme>
</distributed-scheme>
Nested Schemes
Some caching scheme types contain nested scheme definitions. For instance in the above example the distributed schemes include a nested scheme defintion describing their backing map.
Scheme Inheritance
Caching schemes can be defined by specifying all the elements required for a given scheme type, or by inheriting from another named scheme of the same type, and selectively overriding specific values. Scheme inheritance is accomplished by including a <scheme-ref> element in the inheriting scheme containing the scheme-name of the scheme to inherit from.
For example:
The following two configurations will produce equivalent "DistributedInMemoryCache" scheme defintions:
<distributed-scheme>
<scheme-name>DistributedInMemoryCache</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<local-scheme>
<eviction-policy>LRU</eviction-policy>
<high-units>1000</high-units>
<expiry-delay>1h</expiry-delay>
</local-scheme>
</backing-map-scheme>
</distributed-scheme>
<distributed-scheme>
<scheme-name>DistributedInMemoryCache</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<local-scheme>
<scheme-ref>LocalSizeLimited</scheme-ref>
</local-scheme>
</backing-map-scheme>
</distributed-scheme>
<local-scheme>
<scheme-name>LocalSizeLimited</scheme-name>
<eviction-policy>LRU</eviction-policy>
<high-units>1000</high-units>
<expiry-delay>1h</expiry-delay>
</local-scheme>
Please note that while the first is somewhat more compact, the second offers the ability to easily resuse the "LocalSizeLimited" scheme within multiple schemes. The following example demonstrates multiple schemes reusing the same "LocalSizeLimited" base defintion, but the second imposes a diffrent expiry-delay.
<distributed-scheme>
<scheme-name>DistributedInMemoryCache</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<local-scheme>
<scheme-ref>LocalSizeLimited</scheme-ref>
</local-scheme>
</backing-map-scheme>
</distributed-scheme>
<replicated-scheme>
<scheme-name>ReplicatedInMemoryCache</scheme-name>
<service-name>ReplicatedCache</service-name>
<backing-map-scheme>
<local-scheme>
<scheme-ref>LocalSizeLimited</scheme-ref>
<expiry-delay>10m</expiry-delay>
</local-scheme>
</backing-map-scheme>
</replicated-scheme>
<local-scheme>
<scheme-name>LocalSizeLimited</scheme-name>
<eviction-policy>LRU</eviction-policy>
<high-units>1000</high-units>
<expiry-delay>1h</expiry-delay>
</local-scheme>
Elements
The following table describes the different types of schemes you can define within the caching-schemes element.
| Element |
Required/Optional |
Description |
| <local-scheme> |
Optional |
Defines a cache scheme which provides on-heap cache storage. |
| <external-scheme> |
Optional |
Defines a cache scheme which provides off-heap cache storage, for instance on disk. |
| <paged-external-scheme> |
Optional |
Defines a cache scheme which provides off-heap cache storage, that is size-limited via time based paging. |
| <distributed-scheme> |
Optional |
Defines a cache scheme where storage of cache entries is partitioned across the cluster nodes. |
| <replicated-scheme> |
Optional |
Defines a cache scheme where each cache entry is stored on all cluster nodes. |
| <optimistic-scheme> |
Optional |
Defines a replicated cache scheme which uses optimistic rather then pessimistic locking. |
| <near-scheme> |
Optional |
Defines a two tier cache scheme which consists of a fast local front-tier cache of a much larger back-tier cache. |
| <versioned-near-scheme> |
Optional |
Defines a near-scheme which uses object versioning to ensure coherence between the front and back tiers. |
| <overflow-scheme> |
Optional |
Defines a two tier cache scheme where entries evicted from a size-limited front-tier overflow and are stored in a much larger back-tier cache. |
| <invocation-scheme> |
Optional |
Defines an invocation service which can be used for performing custom operations in parallel across cluster nodes. |
| <read-write-backing-map-scheme> |
Optional |
Defines a backing map scheme which provides a cache of a persistent store. |
| <versioned-backing-map-scheme> |
Optional |
Defines a backing map scheme which utilizes object versioning to determine what updates need to be written to the persistent store. |
| <remote-cache-scheme> |
Optional |
Defines a cache scheme that enables caches to be accessed from outside a Coherence cluster via Coherence*Extend. |
| <class-scheme> |
Optional |
Defines a cache scheme using a custom cache implementation.
Any custom implementation must implement the java.util.Map interface, and include a zero-parameter public constructor.
Additionally if the contents of the Map can be modified by anything other than the CacheService itself (e.g. if the Map automatically expires its entries periodically or size-limits its contents), then the returned object must implement the com.tangosol.util.ObservableMap interface. |
| <disk-scheme> |
Optional |
Note: As of Coherence 3.0, the disk-scheme configuration element has been deprecated and replaced by the external-scheme and paged-external-scheme configuration elements. |
class-scheme
Used in: caching-schemes, local-scheme, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, versioned-near-scheme, overflow-scheme, read-write-backing-map-scheme, versioned-backing-map-scheme, cachestore-scheme, listener
Description
Class schemes provide a mechanism for instantiating an arbitrary Java object for use by other schemes. The scheme which contains this element will dictate what class or interface(s) must be extended. See the database cache sample for an example of using a class-scheme.
The class-scheme may be configured to either instantiate objects directly via their class-name, or indirectly via a class-factory-name and method-name. The class-scheme must be configured with either a class-name or class-factory-name and method-name.
Elements
The following table describes the elements you can define within the class-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Contains a fully specified Java class name to instantiate.
This class must extend an appropriate implementation class as dictated by the containing scheme and must declare the exact same set of public constructors as the superclass. |
| <class-factory-name> |
Optional |
Specifies a fully specified name of a Java class that will be used as a factory for object instantiation. |
| <method-name> |
Optional |
Specifies the name of a static factory method on the factory class which will perform object instantiation. |
| <init-params> |
Optional |
Specifies initialization parameters which are accessible by implementations which support the com.tangosol.run.xml.XmlConfigurable interface, or which include a public constructor with a matching signature. |
cachestore-scheme
Used in: local-scheme, read-write-backing-map-scheme, versioned-backing-map-scheme.
Description
Cache store schemes define a mechanism for connecting a cache to a backend data store. The cache store scheme may use any class implementing either the com.tangosol.net.cache.CacheStore or com.tangosol.net.cache.CacheLoader interfaces, where the former offers read-write capabilities, where the latter is read-only. Custom implementations of these interfaces may be produced to connect Coherence to various data stores. See the database cache sample for an example of using a cachestore-scheme.
Elements
The following table describes the elements you can define within the cachestore-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-scheme> |
Optional |
Specifies the implementation of the cache store.
The specified class must implement one of the following two interfaces.
|
| <remote-cache-scheme> |
Optional |
Configures the cachestore-scheme to use Coherence*Extend as its cache store implementation. |
| <operation-bundling> |
Optional |
Specifies the configuration info for a bundling strategy. |
custom-store-manager
Used in: external-scheme, paged-external-scheme, async-store-manager.
Description
Used to create and configure custom implementations of a store manager for use in external caches.
Elements
The following table describes the elements you can define within the custom-store-manager element.
disk-scheme
distributed-scheme
Used in: caching-schemes, near-scheme, versioned-near-scheme, overflow-scheme, versioned-backing-map-scheme
Description
The distributed-scheme defines caches where the storage for entries is partitioned across cluster nodes. See the service overview for a more detailed description of partitioned caches. See the partitioned cache samples for examples of various distributed-scheme configurations.
Clustered Concurrency Control
Partitioned caches support cluster wide key-based locking so that data can be modified in a cluster without encountering the classic missing update problem. Note that any operation made without holding an explicit lock is still atomic but there is no guarantee that the value stored in the cache does not change between atomic operations.
Cache Clients
The partitioned cache service supports the concept of cluster nodes which do not contribute to the overall storage of the cluster. Nodes which are not storage enabled are considered "cache clients".
Cache Partitions
The cache entries are evenly segmented into a number of logical partitions, and each storage enabled cluster node running the specified partitioned service will be responsible for maintain a fair-share of these partitions.
Key Association
By default the specific set of entries assigned to each partition is transparent to the application. In some cases it may be advantageous to keep certain related entries within the same cluster node. A key-associator may be used to indicate related entries, the partitioned cache service will ensure that associated entries reside on the same partition, and thus on the same cluster node. Alternatively, key association may be specified from within the application code by using keys which implement the com.tangosol.net.cache.KeyAssociation interface.
Cache Storage (Backing Map)
Storage for the cache is specified via the backing-map-scheme. For instance a partitioned cache which uses a local cache for its backing map will result in cache entries being stored in-memory on the storage enabled cluster nodes.
Failover
For the purposes of failover a configurable number of backups of the cache may be maintained in backup-storage across the cluster nodes. Each backup is also divided into partitions, and when possible a backup partition will not reside on the same physical machine as the primary partition. If a cluster node abruptly leaves the cluster, responsibility for its partitions will automatically be reassigned to the existing backups, and new backups of those partitions will be created (on remote nodes) in order to maintain the configured backup count.
Partition Redistribution
When a node joins or leaves the cluster, a background redistribution of partitions occurs to ensure that all cluster nodes manage a fair-share of the total number of partitions. The amount of bandwidth consumed by the background transfer of partitions is governed by the transfer-threshold.
Elements
The following table describes the elements you can define within the distributed-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service which will manage caches created from this scheme.
Services are configured from within the operational descriptor. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.MapListener which will be notified of events occurring on the cache. |
| <backing-map-scheme> |
Optional |
Specifies what type of cache will be used within the cache server to store the entries.
Legal values are:
| When using an overflow-based backing map it is important that the corresponding backup-storage be configured for overflow (potentially using the same scheme as the backing-map). See the partitioned cache with overflow sample for an example configuration. |
|
| <partition-count> |
Optional |
Specifies the number of partitions that a partitioned cache will be "chopped up" into. Each node running the partitioned cache service that has the local-storage option set to true will manage a "fair" (balanced) number of partitions. The number of partitions should be larger than the square of the number of cluster members to achieve a good balance, and it is suggested that the number be prime. Good defaults include 257 and 1021 and prime numbers in-between, depending on the expected cluster size. A list of first 1,000 primes can be found at http://www.utm.edu/research/primes/lists/small/1000.txt
Legal values are prime numbers.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <key-associator> |
Optional |
Specifies a class that will be responsible for providing associations between keys and allowing associated keys to reside on the same partition. This implementation must have a zero-parameter public constructor. |
| <key-partitioning> |
Optional |
Specifies the class which will be responsible for assigning keys to partitions. This implementation must have a zero-parameter public constructor.
If unspecified, the default key partitioning algorithm will be used, which ensures that keys are evenly segmented across partitions. |
| <partition-listener> |
Optional |
Specifies a class implements the com.tangosol.net.partition.PartitionListener interface. |
| <backup-count> |
Optional |
Specifies the number of members of the partitioned cache service that hold the backup data for each unit of storage in the cache.
Value of 0 means that in the case of abnormal termination, some portion of the data in the cache will be lost. Value of N means that if up to N cluster nodes terminate at once, the cache data will be preserved.
To maintain the partitioned cache of size M, the total memory usage in the cluster does not depend on the number of cluster nodes and will be in the order of M*(N+1).
Recommended values are 0, 1 or 2.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <backup-storage> |
Optional |
Specifies the type and configuration for the partitioned cache backup storage. |
| <thread-count> |
Optional |
Specifies the number of daemon threads used by the partitioned cache service.
If zero, all relevant tasks are performed on the service thread.
Legal values are positive integers or zero.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <lease-granularity> |
Optional |
Specifies the lease ownership granularity. Available since release 2.3.
Legal values are:
A value of thread means that locks are held by a thread that obtained them and can only be released by that thread. A value of member means that locks are held by a cluster node and any thread running on the cluster node that obtained the lock can release it.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <transfer-threshold> |
Optional |
Specifies the threshold for the primary buckets distribution in kilo-bytes. When a new node joins the partitioned cache service or when a member of the service leaves, the remaining nodes perform a task of bucket ownership re-distribution. During this process, the existing data gets re-balanced along with the ownership information. This parameter indicates a preferred message size for data transfer communications. Setting this value lower will make the distribution process take longer, but will reduce network bandwidth utilization during this activity.
Legal values are integers greater then zero.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <local-storage> |
Optional |
Specifies whether or not a cluster node will contribute storage to the cluster, i.e. maintain partitions. When disabled the node is considered a cache client.
| Normally this value should be left unspecified within the configuration file, and instead set on a per-process basis using the tangosol.coherence.distributed.localstorage system property. This allows cache clients and servers to use the same configuration descriptor. |
Legal values are true or false.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not the cache services associated with this cache scheme should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
| <task-hung-threshold> |
Optional |
Specifies the amount of time in milliseconds that a task can execute before it is considered "hung". Note: a posted task that has not yet started is never considered as hung. This attribute is applied only if the Thread pool is used (the "thread-count" value is positive).
Legal values are positive integers or zero (indicating no default timeout).
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <task-timeout> |
Optional |
Specifies the timeout value in milliseconds for requests executing on the service worker threads. This attribute is applied only if the thread pool is used (the "thread-count" value is positive).
Legal values are positive integers or zero (indicating no default timeout).
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <request-timeout> |
Optional |
Specifies the maximum amount of time a client will wait for a response before abandoning the original request. The request time is measured on the client side as the time elapsed from the moment a request is sent for execution to the corresponding server node(s) and includes the following:
(1) the time it takes to deliver the request to an executing node (server);
(2) the interval between the time the task is received and placed into a service queue until the execution starts;
(3) the task execution time;
(4) the time it takes to deliver a result back to the client.
Legal values are positive integers or zero (indicating no default timeout).
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <operation-bundling> |
Optional |
Specifies the configuration info for a bundling strategy. |
external-scheme
Used in: caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, versioned-near-scheme, overflow-scheme, read-write-backing-map-scheme, versioned-backing-map-scheme
Description
External schemes define caches which are not JVM heap based, allowing for greater storage capacity. See the local cache samples for examples of various external cache configurations.
Implementaion
This scheme is implemented by:
The implementation type is chosen based on the following rule:
- if the high-units element is specified and not zero then SerializationCache is used;
- otherwise SerializationMap is used.
Pluggable Storage Manager
External schemes use a pluggable store manager to store and retrieve binary key value pairs. Supported store managers include:
Size Limited Cache
The cache may be configured as size-limited, which means that once it reaches its maximum allowable size it prunes itself.
| Eviction against disk based caches can be expensive, consider using a paged-external-scheme for such cases. |
Entry Expiration
External schemes support automatic expiration of entries based on the age of the value, as configured by the expiry-delay.
Persistence (long-term storage)
External caches are generally used for temporary storage of large data sets, for example as the back-tier of an overflow-scheme. Certain implementations do however support persistence for non-clustered caches, see the bdb-store-manager and lh-file-manager for details. Clustered persistence should be configured via a read-write-backing-map-scheme on a distributed-scheme.
Elements
The following table describes the elements you can define within the external-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Specifies a custom implementation of the external cache.
Any custom implementation must extend one of the following classes:
and declare the exact same set of public constructors as the superclass. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom external cache implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <high-units> |
Optional |
Used to limit the size of the cache. Contains the maximum number of units that can be placed in the cache before pruning occurs. An entry is the unit of measurement. Once this limit is exceeded, the cache will begin the pruning process, evicting the least recently used entries until the number of units is brought below this limit. The scheme's class-name element may be used to provide custom extensions to SerializationCache, which implement alternative eviction policies.
Legal values are positive integers or zero. Zero implies no limit.
Default value is zero. |
| <expiry-delay> |
Optional |
Specifies the amount of time from last update that entries will be kept by the cache before being expired. Entries that are expired will not be accessible and will be evicted.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of seconds is assumed.
A value of zero implies no expiry.
Default value is zero. |
| <async-store-manager> |
Optional |
Configures the external cache to use an asynchronous storage manager wrapper for any other storage manager. |
| <custom-store-manager> |
Optional |
Configures the external cache to use a custom storage manager implementation. |
| <bdb-store-manager> |
Optional |
Configures the external cache to use Berkeley Database JE on-disk databases for cache storage. |
| <lh-file-manager> |
Optional |
Configures the external cache to use a Coherence LH on-disk database for cache storage. |
| <nio-file-manager> |
Optional |
Configures the external cache to use a memory-mapped file for cache storage. |
| <nio-memory-manager> |
Optional |
Configures the external cache to use an off JVM heap, memory region for cache storage. |
initiator-config
Used in: remote-cache-scheme, remote-invocation-scheme.
Description
The initiator-config element specifies the configuration info for a protocol-specific connection initiator. A connection initiator allows a Coherence*Extend client to connect to a cluster (via a connection acceptor) and use the clustered services offered by the cluster without having to first join the cluster.
The initiator-config element must contain exactly one protocol-specific connection initiator configuration element (either jms-initiator or tcp-initiator).
Elements
The following table describes the elements you can define within the initiator-config element.
| Element |
Required/Optional |
Description |
| <jms-initiator> |
Optional |
Specifies the configuration info for a connection initiator that connects to the cluster over JMS. |
| <tcp-initiator> |
Optional |
Specifies the configuration info for a connection initiator that connects to the cluster over TCP/IP. |
| <outgoing-message-handler> |
Optional |
Specifies the configuration info used by the connection initiator to detect dropped client-to-cluster connections. |
| <use-filters> |
Optional |
Contains the list of filter names to be used by this connection initiator.
For example, specifying use-filter as follows
<use-filters>
<filter-name>gzip</filter-name>
</use-filters>
will activate gzip compression for all network messages, which can help substantially with WAN and low-bandwidth networks. |
| <serializer> |
Optional |
Specifies the class configuration info for a Serializer implementation used by the connection initiator to serialize and deserialize user types.
For example, the following configures a ConfigurablePofContext that uses the my-pof-types.xml POF type configuration file to deserialize user types to and from a POF stream:
<serializer>
<class-name>com.tangosol.io.pof.ConfigurablePofContext</class-name>
<init-params>
<init-param>
<param-type>string</param-type>
<param-value>my-pof-types.xml</param-value>
</init-param>
</init-params>
</serializer>
|
init-param
Used in: init-params.
Defines an individual initialization parameter.
Elements
The following table describes the elements you can define within the init-param element.
| Element |
Required/Optional |
Description |
| <param-name> |
Optional |
Contains the name of the initialization parameter.
For example:
<class-name>com.mycompany.cache.CustomCacheLoader</class-name>
<init-params>
<init-param>
<param-name>sTableName</param-name>
<param-value>EmployeeTable</param-value>
</init-param>
<init-param>
<param-name>iMaxSize</param-name>
<param-value>2000</param-value>
</init-param>
</init-params>
|
| <param-type> |
Optional |
Contains the Java type of the initialization parameter.
The following standard types are supported:
- java.lang.String (a.k.a. string)
- java.lang.Boolean (a.k.a. boolean)
- java.lang.Integer (a.k.a. int)
- java.lang.Long (a.k.a. long)
- java.lang.Double (a.k.a. double)
- java.math.BigDecimal
- java.io.File
- java.sql.Date
- java.sql.Time
- java.sql.Timestamp
For example:
<class-name>com.mycompany.cache.CustomCacheLoader</class-name>
<init-params>
<init-param>
<param-type>java.lang.String</param-type>
<param-value>EmployeeTable</param-value>
</init-param>
<init-param>
<param-type>int</param-type>
<param-value>2000</param-value>
</init-param>
</init-params>
Please refer to the list of available Parameter Macros. |
| <param-value> |
Optional |
Contains the value of the initialization parameter.
The value is in the format specific to the Java type of the parameter.
Please refer to the list of available Parameter Macros. |
init-params
Used in: class-scheme, cache-mapping.
Description
Defines a series of initialization parameters as name/value pairs. See the database cache sample for an example of using init-params.
Elements
The following table describes the elements you can define within the init-params element.
| Element |
Required/Optional |
Description |
| <init-param> |
Optional |
Defines an individual initialization parameter. |
invocation-scheme
Used in: caching-schemes.
Description
Defines an Invocation Service. The invocation service may be used to perform custom operations in parallel on any number of cluster nodes. See the com.tangosol.net.InvocationService API for additional details.
Elements
The following table describes the elements you can define within the invocation-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service which will manage invocations from this scheme.
Services are configured from within the operational descriptor. |
| <thread-count> |
Optional |
Specifies the number of daemon threads used by the invocation service.
If zero, all relevant tasks are performed on the service thread.
Legal values are positive integers or zero.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not this service should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
| <task-hung-threshold> |
Optional |
Specifies the amount of time in milliseconds that a task can execute before it is considered "hung". Note: a posted task that has not yet started is never considered as hung. This attribute is applied only if the Thread pool is used (the "thread-count" value is positive).
Legal values are positive integers or zero (indicating no default timeout).
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <task-timeout> |
Optional |
Specifies the default timeout value in milliseconds for tasks that can be timed-out (e.g. implement the com.tangosol.net.PriorityTask interface), but don't explicitly specify the task execution timeout value. The task execution time is measured on the server side and does not include the time spent waiting in a service backlog queue before being started. This attribute is applied only if the thread pool is used (the "thread-count" value is positive).
Legal values are positive integers or zero (indicating no default timeout).
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <request-timeout> |
Optional |
Specifies the default timeout value in milliseconds for requests that can time-out (e.g. implement the com.tangosol.net.PriorityTask interface), but don't explicitly specify the request timeout value. The request time is measured on the client side as the time elapsed from the moment a request is sent for execution to the corresponding server node(s) and includes the following:
(1) the time it takes to deliver the request to an executing node (server);
(2) the interval between the time the task is received and placed into a service queue until the execution starts;
(3) the task execution time;
(4) the time it takes to deliver a result back to the client.
Legal values are positive integers or zero (indicating no default timeout).
Default value is the value specified in the tangosol-coherence.xml descriptor. |
jms-acceptor
Used in: acceptor-config.
Description
The jms-acceptor element specifies the configuration info for a connection acceptor that accepts connections from Coherence*Extend clients over JMS.
For additional details and example configurations see Configuring and Using Coherence*Extend.
Elements
The following table describes the elements you can define within the jms-acceptor element.
| Element |
Required/Optional |
Description |
| <queue-connection-factory-name> |
Required |
Specifies the JNDI name of the JMS QueueConnectionFactory used by the connection acceptor. |
| <queue-name> |
Required |
Specifies the JNDI name of the JMS Queue used by the connection acceptor. |
jms-initiator
Used in: initiator-config.
Description
The jms-initiator element specifies the configuration info for a connection initiator that enables Coherence*Extend clients to connect to a remote cluster via JMS.
For additional details and example configurations see Configuring and Using Coherence*Extend.
Elements
The following table describes the elements you can define within the jms-initiator element.
| Element |
Required/Optional |
Description |
| <queue-connection-factory-name> |
Required |
Specifies the JNDI name of the JMS QueueConnectionFactory used by the connection initiator. |
| <queue-name> |
Required |
Specifies the JNDI name of the JMS Queue used by the connection initiator. |
| <connect-timeout> |
Optional |
Specifies the maximum amount of time to wait while establishing a connection with a connection acceptor.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of milliseconds is assumed.
Default value is an infinite timeout. |
key-associator
Used in: distributed-scheme
Description
Specifies an implementation of a com.tangosol.net.partition.KeyAssociator which will be used to determine associations between keys, allowing related keys to reside on the same partition.
Alternatively the cache's keys may manage the association by implementing the com.tangosol.net.cache.KeyAssociation interface.
Elements
The following table describes the elements you can define within the key-associator element.
key-partitioning
Used in: distributed-scheme
Description
Specifies an implementation of a com.tangosol.net.partition.KeyPartitioningStrategy which will be used to determine the partition in which a key will reside.
Elements
The following table describes the elements you can define within the key-partitioning element.
lh-file-manager
Used in: external-scheme, paged-external-scheme, async-store-manager.
Description
Configures a store manager which will use a Coherence LH on-disk embedded database for storage. See the persistent disk cache and overflow cache samples for examples of LH based store configurations.
Implementation
Implemented by the com.tangosol.io.lh.LHBinaryStoreManager class. The BinaryStore objects created by this class are instances of com.tangosol.io.lh.LHBinaryStore.
Elements
The following table describes the elements you can define within the lh-file-manager element.
| Element |
Required/Optional |
Description |
| <class-name> |
Optional |
Specifies a custom implementation of the LH BinaryStoreManager.
Any custom implementation must extend the com.tangosol.io.lh.LHBinaryStoreManager class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom LH file manager implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <directory> |
Optional |
Specifies the pathname for the root directory that the LH file manager will use to store files in. If not specified or specifies a non-existent directory, a temporary file in the default location will be used. |
| <file-name> |
Optional |
Specifies the name for a non-temporary (persistent) file that the LH file manager will use to store data in. Specifying this parameter will cause the lh-file-manager to use non-temporary database instances. This is intended only for local caches that are backed by a cache loader from a non-temporary file, so that the local cache can be pre-populated from the disk file on startup. When specified it is recommended that it utilize the {cache-name} macro.
Normally this parameter should be left unspecified, indicating that temporary storage is to be used. |
listener
Used in: local-scheme, external-scheme, paged-external-scheme, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, versioned-near-scheme, overflow-scheme, read-write-backing-map-scheme, versioned-backing-map-scheme.
Description
The Listener element specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on a cache.
Elements
The following table describes the elements you can define within the listener element.
| Element |
Required/Optional |
Description |
| <class-scheme> |
Required |
Specifies the full class name of listener implementation to use.
The specified class must implement the com.tangosol.util.MapListener interface. |
local-scheme
Used in: caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, versioned-near-scheme, overflow-scheme, read-write-backing-map-scheme, versioned-backing-map-scheme
Description
Local cache schemes define in-memory "local" caches. Local caches are generally nested within other cache schemes, for instance as the front-tier of a near-scheme. See the local cache samples for examples of various local cache configurations.
Implementation
Local caches are implemented by the com.tangosol.net.cache.LocalCache class.
Cache of an External Store
A local cache may be backed by an external cache store, cache misses will read-through to the back end store to retrieve the data. If a writable store is provided, cache writes will propagate to the cache store as well. For optimizing read/write access against a cache store see the read-write-backing-map-scheme.
Size Limited Cache
The cache may be configured as size-limited, which means that once it reaches its maximum allowable size it prunes itself back to a specified smaller size, choosing which entries to evict according to its eviction-policy. The entries and size limitations are measured in terms of units as calculated by the scheme's unit-calculator.
Entry Expiration
The local cache supports automatic expiration of entries based on the age of the value, as configured by the expiry-delay.
Elements
The following table describes the elements you can define within the local-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service which will manage caches created from this scheme.
Services are configured from within the operational descriptor. |
| <class-name> |
Optional |
Specifies a custom implementation of the local cache.
Any custom implementation must extend the com.tangosol.net.cache.LocalCache class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom local cache implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occuring on the cache. |
| <cachestore-scheme> |
Optional |
Specifies the store which is being cached. If unspecified the cached data will only reside in memory, and only reflect operations performed on the cache itself. |
| <eviction-policy> |
Optional |
Specifies the type of eviction policy to use.
Legal values are:
- LRU - Least Recently Used eviction policy chooses which entries to evict based on how recently they were last accessed, evicting those that were not accessed the for the longest period first.
- LFU - Least Frequently Used eviction policy chooses which entries to evict based on how often they are being accessed, evicting those that are accessed least frequently first.
- HYBRID - Hybrid eviction policy chooses which entries to evict based the combination (weighted score) of how often and recently they were accessed, evicting those that are accessed least frequently and were not accessed for the longest period first.
- <class-scheme> - A custom eviction policy, specified as a class-scheme. The class specified within this scheme must implement the com.tangosol.net.cache.LocalCache.EvictionPolicy interface.
Default value is HYBRID. |
| <high-units> |
Optional |
Used to limit the size of the cache. Contains the maximum number of units that can be placed in the cache before pruning occurs. An entry is the unit of measurement, unless it is overridden by an alternate unit-calculator. Once this limit is exceeded, the cache will begin the pruning process, evicting entries according to the eviction policy until the low-units size is reached.
Legal values are positive integers or zero. Zero implies no limit.
Default value is 0. |
| <low-units> |
Optional |
Contains the number of units that the cache will be pruned down to when pruning takes place. An entry is the unit of measurement, unless it is overridden by an alternate unit-calculator. When pruning occurs entries will continue to be evicted according to the eviction policy until this size.
Legal values are positive integers or zero. Zero implies the default.
Default value is 75% of the high-units setting (i.e. for a high-units setting of 1000 the default low-units will be 750). |
| <unit-calculator> |
Optional |
Specifies the type of unit calculator to use.
A unit calculator is used to determine the cost (in "units") of a given object.
Legal values are:
Default value is FIXED. |
| <expiry-delay> |
Optional |
Specifies the amount of time from last update that entries will be kept by the cache before being marked as expired. Any attempt to read an expired entry will result in a reloading of the entry from the configured cache store. Expired values are periodically discarded from the cache based on the flush-delay.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of seconds is assumed.
A value of zero implies no expiry.
Default value is zero. |
| <flush-delay> |
Optional |
Specifies the time interval between periodic cache flushes, which will discard expired entries from the cache, thus freeing resources.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of seconds is assumed.
If expiry is enabled, the default flush-delay is 1m, otherwise a default of zero is used and automatic flushes are disabled. |
near-scheme
Used in: caching-schemes.
Description
The near-scheme defines a two tier cache consisting of a front-tier which caches a subset of a back-tier cache. The front-tier is generally a fast, size limited cache, while the back-tier is slower, but much higher capacity. A typical deployment might use a local-scheme for the front-tier, and a distributed-scheme for the back-tier. The result is that a portion of a large partitioned cache will be cached locally in-memory allowing for very fast read access. See the services overview for a more detailed description of near caches, and the near cache sample for an example of a near cache configurations.
Implementation
The near scheme is implemented by the com.tangosol.net.cache.NearCache class.
Front-tier Invalidation
Specifying an invalidation-strategy defines a strategy that is used to keep the front tier of the near cache in sync with the back tier. Depending on that strategy a near cache is configured to listen to certain events occurring on the back tier and automatically update (or invalidate) the front portion of the near cache.
Elements
The following table describes the elements you can define within the near-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Specifies a custom implementation of the near cache.
Any custom implementation must extend the com.tangosol.net.cache.NearCache class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom near cache implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <front-scheme> |
Required |
Specifies the cache-scheme to use in creating the front-tier cache.
Legal values are:
The eviction policy of the front-scheme defines which entries will be cached locally.
For example:
<front-scheme>
<local-scheme>
<eviction-policy>HYBRID</eviction-policy>
<high-units>1000</high-units>
</local-scheme>
</front-scheme>
|
| <back-scheme> |
Required |
Specifies the cache-scheme to use in creating the back-tier cache.
Legal values are:
For example:
<back-scheme>
<distributed-scheme>
<scheme-ref>default-distributed</scheme-ref>
</distributed-scheme>
</back-scheme>
|
| <invalidation-strategy> |
Optional |
Specifies the strategy used keep the front-tier in-sync with the back-tier.
Please see com.tangosol.net.cache.NearCache for more details.
Legal values are:
- none - instructs the cache not to listen for invalidation events at all. This is the best choice for raw performance and scalability when business requirements permit the use of data which might not be absolutely current. Freshness of data can be guaranteed by use of a sufficiently brief eviction policy. The worst case performance is identical to a standard Distributed cache.
- present - instructs the near cache to listen to the back map events related only to the items currently present in the front map.
This strategy works best when cluster nodes have sticky data access patterns (for example, HTTP session management with a sticky load balancer).
- all - instructs the near cache to listen to all back map events.
This strategy is optimal for read-heavy access patterns where there is significant overlap between the front caches on each cluster member.
- auto - instructs the near cache to switch between present and all strategies automatically based on the cache statistics.
Default value is auto.
|
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not the cache services associated with this cache scheme should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
nio-file-manager
Used in: external-scheme, paged-external-scheme, async-store-manager.
Description
Configures an external store which uses memory-mapped file for storage.
Implementation
This store manager is implemented by the com.tangosol.io.nio.MappedStoreManager class. The BinaryStore objects created by this class are instances of the com.tangosol.io.nio.BinaryMapStore.
Elements
The following table describes the elements you can define within the nio-file-manager element.
| Element |
Required/Optional |
Description |
| <class-name> |
Optional |
Specifies a custom implementation of the local cache.
Any custom implementation must extend the com.tangosol.io.nio.MappedStoreManager class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom nio-file-manager implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <initial-size> |
Optional |
Specifies the initial buffer size in megabytes.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of mega is assumed.
Legal values are positive integers between 1 and Integer.MAX_VALUE - 1023.
Default value is 1MB. |
| <maximum-size> |
Optional |
Specifies the maximum buffer size in bytes.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of mega is assumed.
Legal values are positive integers between 1 and Integer.MAX_VALUE - 1023.
Default value is 1024MB. |
| <directory> |
Optional |
Specifies the pathname for the root directory that the manager will use to store files in. If not specified or specifies a non-existent directory, a temporary file in the default location will be used. |
nio-memory-manager
Used in: external-scheme, paged-external-scheme, async-store-manager.
Description
Configures a store-manager which uses an off JVM heap, memory region for storage, which means that it does not affect the Java heap size and the related JVM garbage-collection performance that can be responsible for application pauses. See the NIO cache sample for an example of an NIO cache configuration.
| Some JVMs (starting with 1.4) require the use of a command line parameter if the total NIO buffers will be greater than 64MB. For example: -XX:MaxDirectMemorySize=512M |
Implementation
Implemented by the com.tangosol.io.nio.DirectStoreManager class. The BinaryStore objects created by this class are instances of the com.tangosol.io.nio.BinaryMapStore.
Elements
The following table describes the elements you can define within the nio-memory-manager element.
| Element |
Required/Optional |
Description |
| <class-name> |
Optional |
Specifies a custom implementation of the local cache.
Any custom implementation must extend the com.tangosol.io.nio.DirectStoreManager class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom nio-memory-manager implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <initial-size> |
Optional |
Specifies the initial buffer size in bytes.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceeding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of mega is assumed.
Legal values are positive integers between 1 and Integer.MAX_VALUE - 1023.
Default value is 1MB. |
| <maximum-size> |
Optional |
Specifies the maximum buffer size in bytes.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceeding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of mega is assumed.
Legal values are positive integers between 1 and Integer.MAX_VALUE - 1023.
Default value is 1024MB. |
optimistic-scheme
Used in: caching-schemes, near-scheme, versioned-near-scheme, overflow-scheme
The optimistic scheme defines a cache which fully replicates all of its data to all cluster nodes that are running the service. See the services overview for a more detailed description of optimistic caches.
Optimistic Locking
Unlike the replicated and partitioned caches, optimistic caches do not support concurrency control (locking). Individual operations against entries are atomic but there is no guarantee that the value stored in the cache does not change between atomic operations. The lack of concurrency control allows optimistic caches to support very fast write operations.
Cache Storage (Backing Map)
Storage for the cache is specified via the backing-map-scheme. For instance an optimistic cache which uses a local cache for its backing map will result in cache entries being stored in-memory.
Elements
The following table describes the elements you can define within the optimistic-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service which will manage caches created from this scheme.
Services are configured from within the operational descriptor. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <backing-map-scheme> |
Optional |
Specifies what type of cache will be used within the cache server to store the entries.
Legal values are:
In order to ensure cache coherence, the backing-map of an optimistic cache must not use a read-through pattern to load cache entries. Either use a cache-aside pattern from outside the cache service, or switch to the distributed-scheme, which supports read-through clustered caching. |
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not the cache services associated with this cache scheme should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
outgoing-message-handler
Used in: acceptor-config, initiator-config.
Description
The outgoing-message-handler specifies the configuration info used to detect dropped client-to-cluster connections. For connection initiators and acceptors that use connectionless protocols (e.g. JMS), this information is necessary to proactively detect and release resources allocated to dropped connections. Connection-oriented initiators and acceptors can also use this information as an additional mechanism to detect dropped connections.
Elements
The following table describes the elements you can define within the outgoing-message-handler element.
| Element |
Required/Optional |
Description |
| <heartbeat-interval> |
Optional |
Specifies the interval between ping requests. A ping request is used to ensure the integrity of a connection.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of milliseconds is assumed.
A value of zero disables ping requests.
The default value is zero. |
| <heartbeat-timeout> |
Optional |
Specifies the maximum amount of time to wait for a response to a ping request before declaring the underlying connection unusable.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of milliseconds is assumed.
The default value is the value of the request-timeout element. |
| <request-timeout> |
Optional |
Specifies the maximum amount of time to wait for a response message before declaring the underlying connection unusable.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of milliseconds is assumed.
The default value is an infinite timeout. |
overflow-scheme
Used in: caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme, read-write-backing-map-scheme, versioned-backing-map-scheme.
Description
The overflow-scheme defines a two tier cache consisting of a fast, size limited front-tier, and slower but much higher capacity back-tier cache. When the size limited front fills up, evicted entries are transparently moved to the back. In the event of a cache miss, entries may move from the back to the front. A typical deployment might use a local-scheme for the front-tier, and a external-scheme for the back-tier, allowing for fast local caches with capacities larger the the JVM heap would allow.
Implementation
Implemented by either com.tangosol.net.cache.OverflowMap or com.tangosol.net.cache.SimpleOverflowMap, see expiry-enabled for details.
Entry Expiration
Overflow supports automatic expiration of entries based on the age of the value, as configured by the expiry-delay.
Elements
The following table describes the elements you can define within the overflow-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Specifies a custom implementation of the overflow cache.
Any custom implementation must extend either the com.tangosol.net.cache.OverflowMap or com.tangosol.net.cache.SimpleOverflowMap class, and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom overflow cache implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <front-scheme> |
Required |
Specifies the cache-scheme to use in creating the front-tier cache.
Legal values are:
The eviction policy of the front-scheme defines which entries which items are in the front vs back tiers.
For Example:
<front-scheme>
<local-scheme>
<eviction-policy>HYBRID</eviction-policy>
<high-units>1000</high-units>
</local-scheme>
</front-scheme>
|
| <back-scheme> |
Required |
Specifies the cache-scheme to use in creating the back-tier cache.
Legal values are:
For Example:
<back-scheme>
<external-scheme>
<lh-file-manager/>
</external-scheme>
</back-scheme>
|
| <miss-cache-scheme> |
Optional |
Specifies a cache-scheme for maintaining information on cache misses. For caches which are not expiry-enabled, the miss-cache is used track keys which resulted in both a front and back tier cache miss. The knowledge that a key is not in either tier allows some operations to perform faster, as they can avoid querying the potentially slow back-tier. A size limited scheme may be used to control how many misses are tracked. If unspecified no cache-miss data will be maintained.
Legal values are:
|
| <expiry-enabled> |
Optional |
Turns on support for automatically-expiring data, as provided by the com.tangosol.net.cache.CacheMap API.
When enabled the overflow-scheme will be implemented using com.tangosol.net.cache.OverflowMap, rather then com.tangosol.net.cache.SimpleOverflowMap.
Legal values are true or false.
Default value is false. |
| <expiry-delay> |
Optional |
Specifies the amount of time from last update that entries will be kept by the cache before being expired. Entries that are expired will not be accessible and will be evicted.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of seconds is assumed.
A value of zero implies no expiry.
Default value is zero. |
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not the cache services associated with this cache scheme should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
paged-external-scheme
Used in: caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, versioned-near-scheme, overflow-scheme, read-write-backing-map-scheme, versioned-backing-map-scheme
Description
As with external-schemes, paged-external-schemes define caches which are not JVM heap based, allowing for greater storage capacity. The paged-external-scheme optimizes LRU eviction by using a paging approach. See the Serialization Paged Cache overview for a detailed description of the paged cache functionality.
Implementation
This scheme is implemented by the com.tangosol.net.cache.SerializationPagedCache class.
Paging
Cache entries are maintained over a series of pages, where each page is a separate com.tangosol.io.BinaryStore, obtained from the configured storage manager. When a page is created it is considered to be the "current" page, and all write operations are performed against this page. On a configurable interval the current page is closed and a new current page is created. Read operations for a given key are performed against the last page in which the key was stored. When the number of pages exceeds a configured maximum, the oldest page is destroyed and those items which were not updated since the page was closed are be evicted. For example configuring a cache with a duration of ten minutes per page, and a maximum of six pages, will result in entries being cached for at most an hour.
Paging improves performance by avoiding individual delete operations against the storage manager as cache entries are removed or evicted. Instead the cache simply releases its references to those entries, and relies on the eventual destruction of an entire page to free the associated storage of all page entries in a single stroke.
Pluggable Storage Manager
External schemes use a pluggable store manager to create and destroy pages, as well as to access entries within those pages. Supported store-managers include:
Persistence (long-term storage)
Paged external caches are used for temporary storage of large data sets, for example as the back-tier of an overflow-scheme. These caches are not usable as for long-term storage (persistence), and will not survive beyond the life of the JVM. Clustered persistence should be configured via a read-write-backing-map-scheme on a distributed-scheme. If a non-clustered persistent cache is what is needed, refer to the external-scheme.
Elements
The following table describes the elements you can define within the paged-external-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Specifies a custom implementation of the external paged cache.
Any custom implementation must extend the com.tangosol.net.cache.SerializationPagedCache class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom external paged cache implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <page-limit> |
Required |
Specifies the maximum number of active pages for the paged cache.
Legal values are positive integers between 2 and 3600. |
| <page-duration> |
Optional |
Specifies the length of time, in seconds, that a page in the paged cache is current.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of seconds is assumed.
Legal values are between 5 and 604800 seconds (one week) and zero (no expiry).
Default value is zero |
| <async-store-manager> |
Optional |
Configures the paged external cache to use an asynchronous storage manager wrapper for any other storage manager. |
| <custom-store-manager> |
Optional |
Configures the paged external cache to use a custom storage manager implementation. |
| <bdb-store-manager> |
Optional |
Configures the paged external cache to use Berkeley Database JE on-disk databases for cache storage. |
| <lh-file-manager> |
Optional |
Configures the paged external cache to use a Coherence LH on-disk database for cache storage. |
| <nio-file-manager> |
Optional |
Configures the paged external cache to use a memory-mapped file for cache storage. |
| <nio-memory-manager> |
Optional |
Configures the paged external cache to use an off JVM heap, memory region for cache storage. |
proxy-config
Used in: proxy-scheme.
Description
The proxy-config element specifies the configuration info for the clustered service proxies managed by a proxy service. A service proxy is an intermediary between a remote client (connected to the cluster via a connection acceptor) and a clustered service used by the remote client.
Elements
The following table describes the elements you can define within the proxy-config element.
| Element |
Required/Optional |
Description |
| <cache-service-proxy> |
Optional |
Specifies the configuration info for a clustered cache service proxy managed by the proxy service. |
proxy-scheme
Used in: caching-schemes.
Description
The proxy-scheme element contains the configuration info for a clustered service that allows Coherence*Extend clients to connect to the cluster and use clustered services without having to join the cluster.
Elements
The following table describes the elements you can define within the proxy-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service. |
| <thread-count> |
Optional |
Specifies the number of daemon threads used by the service.
If zero, all relevant tasks are performed on the service thread.
Legal values are positive integers or zero.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <acceptor-config> |
Required |
Contains the configuration of the connection acceptor used by the service to accept connections from Coherence*Extend clients and to allow them to use the services offered by the cluster without having to join the cluster. |
| <proxy-config> |
Optional |
Contains the configuration of the clustered service proxies managed by this service. |
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not this service should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
read-write-backing-map-scheme
Used in: caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme.
Description
The read-write-backing-map-scheme defines a backing map which provides a size limited cache of a persistent store. See the Read-Through, Write-Through, Refresh-Ahead and Write-Behind Caching overview for more details.
Implementation
The read-write-backing-map-scheme is implemented by the com.tangosol.net.cache.ReadWriteBackingMap class.
Cache of an External Store
A read write backing map maintains a cache backed by an external persistent cache store, cache misses will read-through to the backend store to retrieve the data. If a writable store is provided, cache writes will propogate to the cache store as well.
Refresh-Ahead Caching
When enabled the cache will watch for recently accessed entries which are about to expire, and asynchronously reload them from the cache store. This insulates the application from potentially slow reads against the cache store, as items periodically expire.
Write-Behind Caching
When enabled the cache will delay writes to the backend cache store. This allows for the writes to be batched into more efficient update blocks, which occur asynchronously from the client thread.
Elements
The following table describes the elements you can define within the read-write-backing-map-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Specifies a custom implementation of the read write backing map.
Any custom implementation must extend the com.tangosol.net.cache.ReadWriteBackingMap class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom read write backing map implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <cachestore-scheme> |
Optional |
Specifies the store to cache. If unspecified the cached data will only reside within the internal cache, and only reflect operations performed on the cache itself. |
| <internal-cache-scheme> |
Required |
Specifies a cache-scheme which will be used to cache entries.
Legal values are:
|
| <miss-cache-scheme> |
Optional |
Specifies a cache-scheme for maintaining information on cache misses. The miss-cache is used track keys which were not found in the cache store. The knowledge that a key is not in the cache store allows some operations to perform faster, as they can avoid querying the potentially slow cache store. A size-limited scheme may be used to control how many misses are cached. If unspecified no cache-miss data will be maintained.
Legal values are:
|
| <read-only> |
Optional |
Specifies if the cache is read only. If true the cache will load data from cachestore for read operations and will not perform any writing to the cachestore when the cache is updated.
Legal values are true or false.
Default value is false. |
| <write-delay> |
Optional |
Specifies the time interval for a write-behind queue to defer asynchronous writes to the cachestore by.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of seconds is assumed.
If zero, synchronous writes to the cachestore (without queuing) will take place, otherwise the writes will be asynchronous and deferred by the number of seconds after the last update to the value in the cache.
Default is zero. |
| <write-batch-factor> |
Optional |
The write-batch-factor element is used to calculate the "soft-ripe" time for write-behind queue entries.
A queue entry is considered to be "ripe" for a write operation if it has been in the write-behind queue for no less than the write-delay interval. The "soft-ripe" time is the point in time prior to the actual ripe time after which an entry will be included in a batched asynchronous write operation to the CacheStore (along with all other ripe and soft-ripe entries). In other words, a soft-ripe entry is an entry that has been in the write-behind queue for at least the following duration:
D' = (1.0 - F)*D
where:
D = write-delay interval
F = write-batch-factor
Conceptually, the write-behind thread uses the following logic when performing a batched update:
- The thread waits for a queued entry to become ripe.
- When an entry becomes ripe, the thread dequeues all ripe and soft-ripe entries in the queue.
- The thread then writes all ripe and soft-ripe entries either via store() (if there is only the single ripe entry) or storeAll() (if there are multiple ripe/soft-ripe entries).
- The thread then repeats (1).
This element is only applicable if asynchronous writes are enabled (i.e. the value of the write-delay element is greater than zero) and the CacheStore implements the storeAll() method.
The value of the element is expressed as a percentage of the write-delay interval.
Legal values are non-negative doubles less than or equal to 1.0.
Default is zero. |
| <write-requeue-threshold> |
Optional |
Specifies the maximum size of the write-behind queue for which failed cachestore write operations are requeued.
The purpose of this setting is to prevent flooding of the write-behind queue with failed cachestore operations. This can happened in situations where a large number of successive write operations fail.
If zero, write-behind requeueing is disabled.
Legal values are positive integers or zero.
Default is zero. |
| <refresh-ahead-factor> |
Optional |
The refresh-ahead-factor element is used to calculate the "soft-expiration" time for cache entries.
Soft-expiration is the point in time prior to the actual expiration after which any access request for an entry will schedule an asynchronous load request for the entry.
This attribute is only applicable if the internal cache is a LocalCache, configured with automatic expiration.
The value is expressed as a percentage of the internal LocalCache expiration interval. If zero, refresh-ahead scheduling will be disabled. If 1.0, then any get operation will immediately trigger an asynchronous reload.
Legal values are non-negative doubles less than or equal to 1.0.
Default value is zero. |
| <rollback-cachestore-failures> |
Optional |
Specifies whether or not exceptions caught during synchronous cachestore operations are rethrown to the calling thread (possibly over the network to a remote member).
If the value of this element is false, an exception caught during a synchronous cachestore operation is logged locally and the internal cache is updated.
If the value is true, the exception is rethrown to the calling thread and the internal cache is not changed. If the operation was called within a transactional context, this would have the effect of rolling back the current transaction.
Legal values are true or false.
Default value is false. |
replicated-scheme
Used in: caching-schemes, near-scheme, versioned-near-scheme, overflow-scheme, versioned-backing-map-scheme
Description
The replicated scheme defines caches which fully replicate all their cache entries on each cluster nodes running the specified service. See the service overview for a more detailed description of replicated caches.
Clustered Concurrency Control
Replicated caches support cluster wide key-based locking so that data can be modified in a cluster without encountering the classic missing update problem. Note that any operation made without holding an explicit lock is still atomic but there is no guarantee that the value stored in the cache does not change between atomic operations.
Cache Storage (Backing Map)
Storage for the cache is specified via the backing-map scheme. For instance a replicated cache which uses a local cache for its backing map will result in cache entries being stored in-memory.
Elements
The following table describes the elements you can define within the replicated-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service which will manage caches created from this scheme.
Services are configured from within the operational descriptor. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <backing-map-scheme> |
Optional |
Specifies what type of cache will be used within the cache server to store the entries.
Legal values are:
In order to ensure cache coherence, the backing-map of an replicated cache must not use a read-through pattern to load cache entries. Either use a cache-aside pattern from outside the cache service, or switch to the distributed-scheme, which supports read-through clustered caching. |
| <standard-lease-milliseconds> |
Optional |
Specifies the duration of the standard lease in milliseconds. Once a lease has aged past this number of milliseconds, the lock will automatically be released. Set this value to zero to specify a lease that never expires. The purpose of this setting is to avoid deadlocks or blocks caused by stuck threads; the value should be set higher than the longest expected lock duration (e.g. higher than a transaction timeout). It's also recommended to set this value higher then packet-delivery/timeout-milliseconds value.
Legal values are from positive long numbers or zero.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <lease-granularity> |
Optional |
Specifies the lease ownership granularity. Available since release 2.3.
Legal values are:
A value of thread means that locks are held by a thread that obtained them and can only be released by that thread. A value of member means that locks are held by a cluster node and any thread running on the cluster node that obtained the lock can release it.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <mobile-issues> |
Optional |
Specifies whether or not the lease issues should be transfered to the most recent lock holders.
Legal values are true or false.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not the cache services associated with this cache scheme should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
remote-cache-scheme
Used in: cachestore-scheme, caching-schemes, near-scheme.
Description
The remote-cache-scheme element contains the configuration info necessary to use a clustered cache from outside the cluster via Coherence*Extend.
Elements
The following table describes the elements you can define within the remote-cache-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service which will manage caches created from this scheme. |
| <operation-bundling> |
Optional |
Specifies the configuration info for a bundling strategy. |
| <initiator-config> |
Required |
Contains the configuration of the connection initiator used by the service to establish a connection with the cluster. |
remote-invocation-scheme
Used in: caching-schemes
Description
The remote-invocation-scheme element contains the configuration info necessary to execute tasks within the context of a cluster without having to first join the cluster. This scheme uses Coherence*Extend to connect to the cluster.
Elements
The following table describes the elements you can define within the remote-invocation-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service. |
| <initiator-config> |
Required |
Contains the configuration of the connection initiator used by the service to establish a connection with the cluster. |
tcp-acceptor
Used in: acceptor-config.
Description
The tcp-initiator element specifies the configuration info for a connection acceptor that accepts connections from Coherence*Extend clients over TCP/IP.
For additional details and example configurations see Configuring and Using Coherence*Extend.
Elements
The following table describes the elements you can define within the tcp-acceptor element.
| Element |
Required/Optional |
Description |
| <local-address> |
Required |
Specifies the local address (IP or DNS name) and port that the TCP/IP ServerSocket opened by the connection acceptor will listen on.
For example, the following will instruct the connection acceptor to bind the TCP/IP ServerSocket to 192.168.0.2:9099:
<local-address>
<address>192.168.0.2</address>
<port>9099</port>
<reusable>true</reusable>
</local-address>
The <reusable> child element specifies whether or not a TCP/IP socket can be bound to an address if a previous connnection is in a timeout state.
When a TCP/IP connection is closed the connection may remain in a timeout state for a period of time after the connection is closed (typically known as the TIME_WAIT state or 2MSL wait state). For applications using a well known socket address or port it may not be possible to bind a socket to a required address if there is a connection in the timeout state involving the socket address or port.
|
| <keep-alive-enabled> |
Optional |
Indicates whether or not keep alive (SO_KEEPALIVE) is enabled on a TCP/IP socket.
Valid values are true and false.
Keep alive is enabled by default. |
| <tcp-delay-enabled> |
Optional |
Indicates whether or not TCP delay (Nagle's algorithm) is enabled on a TCP/IP socket.
Valid values are true and false.
TCP delay is disabled by default. |
| <receive-buffer-size> |
Optional |
Configures the size of the underlying TCP/IP socket network receive buffer.
Increasing the receive buffer size can increase the performance of network I/O for high-volume connections, while decreasing it can help reduce the backlog of incoming data.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of one is assumed.
Default value is O/S dependent. |
| <send-buffer-size> |
Optional |
Configures the size of the underlying TCP/IP socket network send buffer.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of one is assumed.
Default value is O/S dependent. |
| <listen-backlog> |
Optional |
Configures the size of the TCP/IP server socket backlog queue.
Valid values are positive integers.
Default value is O/S dependent. |
| <linger-timeout> |
Optional |
Enables SO_LINGER on a TCP/IP socket with the specified linger time.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of milliseconds is assumed.
Linger is disabled by default. |
tcp-initiator
Used in: initiator-config.
Description
The tcp-initiator element specifies the configuration info for a connection initiator that enables Coherence*Extend clients to connect to a remote cluster via TCP/IP.
For additional details and example configurations see Configuring and Using Coherence*Extend.
Elements
The following table describes the elements you can define within the tcp-initiator element.
| Element |
Required/Optional |
Description |
| <local-address> |
Optional |
Specifies the local address (IP or DNS name) that the TCP/IP socket opened by the connection initiator will be bound to.
For example, the following will instruct the connection initiator to bind the TCP/IP socket to the IP address 192.168.0.1:
<local-address>
<address>192.168.0.1</address>
</local-address>
|
| <remote-addresses> |
Required |
Contains the <socket-address> of one or more TCP/IP connection acceptors. The TCP/IP connection initiator uses this information to establish a TCP/IP connection with a remote cluster. The TCP/IP connection initiator will attempt to connect to the addresses in a random order, until either the list is exhausted or a TCP/IP connection is established.
For example, the following will instruct the connection initiator to attempt to connect to 192.168.0.2:9099 and 192.168.0.3:9099 in a random order:
<remote-addresses>
<socket-address>
<address>192.168.0.2</address>
<port>9099</port>
</socket-address>
<socket-address>
<address>192.168.0.3</address>
<port>9099</port>
</socket-address>
</remote-addresses>
|
| <keep-alive-enabled> |
Optional |
Indicates whether or not keep alive (SO_KEEPALIVE) is enabled on a TCP/IP socket.
Valid values are true and false.
Keep alive is enabled by default. |
| <tcp-delay-enabled> |
Optional |
Indicates whether or not TCP delay (Nagle's algorithm) is enabled on a TCP/IP socket.
Valid values are true and false.
TCP delay is disabled by default. |
| <receive-buffer-size> |
Optional |
Configures the size of the underlying TCP/IP socket network receive buffer.
Increasing the receive buffer size can increase the performance of network I/O for high-volume connections, while decreasing it can help reduce the backlog of incoming data.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of one is assumed.
Default value is O/S dependent. |
| <send-buffer-size> |
Optional |
Configures the size of the underlying TCP/IP socket network send buffer.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of one is assumed.
Default value is O/S dependent. |
| <connect-timeout> |
Optional |
Specifies the maximum amount of time to wait while establishing a connection with a connection acceptor.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of milliseconds is assumed.
Default value is an infinite timeout. |
| <linger-timeout> |
Optional |
Enables SO_LINGER on a TCP/IP socket with the specified linger time.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of milliseconds is assumed.
Linger is disabled by default. |
versioned-backing-map-scheme
Used in: caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme.
Description
The versioned-backing-map-scheme is an extension of a read-write-backing-map-scheme, defining a size limited cache of a persistent store. It utilizes object versioning to determine what updates need to be written to the persistent store.
Implementation
The versioned-backing-map-scheme scheme is implemented by the com.tangosol.net.cache.VersionedBackingMap class.
Cache of an External Store
As with the read-write-backing-map-scheme, a versioned backing map maintains a cache backed by an external persistent cache store, cache misses will read-through to the backend store to retrieve the data. Cache stores may also support updates to the backend data store.
Refresh-Ahead and Write-Behind Caching
As with the read-write-backing-map-scheme both the refresh-ahead and write-behind caching optimizations are supported. See Read-Through, Write-Through, Refresh-Ahead and Write-Behind Caching for more details.
Versioning
For entries whose values implement the com.tangosol.util.Versionable interface, the versioned backing map will utilize the version identifier to determine if an update needs to be written to the persistent store. The primary benefit of this feature is that in the event of cluster node failover, the backup node can determine if the most recent version of an entry has already been written to the persistent store, and if so it can avoid an extraneous write.
Elements
The following table describes the elements you can define within the versioned-backing-map-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Specifies a custom implementation of the versioned backing map.
Any custom implementation must extend the com.tangosol.net.cache.VersionedBackingMap class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom versioned backing map implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <cachestore-scheme> |
Optional |
Specifies the store to cache. If unspecified the cached data will only reside within the internal cache, and only reflect operations performed on the cache itself. |
| <internal-cache-scheme> |
Required |
Specifies a cache-scheme which will be used to cache entries.
Legal values are:
|
| <miss-cache-scheme> |
Optional |
Specifies a cache-scheme for maintaining information on cache misses. The miss-cache is used track keys which were not found in the cache store. The knowledge that a key is not in the cache store allows some operations to perform faster, as they can avoid querying the potentially slow cache store. A size-limited scheme may be used to control how many misses are cached. If unspecified no cache-miss data will be maintained.
Legal values are:
|
| <read-only> |
Optional |
Specifies if the cache is read only. If true the cache will load data from cachestore for read operations and will not perform any writing to the cachestore when the cache is updated.
Legal values are true or false.
Default value is false. |
| <write-delay> |
Optional |
Specifies the time interval for a write-behind queue to defer asynchronous writes to the cachestore by.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of seconds is assumed.
If zero, synchronous writes to the cachestore (without queuing) will take place, otherwise the writes will be asynchronous and deferred by the number of seconds after the last update to the value in the cache.
Default is zero. |
| <write-batch-factor> |
Optional |
The write-batch-factor element is used to calculate the "soft-ripe" time for write-behind queue entries.
A queue entry is considered to be "ripe" for a write operation if it has been in the write-behind queue for no less than the write-delay interval. The "soft-ripe" time is the point in time prior to the actual "ripe" time after which an entry will be included in a batched asynchronous write operation to the CacheStore (along with all other "ripe" and "soft-ripe" entries).
This element is only applicable if asynchronous writes are enabled (i.e. the value of the write-delay element is greater than zero) and the CacheStore implements the storeAll() method.
The value of the element is expressed as a percentage of the write-delay interval. For example, if the value is zero, only "ripe" entries from the write-behind queue will be batched. On the other hand, if the value is 1.0, all currently queued entries will be batched and the value of the write-delay element will be effectively ignored.
Legal values are non-negative doubles less than or equal to 1.0.
Default is zero. |
| <write-requeue-threshold> |
Optional |
Specifies the maximum size of the write-behind queue for which failed cachestore write operations are requeued.
The purpose of this setting is to prevent flooding of the write-behind queue with failed cachestore operations. This can happened in situations where a large number of successive write operations fail.
If zero, write-behind requeueing is disabled.
Legal values are positive integers or zero.
Default is zero. |
| <refresh-ahead-factor> |
Optional |
The refresh-ahead-factor element is used to calculate the "soft-expiration" time for cache entries.
Soft-expiration is the point in time prior to the actual expiration after which any access request for an entry will schedule an asynchronous load request for the entry.
This attribute is only applicable if the internal cache is a LocalCache, configured with automatic expiration.
The value is expressed as a percentage of the internal LocalCache expiration interval. If zero, refresh-ahead scheduling will be disabled. If 1.0, then any get operation will immediately trigger an asynchronous reload.
Legal values are non-negative doubles less than or equal to 1.0.
Default value is zero. |
| <rollback-cachestore-failures> |
Optional |
Specifies whether or not exceptions caught during synchronous cachestore operations are rethrown to the calling thread (possibly over the network to a remote member).
If the value of this element is false, an exception caught during a synchronous cachestore operation is logged locally and the internal cache is updated.
If the value is true, the exception is rethrown to the calling thread and the internal cache is not changed. If the operation was called within a transactional context, this would have the effect of rolling back the current transaction.
Legal values are true or false.
Default value is false. |
| <version-persistent-scheme> |
Optional |
Specifies a cache-scheme for tracking the version identifier for entries in the persistent cachestore. |
| <version-transient-scheme> |
Optional |
Specifies a cache-scheme for tracking the version identifier for entries in the transient internal cache. |
| <manage-transient> |
Optional |
Specifies if the backing map is responsible for keeping the transient version cache up to date.
If disabled the backing map manages the transient version cache only for operations for which no other party is aware (such as entry expiry). This is used when there is already a transient version cache of the same name being maintained at a higher level, for instance within a versioned-near-scheme.
Legal values are true or false.
Default value is false. |
versioned-near-scheme
Used in: caching-schemes.
| As of Coherence release 2.3, it is suggested that a near-scheme be used instead of versioned-near-scheme. Legacy Coherence applications use versioned-near-scheme to ensure coherence through object versioning. As of Coherence 2.3 the near-scheme includes a better alternative, in the form of reliable and efficient front cache invalidation. |
Description
As with the near-scheme, the versioned-near-scheme defines a two tier cache consisting of a small and fast front-end, and higher-capacity but slower back-end cache. The front-end and back-end are expressed as normal cache-schemes. A typical deployment might use a local-scheme for the front-end, and a distributed-scheme for the back-end. See the services overview for a more detailed description of versioned near caches.
Implementation
The versioned near scheme is implemented by the com.tangosol.net.cache.VersionedNearCache class.
Versioning
Object versioning is used to ensure coherence between the front and back tiers.
Elements
The following table describes the elements you can define within the near-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Specifies a custom implementation of the versioned near cache.
The specified class must extend the com.tangosol.net.cache.VersionedNearCache class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom versioned near cache implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <front-scheme> |
Required |
Specifies the cache-scheme to use in creating the front-tier cache.
Legal values are:
For Example:
<front-scheme>
<local-scheme>
<scheme-ref>default-eviction</scheme-ref>
</local-scheme>
</front-scheme>
or
<front-scheme>
<class-scheme>
<class-name>com.tangosol.util.SafeHashMap</class-name>
<init-params></init-params>
</class-scheme>
</front-scheme>
|
| <back-scheme> |
Required |
Specifies the cache-scheme to use in creating the back-tier cache.
Legal values are:
For Example:
<back-scheme>
<distributed-scheme>
<scheme-ref>default-distributed</scheme-ref>
</distributed-scheme>
</back-scheme>
|
| <version-transient-scheme> |
Optional |
Specifies a scheme for versioning cache entries, which ensures coherence between the front and back tiers. |
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not the cache services associated with this cache scheme should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
version-transient-scheme
Used in: versioned-near-scheme, versioned-backing-map-scheme.
Description
The version-transient-scheme defines a cache for storing object versioning information for use in versioned near-caches. Specifying a size limit on the specified scheme's backing-map allows control over how many version identifiers are tracked.
Elements
The following table describes the elements you can define within the version-transient-scheme element.
| Element |
Required/Optional |
Description |
| <cache-name-suffix> |
Optional |
Specifies the name modifier that is used to create a cache of version objects associated with a given cache. The value of this element is appended to the base cache name.
Legal value is a string.
Default value is "-version".
For example, if the base case is named "Sessions" and this name modifier is set to "-version", the associated version cache will be named "Sessions-version". |
<replicated-scheme>
or <distributed-scheme> |
Required |
Specifies the scheme for the cache used to maintain the versioning information.
Legal values are:
|
version-persistent-scheme
Used in: versioned-backing-map-scheme.
Description
The version-persistent-scheme defines a cache for storing object versioning information in a clustered cache. Specifying a size limit on the specified scheme's backing-map allows control over how many version identifiers are tracked.
Elements
The following table describes the elements you can define within the version-persistent-scheme element.
| Element |
Required/Optional |
Description |
| <cache-name-suffix> |
Optional |
Specifies the name modifier that is used to create a cache of version objects associated with a given cache. The value of this element is appended to the base cache name.
Legal value is a string.
Default value is "-persist".
For example, if the base case is named "Sessions" and this name modifier is set to "-persist", the associated version cache will be named "Sessions-persist". |
<replicated-scheme>
or <distributed-scheme> |
Required |
Specifies the scheme for the cache used to maintain the versioning information.
Legal values are:
|
cache-config
Description
The cache-config element is the root element of the cache configuration descriptor.
At a high level a cache configuration consists of cache schemes and cache scheme mappings. Cache schemes describe a type of cache, for instance a database backed, distributed cache. Cache mappings define what scheme to use for a given cache name.
Elements
The following table describes the elements you can define within the cache-config element.
| Element |
Required/Optional |
Description |
| <caching-scheme-mapping> |
Required |
Specifies the cacheing-scheme that will be used for caches, based on the cache's name. |
| <caching-schemes> |
Required |
Defines the available caching-schemes for use in the cluster. |
cache-mapping
Used in: caching-scheme-mapping
Description
Each cache-mapping element specifyies the cache-scheme which is to be used for a given cache name or pattern.
Elements
The following table describes the elements you can define within the cache-mapping element.
| Element |
Required/Optional |
Description |
| <cache-name> |
Required |
Specifies a cache name or name pattern. The name is unique within a cache factory.
The following cache name patterns are supported:
- exact match, i.e. "MyCache"
- prefix match, i.e. "My*" that matches to any cache name starting with "My"
- any match "*", that matches to any cache name
The patterns get matched in the order of specificity (more specific definition is selected whenever possible). For example, if both "MyCache" and "My*" mappings are specified, the scheme from the "MyCache" mapping will be used to configure a cache named "MyCache". |
| <scheme-name> |
Required |
Contains the caching scheme name. The name is unique within a configuration file.
Caching schemes are configured in the caching-schemes section. |
| <init-params> |
Optional |
Allows specifying replaceable cache scheme parameters.
During cache scheme parsing, any occurrence of any replaceable parameter in format "{parameter-name}" is replaced with the corresponding parameter value.
Consider the following cache mapping example:
<cache-mapping>
<cache-name>My*</cache-name>
<scheme-name>my-scheme</scheme-name>
<init-params>
<init-param>
<param-name>cache-loader</param-name>
<param-value>com.acme.MyCacheLoader</param-value>
</init-param>
<init-param>
<param-name>size-limit</param-name>
<param-value>1000</param-value>
</init-param>
</init-params>
</cache-mapping>
For any cache name match "My*", any occurrence of the literal "{cache-loader}" in any part of the corresponding cache-scheme element will be replaced with the string "com.acme.MyCacheLoader" and any occurrence of the literal "{size-limit}" will be replaced with the value of "1000".
Since Coherence 3.0 |
cachestore-scheme
Used in: local-scheme, read-write-backing-map-scheme, versioned-backing-map-scheme.
Description
Cache store schemes define a mechanism for connecting a cache to a backend data store. The cache store scheme may use any class implementing either the com.tangosol.net.cache.CacheStore or com.tangosol.net.cache.CacheLoader interfaces, where the former offers read-write capabilities, where the latter is read-only. Custom implementations of these interfaces may be produced to connect Coherence to various data stores. See the database cache sample for an example of using a cachestore-scheme.
Elements
The following table describes the elements you can define within the cachestore-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-scheme> |
Optional |
Specifies the implementation of the cache store.
The specified class must implement one of the following two interfaces.
|
| <remote-cache-scheme> |
Optional |
Configures the cachestore-scheme to use Coherence*Extend as its cache store implementation. |
| <operation-bundling> |
Optional |
Specifies the configuration info for a bundling strategy. |
caching-scheme-mapping
Used in: cache-config
Description
Defines mappings between cache names, or name patterns, and caching-schemes. For instance you may define that caches whose names start with "accounts-" will use a distributed caching scheme, while caches starting with the name "rates-" will use a replicated caching scheme.
Elements
The following table describes the elements you can define within the caching-scheme-mapping element.
| Element |
Required/Optional |
Description |
| <cache-mapping> |
Optional |
Contains a single binding between a cache name and the caching scheme this cache will use. |
caching-schemes
Used in: cache-config
Description
The caching-schemes element defines a series of cache scheme elements. Each cache scheme defines a type of cache, for instance a database backed partitioned cache, or a local cache with an LRU eviction policy. Scheme types are bound to actual caches using cache-scheme-mappings.
Scheme Types and Names
Each of the cache scheme element types is used to describe a different type of cache, for instance distributed, versus replicated. Multiple instances of the same type may be defined so long as each has a unique scheme-name.
For example the following defines two different distributed schemes:
<distributed-scheme>
<scheme-name>DistributedInMemoryCache</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<local-scheme/>
</backing-map-scheme>
</distributed-scheme>
<distributed-scheme>
<scheme-name>DistributedOnDiskCache</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<external-scheme>
<nio-file-manager>
<initial-size>8MB</initial-size>
<maximum-size>512MB</maximum-size>
<directory></directory>
</nio-file-manager>
</external-scheme>
</backing-map-scheme>
</distributed-scheme>
Nested Schemes
Some caching scheme types contain nested scheme definitions. For instance in the above example the distributed schemes include a nested scheme defintion describing their backing map.
Scheme Inheritance
Caching schemes can be defined by specifying all the elements required for a given scheme type, or by inheriting from another named scheme of the same type, and selectively overriding specific values. Scheme inheritance is accomplished by including a <scheme-ref> element in the inheriting scheme containing the scheme-name of the scheme to inherit from.
For example:
The following two configurations will produce equivalent "DistributedInMemoryCache" scheme defintions:
<distributed-scheme>
<scheme-name>DistributedInMemoryCache</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<local-scheme>
<eviction-policy>LRU</eviction-policy>
<high-units>1000</high-units>
<expiry-delay>1h</expiry-delay>
</local-scheme>
</backing-map-scheme>
</distributed-scheme>
<distributed-scheme>
<scheme-name>DistributedInMemoryCache</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<local-scheme>
<scheme-ref>LocalSizeLimited</scheme-ref>
</local-scheme>
</backing-map-scheme>
</distributed-scheme>
<local-scheme>
<scheme-name>LocalSizeLimited</scheme-name>
<eviction-policy>LRU</eviction-policy>
<high-units>1000</high-units>
<expiry-delay>1h</expiry-delay>
</local-scheme>
Please note that while the first is somewhat more compact, the second offers the ability to easily resuse the "LocalSizeLimited" scheme within multiple schemes. The following example demonstrates multiple schemes reusing the same "LocalSizeLimited" base defintion, but the second imposes a diffrent expiry-delay.
<distributed-scheme>
<scheme-name>DistributedInMemoryCache</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<local-scheme>
<scheme-ref>LocalSizeLimited</scheme-ref>
</local-scheme>
</backing-map-scheme>
</distributed-scheme>
<replicated-scheme>
<scheme-name>ReplicatedInMemoryCache</scheme-name>
<service-name>ReplicatedCache</service-name>
<backing-map-scheme>
<local-scheme>
<scheme-ref>LocalSizeLimited</scheme-ref>
<expiry-delay>10m</expiry-delay>
</local-scheme>
</backing-map-scheme>
</replicated-scheme>
<local-scheme>
<scheme-name>LocalSizeLimited</scheme-name>
<eviction-policy>LRU</eviction-policy>
<high-units>1000</high-units>
<expiry-delay>1h</expiry-delay>
</local-scheme>
Elements
The following table describes the different types of schemes you can define within the caching-schemes element.
| Element |
Required/Optional |
Description |
| <local-scheme> |
Optional |
Defines a cache scheme which provides on-heap cache storage. |
| <external-scheme> |
Optional |
Defines a cache scheme which provides off-heap cache storage, for instance on disk. |
| <paged-external-scheme> |
Optional |
Defines a cache scheme which provides off-heap cache storage, that is size-limited via time based paging. |
| <distributed-scheme> |
Optional |
Defines a cache scheme where storage of cache entries is partitioned across the cluster nodes. |
| <replicated-scheme> |
Optional |
Defines a cache scheme where each cache entry is stored on all cluster nodes. |
| <optimistic-scheme> |
Optional |
Defines a replicated cache scheme which uses optimistic rather then pessimistic locking. |
| <near-scheme> |
Optional |
Defines a two tier cache scheme which consists of a fast local front-tier cache of a much larger back-tier cache. |
| <versioned-near-scheme> |
Optional |
Defines a near-scheme which uses object versioning to ensure coherence between the front and back tiers. |
| <overflow-scheme> |
Optional |
Defines a two tier cache scheme where entries evicted from a size-limited front-tier overflow and are stored in a much larger back-tier cache. |
| <invocation-scheme> |
Optional |
Defines an invocation service which can be used for performing custom operations in parallel across cluster nodes. |
| <read-write-backing-map-scheme> |
Optional |
Defines a backing map scheme which provides a cache of a persistent store. |
| <versioned-backing-map-scheme> |
Optional |
Defines a backing map scheme which utilizes object versioning to determine what updates need to be written to the persistent store. |
| <remote-cache-scheme> |
Optional |
Defines a cache scheme that enables caches to be accessed from outside a Coherence cluster via Coherence*Extend. |
| <class-scheme> |
Optional |
Defines a cache scheme using a custom cache implementation.
Any custom implementation must implement the java.util.Map interface, and include a zero-parameter public constructor.
Additionally if the contents of the Map can be modified by anything other than the CacheService itself (e.g. if the Map automatically expires its entries periodically or size-limits its contents), then the returned object must implement the com.tangosol.util.ObservableMap interface. |
| <disk-scheme> |
Optional |
Note: As of Coherence 3.0, the disk-scheme configuration element has been deprecated and replaced by the external-scheme and paged-external-scheme configuration elements. |
class-scheme
Used in: caching-schemes, local-scheme, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, versioned-near-scheme, overflow-scheme, read-write-backing-map-scheme, versioned-backing-map-scheme, cachestore-scheme, listener
Description
Class schemes provide a mechanism for instantiating an arbitrary Java object for use by other schemes. The scheme which contains this element will dictate what class or interface(s) must be extended. See the database cache sample for an example of using a class-scheme.
The class-scheme may be configured to either instantiate objects directly via their class-name, or indirectly via a class-factory-name and method-name. The class-scheme must be configured with either a class-name or class-factory-name and method-name.
Elements
The following table describes the elements you can define within the class-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Contains a fully specified Java class name to instantiate.
This class must extend an appropriate implementation class as dictated by the containing scheme and must declare the exact same set of public constructors as the superclass. |
| <class-factory-name> |
Optional |
Specifies a fully specified name of a Java class that will be used as a factory for object instantiation. |
| <method-name> |
Optional |
Specifies the name of a static factory method on the factory class which will perform object instantiation. |
| <init-params> |
Optional |
Specifies initialization parameters which are accessible by implementations which support the com.tangosol.run.xml.XmlConfigurable interface, or which include a public constructor with a matching signature. |
custom-store-manager
Used in: external-scheme, paged-external-scheme, async-store-manager.
Description
Used to create and configure custom implementations of a store manager for use in external caches.
Elements
The following table describes the elements you can define within the custom-store-manager element.
disk-scheme
distributed-scheme
Used in: caching-schemes, near-scheme, versioned-near-scheme, overflow-scheme, versioned-backing-map-scheme
Description
The distributed-scheme defines caches where the storage for entries is partitioned across cluster nodes. See the service overview for a more detailed description of partitioned caches. See the partitioned cache samples for examples of various distributed-scheme configurations.
Clustered Concurrency Control
Partitioned caches support cluster wide key-based locking so that data can be modified in a cluster without encountering the classic missing update problem. Note that any operation made without holding an explicit lock is still atomic but there is no guarantee that the value stored in the cache does not change between atomic operations.
Cache Clients
The partitioned cache service supports the concept of cluster nodes which do not contribute to the overall storage of the cluster. Nodes which are not storage enabled are considered "cache clients".
Cache Partitions
The cache entries are evenly segmented into a number of logical partitions, and each storage enabled cluster node running the specified partitioned service will be responsible for maintain a fair-share of these partitions.
Key Association
By default the specific set of entries assigned to each partition is transparent to the application. In some cases it may be advantageous to keep certain related entries within the same cluster node. A key-associator may be used to indicate related entries, the partitioned cache service will ensure that associated entries reside on the same partition, and thus on the same cluster node. Alternatively, key association may be specified from within the application code by using keys which implement the com.tangosol.net.cache.KeyAssociation interface.
Cache Storage (Backing Map)
Storage for the cache is specified via the backing-map-scheme. For instance a partitioned cache which uses a local cache for its backing map will result in cache entries being stored in-memory on the storage enabled cluster nodes.
Failover
For the purposes of failover a configurable number of backups of the cache may be maintained in backup-storage across the cluster nodes. Each backup is also divided into partitions, and when possible a backup partition will not reside on the same physical machine as the primary partition. If a cluster node abruptly leaves the cluster, responsibility for its partitions will automatically be reassigned to the existing backups, and new backups of those partitions will be created (on remote nodes) in order to maintain the configured backup count.
Partition Redistribution
When a node joins or leaves the cluster, a background redistribution of partitions occurs to ensure that all cluster nodes manage a fair-share of the total number of partitions. The amount of bandwidth consumed by the background transfer of partitions is governed by the transfer-threshold.
Elements
The following table describes the elements you can define within the distributed-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service which will manage caches created from this scheme.
Services are configured from within the operational descriptor. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.MapListener which will be notified of events occurring on the cache. |
| <backing-map-scheme> |
Optional |
Specifies what type of cache will be used within the cache server to store the entries.
Legal values are:
| When using an overflow-based backing map it is important that the corresponding backup-storage be configured for overflow (potentially using the same scheme as the backing-map). See the partitioned cache with overflow sample for an example configuration. |
|
| <partition-count> |
Optional |
Specifies the number of partitions that a partitioned cache will be "chopped up" into. Each node running the partitioned cache service that has the local-storage option set to true will manage a "fair" (balanced) number of partitions. The number of partitions should be larger than the square of the number of cluster members to achieve a good balance, and it is suggested that the number be prime. Good defaults include 257 and 1021 and prime numbers in-between, depending on the expected cluster size. A list of first 1,000 primes can be found at http://www.utm.edu/research/primes/lists/small/1000.txt
Legal values are prime numbers.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <key-associator> |
Optional |
Specifies a class that will be responsible for providing associations between keys and allowing associated keys to reside on the same partition. This implementation must have a zero-parameter public constructor. |
| <key-partitioning> |
Optional |
Specifies the class which will be responsible for assigning keys to partitions. This implementation must have a zero-parameter public constructor.
If unspecified, the default key partitioning algorithm will be used, which ensures that keys are evenly segmented across partitions. |
| <partition-listener> |
Optional |
Specifies a class implements the com.tangosol.net.partition.PartitionListener interface. |
| <backup-count> |
Optional |
Specifies the number of members of the partitioned cache service that hold the backup data for each unit of storage in the cache.
Value of 0 means that in the case of abnormal termination, some portion of the data in the cache will be lost. Value of N means that if up to N cluster nodes terminate at once, the cache data will be preserved.
To maintain the partitioned cache of size M, the total memory usage in the cluster does not depend on the number of cluster nodes and will be in the order of M*(N+1).
Recommended values are 0, 1 or 2.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <backup-storage> |
Optional |
Specifies the type and configuration for the partitioned cache backup storage. |
| <thread-count> |
Optional |
Specifies the number of daemon threads used by the partitioned cache service.
If zero, all relevant tasks are performed on the service thread.
Legal values are positive integers or zero.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <lease-granularity> |
Optional |
Specifies the lease ownership granularity. Available since release 2.3.
Legal values are:
A value of thread means that locks are held by a thread that obtained them and can only be released by that thread. A value of member means that locks are held by a cluster node and any thread running on the cluster node that obtained the lock can release it.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <transfer-threshold> |
Optional |
Specifies the threshold for the primary buckets distribution in kilo-bytes. When a new node joins the partitioned cache service or when a member of the service leaves, the remaining nodes perform a task of bucket ownership re-distribution. During this process, the existing data gets re-balanced along with the ownership information. This parameter indicates a preferred message size for data transfer communications. Setting this value lower will make the distribution process take longer, but will reduce network bandwidth utilization during this activity.
Legal values are integers greater then zero.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <local-storage> |
Optional |
Specifies whether or not a cluster node will contribute storage to the cluster, i.e. maintain partitions. When disabled the node is considered a cache client.
| Normally this value should be left unspecified within the configuration file, and instead set on a per-process basis using the tangosol.coherence.distributed.localstorage system property. This allows cache clients and servers to use the same configuration descriptor. |
Legal values are true or false.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not the cache services associated with this cache scheme should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
| <task-hung-threshold> |
Optional |
Specifies the amount of time in milliseconds that a task can execute before it is considered "hung". Note: a posted task that has not yet started is never considered as hung. This attribute is applied only if the Thread pool is used (the "thread-count" value is positive).
Legal values are positive integers or zero (indicating no default timeout).
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <task-timeout> |
Optional |
Specifies the timeout value in milliseconds for requests executing on the service worker threads. This attribute is applied only if the thread pool is used (the "thread-count" value is positive).
Legal values are positive integers or zero (indicating no default timeout).
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <request-timeout> |
Optional |
Specifies the maximum amount of time a client will wait for a response before abandoning the original request. The request time is measured on the client side as the time elapsed from the moment a request is sent for execution to the corresponding server node(s) and includes the following:
(1) the time it takes to deliver the request to an executing node (server);
(2) the interval between the time the task is received and placed into a service queue until the execution starts;
(3) the task execution time;
(4) the time it takes to deliver a result back to the client.
Legal values are positive integers or zero (indicating no default timeout).
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <operation-bundling> |
Optional |
Specifies the configuration info for a bundling strategy. |
external-scheme
Used in: caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, versioned-near-scheme, overflow-scheme, read-write-backing-map-scheme, versioned-backing-map-scheme
Description
External schemes define caches which are not JVM heap based, allowing for greater storage capacity. See the local cache samples for examples of various external cache configurations.
Implementaion
This scheme is implemented by:
The implementation type is chosen based on the following rule:
- if the high-units element is specified and not zero then SerializationCache is used;
- otherwise SerializationMap is used.
Pluggable Storage Manager
External schemes use a pluggable store manager to store and retrieve binary key value pairs. Supported store managers include:
Size Limited Cache
The cache may be configured as size-limited, which means that once it reaches its maximum allowable size it prunes itself.
| Eviction against disk based caches can be expensive, consider using a paged-external-scheme for such cases. |
Entry Expiration
External schemes support automatic expiration of entries based on the age of the value, as configured by the expiry-delay.
Persistence (long-term storage)
External caches are generally used for temporary storage of large data sets, for example as the back-tier of an overflow-scheme. Certain implementations do however support persistence for non-clustered caches, see the bdb-store-manager and lh-file-manager for details. Clustered persistence should be configured via a read-write-backing-map-scheme on a distributed-scheme.
Elements
The following table describes the elements you can define within the external-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Specifies a custom implementation of the external cache.
Any custom implementation must extend one of the following classes:
and declare the exact same set of public constructors as the superclass. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom external cache implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <high-units> |
Optional |
Used to limit the size of the cache. Contains the maximum number of units that can be placed in the cache before pruning occurs. An entry is the unit of measurement. Once this limit is exceeded, the cache will begin the pruning process, evicting the least recently used entries until the number of units is brought below this limit. The scheme's class-name element may be used to provide custom extensions to SerializationCache, which implement alternative eviction policies.
Legal values are positive integers or zero. Zero implies no limit.
Default value is zero. |
| <expiry-delay> |
Optional |
Specifies the amount of time from last update that entries will be kept by the cache before being expired. Entries that are expired will not be accessible and will be evicted.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of seconds is assumed.
A value of zero implies no expiry.
Default value is zero. |
| <async-store-manager> |
Optional |
Configures the external cache to use an asynchronous storage manager wrapper for any other storage manager. |
| <custom-store-manager> |
Optional |
Configures the external cache to use a custom storage manager implementation. |
| <bdb-store-manager> |
Optional |
Configures the external cache to use Berkeley Database JE on-disk databases for cache storage. |
| <lh-file-manager> |
Optional |
Configures the external cache to use a Coherence LH on-disk database for cache storage. |
| <nio-file-manager> |
Optional |
Configures the external cache to use a memory-mapped file for cache storage. |
| <nio-memory-manager> |
Optional |
Configures the external cache to use an off JVM heap, memory region for cache storage. |
init-param
Used in: init-params.
Defines an individual initialization parameter.
Elements
The following table describes the elements you can define within the init-param element.
| Element |
Required/Optional |
Description |
| <param-name> |
Optional |
Contains the name of the initialization parameter.
For example:
<class-name>com.mycompany.cache.CustomCacheLoader</class-name>
<init-params>
<init-param>
<param-name>sTableName</param-name>
<param-value>EmployeeTable</param-value>
</init-param>
<init-param>
<param-name>iMaxSize</param-name>
<param-value>2000</param-value>
</init-param>
</init-params>
|
| <param-type> |
Optional |
Contains the Java type of the initialization parameter.
The following standard types are supported:
- java.lang.String (a.k.a. string)
- java.lang.Boolean (a.k.a. boolean)
- java.lang.Integer (a.k.a. int)
- java.lang.Long (a.k.a. long)
- java.lang.Double (a.k.a. double)
- java.math.BigDecimal
- java.io.File
- java.sql.Date
- java.sql.Time
- java.sql.Timestamp
For example:
<class-name>com.mycompany.cache.CustomCacheLoader</class-name>
<init-params>
<init-param>
<param-type>java.lang.String</param-type>
<param-value>EmployeeTable</param-value>
</init-param>
<init-param>
<param-type>int</param-type>
<param-value>2000</param-value>
</init-param>
</init-params>
Please refer to the list of available Parameter Macros. |
| <param-value> |
Optional |
Contains the value of the initialization parameter.
The value is in the format specific to the Java type of the parameter.
Please refer to the list of available Parameter Macros. |
invocation-scheme
Used in: caching-schemes.
Description
Defines an Invocation Service. The invocation service may be used to perform custom operations in parallel on any number of cluster nodes. See the com.tangosol.net.InvocationService API for additional details.
Elements
The following table describes the elements you can define within the invocation-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service which will manage invocations from this scheme.
Services are configured from within the operational descriptor. |
| <thread-count> |
Optional |
Specifies the number of daemon threads used by the invocation service.
If zero, all relevant tasks are performed on the service thread.
Legal values are positive integers or zero.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not this service should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
| <task-hung-threshold> |
Optional |
Specifies the amount of time in milliseconds that a task can execute before it is considered "hung". Note: a posted task that has not yet started is never considered as hung. This attribute is applied only if the Thread pool is used (the "thread-count" value is positive).
Legal values are positive integers or zero (indicating no default timeout).
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <task-timeout> |
Optional |
Specifies the default timeout value in milliseconds for tasks that can be timed-out (e.g. implement the com.tangosol.net.PriorityTask interface), but don't explicitly specify the task execution timeout value. The task execution time is measured on the server side and does not include the time spent waiting in a service backlog queue before being started. This attribute is applied only if the thread pool is used (the "thread-count" value is positive).
Legal values are positive integers or zero (indicating no default timeout).
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <request-timeout> |
Optional |
Specifies the default timeout value in milliseconds for requests that can time-out (e.g. implement the com.tangosol.net.PriorityTask interface), but don't explicitly specify the request timeout value. The request time is measured on the client side as the time elapsed from the moment a request is sent for execution to the corresponding server node(s) and includes the following:
(1) the time it takes to deliver the request to an executing node (server);
(2) the interval between the time the task is received and placed into a service queue until the execution starts;
(3) the task execution time;
(4) the time it takes to deliver a result back to the client.
Legal values are positive integers or zero (indicating no default timeout).
Default value is the value specified in the tangosol-coherence.xml descriptor. |
jms-acceptor
Used in: acceptor-config.
Description
The jms-acceptor element specifies the configuration info for a connection acceptor that accepts connections from Coherence*Extend clients over JMS.
For additional details and example configurations see Configuring and Using Coherence*Extend.
Elements
The following table describes the elements you can define within the jms-acceptor element.
| Element |
Required/Optional |
Description |
| <queue-connection-factory-name> |
Required |
Specifies the JNDI name of the JMS QueueConnectionFactory used by the connection acceptor. |
| <queue-name> |
Required |
Specifies the JNDI name of the JMS Queue used by the connection acceptor. |
jms-initiator
Used in: initiator-config.
Description
The jms-initiator element specifies the configuration info for a connection initiator that enables Coherence*Extend clients to connect to a remote cluster via JMS.
For additional details and example configurations see Configuring and Using Coherence*Extend.
Elements
The following table describes the elements you can define within the jms-initiator element.
| Element |
Required/Optional |
Description |
| <queue-connection-factory-name> |
Required |
Specifies the JNDI name of the JMS QueueConnectionFactory used by the connection initiator. |
| <queue-name> |
Required |
Specifies the JNDI name of the JMS Queue used by the connection initiator. |
| <connect-timeout> |
Optional |
Specifies the maximum amount of time to wait while establishing a connection with a connection acceptor.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of milliseconds is assumed.
Default value is an infinite timeout. |
key-associator
Used in: distributed-scheme
Description
Specifies an implementation of a com.tangosol.net.partition.KeyAssociator which will be used to determine associations between keys, allowing related keys to reside on the same partition.
Alternatively the cache's keys may manage the association by implementing the com.tangosol.net.cache.KeyAssociation interface.
Elements
The following table describes the elements you can define within the key-associator element.
key-partitioning
Used in: distributed-scheme
Description
Specifies an implementation of a com.tangosol.net.partition.KeyPartitioningStrategy which will be used to determine the partition in which a key will reside.
Elements
The following table describes the elements you can define within the key-partitioning element.
lh-file-manager
Used in: external-scheme, paged-external-scheme, async-store-manager.
Description
Configures a store manager which will use a Coherence LH on-disk embedded database for storage. See the persistent disk cache and overflow cache samples for examples of LH based store configurations.
Implementation
Implemented by the com.tangosol.io.lh.LHBinaryStoreManager class. The BinaryStore objects created by this class are instances of com.tangosol.io.lh.LHBinaryStore.
Elements
The following table describes the elements you can define within the lh-file-manager element.
| Element |
Required/Optional |
Description |
| <class-name> |
Optional |
Specifies a custom implementation of the LH BinaryStoreManager.
Any custom implementation must extend the com.tangosol.io.lh.LHBinaryStoreManager class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom LH file manager implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <directory> |
Optional |
Specifies the pathname for the root directory that the LH file manager will use to store files in. If not specified or specifies a non-existent directory, a temporary file in the default location will be used. |
| <file-name> |
Optional |
Specifies the name for a non-temporary (persistent) file that the LH file manager will use to store data in. Specifying this parameter will cause the lh-file-manager to use non-temporary database instances. This is intended only for local caches that are backed by a cache loader from a non-temporary file, so that the local cache can be pre-populated from the disk file on startup. When specified it is recommended that it utilize the {cache-name} macro.
Normally this parameter should be left unspecified, indicating that temporary storage is to be used. |
listener
Used in: local-scheme, external-scheme, paged-external-scheme, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, versioned-near-scheme, overflow-scheme, read-write-backing-map-scheme, versioned-backing-map-scheme.
Description
The Listener element specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on a cache.
Elements
The following table describes the elements you can define within the listener element.
| Element |
Required/Optional |
Description |
| <class-scheme> |
Required |
Specifies the full class name of listener implementation to use.
The specified class must implement the com.tangosol.util.MapListener interface. |
local-scheme
Used in: caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, versioned-near-scheme, overflow-scheme, read-write-backing-map-scheme, versioned-backing-map-scheme
Description
Local cache schemes define in-memory "local" caches. Local caches are generally nested within other cache schemes, for instance as the front-tier of a near-scheme. See the local cache samples for examples of various local cache configurations.
Implementation
Local caches are implemented by the com.tangosol.net.cache.LocalCache class.
Cache of an External Store
A local cache may be backed by an external cache store, cache misses will read-through to the back end store to retrieve the data. If a writable store is provided, cache writes will propagate to the cache store as well. For optimizing read/write access against a cache store see the read-write-backing-map-scheme.
Size Limited Cache
The cache may be configured as size-limited, which means that once it reaches its maximum allowable size it prunes itself back to a specified smaller size, choosing which entries to evict according to its eviction-policy. The entries and size limitations are measured in terms of units as calculated by the scheme's unit-calculator.
Entry Expiration
The local cache supports automatic expiration of entries based on the age of the value, as configured by the expiry-delay.
Elements
The following table describes the elements you can define within the local-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service which will manage caches created from this scheme.
Services are configured from within the operational descriptor. |
| <class-name> |
Optional |
Specifies a custom implementation of the local cache.
Any custom implementation must extend the com.tangosol.net.cache.LocalCache class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom local cache implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occuring on the cache. |
| <cachestore-scheme> |
Optional |
Specifies the store which is being cached. If unspecified the cached data will only reside in memory, and only reflect operations performed on the cache itself. |
| <eviction-policy> |
Optional |
Specifies the type of eviction policy to use.
Legal values are:
- LRU - Least Recently Used eviction policy chooses which entries to evict based on how recently they were last accessed, evicting those that were not accessed the for the longest period first.
- LFU - Least Frequently Used eviction policy chooses which entries to evict based on how often they are being accessed, evicting those that are accessed least frequently first.
- HYBRID - Hybrid eviction policy chooses which entries to evict based the combination (weighted score) of how often and recently they were accessed, evicting those that are accessed least frequently and were not accessed for the longest period first.
- <class-scheme> - A custom eviction policy, specified as a class-scheme. The class specified within this scheme must implement the com.tangosol.net.cache.LocalCache.EvictionPolicy interface.
Default value is HYBRID. |
| <high-units> |
Optional |
Used to limit the size of the cache. Contains the maximum number of units that can be placed in the cache before pruning occurs. An entry is the unit of measurement, unless it is overridden by an alternate unit-calculator. Once this limit is exceeded, the cache will begin the pruning process, evicting entries according to the eviction policy until the low-units size is reached.
Legal values are positive integers or zero. Zero implies no limit.
Default value is 0. |
| <low-units> |
Optional |
Contains the number of units that the cache will be pruned down to when pruning takes place. An entry is the unit of measurement, unless it is overridden by an alternate unit-calculator. When pruning occurs entries will continue to be evicted according to the eviction policy until this size.
Legal values are positive integers or zero. Zero implies the default.
Default value is 75% of the high-units setting (i.e. for a high-units setting of 1000 the default low-units will be 750). |
| <unit-calculator> |
Optional |
Specifies the type of unit calculator to use.
A unit calculator is used to determine the cost (in "units") of a given object.
Legal values are:
Default value is FIXED. |
| <expiry-delay> |
Optional |
Specifies the amount of time from last update that entries will be kept by the cache before being marked as expired. Any attempt to read an expired entry will result in a reloading of the entry from the configured cache store. Expired values are periodically discarded from the cache based on the flush-delay.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of seconds is assumed.
A value of zero implies no expiry.
Default value is zero. |
| <flush-delay> |
Optional |
Specifies the time interval between periodic cache flushes, which will discard expired entries from the cache, thus freeing resources.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of seconds is assumed.
If expiry is enabled, the default flush-delay is 1m, otherwise a default of zero is used and automatic flushes are disabled. |
near-scheme
Used in: caching-schemes.
Description
The near-scheme defines a two tier cache consisting of a front-tier which caches a subset of a back-tier cache. The front-tier is generally a fast, size limited cache, while the back-tier is slower, but much higher capacity. A typical deployment might use a local-scheme for the front-tier, and a distributed-scheme for the back-tier. The result is that a portion of a large partitioned cache will be cached locally in-memory allowing for very fast read access. See the services overview for a more detailed description of near caches, and the near cache sample for an example of a near cache configurations.
Implementation
The near scheme is implemented by the com.tangosol.net.cache.NearCache class.
Front-tier Invalidation
Specifying an invalidation-strategy defines a strategy that is used to keep the front tier of the near cache in sync with the back tier. Depending on that strategy a near cache is configured to listen to certain events occurring on the back tier and automatically update (or invalidate) the front portion of the near cache.
Elements
The following table describes the elements you can define within the near-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Specifies a custom implementation of the near cache.
Any custom implementation must extend the com.tangosol.net.cache.NearCache class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom near cache implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <front-scheme> |
Required |
Specifies the cache-scheme to use in creating the front-tier cache.
Legal values are:
The eviction policy of the front-scheme defines which entries will be cached locally.
For example:
<front-scheme>
<local-scheme>
<eviction-policy>HYBRID</eviction-policy>
<high-units>1000</high-units>
</local-scheme>
</front-scheme>
|
| <back-scheme> |
Required |
Specifies the cache-scheme to use in creating the back-tier cache.
Legal values are:
For example:
<back-scheme>
<distributed-scheme>
<scheme-ref>default-distributed</scheme-ref>
</distributed-scheme>
</back-scheme>
|
| <invalidation-strategy> |
Optional |
Specifies the strategy used keep the front-tier in-sync with the back-tier.
Please see com.tangosol.net.cache.NearCache for more details.
Legal values are:
- none - instructs the cache not to listen for invalidation events at all. This is the best choice for raw performance and scalability when business requirements permit the use of data which might not be absolutely current. Freshness of data can be guaranteed by use of a sufficiently brief eviction policy. The worst case performance is identical to a standard Distributed cache.
- present - instructs the near cache to listen to the back map events related only to the items currently present in the front map.
This strategy works best when cluster nodes have sticky data access patterns (for example, HTTP session management with a sticky load balancer).
- all - instructs the near cache to listen to all back map events.
This strategy is optimal for read-heavy access patterns where there is significant overlap between the front caches on each cluster member.
- auto - instructs the near cache to switch between present and all strategies automatically based on the cache statistics.
Default value is auto.
|
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not the cache services associated with this cache scheme should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
nio-file-manager
Used in: external-scheme, paged-external-scheme, async-store-manager.
Description
Configures an external store which uses memory-mapped file for storage.
Implementation
This store manager is implemented by the com.tangosol.io.nio.MappedStoreManager class. The BinaryStore objects created by this class are instances of the com.tangosol.io.nio.BinaryMapStore.
Elements
The following table describes the elements you can define within the nio-file-manager element.
| Element |
Required/Optional |
Description |
| <class-name> |
Optional |
Specifies a custom implementation of the local cache.
Any custom implementation must extend the com.tangosol.io.nio.MappedStoreManager class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom nio-file-manager implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <initial-size> |
Optional |
Specifies the initial buffer size in megabytes.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of mega is assumed.
Legal values are positive integers between 1 and Integer.MAX_VALUE - 1023.
Default value is 1MB. |
| <maximum-size> |
Optional |
Specifies the maximum buffer size in bytes.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of mega is assumed.
Legal values are positive integers between 1 and Integer.MAX_VALUE - 1023.
Default value is 1024MB. |
| <directory> |
Optional |
Specifies the pathname for the root directory that the manager will use to store files in. If not specified or specifies a non-existent directory, a temporary file in the default location will be used. |
nio-memory-manager
Used in: external-scheme, paged-external-scheme, async-store-manager.
Description
Configures a store-manager which uses an off JVM heap, memory region for storage, which means that it does not affect the Java heap size and the related JVM garbage-collection performance that can be responsible for application pauses. See the NIO cache sample for an example of an NIO cache configuration.
| Some JVMs (starting with 1.4) require the use of a command line parameter if the total NIO buffers will be greater than 64MB. For example: -XX:MaxDirectMemorySize=512M |
Implementation
Implemented by the com.tangosol.io.nio.DirectStoreManager class. The BinaryStore objects created by this class are instances of the com.tangosol.io.nio.BinaryMapStore.
Elements
The following table describes the elements you can define within the nio-memory-manager element.
| Element |
Required/Optional |
Description |
| <class-name> |
Optional |
Specifies a custom implementation of the local cache.
Any custom implementation must extend the com.tangosol.io.nio.DirectStoreManager class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom nio-memory-manager implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <initial-size> |
Optional |
Specifies the initial buffer size in bytes.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceeding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of mega is assumed.
Legal values are positive integers between 1 and Integer.MAX_VALUE - 1023.
Default value is 1MB. |
| <maximum-size> |
Optional |
Specifies the maximum buffer size in bytes.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceeding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of mega is assumed.
Legal values are positive integers between 1 and Integer.MAX_VALUE - 1023.
Default value is 1024MB. |
optimistic-scheme
Used in: caching-schemes, near-scheme, versioned-near-scheme, overflow-scheme
The optimistic scheme defines a cache which fully replicates all of its data to all cluster nodes that are running the service. See the services overview for a more detailed description of optimistic caches.
Optimistic Locking
Unlike the replicated and partitioned caches, optimistic caches do not support concurrency control (locking). Individual operations against entries are atomic but there is no guarantee that the value stored in the cache does not change between atomic operations. The lack of concurrency control allows optimistic caches to support very fast write operations.
Cache Storage (Backing Map)
Storage for the cache is specified via the backing-map-scheme. For instance an optimistic cache which uses a local cache for its backing map will result in cache entries being stored in-memory.
Elements
The following table describes the elements you can define within the optimistic-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service which will manage caches created from this scheme.
Services are configured from within the operational descriptor. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <backing-map-scheme> |
Optional |
Specifies what type of cache will be used within the cache server to store the entries.
Legal values are:
In order to ensure cache coherence, the backing-map of an optimistic cache must not use a read-through pattern to load cache entries. Either use a cache-aside pattern from outside the cache service, or switch to the distributed-scheme, which supports read-through clustered caching. |
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not the cache services associated with this cache scheme should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
overflow-scheme
Used in: caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme, read-write-backing-map-scheme, versioned-backing-map-scheme.
Description
The overflow-scheme defines a two tier cache consisting of a fast, size limited front-tier, and slower but much higher capacity back-tier cache. When the size limited front fills up, evicted entries are transparently moved to the back. In the event of a cache miss, entries may move from the back to the front. A typical deployment might use a local-scheme for the front-tier, and a external-scheme for the back-tier, allowing for fast local caches with capacities larger the the JVM heap would allow.
Implementation
Implemented by either com.tangosol.net.cache.OverflowMap or com.tangosol.net.cache.SimpleOverflowMap, see expiry-enabled for details.
Entry Expiration
Overflow supports automatic expiration of entries based on the age of the value, as configured by the expiry-delay.
Elements
The following table describes the elements you can define within the overflow-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Specifies a custom implementation of the overflow cache.
Any custom implementation must extend either the com.tangosol.net.cache.OverflowMap or com.tangosol.net.cache.SimpleOverflowMap class, and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom overflow cache implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <front-scheme> |
Required |
Specifies the cache-scheme to use in creating the front-tier cache.
Legal values are:
The eviction policy of the front-scheme defines which entries which items are in the front vs back tiers.
For Example:
<front-scheme>
<local-scheme>
<eviction-policy>HYBRID</eviction-policy>
<high-units>1000</high-units>
</local-scheme>
</front-scheme>
|
| <back-scheme> |
Required |
Specifies the cache-scheme to use in creating the back-tier cache.
Legal values are:
For Example:
<back-scheme>
<external-scheme>
<lh-file-manager/>
</external-scheme>
</back-scheme>
|
| <miss-cache-scheme> |
Optional |
Specifies a cache-scheme for maintaining information on cache misses. For caches which are not expiry-enabled, the miss-cache is used track keys which resulted in both a front and back tier cache miss. The knowledge that a key is not in either tier allows some operations to perform faster, as they can avoid querying the potentially slow back-tier. A size limited scheme may be used to control how many misses are tracked. If unspecified no cache-miss data will be maintained.
Legal values are:
|
| <expiry-enabled> |
Optional |
Turns on support for automatically-expiring data, as provided by the com.tangosol.net.cache.CacheMap API.
When enabled the overflow-scheme will be implemented using com.tangosol.net.cache.OverflowMap, rather then com.tangosol.net.cache.SimpleOverflowMap.
Legal values are true or false.
Default value is false. |
| <expiry-delay> |
Optional |
Specifies the amount of time from last update that entries will be kept by the cache before being expired. Entries that are expired will not be accessible and will be evicted.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of seconds is assumed.
A value of zero implies no expiry.
Default value is zero. |
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not the cache services associated with this cache scheme should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
paged-external-scheme
Used in: caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme, near-scheme, versioned-near-scheme, overflow-scheme, read-write-backing-map-scheme, versioned-backing-map-scheme
Description
As with external-schemes, paged-external-schemes define caches which are not JVM heap based, allowing for greater storage capacity. The paged-external-scheme optimizes LRU eviction by using a paging approach. See the Serialization Paged Cache overview for a detailed description of the paged cache functionality.
Implementation
This scheme is implemented by the com.tangosol.net.cache.SerializationPagedCache class.
Paging
Cache entries are maintained over a series of pages, where each page is a separate com.tangosol.io.BinaryStore, obtained from the configured storage manager. When a page is created it is considered to be the "current" page, and all write operations are performed against this page. On a configurable interval the current page is closed and a new current page is created. Read operations for a given key are performed against the last page in which the key was stored. When the number of pages exceeds a configured maximum, the oldest page is destroyed and those items which were not updated since the page was closed are be evicted. For example configuring a cache with a duration of ten minutes per page, and a maximum of six pages, will result in entries being cached for at most an hour.
Paging improves performance by avoiding individual delete operations against the storage manager as cache entries are removed or evicted. Instead the cache simply releases its references to those entries, and relies on the eventual destruction of an entire page to free the associated storage of all page entries in a single stroke.
Pluggable Storage Manager
External schemes use a pluggable store manager to create and destroy pages, as well as to access entries within those pages. Supported store-managers include:
Persistence (long-term storage)
Paged external caches are used for temporary storage of large data sets, for example as the back-tier of an overflow-scheme. These caches are not usable as for long-term storage (persistence), and will not survive beyond the life of the JVM. Clustered persistence should be configured via a read-write-backing-map-scheme on a distributed-scheme. If a non-clustered persistent cache is what is needed, refer to the external-scheme.
Elements
The following table describes the elements you can define within the paged-external-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Specifies a custom implementation of the external paged cache.
Any custom implementation must extend the com.tangosol.net.cache.SerializationPagedCache class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom external paged cache implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <page-limit> |
Required |
Specifies the maximum number of active pages for the paged cache.
Legal values are positive integers between 2 and 3600. |
| <page-duration> |
Optional |
Specifies the length of time, in seconds, that a page in the paged cache is current.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of seconds is assumed.
Legal values are between 5 and 604800 seconds (one week) and zero (no expiry).
Default value is zero |
| <async-store-manager> |
Optional |
Configures the paged external cache to use an asynchronous storage manager wrapper for any other storage manager. |
| <custom-store-manager> |
Optional |
Configures the paged external cache to use a custom storage manager implementation. |
| <bdb-store-manager> |
Optional |
Configures the paged external cache to use Berkeley Database JE on-disk databases for cache storage. |
| <lh-file-manager> |
Optional |
Configures the paged external cache to use a Coherence LH on-disk database for cache storage. |
| <nio-file-manager> |
Optional |
Configures the paged external cache to use a memory-mapped file for cache storage. |
| <nio-memory-manager> |
Optional |
Configures the paged external cache to use an off JVM heap, memory region for cache storage. |
proxy-config
Used in: proxy-scheme.
Description
The proxy-config element specifies the configuration info for the clustered service proxies managed by a proxy service. A service proxy is an intermediary between a remote client (connected to the cluster via a connection acceptor) and a clustered service used by the remote client.
Elements
The following table describes the elements you can define within the proxy-config element.
| Element |
Required/Optional |
Description |
| <cache-service-proxy> |
Optional |
Specifies the configuration info for a clustered cache service proxy managed by the proxy service. |
proxy-scheme
Used in: caching-schemes.
Description
The proxy-scheme element contains the configuration info for a clustered service that allows Coherence*Extend clients to connect to the cluster and use clustered services without having to join the cluster.
Elements
The following table describes the elements you can define within the proxy-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service. |
| <thread-count> |
Optional |
Specifies the number of daemon threads used by the service.
If zero, all relevant tasks are performed on the service thread.
Legal values are positive integers or zero.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <acceptor-config> |
Required |
Contains the configuration of the connection acceptor used by the service to accept connections from Coherence*Extend clients and to allow them to use the services offered by the cluster without having to join the cluster. |
| <proxy-config> |
Optional |
Contains the configuration of the clustered service proxies managed by this service. |
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not this service should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
read-write-backing-map-scheme
Used in: caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme.
Description
The read-write-backing-map-scheme defines a backing map which provides a size limited cache of a persistent store. See the Read-Through, Write-Through, Refresh-Ahead and Write-Behind Caching overview for more details.
Implementation
The read-write-backing-map-scheme is implemented by the com.tangosol.net.cache.ReadWriteBackingMap class.
Cache of an External Store
A read write backing map maintains a cache backed by an external persistent cache store, cache misses will read-through to the backend store to retrieve the data. If a writable store is provided, cache writes will propogate to the cache store as well.
Refresh-Ahead Caching
When enabled the cache will watch for recently accessed entries which are about to expire, and asynchronously reload them from the cache store. This insulates the application from potentially slow reads against the cache store, as items periodically expire.
Write-Behind Caching
When enabled the cache will delay writes to the backend cache store. This allows for the writes to be batched into more efficient update blocks, which occur asynchronously from the client thread.
Elements
The following table describes the elements you can define within the read-write-backing-map-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Specifies a custom implementation of the read write backing map.
Any custom implementation must extend the com.tangosol.net.cache.ReadWriteBackingMap class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom read write backing map implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <cachestore-scheme> |
Optional |
Specifies the store to cache. If unspecified the cached data will only reside within the internal cache, and only reflect operations performed on the cache itself. |
| <internal-cache-scheme> |
Required |
Specifies a cache-scheme which will be used to cache entries.
Legal values are:
|
| <miss-cache-scheme> |
Optional |
Specifies a cache-scheme for maintaining information on cache misses. The miss-cache is used track keys which were not found in the cache store. The knowledge that a key is not in the cache store allows some operations to perform faster, as they can avoid querying the potentially slow cache store. A size-limited scheme may be used to control how many misses are cached. If unspecified no cache-miss data will be maintained.
Legal values are:
|
| <read-only> |
Optional |
Specifies if the cache is read only. If true the cache will load data from cachestore for read operations and will not perform any writing to the cachestore when the cache is updated.
Legal values are true or false.
Default value is false. |
| <write-delay> |
Optional |
Specifies the time interval for a write-behind queue to defer asynchronous writes to the cachestore by.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of seconds is assumed.
If zero, synchronous writes to the cachestore (without queuing) will take place, otherwise the writes will be asynchronous and deferred by the number of seconds after the last update to the value in the cache.
Default is zero. |
| <write-batch-factor> |
Optional |
The write-batch-factor element is used to calculate the "soft-ripe" time for write-behind queue entries.
A queue entry is considered to be "ripe" for a write operation if it has been in the write-behind queue for no less than the write-delay interval. The "soft-ripe" time is the point in time prior to the actual ripe time after which an entry will be included in a batched asynchronous write operation to the CacheStore (along with all other ripe and soft-ripe entries). In other words, a soft-ripe entry is an entry that has been in the write-behind queue for at least the following duration:
D' = (1.0 - F)*D
where:
D = write-delay interval
F = write-batch-factor
Conceptually, the write-behind thread uses the following logic when performing a batched update:
- The thread waits for a queued entry to become ripe.
- When an entry becomes ripe, the thread dequeues all ripe and soft-ripe entries in the queue.
- The thread then writes all ripe and soft-ripe entries either via store() (if there is only the single ripe entry) or storeAll() (if there are multiple ripe/soft-ripe entries).
- The thread then repeats (1).
This element is only applicable if asynchronous writes are enabled (i.e. the value of the write-delay element is greater than zero) and the CacheStore implements the storeAll() method.
The value of the element is expressed as a percentage of the write-delay interval.
Legal values are non-negative doubles less than or equal to 1.0.
Default is zero. |
| <write-requeue-threshold> |
Optional |
Specifies the maximum size of the write-behind queue for which failed cachestore write operations are requeued.
The purpose of this setting is to prevent flooding of the write-behind queue with failed cachestore operations. This can happened in situations where a large number of successive write operations fail.
If zero, write-behind requeueing is disabled.
Legal values are positive integers or zero.
Default is zero. |
| <refresh-ahead-factor> |
Optional |
The refresh-ahead-factor element is used to calculate the "soft-expiration" time for cache entries.
Soft-expiration is the point in time prior to the actual expiration after which any access request for an entry will schedule an asynchronous load request for the entry.
This attribute is only applicable if the internal cache is a LocalCache, configured with automatic expiration.
The value is expressed as a percentage of the internal LocalCache expiration interval. If zero, refresh-ahead scheduling will be disabled. If 1.0, then any get operation will immediately trigger an asynchronous reload.
Legal values are non-negative doubles less than or equal to 1.0.
Default value is zero. |
| <rollback-cachestore-failures> |
Optional |
Specifies whether or not exceptions caught during synchronous cachestore operations are rethrown to the calling thread (possibly over the network to a remote member).
If the value of this element is false, an exception caught during a synchronous cachestore operation is logged locally and the internal cache is updated.
If the value is true, the exception is rethrown to the calling thread and the internal cache is not changed. If the operation was called within a transactional context, this would have the effect of rolling back the current transaction.
Legal values are true or false.
Default value is false. |
remote-cache-scheme
Used in: cachestore-scheme, caching-schemes, near-scheme.
Description
The remote-cache-scheme element contains the configuration info necessary to use a clustered cache from outside the cluster via Coherence*Extend.
Elements
The following table describes the elements you can define within the remote-cache-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service which will manage caches created from this scheme. |
| <operation-bundling> |
Optional |
Specifies the configuration info for a bundling strategy. |
| <initiator-config> |
Required |
Contains the configuration of the connection initiator used by the service to establish a connection with the cluster. |
remote-invocation-scheme
Used in: caching-schemes
Description
The remote-invocation-scheme element contains the configuration info necessary to execute tasks within the context of a cluster without having to first join the cluster. This scheme uses Coherence*Extend to connect to the cluster.
Elements
The following table describes the elements you can define within the remote-invocation-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service. |
| <initiator-config> |
Required |
Contains the configuration of the connection initiator used by the service to establish a connection with the cluster. |
replicated-scheme
Used in: caching-schemes, near-scheme, versioned-near-scheme, overflow-scheme, versioned-backing-map-scheme
Description
The replicated scheme defines caches which fully replicate all their cache entries on each cluster nodes running the specified service. See the service overview for a more detailed description of replicated caches.
Clustered Concurrency Control
Replicated caches support cluster wide key-based locking so that data can be modified in a cluster without encountering the classic missing update problem. Note that any operation made without holding an explicit lock is still atomic but there is no guarantee that the value stored in the cache does not change between atomic operations.
Cache Storage (Backing Map)
Storage for the cache is specified via the backing-map scheme. For instance a replicated cache which uses a local cache for its backing map will result in cache entries being stored in-memory.
Elements
The following table describes the elements you can define within the replicated-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <service-name> |
Optional |
Specifies the name of the service which will manage caches created from this scheme.
Services are configured from within the operational descriptor. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <backing-map-scheme> |
Optional |
Specifies what type of cache will be used within the cache server to store the entries.
Legal values are:
In order to ensure cache coherence, the backing-map of an replicated cache must not use a read-through pattern to load cache entries. Either use a cache-aside pattern from outside the cache service, or switch to the distributed-scheme, which supports read-through clustered caching. |
| <standard-lease-milliseconds> |
Optional |
Specifies the duration of the standard lease in milliseconds. Once a lease has aged past this number of milliseconds, the lock will automatically be released. Set this value to zero to specify a lease that never expires. The purpose of this setting is to avoid deadlocks or blocks caused by stuck threads; the value should be set higher than the longest expected lock duration (e.g. higher than a transaction timeout). It's also recommended to set this value higher then packet-delivery/timeout-milliseconds value.
Legal values are from positive long numbers or zero.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <lease-granularity> |
Optional |
Specifies the lease ownership granularity. Available since release 2.3.
Legal values are:
A value of thread means that locks are held by a thread that obtained them and can only be released by that thread. A value of member means that locks are held by a cluster node and any thread running on the cluster node that obtained the lock can release it.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <mobile-issues> |
Optional |
Specifies whether or not the lease issues should be transfered to the most recent lock holders.
Legal values are true or false.
Default value is the value specified in the tangosol-coherence.xml descriptor. |
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not the cache services associated with this cache scheme should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
tcp-acceptor
Used in: acceptor-config.
Description
The tcp-initiator element specifies the configuration info for a connection acceptor that accepts connections from Coherence*Extend clients over TCP/IP.
For additional details and example configurations see Configuring and Using Coherence*Extend.
Elements
The following table describes the elements you can define within the tcp-acceptor element.
| Element |
Required/Optional |
Description |
| <local-address> |
Required |
Specifies the local address (IP or DNS name) and port that the TCP/IP ServerSocket opened by the connection acceptor will listen on.
For example, the following will instruct the connection acceptor to bind the TCP/IP ServerSocket to 192.168.0.2:9099:
<local-address>
<address>192.168.0.2</address>
<port>9099</port>
<reusable>true</reusable>
</local-address>
The <reusable> child element specifies whether or not a TCP/IP socket can be bound to an address if a previous connnection is in a timeout state.
When a TCP/IP connection is closed the connection may remain in a timeout state for a period of time after the connection is closed (typically known as the TIME_WAIT state or 2MSL wait state). For applications using a well known socket address or port it may not be possible to bind a socket to a required address if there is a connection in the timeout state involving the socket address or port.
|
| <keep-alive-enabled> |
Optional |
Indicates whether or not keep alive (SO_KEEPALIVE) is enabled on a TCP/IP socket.
Valid values are true and false.
Keep alive is enabled by default. |
| <tcp-delay-enabled> |
Optional |
Indicates whether or not TCP delay (Nagle's algorithm) is enabled on a TCP/IP socket.
Valid values are true and false.
TCP delay is disabled by default. |
| <receive-buffer-size> |
Optional |
Configures the size of the underlying TCP/IP socket network receive buffer.
Increasing the receive buffer size can increase the performance of network I/O for high-volume connections, while decreasing it can help reduce the backlog of incoming data.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of one is assumed.
Default value is O/S dependent. |
| <send-buffer-size> |
Optional |
Configures the size of the underlying TCP/IP socket network send buffer.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of one is assumed.
Default value is O/S dependent. |
| <listen-backlog> |
Optional |
Configures the size of the TCP/IP server socket backlog queue.
Valid values are positive integers.
Default value is O/S dependent. |
| <linger-timeout> |
Optional |
Enables SO_LINGER on a TCP/IP socket with the specified linger time.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of milliseconds is assumed.
Linger is disabled by default. |
tcp-initiator
Used in: initiator-config.
Description
The tcp-initiator element specifies the configuration info for a connection initiator that enables Coherence*Extend clients to connect to a remote cluster via TCP/IP.
For additional details and example configurations see Configuring and Using Coherence*Extend.
Elements
The following table describes the elements you can define within the tcp-initiator element.
| Element |
Required/Optional |
Description |
| <local-address> |
Optional |
Specifies the local address (IP or DNS name) that the TCP/IP socket opened by the connection initiator will be bound to.
For example, the following will instruct the connection initiator to bind the TCP/IP socket to the IP address 192.168.0.1:
<local-address>
<address>192.168.0.1</address>
</local-address>
|
| <remote-addresses> |
Required |
Contains the <socket-address> of one or more TCP/IP connection acceptors. The TCP/IP connection initiator uses this information to establish a TCP/IP connection with a remote cluster. The TCP/IP connection initiator will attempt to connect to the addresses in a random order, until either the list is exhausted or a TCP/IP connection is established.
For example, the following will instruct the connection initiator to attempt to connect to 192.168.0.2:9099 and 192.168.0.3:9099 in a random order:
<remote-addresses>
<socket-address>
<address>192.168.0.2</address>
<port>9099</port>
</socket-address>
<socket-address>
<address>192.168.0.3</address>
<port>9099</port>
</socket-address>
</remote-addresses>
|
| <keep-alive-enabled> |
Optional |
Indicates whether or not keep alive (SO_KEEPALIVE) is enabled on a TCP/IP socket.
Valid values are true and false.
Keep alive is enabled by default. |
| <tcp-delay-enabled> |
Optional |
Indicates whether or not TCP delay (Nagle's algorithm) is enabled on a TCP/IP socket.
Valid values are true and false.
TCP delay is disabled by default. |
| <receive-buffer-size> |
Optional |
Configures the size of the underlying TCP/IP socket network receive buffer.
Increasing the receive buffer size can increase the performance of network I/O for high-volume connections, while decreasing it can help reduce the backlog of incoming data.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of one is assumed.
Default value is O/S dependent. |
| <send-buffer-size> |
Optional |
Configures the size of the underlying TCP/IP socket network send buffer.
The value of this element must be in the following format:
where the first non-digit (from left to right) indicates the factor with which the preceding decimal value should be multiplied:
- K or k (kilo, 210)
- M or m (mega, 220)
- G or g (giga, 230)
- T or t (tera, 240)
If the value does not contain a factor, a factor of one is assumed.
Default value is O/S dependent. |
| <connect-timeout> |
Optional |
Specifies the maximum amount of time to wait while establishing a connection with a connection acceptor.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of milliseconds is assumed.
Default value is an infinite timeout. |
| <linger-timeout> |
Optional |
Enables SO_LINGER on a TCP/IP socket with the specified linger time.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of milliseconds is assumed.
Linger is disabled by default. |
version-persistent-scheme
Used in: versioned-backing-map-scheme.
Description
The version-persistent-scheme defines a cache for storing object versioning information in a clustered cache. Specifying a size limit on the specified scheme's backing-map allows control over how many version identifiers are tracked.
Elements
The following table describes the elements you can define within the version-persistent-scheme element.
| Element |
Required/Optional |
Description |
| <cache-name-suffix> |
Optional |
Specifies the name modifier that is used to create a cache of version objects associated with a given cache. The value of this element is appended to the base cache name.
Legal value is a string.
Default value is "-persist".
For example, if the base case is named "Sessions" and this name modifier is set to "-persist", the associated version cache will be named "Sessions-persist". |
<replicated-scheme>
or <distributed-scheme> |
Required |
Specifies the scheme for the cache used to maintain the versioning information.
Legal values are:
|
version-transient-scheme
Used in: versioned-near-scheme, versioned-backing-map-scheme.
Description
The version-transient-scheme defines a cache for storing object versioning information for use in versioned near-caches. Specifying a size limit on the specified scheme's backing-map allows control over how many version identifiers are tracked.
Elements
The following table describes the elements you can define within the version-transient-scheme element.
| Element |
Required/Optional |
Description |
| <cache-name-suffix> |
Optional |
Specifies the name modifier that is used to create a cache of version objects associated with a given cache. The value of this element is appended to the base cache name.
Legal value is a string.
Default value is "-version".
For example, if the base case is named "Sessions" and this name modifier is set to "-version", the associated version cache will be named "Sessions-version". |
<replicated-scheme>
or <distributed-scheme> |
Required |
Specifies the scheme for the cache used to maintain the versioning information.
Legal values are:
|
versioned-backing-map-scheme
Used in: caching-schemes, distributed-scheme, replicated-scheme, optimistic-scheme.
Description
The versioned-backing-map-scheme is an extension of a read-write-backing-map-scheme, defining a size limited cache of a persistent store. It utilizes object versioning to determine what updates need to be written to the persistent store.
Implementation
The versioned-backing-map-scheme scheme is implemented by the com.tangosol.net.cache.VersionedBackingMap class.
Cache of an External Store
As with the read-write-backing-map-scheme, a versioned backing map maintains a cache backed by an external persistent cache store, cache misses will read-through to the backend store to retrieve the data. Cache stores may also support updates to the backend data store.
Refresh-Ahead and Write-Behind Caching
As with the read-write-backing-map-scheme both the refresh-ahead and write-behind caching optimizations are supported. See Read-Through, Write-Through, Refresh-Ahead and Write-Behind Caching for more details.
Versioning
For entries whose values implement the com.tangosol.util.Versionable interface, the versioned backing map will utilize the version identifier to determine if an update needs to be written to the persistent store. The primary benefit of this feature is that in the event of cluster node failover, the backup node can determine if the most recent version of an entry has already been written to the persistent store, and if so it can avoid an extraneous write.
Elements
The following table describes the elements you can define within the versioned-backing-map-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Specifies a custom implementation of the versioned backing map.
Any custom implementation must extend the com.tangosol.net.cache.VersionedBackingMap class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom versioned backing map implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <cachestore-scheme> |
Optional |
Specifies the store to cache. If unspecified the cached data will only reside within the internal cache, and only reflect operations performed on the cache itself. |
| <internal-cache-scheme> |
Required |
Specifies a cache-scheme which will be used to cache entries.
Legal values are:
|
| <miss-cache-scheme> |
Optional |
Specifies a cache-scheme for maintaining information on cache misses. The miss-cache is used track keys which were not found in the cache store. The knowledge that a key is not in the cache store allows some operations to perform faster, as they can avoid querying the potentially slow cache store. A size-limited scheme may be used to control how many misses are cached. If unspecified no cache-miss data will be maintained.
Legal values are:
|
| <read-only> |
Optional |
Specifies if the cache is read only. If true the cache will load data from cachestore for read operations and will not perform any writing to the cachestore when the cache is updated.
Legal values are true or false.
Default value is false. |
| <write-delay> |
Optional |
Specifies the time interval for a write-behind queue to defer asynchronous writes to the cachestore by.
The value of this element must be in the following format:
where the first non-digits (from left to right) indicate the unit of time duration:
- MS or ms (milliseconds)
- S or s (seconds)
- M or m (minutes)
- H or h (hours)
- D or d (days)
If the value does not contain a unit, a unit of seconds is assumed.
If zero, synchronous writes to the cachestore (without queuing) will take place, otherwise the writes will be asynchronous and deferred by the number of seconds after the last update to the value in the cache.
Default is zero. |
| <write-batch-factor> |
Optional |
The write-batch-factor element is used to calculate the "soft-ripe" time for write-behind queue entries.
A queue entry is considered to be "ripe" for a write operation if it has been in the write-behind queue for no less than the write-delay interval. The "soft-ripe" time is the point in time prior to the actual "ripe" time after which an entry will be included in a batched asynchronous write operation to the CacheStore (along with all other "ripe" and "soft-ripe" entries).
This element is only applicable if asynchronous writes are enabled (i.e. the value of the write-delay element is greater than zero) and the CacheStore implements the storeAll() method.
The value of the element is expressed as a percentage of the write-delay interval. For example, if the value is zero, only "ripe" entries from the write-behind queue will be batched. On the other hand, if the value is 1.0, all currently queued entries will be batched and the value of the write-delay element will be effectively ignored.
Legal values are non-negative doubles less than or equal to 1.0.
Default is zero. |
| <write-requeue-threshold> |
Optional |
Specifies the maximum size of the write-behind queue for which failed cachestore write operations are requeued.
The purpose of this setting is to prevent flooding of the write-behind queue with failed cachestore operations. This can happened in situations where a large number of successive write operations fail.
If zero, write-behind requeueing is disabled.
Legal values are positive integers or zero.
Default is zero. |
| <refresh-ahead-factor> |
Optional |
The refresh-ahead-factor element is used to calculate the "soft-expiration" time for cache entries.
Soft-expiration is the point in time prior to the actual expiration after which any access request for an entry will schedule an asynchronous load request for the entry.
This attribute is only applicable if the internal cache is a LocalCache, configured with automatic expiration.
The value is expressed as a percentage of the internal LocalCache expiration interval. If zero, refresh-ahead scheduling will be disabled. If 1.0, then any get operation will immediately trigger an asynchronous reload.
Legal values are non-negative doubles less than or equal to 1.0.
Default value is zero. |
| <rollback-cachestore-failures> |
Optional |
Specifies whether or not exceptions caught during synchronous cachestore operations are rethrown to the calling thread (possibly over the network to a remote member).
If the value of this element is false, an exception caught during a synchronous cachestore operation is logged locally and the internal cache is updated.
If the value is true, the exception is rethrown to the calling thread and the internal cache is not changed. If the operation was called within a transactional context, this would have the effect of rolling back the current transaction.
Legal values are true or false.
Default value is false. |
| <version-persistent-scheme> |
Optional |
Specifies a cache-scheme for tracking the version identifier for entries in the persistent cachestore. |
| <version-transient-scheme> |
Optional |
Specifies a cache-scheme for tracking the version identifier for entries in the transient internal cache. |
| <manage-transient> |
Optional |
Specifies if the backing map is responsible for keeping the transient version cache up to date.
If disabled the backing map manages the transient version cache only for operations for which no other party is aware (such as entry expiry). This is used when there is already a transient version cache of the same name being maintained at a higher level, for instance within a versioned-near-scheme.
Legal values are true or false.
Default value is false. |
versioned-near-scheme
Used in: caching-schemes.
| As of Coherence release 2.3, it is suggested that a near-scheme be used instead of versioned-near-scheme. Legacy Coherence applications use versioned-near-scheme to ensure coherence through object versioning. As of Coherence 2.3 the near-scheme includes a better alternative, in the form of reliable and efficient front cache invalidation. |
Description
As with the near-scheme, the versioned-near-scheme defines a two tier cache consisting of a small and fast front-end, and higher-capacity but slower back-end cache. The front-end and back-end are expressed as normal cache-schemes. A typical deployment might use a local-scheme for the front-end, and a distributed-scheme for the back-end. See the services overview for a more detailed description of versioned near caches.
Implementation
The versioned near scheme is implemented by the com.tangosol.net.cache.VersionedNearCache class.
Versioning
Object versioning is used to ensure coherence between the front and back tiers.
Elements
The following table describes the elements you can define within the near-scheme element.
| Element |
Required/Optional |
Description |
| <scheme-name> |
Optional |
Specifies the scheme's name. The name must be unique within a configuration file. |
| <scheme-ref> |
Optional |
Specifies the name of another scheme to inherit from. |
| <class-name> |
Optional |
Specifies a custom implementation of the versioned near cache.
The specified class must extend the com.tangosol.net.cache.VersionedNearCache class and declare the exact same set of public constructors. |
| <init-params> |
Optional |
Specifies initialization parameters, for use in custom versioned near cache implementations which implement the com.tangosol.run.xml.XmlConfigurable interface. |
| <listener> |
Optional |
Specifies an implementation of a com.tangosol.util.MapListener which will be notified of events occurring on the cache. |
| <front-scheme> |
Required |
Specifies the cache-scheme to use in creating the front-tier cache.
Legal values are:
For Example:
<front-scheme>
<local-scheme>
<scheme-ref>default-eviction</scheme-ref>
</local-scheme>
</front-scheme>
or
<front-scheme>
<class-scheme>
<class-name>com.tangosol.util.SafeHashMap</class-name>
<init-params></init-params>
</class-scheme>
</front-scheme>
|
| <back-scheme> |
Required |
Specifies the cache-scheme to use in creating the back-tier cache.
Legal values are:
For Example:
<back-scheme>
<distributed-scheme>
<scheme-ref>default-distributed</scheme-ref>
</distributed-scheme>
</back-scheme>
|
| <version-transient-scheme> |
Optional |
Specifies a scheme for versioning cache entries, which ensures coherence between the front and back tiers. |
| <autostart> |
Optional |
The autostart element is intended to be used by cache servers (i.e. com.tangosol.net.DefaultCacheServer). It specifies whether or not the cache services associated with this cache scheme should be automatically started at a cluster node.
Legal values are true or false.
Default value is false. |
Data Management Features
Read-Through, Write-Through, Refresh-Ahead and Write-Behind Caching
Overview
Coherence supports transparent read-write caching of any datasource, including databases, web services, packaged applications and filesystems, however, databases are the most common use case. As shorthand "database" will be used to describe any back-end data source. Effective caches must support both intensive read-only and read-write operations, and in the case of read-write operations, the cache and database must be kept fully synchronized. To accomplish this, Coherence supports Read-Through, Write-Through, Refresh-Ahead and Write-Behind caching.
| For use with Partitioned (Distributed) and Near cache topologies
Read-through/write-through caching (and variants) are intended for use only with the Partitioned (Distributed) cache topology (and by extension, Near cache). Local caches support a subset of this functionality. Replicated and Optimistic caches should not be used. |
Pluggable Cache Store
A CacheStore is an application-specific adapter used to connect a cache to a underlying datasource. The CacheStore implementation accesses the datasource via a data access mechanism (e.g., Hibernate, JDO, JDBC, another application, mainframe, another cache, etc.). The CacheStore understands how to build a Java object using data retrieved from the datasource, map and write an object to the datasource, and erase an object from the datasource.
Both the datasource connection strategy and the datasource-to-application-object mapping information are specific to the datasource schema, application class layout, and operating environment. Therefore, this mapping information must be provided by the application developer in the form of a CacheStore implementation.
Read-Through Caching
When an application asks the cache for an entry, for example the key X, and X is not already in the cache, Coherence will automatically delegate to the CacheStore and ask it to load X from the underlying datasource. If X exists in the datasource, the CacheStore will load it, return it to Coherence, then Coherence will place it in the cache for future use and finally will return X to the application code that requested it. This is called Read-Through caching. Refresh-Ahead Cache functionality may further improve read performance (by reducing perceived latency).
Write-Through Caching
Coherence can handle updates to the datasource in two distinct ways, the first being Write-Through. In this case, when the application updates a piece of data in the cache (i.e. calls put(...) to change a cache entry,) the operation will not complete (i.e. the put will not return) until Coherence has gone through the CacheStore and successfully stored the data to the underlying datasource. This does not improve write performance at all, since you are still dealing with the latency of the write to the datasource. Improving the write performance is the purpose for the Write-Behind Cache functionality.
Refresh-Ahead Caching
In the Refresh-Ahead scenario, Coherence allows a developer to configure the cache to automatically and asynchronously reload (refresh) any recently accessed cache entry from the cache loader prior to its expiration. The result is that once a frequently accessed entry has entered the cache, the application will not feel the impact of a read against a potentially slow cache store when the entry is reloaded due to expiration. The refresh-ahead time is configured as a percentage of the entry's expiration time; for instance, if specified as 0.75, an entry with a one minute expiration time that is accessed within fifteen seconds of its expiration will be scheduled for an asynchronous reload from the cache store.
Write-Behind Caching
In the Write-Behind scenario, modified cache entries are asynchronously written to the datasource after a configurable delay, whether after 10 seconds, 20 minutes, a day or even a week or longer. For Write-Behind caching, Coherence maintains a write-behind queue of the data that needs to be updated in the datasource. When the application updates X in the cache, X is added to the write-behind queue (if it isn't there already; otherwise, it is replaced), and after the specified write-behind delay Coherence will call the CacheStore to update the underlying datasource with the latest state of X. Note that the write-behind delay is relative to the first of a series of modifications – in other words, the data in the datasource will never lag behind the cache by more than the write-behind delay.
The result is a "read-once and write at a configurable interval" (i.e. much less often) scenario. There are four main benefits to this type of architecture:
- The application improves in performance, because the user does not have to wait for data to be written to the underlying datasource. (The data is written later, and by a different execution thread.)
- The application experiences drastically reduced database load: Since the amount of both read and write operations is reduced, so is the database load. The reads are reduced by caching, as with any other caching approach. The writes - which are typically much more expensive operations - are often reduced because multiple changes to the same object within the write-behind interval are "coalesced" and only written once to the underlying datasource ("write-coalescing"). Additionally, writes to multiple cache entries may be combined into a single database transaction ("write-combining") via the CacheStore.storeAll() method.
- The application is somewhat insulated from database failures: the Write-Behind feature can be configured in such a way that a write failure will result in the object being re-queued for write. If the data that the application is using is in the Coherence cache, the application can continue operation without the database being up. This is easily attainable when using the Coherence Partitioned Cache, which partitions the entire cache across all participating cluster nodes (with local-storage enabled), thus allowing for enormous caches.
- Linear Scalability: For an application to handle more concurrent users you need only increase the number of nodes in the cluster; the effect on the database in terms of load can be tuned by increasing the write-behind interval.
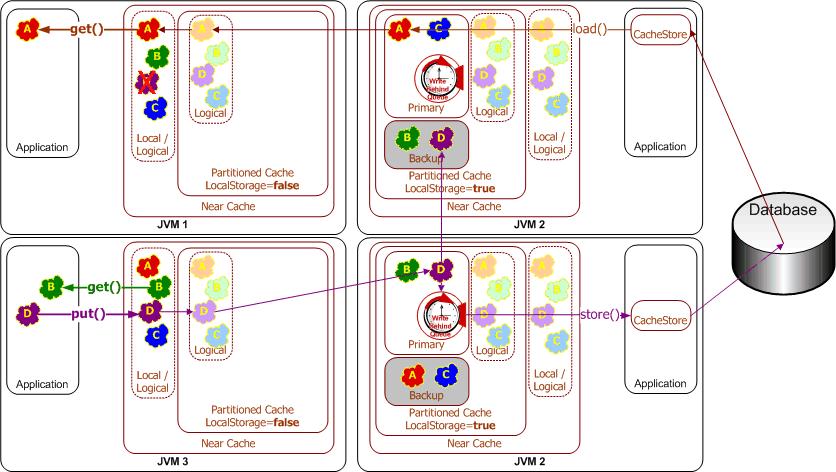
Write-Behind Requirements
While enabling write-behind caching is simply a matter of adjusting one configuration setting, ensuring that write-behind works as expected is more involved. Specifically, application design must address several design issues up-front.
The most direct implication of write-behind caching is that database updates occur outside of the cache transaction; that is, the cache transaction will (in most cases) complete before the database transaction(s) begin. This implies that the database transactions must never fail; if this cannot be guaranteed, then rollbacks must be accomodated.
As write-behind may re-order database updates, referential integrity constraints must allow out-of-order updates. Conceptually, this means using the database as ISAM-style storage (primary-key based access with a guarantee of no conflicting updates). If other applications share the database, this introduces a new challenge – there is no way to guarantee that a write-behind transaction will not conflict with an external update. This implies that write-behind conflicts must be handled heuristically or escalated for manual adjustment by a human operator.
As a rule of thumb, mapping each cache entry update to a logical database transaction is ideal, as this guarantees the simplest database transactions.
Because write-behind effectively makes the cache the system-of-record (until the write-behind queue has been written to disk), business regulations must allow cluster-durable (rather than disk-durable) storage of data and transactions.
In earlier releases of Coherence, rebalancing (due to failover/failback) would result in the re-queueing of all cache entries in the affected cache partitions (typically 1/N where N is the number of servers in the cluster). While the nature of write-behind (asynchronous queueing and load-averaging) minimized the direct impact of this, for some workloads it could be problematic. Best practice for affected applications was to use com.tangosol.net.cache.VersionedBackingMap. As of Coherence 3.2, backups are notified when a modified entry has been successfully written to the datasource, avoiding the need for this strategy. If possible, applications should deprecate use of the VersionedBackingMap if it was used only for its write-queueing behavior.
Selecting a Cache Strategy
Read-Through/Write-Through vs cache-aside
There are two common approaches to the cache-aside pattern in a clustered environment. One involves checking for a cache miss, then querying the database, populating the cache, and continuing application processing. This can result in multiple database hits if different application threads perform this processing at the same time. Alternatively, applications may perform double-checked locking (which works since the check is atomic with respect to the cache entry). This, however, results in a substantial amount of overhead on a cache miss or a database update (a clustered lock, additional read, and clustered unlock – up to 10 additional network hops, or 6-8ms on a typical gigabit ethernet connection, plus additional processing overhead and an increase in the "lock duration" for a cache entry).
By using inline caching, the entry is locked only for the 2 network hops (while the data is copied to the backup server for fault-tolerance). Additionally, the locks are maintained locally on the partition owner. Furthermore, application code is fully managed on the cache server, meaning that only a controlled subset of nodes will directly access the database (resulting in more predictable load and security). Additionally, this decouples cache clients from database logic.
Refresh-Ahead vs Read-Through
Refresh-ahead offers reduced latency compared to read-through, but only if the cache can accurately predict which cache items are likely to be needed in the future. With full accuracy in these predictions, refresh-ahead will offer reduced latency and no added overhead. The higher the rate of misprediction, the greater the impact will be on throughput (as more unnecessary requests will be sent to the database) – potentially even having a negative impact on latency should the database start to fall behind on request processing.
Write-Behind vs Write-Through
If the requirements for write-behind caching can be satisfied, write-behind caching may deliver considerably higher throughput and reduced latency compared to write-through caching. Additionally write-behind caching lowers the load on the database (fewer writes), and on the cache server (reduced cache value deserialization).
Idempotency
All CacheStore operations should be designed to be idempotent (that is, repeatable without unwanted side-effects). For write-through and write-behind caches, this allows Coherence to provide low-cost fault-tolerance for partial updates by re-trying the database portion of a cache update during failover processing. For write-behind caching, idempotency also allows Coherence to combine multiple cache udpates into a single CacheStore invocation without affecting data integrity.
Applications that have a requirement for write-behind caching but which must avoid write-combining (e.g. for auditing reasons), should create a "versioned" cache key (e.g. by combining the natural primary key with a sequence id).
Write-Through Limitations
Coherence does not support two-phase CacheStore operations across multiple CacheStore instances. In other words, if two cache entries are updated, triggering calls to CacheStore modules sitting on separate cache servers, it is possible for one database update to succeed and for the other to fail. In this case, it may be preferable to use a cache-aside architecture (updating the cache and database as two separate components of a single transaction) in conjunction with the application server transaction manager. In many cases it is possible to design the database schema to prevent logical commit failures (but obviously not server failures). Write-behind caching avoids this issue as "puts" are not affected by database behavior (and the underlying issues will have been addressed earlier in the design process). This limitation will be addressed in an upcoming release of Coherence.
Cache Queries
Cache queries only operate on data stored in the cache and will not trigger the CacheStore to load any missing (or potentially missing) data. Therefore, applications that query CacheStore-backed caches should ensure that all necessary data required for the queries has been pre-loaded. For efficiency, most bulk load operations should be done at application startup by streaming the dataset directly from the database into the cache (batching blocks of data into the cache via NamedCache.putAll(). The loader process will need to use a "Controllable CacheStore" pattern to disable circular updates back to the database. The CacheStore may be controlled via Invocation service (sending agents across the cluster to modify a local flag in each JVM) or by setting the value in a Replicated cache (a different cache service) and reading it in every CacheStore method invocation (minimal overhead compared to the typical database operation). A custom MBean can also be used, a simple task with Coherence's clustered JMX facilities.
Creating a CacheStore Implementation
CacheStore implementations are pluggable, and depending on the cache's usage of the datasource you will need to implement one of two interfaces:
These interfaces are located in the com.tangosol.net.cache package. The CacheLoader interface has two main methods: load(Object key) and loadAll(Collection keys), and the CacheStore interface adds the methods store(Object key, Object value), storeAll(Map mapEntries), erase(Object key) and eraseAll(Collection colKeys).
See the section titled sample cache store for an example implementation.
Plugging in a CacheStore Implementation
To plug in a CacheStore module, specify the CacheStore implementation class name within the distributed-scheme/backing-map-scheme/read-write-backing-map-scheme/cachestore-scheme cache configuration element.
The read-write-backing-map-scheme configures a com.tangosol.net.cache.ReadWriteBackingMap. This backing map is composed of two key elements: an internal map that actually caches the data (see internal-cache-scheme), and a CacheStore module that interacts with the database (see cachestore-scheme).
<?xml version="1.0"?>
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
<cache-config>
<caching-scheme-mapping>
<cache-mapping>
<cache-name>com.company.dto.*</cache-name>
<scheme-name>distributed-rwbm</scheme-name>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<distributed-scheme>
<scheme-name>distributed-rwbm</scheme-name>
<backing-map-scheme>
<read-write-backing-map-scheme>
<internal-cache-scheme>
<local-scheme/>
</internal-cache-scheme>
<cachestore-scheme>
<class-scheme>
<class-name>com.company.MyCacheStore</class-name>
<init-params>
<init-param>
<param-type>java.lang.String</param-type>
<param-value>{cache-name}</param-value>
</init-param>
</init-params>
</class-scheme>
</cachestore-scheme>
</read-write-backing-map-scheme>
</backing-map-scheme>
</distributed-scheme>
</caching-schemes>
</cache-config>
| The init-params element contains an ordered list of parameters that will be passed into the CacheStore constructor. The {cache-name} configuration macro is used to pass the cache name into the CacheStore implementation, allowing it to be mapped to a database table. For a complete list of available macros, please see the documentation section titled Parameter Macros.
For more detailed information on configuring write-behind and refresh-ahead, please see the read-write-backing-map-scheme element documentation, taking note of the write-batch-factor, refresh-ahead-factor, write-requeue-threshold and rollback-cachestore-failures elements. |
| Thread Count
The use of a CacheStore module will substantially increase the consumption of cache service threads (even the fastest database select is orders of magnitude slower than updating an in-memory structure). As a result, the cache service thread count will need to be increased (typically in the range 10-100). The most noticeable symptom of an insufficient thread pool is increased latency for cache requests (without corresponding behavior in the backing database). |
Implementation Considerations
Please keep the following in mind when implementing a CacheStore.
Re-entrant Calls
The CacheStore implementation must not call back into the hosting cache service. This includes OR/M solutions that may internally reference Coherence cache services. Note that calling into another cache service instance is allowed, though care should be taken to avoid deeply nested calls (as each call will "consume" a cache service thread and could result in deadlock if a cache service threadpool is exhausted).
Cache Server Classpath
The classes for cache entries (a.k.a. Value Objects, Data Transfer Objects, etc) must be in the cache server classpath (as the cache server must serialize-deserialize cache entries to interact with the CacheStore module.
CacheStore Collection Operations
The CacheStore.storeAll() method is most likely to be used if the cache is configured as write-behind and the <write-batch-factor> is configured. The CacheStore.loadAll() method is not used by Coherence at present. For similar reasons, its first use will likely require refresh-ahead to be enabled.
Connection Pools
Database connections should be retrieved from the container connection pool (or a 3rd party connection pool) or by using a thread-local lazy-initialization pattern. As dedicated cache servers are often deployed without a managing container, the latter may be the most attractive option (though the cache service thread-pool size should be constrained to avoid excessive simultaneous database connections).
Querying the Cache
Functionality
Coherence provides the ability to search for cache entries that meet a given set of criteria. The result set may be sorted if desired. Queries are evaluated with Read Committed isolation.
It should be noted that queries apply only to currently cached data (and will not use the CacheLoader interface to retrieve additional data that may satisfy the query). Thus, the dataset should be loaded entirely into cache before queries are performed. In cases where the dataset is too large to fit into available memory, it may be possible to restrict the cache contents along a specific dimension (e.g. date) and manually switch between cache queries and database queries based on the structure of the query. For maintainability, this is usually best implemented inside a cache-aware data access object (DAO).
Indexing requires the ability to extract attributes on each Partitioned cache node; in the case of dedicated CacheServer instances, this implies (usually) that application classes must be installed in the CacheServer classpath.
For Local and Replicated caches, queries are evaluated locally against unindexed data. For Partitioned caches, queries are performed in parallel across the cluster, using indexes if available. Coherence includes a Cost-Based Optimizer (CBO). Access to unindexed attributes requires object deserialization (though indexing on other attributes can reduce the number of objects that must be evaluated). When using a Near cache in front of a Partitioned cache, the query execution is similar, except that the value portion of each entry in the result set will be retrieved from the front (local) cache if available.
Simple Queries
Querying cache content is very simple:
Filter filter = new GreaterEqualsFilter("getAge", 18);
for (Iterator iter = cache.entrySet(filter).iterator(); iter.hasNext(); )
{
Map.Entry entry = (Map.Entry) iter.next();
Integer key = (Integer) entry.getKey();
Person person = (Person) entry.getValue();
System.out.println("key=" + key + " person=" + person);
}
Coherence provides a wide range of filters in the com.tangosol.util.filter package.
A LimitFilter may be used to limit the amount of data sent to the client, and also to provide "paging" for users:
int pageSize = 25;
Filter filter = new GreaterEqualsFilter("getAge", 18);
Filter limitFilter = new LimitFilter(filter, pageSize);
Set entries = cache.entrySet(limitFilter);
limitFilter.nextPage();
entries = cache.entrySet(limitFilter);
Any queryable attribute may be indexed with the addIndex method:
cache.addIndex(extractor, true, null);
The fOrdered argument specifies whether the index structure is sorted. Sorted indexes are useful for range queries, including "select all entries that fall between two dates" and "select all employees whose family name begins with 'S'". For "equality" queries, an unordered index may be used, which may have better efficiency in terms of space and time.
The comparator argument can be used to provide a custom java.util.Comparator for ordering the index.
|
This method is only intended as a hint to the cache implementation, and as such it may be ignored by the cache if indexes are not supported or if the desired index (or a similar index) already exists. It is expected that an application will call this method to suggest an index even if the index may already exist, just so that the application is certain that index has been suggested. For example in a distributed environment, each server will likely suggest the same set of indexes when it starts, and there is no downside to the application blindly requesting those indexes regardless of whether another server has already requested the same indexes.
Indexes are a feature of Coherence Enterprise Edition or higher. This method will have no effect when using Coherence Standard Edition. |
Note that queries can be combined by Coherence if necessary, and also that Coherence includes a cost-based optimizer (CBO) to prioritize the usage of indexes. To take advantage of an index, queries must use extractors that are equal ((Object.equals()) to the one used in the query.
A list of applied indexes can be retrieved from the StorageManagerMBean via JMX.
Query Concepts
This section goes into more detail on the design of the query interface, building up from the core components.
The concept of querying is based on the ValueExtractor interface. A value extractor is used to extract an attribute from a given object for the purpose of querying (and similarly, indexing). Most developers will need only the ReflectionExtractor implementation of this interface. The ReflectionExtractor uses reflection to extract an attribute from a value object by referring to a method name, typically a "getter" method like getName().
ValueExtractor extractor = new ReflectionExtractor("getName");
Any "void argument" method can be used, including Object methods like toString() (useful for prototyping/debugging). Indexes may be either traditional "field indexes" (indexing fields of objects) or "functional indexes" (indexing "virtual" object attributes). For example, if a class has field accessors "getFirstName" and "getLastName", the class may define a function "getFullName" which concatenates those names, and this function may be indexed.
To query a cache that contains objects with "getName" attributes, a Filter must be used. A filter has a single method which determines whether a given object meets a criterion.
Filter filter = new EqualsFilter(extractor, "Bob Smith");
Note that the filters also have convenience constructors that accept a method name and internally construct a ReflectionExtractor:
Filter filter = new EqualsFilter("getName", "Bob Smith");
To select the entries of a cache that satisfy a particular filter:
for (Iterator iter = cache.entrySet(filter).iterator(); iter.hasNext(); )
{
Map.Entry entry = (Map.Entry)iter.next();
Integer key = (Integer)entry.getKey();
Person person = (Person)entry.getValue();
System.out.println("key=" + key + " person=" + person);
}
To select and also sort the entries:
Iterator iter = cache.entrySet(filter, null).iterator();
The additional null argument specifies that the result set should be sorted using the "natural ordering" of Comparable objects within the cache. The client may explicitly specify the ordering of the result set by providing an implementation of Comparator. Note that sorting places significant restrictions on the optimizations that Coherence can apply, as sorting requires that the entire result set be available prior to sorting.
Using the keySet form of the queries – combined with getAll() – may provide more control over memory usage:
Set setKeys = cache.keySet(filter);
Set setPageKeys = new HashSet();
int PAGE_SIZE = 100;
for (Iterator iter = setKeys.iterator(); iter.hasNext();)
{
setPageKeys.add(iter.next());
if (setKeyPage.size() == PAGE_SIZE || !iter.hasNext())
{
Map mapResult = cache.getAll(setPageKeys);
setPageKeys.clear();
}
}
Queries Involving Multi-Value Attributes
Coherence supports indexing and querying of multi-value attributes including collections and arrays. When an object is indexed, Coherence will check to see if it is a multi-value type, and will then index it as a collection rather than a singleton. The ContainsAllFilter, ContainsAnyFilter and ContainsFilter are used to query against these collections.
Set searchTerms = new HashSet();
searchTerms.add("java");
searchTerms.add("clustering");
searchTerms.add("books");
Filter filter = new ContainsAllFilter("getWords", searchTerms);
Set entrySet = cache.entrySet(filter);
ChainedExtractor
The ChainedExtractor implementation allows chained invocation of zero-argument (accessor) methods.
ValueExtractor extractor = new ChainedExtractor("getName.length");
In the example above, the extractor will first use reflection to call getName() on each cached Person object, and then use reflection to call length() on the returned String. This extractor could be passed into a query, allowing queries (for example) to select all people with names not exceeding 10 letters. Method invocations may be chained indefinitely, for example "getName.trim.length".
Continuous Query
Overview
While it is possible to obtain a point in time query result from a Coherence cache, and it is possible to receive events that would change the result of that query, Coherence provides a feature that combines a query result with a continuous stream of related events in order to maintain an up-to-date query result in a real-time fashion. This capability is called Continuous Query, because it has the same effect as if the desired query had zero latency and the query were being executed several times every millisecond!
Coherence implements the Continuous Query functionality by materializing the results of the query into a Continuous Query Cache, and then keeping that cache up-to-date in real-time using event listeners on the query. In other words, a Coherence Continuous Query is a cached query result that never gets out-of-date.
Uses of Continuous Query Caching
There are several different general use categories for Continuous Query Caching:
- It is an ideal building block for Complex Event Processing (CEP) systems and event correlation engines.
- It is ideal for situations in which an application repeats a particular query, and would benefit from always having instant access to the up-to-date result of that query.
- A Continuous Query Cache is analogous to a materialized view, and is useful for accessing and manipulating the results of a query using the standard NamedCache API, as well as receiving an ongoing stream of events related to that query.
- A Continuous Query Cache can be used in a manner similar to a Near Cache, because it maintains an up-to-date set of data locally where it is being used, for example on a particular server node or on a client desktop; note that a Near Cache is invalidation-based, but the Continuous Query Cache actually maintains its data in an up-to-date manner.
An example use case is a trading system desktop, in which a trader's open orders and all related information needs to be maintained in an up-to-date manner at all times. By combining the Coherence*Extend functionality with Continuous Query Caching, an application can support literally tens of thousands of concurrent users.
| Continuous Query Caches are useful in almost every type of application, including both client-based and server-based applications, because they provide the ability to very easily and efficiently maintain an up-to-date local copy of a specified sub-set of a much larger and potentially distributed cached data set.
|
The Coherence Continuous Query Cache
The Coherence implementation of Continuous Query is found in the com.tangosol.net.cache.ContinuousQueryCache class. This class, like all Coherence caches, implements the standard NamedCache interface, which includes the following capabilities:
- Cache access and manipulation using the Map interface: NamedCache extends the standard Map interface from the Java Collections Framework, which is the same interface implemented by the JDK's HashMap and Hashtable classes.
- Events for all objects modifications that occur within the cache: NamedCache extends the ObservableMap interface.
- Identity-based cluster-wide locking of objects in the cache: NamedCache extends the ConcurrentMap interface.
- Querying the objects in the cache: NamedCache extends the QueryMap interface.
- Distributed Parallel Processing and Aggregation of objects in the cache: NamedCache extends the InvocableMap interface.
Since the ContinuousQueryCache implements the NamedCache interface, which is the same API provided by all Coherence caches, it is extremely simple to use, and it can be easily substituted for another cache when its functionality is called for.
Constructing a Continuous Query Cache
There are two items that define a Continuous Query Cache:
- The underlying cache that it is based on;
- A query of that underlying cache that produces the sub-set that the Continuous Query Cache will cache.
The underlying cache is any Coherence cache, including another Continuous Query Cache. A cache is usually obtained from a CacheFactory, which allows the developer to simply specify the name of the cache and have it automatically configured based on the application's cache configuration information; for example:
NamedCache cache = CacheFactory.getCache("orders");
The query is the same type of query that would be used to query any other cache; for example:
Filter filter = new AndFilter(new EqualsFilter("getTrader", traderid),
new EqualsFilter("getStatus", Status.OPEN));
Normally, to query a cache, one of the methods from the QueryMap is used; for examples, to obtain a snap-shot of all open trades for this trader:
Set setOpenTrades = cache.entrySet(filter);
Similarly, the Continuous Query Cache is constructed from those same two pieces:
ContinuousQueryCache cacheOpenTrades = new ContinuousQueryCache(cache, filter);
| Cleaning up the resources associated with a ContinuousQueryCache
A ContinuousQueryCache places one or more event listeners on its underlying cache. If the ContinuousQueryCache is used for the duration of the application, then the resources will be cleaned up when the node is shut down or otherwise stops. However, if the ContinuousQueryCache is only used for a period of time, then when the application is done using it, the application must call the release() method on the ContinuousQueryCache. |
Caching only keys, or caching both keys and values
When constructing a ContinuousQueryCache, it is possible to specify that the cache should only keep track of the keys that result from the query, and obtain the values from the underlying cache only when they are asked for. This feature may be useful for creating a ContinuousQueryCache that represents a very large query result set, or if the values are never or rarely requested. To specify that only the keys should be cached, use the constructor that allows the CacheValues property to be configured; for example:
ContinuousQueryCache cacheOpenTrades = new ContinuousQueryCache(cache, filter, false);
If necessary, the CacheValues property can also be modified after the cache has been instantiated; for example:
cacheOpenTrades.setCacheValues(true);
| CacheValues property and Event Listeners
If the ContinuousQueryCache has any standard (non-lite) event listeners, or if any of the event listeners are filtered, then the CacheValues property will automatically be set to true, because the ContinuousQueryCache uses the locally cached values to filter events and to supply the old and new values for the events that it raises. |
Listening to the ContinuousQueryCache
Since the ContinuousQueryCache is itself observable, it is possible for the client to place one or more event listeners onto it. For example:
ContinuousQueryCache cacheOpenTrades = new ContinuousQueryCache(cache, filter);
cacheOpenTrades.addMapListener(listener);
Assuming some processing has to occur against every item that is already in the cache and every item added to the cache, there are two approaches. First, the processing could occur then a listener could be added to handle any later additions:
ContinuousQueryCache cacheOpenTrades = new ContinuousQueryCache(cache, filter);
for (Iterator iter = cacheOpenTrades.entrySet().iterator(); iter.hasNext(); )
{
Map.Entry entry = (Map.Entry) iter.next();
}
cacheOpenTrades.addMapListener(listener);
However, that code is incorrect because it allows events that occur in the split second after the iteration and before the listener is added to be missed! The alternative is to add a listener first, so no events are missed, and then do the processing:
ContinuousQueryCache cacheOpenTrades = new ContinuousQueryCache(cache, filter);
cacheOpenTrades.addMapListener(listener);
for (Iterator iter = cacheOpenTrades.entrySet().iterator(); iter.hasNext(); )
{
Map.Entry entry = (Map.Entry) iter.next();
}
However, it is possible that the same entry will show up in both an event an in the Iterator, and the events can be asynchronous, so the sequence of operations cannot be guaranteed.
The solution is to provide the listener during construction, and it will receive one event for each item that is in the Continuous Query Cache, whether it was there to begin with (because it was in the query) or if it got added during or after the construction of the cache:
ContinuousQueryCache cacheOpenTrades = new ContinuousQueryCache(cache, filter, listener);
| Achieving a stable materialized view
The ContinuousQueryCache implementation faced the same challenge: How to assemble an exact point-in-time snapshot of an underlying cache while receiving a stream of modification events from that same cache. The solution has several parts. First, Coherence supports an option for synchronous events, which provides a set of ordering guarantees. Secondly, the ContinuousQueryCache has a two-phase implementation of its initial population that allows it to first query the underlying cache and then subsequently resolve all of the events that came in during the first phase. Since achieving these guarantees of data visibility without any missing or repeated events is fairly complex, the ContinuousQueryCache allows a developer to pass a listener during construction, thus avoiding exposing these same complexities to the application developer. |
Making the ContinuousQueryCache Read-Only
The ContinuousQueryCache can be made into a read-only cache; for example:
cacheOpenTrades.setReadOnly(true);
A read-only ContinuousQueryCache will not allow objects to be added to, changed in, removed from or locked in the cache.
Once a ContinuousQueryCache has been set to read-only, it cannot be changed back to read/write.
Transactions, Locks and Concurrency
Concurrency Options
Coherence provides several options for managing concurrent access to data.
| Explicit locking |
The ConcurrentMap interface (part of the NamedCache interface) supports explicit locking operations. Many developers find this simple locking API to be the most natural approach. |
| Transactions |
The TransactionMap API builds on top of the explicit locking operations to support ACID-style transactions. |
| Container Integration |
For transaction management in a Java EE container, Coherence provides a JCA resource adaptor in order to allow transactions to be managed via JTA. Although Coherence does not support XA transactions at this time, it can participate in XA transactions as the last resource. |
| EntryProcessors |
Coherence also supports a lock-free programming model through the EntryProcessor API. For many transaction types, this minimizes contention and latency and improves system throughput, without compromising the fault-tolerance of data operations. |
| Data Source Integration |
Guidelines on maintaining caches with local (non XA) data resources. |
Explicit Locking
The standard NamedCache interface extends the ConcurrentMap interface which includes basic locking methods. Locking operations are applied at the entry level by requesting a lock against a specific key in a NamedCache:
NamedCache cache = CacheFactory.getCache("dist-cache");
Object key = "example_key";
cache.lock(key, -1);
try
{
Object value = cache.get(key);
cache.put(key, value);
}
finally
{
cache.unlock(key);
}
Coherence lock functionality is similar to the Java synchronized keyword and the C# lock keyword: locks only block locks. Threads must cooperatively coordinate access to data through appropriate use of locking. If a thread has locked the key to an item, another thread can read the item without locking.
Locks are unaffected by server failure (and will failover to a backup server.) Locks are immediately released when the lock owner (client) fails.
Locking behavior varies depending on the timeout requested and the type of cache. A timeout of -1 will block indefinitely until a lock can be obtained, 0 will return immediately, and a value greater than 0 will wait the specified number of milliseconds before timing out. The boolean return value should be examined to ensure the caller has actually obtained the lock. See ConcurrentMap.lock() for more details. Note that if a timeout value is not passed to lock() the default is 0. With replicated caches, the entire cache can be locked by using ConcurrentMap.LOCK_ALL as the key, although this is usually not recommended. This operation is not supported with partitioned caches.
In both replicated and partitioned caches, gets are permitted on keys that are locked. In a replicated cache, puts are blocked, but they are not blocked in a partitioned cache. Once a lock is in place, it is the responsibility of the caller (either in the same thread or the same cluster node, depending on the lease-granularity configuration) to release the lock. This is why locks should always be released with a finally clause (or equivalent). If this is not done, unhandled exceptions may leave locks in place indefinitely.
Transactions
A TransactionMap can be used to update multiple items in a Coherence cache in a transaction. In order to perform transactions with a TransactionMap, the Java Transaction API (JTA) libraries must be present in the classpath. TransactionMaps are created using the CacheFactory:
NamedCache cache = CacheFactory.getCache("dist-cache");
TransactionMap tmap = CacheFactory.getLocalTransaction(cache);
Before using a TransactionMap, concurrency and isolation levels should be set to the desired level. For most short lived, highly concurrent transactions, a concurrency level of CONCUR_PESSIMISTIC and an isolation level of TRANSACTION_REPEATABLE_GET should be used. For most long lived transactions that don't occur as often, CONCUR_OPTIMISTIC and TRANSACTION_REPEATABLE_GET are good defaults. The combination of concurrency level CONCUR_PESSIMISTIC and isolation level TRANSACTION_SERIALIZABLE will lock the entire cache. As mentioned previously, partitioned caches do not allow the entire cache to be locked, thus this mode will not work for partitioned caches. (In general, this level of isolation is not required for reliable transaction processing.) Queries against caches (calling keySet(Filter) or entrySet(Filter)) are always performed with READ_COMMITTED isolation. For more information about concurrency and isolation levels, see the TransactionMap API.
Here is how to set the isolation and concurrency levels:
tmap.setTransactionIsolation(TransactionMap.TRANSACTION_REPEATABLE_GET);
tmap.setConcurrency(TransactionMap.CONCUR_PESSIMISTIC);
Now the TransactionMap can be used to update the cache in a transaction:
import com.tangosol.net.CacheFactory;
import com.tangosol.net.NamedCache;
import com.tangosol.util.Base;
import com.tangosol.util.TransactionMap;
import java.util.Collection;
import java.util.Collections;
public class TxMapSample
extends Base
{
public static void main(String[] args)
{
NamedCache cache = CacheFactory.getCache("dist-cache");
String key1 = "key1";
String key2 = "key2";
cache.put(key1, new Integer(1));
cache.put(key2, new Integer(1));
out("Initial value for key 1: " + cache.get(key1));
out("Initial value for key 2: " + cache.get(key2));
TransactionMap mapTx = CacheFactory.getLocalTransaction(cache);
mapTx.setTransactionIsolation(TransactionMap.TRANSACTION_REPEATABLE_GET);
mapTx.setConcurrency(TransactionMap.CONCUR_PESSIMISTIC);
Collection txnCollection = Collections.singleton(mapTx);
boolean fTxSucceeded = false;
try
{
mapTx.begin();
int i1 = ((Integer)mapTx.get(key1)).intValue();
mapTx.put(key1, new Integer(++i1));
int i2 = ((Integer)mapTx.get(key2)).intValue();
mapTx.put(key2, new Integer(++i2));
fTxSucceeded = CacheFactory.commitTransactionCollection(txnCollection, 1);
}
catch (Throwable t)
{
CacheFactory.rollbackTransactionCollection(txnCollection);
}
int v1 = ((Integer) cache.get(key1)).intValue();
int v2 = ((Integer) cache.get(key2)).intValue();
out("Transaction " + (fTxSucceeded ? "succeeded" : "did not succeed"));
out("Updated value for key 1: " + v1);
out("Updated value for key 2: " + v2);
azzert(v1 == 2, "Expected value for key1 == 2");
azzert(v2 == 2, "Expected value for key2 == 2");
}
}
Although the CacheFactory API provides helper methods for committing and rolling back a collection of TransactionMaps, the collection of TransactionMaps will not be committed atomically. If one of the transactions fails during commit, the state of that TransactionMap is undetermined, and some of the transactions may not be rolled back.
Note that MapListeners registered with caches in a transaction will fire a MapEvent as soon as the item is committed. MapListeners do not take transactions into account. Therefore, in the above example it is possible to receive a MapEvent for key1 before key2 is updated.
Container Integration
JCA
Coherence ships with a JCA 1.0 compliant resource adaptor that can be used to manage transactions in a Java EE container. It is packaged in a resource adaptor archive (RAR) file that can be deployed to any Java EE container compatible with JCA 1.0. Once deployed, JTA can be used to execute the transaction:
String key = "key";
Context ctx = new InitialContext();
UserTransaction tx = null;
try
{
tx = (UserTransaction) ctx.lookup("java:comp/UserTransaction");
tx.begin();
CacheAdapter adapter = null;
try
{
adapter = new CacheAdapter(ctx, "tangosol.coherenceTx",
CacheAdapter.CONCUR_OPTIMISTIC,
CacheAdapter.TRANSACTION_GET_COMMITTED, 0);
NamedCache cache = adapter.getNamedCache("dist-test",
getClass().getClassLoader());
int n = ((Integer)cache.get(key)).intValue();
cache.put(key, new Integer(++n));
}
catch (Throwable t)
{
String sMsg = "Failed to connect: " + t;
System.err.println(sMsg);
t.printStackTrace(System.err);
}
finally
{
try
{
adapter.close();
}
catch (Throwable ex)
{
System.err.println("SHOULD NOT HAPPEN: " + ex);
}
}
}
finally
{
try
{
tx.commit();
}
catch (Throwable t)
{
String sMsg = "Failed to commit: " + t;
System.err.println(sMsg);
}
}
XA
Coherence can participate in an XA transaction as the last resource. This feature is supported by most transaction managers and is known by various names, such as "Last Resource Commit," "Last Participant," or "Logging Last Resource." In this scenario, the completion of a transaction would involve the following steps:
- prepare is called on all XA resources
- commit is called on the Coherence transaction
- if the commit is successful, commit is called on the other XA participants in the transaction.
Refer to your transaction manager's documentation on XA last resource configuration for further details on this technique.
Entry Processors
The InvocableMap superinterface of NamedCache allows for concurrent lock-free execution of processing code within a cache. This processing is performed by an EntryProcessor. In exchange for reduced flexibility compared to the more general purpose TransactionMap and ConcurrentMap explicit locking APIs, EntryProcessors provide the highest levels of efficiency without compromising data reliability.
Since EntryProcessors perform an implicit low level lock on the entries they are processing, the end user can place processing code in an EntryProcessor without having to worry about concurrency control. Note that this is not the same as the explicit lock(key) functionality provided by ConcurrentMap!
In a replicated cache or a partitioned cache running under Caching Edition, execution will happen locally on the initiating client. In partitioned caches running under Enterprise Edition or greater, the execution occurs on the node that is responsible for primary storage of the data.
InvocableMap provides three methods of starting EntryProcessors:
- Invoke an EntryProcessor on a specific key. Note that the key need not exist in the cache in order to invoke an EntryProcessor on it.
- Invoke an EntryProcessor on a collection of keys.
- Invoke an EntryProcessor on a Filter. In this case, the Filter will be executed against the cache entries. Each entry that matches the Filter criteria will have the EntryProcessor executed against it. For more information on Filters, see Querying the Cache.
In partitioned caches running under Enterprise Edition or greater, EntryProcessors will be executed in parallel across the cluster (on the nodes that own the individual entries.) This provides a significant advantage over having a client lock all affected keys, pull all required data from the cache, process the data, place the data back in the cache, and unlock the keys. The processing occurs in parallel across multiple machines (as opposed to serially on one machine) and the network overhead of obtaining and releasing locks is eliminated.
Here is a sample of high level concurrency control. Code that will require network access is commented:
final NamedCache cache = CacheFactory.getCache("dist-test");
final String key = "key";
cache.put(key, new Integer(1));
if (cache.lock(key, 0))
{
try
{
Integer i = (Integer) cache.get(key);
cache.put(key, new Integer(i.intValue() + 1));
}
finally
{
cache.unlock(key);
}
}
The following is an equivalent technique using an Entry Processor. Again, network access is commented:
final NamedCache cache = CacheFactory.getCache("dist-test");
final String key = "key";
cache.put(key, new Integer(1));
cache.invoke(key, new MyCounterProcessor());
...
public static class MyCounterProcessor
extends AbstractProcessor
{
public Object process(InvocableMap.Entry entry)
{
Integer i = (Integer) entry.getValue();
entry.setValue(new Integer(i.intValue() + 1));
return null;
}
}
EntryProcessors are individually executed atomically, however multiple EntryProcessor invocations via InvocableMap.invokeAll() will not be executed as one atomic unit. As soon as an individual EntryProcessor has completed, any updates made to the cache will be immediately visible while the other EntryProcessors are executing. Furthermore, an uncaught exception in an EntryProcessor will not prevent the others from executing. Should the primary node for an entry fail while executing an EntryProcessor, the backup node will perform the execution instead. However if the node fails after the completion of an EntryProcessor, the EntryProcessor will not be invoked on the backup.
Note that in general, EntryProcessors should be short lived. Applications with longer running EntryProcessors should increase the size of the distributed service thread pool so that other operations performed by the distributed service are not blocked by the long running EntryProcessor.
Coherence includes several EntryProcessor implementations for common use cases. Further details on these EntryProcessors, along with additional information on parallel data processing, can be found in this document: Provide a Data Grid.
Data Source Integration
When using write-behind and write-through to a database in a Coherence cache, transactional behavior must be taken into account. With write-through enabled, the put will succeed if the item is successfully stored in the database. Otherwise, the exception that occurred in the CacheStore will be rethrown to the client. (Note: in order to enable this behavior, set <rollback-cachestore-failures> to true. See read-write-backing-map-scheme for more details.) This only applies when updating one cache item at a time; if two cache items are updated at a time then each CacheStore operation will be a distinct database transaction. This limitation will be addressed in a future release of Coherence.
Write-behind caching provides much higher throughput and performance. However, writes to the database are performed after the cache has been updated. Therefore care must be taken to ensure that writes to the database will not fail. Write-behind should only be used in applications where:
- data constraints will be managed by the application, not the database
- no other application will update the database
See Read-Through, Write-Through, Refresh-Ahead and Write-Behind Caching for more information on cache stores.
If multiple updates to cache entries must be persisted to the database in a transaction, it may be more suitable to implement a cache-aside pattern where the client is responsible for updating the database and the cache. Note that a CacheLoader may still be used to load cache misses from the data source.
Advanced Features
Specifying a Custom Eviction Policy
The LocalCache class is used for size-limited caches. It is used both for caching on-heap objects, as in a local cache or the front portion of a near cache, and can also be used as the backing map for a partitioned cache. Applications can provide custom eviction policies for use with a LocalCache. Note that Coherence's default eviction policy is very effective for most workloads, and so the vast majority of applications will not need to provide a custom policy. Also, it is generally best to restrict the usage of eviction policies to scenarios where the evicted data is present in a backing system (e.g., the back portion of a near cache or a database) – eviction should be treated as a physical operation (freeing memory) and not a logical operation (deleting an entity).
The following source code example shows the implementation of a simple custom eviction policy:
import com.tangosol.net.cache.CacheEvent;
import com.tangosol.net.cache.LocalCache;
import com.tangosol.net.cache.OldCache;
import com.tangosol.util.AbstractMapListener;
import com.tangosol.util.MapEvent;
import java.util.Iterator;
public class MyEvictionPolicy extends AbstractMapListener implements OldCache.EvictionPolicy
{
LocalCache m_cache = null;
public void entryInserted(MapEvent evt)
{
System.out.println("entryInserted:" + isSynthetic(evt) + evt);
if (m_cache == null)
{
m_cache = (LocalCache) evt.getMap();
}
}
public void entryUpdated(MapEvent evt)
{
System.out.println("entryUpdated:" + isSynthetic(evt) + evt);
}
public void entryDeleted(MapEvent evt)
{
System.out.println("entryDeleted:" + isSynthetic(evt) + evt);
}
String isSynthetic(MapEvent evt)
{
return ((CacheEvent) evt).isSynthetic() ? " SYNTHETIC " : " ";
}
public void entryTouched(OldCache.Entry entry)
{
System.out.println("entryTouched:" + entry.getKey());
}
public void requestEviction(int cMaximum)
{
int cCurrent = m_cache.getUnits();
System.out.println("requestEviction: current:" + cCurrent + " to:" + cMaximum);
for (Iterator iter = m_cache.entrySet().iterator(); iter.hasNext();)
{
OldCache.Entry entry = (OldCache.Entry) iter.next();
if (m_cache.getUnits() > cMaximum)
{
m_cache.evict(entry.getKey());
}
else
{
break;
}
}
}
public MyEvictionPolicy()
{
}
}
This Coherence cache configuration (e.g. coherence-cache-config.xml) shows how to plug in the eviction policy:
<?xml version="1.0"?>
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
<cache-config>
<caching-scheme-mapping>
<cache-mapping>
<cache-name>test</cache-name>
<scheme-name>example-near</scheme-name>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<distributed-scheme>
<scheme-name>example-distributed</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<local-scheme>
<scheme-ref>example-backing-map</scheme-ref>
</local-scheme>
</backing-map-scheme>
<autostart>true</autostart>
</distributed-scheme>
<near-scheme>
<scheme-name>example-near</scheme-name>
<front-scheme>
<local-scheme>
<eviction-policy>
<class-scheme>
<class-name>MyEvictionPolicy</class-name>
</class-scheme>
</eviction-policy>
<high-units>10</high-units>
</local-scheme>
</front-scheme>
<back-scheme>
<distributed-scheme>
<scheme-ref>example-distributed</scheme-ref>
</distributed-scheme>
</back-scheme>
<invalidation-strategy>all</invalidation-strategy>
<autostart>true</autostart>
</near-scheme>
<local-scheme>
<scheme-name>example-backing-map</scheme-name>
<eviction-policy>HYBRID</eviction-policy>
<high-units>{back-size-limit 0}</high-units>
<expiry-delay>{back-expiry 1h}</expiry-delay>
<flush-delay>1m</flush-delay>
<cachestore-scheme></cachestore-scheme>
</local-scheme>
</caching-schemes>
</cache-config>
Partition Affinity
Overview
Partition affinity describes the concept of ensuring that a group of related cache entries is contained within a single cache partition. This ensures that all relevant data is managed on a single primary cache node (without compromising fault-tolerance).
Affinity may span multiple caches (as long as they are managed by the same cache service, which will generally be the case). For example, in a master-detail pattern such as an "Order-LineItem", the Order object may be co-located with the entire collection of LineItem objects that are associated with it.
The benefit is two-fold. First, only a single cache node is required to manage queries and transactions against a set of related items. Second, all concurrency operations can be managed locally, avoiding the need for clustered synchronization.
A number of standard Coherence operations can benefit from affinity, including cache queries, InvocableMap operations and the getAll/putAll/removeAll methods.
| Partition affinity is specified in terms of entry keys (not values). As a result, the association information must be present in the key class. Similarly, the association logic applies to the key class, not the value class.
|
Specifying Affinity
Affinity is specified in terms of a relationship to a partitioned key. In the Order-LineItem example above, the Order objects would be partitioned normally, and the LineItem objects would be associated with the appropriate Order object.
The association does not need to be directly tied to the actual parent key – it only needs to be a functional mapping of the parent key. It could be a single field of the parent key (even if it is non-unique), or an integer hash of the parent key. All that matters is that all child keys return the same associated key; it does not matter whether the associated key is an actual key (it is simply a "group id"). This fact may help minimize the size impact on the child key classes that don't already contain the parent key information (as it is derived data, the size of the data may be decided explicitly, and it also will not affect the behavior of the key). Note that making the association too general (having too many keys associated with the same "group id") can cause a "lumpy" distribution (if all child keys return the same association key regardless of what the parent key is, the child keys will all be assigned to a single partition, and will not be spread across the cluster).
There are two ways to ensure that a set of cache entries are co-located. Note that association is based on the cache key, not the value (otherwise updating a cache entry could cause it to change partitions). Also, note that while the Order will be co-located with the child LineItems, Coherence at present does not support composite operations that span multiple caches (e.g. updating the Order and the collection of LineItems within a single invocation request com.tangosol.util.InvocableMap.EntryProcessor).
For application-defined keys, the class (of the cache key) may implement com.tangosol.net.cache.KeyAssociation as follows:
import com.tangosol.net.cache.KeyAssociation;
public class LineItemId implements KeyAssociation
{
public Object getAssociatedKey()
{
return getOrderId();
}
}
Applications may also provide a custom KeyAssociator:
import com.tangosol.net.partition.KeyAssociator;
public class LineItemAssociator implements KeyAssociator
{
public Object getAssociatedKey(Object oKey)
{
if (oKey instanceof LineItemId)
{
return ((LineItemId) oKey).getOrderId();
}
else if (oKey instanceof OrderId)
{
return oKey;
}
else
{
return null;
}
}
public void init(PartitionedService service)
{
}
}
The key associator may be configured for a NamedCache in the associated distributed-scheme element:
<distributed-scheme>
<key-associator>LineItemAssociator</key-associator>
</distributed-scheme>
An example of using affinity for efficient query ( NamedCache.entrySet(Filter)) and cache access ( NamedCache.getAll(Collection)).
OrderId orderId = new OrderId(1234);
Filter filterEq = new EqualsFilter("getOrderId", orderId);
Filter filterAsc = new KeyAssociatedFilter(filterEq, orderId);
Set setLineItemKeys = cacheLineItems.keySet(filterAsc);
Set setLineItems = cacheLineItems.getAll(setLineItemKeys);
cacheLineItems.keySet().removeAll(setLineItemKeys);
Serialization Paged Cache
Summary
Oracle Coherence provides explicit support for efficient caching of huge amounts of automatically-expiring data using potentially high-latency storage mechanisms such as disk files. The benefits include supporting much larger data sets than can be managed in memory, while retaining an efficient expiry mechanism for timing out the management (and automatically freeing the resources related to the management) of that data. Optimal usage scenarios include the ability to store many large objects, XML documents or content that will be rarely accessed, or whose accesses will tolerate a higher latency if the cached data has been paged to disk.
Description
This feature is known as a Serialization Paged Cache:
- Serialization implies that objects stored in the cache are serialized and stored in a Binary Store; refer to the existing features Serialization Map and Serialization Cache.
- Paged implies that the objects stored in the cache are segmented for efficiency of management; in this case, the pages represent periods of time such that the cache could be divided into pages of one hour each.
- Cache implies that there can be limits specified to the size of the cache; in this case, the limit is the maximum number of concurrent pages that the cache will manage before expiring pages, starting with the oldest page.
The result is a feature that organizes data in the cache based on the time that the data was placed in the cache, and then is capable of efficiently expiring that data from the cache, an entire page at a time, and typically without having to reload any data from disk.
The primary configuration for the Serialization Paged Cache is composed of two parameters: The number of pages that the cache will manage, and the length of time represented by each page. For example, to cache data for one day, the cache can be configured as 24 pages of one hour each, or 96 pages of 15 minutes each, etc.
Each page of data in the cache is managed by a separate Binary Store. The cache requires a Binary Store Manager, which provides the means to create and destroy these Binary Stores. Coherence 2.4 provides Binary Store Managers for all of the built-in Binary Store implementations, including disk (referred to as "LH") and the various NIO implementations.
A new optimization is provided in Coherence 2.4 for the partitioned cache service, since - when it is used to back a partitioned cache - the data being stored in any of the Serialization Maps and Caches is entirely binary in form. This is called the Binary Map optimization, and when it is enabled, it gives the Serialization Map, the Serialization Cache and the Serialization Paged Cache permission to assume that all data being stored in the cache is binary. The result of this optimization is a lower CPU and memory utilization, and also slightly higher performance.
Explicit support is also provided in the Serialization Paged Cache for the high-availability features of the partitioned cache service, by providing a configuration that can be used for the primary storage of the data as well as a configuration that is optimized for the backup storage of the data. The configuration for the backup storage is known as a passive model, because it does not actively expire data from its storage, but rather reflects the expiration that is occurring on the primary cache storage. When using the high-availability data feature (a backup count of one or greater; the default is one) for a partitioned cache service, and using the Serialization Paged Cache as the backing storage for the service, we strongly suggest that you also use the Serialization Paged Cache as the backup store, and configure the backup with the passive option.
When used with the distributed cache service, special considerations should be made for load balancing and failover purposes. The partition-count parameter of the distributed cache service should be set higher than normal if the amount of cache data is very large or huge; that will break up the overall cache into smaller chunks for load-balancing and recovery processing due to failover. For example, if the cache is expected to be one terabyte in size, twenty thousand partitions will break the cache up into units averaging about 50MB in size. If a unit (the size of a partition) is too large, it will cause an out-of-memory condition when load-balancing the cache. (Remember to make sure that the partition count is a prime number; see http://primes.utm.edu/lists/small/ for lists of prime numbers that you can use.)
In order to support huge caches (e.g. terabytes) of expiring data, the expiration processing is performed concurrently on a daemon thread with no interruption to the cache processing. The result is that many thousands or millions of objects can exist in a single cache page, and they can be expired asynchronously, thus avoiding any interruption of service. The daemon thread is an option that is enabled by default, but it can be disabled.
When the cache is used for large amounts of data, the pages will typically be disk-backed. Since the cache eventually expires each page, thus releasing the disk resources, the cache uses a virtual erase optimization by default. This means that data that is explicitly removed or expired from the cache is not actually removed from the underlying Binary Store, but when a page (a Binary Store) is completely emptied, it will be erased in its entirety. This reduces I/O by a considerable margin, particularly during expiry processing as well as during operations such as load-balancing that have to redistribute large amounts of data within the cluster. The cost of this optimization is that the disk files (if a disk-based Binary Store option is used) will tend to be larger than the data that they are managing would otherwise imply; since disk space is considered to be inexpensive compared to other factors such as response times, the virtual erase optimization is enabled by default, but it can be disabled. Note that the disk space is typically allocated locally to each server, and thus a terabyte cache partitioned over one hundred servers would only use about 20GB of disk space per server (10GB for the primary store and 10GB for the backup store, assuming one level of backup.)
Security Framework
Transport Layer Security
For information on transport layer security please see the network encryption filters section.
Access Controller
Security Framework in Coherence is based on a concept of Clustered Access Controller, which can be turned on (activated) by a configurable parameter or command line attribute.
The Access Controller manages access to the "clustered resources", such as clustered services and caches and controls operations that include (but not limited to) the following:
- creating a new clustered cache or service;
- joining an existing clustered cache or service;
- destroying an existing clustered cache.
The Access Controller serves three purposes:
- to grant or deny access to a protected clustered resource based on the caller's permissions
- to encrypt outgoing communications based on the caller's private credentials
- to decrypt incoming communications based on the caller's public credentials
Coherence uses a local LoginModule (see JAAS Reference Guide for details) to authenticate the caller and an Access Controller on one or more cluster nodes to verify the caller's access rights.
The Access Controller is a pluggable component that could be declared in the Coherence Deployment Descriptor. The specified class should implement the com.tangosol.net.security.AccessController interface.
Coherence provides a default Access Controller implementation that is based on the Key Management infrastructure that is shipped as a standard part of Sun's JDK.
Each clustered service in Coherence maintains a concept of a "senior" service member (cluster node), which serves as a controlling agent for a particular service. While the senior member does not have to consult anyone when accessing a clustered resource, any junior node willing to join that service has to request and receive a confirmation from the senior member, which in turn notifies all other cluster nodes about the joining node.
Since Coherence is a system providing distributed data management and computing, the security subsystem is designed to operate in a partially hostile environment. We assume that when there is data shared between two cluster nodes either node could be a malicious one - lacking sufficient credentials to join a clustered service or obtain access to a clustered resource.
Let's call a cluster node that may try to gain unauthorized access to clustered resources via non-standard means as a "malicious" node. The means of such an access could vary. They could range from attempts to get protected or private class data using reflection, replacing classes in the distribution (coherence.jar, tangosol.jar or other application binaries), modifying classes on-the-fly using custom ClassLoader(s) etc. Alternatively, a cluster node that never attempts to gain unauthorized access to clustered resources via non-standard means will be called a "trusted" node. It's important to note that even a trusted node may attempt to gain access to resources without having sufficient rights, but it does so in a standard way via exposed standard API.
File system mechanisms (the same that is used to protect the integrity of the Java runtime libraries) and standard Java security policy could be used to resolve an issue of guarantying the trustworthiness of a given single node. In a case of inter-node communications there are two dangers that we have to consider:
- A malicious node surpasses the local access check and attempts to join a clustered service or gain access to a clustered resource controlled by a trusted node;
- A malicious node creates a clustered service or clustered resource becoming its controller.
To prevent either of these two scenarios from occurring Coherence utilizes two-ways encryption algorithm: all client requests must be accompanied by the proof of identity and all service responses must be accompanied by the proof of trustworthiness.
Proof of Identity
In a case of an active Access Controller the client code could use the following construct to authenticate the caller and perform necessary actions:
import com.tangosol.net.security.Security;
import java.security.PrivilegedAction;
import javax.security.auth.Subject;
...
Subject subject = Security.login(sName, acPassword);
PrivilegedAction action = new PrivilegedAction()
{
public Object run()
{
...
}
};
Security.runAs(subject, action);
During the "login" call Coherence utilizes JAAS that runs on the caller's node to authenticate the caller. In a case of successful authentication, it uses the local Access Controller to:
- Determine whether or not the local caller has sufficient rights to access the protected clustered resource (local access check);
- Encrypt the outgoing communications regarding the access to the resource with the caller's private credentials retrieved during the authentication phase;
- Decrypt the result of the remote check using the requestor's public credentials;
- In the case that access is granted verify whether the responder had sufficient rights to do so.
Step 2 in this cycle serves a role of the proof of identity for the responder preventing a malicious node pretending to pass the local access check phase.
There are two alternative ways to provide the client authentication information. First, a reference to a CallbackHandler could be passed instead of the user name and password. Second, a previously authenticated Subject could be used, which could become handy when Coherence is used by a J2EE application that could retrieve an authenticated Subject from the application container.
If a caller's request comes without any authentication context, Coherence will instantiate and call a CallbackHandler implementation declared in the Coherence operational descriptor to retrieve the appropriate credentials. However that "lazy" approach is much less efficient, since without externally defined call scope, every access to a protected clustered resource will force repetitive authentication calls.
Proof of Trustworthiness
Every clustered resource in Coherence is created by an explicit API call. A senior service member retains the private credentials that are presented during that call as a proof of trustworthiness. When the senior service member receives an access request to a protected clustered resource, it use the local Access Controller to:
- Decrypt the incoming communication using the remote caller's public credentials;
- Determine whether or not the remote caller has sufficient rights to access the protected clustered resource (remote access check);
- Encrypt the response of access check using the private credentials of the service.
Since the requestor will accept the response as valid only after decrypting it, step 3) in this cycle serves a role of the proof of trustworthiness for the requestor preventing a malicious node pretending to be a valid service senior.
Default Access Controller implementation
Coherence is shipped with an Access Controller implementation that uses a standard Java KeyStore. The implementation class is com.tangosol.net.security.DefaultController and the corresponding part of the Coherence operational descriptor used to configure the default implementation looks like:
<security-config>
<enabled system-property="tangosol.coherence.security">true</enabled>
<login-module-name>Coherence</login-module-name>
<access-controller>
<class-name>com.tangosol.net.security.DefaultContoller</class-name>
<init-params>
<init-param id="1">
<param-type>java.io.File</param-type>
<param-value>./keystore.jks</param-value>
</init-param>
<init-param id="2">
<param-type>java.io.File</param-type>
<param-value>./permissions.xml</param-value>
</init-param>
</init-params>
</access-controller>
<callback-handler>
<class-name/>
</callback-handler>
</security-config>
The "login-module-name" element serves as the application name in a login configuration file (see JAAS Reference Guide1 for complete details). Coherence is shipped with a Java keystore (JKS) based login module that is contained in the coherence-login.jar, which depends only on standard Java runtime classes and could be placed in the JRE's lib/ext (standard extension) directory. The corresponding login module declaration would look like:
Coherence {
com.tangosol.security.KeystoreLogin required
keyStorePath="${user.dir}${/}keystore.jks";
};
The "access-controller" element defines the AccessController implementation that takes two parameters to instantiate. The first parameter is a path to the same keystore that will be used by both controller and login module. The second parameter is a path to the access permission file (see discussion below).
The "callback-handler" is an optional element that defines a custom implementation of the javax.security.auth.callback.CallbackHandler interface that would be instantiated and used by Coherence to authenticate the client when all other means are exhausted.
Two more steps have to be performed, to make the default Access Controller implementation usable in your application. First, we have to create a keystore with necessary principals. Then, we need to create the "permissions" file that would declare the access right for the corresponding principals.
Consider the following example that creates three principals: "admin" to be used by the Java Security framework; "manager" and "worker" to be used by Coherence:
Consider the following example that assigns all rights to the "Manager" principal, only "join" rights to the "Worker" principal for caches that have names prefixed by "common" and all rights to the "Worker" principal for the invocation service named "invocation":
<?xml version='1.0'?>
<permissions>
<grant>
<principal>
<class>javax.security.auth.x500.X500Principal</class>
<name>CN=Manager,OU=MyUnit</name>
</principal>
<permission>
<target>*</target>
<action>all</action>
</permission>
</grant>
<grant>
<principal>
<class>javax.security.auth.x500.X500Principal</class>
<name>CN=Worker,OU=MyUnit</name>
</principal>
<permission>
<target>cache=common*</target>
<action>join</action>
</permission>
<permission>
<target>service=invocation</target>
<action>all</action>
</permission>
</grant>
</permissions>
Working in applications with installed security manager
1. The policy file format is fully described in J2SE Security Guide.
Example:
grant codeBase "file:${coherence.home}/lib/tangosol.jar"
{
permission java.security.AllPermission;
};
grant codeBase "file:${coherence.home}/lib/coherence.jar"
{
permission java.security.AllPermission;
};
2. The binaries could be signed using the JDK jarsigner tool, for example:
jarsigner -keystore ./keystore.jks -storepass password coherence.jar admin
and then additionally protected in the policy file:
grant SignedBy "admin" codeBase "file:${coherence.home}/lib/coherence.jar"
{
permission java.security.AllPermission;
};
3. All relevant files such as policy format, coherence binaries, and permissions should be protected by operating system mechanisms to prevent malicious modifications.
Network Filters
What is a Filter?
A filter is a mechanism for plugging into the low-level TCMP stream protocol. Every message that is sent across the network by Coherence is streamed through this protocol. Coherence supports custom filters. By writing a filter, the contents of the network traffic can be modified. The most common examples of modification are encryption and compression.
Standard Filters
Compression Filter
The compression filter is based on the java.util.zip package and compresses message contents thus reducing the network load. This is useful when there is ample CPU available but insufficient network bandwidth. See the configuration section for information on enabaling this filter.
Encryption Filters
Coherence ships with two JCA based encryption filters which can be used to protect the custered communications for privacy and authenticity.
Symmetric Encryption Filter
This filter uses symmetric encryption to protect cluster communications. The encryption key is generated from a shared password known to all cluster members. This filter is suitable for small deployments or where the maintenance and protection of a shared password is feasible.
To enable this filter specify which services will have their traffic encrypted via this filter, or to enable it for all cluster traffic you may simply specify it as a filter for the <outgoing-message-handler> element.
<outgoing-message-handler>
<use-filters>
<filter-name>symmetric-encryption</filter-name>
</use-filters>
</outgoing-message-handler>
The shared password may either be specified in the <filters> section of the operational configuration file, or via the tangosol.coherence.security.password system property, see the Symmetric Encryption Filter Parameters section for additional configuration options.
PKCS Encryption Filter
This filter uses public key cryptography (asymmetric encryption) to protect the cluster join protocol, and then switches over to much faster symmetric encryption for service level data transfers. Unlike the symmetric encryption filter, there is no persisted shared secret. The symmetric encryption key is randomlly generated by the cluster's senior member, and is securly transfer to authenticated cluster members as part of the cluster join protocol. This encyrption filter is suitable for deployments where maintenance of a shared secret is not feasable.
| This filter requires the JVM be configured with a JCA public key cryptography provider implementation such as Bouncy Castle, which supports asymmetric block ciphers. See the JCA documentation for details on installing and configuring JCA providers. |
In the default setup each cluster node must be configured with a Java Keystore from which it may retrieve its identity Certificate and associated private key, as well as a set of trusted Certificates for other cluster members. You can consturct this keystore as follows:
Create a Java Keystore and the local cluster member's password protected certificate and private key.
Export this public certificate for inclusion in all cluster members keystores.
Import the Certificates of other trusted cluster members. Each certificate must be stored under a unique but otherwise unimportant alias.
At this point you will have one keystore per cluster node, each containing a single private key plus a full set of trusted public certificates. If new nodes are to be added to the cluster the keystores of all existing nodes must be updated with the new node's certificate.
| You may also choose to supply custom key and trust management logic to eliminate the need for a full keystore per node. See the implementation's documentation for details on customization. |
Then configure the cluster to encrypt all traffic using this filter by specifying it in the <outgoing-message-handler>.
<outgoing-message-handler>
<use-filters>
<filter-name>pkcs-encryption</filter-name>
</use-filters>
</outgoing-message-handler>
The keystore and alias password may either be specified in the <filters> section of the operational configuration file, or via the tangosol.coherence.security.password system property, see the PKCS Encryption Filter Parameters section for additional configuration options.
Note unlike the Symmetric Encryption Filter, this filter is not currently supported by Coherence*Extend, or on a service by service level.
Configuring Filters
There are two steps to configuring a filter. The first is to declare the filter in the <filters> XML element of the tangosol-coherence.xml file:
<filter>
<filter-name>gzip</filter-name>
<filter-class>com.tangosol.net.CompressionFilter</filter-class>
<init-params>
<init-param>
<param-name>strategy</param-name>
<param-value>gzip</param-value>
</init-param>
</init-params>
</filter>
For more information on the structure of the <filters> XML element of the tangosol-coherence.xml file, see the documentation in the coherence.dtd file, which is also located inside coherence.jar.
The second step is to attach the filter to one or more specific services, or to make the filter global (for all services). To specify the filter for a specific service, for example the ReplicatedCache service, add a <filter-name> element to the <use-filters> element of the service declaration in the tangosol-coherence.xml file:
<service>
<service-type>ReplicatedCache</service-type>
<service-component>ReplicatedCache</service-component>
<use-filters>
<filter-name>gzip</filter-name>
</use-filters>
<init-params>
...
</init-params>
</service>
To add the filter to all services, do the same under the <outgoing-message-handler> XML element instead of under a <service> XML element:
<outgoing-message-handler>
<use-daemon>false</use-daemon>
<use-filters>
<filter-name>gzip</filter-name>
</use-filters>
</outgoing-message-handler>
|
Filters should be used in an all-or-nothing manner: If one cluster member is using a filter and other is not, the messaging protocol will fail. You should stop the entire cluster before configuring filters. |
Creating a Custom Filter
To create a new filter, create a Java class that implements the com.tangosol.io.WrapperStreamFactory interface and optionally implements the com.tangosol.run.xml.XmlConfigurable interface. The WrapperStreamFactory interface provides the stream to be wrapped ("filtered") on input (received message) or output (sending message) and expects a stream back that wraps the original stream. These methods are called for each incoming and outgoing message.
If the filter class implements the XmlConfigurable interface, then Coherence will configure the filter after instantiating it. For example, consider the following filter declaration in the tangosol-coherence.xml file:
<filter>
<filter-name>my-gzip-filter</filter-name>
<filter-class>com.tangosol.net.CompressionFilter</filter-class>
<init-params>
<init-param>
<param-name>strategy</param-name>
<param-value>gzip</param-value>
</init-param>
<init-param>
<param-name>buffer-length</param-name>
<param-value>1024</param-value>
</init-param>
</init-params>
</filter>
If the filter is associated with a service type, every time a new service is started of that type, Coherence will instantiate the CompressionFilter class and will hold it with the service until the service stops. If the filter is associated with all outgoing messages, Coherence will instantiate the filter on startup and will hold it until the cluster stops. After instantiating the filter, Coherence will call the setConfig method (if the filter implements XmlConfigurable) with the following XML element:
<config>
<strategy>gzip</strategy>
<buffer-length>1024</buffer-length>
</config>
Priority Tasks
Coherence Priority Tasks provide applications that have critical response time requirements better control of the execution of processes within Coherence. Execution and request timeouts can be configured to limit wait time for long running threads. In addition, a custom task API allows applications to control queue processing. Note that these features should be used with extreme caution because they can dramatically effect performance and throughput of the data grid.
Priority Tasks - Timeouts
Overview
Care should be taken when configuring Coherence Task Execution timeouts, especially for Coherence applications that pre-date this feature and thus do not handle timeout exceptions. If a write-through in a CacheStore is blocked (for instance, if a database query is hung) and exceeds the configured timeout value, the Coherence Task Manager will attempt to interrupt the execution of the thread and an exception will be thrown. In a similar fashion, queries or aggregations that exceed configured timeouts will be interrupted and an exception will be thrown. Applications that use this feature should make sure that they handle these exceptions correctly to ensure system integrity. Since this configuration is done at a service by service basis, changing these settings on existing caches/services not designed with this feature in mind should be done with great care.
Configuration
When configuring Execution Timeouts three values need to be considered request-timeout, task-timeout, and the task-hung-threshold (see reference). The request-timeout is the amount of time the client will wait a request to return. The task-timeout is the amount of time that the server will allow the thread to execute before interrupting execution. The task-hung-threshold is the amount of time that a thread can execute before the server reports the thread as "hung." "Hung" threads are for reporting purposes only. These timeout settings are in milliseconds and are configured in the coherence-cache-config.xml or by using command line parameters. See the reference and examples below.
Reference
| setting |
Description |
| <task-hung-threshold> |
Specifies the amount of time in milliseconds that a task can execute before it is considered "hung". Note: A posted task that has not yet started is never considered as hung. This attribute is applied only if the Thread pool is used (the "thread-count" value is positive). |
| <task-timeout> |
Specifies the default timeout value for tasks that can be timed-out (e.g. implement the PriorityTask interface), but don't explicitly specify the task execution timeout value. The task execution time is measured on the server side and does not include the time spent waiting in a service backlog queue before being started. This attribute is applied only if the thread pool is used (the "thread-count" value is positive) |
| <request-timeout> |
Specifies the default timeout value for requests that can time-out (e.g. implement the PriorityTask interface), but don't explicitly specify the request timeout value. The request time is measured on the client side as the time elapsed from the moment a request is sent for execution to the corresponding server node(s) and includes the following:
(1) the time it takes to deliver the request to an executing node (server).
(2) the interval between the time the task is received and placed into a service queue until the execution starts.
(3) the task execution time.
(4) the time it takes to deliver a result back to the client.
|
Examples
To set the distributed cache thread count to 7 with a task time out of 5000 milliseconds and a task hung threshold of 10000 milliseconds, the following would need to be added to the coherence-cache-config.xml for the node.
Setting the client request timeout to 15 milliseconds
Note: The request-timeout should always be longer than the thread-hung-threshold or the task-timeout.
Command Line options
The command line options are for setting the service type (distributed cache, invocation, proxy, etc) default for the node.
| Option |
Desicription |
| tangosol.coherence.replicated.request.timeout |
The default client request timeout for the Replicated cache service |
| tangosol.coherence.optimistic.request.timeout |
The default client request timeout for the Optimistic cache service |
| tangosol.coherence.distributed.request.timeout |
The default client request timeout for distributed cache services |
| tangosol.coherence.distributed.task.timeout |
The default server execution timeout for distributed cache services |
| tangosol.coherence.distributed.task.hung |
the default time before a thread is reported as hung by distributed cache services |
| tangosol.coherence.invocation.request.timeout |
The default client request timeout for invocation services |
| tangosol.coherence.invocation.task.timeout |
The default server execution timeout invocation services |
| tangosol.coherence.invocation.task.hung |
the default time before a thread is reported as hung by invocation services |
| tangosol.coherence.proxy.request.timeout |
The default client request timeout for proxy services |
| tangosol.coherence.proxy.task.timeout |
The default server execution timeout proxy services |
| tangosol.coherence.proxy.task.hung |
the default time before a thread is reported as hung by proxy services |
Priority Task Execution - Custom Objects
Overview
The PriorityTask interface allows to control the ordering in which a service schedules tasks for execution using a thread pool and hold their execution time to a specifed limit. Instances of PriorityTask typically also implement either Invocable or Runnable interface. Priority Task Execution is only relevant when a task back logs exists.
Execution Type
SCHEDULE_STANDARD - a task will be scheduled for execution in a natural (based on the request arrival time) order;
SCHEDULE_FIRST - a task will be scheduled in front of any equal or lower scheduling priority tasks and executed as soon as any of worker threads become available;
SCHEDULE_IMMEDIATE - a task will be immediately executed by any idle worker thread; if all of them are active, a new thread will be created to execute this task.
Developing
Coherence provides 4 classes to aid developers in creating priority task objects
PriorityProcessor can be extended to create a custom entry processor.
PriorityFilter can be extended to create a custom priority filter.
PriorityAggregator can be extended to create a custom aggregation.
PriorityTask can be extended to create an priority invocation class.
After extending each of these classes the developer will need to implement several methods. The return values for getRequestTimeoutMillis, getExecutionTimeoutMillis and getSchedulingPriority should be stored at a class by class basis in your application configuration parameters.
| Method |
Description |
| public long getRequestTimeoutMillis() |
Obtain the maximum amount of time a calling thread is willing to wait for a result of the request execution. The request time is measured on the client side as the time elapsed from the moment a request is sent for execution to the corresponding server node(s) and includes: the time it takes to deliver the request to the executing node(s);the interval between the time the task is received and placed into a service queue until the execution starts; the task execution time; the time it takes to deliver a result back to the client. The value of TIMEOUT_DEFAULT indicates a default timeout value configured for the corresponding service; the value of TIMEOUT_NONE indicates that the client thread is willing to wait indefinitely until the task execution completes or is canceled by the service due to a task execution timeout specified by the getExecutionTimeoutMillis() value. |
| public long getExecutionTimeoutMillis() |
Obtain the maximum amount of time this task is allowed to run before the corresponding service will attempt to stop it. The value of TIMEOUT_DEFAULT indicates a default timeout value configured for the corresponding service; the value of TIMEOUT_NONE indicates that this task can execute indefinitely. If, by the time the specified amount of time passed, the task has not finished, the service will attempt to stop the execution by using the Thread.interrupt() method. In the case that interrupting the thread does not result in the task's termination, the runCanceled method will be called. |
| public int getSchedulingPriority() |
Obtain this task's scheduling priority. Valid values are SCHEDULE_STANDARD, SCHEDULE_FIRST, SCHEDULE_IMMEDIATE |
| public void runCanceled(boolean fAbandoned) |
This method will be called if and only if all attempts to interrupt this task were unsuccessful in stopping the execution or if the execution was canceled before it had a chance to run at all. Since this method is usually called on a service thread, implementors must exercise extreme caution since any delay introduced by the implementation will cause a delay of the corresponding service. |
Errors
When a task timeout occurs the node will get a RequestTimeoutException. e.g:
com.tangosol.net.RequestTimeoutException: Request timed out after 4015 millis
at com.tangosol.coherence.component.util.daemon.queueProcessor.Service.checkRequestTimeout(Service.CDB:8)
at com.tangosol.coherence.component.util.daemon.queueProcessor.Service.poll(Service.CDB:52)
at com.tangosol.coherence.component.util.daemon.queueProcessor.Service.poll(Service.CDB:18)
at com.tangosol.coherence.component.util.daemon.queueProcessor.service.InvocationService.query(InvocationService.CDB:17)
at com.tangosol.coherence.component.util.safeService.SafeInvocationService.query(SafeInvocationService.CDB:1)
Testing
Evaluating Performance and Scalability
Setting Expectations
Often times the Coherence distributed caches will be evaluated with respect to pre-existing local caches. The local caches generally take the form of in-processes hash maps. While Coherence does include facilities for in-process non-clustered caches, direct performance comparison between local caches and a distributed cache not realistic. By the very nature of being out of process the distributed cache must perform serialization and network transfers. For this cost you gain cluster wide coherency of the cache data, as well as data and query scalability beyond what a single JVM or machine is capable of providing. This does not mean that you cannot achieve impressive performance using a distributed cache, but it must be evaluated in the correct context.
Measuring Latency and Throughput
When evaluating performance you try to establish two things, latency, and throughput. A simple performance analysis test may simply try performing a series of timed cache accesses in a tight loop. While these tests may accurately measure latency, in order to measure maximum throughput on a distributed cache a test must make use of multiple threads concurrently accessing the cache, and potentially multiple test clients. In a single threaded test the client thread will naturally spend the majority of the time simply waiting on the network. By running multiple clients/threads, you can more efficiently make use of your available processing power by issuing a number of requests in parallel. The use of batching operations can also be used to increase the data density of each operation. As you add threads you should see that the throughput continues to increase until you've maxed out the CPU or network, while the overall latency remains constant for the same period.
Demonstrating Scalability
To show true linear scalability as you increase cluster size, you need to be prepared to be add hardware, and not simply JVMs to the cluster. Adding JVMs to a single machine will scale only up to the point where the CPU or network are fully utilized.
Plan on testing with clusters with more then just two cache servers (storage enabled nodes). The jump from one to two cache servers will not show the same scalability as from two to four. The reason for this is because by default Coherence will maintain one backup copy of each piece of data written into the cache. The process of maintaining backups only begins once there are two storage enabled nodes in the cluster (there must have a place to put the backup). Thus when you move from a one to two, the amount of work involved in a mutating operation such as cache.put actually doubles, but beyond that the amount of work stays fixed, and will be evenly distributed across the nodes.
Tuning your environment
To get the most out of your cluster it is important that you've tuned of your environment and JVMs. Please take a look at our performance tuning guide, it is a good start to getting this most out of your environment. For instance Coherence includes a registry script for Windows (optimize.reg), which will adjust a few critical settings and allow Windows to achieve much higher data rates.
Measurements on a large cluster
The following graphs show the results of scaling out a cluster in an environment of 100 machines. In this particular environment Coherence was able to scale to the limits of the networks switching infrastructure. Namely there were 8 sets of ~12 machines, each set having a 4Gbs link to a central switch. Thus for this test Coherence's network throughput scales up to ~32 machines at which point it has maxed out the available bandwidth, beyond that it continues to scale in total data capacity.
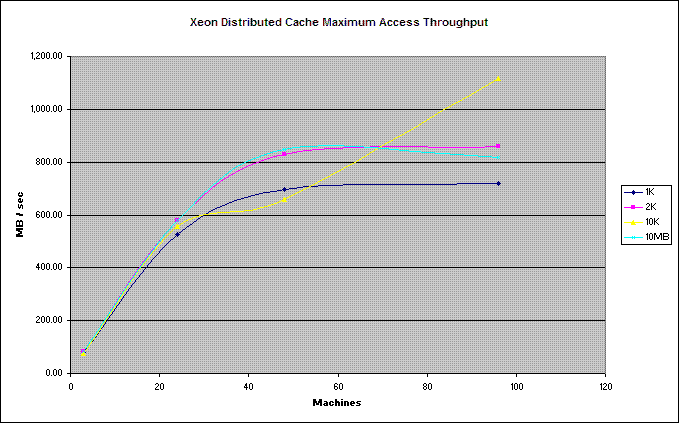
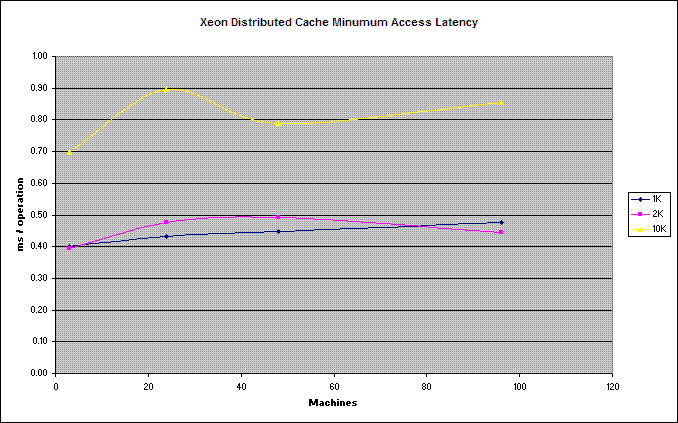
Latency for 10MB operations (~300ms) is not included in the graph for display reasons, as the payload is 1000x the next payload size. See the attached spreadsheet for raw data and additional graphs.
Test for yourself
The attached zip file includes the Coherence based test tool used in the above tests. See the included readme.txt for details on test execution.
Scaling Out Your Data Grid Aggregations Linearly
| All of the Data Grid capabilities described below are features of Coherence Enterprise Edition and higher.
|
Overview
Coherence provides a data grid by dynamically, transparently and automatically partitioning the data set across all storage enabled nodes in a cluster. We have been doing some scale out testing on our new Dual 2.3GHz PowerPC G5 Xserve cluster and here is one of the tests that we have performed using the Data Grid Aggregation feature.
The new InvocableMap tightly binds the concepts of a data grid (i.e. partitioned cache) and the processing of the data stored in the grid. When you take the InvocableMap and combine it with the linear scalability of Coherence itself you get an extremely powerful solution. The following tests show that you can take an application that Coherence provides you (the developer, the engineer, the architect, etc.) the ability to build an application once that can scale out to handle any SLA requirement, any increase in throughput requirements. For example, the following test demonstrate Coherence's ability to linearly increase the number of trades aggregated per second as you increase hardware. I.e. if one machine can aggregate X trades per second, if you add a second machine to the data grid you will be able to aggregate 2X trades per second, if you add a third machine to the data grid you will be able to aggregate 3X trades per second and so on...
The data
First, we need some data to aggregate. In this case we used a Trade object with a three properties Id, Price and Symbol.
package com.tangosol.examples.coherence.data;
import com.tangosol.util.Base;
import com.tangosol.util.ExternalizableHelper;
import com.tangosol.io.ExternalizableLite;
import java.io.IOException;
import java.io.NotActiveException;
import java.io.DataInput;
import java.io.DataOutput;
/**
* Example Trade class
*
* @author erm 2005.12.27
*/
public class Trade
extends Base
implements ExternalizableLite
{
/**
* Default Constructor
*/
public Trade()
{
}
public Trade(int iId, double dPrice, String sSymbol)
{
setId(iId);
setPrice(dPrice);
setSymbol(sSymbol);
}
public int getId()
{
return m_iId;
}
public void setId(int iId)
{
m_iId = iId;
}
public double getPrice()
{
return m_dPrice;
}
public void setPrice(double dPrice)
{
m_dPrice = dPrice;
}
public String getSymbol()
{
return m_sSymbol;
}
public void setSymbol(String sSymbol)
{
m_sSymbol = sSymbol;
}
/**
* Restore the contents of this object by loading the object's state from the
* passed DataInput object.
*
* @param in the DataInput stream to read data from in order to restore the
* state of this object
*
* @throws IOException if an I/O exception occurs
* @throws NotActiveException if the object is not in its initial state, and
* therefore cannot be deserialized into
*/
public void readExternal(DataInput in)
throws IOException
{
m_iId = ExternalizableHelper.readInt(in);
m_dPrice = in.readDouble();
m_sSymbol = ExternalizableHelper.readSafeUTF(in);
}
/**
* Save the contents of this object by storing the object's state into the
* passed DataOutput object.
*
* @param out the DataOutput stream to write the state of this object to
*
* @throws IOException if an I/O exception occurs
*/
public void writeExternal(DataOutput out)
throws IOException
{
ExternalizableHelper.writeInt(out, m_iId);
out.writeDouble(m_dPrice);
ExternalizableHelper.writeSafeUTF(out, m_sSymbol);
}
private int m_iId;
private double m_dPrice;
private String m_sSymbol;
}
Configure a partitioned cache
The cache configuration is easy through the XML Cache Configuration Elements. Here I define one wildcard cache-mapping that maps to one caching-scheme which has unlimited capacity:
<?xml version="1.0"?>
<!DOCTYPE cache-config SYSTEM "cache-config.dtd">
<cache-config>
<caching-scheme-mapping>
<cache-mapping>
<cache-name>*</cache-name>
<scheme-name>example-distributed</scheme-name>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<!--
Distributed caching scheme.
-->
<distributed-scheme>
<scheme-name>example-distributed</scheme-name>
<service-name>DistributedCache</service-name>
<backing-map-scheme>
<class-scheme>
<scheme-ref>unlimited-backing-map</scheme-ref>
</class-scheme>
</backing-map-scheme>
<autostart>true</autostart>
</distributed-scheme>
<!--
Backing map scheme definition used by all the caches that do
not require any eviction policies
-->
<class-scheme>
<scheme-name>unlimited-backing-map</scheme-name>
<class-name>com.tangosol.util.SafeHashMap</class-name>
<init-params></init-params>
</class-scheme>
</caching-schemes>
</cache-config>
Add an index to the Price property
ReflectionExtractor extPrice = new ReflectionExtractor("getPrice");
m_cache.addIndex(extPrice, true, null);
Adding an index to this property increases performance by allowing Coherence to access the values directly rather than having to deserialize each item to accomplish the calculation. In our tests the aggregation speed was increased by more than 2x after an index was applied.
The code to perform a parallel aggregation across all JVMs in the data grid
Double DResult;
DResult = (Double) m_cache.aggregate((Filter) null, new DoubleSum("getPrice"));
| The aggregation is initiated and results received by a single client. I.e. a single "low-power" client is able to utilize the full processing power of the cluster/data grid in aggregate to perform this aggregation in parallel with just one line of code. |
The testing environment/process
A "test run" does a number of things:
- Loads 200,000 trade objects into the data grid.
- Adds indexes to Price property.
- Performs a parallel aggregation of all trade objects stored in the data grid. This aggregation step is done 20 times to obtain an "average run time" to ensure that the test takes into account garbage collection.
- Loads 400,000 trade objects into the data grid.
- Repeats steps 2 and 3.
- Loads 600,000 trade objects into the data grid.
- Repeats steps 2 and 3.
- Loads 800,000 trade objects into the data grid.
- Repeats steps 2 and 3.
- Loads 1,000,000 trade objects into the data grid.
- Repeats steps 2 and 3.
| Client
The test client itself is run on an Intel Core Duo iMac which is marked as Local Storage disabled.
The command line used to start the client was:
java ... -Dtangosol.coherence.distributed.localstorage=false -Xmx128m -Xms128m com.tangosol.examples.coherence.invocable.TradeTest |
This "test suite" (and subsequent results) includes data from four "test runs":
- Start 4 JVMs on one Xserve - Perform a "test run"
- Start 4 JVMs on each of two Xserves - Perform a "test run"
- Start 4 JVMs on each of three Xserves - Perform a "test run"
- Start 4 JVMs on each of four Xserves - Perform a "test run"
| Server
In this case a "JVM" refers to a cache server instance (i.e. a data grid node) that is a standalone JVM responsible for managing/storing the data. I used the DefaultCacheServer helper class to accomplish this.
The command line used to start the server was:
java ... -Xmx384m -Xms384m -server com.tangosol.net.DefaultCacheServer |
JDK Version
The JDK used on both the client and the servers was Java(TM) 2 Runtime Environment, Standard Edition (build 1.5.0_05-84)
The results
| The lowest and highest times were not used in the calculations below resulting in a data set of eighteen results used to create an average. |
As you can see in the following graph the average aggregation time for the aggregations decreases linearly as more cache servers/machines are added to the data grid!
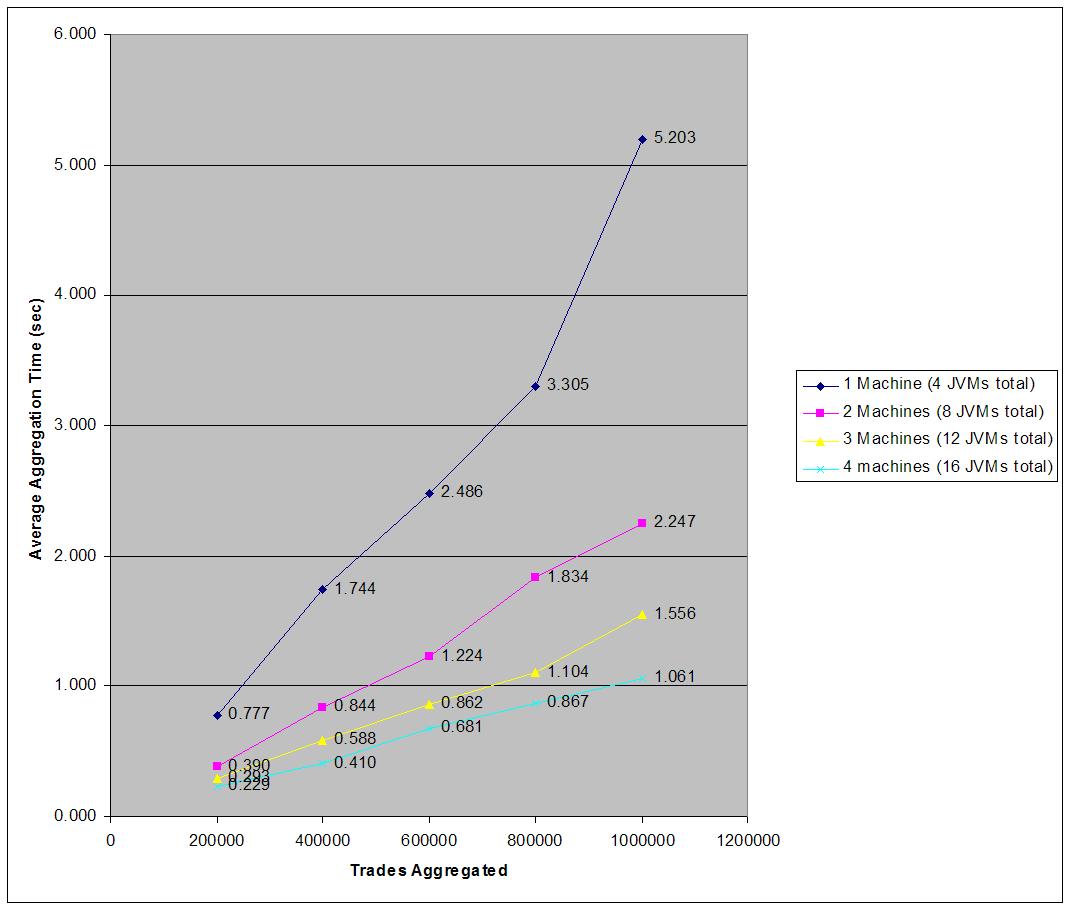
Similarly, the following graph illustrates how the aggregations per second scales linearly as you add more machines! When moving from 1 machine to 2 machines the trades aggregated per second double, when moving from 2 machines to 4 machines the trades aggregated per second double again.
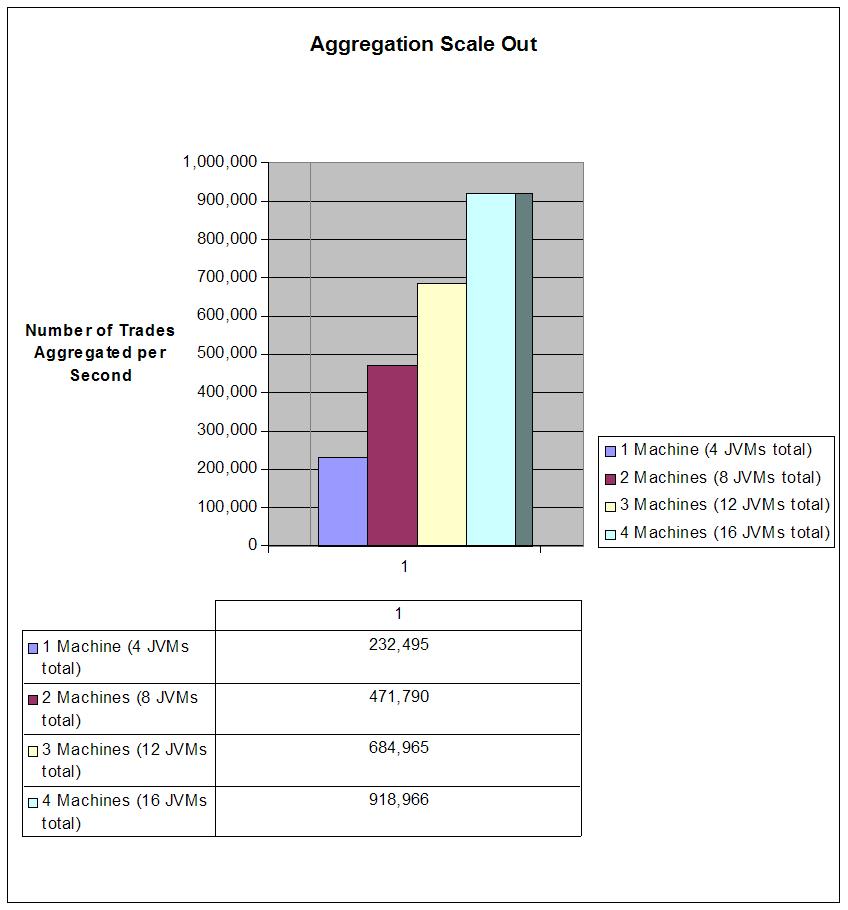
| FAILOVER!
The above aggregations will complete successfully and correctly even if one of the cache servers or and entire machine fails during the aggregation! |
Conclusion
Combining the Coherence data grid (i.e. partitioned cache) with the InvocableMap features enables:
- Applications to scale out data grid calculations linearly;
- Groups to meet increasingly aggresive SLAs by dynamically/trasparently adding more resources to the data grid. I.e. if you need to achieve 1,837,932 trade aggregations per second all that is required is to start 16 more cache servers across four more machines;
Release Notes
Coherence 3.3 Release Notes
Oracle CoherenceTM 3.3 Release Notes
The following is a list of new features and improvements in Oracle Coherence 3.3:
- Cluster Protocol Enhancements:
- Reduced overall thread contention on multi-core machines. (COH-1024, COH-1042, b383)
- Improved network utilization efficiency for small logical messages by implementing a packet bundling algorithm. (COH-847, b381)
- Improved the flow control algorithm for networks with bandwidth below 1Gb. (COH-909, b381)
- Improved cluster segmentation resolution protocol for cluster nodes recovering from abnormally long GC pauses. (COH-975, b381)
- Deterministic Request Execution:
- Coherence 3.3 introduces the ability to control the ordering in which a clustered service schedules tasks for execution using its thread pool, limit their execution times to a specified duration and monitor related statistic. See the com.tangosol.net.PriorityTask interface, the documentation for the "task-timeout" and "request-timeout" cache configuration elements for the partitioned cache and invocation services and the following attributes of the ServiceMBean: TaskHungCount, TaskHungDuration, TaskHungTaskId, TaskHungThresholdMillis, TaskTimeoutCount, ThreadAbandonedCount. (COH-275, COH-443, COH-889, b381)
- Coherence*Web Enhancements:
- Added support for Jetty 6 and Oracle OC4J 10.1.3 web containers. (COH-793, COH-1034, b381)
- Coherence*Extend Enhancements and Fixes:
- Fixed an assertion error in the TCP/IP acceptor caused by incorrect buffer boundary calculation. See http://forums.tangosol.com/thread.jspa?messageID=7292. (COH-1063, b383)
- Added lite event support for replicated and local caches accessed via Coherence*Extend. (COH-1014, b381)
- Fixed a potential deadlock caused by a client disconnect during heavy concurrent cache updates. (COH-993, b381)
- Various POF-serialization improvements and fixes related to collections support. (COH-1007, COH-1011, COH-1015, COH-1018, b381)
- Renamed example-pof-config.xml to coherence-pof-config.xml. (COH-980, b381)
- J2CA Resource Adapter and TransactionMap Enhancements:
- Added a new External Concurrency Mode. See the com.tangosol.util.TransactionMap interface. (COH-482, b383)
- Fixed the ra.xml descriptor to conform with the J2CA 1.0 specification. (COH-1047, b383)
- Configuration and Management Enhancements and fixes:
- Fixed a bug that prevented an automatic restart of the management service upon cache server restart. (COH-1027, b383)
- Improved handling of empty strings in the cache configuration descriptor, See http://forums.tangosol.com/thread.jspa?threadID=1039. (COH-721, b383)
- Added a default process name calculation using PID for nodes running on JRE 1.5 or higher. (COH-1025, b383)
- Other Enhancements and Fixes:
- Certified Coherence on JRE 1.6. (COH-923, b383)
- Added the ability to bundle multiple concurrent requests into a single "bulk" operation. This functionality is currently configurable within the cachestore-scheme and remote-cache-scheme configuration elements. (COH-985, b383)
- Fixed a potential deadlock between service worker and event dispatcher threads during a massive event delivery burst. (COH-671, COH-1067, b383)
- Fixed an issue with the NearCache "present" invalidation strategy causing missed listener registration calls during heavy front map eviction. (COH-950, COH-1045, b383)
- Fixed a ClassCastException for LimitFilter-based queries with a custom Comparator. See http://forums.tangosol.com/thread.jspa?messageID=7330. (COH-1075, b383)
- Fixed a potential deadlock in the WorkManager startup sequence. (COH-1070, b383)
- Enabled the system property override for the Hibernate cache provider cache configuration descriptor location. (COH-1052, b383)
- Added support for methods with parameters to the ReflectionExtractor. (COH-802, b381)
- Under Sun JRE 1.5, dynamically creating a large number of threads (e.g. heavy processing of RMI requests) could cause locks to be acquired erroneously. (COH-992, b381)
- Improved the implementation of write-behind persistence to more efficiently batch updates. (COH-972, b381)
- Fixed missing synchronization in InvokeAll request processing that caused an erratic assertion exception. (COH-976, b381)
- Fixed an issue in InvokeAll request processing by pooled threads causing a failure to return the results of execution. (COH-978, b381)
- Eliminated a rare race condition during partitioned cache "clear" operations that caused an assertion exception. (COH-1016, b381)
- Configuring a backing map with a "high-units" setting smaller than the number of pooled threads could cause an NPE during eviction. (COH-926, b381)
- Fixed a performance degradation for OverflowMap configured with a high capacity front map. (COH-1006, b381)
- Hardened out-of-memory failure handling during BinaryMap "grow" and "shrink" operations. (COH-922, b381)
Feature Listing
Coherence Features by Edition
Coherence Server Editions
|
|
Standard Edition
(Formerly known as Caching Edition) |
Enterprise Edition
(Formerly known as Application Edition) |
Grid Edition
(Formerly known as Data Grid Edition) |
|
|
Application caching solution |
Application data management |
Enterprise-wide data management |
|
|
* Fault-tolerant data caching
|
* Fault-tolerant data caching
* Data management including
write-behind, transactions,
analytics and events
|
* Fault-tolerant data caching
* Data management including
write-behind, transactions,
analytics and events
* Support for heterogeneous
clients |
| Connectivity |
Embedded Data Client and Real Time Client functionality 1 |
●
|
●
|
●
|
| |
TCMP cluster technology 3, 8 |
●
|
●
|
●
|
| |
Support for cross-platform Data Clients |
●
|
●
|
●
|
| |
Multicast-free operation (WKA) |
|
●
|
●
|
| Security |
Network traffic encryption |
●
|
●
|
●
|
| |
Java Authentication & Authorization Service (JAAS) |
●
|
●
|
●
|
| Management & Monitoring |
Management host 3 |
●
|
●
|
●
|
| |
Manageable via clustered JMX |
|
●
|
●
|
| Caching |
Local cache, Near cache, continuous query cache, real-time events |
●
|
●
|
●
|
| |
Fully replicated data management |
●
|
●
|
●
|
| |
Partitioned data management |
●
|
●
|
●
|
| |
Data source integration via read-through/write-through caching |
●
|
●
|
●
|
| Integration |
Hibernate integration |
●
|
●
|
●
|
| |
HTTP session management for application servers 4 |
|
●
|
●
|
| |
BEA Portal "p13n cache" integration |
|
●
|
●
|
| Analytics |
Parallel InvocableMap and QueryMap 5 |
|
●
|
●
|
| Transactions |
Write-behind caching |
|
●
|
●
|
| |
J2CA Resource Adapter |
|
●
|
●
|
| Compute Grid |
InvocationService |
|
●
|
●
|
| |
WorkManager |
|
●
|
●
|
| Enterprise Data Grid |
WAN support 6 |
|
|
●
|
| |
Support for cross-platform Real Time Clients |
|
|
●
|
Coherence Client Editions
|
|
Data Client |
Real Time Client |
|
|
Data Grid client for use anywhere |
Real time desktop client |
| |
|
* Access to data and services
on the data grid
|
* Access to data and services
on the data grid
* Real time synchronization with
the data grid |
| Client API |
Data transformation (PIFPOF / ExternalizableLite / XmlBean) |
●
|
●
|
| |
InvocationService |
|
|
| |
NamedCache (core) |
●
|
●
|
| |
NamedCache (with ObservableMap real time events) |
|
●
|
| Connectivity |
Coherence*Extend client 9 |
●
|
●
|
| |
Multicast-free operation |
|
|
| Security |
Network traffic encryption |
●
|
●
|
| Caching |
Local cache |
|
●
|
| |
Near cache |
|
●
|
| |
Continuous query cache |
|
●
|
1 Coherence TCMP clusters must be homogeneous with respect to the Coherence Edition. A TCMP cluster of one type (e.g. Caching Edition) may connect to a TCMP cluster of another type (e.g. Grid Edition) as a Data Client or as a Real Time Client, but this requires server-side licenses. The connection type is configurable and defaults to Real Time Client.
2 Supports integration with a local MBeanServer. This, in conjunction with local JMX "agents", allows this node to provide management and monitoring features. Clustered JMX support adds the ability for this node to manage and monitor remote nodes as well.
3 Coherence Editions may not be mixed within the context of a single TCMP-based cluster. Integration of different Edition types is accomplished via Coherence*Extend (with each cluster acting as either a Data Client or a Real Time Client).
4 Caching Edition does not support InvocationService, which is required for an additional "sticky" load balancer optimization.
5 Parallel support for InvocableMap and QueryMap will result in server-side execution whenever possible, minimizing data transfer, allowing use of indexing, and parallelizing execution across the cluster. Without parallel support, the operations will retrieve the full dataset to the client for evaluation (which may be very inefficient).
6 Data Grid Edition is required for WAN deployments.
7 InvocationService requests from Data Client and Real Time Client are client-only, and there are limitations in Coherence 3.2.
8 Oracle's cluster-aware wire protocol (TCMP) provides detailed knowledge of the entire cluster that enables direct server access for lower latency and higher throughput, faster failover/failback/rebalancing, and the ability for any participating member to act as a service provider (e.g. data management, remote invocation, management and monitoring, etc.).
9 Coherence*Extend is used to extend the core TCMP cluster to a greater ranging network, including desktops, other servers and WAN links. The Coherence*Extend protocol may be transported over TCP/IP (optimal performance) or over a pre-existing JMS provider (for compatibility with existing infrastructure).