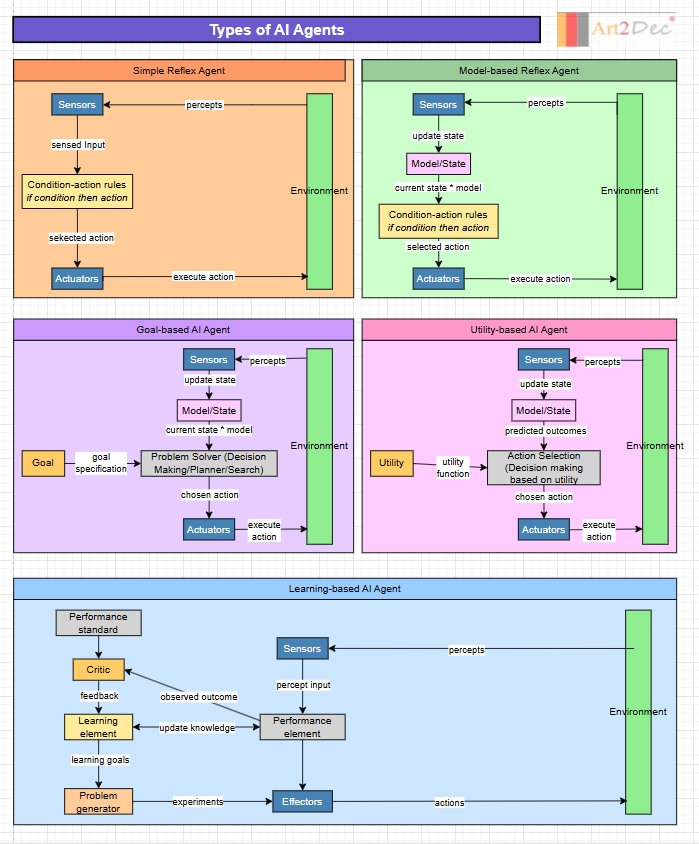
AI agents don’t all think and act in the same way. They range from simple rule-followers to systems that learn and adapt. Each type marks a step forward in how machines perceive, decide, and act.
Simple Reflex Agents: These follow condition–action rules. For example, if the temperature is high, turn on the fan. No memory, no thinking, just instant reaction. They are fast and simple.
Model-based Reflex Agents: These maintain an internal understanding of their environment. They are not just reacting to immediate inputs, they have a model that helps them make sense of what is happening beyond what they can see right now.
Goal-based Agents: Here, the focus shifts to goals. Decisions are made based on whether an action brings the agent closer to its objective.
Utility-based Agents: These go a step further by weighing different outcomes. They choose the action that offers the best overall result, balancing trade-offs along the way.
Learning Agents: These are the most advanced. They improve continuously, using feedback to adapt and perform better over time.
Traditional software follows a predetermined path. However, AI agents can navigate uncertain situations and figure out what needs to be done. AI Agents can perceive, decide, and adapt to achieve goals. This represents a significant leap from static programs to dynamic collaborations. At its core, an AI agent works in a continuous cycle during which it perceives the current situation, thinks about what to do next, acts by taking a specific step, observes the results of the action, and then repeats the process. This cycle continues until the agent determines it has completed the task or needs human input to proceed further.
Multiple types of AI Agents exist, each supporting different capabilities:
1 – Simple Reflect Agents react to patterns, like thermostats or basic chatbots. 2 – Model-Based Agents build internal maps of their environment, enabling context-aware behavior. 3 – Goal-Based Agents can plan ahead and choose actions that serve specific objectives. 4 – Utility-Based Agents weigh trade-offs to find the best possible outcome. 5 – Learning Agents improve continuously by learning from feedback and experience.
AI agents are ushering in an era where software systems can become active collaborators.
A detailed glossary of essential terminology for understanding large language models and their applications.
Glossary of Key Terms
Foundation Model: A large language model (LLM) pre-trained on a massive dataset, capable of understanding and generating human-like text across a wide range of tasks.
Fine-Tuning: The process of taking a pre-trained LLM and further training it on a smaller, task-specific dataset to adapt its weights and improve its performance on that particular task or domain.
RAG (Retrieval-Augmented Generation): A framework that enhances LLM responses by retrieving relevant information from an external Knowledge Base and incorporating it into the generation process.
Knowledge Base (KB): A collection of documents or data from which relevant information is retrieved in a RAG system.
Vector Database: A specialized database that stores vector representations (embeddings) of data, optimized for efficient similarity searches used in RAG for retrieving relevant information.
Prompting: The act of providing carefully crafted input text to an LLM to guide its output generation and elicit desired responses.
Zero-Shot Learning: The ability of an LLM to perform a task based solely on the task instructions, without any prior examples.
Few-Shot Learning: The ability of an LLM to learn and perform a task given only a very small number of examples in the prompt.
Instruction Tuning: A fine-tuning technique where the training data includes specific instructions paired with desired outputs, improving the LLM’s ability to follow instructions effectively.
Hallucination: The tendency of LLMs to generate incorrect, nonsensical, or factually inconsistent information that is not supported by the input context or their training data.
Context Length: The maximum number of input tokens or words that an LLM can process and consider when generating an output.
Transformer: A popular neural network architecture widely used in LLMs, known for its attention mechanism that allows it to weigh the importance of different parts of the input sequence and its parallel processing capabilities.
In-Context Learning: The ability of an LLM to learn a new task by being provided with examples directly within the prompt, without requiring explicit fine-tuning.
Quantization: A technique used to reduce the computational resources and memory footprint of an LLM by decreasing the precision of its parameters.
Freeze Tuning: A fine-tuning method where most of the LLM’s parameters are kept frozen, and only a small subset of layers or parameters are updated during training.
Contrastive Learning: A fine-tuning approach that trains LLMs to understand the similarity and differences between data points, often used for improving the quality of embeddings.
RLHF (Reinforcement Learning from Human Feedback): A technique used to align LLM behavior with human preferences by using human feedback as a reward signal to train the model.
Reward Modeling: A component of RLHF where a separate model is trained to predict human preference scores for different LLM outputs, serving as the reward signal for reinforcement learning.
Pruning: A technique used to reduce the size and computational cost of LLMs by removing redundant or less important connections or parameters.
LoRA (Low-Rank Adaption): A Parameter-Efficient Fine-Tuning (PEFT) method that inserts a smaller set of new weight matrices into the LLM and trains only these new parameters, significantly reducing the number of trainable parameters.
SFT (Supervised Fine-Tuning): The process of updating a pre-trained LLM with labeled data (input-output pairs) to make it perform a specific task.
Transfer Learning: A machine learning technique where knowledge gained from training on a large dataset is applied to improve the performance on a smaller, related task.
PEFT (Parameter-Efficient Fine-Tuning): Techniques that update only a small fraction of an LLM’s parameters during fine-tuning, making the process more computationally efficient and cost-effective.
Agent Planning: A module in LLM applications that breaks down complex tasks into smaller, manageable steps to fulfill user requests.
LLM Agent: An application that combines the capabilities of an LLM with other modules like planning, memory, and tool use to execute complex tasks.
Agent Memory: A module that allows an LLM agent to store and recall past interactions and experiences, enabling more coherent and context-aware behavior.
Function Calling: The ability of LLM agents to interact with external tools and APIs to gather information or perform actions required to complete a task.
Vector Search: The process of finding the most relevant vector representations in a vector database based on similarity to a query vector.
Indexing: The process of organizing and structuring data in a Knowledge Base (KB) to enable efficient retrieval. In the context of RAG, it often involves converting KB chunks into vector embeddings and storing them in a vector database.
Embedding Model: An LLM or a specialized model that converts text or other data into numerical vector representations (embeddings).
AGIRetrieval: An approach used to rank and fetch Knowledge Base (KB) chunks from the vector search results, which will then be used as additional context for the LLM in RAG.
Chunking: The process of dividing large documents or the Knowledge Base into smaller, more manageable pieces (chunks) for efficient storage and retrieval in RAG.
Artificial General Intelligence (AGI): The theoretical ability of a machine to perform any intellectual task that a human being can, across a wide range of domains.
LLM Bias: Systematic and unfair prejudices present in an LLM’s predictions, often originating from biases in the training data.
Responsible AI: An overarching framework encompassing principles and practices aimed at ensuring the ethical, fair, and transparent development and deployment of AI systems.
GDPR Compliance: Ensuring that the development and deployment of AI systems adhere to the regulations outlined in the General Data Protection Regulation, which protects individuals’ privacy rights in the European Union.
AI Governance: The set of rules, policies, and frameworks that regulate the development and deployment of AI systems.
XAI (Explainable AI): Techniques and methods used to make the outputs and decision-making processes of AI models understandable and transparent to humans.
LLMOps: A set of practices and tools for managing and optimizing the entire lifecycle of LLM deployment, including development, training, deployment, monitoring, and maintenance.
Alignment: The process of ensuring that the behavior and outputs of an LLM are consistent with human values, intentions, and ethical principles.
Model Ethics: Principles and guidelines that promote ethical behavior (transparency, fairness, accountability, etc.) when deploying AI models, especially those that are publicly facing.
PII (Personally Identifiable Information): Any information that can be used to identify an individual. Handling PII requires careful processes and user consent.
Privacy-preserving AI: Techniques and methods used to train and utilize LLMs while safeguarding the privacy of sensitive data.
Adversarial Defense: Methods and techniques designed to protect LLMs against malicious attempts to manipulate their behavior or exploit vulnerabilities.
Prompt Injection: A type of adversarial attack where carefully crafted inputs are used to trick an LLM into deviating from its intended purpose or revealing sensitive information.
Adversarial Attacks: Deliberate attempts to manipulate LLMs through crafted inputs, causing them to produce incorrect, unexpected, or harmful outputs.
Jailbreaking: A type of adversarial attack that attempts to bypass the safety measures and constraints of an LLM to make it generate unsafe or prohibited content.
Red-Teaming: A security assessment process involving simulated adversarial attacks to identify vulnerabilities and weaknesses in LLM systems.
Prompt Leaking: An adversarial technique that tricks an LLM into revealing parts of its original prompt or internal workings.
Robustness: The ability of an LLM to maintain its performance and accuracy even when encountering noisy, unexpected, or adversarial inputs.
Black-Box Attacks: Adversarial attacks where the attacker has no knowledge of the LLM’s internal architecture or parameters and can only interact with it through its input and output.
White-Box Attacks: Adversarial attacks where the attacker has full knowledge of the LLM’s internal architecture, parameters, and training data.
Vulnerability: A weakness or flaw in an LLM system that can be exploited for malicious purposes, such as adversarial attacks or data breaches.
Deep-fakes: Synthetic media (images, videos, audio) generated by AI models, often used to create realistic but fake content.
Watermarking: Embedding hidden, detectable markers into LLM-generated content to identify its origin and potentially combat the spread of misinformation.
Unsupervised Learning: A machine learning paradigm where models learn patterns and structures from unlabeled data without explicit guidance or correct answers.
Supervised Learning: A machine learning paradigm where models learn from labeled data, associating inputs with their corresponding correct outputs.
Reinforcement Learning: A machine learning paradigm where an agent learns through trial and error by interacting with an environment and receiving rewards or penalties based on its actions.
Federated Learning: A decentralized machine learning approach where models are trained across multiple devices or organizations without sharing the raw data.
Online Learning: A learning paradigm where a model continuously learns from a stream of incoming data, updating its knowledge in real-time.
Continual Learning: A learning paradigm focused on enabling models to learn from a sequence of tasks or data without forgetting previously learned knowledge.
Multi-task Learning: A learning approach where a single model is trained to perform multiple different tasks, often leveraging shared knowledge between related tasks to improve performance.
Adversarial Learning: A learning paradigm that involves training models against adversarial examples or competing models to improve their robustness and ability to generalize.
Active Learning: A learning approach where the model strategically selects the most informative data points for human labeling to improve learning efficiency.
Meta-Learning: Also known as “learning to learn,” this paradigm focuses on training models to acquire general knowledge and learning skills that can be quickly applied to new, unseen tasks with minimal data.
Quiz and Answer Key
Explain the core functionality of a Foundation Model and provide a key characteristic that distinguishes this type of LLM.
A Foundation Model is an LLM designed to generate and understand human-like text across a wide range of use-cases. A key characteristic is its broad pre-training on massive datasets, enabling it to perform diverse tasks with minimal or no task-specific fine-tuning.
Describe the process of Fine-Tuning an LLM. What is the primary goal of this process?
Fine-tuning is the process of adapting a pre-trained LLM to a specific task or domain by further training it on task-specific data. The primary goal is to improve the LLM’s performance and accuracy on the targeted application.
What is Retrieval-Augmented Generation (RAG)? Briefly outline the roles of the Knowledge Base and Vector Database in this process.
Retrieval-Augmented Generation (RAG) is a framework that enhances LLM responses by retrieving relevant information from an external Knowledge Base and appending it to the prompt. The Knowledge Base is a collection of documents, while the Vector Database stores vector representations of this KB to enable efficient similarity-based retrieval.
Differentiate between Zero-Shot Learning and Few-Shot Learning in the context of prompting LLMs for specific tasks.
In Zero-Shot Learning, an LLM is given only task instructions and must rely solely on its pre-existing knowledge to perform the task. In contrast, Few-Shot Learning provides the LLM with a very small number of examples alongside the task instructions to guide its output generation.
Define Instruction Tuning and explain how it aims to improve the behavior of an LLM.
Instruction Tuning involves adjusting an LLM’s behavior during fine-tuning by providing specific instructions along with the training data. This process aims to improve the LLM’s ability to follow instructions and generate more accurate and relevant responses based on those instructions.
What is Hallucination in the context of LLMs? Provide a brief example of what this might look like.
Hallucination in LLMs refers to the tendency of these models to sometimes generate incorrect, nonsensical, or factually inconsistent information that is not grounded in the provided context or their training data. An example could be an LLM generating a fictitious historical event or attributing a quote to the wrong person.
Explain the concept of Context Length and why it is a significant factor in LLM performance.
Context Length is the maximum number of input words or tokens that an LLM can consider when generating an output. It is significant because it limits the amount of information the LLM can process at once, impacting its ability to understand long documents or maintain context over extended conversations.
Describe In-Context Learning and how it differs from traditional fine-tuning methods.
In-Context Learning involves integrating task examples directly into the prompts provided to an LLM, enabling it to understand and handle new tasks without requiring explicit fine-tuning of its weights. This approach leverages the LLM’s pre-existing knowledge and its ability to learn from the provided examples within the prompt itself.
What is Reinforcement Learning from Human Feedback (RLHF)? Briefly explain the role of Reward Modeling in this process.
Reinforcement Learning from Human Feedback (RLHF) is a technique that uses human feedback as a reward or penalty signal to further train an LLM and align its behavior with human preferences. Reward Modeling is a key component where a separate model is trained to predict the human preference score for different LLM outputs, which then serves as the reward signal during reinforcement learning.
Explain the concept of Prompt Injection and why it is considered a security vulnerability for LLMs.
Prompt Injection refers to deliberate attempts to trick LLMs with carefully crafted inputs that manipulate the model’s original instructions and cause it to perform unintended or malicious tasks. This is a vulnerability because it can be exploited to bypass safety measures, extract sensitive information, or generate harmful content.
With the growing number of LLMs like GPT-4o, LLaMA, and Claude, along with many more emerging rapidly, businesses’ key question is how to choose the best one for their needs. This guide will provide a straightforward framework for selecting the most suitable LLM for your business requirements.
Overview
The article introduces a framework to help businesses select the right LLM (Large Language Model) by evaluating cost, accuracy, scalability, and technical compatibility.
When choosing an LLM, it emphasizes that businesses should identify their specific needs—such as customer support, technical problem-solving, or data analysis.
The framework includes detailed comparisons of LLMs based on factors like fine-tuning capabilities, cost structure, latency, and security features tailored to different use cases.
Real-world case studies, such as educational tools and customer support automation, illustrate how different LLMs can be applied effectively.
The conclusion advises businesses to experiment and test LLMs with real-world data, noting there is no “one-size-fits-all” model, but the framework helps make informed decisions.
Why LLMs Matter for Your Business?
Businesses in many different industries are already gaining from Large Language Model capabilities. They can save time and money by producing content, automating customer service, and analyzing data. Also, users don’t need to learn any specialist technological skills; they just need to be proficient in natural language.
But what can LLM do?
LLMs can assist staff members in retrieving data from a database without coding or domain expertise. Thus, LLMs successfully close the skills gap by giving users access to technical knowledge, facilitating the smoothest possible integration of business and technology.
A Simple Framework for Choosing an LLM
Picking the right LLM isn’t one-size-fits-all. It depends on your specific goals and the problems you must solve. Here’s a step-by-step framework to guide you:
1. What Can It Do? (Capability)
Start by determining what your business needs the LLM for. For example, are you using it to help with customer support, answer technical questions, or do something else? Here are more questions:
Can the LLM be fine-tuned to fit your specific needs?
Can it work with your existing data?
Does it have enough “memory” to handle long inputs?
Capability Comparison
LLM
Can Be Fine-Tuned
Works with Custom Data
Memory (Context Length)
LLM 1
Yes
Yes
2048 tokens
LLM 2
No
Yes
4096 tokens
LLM 3
Yes
No
1024 tokens
For instance, Here, we could choose LLM 2 if we don’t care about fine-tuning and focus more on having a larger context window.
2. How Accurate Is It?
Accuracy is key. If you want an LLM that can give you reliable answers, test it with some real-world data to see how well it performs. Here are some questions:
Can the LLM be improved with tuning?
Does it consistently perform well?
Accuracy Comparison
LLM
General Accuracy
Accuracy with Custom Data
LLM 1
90%
85%
LLM 2
85%
80%
LLM 3
88%
86%
Here, we could choose LLM 3 if we prioritize accuracy with custom data, even if its general accuracy is slightly lower than LLM 1.
3. What Does It Cost?
LLMs can get expensive, especially when they’re in production. Some charge per use (like ChatGPT), while others have upfront costs for setup. Here are some questions:
Is the cost a one-time fee or ongoing (like a subscription)?
Is the cost worth the business benefits?
Cost Comparison
LLM
Cost
Pricing Model
LLM 1
High
Pay per API call (tokens)
LLM 2
Low
One-time hardware cost
LLM 3
Medium
Subscription-based
If minimizing ongoing costs is a priority, LLM 2 could be the best choice with its one-time hardware cost, even though LLM 1 may offer more flexibility with pay-per-use pricing.
4. Is It Compatible with Your Tech?
Make sure the LLM fits with your current tech setup. Most LLMs use Python, but your business might use something different, like Java or Node.js. Here are some questions:
Does it work with your existing technology stack?
5. Is It Easy to Maintain?
Maintenance is often overlooked, but it’s an important aspect. Some LLMs need more updates or come with limited documentation, which could make things harder in the long run. Here are some questions:
Does the LLM have good support and clear documentation?
Maintenance Comparison
LLM
Maintenance Level
Documentation Quality
LLM 1
Low (Easy)
Excellent
LLM 2
Medium (Moderate)
Limited
LLM 3
High (Difficult)
Inadequate
For instance: If ease of maintenance is a priority, LLM 1 would be the best choice, given its low maintenance needs and excellent documentation, even if other models may offer more features.
6. How Fast Is It? (Latency)
Latency is the time it takes an LLM to respond. Speed is important for some applications (like customer service), while for others, it might not be a big deal. Here are some questions:
How quickly does the LLM respond?
Latency Comparison
LLM
Response Time
Can It Be Optimized?
LLM 1
100ms
Yes (80ms)
LLM 2
300ms
Yes (250ms)
LLM 3
200ms
Yes (150ms)
For instance, If response speed is critical, such as for customer service applications, LLM 1 would be the best option with its low latency and potential for further optimization.
7. Can It Scale?
If your business is small, scaling might not be an issue. But if you’re expecting a lot of users, the LLM needs to handle multiple people or lots of data simultaneously. Here are some questions:
Can it scale up to handle more users or data?
Scalability Comparison
LLM
Max Users
Scalability Level
LLM 1
1000
High
LLM 2
500
Medium
LLM 3
1000
High
If scalability is a key factor and you anticipate a high number of users, both LLM 1 and LLM 3 would be suitable choices. Both offer high scalability to support up to 1000 users.
8. Infrastructure Needs
Different LLMs have varying infrastructure needs—some are optimized for the cloud, while others require powerful hardware like GPUs. Consider whether your business has the right setup for both development and production. Here are some questions:
Does it run efficiently on single or multiple GPUs/CPUs?
Does it support quantization for deployment on lower resources?
Can it be deployed on-premise or only in the cloud?
For instance, If your business lacks high-end hardware, a cloud-optimized LLM might be the best choice, whereas an on-premise solution would suit companies with existing GPU infrastructure.
9. Is It Secure?
Security is important, especially if you’re handling sensitive information. Make sure the LLM is secure and follows data protection laws.
Does it have secure data storage?
Is it compliant with regulations like GDPR?
Security Comparison
LLM
Security Features
GDPR Compliant
LLM 1
High
Yes
LLM 2
Medium
No
LLM 3
Low
Yes
For instance, If security and regulatory compliance are top priorities, LLM 1 would be the best option, as it offers high security and is GDPR compliant, unlike LLM 2.
10. What Kind of Support Is Available?
Good support can make or break your LLM experience, especially when encountering problems. Here are some questions:
Do the creators of the LLM provide support or help?
Is it easy to connect if any help is required to implement the LLM?
What is the availability of the support being provided?
Consider the LLM that has a good community or commercial support available.
Real-World Examples (Case Studies)
Here are some real-world examples:
Example 1: Education
Problem: Solving IIT-JEE exam questions
Key Considerations:
Needs fine-tuning for specific datasets
Accuracy is critical
Should scale to handle thousands of users
Example 2: Customer Support Automation
Problem: Automating customer queries
Key Considerations:
Security is vital (no data leaks)
Privacy matters (customers’ data must be protected)
Comparing LLM 1, 2, and 3
Criteria
LLM 1
LLM 2
LLM 3
Capability
Supports fine-tuning, custom data
Limited fine-tuning, large context
Fine-tuning supported
Accuracy
High (90%)
Medium (85%)
Medium (88%)
Cost
High (API pricing)
Low (One-time cost)
Medium (Subscription)
Tech Compatibility
Python-based
Python-based
Python-based
Maintenance
Low (Easy)
Medium (Moderate)
High (Frequent updates)
Latency
Fast (100ms)
Slow (300ms)
Moderate (200ms)
Scalability
High (1000 users)
Medium (500 users)
High (1000 users)
Security
High
Medium
Low
Support
Strong community
Limited support
Open-source community
Privacy Compliance
Yes (GDPR compliant)
No
Yes
Applying this to the cases:
Case Study 1: Education (Solving IIT-JEE Exam Questions)LLM 1 would be the ideal choice due to its strong fine-tuning capabilities for specific datasets, high accuracy, and ability to scale for thousands of users, making it perfect for handling large-scale educational applications.
Case Study 2: Customer Support AutomationLLM 1 is also the best fit here, thanks to its high security features and GDPR compliance. These features ensure that customer data is protected, which is critical for automating sensitive customer queries.
Conclusion
In summary, picking the right LLM for your business depends on several factors like cost, accuracy, scalability, and how it fits into your tech setup. This framework may help you find the right LLM and make sure to test the LLM with real-world data before committing. Remember, there’s no “perfect” LLM, but you can find the one that fits your business best by exploring, testing, and evaluating your options.
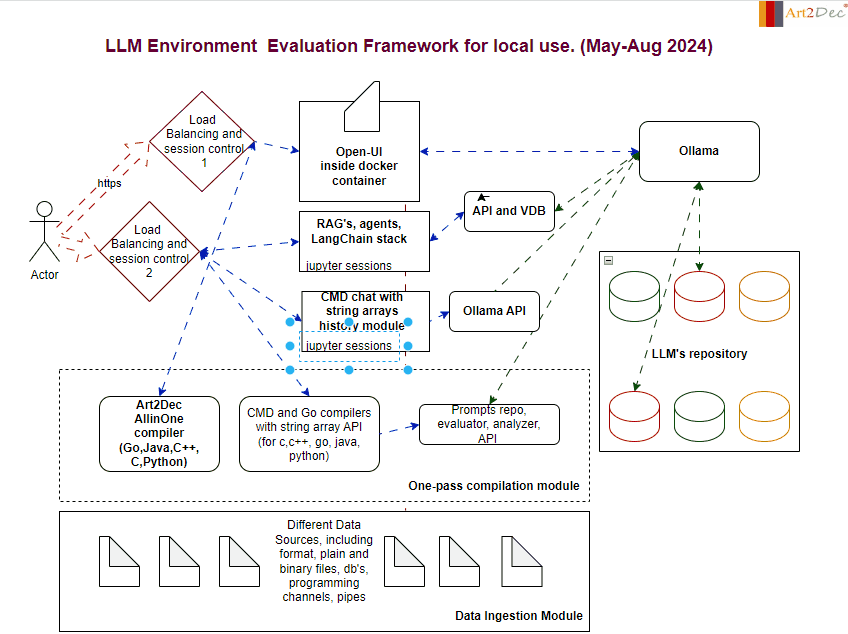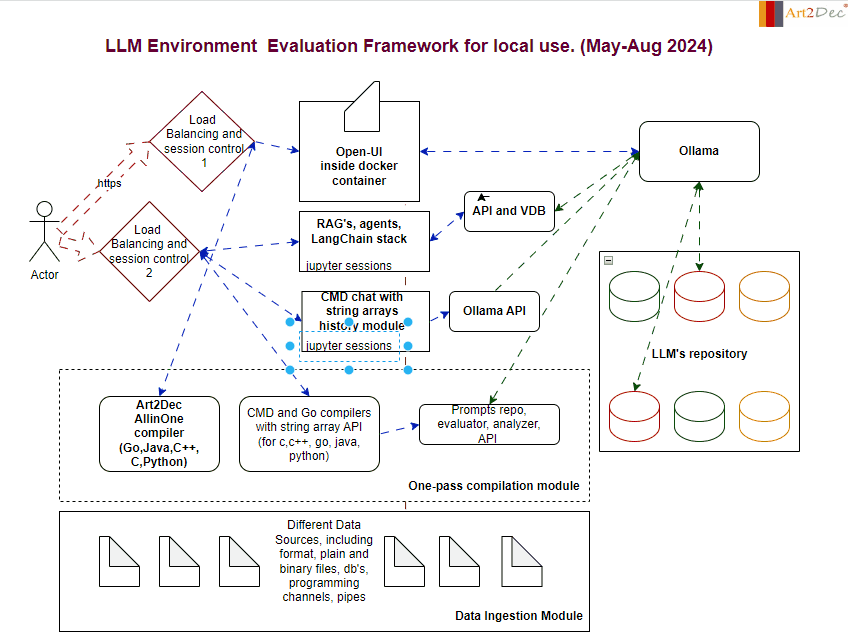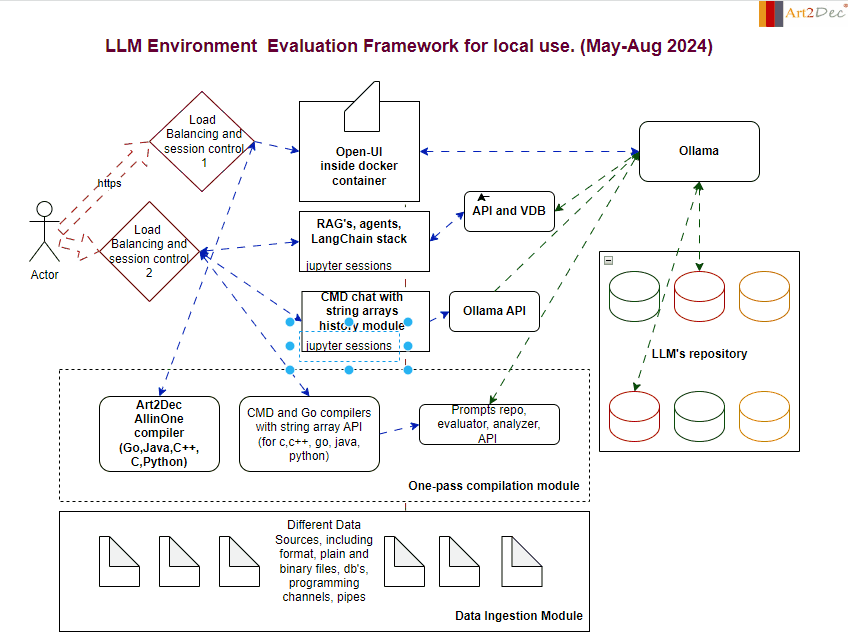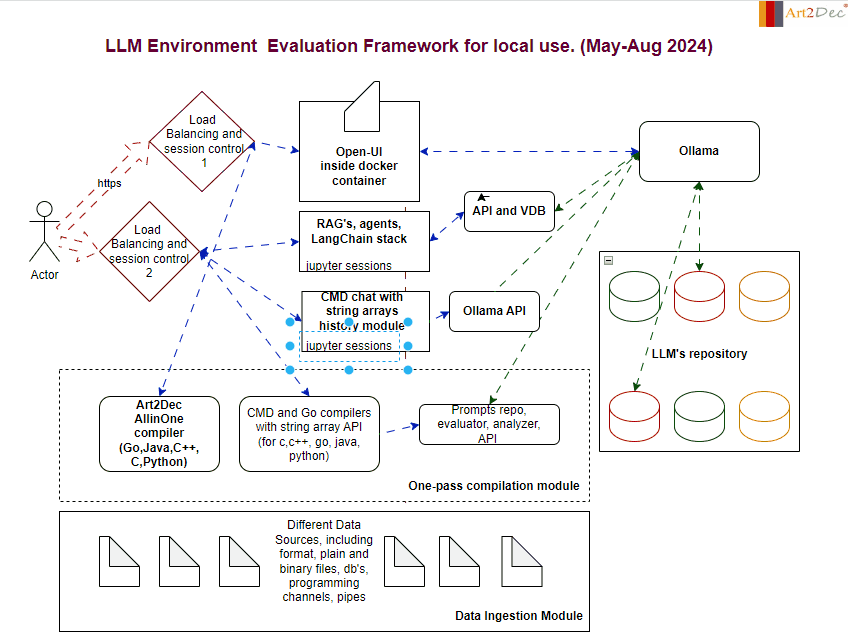
The LLM Evaluation Framework is designed for a local environment, facilitating the comprehensive evaluation and integration of large language models (LLMs). The framework comprises several key modules:
One-Pass Compilation Module: This module is a core component of the framework, integrating the Art2Dec All-in-One compiler to support multiple programming languages such as Go, Java, C++, and Python for testing. It includes also CMD and Go compilers with a string array API for languages like C, C++, Go, Java, and Python, enabling efficient compilation and execution of code. Additionally, it houses the Prompts Repo, Evaluator, Analyzer, and API module, which manages the storage and retrieval of prompts, evaluates LLM outputs, and analyzes performance data. This integration ensures a seamless workflow, allowing developers to compile, evaluate, and analyze their LLM-related tasks in a streamlined environment.
Data Ingestion Module: Capable of handling diverse data sources, including plain and binary files, databases, and programming channels, this module is responsible for the structured ingestion and preprocessing of data, feeding it into the system for analysis and evaluation.
Ollama Module: Ollama acts as a central hub for managing LLM interactions. It connects with the LLM’s repository and coordinates with various APIs, ensuring smooth communication and model deployment.
LLM Repository: A structured storage system that houses different versions and types of LLMs. This repository allows for easy access, retrieval, and management of models, facilitating rapid testing and deployment.
Chat and CMD Chat Modules: These modules provide interactive interfaces for users. The Chat module handles standard interactions with LLMs, while the CMD Chat module extends capabilities with command-line-based string array manipulations, allowing for detailed session history management.
APIs and Integrations module: The framework integrates various APIs, including those for prompts, evaluation, analysis, and the Ollama API, ensuring that all components can communicate effectively within the environment as well like make an adaptation of llm’s output to different compilers.
This framework is designed to streamline the evaluation process, providing a robust and scalable solution for working with LLMs in a controlled local environment.
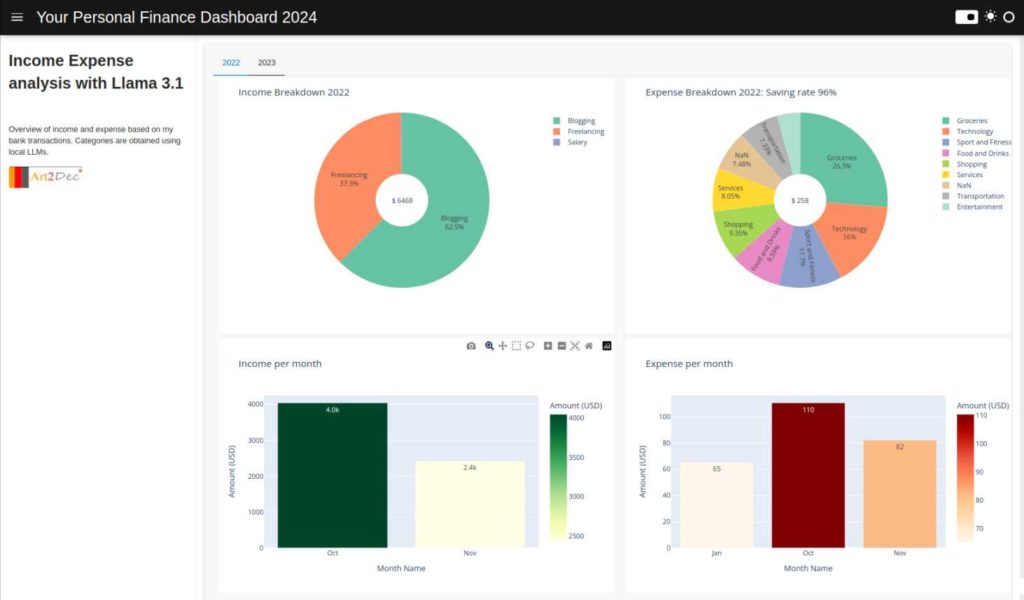
IEA is a cutting-edge personal finance application that leverages the advanced capabilities of the Llama 3.1 LLM model to provide tailored financial insights and advice. Whether you’re budgeting, tracking expenses, or planning for long-term goals, IEA offers personalized guidance by understanding your unique financial situation. The app simplifies complex financial data, suggests spending strategies, and helps you make informed decisions, ensuring that your financial health is always on track.
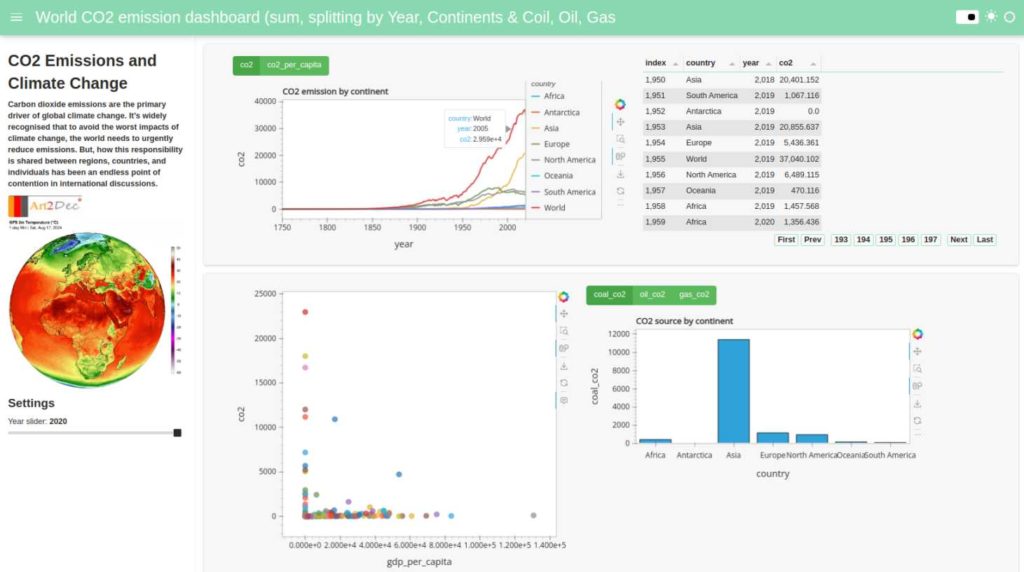
CO2 emissions application provides a comprehensive overview of carbon dioxide emissions by continent, focusing on emissions from coal, oil, and gas. Spanning from 1750 to the present, the dashboard offers detailed insights into how CO2 emissions have evolved over time, emphasizing the primary role of carbon dioxide in climate change. As the world faces the urgent need to reduce emissions, this tool highlights the issues of responsibility among and amount of emissions splitting for coal, oil, gas.
ChatGPT is a popular chatbot and virtual assistant developed by OpenAI and has been on the market since November 30, 2022. This chart model allows you to fine-tune and steer a conversation toward the ideal duration, structure, tone, degree of detail, and language.
Fortunately, with the continuous advancements in AI, open-source ChartGPT Alternatives have emerged as powerful tools that provide the same conversational skills and additional benefits of customization and transparency.
In addition, the open-source nature of these ChartGPT alternatives empowers developers to tailor the models to their specific needs, unleashing their full potential in various software and fostering collaboration.
In this post, we’ve compiled the best open-source ChartGPT Alternatives, highlighting their cutting-edge features and benefits.
1. GPT4All
GPT4All is a free, state-of-the-art chatbot that executes locally and respects user privacy. GPU or an internet connection is not necessarily needed for the functionality of this tool.
GPT4All comes with a variety of features users can explore, including creating poems, responding to inquiries, and presenting customized writing assistance.
Its additional features include building Python code, comprehending documents, and even training your GPT4All models. On top of that, GPT4All is an open-source environment that lets you set up and execute large, customized language models locally on consumer-grade CPUs.
Whether you want an instruction-based model for more in-depth interactions or a chat-based model for quicker responses, this tool has you covered.
2. OpenChatKit
OpenChatKit is a fantastic ChatGPT alternative, offering individuals similar natural language processing (NLP) capabilities while allowing more flexibility and control.
The tool allows users to train and fine-tune their models to fit specific use cases, as it is built on EleutherAI’s GPT-NeoX framework.
OpenChatKit‘s comprehensive features also give developers the capacity to create both general-purpose and specialized chatbot tools using a full toolkit that is easily accessed under the Apache 2.0 license.
In addition to features like the use of trained models and a retrieval system, OpenChatKit lets chatbots execute a variety of tasks, including arithmetic problem-solving, narrative and code writing, and document summarization.
OpenChatKit
3. HuggingChat
HuggingChat is a comprehensive platform that features an extensive selection of cutting-edge open large language models (LLMs).
To guarantee anonymity by design, Hugging Face (HF) accounts are used for user authentication, as the conversations remain private and aren’t shared with anyone, including model authors.
For consistency in providing a broad selection of state-of-the-art LLMs, HuggingChat periodically changes these models, including Llama 2 70B, CodeLlama 35B, and Mistral 7B.
In addition, this tool offers a platform for users to engage in public discussions, offering insightful feedback and helping to shape its future.
HuggingChat
4. Koala
Koala is a sophisticated chatbot, trained using discussion data from the internet to enhance Meta’s LLaMA. With its performance being compared to ChatGPT and Stanford’s Alpaca, this special model has undergone thorough dataset curation and training in extensive user research.
In over half of the situations, the outcomes show how good Koala is at answering a variety of customer inquiries, as it matches ChatGPT and frequently outshines Alpaca.
When trained on correctly obtained data, locally run chatbots can outperform their larger equivalents by using smaller public models like Koala.
Koala Chatbot
5. Alpaca-LoRA
Alpaca-LoRA is an innovative project that uses low-rank adaptation (LoRA) to replicate Stanford Alpaca outcomes. To research consumer hardware, like Raspberry Pi this project offers a text-davinci-003-quality Instruct model that is to be used.
The code offers flexibility and scalability and can be readily extended to 13b, 30b, and 65b models. In addition to the generated LoRA weights, the project also provides a script for downloading and inferring the foundation model and LoRA.
Without the need for hyperparameter adjustment, the LoRA model exhibits similar results to the Stanford Alpaca model, demonstrating its efficacy and opening up possibilities for extra improvement through user testing and feedback.
6. ColossalChat
ColossalChat is at the forefront of open-source large AI model solutions, featuring a full RLHF pipeline that includes supervised data gathering, fine-tuning reward model training, and reinforcement learning based on the LLaMA pre-trained model. It shares a useful open-source project that closely resembles the original ChatGPT technological solution.
With its cutting-edge features, this platform offers an open-source 104K bilingual dataset in both Chinese and English, an interactive demo for online exploration without registration, and open-source RLHF training code for 7B and 13B models.
In addition, ColossalChat provides 4-bit quantized inference, for 7 billion-parameter models, making it accessible with low GPU memory needs.
Thanks to its RLHF fine-tuning feature, ColossalChat is bilingual in both English and Chinese, enabling a variety of features like general knowledge tests, email writing, algorithm development, and ChatGPT cloning methods.
To provide a high-performance, user-friendly conversational AI experience, this tool guarantees adaptability, effectiveness, and smooth integration by utilizing PyTorch.
7. Baize
Baize is an open-source chat model that was trained with LoRA and optimized for performance using 100k self-generated dialogs from ChatGPT and Alpaca’s data. The project has produced models 7B, 13B, and 30B as it aims to offer a complete chat model solution.
To strictly prohibit commercial use and only allow intended reasons purely for research, the model weights and code are made available under the GPL-3.0 license, as An important tool for the AI field, Baize provides a workable open-source project that consists of an entire RLHF method for emulating ChatGPT-like models.
For CLI and API usage, users may connect with Baize using Fastchat, offering a smooth experience for utilizing the model’s features. The project also provides an intuitive Gradio chat interface, CLI and API support, and a bilingual dataset.
8. Dolly v2
Dolly v2 is a significant language model developed by Databricks, Inc. and trained via the Databricks machine learning platform to adhere to instructions. The instruction-following model can be purchased in multiple sizes (12B, 7B, and 3B) and has a license for commercial use.
In addition, this tool can be optimized on a ~15K record instruction corpus created by Databricks personnel, and it’s also based on EleutherAI’s Pythia-12b. The aim of the model is to be used with the transformers library on GPU-equipped computers because of its excellent instruction-following ability.
With its detailed features, this tool is useful for language processing jobs, and since it is still a work-in-progress model, its performance and drawbacks are continuously being evaluated and enhanced.
9. Vicuna
Vicuna-13B is an open-source chatbot, refined using user-shared talks gathered from ShareGPT.
By exceeding other models such as LLaMA and Stanford Alpaca in over 90% of situations and surpassing OpenAI ChatGPT and Google Bard in quality, this tool has proven to be very competitive in performance.
The model provides an online demo for individuals to experience its first-hand capabilities, which are freely accessible to the public for non-commercial use.
One of Vicuna-13 B’s amazing features and strengths is its capacity to provide comprehensive and structured responses, especially when fine-tuned using 70K user-shared ChatGPT discussions.
10. ChatRWKV
ChatRWKV, an inventive chatbot powered by the RWKV (100% RNN) language model, provides an alternative to transformer-based models like ChatGPT.
Jumping right into its features, RWKV-6, the most recent version, is renowned for its quality and scaling, matching transformers, and using less VRAM while operating faster. The model can be used for non-commercial purposes with Stability EleutherAI as its sponsor.
ChatRWKV’s tailored feature is its capacity to produce excellent responses, especially true with the RWKV-6 version, which has proven to be a highly effective tool.
On top of that, the presence of RWKV Discord, a community with over 7,000 members, suggests that this technology has a healthy following, because of its open-source nature and cutting-edge resources available, making it a fantastic choice for developers and researchers interested in experiencing RNN-based language models for chatbots.
11. Cerebras-GPT
The Cerebras-GPT is a family of large language models (LLMs) developed by Cerebras Systems to aid in studying LLM scaling laws using open architectures and datasets.
Having been trained using Chinchilla scaling principles and including parameters ranging from 111M to 13B, these models are compute-optimal. On top of that, these models may be found on Hugging Face, and EleutherAI’s Pile dataset as used in their training.
Even though chatbot functionality isn’t addressed specifically, Cerebras-GPT models are meant to show off how easy and scalable it is to train LLMs using the Cerebras hardware and software stack. This implies that research and development should take precedence over using chatbots in the real world.
12. Open Assistant
OpenAssistant is a finished project that aims to make a high-quality chat-based large language model accessible. The project aims to elevate language itself, revolutionizing language innovation and making the world a better place.
This tool’s inclusive features include a chat frontend for real-time communication and a data gathering frontend for enhancing the assistant’s functionality, which OpenAssistant provides.
The release of the OpenAssistant Conversations (OASST1) corpus, highlights the democratization of large-scale alignment research. Moreover, HuggingFace hosts the final published oasst2 dataset at OpenAssistant/oasst2.
OpenAssistant’s models and code are available under the Apache 2.0 license as an open-source project, which permits a variety of usage, including for profit. The initiative is designed and managed by LAION, which includes a team of volunteers across the globe.
The project offers chances for participation in data collection and development for any individuals interested in contributing.
Conclusion
With the help of these cutting-edge resources, small businesses, researchers, and developers can take advantage of language-based technology and take on the biggest names in the market.
Even though they may not outperform GPT-4, it is clear that they have room to grow and improve with the help of the community. These models are particularly perfect substitutes for GPT-4.