Provide a Data Grid
Oracle Coherence provides the ideal infrastructure for building Data Grid services, as well as the client and server-based applications that utilize a Data Grid. At a basic level, Oracle Coherence can manage an immense amount of data across a large number of servers in a grid; it can provide close to zero latency access for that data; it supports parallel queries across that data; and it supports integration with database and EIS systems that act as the system of record for that data. For more information on the infrastructure for the Data Grid features in Oracle Coherence, refer to the discussion on Data grid capabilities. Additionally, Oracle Coherence provides a number of services that are ideal for building effective data grids.
- Targeted Execution
- Parallel Execution
- Query-Based Execution
- Data-Grid-Wide Execution
- Agents for Targeted, Parallel and Query-Based Execution
- Data Grid Aggregation
- Node-Based Execution
- Work Manager
Oracle Coherence provides an extensive set of capabilities that make Data Grid services simple, seamless and seriously scalable. While the data grid provides an entire unified view of the complete data domain, the Data Grid features enable applications to take advantage of the partitioning of data that Oracle Coherence provides in a scale-out environment.
Overview
Oracle invented the concept of a data fabric with the introduction of the Coherence partitioned data management service in 2002. Since then, Forrester Research has labeled the combination of data virtualization, transparent and distributed EIS integration, queryability and uniform accessibility found in Coherence as an information fabric. The term fabric comes from a 2-dimensional illustration of interconnects, as in a switched fabric. The purpose of a fabric architecture is that all points within a fabric have a direct interconnect with all other points.
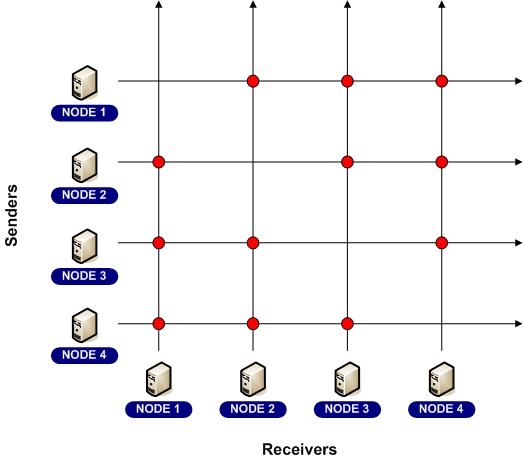
Data Fabric
An information fabric, or the more simple form called a data fabric or data grid, uses a switched fabric concept as the basis for managing data in a distributed environment. Also referred to as a dynamic mesh architecture, Coherence automatically and dynamically forms a reliable, increasingly resilient switched fabric composed of any number of servers within a grid environment. Consider the attributes and benefits of this architecture:
- The aggregate data throughput of the fabric is linearly proportional to the number of servers;
- The in-memory data capacity and data-indexing capacity of the fabric is linearly proportional to the number of servers;
- The aggregate I/O throughput for disk-based overflow and disk-based storage of data is linearly proportional to the number of servers;
- The resiliency of the fabric increases with the extent of the fabric, resulting in each server being responsible for only 1/n of the failover responsibility for a fabric with an extent of n servers;
- If the fabric is servicing clients, such as trading systems, the aggregage maximum number of clients that can be served is linearly proportional to the number of servers.
Coherence accomplishes these technical feats through a variety of algorithms:
- Coherence dynamically partitions data across all data fabric nodes;
- Since each data fabric node has a configurable maximum amount of data that it will manage, the capacity of the data fabric is linearly proportional to the number of data fabric nodes;
- Since the partitioning is automatic and load-balancing, each data fabric node ends up with its fair share of the data management responsibilities, allowing the throughput (in terms of network throughput, disk I/O throughput, query throughput, etc.) to scale linearly with the number of data fabric nodes;
- Coherence maintains a configurable level of redundancy of data, automatically eliminating single points of failure (SPOFs) by ensuring that data is kept synchronously up-to-date in multiple data fabric nodes;
- Coherence spreads out the responsibility for data redundancy in a dynamically load-balanced manner so that each server backs up a small amount of data from many other servers, instead of backing up all of the data from one particular server, thus amortizing the impact of a server failure across the entire data fabric;
- Each data fabric node can handle a large number of client connections, which can be load-balanced by a hardware load balancer.
EIS and Database Integration
The Coherence information fabric can automatically load data on demand from an underlying database or EIS using automatic read-through functionality. If data in the fabric are modified, the same functionality allows that data to be synchronously updated in the database, or queued for asynchronous write-behind.
Coherence automatically partitions data access across the data fabric, resulting in load-balanced data accesses and efficient use of database and EIS connectivity. Furthermore, the read-ahead and write-behind capabilities can cut data access latencies to near-zero levels and insulate the application from temporary database and EIS failures.
 |
Coherence solves the data bottleneck for large-scale compute grids
In large-scale compute grids, such as in DataSynapse financial grids and biotech grids, the bottleneck for most compute processes is in loading a data set and making it available to the compute engines that require it. By layering a Coherence data fabric onto (or beside) a compute grid, these data sets can be maintained in memory at all times, and Coherence can feed the data in parallel at close to wire speed to all of the compute nodes. In a large-scale deployment, Coherence can provide several thousand times the aggregate data throughput of the underlying data source. |
Queryable
The Coherence information fabric supports querying from any server in the fabric or any client of the fabric. The queries can be performed using any criteria, including custom criteria such as XPath queries and full text searches. When Coherence partitioning is used to manage the data, the query is processed in parallel across the entire fabric (i.e. the query is also partitioned), resulting in an data query engine that can scale its throughput up to fabrics of thousands of servers. For example, in a trading system it is possible to query for all open "Order" objects for a particular trader:
NamedCache mapTrades = ...
Filter filter = new AndFilter(new EqualsFilter("getTrader", traderid),
new EqualsFilter("getStatus", Status.OPEN));
Set setOpenTrades = mapTrades.entrySet(filter);
When an application queries for data from the fabric, the result is a point-in-time snapshot. Additionally, the query results can be kept up-to-date by placing a listener on the query itself or by using the Coherence Continuous Query feature.
Continuous Query
While it is possible to obtain a point in time query result from a Coherence data fabric, and it is possible to receive events that would change the result of that query, Coherence provides a feature that combines a query result with a continuous stream of related events that maintain the query result in a real-time fashion. This capability is called Continuous Query, because it has the same effect as if the desired query had zero latency and the query were repeated several times every millisecond!
Coherence implements Continuous Query using a combination of its data fabric parallel query capability and its real-time event-filtering and streaming. The result is support for thousands of client application instances, such as trading desktops. Using the previous trading system example, it can be converted to a Continuous Query with only one a single line of code changed:
NamedCache mapTrades = ...
Filter filter = new AndFilter(new EqualsFilter("getTrader", traderid),
new EqualsFilter("getStatus", Status.OPEN));
NamedCache mapOpenTrades = new ContinuousQueryCache(mapTrades, filter);
The result of the Continuous Query is maintained locally, and optionally all of corresponding data can be cached locally as well.
Summary
Coherence is successfully deployed as a large-scale data fabric for many of the world's largest financial, telecommunications, logistics, travel and media organizations. With unlimited scalability, the highest levels of availability, close to zero latency, an incredibly rich set of capabilities and a sterling reputation for quality, Coherence is the Information Fabric of choice.
Targeted Execution
Coherence provides for the ability to execute an agent against an entry in any map of data managed by the Data Grid:
map.invoke(key, agent);
In the case of partitioned data, the agent executes on the grid node that owns the data to execute against. This means that the queueing, concurrency management, agent execution, data access by the agent and data modification by the agent all occur on that grid node. (Only the synchronous backup of the resultant data modification, if any, requires additional network traffic.) For many processing purposes, it is much more efficient to move the serialized form of the agent (usually only a few hundred bytes, at most) than to handle distributed concurrency control, coherency and data updates.
For request/response processing, the agent returns a result:
Object oResult = map.invoke(key, agent);
In other words, Coherence as a Data Grid will determine the location to execute the agent based on the configuration for the data topology, move the agent there, execute the agent (automatically handling concurrency control for the item while executing the agent), back up the modifications if any, and return a result.
Parallel Execution
Coherence additionally provides for the ability to execute an agent against an entire collection of entries. In a partitioned Data Grid, the execution occurs in parallel, meaning that the more nodes that are in the grid, the broader the work is load-balanced across the Data Grid:
map.invokeAll(collectionKeys, agent);
For request/response processing, the agent returns one result for each key processed:
Map mapResults = map.invokeAll(collectionKeys, agent);
In other words, Coherence determines the optimal location(s) to execute the agent based on the configuration for the data topology, moves the agent there, executes the agent (automatically handling concurrency control for the item(s) while executing the agent), backing up the modifications if any, and returning the coalesced results.
Query-Based Execution
As discussed in the queryable data fabric topic, Coherence supports the ability to query across the entire data grid. For example, in a trading system it is possible to query for all open "Order" objects for a particular trader:
NamedCache map = CacheFactory.getCache("trades");
Filter filter = new AndFilter(new EqualsFilter("getTrader", traderid),
new EqualsFilter("getStatus", Status.OPEN));
Set setOpenTradeIds = mapTrades.keySet(filter);
By combining this feature with Parallel Execution in the data grid, Coherence provides for the ability to execute an agent against a query. As in the previous section, the execution occurs in parallel, and instead of returning the identities or entries that match the query, Coherence executes the agents against the entries:
map.invokeAll(filter, agent);
For request/response processing, the agent returns one result for each key processed:
Map mapResults = map.invokeAll(filter, agent);
In other words, Coherence combines its Parallel Query and its Parallel Execution together to achieve query-based agent invocation against a Data Grid.
Data-Grid-Wide Execution
Passing an instance of AlwaysFilter (or a null) to the invokeAll method will cause the passed agent to be executed against all entries in the InvocableMap:
map.invokeAll((Filter) null, agent);
As with the other types of agent invocation, request/response processing is supported:
Map mapResults = map.invokeAll((Filter) null, agent);
In other words, with a single line of code, an application can process all the data spread across a particular map in the Data Grid.
Agents for Targeted, Parallel and Query-Based Execution
An agent implements the EntryProcessor interface, typically by extending the AbstractProcessor class.
A number of agents are included with Coherence, including:
- AbstractProcessor - an abstract base class for building an EntryProcessor
- ExtractorProcessor - extracts and returns a specific value (such as a property value) from an object stored in an InvocableMap
- CompositeProcessor - bundles together a collection of EntryProcessor objects that are invoked sequentially against the same Entry
- ConditionalProcessor - conditionally invokes an EntryProcessor if a Filter against the Entry-to-process evaluates to true
- PropertyProcessor - an abstract base class for EntryProcessor implementations that depend on a PropertyManipulator
- NumberIncrementor - pre- or post-increments any property of a primitive integral type, as well as Byte, Short, Integer, Long, Float, Double, BigInteger, BigDecimal
- NumberMultiplier - multiplies any property of a primitive integral type, as well as Byte, Short, Integer, Long, Float, Double, BigInteger, BigDecimal, and returns either the previous or new value
The EntryProcessor interface (contained within the InvocableMap interface) contains only two methods:
/**
* An invocable agent that operates against the Entry objects within a
* Map.
*/
public interface EntryProcessor
extends Serializable
{
/**
* Process a Map Entry.
*
* @param entry the Entry to process
*
* @return the result of the processing, if any
*/
public Object process(Entry entry);
/**
* Process a Set of InvocableMap Entry objects. This method is
* semantically equivalent to:
* <pre>
* Map mapResults = new ListMap();
* for (Iterator iter = setEntries.iterator(); iter.hasNext(); )
* {
* Entry entry = (Entry) iter.next();
* mapResults.put(entry.getKey(), process(entry));
* }
* return mapResults;
* </pre>
*
* @param setEntries a read-only Set of InvocableMap Entry objects to
* process
*
* @return a Map containing the results of the processing, up to one
* entry for each InvocableMap Entry that was processed, keyed
* by the keys of the Map that were processed, with a
* corresponding value being the result of the processing for
* each key
*/
public Map processAll(Set setEntries);
}
(The AbstractProcessor implements the processAll method as described in the JavaDoc above.)
The InvocableMap.Entry that is passed to an EntryProcessor is an extension of the Map.Entry interface that allows an EntryProcessor implementation to obtain the necessary information about the entry and to make the necessary modifications in the most efficient manner possible:
/**
* An InvocableMap Entry contains additional information and exposes
* additional operations that the basic Map Entry does not. It allows
* non-existent entries to be represented, thus allowing their optional
* creation. It allows existent entries to be removed from the Map. It
* supports a number of optimizations that can ultimately be mapped
* through to indexes and other data structures of the underlying Map.
*/
public interface Entry
extends Map.Entry
{
// ----- Map Entry interface ------------------------------------
/**
* Return the key corresponding to this entry. The resultant key does
* not necessarily exist within the containing Map, which is to say
* that <tt>InvocableMap.this.containsKey(getKey)</tt> could return
* false. To test for the presence of this key within the Map, use
* {@link #isPresent}, and to create the entry for the key, use
* {@link #setValue}.
*
* @return the key corresponding to this entry; may be null if the
* underlying Map supports null keys
*/
public Object getKey();
/**
* Return the value corresponding to this entry. If the entry does
* not exist, then the value will be null. To differentiate between
* a null value and a non-existent entry, use {@link #isPresent}.
* <p/>
* <b>Note:</b> any modifications to the value retrieved using this
* method are not guaranteed to persist unless followed by a
* {@link #setValue} or {@link #update} call.
*
* @return the value corresponding to this entry; may be null if the
* value is null or if the Entry does not exist in the Map
*/
public Object getValue();
/**
* Store the value corresponding to this entry. If the entry does
* not exist, then the entry will be created by invoking this method,
* even with a null value (assuming the Map supports null values).
*
* @param oValue the new value for this Entry
*
* @return the previous value of this Entry, or null if the Entry did
* not exist
*/
public Object setValue(Object oValue);
// ----- InvocableMap Entry interface ---------------------------
/**
* Store the value corresponding to this entry. If the entry does
* not exist, then the entry will be created by invoking this method,
* even with a null value (assuming the Map supports null values).
* <p/>
* Unlike the other form of {@link #setValue(Object) setValue}, this
* form does not return the previous value, and as a result may be
* significantly less expensive (in terms of cost of execution) for
* certain Map implementations.
*
* @param oValue the new value for this Entry
* @param fSynthetic pass true only if the insertion into or
* modification of the Map should be treated as a
* synthetic event
*/
public void setValue(Object oValue, boolean fSynthetic);
/**
* Extract a value out of the Entry's value. Calling this method is
* semantically equivalent to
* <tt>extractor.extract(entry.getValue())</tt>, but this method may
* be significantly less expensive because the resultant value may be
* obtained from a forward index, for example.
*
* @param extractor a ValueExtractor to apply to the Entry's value
*
* @return the extracted value
*/
public Object extract(ValueExtractor extractor);
/**
* Update the Entry's value. Calling this method is semantically
* equivalent to:
* <pre>
* Object oTarget = entry.getValue();
* updater.update(oTarget, oValue);
* entry.setValue(oTarget, false);
* </pre>
* The benefit of using this method is that it may allow the Entry
* implementation to significantly optimize the operation, such as
* for purposes of delta updates and backup maintenance.
*
* @param updater a ValueUpdater used to modify the Entry's value
*/
public void update(ValueUpdater updater, Object oValue);
/**
* Determine if this Entry exists in the Map. If the Entry is not
* present, it can be created by calling {@link #setValue} or
* {@link #setValue}. If the Entry is present, it can be destroyed by
* calling {@link #remove}.
*
* @return true iff this Entry is existent in the containing Map
*/
public boolean isPresent();
/**
* Remove this Entry from the Map if it is present in the Map.
* <p/>
* This method supports both the operation corresponding to
* {@link Map#remove} as well as synthetic operations such as
* eviction. If the containing Map does not differentiate between
* the two, then this method will always be identical to
* <tt>InvocableMap.this.remove(getKey())</tt>.
*
* @param fSynthetic pass true only if the removal from the Map
* should be treated as a synthetic event
*/
public void remove(boolean fSynthetic);
}
Data Grid Aggregation
While the above agent discussion correspond to scalar agents, the InvocableMap interface also supports aggregation:
/**
* Perform an aggregating operation against the entries specified by the
* passed keys.
*
* @param collKeys the Collection of keys that specify the entries within
* this Map to aggregate across
* @param agent the EntryAggregator that is used to aggregate across
* the specified entries of this Map
*
* @return the result of the aggregation
*/
public Object aggregate(Collection collKeys, EntryAggregator agent);
/**
* Perform an aggregating operation against the set of entries that are
* selected by the given Filter.
* <p/>
* <b>Note:</b> calling this method on partitioned caches requires a
* Coherence Enterprise Edition (or higher) license.
*
* @param filter the Filter that is used to select entries within this
* Map to aggregate across
* @param agent the EntryAggregator that is used to aggregate across
* the selected entries of this Map
*
* @return the result of the aggregation
*/
public Object aggregate(Filter filter, EntryAggregator agent);
A simple EntryAggregator processes a set of InvocableMap.Entry objects to achieve a result:
/**
* An EntryAggregator represents processing that can be directed to occur
* against some subset of the entries in an InvocableMap, resulting in a
* aggregated result. Common examples of aggregation include functions
* such as min(), max() and avg(). However, the concept of aggregation
* applies to any process that needs to evaluate a group of entries to
* come up with a single answer.
*/
public interface EntryAggregator
extends Serializable
{
/**
* Process a set of InvocableMap Entry objects in order to produce an
* aggregated result.
*
* @param setEntries a Set of read-only InvocableMap Entry objects to
* aggregate
*
* @return the aggregated result from processing the entries
*/
public Object aggregate(Set setEntries);
}
For efficient execution in a Data Grid, an aggregation process must be designed to operate in a parallel manner. The
/**
* A ParallelAwareAggregator is an advanced extension to EntryAggregator
* that is explicitly capable of being run in parallel, for example in a
* distributed environment.
*/
public interface ParallelAwareAggregator
extends EntryAggregator
{
/**
* Get an aggregator that can take the place of this aggregator in
* situations in which the InvocableMap can aggregate in parallel.
*
* @return the aggregator that will be run in parallel
*/
public EntryAggregator getParallelAggregator();
/**
* Aggregate the results of the parallel aggregations.
*
* @return the aggregation of the parallel aggregation results
*/
public Object aggregateResults(Collection collResults);
}
Coherence comes with all of the natural aggregation functions, including:

|
All aggregators that come with Coherence are parallel-aware. |
- See the com.tangosol.util.aggregator package for a list of Coherence aggregators. To implement your own aggregator, see the AbstractAggregator abstract base class.
Node-Based Execution
Coherence provides an Invocation Service which allows execution of single-pass agents (called Invocable objects) anywhere within the grid. The agents can be executed on any particular node of the grid, in parallel on any particular set of nodes in the grid, or in parallel on all nodes of the grid.
An invocation service is configured using the invocation-scheme element in the cache configuration file. Using the name of the service, the application can easily obtain a reference to the service:
InvocationService service = CacheFactory.getInvocationService("agents");
Agents are simply runnable classes that are part of the application. The simplest example is a simple agent that is designed to request a GC from the JVM:
/**
* Agent that issues a garbage collection.
*/
public class GCAgent
extends AbstractInvocable
{
public void run()
{
System.gc();
}
}
To execute that agent across the entire cluster, it takes one line of code:
service.execute(new GCAgent(), null, null);
Here is an example of an agent that supports a grid-wide request/response model:
/**
* Agent that determines how much free memory a grid node has.
*/
public class FreeMemAgent
extends AbstractInvocable
{
public void run()
{
Runtime runtime = Runtime.getRuntime();
int cbFree = runtime.freeMemory();
int cbTotal = runtime.totalMemory();
setResult(new int[] {cbFree, cbTotal});
}
}
To execute that agent across the entire grid and retrieve all the results from it, it still takes only one line of code:
Map map = service.query(new FreeMemAgent(), null);
While it is easy to do a grid-wide request/response, it takes a bit more code to print out the results:
Iterator iter = map.entrySet().iterator();
while (iter.hasNext())
{
Map.Entry entry = (Map.Entry) iter.next();
Member member = (Member) entry.getKey();
int[] anInfo = (int[]) entry.getValue();
if (anInfo != null) // null if member died
System.out.println("Member " + member + " has "
+ anInfo[0] + " bytes free out of "
+ anInfo[1] + " bytes total");
}
The agent operations can be stateful, which means that their invocation state is serialized and transmitted to the grid nodes on which the agent is to be run.
/**
* Agent that carries some state with it.
*/
public class StatefulAgent
extends AbstractInvocable
{
public StatefulAgent(String sKey)
{
m_sKey = sKey;
}
public void run()
{
// the agent has the key that it was constructed with
String sKey = m_sKey;
// ...
}
private String m_sKey;
}
Work Manager
Coherence provides a grid-enabled implementation of the IBM and BEA CommonJ Work Manager, which is the basis for JSR-237. Once JSR-237 is complete, Oracle has committed to support the standardized J2EE API for Work Manager as well.
Using a Work Manager, an application can submit a collection of work that needs to be executed. The Work Manager distributes that work in such a way that it is executed in parallel, typically across the grid. In other words, if there are ten work items submitted and ten servers in the grid, then each server will likely process one work item. Further, the distribution of work items across the grid can be tailored, so that certain servers (e.g. one that acts as a gateway to a particular mainframe service) will be the first choice to run certain work items, for sake of efficiency and locality of data.
The application can then wait for the work to be completed, and can provide a timeout for how long it is willing to wait. The API for this purpose is quite powerful, allowing an application to wait for the first work item to complete, or for a specified set of the work items to complete. By combining methods from this API, it is possible to do things like "Here are 10 items to execute; for these 7 unimportant items, wait no more than 5 seconds, and for these 3 important items, wait no more than 30 seconds":
Work[] aWork = ...
Collection collBigItems = new ArrayList();
Collection collAllItems = new ArrayList();
for (int i = 0, c = aWork.length; i < c; ++i)
{
WorkItem item = manager.schedule(aWork[i]);
if (i < 3)
{
// the first three work items are the important ones
collBigItems.add(item);
}
collAllItems.add(item);
}
Collection collDone = manager.waitForAll(collAllItems, 5000L);
if (!collDone.containsAll(collBigItems))
{
// wait the remainder of 30 seconds for the important work to finish
manager.waitForAll(collBigItems, 25000L);
}
Of course, the best descriptions come from real-world production usage:
Oracle Coherence Work Manager: Feedback from a Major Financial Institution
Our primary use case for the Work Manager is to allow our application to serve coarse-grained service requests using our blade infrastructure in a standards-based way. We often have what appears to be a simple request, like "give me this family's information." In reality, however, this request expands into a large number of requests to several diverse back-end data sources consisting of web services, RDMBS calls, etc. This use case expands into two different but related problems that we are looking to the distributed version of the work manager to solve.
1. How do we take a coarse-grained request that expands into several fine-grained requests and execute them in parallel to avoid blocking the caller for an unreasonable time? In the above example, we may have to make upwards of 100 calls to various places to retrieve the information. Since J2EE has no legal threading model, and since the threading we observed when trying a message-based approach to this was unacceptable, we decided to use the Coherence Work Manager implementation.
2. Given that we want to make many external system calls in parallel while still leveraging low-cost blades, we are hoping that fanning the required work across many dual processor (logically 4-processor because of hyperthreading) machines allows us to scale an inherently vertical scalability problem with horizontal scalability at the hardware level. We think this is reasonable because the cost to marshall the request to a remote Work Manager instance is small compared to the cost to execute the service, which usually involves dozens or hundreds of milliseconds.
For more information on the Work Manager Specification and API, see Timer and Work Manager for Application Servers on the BEA dev2dev web site and JSR 237.
Summary
Coherence provides an extensive set of capabilities that make Data Grid services simple, seamless and seriously scalable. While the data fabric provides an entire unified view of the complete data domain, the Data Grid features enable applications to take advantage of the partitioning of data that Coherence provides in a scale-out environment. |