Release 11g (11.1.1)
Part Number E13880-01
Contents
Previous
Next
| Oracle Fusion Middleware Administrator's and Developer's Guide for Oracle Business Intelligence Publisher Release 11g (11.1.1) Part Number E13880-01 | Contents | Previous | Next |
| View PDF |
This chapter is aimed at developers who wish to create programs or applications that interact with BI Publisher through its application programming interface. This information is meant to be used in conjunction with the Oracle Fusion Middleware Java API Reference for Oracle Business Intelligence Publisher, which is available in the Oracle Fusion Middleware Business Intelligence Documentation Library.
This section assumes the reader is familiar with Java programming, XML, and XSL technologies.
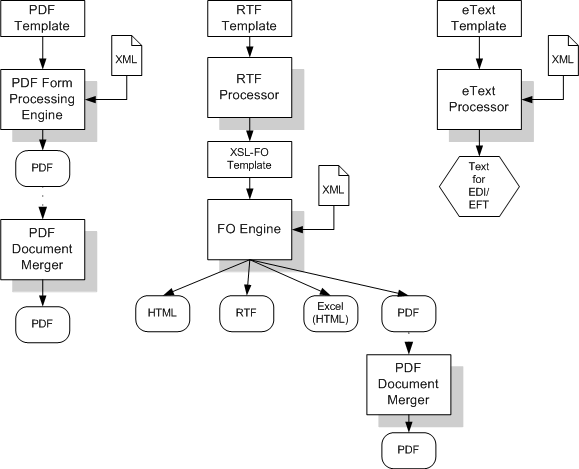
BI Publisher is made up of the following core API components:
PDF Form Processing Engine
Merges a PDF template with XML data (and optional metadata) to produce PDF document output.
RTF Processor
Converts an RTF template to XSL in preparation for input to the FO Engine.
FO Engine
Merges XSL and XML to produce any of the following output formats: Excel (HTML), PDF, RTF, or HTML.
PDF Document Merger
Provides optional postprocessing of PDF files to merge documents, add page numbering, and set watermarks.
eText Processor
Converts RTF eText templates to XSL and merges the XSL with XML to produce text output for EDI and EFT transmissions.
Document Processor (XML APIs)
Provides batch processing functionality to access a single API or multiple APIs by passing a single XML file to specify template names, data sources, languages, output type, output names, and destinations.
The following diagram illustrates the template type and output type options for each core processing engine:
In order to use the BI Publisher APIs you need the following JAR files in your class path:
aolj.jar - version information for Oracle E-Business Suite
collections.jar - you only need this if you are working with the delivery APIs or bursting engine.
dvt-jclient.jar - a charting library
dvt-utils.jar - a charting library
groovy-all-1.6.3.jar - Groovy
i18nAPI_v3.jar - the i18n library used for localization functions
jewt4.jar - a charting support library
mail.jar - used for SMTP delivery
ojdl.jar - used for Oracle Diagnostic Logging
orai18n-collation.jar - used by XDK
orai18n-mapping.jar - used by XDK
orai18n.jar - contains character set and globalization support files used by XDK
osdt_cert.jar - security library for SMIME support
osdt_cms.jar - security library for SMIME support
osdt_core.jar - security library for SMIME support
osdt_smime.jar - security library for SMIME support
share.jar - a charting support library
xdoparser.jar - the scalable XML parser and XSLT 2.0 engine (10g)
xdoparser11g.jar - the scalable XML parser and XSLT 2.0 engine (11g)
xmlparserv2.jar - 11g XDK (SAX and DOM)
If you are using Oracle JDeveloper, then the charting and XML Parser libraries will already be available to you. However, it is recommended that you create a directory with all of the required JAR files to use as a custom library in your project. This will help prevent unexpected errors after deployment.
The easiest method to obtain the libraries is to download the and install the Template Builder for Microsoft Word Add-in. Download the Template Builder for Word from the Home page, under Get Started, click Download BI Publisher Tools, then click Template Builder for Word.
The JAR files are packaged with the Template Builder in the jlib library under the install directory.
A sample path to the jlib would be:
C:\Program Files\Oracle\BI Publisher\BI Publisher Desktop\Template Builder for Word\jlib
Note that the Template Builder does include the aolj.jar. You must use the versioninfo.jar instead.
The PDF Form Processing Engine creates a PDF document by merging a PDF template with an XML data file. This can be done using file names, streams, or an XML data string.
As input to the PDF Processing Engine you can optionally include an XML-based Template MetaInfo (.xtm) file. This is a supplemental template to define the placement of overflow data.
The FO Processing Engine also includes utilities to provide information about your PDF template. You can:
Retrieve a list of field names from a PDF template
Convert XML data into XFDF using XSLT
XML data can be merged with a PDF template to produce a PDF output document in three ways:
Using input/output file names
Using input/output streams
Using an input XML data string
Input:
Template file name (String)
XML file name (String)
Output:
PDF file name (String)
import oracle.xdo.template.FormProcessor;
.
.
FormProcessor fProcessor = new FormProcessor();
fProcessor.setTemplate(args[0]); // Input File (PDF) name
fProcessor.setData(args[1]); // Input XML data file name
fProcessor.setOutput(args[2]); // Output File (PDF) name fProcessor.process();
Input:
PDF Template (Input Stream)
XML Data (Input Stream)
Output:
PDF (Output Stream)
import java.io.*;
import oracle.xdo.template.FormProcessor;
.
.
.
FormProcessor fProcessor = new FormProcessor();
FileInputStream fIs = new FileInputStream(originalFilePath); // Input File
FileInputStream fIs2 = new FileInputStream(dataFilePath); // Input Data
FileInputStream fIs3 = new FileInputStream(metaData); // Metadata XML Data
FileOutputStream fOs = new FileOutputStream(newFilePath); // Output File
fProcessor.setTemplate(fIs);
fProcessor.setData(fIs2); // Input Data
fProcessor.setOutput(fOs);
fProcessor.process();
fIs.close();
fOs.close();
Input:
Template file name (String)
XML data (String)
Output:
PDF file name (String)
import oracle.xdo.template.FormProcessor;
.
.
.
FormProcessor fProcessor = new FormProcessor();
fProcessor.setTemplate(originalFilePath); // Input File (PDF) name
fProcessor.setDataString(xmlContents); // Input XML string
fProcessor.setOutput(newFilePath); // Output File (PDF) name
fProcessor.process();
Use the FormProcessor.getFieldNames() API to retrieve the field names from a PDF template. The API returns the field names into an Enumeration object.
Input:
PDF Template
Output:
Enumeration Object
import java.util.Enumeration;
import oracle.xdo.template.FormProcessor;
.
.
.
FormProcessor fProcessor = new FormProcessor();
fProcessor.setTemplate(filePath); // Input File (PDF) name
Enumeration enum = fProcessor.getFieldNames();
while(enum.hasMoreElements())
{
String formName = (String)enum.nextElement();
System.out.println("name : " + formName + " , value : " + fProcessor.getFieldValue(formName));
}
XML Forms Data Format (XFDF) is a format for representing forms data and annotations in a PDF document. XFDF is the XML version of Forms Data Format (FDF), a simplified version of PDF for representing forms data and annotations. Form fields in a PDF document include edit boxes, buttons, and radio buttons.
Use this class to generate XFDF data. When you create an instance of this class, an internal XFDF tree is initialized. Use append() methods to append a FIELD element to the XFDF tree by passing a String name-value pair. You can append data as many times as you want.
This class also allows you to append XML data by calling appendXML() methods. Note that you must set the appropriate XSL stylesheet by calling setStyleSheet() method before calling appendXML() methods. You can append XML data as many times as you want.
You can retrieve the internal XFDF document at any time by calling one of the following methods: toString(), toReader(), toInputStream(), or toXMLDocument().
The following is a sample of XFDF data:
<?xml version="1.0" encoding="UTF-8"?>
<xfdf xmlns="http://ns.adobe.com/xfdf/" xml:space="preserve">
<fields>
<field name="TITLE">
<value>Purchase Order</value>
</field>
<field name="SUPPLIER_TITLE">
<value>Supplie</value>
</field>
...
</fields>The following code example shows how the API can be used:
import oracle.xdo.template.FormProcessor;
import oracle.xdo.template.pdf.xfdf.XFDFObject;
.
.
.
FormProcessor fProcessor = new FormProcessor();
fProcessor.setTemplate(filePath); // Input File (PDF) name
XFDFObject xfdfObject = new XFDFObject(fProcessor.getFieldInfo());
System.out.println(xfdfObject.toString());
Use an XSL stylesheet to convert standard XML to the XFDF format. Following is an example of the conversion of sample XML data to XFDF:
Assume your starting XML has a ROWSET/ROW format as follows:
<ROWSET>
<ROW num="0">
<SUPPLIER>Supplier</SUPPLIER>
<SUPPLIERNUMBER>Supplier Number</SUPPLIERNUMBER>
<CURRCODE>Currency</CURRCODE>
</ROW>
...
</ROWSET>From this XML you want to generate the following XFDF format:
<fields>
<field name="SUPPLIER1">
<value>Supplier</value>
</field>
<field name="SUPPLIERNUMBER1">
<value>Supplier Number</value>
</field>
<field name="CURRCODE1">
<value>Currency</value>
</field>
...
</fields>The following XSLT will carry out the transformation:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<fields>
<xsl:apply-templates/>
</fields>
</xsl:template>
<!-- Count how many ROWs(rows) are in the source XML file. -->
<xsl:variable name="cnt" select="count(//row|//ROW)" />
<!-- Try to match ROW (or row) element.
<xsl:template match="ROW/*|row/*">
<field>
<!-- Set "name" attribute in "field" element. -->
<xsl:attribute name="name">
<!-- Set the name of the current element (column name)as a value of the current name attribute. -->
<xsl:value-of select="name(.)" />
<!-- Add the number at the end of the name attribute value if more than 1 rows found in the source XML file.-->
<xsl:if test="$cnt > 1">
<xsl:number count="ROW|row" level="single" format="1"/>
</xsl:if>
</xsl:attribute>
<value>
<!--Set the text data set in the current column data as a text of the "value" element. -->
<xsl:value-of select="." />
</value>
</field>
</xsl:template>
</xsl:stylesheet> You can then use the XFDFObject to convert XML to the XFDF format using an XSLT as follows:
import java.io.*;
import oracle.xdo.template.pdf.xfdf.XFDFObject;
.
.
.
XFDFObject xfdfObject = new XFDFObject();
xfdfObject .setStylesheet(new BufferedInputStream(new FileInputStream(xslPath))); // XSL file name
xfdfObject .appendXML( new File(xmlPath1)); // XML data file name
xfdfObject .appendXML( new File(xmlPath2)); // XML data file name
System.out.print(xfdfObject .toString());
The RTFProcessor can generate the pairing XLIFF file. The API example is as follows:
public static void main(String[] args)
{
RTFProcessor rtfp = new RTFProcessor(args[0]); //input RTF template
rtfp.setOutput(args[1]); // XSL output file
rtfp.setXLIFFOutput(args[2]); // XLIFF output file
rtfp.process();
System.exit(0);
}
To generate the translated report, call FOProcessor as follows:
FOProcessor p1 = new FOProcessor();
p1.setXLIFF(xliff);// set xliff file, which is generated from RTFProcessor
p1.setData(xml); // set data file
p1.setTemplate(xsl); // set xsl file
p1.setOutput(pdf);
p1.generate();The RTF processor engine takes an RTF template as input. The processor parses the template and creates an XSL-FO template. This can then be passed along with a data source (XML file) to the FO Engine to produce PDF, HTML, RTF, or Excel (HTML) output.
Use either input/output file names or input/output streams as shown in the following examples:
Input:
RTF file name (String)
Output:
XSL file name (String)
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args)
{
RTFProcessor rtfProcessor = new RTFProcessor(args[0]); //input template
rtfProcessor.setOutput(args[1]); // output file
rtfProcessor.process();
System.exit(0);
}
Input:
RTF (InputStream)
Output:
XSL (OutputStream)
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args)
{
FileInputStream fIs = new FileInputStream(args[0]); //input template
FileOutputStream fOs = new FileOutputStream(args[1]); // output
RTFProcessor rtfProcessor = new RTFProcessor(fIs);
rtfProcessor.setOutput(fOs);
rtfProcessor.process();
// Closes inputStreams outputStream
System.exit(0);
}
The FO Processor Engine is BI Publisher's implementation of the W3C XSL-FO standard. It does not represent a complete implementation of every XSL-FO component. For a list of supported XSL-FO elements, see Supported XSL-FO Elements, Oracle Fusion Middleware Report Designer's Guide for Business Intelligence Publisher.
The FO Processor can generate output in PDF, RTF, HTML, or Excel (HTML) from either of the following two inputs:
Template (XSL) and Data (XML) combination
FO object
Both input types can be passed as file names, streams, or in an array. Set the output format by setting the setOutputFormat method to one of the following:
FORMAT_EXCEL
FORMAT_HTML
FORMAT_PDF
FORMAT_RTF
FORMAT_PPTX
FORMAT_MHTML
FORMAT_PPTMHT
FORMAT_EXCEL_MHTML
FORMAT_PDFZ
An XSL-FO utility is also provided that creates XSL-FO from the following inputs:
XSL file and XML file
Two XML files and two XSL files
Two XSL-FO files (merge)
The FO object output from the XSL-FO utility can then be used as input to the FO processor.
BI Publisher utilizes the Unicode BiDi algorithm for BiDi layout. Based on specific values for the properties writing-mode, direction, and unicode bidi, the FO Processor supports the BiDi layout.
The writing-mode property defines how word order is supported in lines and order of lines in text. That is: right-to-left, top-to-bottom or left-to-right, top-to-bottom. The direction property determines how a string of text will be written: that is, in a specific direction, such as right-to-left or left-to-right. The unicode bidi controls and manages override behavior.
The FO Processor supports a two-level font fallback mechanism. This mechanism provides control over what default fonts to use when a specified font or glyph is not found. BI Publisher provides appropriate default fallback fonts automatically without requiring any configuration. BI Publisher also supports user-defined configuration files that specify the default fonts to use. For glyph fallback, the default mechanism will only replace the glyph and not the entire string.
For headers and footers that require more space than what is defined in the template, the FO Processor extends the regions and reduces the body region by the difference between the value of the page header and footer and the value of the body region margin.
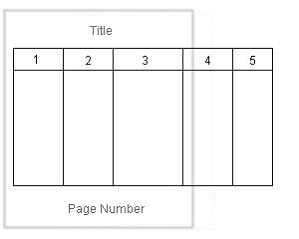
This feature supports a "Z style" of horizontal table break. The horizontal table break is not sensitive to column span, so that if the column-spanned cells exceed the page (or area width), the FO Processor splits it and does not apply any intelligent formatting to the split cell.
The following figure shows a table that is too wide to display on one page:
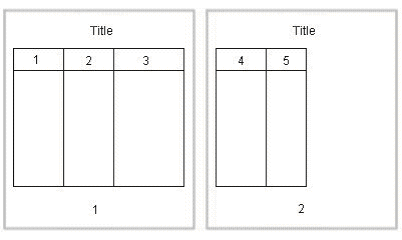
The following figure shows one option of how the horizontal table break will handle the wide table. In this example, a horizontal table break is inserted after the third column.
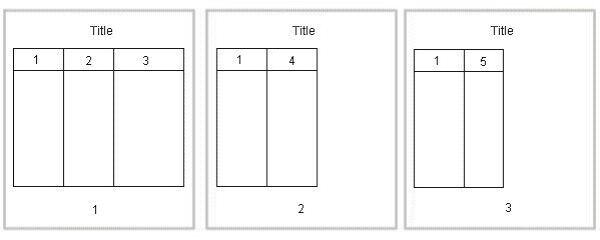
The following figure shows another option. The table breaks after the third column, but includes the first column with each new page.
The following example shows how to use the FO Processor to create an output file using file names.
Input:
XML file name (String)
XSL file name (String)
Output:
Output file name (String)
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args)
{
FOProcessor processor = new FOProcessor();
processor.setData(args[0]); // set XML input file
processor.setTemplate(args[1]); // set XSL input file
processor.setOutput(args[2]); //set output file
processor.setOutputFormat(FOProcessor.FORMAT_PDF);
// Start processing
try
{
processor.generate();
}
catch (XDOException e)
{
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
The processor can also be used with input/output streams as shown in the following example:
Input:
XML data (InputStream)
XSL data (InputStream)
Output:
Output stream (OutputStream)
import java.io.InputStream;
import java.io.OutputStream;
import oracle.xdo.template.FOProcessor;
.
.
.
public void runFOProcessor(InputStream xmlInputStream,
InputStream xslInputStream,
OutputStream pdfOutputStream)
{
FOProcessor processor = new FOProcessor();
processor.setData(xmlInputStream);
processor.setTemplate(xslInputStream);
processor.setOutput(pdfOutputStream);
// Set output format (for PDF generation)
processor.setOutputFormat(FOProcessor.FORMAT_PDF);
// Start processing
try
{
processor.generate();
}
catch (XDOException e)
{
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
An array of data and template combinations can be processed to generate a single output file from the multiple inputs. The number of input data sources must match the number of templates that are to be applied to the data. For example, an input of File1.xml, File2.xml, File3.xml and File1.xsl, File2.xsl, and File3.xsl will produce a single File1_File2_File3.pdf.
Input:
XML data (Array)
XSL data (template) (Array)
Output:
File Name (String)
import java.io.InputStream;
import java.io.OutputStream;
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args)
{
String[] xmlInput = {"first.xml", "second.xml", "third.xml"};
String[] xslInput = {"first.xsl", "second.xsl", "third.xsl"};
FOProcessor processor = new FOProcessor();
processor.setData(xmlInput);
processor.setTemplate(xslInput);
processor.setOutput("/tmp/output.pdf); //set (PDF) output file
processor.setOutputFormat(FOProcessor.FORMAT_PDF); processor.process();
// Start processing
try
{
processor.generate();
}
catch (XDOException e)
{
e.printStackTrace();
System.exit(1);
}
}
Use the XSL-FO Utility to create an XSL-FO output file from input XML and XSL files, or to merge two XSL-FO files. Output from this utility can be used to generate your final output. See Generating Output from an XSL-FO file.
Input:
XML file
XSL file
Output:
XSL-FO (InputStream)
import oracle.xdo.template.fo.util.FOUtility;
.
.
.
public static void main(String[] args)
{
InputStream foStream;
// creates XSL-FO InputStream from XML(arg[0])
// and XSL(arg[1]) filepath String
foStream = FOUtility.createFO(args[0], args[1]);
if (mergedFOStream == null)
{
System.out.println("Merge failed.");
System.exit(1);
}
System.exit(0);
}
Input:
XML File 1
XML File 2
XSL File 1
XSL File 2
Output:
XSL-FO (InputStream)
import oracle.xdo.template.fo.util.FOUtility;
.
.
.
public static void main(String[] args)
{
InputStream firstFOStream, secondFOStream, mergedFOStream;
InputStream[] input = InputStream[2];
// creates XSL-FO from arguments
firstFOStream = FOUtility.createFO(args[0], args[1]);
// creates another XSL-FO from arguments
secondFOStream = FOUtility.createFO(args[2], args[3]);
// set each InputStream into the InputStream Array
Array.set(input, 0, firstFOStream);
Array.set(input, 1, secondFOStream);
// merges two XSL-FOs
mergedFOStream = FOUtility.mergeFOs(input);
if (mergedFOStream == null)
{
System.out.println("Merge failed.");
System.exit(1);
}
System.exit(0);
}
Input:
Two XSL-FO file names (Array)
Output:
One XSL-FO (InputStream)
import oracle.xdo.template.fo.util.FOUtility;
.
.
.
public static void main(String[] args)
{
InputStream mergedFOStream;
// creates Array
String[] input = {args[0], args[1]};
// merges two FO files
mergedFOStream = FOUtility.mergeFOs(input);
if (mergedFOStream == null)
{
System.out.println("Merge failed.");
System.exit(1);
}
System.exit(0);
}
The FO Processor can also be used to process an FO object to generate your final output. An FO object is the result of the application of an XSL-FO stylesheet to XML data. These objects can be generated from a third party application and fed as input to the FO Processor.
The processor is called using a similar method to those already described, but a template is not required as the formatting instructions are contained in the FO.
Input:
FO file name (String)
Output:
PDF file name (String)
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args) {
FOProcessor processor = new FOProcessor();
processor.setData(args[0]); // set XSL-FO input file
processor.setTemplate((String)null);
processor.setOutput(args[2]); //set (PDF) output file
processor.setOutputFormat(FOProcessor.FORMAT_PDF);
// Start processing
try
{
processor.generate();
}
catch (XDOException e)
{
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
Input:
FO data (InputStream)
Output:
Output (OutputStream)
import java.io.InputStream;
import java.io.OutputStream;
import oracle.xdo.template.FOProcessor;
.
.
.
public void runFOProcessor(InputStream xmlfoInputStream,
OutputStream pdfOutputStream)
{
FOProcessor processor = new FOProcessor();
processor.setData(xmlfoInputStream);
processor.setTemplate((String)null);
processor.setOutput(pdfOutputStream);
// Set output format (for PDF generation)
processor.setOutputFormat(FOProcessor.FORMAT_PDF);
// Start processing
try
{
processor.generate();
}
catch (XDOException e)
{
e.printStackTrace();
System.exit(1);
}
}
Pass multiple FO inputs as an array to generate a single output file. A template is not required, therefore set the members of the template array to null, as shown in the example.
Input:
FO data (Array)
Output:
Output File Name (String)
import java.lang.reflect.Array;
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args)
{
String[] xmlInput = {"first.fo", "second.fo", "third.fo"};
String[] xslInput = {null, null, null}; // null needs for xsl-fo input
FOProcessor processor = new FOProcessor();
processor.setData(xmlInput);
processor.setTemplate(xslInput);
processor.setOutput("/tmp/output.pdf); //set (PDF) output file
processor.setOutputFormat(FOProcessor.FORMAT_PDF); processor.process();
// Start processing
try
{
processor.generate();
}
catch (XDOException e)
{
e.printStackTrace();
System.exit(1);
}
}
The PDF Document Merger class provides a set of utilities to manipulate PDF documents. Using these utilities, you can merge documents, add page numbering, set backgrounds, and add watermarks.
Many business documents are composed of several individual documents that need to be merged into a single final document. The PDFDocMerger class supports the merging of multiple documents to create a single PDF document. This can then be manipulated further to add page numbering, watermarks, or other background images.
The following code demonstrates how to merge (concatenate) two PDF documents using physical files to generate a single output document.
Input:
PDF_1 file name (String)
PDF_2 file name (String)
Output:
PDF file name (String)
import java.io.*;
import oracle.xdo.common.pdf.util.PDFDocMerger;
.
.
.
public static void main(String[] args)
{
try
{
// Last argument is PDF file name for output
int inputNumbers = args.length - 1;
// Initialize inputStreams
FileInputStream[] inputStreams = new FileInputStream[inputNumbers];
inputStreams[0] = new FileInputStream(args[0]);
inputStreams[1] = new FileInputStream(args[1]);
// Initialize outputStream
FileOutputStream outputStream = new FileOutputStream(args[2]);
// Initialize PDFDocMerger
PDFDocMerger docMerger = new PDFDocMerger(inputStreams, outputStream);
// Merge PDF Documents and generates new PDF Document
docMerger.mergePDFDocs();
docMerger = null;
// Closes inputStreams and outputStream
}
catch(Exception exc)
{
exc.printStackTrace();
}
}
Input:
PDF Documents (InputStream Array)
Output:
PDF Document (OutputStream)
import java.io.*;
import oracle.xdo.common.pdf.util.PDFDocMerger;
.
.
.
public boolean mergeDocs(InputStream[] inputStreams, OutputStream outputStream)
{
try
{
// Initialize PDFDocMerger
PDFDocMerger docMerger = new PDFDocMerger(inputStreams, outputStream);
// Merge PDF Documents and generates new PDF Document
docMerger.mergePDFDocs();
docMerger = null;
return true;
}
catch(Exception exc)
{
exc.printStackTrace();
return false;
}
}
The following code demonstrates how to merge two PDF documents using input streams to generate a single merged output stream.
To add page numbers:
Create a background PDF template document that includes a PDF form field in the position that you would like the page number to appear on the final output PDF document.
Name the form field @pagenum@.
Enter the number in the field from which to start the page numbering. If you do not enter a value in the field, the start page number defaults to 1.
Input:
PDF Documents (InputStream Array)
Background PDF Document (InputStream)
Output:
PDF Document (OutputStream)
import java.io.*;
import oracle.xdo.common.pdf.util.PDFDocMerger;
.
.
.
public static boolean mergeDocs(InputStream[] inputStreams, InputStream backgroundStream, OutputStream outputStream)
{
try
{
// Initialize PDFDocMerger
PDFDocMerger docMerger = new PDFDocMerger(inputStreams, outputStream);
// Set Background
docMerger.setBackground(backgroundStream);
// Merge PDF Documents and generates new PDF Document
docMerger.mergePDFDocs();
docMerger = null;
return true;
}
catch(Exception exc)
{
exc.printStackTrace();
return false;
}
}
The FO Processor supports page numbering natively through the XSL-FO templates, but if you are merging multiple documents you must use this class to number the complete document from beginning to end.
The following code example places page numbers in a specific point on the page, formats the numbers, and sets the start value using the following methods:
setPageNumberCoordinates (x, y) - sets the x and y coordinates for the page number position. The following example sets the coordinates to 300, 20.
setPageNumberFontInfo (font name, size) - sets the font and size for the page number. If you do not call this method, the default "Helvetica", size 8 is used. The following example sets the font to "Courier", size 8.
setPageNumberValue (n, n) - sets the start number and the page on which to begin numbering. If you do not call this method, the default values 1, 1 are used.
Input:
PDF Documents (InputStream Arrary)
Output:
PDF Document (OutputStream)
import java.io.*;
import oracle.xdo.common.pdf.util.PDFDocMerger;
.
.
.
public boolean mergeDocs(InputStream[] inputStreams, OutputStream outputStream)
{
try
{
// Initialize PDFDocMerger
PDFDocMerger docMerger = new PDFDocMerger(inputStreams, outputStream);
// Calls several methods to specify Page Number
// Calling setPageNumberCoordinates() method is necessary to set Page Numbering
// Please refer to javadoc for more information
docMerger.setPageNumberCoordinates(300, 20);
// If this method is not called, then the default font"(Helvetica, 8)" is used.
docMerger.setPageNumberFontInfo("Courier", 8);
// If this method is not called, then the default initial value "(1, 1)" is used.
docMerger.setPageNumberValue(1, 1);
// Merge PDF Documents and generates new PDF Document
docMerger.mergePDFDocs();
docMerger = null;
return true;
}
catch(Exception exc)
{
exc.printStackTrace();
return false;
}
}
Some documents that are in a draft phase require that a watermark indicating "DRAFT" be displayed throughout the document. Other documents might require a background image on the document. The following code sample shows how to use the PDFDocMerger class to set a watermark.
Use the SetTextDefaultWatermark( ) method to set a text watermark with the following attributes:
Text angle (in degrees): 55
Color: light gray (0.9, 0.9, 0.9)
Font: Helvetica
Font Size: 100
The start position is calculated based on the length of the text
Alternatively, use the SetTextWatermark( ) method to set each attribute separately. Use the SetTextWatermark() method as follows:
SetTextWatermark ("Watermark Text", x, y) - declare the watermark text, and set the x and y coordinates of the start position. In the following example, the watermark text is "Draft" and the coordinates are 200f, 200f.
setTextWatermarkAngle (n) - sets the angle of the watermark text. If this method is not called, 0 will be used.
setTextWatermarkColor (R, G, B) - sets the RGB color. If this method is not called, light gray (0.9, 0.9, 0.9) will be used.
setTextWatermarkFont ("font name", font size) - sets the font and size. If you do not call this method, Helvetica, 100 will be used.
The following example shows how to set these properties and then call the PDFDocMerger.
Input:
PDF Documents (InputStream)
Output:
PDF Document (OutputStream)
import java.io.*;
import oracle.xdo.common.pdf.util.PDFDocMerger;
.
.
.
public boolean mergeDocs(InputStream inputStreams, OutputStream outputStream)
{
try
{
// Initialize PDFDocMerger
PDFDocMerger docMerger = new PDFDocMerger(inputStreams, outputStream);
// You can use setTextDefaultWatermark() without these detailed setting
docMerger.setTextWatermark("DRAFT", 200f, 200f); //set text and place
docMerger.setTextWatermarkAngle(80); //set angle
docMerger.setTextWatermarkColor(1.0f, 0.3f, 0.5f); // set RGB Color
// Merge PDF Documents and generates new PDF Document
docMerger.mergePDFDocs();
docMerger = null;
return true;
}
catch(Exception exc)
{
exc.printStackTrace();
return false;
}
}
An image watermark can be set to cover the entire background of a document, or just to cover a specific area (for example, to display a logo). Specify the placement and size of the image using rectangular coordinates as follows:
float[ ] rct = {LowerLeft X, LowerLeft Y, UpperRight X, UpperRight Y}
For example:
float[ ] rct = {100f, 100f, 200f, 200f}
The image will be sized to fit the rectangular area defined.
To use the actual image size, without sizing it, define the LowerLeft X and LowerLeft Y positions to define the placement and specify the UpperRight X and UpperRight Y coordinates as -1f. For example:
float[ ] rct = {100f, 100f, -1f, -1f}
Input:
PDF Documents (InputStream)
Image File (InputStream)
Output:
PDF Document (OutputStream)
import java.io.*;
import oracle.xdo.common.pdf.util.PDFDocMerger;
.
.
.
public boolean mergeDocs(InputStream inputStreams, OutputStream outputStream, String imageFilePath)
{
try
{
// Initialize PDFDocMerger
PDFDocMerger docMerger = new PDFDocMerger(inputStreams, outputStream);
FileInputStream wmStream = new FileInputStream(imageFilePath);
float[] rct = {100f, 100f, -1f, -1f};
pdfMerger.setImageWatermark(wmStream, rct);
// Merge PDF Documents and generates new PDF Document
docMerger.mergePDFDocs();
docMerger = null;
// Closes inputStreams
return true;
}
catch(Exception exc)
{
exc.printStackTrace();
return false;
}
}
The PDFBookBinder processor is useful for the merging of multiple PDF documents into a single document consisting of a hierarchy of chapters, sections, and subsections and a table of contents for the document. The processor also generates PDF style “bookmarks”; the outline structure is determined by the chapter and section hierarchy. The processor is extremely powerful allowing you complete control over the combined document.
The table of contents formatting and style is created through the use of an RTF template created in Microsoft Word. The chapters are passed into the program as separate PDF files (one chapter, section, or subsection corresponds to one PDF file). Templates may also be specified at the chapter level for insertion of dynamic or static content, page numbering, and placement of hyperlinks within the document.
The templates can be in RTF or PDF format. RTF templates are more flexible by allowing you to leverage BI Publisher's support for dynamic content. PDF templates are much less flexible, making it difficult to achieve desirable effects such as the reflow of text areas when inserting page numbers and other types of dynamic content.
The templates can be rotated (at right angles) or be made transparent. A PDF template can also be specified at the book level, enabling the ability to specify global page numbering, or other content such as backgrounds and watermarks. A title page can also be passed in as a parameter, as well as cover and closing pages for each chapter or section.
The structure of the book’s chapters, sections, and subsections is represented as XML and passed in as a command line parameter; or it can also be passed in at the API level. All of the chapter and section files, as well as all the templates files and their respective parameters, are specified inside this XML structure. Therefore, the only two required parameters are an XML file and a PDF output file.
You can also specify volume breaks inside the book structure. Specifying volume breaks will split the content up into separate output files for easier file and printer management.
The structure of the XML control file is represented in the following diagram:
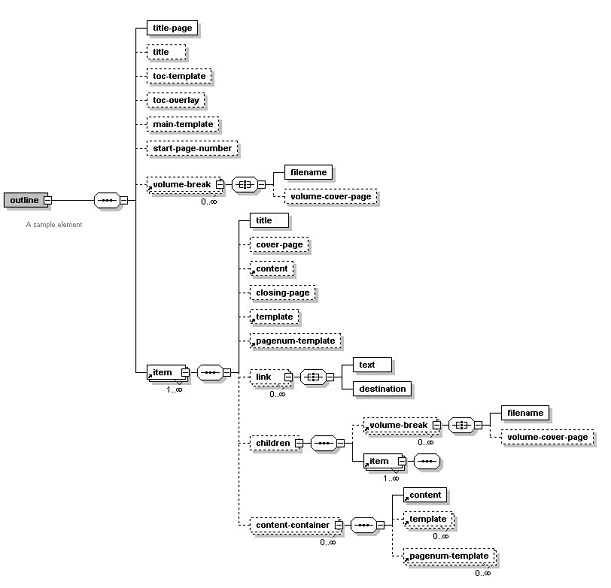
To specify template and content file locations in your XML structure, you can specify a path relative to your local file system or you can specify a URL referring to the template or content location. Secure HTTP protocol is supported, as well as specially recognized BI Publisher protocols, such as:
xdoxsl:/// used to load subtemplate.
“xdo://” - used to load other resources such as images.
Following is an example of the command line usage:
java oracle.xdo.template.pdf.book.PDFBookBinder [-debug <true or false>] [-tmp <temp dir>] -xml <input xml> -pdf <output pdf>where
-xml <file> is the file name of the input XML file containing the table of contents XML structure.
-pdf <file> is the final generated PDF output file.
-tmp <directory> is the temporary directory for better memory management. (This is optional, if not specified, the system environment variable “java.io.tmpdir” will be used.)
-log <file> sets the output log file (optional, default is System.out).
-debug <true or false> turns debugging off or on.
The following is an example of an API method call:
String xmlInputPath = “c:\\tmp\\toc.xml”;
String pdfOutputPath = “c:\\tmp\\final_book.pdf”;
PDFBookBinder bookBinder = new PDFBookBinder(xmlInputPath,
pdfOutputPath);
bookBinder.setConfig(new Properties());
bookBinder.process();
The Document Processor Engine provides batch processing functionality to access a single API or multiple APIs by passing a single XML instance document to specify template names, data sources, languages, output type, output names, and destinations.
This solution enables batch printing with BI Publisher, in which a single XML document can be used to define a set of invoices for customers, including the preferred output format and delivery channel for those customers. The XML format is very flexible allowing multiple documents to be created or a single master document.
This section:
Describes the hierarchy and elements of the Document Processor XML file
Provides sample XML files to demonstrate specific processing options
Provides example code to invoke the processors
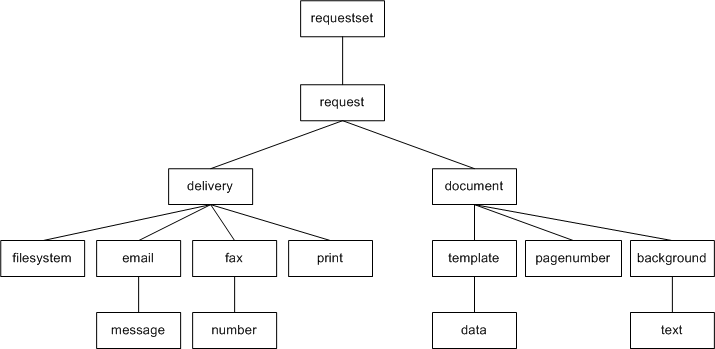
The Document Processor XML file has the following element hierarchy:
Requestset
request
delivery
filesystem
print
fax
number
email
message
document
background
text
pagenumber
template
dataThis hierarchy is displayed in the following illustration:
The following table describes each of the elements:
| Element | Attributes | Description |
|---|---|---|
| requestset | xmlns version | Root element must contain [xmlns:xapi="http://xmlns.oracle.com/oxp/xapi/"] block The version is not required, but defaults to "1.0". |
| request | N/A | Element that contains the data and template processing definitions. |
| delivery | N/A | Defines where the generated output is sent. |
| document | output-type | Specify one output that can have several template elements. The output-type attribute is optional. Valid values are: pdf (Default) rtf html excel text |
| filesystem | output | Specify this element to save the output to the file system. Define the directory path in the output attribute. |
| The print element can occur multiple times under delivery to print one document to several printers. Specify the printer attribute as a URI, such as:"ipp://myprintserver:631/printers/printername" | |
| fax |
| Specify a URI in the server attribute, for example: "ipp://myfaxserver1:631/printers/myfaxmachine" |
| number | The number element can occur multiple times to list multiple fax numbers. Each element occurrence must contain only one number. | |
| Specify the outgoing mail server (SMTP) in the server attribute. Specify the mail server port in the port attribute. | |
| message |
| The message element can be placed several times under the email element. You can specify character data in the message element. You can specify multiple e-mail addresses in the to, cc and bcc attributes separated by a comma. The attachment value is either true or false (default). If attachment is true, then a generated document will be attached when the e-mail is sent. The subject attribute is optional. |
| background | where | If the background text is required on a specific page, then set the where value to the page numbers required. The page index starts at 1. The default value is 0, which places the background on all pages. |
| text |
| Specify the watermark text in the title value. A default value of "yes" automatically draws the watermark with forward slash type. The default value is yes. |
| pagenumber |
| The initial-page-index default value is 0. The initial-value default value is 1. "Helvetica" is used for the page number font. The x-pos provides lower left x position. The y-pos provides lower left y position. |
| template |
| Contains template information. Valid values for the type attribute are rtf xsl-fo etext The default value is "pdf". |
| data | location | Define the location attribute to specify the location of the data, or attach the actual XML data with subelements. The default value of location is "inline". It the location points to either an XML file or a URL, then the data should contain an XML declaration with the proper encoding. If the location attribute is not specified, the data element should contain the subelements for the actual data. This must not include an XML declaration. |
Following are sample XML files that show:
Simple XML shape
Defining two data sets
Defining multiple templates and data
Retrieving templates over HTTP
Retrieving data over HTTP
Generating more than one output
Defining page numbers
The following example shows how to define two data sources to merge with one template to produce one output file delivered to the file system:
<?xml version="1.0" encoding="UTF-8"?>
<xapi:requestset xmlns:xapi="http://xmlns.oracle.com/oxp/xapi">
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\tmp\outfile.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:template type="pdf"
location="d:\mywork\template1.pdf">
<xapi:data>
<field1>The first set of data</field1>
</xapi:data>
<xapi:data>
<field1>The second set of data</field1>
</xapi:data>
</xapi:template>
</xapi:document>
</xapi:request>
</xapi:requestset>The following example builds on the previous examples by applying two data sources to one template and two data sources to a second template, and then merging the two into a single output file. Note that when merging documents, the output-type must be "pdf".
<?xml version="1.0" encoding="UTF-8"?>
<xapi:requestset xmlns:xapi="http://xmlns.oracle.com/oxp/xapi">
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\tmp\outfile3.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:template type="pdf"
location="d:\mywork\template1.pdf">
<xapi:data>
<field1>The first set of data</field1>
</xapi:data>
<xapi:data>
<field1>The second set of data</field1>
</xapi:data>
</xapi:template>
<xapi:template type="pdf"
location="d:\mywork\template2.pdf">
<xapi:data>
<field1>The third set of data</field1>
</xapi:data>
<xapi:data>
<field1>The fourth set of data</field1>
</xapi:data>
</xapi:template>
</xapi:document>
</xapi:request>
</xapi:requestset>This sample is identical to the previous example, except in this case the two templates are retrieved over HTTP:
<?xml version="1.0" encoding="UTF-8"?>
<xapi:requestset xmlns:xapi="http://xmlns.oracle.com/oxp/xapi">
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\temp\out4.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:template type="pdf"
location="http://your.server:9999/templates/template1.pdf">
<xapi:data>
<field1>The first page data</field1>
</xapi:data>
<xapi:data>
<field1>The second page data</field1>
</xapi:data>
</xapi:template>
<xapi:template type="pdf"
location="http://your.server:9999/templates/template2.pdf">
<xapi:data>
<field1>The third page data</field1>
</xapi:data>
<xapi:data>
<field1>The fourth page data</field1>
</xapi:data>
</xapi:template>
</xapi:document>
</xapi:request>
</xapi:requestset>This sample builds on the previous example and shows one template with two data sources, all retrieved via HTTP; and a second template retrieved via HTTP with its two data sources embedded in the XML:
<?xml version="1.0" encoding="UTF-8"?>
<xapi:requestset xmlns:xapi="http://xmlns.oracle.com/oxp/xapi">
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\temp\out5.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:template type="pdf"
location="http://your.server:9999/templates/template1.pdf">
<xapi:data location="http://your.server:9999/data/data_1.xml"/>
<xapi:data location="http://your.server:9999/data/data_2.xml"/>
</xapi:template>
<xapi:template type="pdf"
location="http://your.server:9999/templates/template2.pdf">
<xapi:data>
<field1>The third page data</field1>
</xapi:data>
<xapi:data>
<field1>The fourth page data</field1>
</xapi:data>
</xapi:template>
</xapi:document>
</xapi:request>
</xapi:requestset>The following sample shows the generation of two outputs: out_1.pdf and out_2.pdf. Note that a request element is defined for each output.
<?xml version="1.0" encoding="UTF-8"?>
<xapi:requestset xmlns:xapi="http://xmlns.oracle.com/oxp/xapi">
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\temp\out_1.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:template type="pdf"
location="d:\mywork\template1.pdf">
<xapi:data>
<field1>The first set of data</field1>
</xapi:data>
<xapi:data>
<field1>The second set of data</field1>
</xapi:data>
</xapi:template>
</xapi:document>
</xapi:request>
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\temp\out_2.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:template type="pdf"
location="d:mywork\template2.pdf">
<xapi:data>
<field1>The third set of data</field1>
</xapi:data>
<xapi:data>
<field1>The fourth set of data</field1>
</xapi:data>
</xapi:template>
</xapi:document>
</xapi:request>
</xapi:requestset>The following sample shows the use of the pagenumber element to define page numbers on a PDF output document. The first document that is generated will begin with an initial page number value of 1. The second output document will begin with an initial page number value of 3. The pagenumber element can reside anywhere within the document element tags.
Note that page numbering that is applied using the pagenumber element will not replace page numbers that are defined in the template.
<?xml version="1.0" encoding="UTF-8"?>
<xapi:requestset xmlns:xapi="http://xmlns.oracle.com/oxp/xapi">
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\temp\out7-1.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:pagenumber initial-value="1" initial-page-index="1"
x-pos="300" y-pos="20" />
<xapi:template type="pdf"
location="d:\mywork\template1.pdf">
<xapi:data>
<field1>The first page data</field1>
</xapi:data>
<xapi:data>
<field1>The second page data</field1>
</xapi:data>
</xapi:template>
</xapi:document>
</xapi:request>
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\temp\out7-2.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:template type="pdf"
location="d:\mywork\template2.pdf">
<xapi:data>
<field1>The third page data</field1>
</xapi:data>
<xapi:data>
<field1>The fourth page data</field1>
</xapi:data>
</xapi:template>
<xapi:pagenumber initial-value="3" initial-page-index="1"
x-pos="300" y-pos="20" />
</xapi:document>
</xapi:request>
</xapi:requestset>The following code samples show how to invoke the document processor engine using an input file name and an input stream.
Input:
Data file name (String)
Directory for Temporary Files (String)
import oracle.xdo.batch.DocumentProcessor;
.
.
.
public static void main(String[] args)
{
.
.
.
try
{
// dataFile --- File path of the Document Processor XML
// tempDir --- Temporary Directory path
DocumentProcessor docProcessor = new DocumentProcessor(dataFile, tempDir);
docProcessor.process();
}
catch(Exception e)
{
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
Input:
Data file (InputStream)
Directory for Temporary Files (String)
import oracle.xdo.batch.DocumentProcessor;
import java.io.InputStream;
.
.
.
public static void main(String[] args)
{
.
.
.
try
{
// dataFile --- File path of the Document Processor XML
// tempDir --- Temporary Directory path
FileInputStream fIs = new FileInputStream(dataFile);
DocumentProcessor docProcessor = new DocumentProcessor(fIs, tempDir);
docProcessor.process();
fIs.close();
}
catch(Exception e)
{
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
The FO Processor supports PDF security and other properties that can be applied to your final documents. Security properties include making a document unprintable and applying password security to an encrypted document.
Other properties allow you to define font subsetting and embedding. If your template uses a font that would not normally be available to BI Publisher at runtime, you can use the font properties to specify the location of the font. At runtime BI Publisher will retrieve and use the font in the final document. For example, this property might be used for check printing for which a MICR font is used to generate the account and routing numbers on the checks.
See Setting Runtime Properties for the full list of properties.
The properties can be set in two ways:
At runtime, specify the property as a Java Property object to pass to the FO Processor.
Set the property in a configuration file.
Set the property in the template (RTF templates only). See Setting Properties, Oracle Fusion Middleware Report Designer's Guide for Business Intelligence Publisher in the RTF template for this method.
To pass a property as a Property object, set the name/value pair for the property prior to calling the FO Processor, as shown in the following example:
Input:
XML file name (String)
XSL file name (String)
Output:
PDF file name (String)
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args)
{
FOProcessor processor = new FOProcessor();
processor.setData(args[0]); // set XML input file
processor.setTemplate(args[1]); // set XSL input file
processor.setOutput(args[2]); //set (PDF) output file
processor.setOutputFormat(FOProcessor.FORMAT_PDF);
Properties prop = new Properties();
/* PDF Security control: */
prop.put("pdf-security", "true");
/* Permissions password: */
prop.put("pdf-permissions-password", "abc");
/* Encryption level: */
prop.put("pdf-encription-level", "0");
processor.setConfig(prop);
// Start processing
try
{
processor.generate();
}
catch (XDOException e)
{
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
The following code shows an example of passing the location of a configuration file.
Input:
XML file name (String)
XSL file name (String)
Output:
PDF file name (String)
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args)
{
FOProcessor processor = new FOProcessor();
processor.setData(args[0]); // set XML input file
processor.setTemplate(args[1]); // set XSL input file
processor.setOutput(args[2]); //set (PDF) output file
processor.setOutputFormat(FOProcessor.FORMAT_PDF);
processor.setConfig(“/tmp/xmlpconfig.xml”);
// Start processing
try
{
processor.generate();
} catch (XDOException e)
{ e.printStackTrace();
System.exit(1);
}
System.exit(0);
}Input:
Data file name (String)
Directory for Temporary Files (String)
Output:
PDF FIle
import oracle.xdo.batch.DocumentProcessor;
.
.
.
public static void main(String[] args)
{
.
.
.
try
{
// dataFile --- File path of the Document Processor XML
// tempDir --- Temporary Directory path
DocumentProcessor docProcessor = new DocumentProcessor(dataFile, tempDir);
Properties prop = new Properties();
/* PDF Security control: */
prop.put("pdf-security", "true");
/* Permissions password: */
prop.put("pdf-permissions-password", "abc");
/* encryption level: */
prop.put("pdf-encription-level", "0");
processor.setConfig(prop);
docProcessor.process();
}
catch(Exception e)
{
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
For the advanced formatting to work in the template, you must provide a Java class with the appropriate methods to format the data at runtime. Many font vendors offer the code with their fonts to carry out the formatting; these must be incorporated as methods into a class that is available to the BI Publisher formatting libraries at runtime. There are some specific interfaces that you must provide in the class for the library to call the correct method for encoding.
If you use one of the three barcodes provided with BI Publisher, you do not need to provide the Java class. For more information see "Using the Barcode Fonts Shipped with BI Publisher" in the Oracle Fusion Middleware Report Designer's Guide for Oracle Business Intelligence Publisher.
Note: See Advanced Barcode Formatting, Oracle Fusion Middleware Report Designer's Guide for Business Intelligence Publisher for the setup required in the RTF template.
You must implement the following three methods in this class:
/**
* Return a unique ID for this barcode encoder
* @return the id as a string
*/
public String getVendorID();
/**
* Return true if this encoder support a specific type of barcode
* @param type the type of the barcode
* @return true if supported
*/
public boolean isSupported(String type);
/**
* Encode a barcode string by given a specific type
* @param data the original data for the barcode
* @param type the type of the barcode
* @return the formatted data
*/
public String encode(String data, String type);
Place this class in the classpath for the middle tier JVM in which BI Publisher is running.
Note: For E-Business Suite users, the class must be placed in the classpath for the middle tier and any concurrent nodes that are present.
If in the register-barcode-vendor command the barcode_vendor_id is not provided, BI Publisher will call the getVendorID() and use the result of the method as the ID for the vendor.
The following is an example class that supports the code128 a, b and c encodings:
Important: The following code sample can be copied and pasted for use in your system. Note that due to publishing constraints you will need to correct line breaks and ensure that you delete quotes that display as "smart quotes" and replace them with simple quotes.
package oracle.xdo.template.rtf.util.barcoder;
import java.util.Hashtable;
import java.lang.reflect.Method;
import oracle.xdo.template.rtf.util.XDOBarcodeEncoder;
import oracle.xdo.common.log.Logger;
// This class name will be used in the register vendor
// field in the template.
public class BarcodeUtil implements XDOBarcodeEncoder
// The class implements the XDOBarcodeEncoder interface
{
// This is the barcode vendor id that is used in the
// register vendor field and format-barcode fields
public static final String BARCODE_VENDOR_ID = "XMLPBarVendor";
// The hashtable is used to store references to
// the encoding methods
public static final Hashtable ENCODERS = new Hashtable(10);
// The BarcodeUtil class needs to be instantiated
public static final BarcodeUtil mUtility = new BarcodeUtil();
// This is the main code that is executed in the class,
// it is loading the methods for the encoding into the hashtable.
// In this case we are loading the three code128 encoding
// methods we have created.
static {
try {
Class[] clazz = new Class[] { "".getClass() };
ENCODERS.put("code128a",mUtility.getClass().getMethod("code128a", clazz));
ENCODERS.put("code128b",mUtility.getClass().getMethod("code128b", clazz));
ENCODERS.put("code128c",mUtility.getClass().getMethod("code128c", clazz));
} catch (Exception e) {
// This is using the BI Publisher logging class to push
// errors to the XMLP log file.
Logger.log(e,5);
}
}// The getVendorID method is called from the template layer
// at runtime to ensure the correct encoding method are used
public final String getVendorID()
{
return BARCODE_VENDOR_ID;
}
//The isSupported method is called to ensure that the
// encoding method called from the template is actually
// present in this class.
// If not then XMLP will report this in the log.
public final boolean isSupported(String s)
{
if(s != null)
return ENCODERS.containsKey(s.trim().toLowerCase());
else
return false;
}
// The encode method is called to then call the appropriate
// encoding method, in this example the code128a/b/c methods.
public final String encode(String s, String s1)
{
if(s != null && s1 != null)
{
try
{
Method method = (Method)ENCODERS.get(s1.trim().toLowerCase());
if(method != null)
return (String)method.invoke(this, new Object[] {
s
});
else
return s;
}
catch(Exception exception)
{
Logger.log(exception,5);
}
return s;
} else
{
return s;
}
}
/** This is the complete method for Code128a */
public static final String code128a( String DataToEncode )
{
char C128_Start = (char)203;
char C128_Stop = (char)206;
String Printable_string = "";
char CurrentChar;
int CurrentValue=0;
int weightedTotal=0;
int CheckDigitValue=0;
char C128_CheckDigit='w';
DataToEncode = DataToEncode.trim();
weightedTotal = ((int)C128_Start) - 100;
for( int i = 1; i <= DataToEncode.length(); i++ )
{
//get the value of each character
CurrentChar = DataToEncode.charAt(i-1);
if( ((int)CurrentChar) < 135 )
CurrentValue = ((int)CurrentChar) - 32;
if( ((int)CurrentChar) > 134 )
CurrentValue = ((int)CurrentChar) - 100;
CurrentValue = CurrentValue * i;
weightedTotal = weightedTotal + CurrentValue;
}
//divide the WeightedTotal by 103 and get the remainder,
//this is the CheckDigitValue
CheckDigitValue = weightedTotal % 103;
if( (CheckDigitValue < 95) && (CheckDigitValue > 0) )
C128_CheckDigit = (char)(CheckDigitValue + 32);
if( CheckDigitValue > 94 )
C128_CheckDigit = (char)(CheckDigitValue + 100);
if( CheckDigitValue == 0 ){
C128_CheckDigit = (char)194;
}
Printable_string = C128_Start + DataToEncode + C128_CheckDigit + C128_Stop + " ";
return Printable_string;
}/** This is the complete method for Code128b ***/
public static final String code128b( String DataToEncode )
{
char C128_Start = (char)204;
char C128_Stop = (char)206;
String Printable_string = "";
char CurrentChar;
int CurrentValue=0;
int weightedTotal=0;
int CheckDigitValue=0;
char C128_CheckDigit='w';
DataToEncode = DataToEncode.trim();
weightedTotal = ((int)C128_Start) - 100;
for( int i = 1; i <= DataToEncode.length(); i++ )
{
//get the value of each character
CurrentChar = DataToEncode.charAt(i-1);
if( ((int)CurrentChar) < 135 )
CurrentValue = ((int)CurrentChar) - 32;
if( ((int)CurrentChar) > 134 )
CurrentValue = ((int)CurrentChar) - 100;
CurrentValue = CurrentValue * i;
weightedTotal = weightedTotal + CurrentValue;
}
//divide the WeightedTotal by 103 and get the remainder,
//this is the CheckDigitValue
CheckDigitValue = weightedTotal % 103;
if( (CheckDigitValue < 95) && (CheckDigitValue > 0) )
C128_CheckDigit = (char)(CheckDigitValue + 32);
if( CheckDigitValue > 94 )
C128_CheckDigit = (char)(CheckDigitValue + 100);
if( CheckDigitValue == 0 ){
C128_CheckDigit = (char)194;
}
Printable_string = C128_Start + DataToEncode + C128_CheckDigit + C128_Stop + " ";
return Printable_string;
}
/** This is the complete method for Code128c **/
public static final String code128c( String s )
{
char C128_Start = (char)205;
char C128_Stop = (char)206;
String Printable_string = "";
String DataToPrint = "";
String OnlyCorrectData = "";
int i=1;
int CurrentChar=0;
int CurrentValue=0;
int weightedTotal=0;
int CheckDigitValue=0;
char C128_CheckDigit='w';
DataToPrint = "";
s = s.trim();
for(i = 1; i <= s.length(); i++ )
{
//Add only numbers to OnlyCorrectData string
CurrentChar = (int)s.charAt(i-1);
if((CurrentChar < 58) && (CurrentChar > 47))
{
OnlyCorrectData = OnlyCorrectData + (char)s.charAt(i-1);
}
}
s = OnlyCorrectData;
//Check for an even number of digits, add 0 if not even
if( (s.length() % 2) == 1 )
{
s = "0" + s;
}
//<<<< Calculate Modulo 103 Check Digit and generate
// DataToPrint >>>>
//Set WeightedTotal to the Code 128 value of
// the start character
weightedTotal = ((int)C128_Start) - 100;
int WeightValue = 1;
for( i = 1; i <= s.length(); i += 2 )
{
//Get the value of each number pair (ex: 5 and 6 = 5*10+6 =56)
//And assign the ASCII values to DataToPrint
CurrentChar = ((((int)s.charAt(i-1))-48)*10) + (((int)s.charAt(i))-48);
if((CurrentChar < 95) && (CurrentChar > 0))
DataToPrint = DataToPrint + (char)(CurrentChar + 32);
if( CurrentChar > 94 )
DataToPrint = DataToPrint + (char)(CurrentChar + 100);
if( CurrentChar == 0)
DataToPrint = DataToPrint + (char)194;
//multiply by the weighting character
//add the values together to get the weighted total
weightedTotal = weightedTotal + (CurrentChar * WeightValue);
WeightValue = WeightValue + 1;
}
//divide the WeightedTotal by 103 and get the remainder,
//this is the CheckDigitValue
CheckDigitValue = weightedTotal % 103;
if((CheckDigitValue < 95) && (CheckDigitValue > 0))
C128_CheckDigit = (char)(CheckDigitValue + 32);
if( CheckDigitValue > 94 )
C128_CheckDigit = (char)(CheckDigitValue + 100);
if( CheckDigitValue == 0 ){
C128_CheckDigit = (char)194;
}
Printable_string = C128_Start + DataToPrint + C128_CheckDigit + C128_Stop + " ";
Logger.log(Printable_string,5);
return Printable_string;
}
}Once you create the class and place it in the correct classpath, your template creators can start using it to format the data for barcodes. You must give them the following information to include in the template commands:
The class name and path.
In this example:
oracle.xdo.template.rtf.util.barcoder.BarcodeUtil
The barcode vendor ID you created.
In this example: XMLPBarVendor
The available encoding methods.
In this example, code128a, code128b and code128c They can then use this information to successfully encode their data for barcode output.
They can then use this information to successfully encode their data for barcode output.
![]()
Copyright © 2004, 2010, Oracle and/or its affiliates. All rights reserved.