
RHCSA Series: Reviewing Essential Commands & System Documentation – Part 1
RHCSA (Red Hat Certified System Administrator) is a certification exam from Red Hat company, which provides an open source operating system and software to the enterprise community, It also provides support, training and consulting services for the organizations.

RHCSA Exam Preparation Guide
RHCSA exam is the certification obtained from Red Hat Inc, after passing the exam (codename EX200). RHCSA exam is an upgrade to the RHCT (Red Hat Certified Technician) exam, and this upgrade is compulsory as the Red Hat Enterprise Linux was upgraded. The main variation between RHCT and RHCSA is that RHCT exam based on RHEL 5, whereas RHCSA certification is based on RHEL 6 and 7, the courseware of these two certifications are also vary to a certain level.
This Red Hat Certified System Administrator (RHCSA) is essential to perform the following core system administration tasks needed in Red Hat Enterprise Linux environments:
- Understand and use necessary tools for handling files, directories, command-environments line, and system-wide / packages documentation.
- Operate running systems, even in different run levels, identify and control processes, start and stop virtual machines.
- Set up local storage using partitions and logical volumes.
- Create and configure local and network file systems and its attributes (permissions, encryption, and ACLs).
- Setup, configure, and control systems, including installing, updating and removing software.
- Manage system users and groups, along with use of a centralized LDAP directory for authentication.
- Ensure system security, including basic firewall and SELinux configuration.
To view fees and register for an exam in your country, check the RHCSA Certification page.
In this 15-article RHCSA series, titled Preparation for the RHCSA (Red Hat Certified System Administrator) exam, we will going to cover the following topics on the latest releases of Red Hat Enterprise Linux 7.
In this Part 1 of the RHCSA series, we will explain how to enter and execute commands with the correct syntax in a shell prompt or terminal, and explained how to find, inspect, and use system documentation.

RHCSA: Reviewing Essential Linux Commands – Part 1
Prerequisites:
At least a slight degree of familiarity with basic Linux commands such as:
- cd command (change directory)
- ls command (list directory)
- cp command (copy files)
- mv command (move or rename files)
- touch command (create empty files or update the timestamp of existing ones)
- rm command (delete files)
- mkdir command (make directory)
The correct usage of some of them are anyway exemplified in this article, and you can find further information about each of them using the suggested methods in this article.
Though not strictly required to start, as we will be discussing general commands and methods for information search in a Linux system, you should try to install RHEL 7 as explained in the following article. It will make things easier down the road.
Interacting with the Linux Shell
If we log into a Linux box using a text-mode login screen, chances are we will be dropped directly into our default shell. On the other hand, if we login using a graphical user interface (GUI), we will have to open a shell manually by starting a terminal. Either way, we will be presented with the user prompt and we can start typing and executing commands (a command is executed by pressing the Enter key after we have typed it).
Commands are composed of two parts:
- the name of the command itself, and
- arguments
Certain arguments, called options (usually preceded by a hyphen), alter the behavior of the command in a particular way while other arguments specify the objects upon which the command operates.
The type command can help us identify whether another certain command is built into the shell or if it is provided by a separate package. The need to make this distinction lies in the place where we will find more information about the command. For shell built-ins we need to look in the shell’s man page, whereas for other binaries we can refer to its own man page.
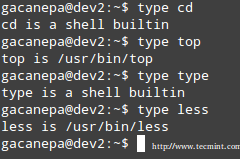
Check Shell built in Commands
In the examples above, cd and type are shell built-ins, while top and less are binaries external to the shell itself (in this case, the location of the command executable is returned by type).
Other well-known shell built-ins include:
- echo command: Displays strings of text.
- pwd command: Prints the current working directory.

More Built in Shell Commands
exec command
Runs an external program that we specify. Note that in most cases, this is better accomplished by just typing the name of the program we want to run, but the exec command has one special feature: rather than create a new process that runs alongside the shell, the new process replaces the shell, as can verified by subsequent.
# ps -ef | grep [original PID of the shell process]
When the new process terminates, the shell terminates with it. Run exec top and then hit the q key to quit top. You will notice that the shell session ends when you do, as shown in the following screencast:
export command
Exports variables to the environment of subsequently executed commands.
history Command
Displays the command history list with line numbers. A command in the history list can be repeated by typing the command number preceded by an exclamation sign. If we need to edit a command in history list before executing it, we can press Ctrl + r and start typing the first letters associated with the command. When we see the command completed automatically, we can edit it as per our current need:
This list of commands is kept in our home directory in a file called .bash_history. The history facility is a useful resource for reducing the amount of typing, especially when combined with command line editing. By default, bash stores the last 500 commands you have entered, but this limit can be extended by using the HISTSIZEenvironment variable:

Linux history Command
But this change as performed above, will not be persistent on our next boot. In order to preserve the change in the HISTSIZE variable, we need to edit the .bashrc file by hand:
# for setting history length see HISTSIZE and HISTFILESIZE in bash(1) HISTSIZE=1000
Important: Keep in mind that these changes will not take effect until we restart our shell session.
alias command
With no arguments or with the -p option prints the list of aliases in the form alias name=value on standard output. When arguments are provided, an alias is defined for each name whose value is given.
With alias, we can make up our own commands or modify existing ones by including desired options. For example, suppose we want to alias ls to ls –color=auto so that the output will display regular files, directories, symlinks, and so on, in different colors:
# alias ls='ls --color=auto'
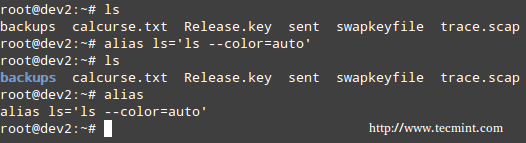
Linux alias Command
Note: That you can assign any name to your “new command” and enclose as many commands as desired between single quotes, but in that case you need to separate them by semicolons, as follows:
# alias myNewCommand='cd /usr/bin; ls; cd; clear'
exit command
The exit and logout commands both terminate the shell. The exit command terminates any shell, but the logoutcommand terminates only login shells—that is, those that are launched automatically when you initiate a text-mode login.
If we are ever in doubt as to what a program does, we can refer to its man page, which can be invoked using the man command. In addition, there are also man pages for important files (inittab, fstab, hosts, to name a few), library functions, shells, devices, and other features.
Examples:
- man uname (print system information, such as kernel name, processor, operating system type, architecture, and so on).
- man inittab (init daemon configuration).
Another important source of information is provided by the info command, which is used to read info documents. These documents often provide more information than the man page. It is invoked by using the info keyword followed by a command name, such as:
# info ls # info cut
In addition, the /usr/share/doc directory contains several subdirectories where further documentation can be found. They either contain plain-text files or other friendly formats.
Make sure you make it a habit to use these three methods to look up information for commands. Pay special and careful attention to the syntax of each of them, which is explained in detail in the documentation.
Converting Tabs into Spaces with expand Command
Sometimes text files contain tabs but programs that need to process the files don’t cope well with tabs. Or maybe we just want to convert tabs into spaces. That’s where the expand tool (provided by the GNU coreutils package) comes in handy.
For example, given the file NumbersList.txt, let’s run expand against it, changing tabs to one space, and display on standard output.
# expand --tabs=1 NumbersList.txt

Linux expand Command
The unexpand command performs the reverse operation (converts spaces into tabs).
Display the first lines of a file with head and the last lines with tail
By default, the head command followed by a filename, will display the first 10 lines of the said file. This behavior can be changed using the -n option and specifying a certain number of lines.
# head -n3 /etc/passwd # tail -n3 /etc/passwd

Linux head and tail Command
One of the most interesting features of tail is the possibility of displaying data (last lines) as the input file grows (tail -f my.log, where my.log is the file under observation). This is particularly useful when monitoring a log to which data is being continually added.
Read More: Manage Files Effectively using head and tail Commands
Merging Lines with paste
The paste command merges files line by line, separating the lines from each file with tabs (by default), or another delimiter that can be specified (in the following example the fields in the output are separated by an equal sign).
# paste -d= file1 file2
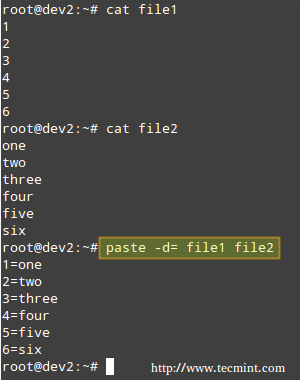
Merge Files in Linux
Breaking a file into pieces using split command
The split command is used split a file into two (or more) separate files, which are named according to a prefix of our choosing. The splitting can be defined by size, chunks, or number of lines, and the resulting files can have a numeric or alphabetic suffixes. In the following example, we will split bash.pdf into files of size 50 KB (-b 50KB), using numeric suffixes (-d):
# split -b 50KB -d bash.pdf bash_

Split Files in Linux
You can merge the files to recreate the original file with the following command:
# cat bash_00 bash_01 bash_02 bash_03 bash_04 bash_05 > bash.pdf
Translating characters with tr command
The tr command can be used to translate (change) characters on a one-by-one basis or using character ranges. In the following example we will use the same file2 as previously, and we will change:
- lowercase o’s to uppercase,
- and all lowercase to uppercase
# cat file2 | tr o O # cat file2 | tr [a-z] [A-Z]
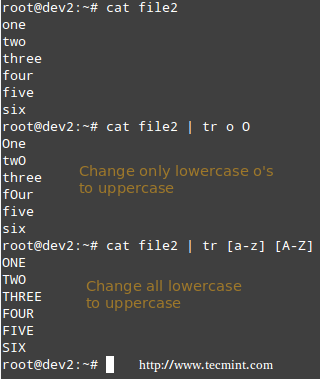
Translate Characters in Linux
Reporting or deleting duplicate lines with uniq and sort command
The uniq command allows us to report or remove duplicate lines in a file, writing to stdout by default. We must note that uniq does not detect repeated lines unless they are adjacent. Thus, uniq is commonly used along with a preceding sort (which is used to sort lines of text files).
By default, sort takes the first field (separated by spaces) as key field. To specify a different key field, we need to use the -k option. Please note how the output returned by sort and uniq change as we change the key field in the following example:
# cat file3 # sort file3 | uniq # sort -k2 file3 | uniq # sort -k3 file3 | uniq

Remove Duplicate Lines in Linux
Extracting text with cut command
The cut command extracts portions of input lines (from stdin or files) and displays the result on standard output, based on number of bytes (-b), characters (-c), or fields (-f).
When using cut based on fields, the default field separator is a tab, but a different separator can be specified by using the -d option.
# cut -d: -f1,3 /etc/passwd # Extract specific fields: 1 and 3 in this case # cut -d: -f2-4 /etc/passwd # Extract range of fields: 2 through 4 in this example

Extract Text From a File in Linux
Note that the output of the two examples above was truncated for brevity.
Reformatting files with fmt command
fmt is used to “clean up” files with a great amount of content or lines, or with varying degrees of indentation. The new paragraph formatting defaults to no more than 75 characters wide. You can change this with the -w (width) option, which set the line length to the specified number of characters.
For example, let’s see what happens when we use fmt to display the /etc/passwd file setting the width of each line to 100 characters. Once again, output has been truncated for brevity.
# fmt -w100 /etc/passwd

File Reformatting in Linux
Formatting content for printing with pr command
pr paginates and displays in columns one or more files for printing. In other words, pr formats a file to make it look better when printed. For example, the following command:
# ls -a /etc | pr -n --columns=3 -h "Files in /etc"
Shows a listing of all the files found in /etc in a printer-friendly format (3 columns) with a custom header (indicated by the -h option), and numbered lines (-n).

File Formatting in Linux
Summary
In this article we have discussed how to enter and execute commands with the correct syntax in a shell prompt or terminal, and explained how to find, inspect, and use system documentation. As simple as it seems, it’s a large first step in your way to becoming a RHCSA.
If you would like to add other commands that you use on a periodic basis and that have proven useful to fulfill your daily responsibilities, feel free to share them with the world by using the comment form below. Questions are also welcome. We look forward to hearing from you!
RHCSA Series: How to Perform File and Directory Management – Part 2
In this article, RHCSA Part 2: File and directory management, we will review some essential skills that are required in the day-to-day tasks of a system administrator.

RHCSA: Perform File and Directory Management – Part 2
Create, Delete, Copy, and Move Files and Directories
File and directory management is a critical competence that every system administrator should possess. This includes the ability to create / delete text files from scratch (the core of each program’s configuration) and directories (where you will organize files and other directories), and to find out the type of existing files.
The touch command can be used not only to create empty files, but also to update the access and modification times of existing files.

touch command example
You can use file [filename] to determine a file’s type (this will come in handy before launching your preferred text editor to edit it).
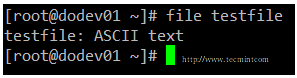
file command example
and rm [filename] to delete it.

rm command example
As for directories, you can create directories inside existing paths with mkdir [directory] or create a full path with mkdir -p [/full/path/to/directory].

mkdir command example
When it comes to removing directories, you need to make sure that they’re empty before issuing the rmdir [directory] command, or use the more powerful (handle with care!) rm -rf [directory]. This last option will force remove recursively the [directory] and all its contents – so use it at your own risk.
Input and Output Redirection and Pipelining
The command line environment provides two very useful features that allows to redirect the input and output of commands from and to files, and to send the output of a command to another, called redirection and pipelining, respectively.
To understand those two important concepts, we must first understand the three most important types of I/O (Input and Output) streams (or sequences) of characters, which are in fact special files, in the *nix sense of the word.
- Standard input (aka stdin) is by default attached to the keyboard. In other words, the keyboard is the standard input device to enter commands to the command line.
- Standard output (aka stdout) is by default attached to the screen, the device that “receives” the output of commands and display them on the screen.
- Standard error (aka stderr), is where the status messages of a command is sent to by default, which is also the screen.
In the following example, the output of ls /var is sent to stdout (the screen), as well as the result of ls /tecmint. But in the latter case, it is stderr that is shown.

Input and Output Example
To more easily identify these special files, they are each assigned a file descriptor, an abstract representation that is used to access them. The essential thing to understand is that these files, just like others, can be redirected. What this means is that you can capture the output from a file or script and send it as input to another file, command, or script. This will allow you to store on disk, for example, the output of commands for later processing or analysis.
To redirect stdin (fd 0), stdout (fd 1), or stderr (fd 2), the following operators are available.
| Redirection Operator | Effect |
| > | Redirects standard output to a file containing standard output. If the destination file exists, it will be overwritten. |
| >> | Appends standard output to a file. |
| 2> | Redirects standard error to a file containing standard output. If the destination file exists, it will be overwritten. |
| 2>> | Appends standard error to the existing file. |
| &> | Redirects both standard output and standard error to a file; if the specified file exists, it will be overwritten. |
| < | Uses the specified file as standard input. |
| <> | The specified file is used for both standard input and standard output. |
As opposed to redirection, pipelining is performed by adding a vertical bar (|) after a command and before another one.
Remember:
- Redirection is used to send the output of a command to a file, or to send a file as input to a command.
- Pipelining is used to send the output of a command to another command as input.
Examples Of Redirection and Pipelining
Example 1: Redirecting the output of a command to a file
There will be times when you will need to iterate over a list of files. To do that, you can first save that list to a file and then read that file line by line. While it is true that you can iterate over the output of ls directly, this example serves to illustrate redirection.
# ls -1 /var/mail > mail.txt
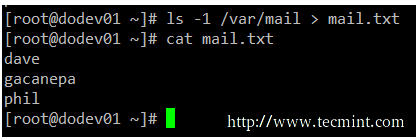
Redirect output of command tot a file
Example 2: Redirecting both stdout and stderr to /dev/null
In case we want to prevent both stdout and stderr to be displayed on the screen, we can redirect both file descriptors to /dev/null. Note how the output changes when the redirection is implemented for the same command.
# ls /var /tecmint # ls /var/ /tecmint &> /dev/null

Redirecting stdout and stderr ouput to /dev/null
Example 3: Using a file as input to a command
While the classic syntax of the cat command is as follows.
# cat [file(s)]
You can also send a file as input, using the correct redirection operator.
# cat < mail.txt
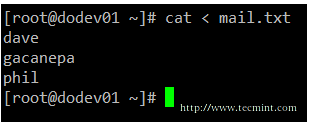
cat command example
Example 4: Sending the output of a command as input to another
If you have a large directory or process listing and want to be able to locate a certain file or process at a glance, you will want to pipeline the listing to grep.
Note that we use to pipelines in the following example. The first one looks for the required keyword, while the second one will eliminate the actual grep command from the results. This example lists all the processes associated with the apache user.
# ps -ef | grep apache | grep -v grep

Send output of command as input to another
Archiving, Compressing, Unpacking, and Uncompressing Files
If you need to transport, backup, or send via email a group of files, you will use an archiving (or grouping) tool such as tar, typically used with a compression utility like gzip, bzip2, or xz.
Your choice of a compression tool will be likely defined by the compression speed and rate of each one. Of these three compression tools, gzip is the oldest and provides the least compression, bzip2 provides improved compression, and xz is the newest and provides the best compression. Typically, files compressed with these utilities have .gz, .bz2, or .xz extensions, respectively.
| Command | Abbreviation | Description |
| –create | c | Creates a tar archive |
| –concatenate | A | Appends tar files to an archive |
| –append | r | Appends non-tar files to an archive |
| –update | u | Appends files that are newer than those in an archive |
| –diff or –compare | d | Compares an archive to files on disk |
| –list | t | Lists the contents of a tarball |
| –extract or –get | x | Extracts files from an archive |
| Operation modifier | Abbreviation | Description |
| —directory dir | C | Changes to directory dir before performing operations |
| —same-permissions and —same-owner | p | Preserves permissions and ownership information, respectively. |
| –verbose | v | Lists all files as they are read or extracted; if combined with –list, it also displays file sizes, ownership, and timestamps |
| —exclude file | — | Excludes file from the archive. In this case, file can be an actual file or a pattern. |
| —gzip or —gunzip | z | Compresses an archive through gzip |
| –bzip2 | j | Compresses an archive through bzip2 |
| –xz | J | Compresses an archive through xz |
Example 5: Creating a tarball and then compressing it using the three compression utilities
You may want to compare the effectiveness of each tool before deciding to use one or another. Note that while compressing small files, or a few files, the results may not show much differences, but may give you a glimpse of what they have to offer.
# tar cf ApacheLogs-$(date +%Y%m%d).tar /var/log/httpd/* # Create an ordinary tarball # tar czf ApacheLogs-$(date +%Y%m%d).tar.gz /var/log/httpd/* # Create a tarball and compress with gzip # tar cjf ApacheLogs-$(date +%Y%m%d).tar.bz2 /var/log/httpd/* # Create a tarball and compress with bzip2 # tar cJf ApacheLogs-$(date +%Y%m%d).tar.xz /var/log/httpd/* # Create a tarball and compress with xz

tar command examples
Example 6: Preserving original permissions and ownership while archiving and when
If you are creating backups from users’ home directories, you will want to store the individual files with the original permissions and ownership instead of changing them to that of the user account or daemon performing the backup. The following example preserves these attributes while taking the backup of the contents in the /var/log/httpd directory:
# tar cJf ApacheLogs-$(date +%Y%m%d).tar.xz /var/log/httpd/* --same-permissions --same-owner
Create Hard and Soft Links
In Linux, there are two types of links to files: hard links and soft (aka symbolic) links. Since a hard link represents another name for an existing file and is identified by the same inode, it then points to the actual data, as opposed to symbolic links, which point to filenames instead.
In addition, hard links do not occupy space on disk, while symbolic links do take a small amount of space to store the text of the link itself. The downside of hard links is that they can only be used to reference files within the filesystem where they are located because inodes are unique inside a filesystem. Symbolic links save the day, in that they point to another file or directory by name rather than by inode, and therefore can cross filesystem boundaries.
The basic syntax to create links is similar in both cases:
# ln TARGET LINK_NAME # Hard link named LINK_NAME to file named TARGET # ln -s TARGET LINK_NAME # Soft link named LINK_NAME to file named TARGET
Example 7: Creating hard and soft links
There is no better way to visualize the relation between a file and a hard or symbolic link that point to it, than to create those links. In the following screenshot you will see that the file and the hard link that points to it share the same inode and both are identified by the same disk usage of 466 bytes.
On the other hand, creating a hard link results in an extra disk usage of 5 bytes. Not that you’re going to run out of storage capacity, but this example is enough to illustrate the difference between a hard link and a soft link.

Difference between a hard link and a soft link
A typical usage of symbolic links is to reference a versioned file in a Linux system. Suppose there are several programs that need access to file fooX.Y, which is subject to frequent version updates (think of a library, for example). Instead of updating every single reference to fooX.Y every time there’s a version update, it is wiser, safer, and faster, to have programs look to a symbolic link named just foo, which in turn points to the actual fooX.Y.
Thus, when X and Y change, you only need to edit the symbolic link foo with a new destination name instead of tracking every usage of the destination file and updating it.
Summary
In this article we have reviewed some essential file and directory management skills that must be a part of every system administrator’s tool-set. Make sure to review other parts of this series as well in order to integrate these topics with the content covered in this tutorial.
Feel free to let us know if you have any questions or comments. We are always more than glad to hear from our readers.
RHCSA Series: How to Manage Users and Groups in RHEL 7 – Part 3
Managing a RHEL 7 server, as it is the case with any other Linux server, will require that you know how to add, edit, suspend, or delete user accounts, and grant users the necessary permissions to files, directories, and other system resources to perform their assigned tasks.

RHCSA: User and Group Management – Part 3
Managing User Accounts
To add a new user account to a RHEL 7 server, you can run either of the following two commands as root:
# adduser [new_account] # useradd [new_account]
When a new user account is added, by default the following operations are performed.
- His/her home directory is created (
/home/usernameunless specified otherwise). - These
.bash_logout,.bash_profileand.bashrchidden files are copied inside the user’s home directory, and will be used to provide environment variables for his/her user session. You can explore each of them for further details. - A mail spool directory is created for the added user account.
- A group is created with the same name as the new user account.
The full account summary is stored in the /etc/passwd file. This file holds a record per system user account and has the following format (fields are separated by a colon):
[username]:[x]:[UID]:[GID]:[Comment]:[Home directory]:[Default shell]
- These two fields
[username]and[Comment]are self explanatory. - The second filed ‘x’ indicates that the account is secured by a shadowed password (in
/etc/shadow), which is used to logon as[username]. - The fields
[UID]and[GID]are integers that shows the User IDentification and the primary Group IDentification to which[username]belongs, equally.
Finally,
- The
[Home directory]shows the absolute location of[username]’shome directory, and [Default shell]is the shell that is commit to this user when he/she logins into the system.
Another important file that you must become familiar with is /etc/group, where group information is stored. As it is the case with /etc/passwd, there is one record per line and its fields are also delimited by a colon:
[Group name]:[Group password]:[GID]:[Group members]
where,
[Group name]is the name of group.- Does this group use a group password? (An “x” means no).
[GID]: same as in/etc/passwd.[Group members]: a list of users, separated by commas, that are members of each group.
After adding an account, at anytime, you can edit the user’s account information using usermod, whose basic syntax is:
# usermod [options] [username]
Read Also:
15 ‘useradd’ Command Examples
15 ‘usermod’ Command Examples
EXAMPLE 1: Setting the expiry date for an account
If you work for a company that has some kind of policy to enable account for a certain interval of time, or if you want to grant access to a limited period of time, you can use the --expiredate flag followed by a date in YYYY-MM-DD format. To verify that the change has been applied, you can compare the output of
# chage -l [username]
before and after updating the account expiry date, as shown in the following image.
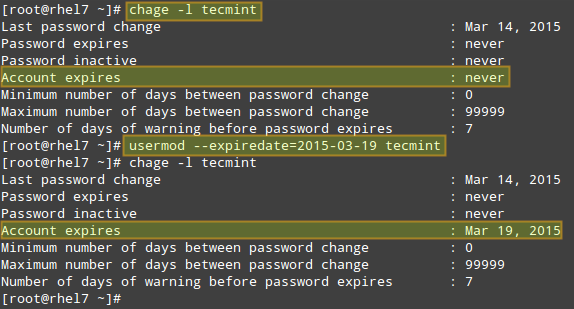
Change User Account Information
EXAMPLE 2: Adding the user to supplementary groups
Besides the primary group that is created when a new user account is added to the system, a user can be added to supplementary groups using the combined -aG, or –append –groups options, followed by a comma separated list of groups.
EXAMPLE 3: Changing the default location of the user’s home directory and / or changing its shell
If for some reason you need to change the default location of the user’s home directory (other than /home/username), you will need to use the -d, or –home options, followed by the absolute path to the new home directory.
If a user wants to use another shell other than bash (for example, sh), which gets assigned by default, use usermod with the –shell flag, followed by the path to the new shell.
EXAMPLE 4: Displaying the groups an user is a member of
After adding the user to a supplementary group, you can verify that it now actually belongs to such group(s):
# groups [username] # id [username]
The following image depicts Examples 2 through 4:

Adding User to Supplementary Group
In the example above:
# usermod --append --groups gacanepa,users --home /tmp --shell /bin/sh tecmint
To remove a user from a group, omit the --append switch in the command above and list the groups you want the user to belong to following the --groups flag.
EXAMPLE 5: Disabling account by locking password
To disable an account, you will need to use either the -L (lowercase L) or the –lock option to lock a user’s password. This will prevent the user from being able to log on.
EXAMPLE 6: Unlocking password
When you need to re-enable the user so that he can log on to the server again, use the -U or the –unlock option to unlock a user’s password that was previously blocked, as explained in Example 5 above.
# usermod --unlock tecmint
The following image illustrates Examples 5 and 6:

Lock Unlock User Account
EXAMPLE 7: Deleting a group or an user account
To delete a group, you’ll want to use groupdel, whereas to delete a user account you will use userdel (add the –rswitch if you also want to delete the contents of its home directory and mail spool):
# groupdel [group_name] # Delete a group # userdel -r [user_name] # Remove user_name from the system, along with his/her home directory and mail spool
If there are files owned by group_name, they will not be deleted, but the group owner will be set to the GID of the group that was deleted.
Listing, Setting and Changing Standard ugo/rwx Permissions
The well-known ls command is one of the best friends of any system administrator. When used with the -l flag, this tool allows you to view a list a directory’s contents in long (or detailed) format.
However, this command can also be applied to a single file. Either way, the first 10 characters in the output of ls -l represent each file’s attributes.
The first char of this 10-character sequence is used to indicate the file type:
- – (hyphen): a regular file
- d: a directory
- l: a symbolic link
- c: a character device (which treats data as a stream of bytes, i.e. a terminal)
- b: a block device (which handles data in blocks, i.e. storage devices)
The next nine characters of the file attributes, divided in groups of three from left to right, are called the file mode and indicate the read (r), write(w), and execute (x) permissions granted to the file’s owner, the file’s group owner, and the rest of the users (commonly referred to as “the world”), respectively.
While the read permission on a file allows the same to be opened and read, the same permission on a directory allows its contents to be listed if the execute permission is also set. In addition, the execute permission in a file allows it to be handled as a program and run.
File permissions are changed with the chmod command, whose basic syntax is as follows:
# chmod [new_mode] file
where new_mode is either an octal number or an expression that specifies the new permissions. Feel free to use the mode that works best for you in each case. Or perhaps you already have a preferred way to set a file’s permissions – so feel free to use the method that works best for you.
The octal number can be calculated based on the binary equivalent, which can in turn be obtained from the desired file permissions for the owner of the file, the owner group, and the world.The presence of a certain permission equals a power of 2 (r=22, w=21, x=20), while its absence means 0. For example:

File Permissions
To set the file’s permissions as indicated above in octal form, type:
# chmod 744 myfile
Please take a minute to compare our previous calculation to the actual output of ls -l after changing the file’s permissions:
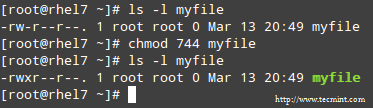
Long List Format
EXAMPLE 8: Searching for files with 777 permissions
As a security measure, you should make sure that files with 777 permissions (read, write, and execute for everyone) are avoided like the plague under normal circumstances. Although we will explain in a later tutorial how to more effectively locate all the files in your system with a certain permission set, you can -by now- combine ls with grep to obtain such information.
In the following example, we will look for file with 777 permissions in the /etc directory only. Note that we will use pipelining as explained in Part 2: File and Directory Management of this RHCSA series:
# ls -l /etc | grep rwxrwxrwx

Find All Files with 777 Permission
EXAMPLE 9: Assigning a specific permission to all users
Shell scripts, along with some binaries that all users should have access to (not just their corresponding owner and group), should have the execute bit set accordingly (please note that we will discuss a special case later):
# chmod a+x script.sh
Note: That we can also set a file’s mode using an expression that indicates the owner’s rights with the letter u, the group owner’s rights with the letter g, and the rest with o. All of these rights can be represented at the same time with the letter a. Permissions are granted (or revoked) with the + or - signs, respectively.

Set Execute Permission on File
A long directory listing also shows the file’s owner and its group owner in the first and second columns, respectively. This feature serves as a first-level access control method to files in a system:
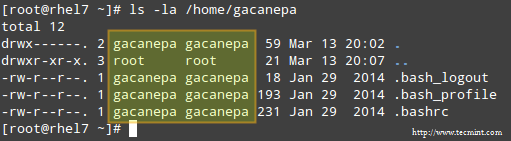
Check File Owner and Group
To change file ownership, you will use the chown command. Note that you can change the file and group ownership at the same time or separately:
# chown user:group file
Note: That you can change the user or group, or the two attributes at the same time, as long as you don’t forget the colon, leaving user or group blank if you want to update the other attribute, for example:
# chown :group file # Change group ownership only # chown user: file # Change user ownership only
EXAMPLE 10: Cloning permissions from one file to another
If you would like to “clone” ownership from one file to another, you can do so using the –reference flag, as follows:
# chown --reference=ref_file file
where the owner and group of ref_file will be assigned to file as well:

Clone File Ownership
Setting Up SETGID Directories for Collaboration
Should you need to grant access to all the files owned by a certain group inside a specific directory, you will most likely use the approach of setting the setgid bit for such directory. When the setgid bit is set, the effective GID of the real user becomes that of the group owner.
Thus, any user can access a file under the privileges granted to the group owner of such file. In addition, when the setgid bit is set on a directory, newly created files inherit the same group as the directory, and newly created subdirectories will also inherit the setgid bit of the parent directory.
# chmod g+s [filename]
To set the setgid in octal form, prepend the number 2 to the current (or desired) basic permissions.
# chmod 2755 [directory]
Conclusion
A solid knowledge of user and group management, along with standard and special Linux permissions, when coupled with practice, will allow you to quickly identify and troubleshoot issues with file permissions in your RHEL 7 server.
I assure you that as you follow the steps outlined in this article and use the system documentation (as explained in Part 1: Reviewing Essential Commands & System Documentation of this series) you will master this essential competence of system administration.
Feel free to let us know if you have any questions or comments using the form below.
RHCSA Series: Editing Text Files with Nano and Vim / Analyzing text with grep and regexps – Part 4
Every system administrator has to deal with text files as part of his daily responsibilities. That includes editing existing files (most likely configuration files), or creating new ones. It has been said that if you want to start a holy war in the Linux world, you can ask sysadmins what their favorite text editor is and why. We are not going to do that in this article, but will present a few tips that will be helpful to use two of the most widely used text editors in RHEL 7: nano (due to its simplicity and easiness of use, specially to new users), and vi/m (due to its several features that convert it into more than a simple editor). I am sure that you can find many more reasons to use one or the other, or perhaps some other editor such as emacs or pico. It’s entirely up to you.

RHCSA: Editing Text Files with Nano and Vim – Part 4
Editing Files with Nano Editor
To launch nano, you can either just type nano at the command prompt, optionally followed by a filename (in this case, if the file exists, it will be opened in edition mode). If the file does not exist, or if we omit the filename, nano will also be opened in edition mode but will present a blank screen for us to start typing:

Nano Editor
As you can see in the previous image, nano displays at the bottom of the screen several functions that are available via the indicated shortcuts (^, aka caret, indicates the Ctrl key). To name a few of them:
- Ctrl + G: brings up the help menu with a complete list of functions and descriptions:Ctrl + X: exits the current file. If changes have not been saved, they are discarded.
- Ctrl + R: lets you choose a file to insert its contents into the present file by specifying a full path.
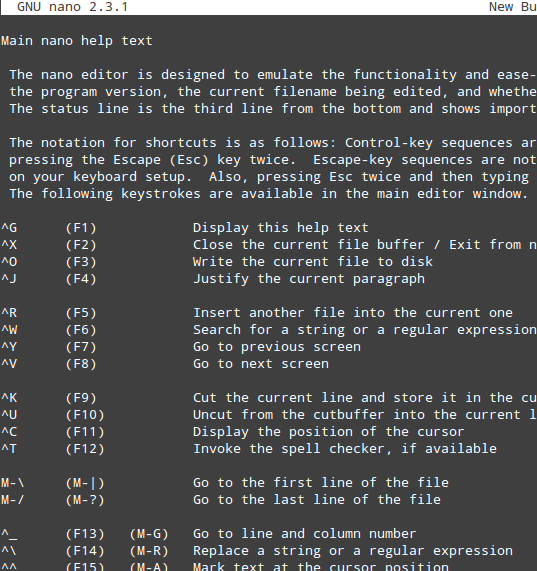
Nano Editor Help Menu
- Ctrl + O: saves changes made to a file. It will let you save the file with the same name or a different one. Then press Enter to confirm.

Nano Editor Save Changes Mode
- Ctrl + X: exits the current file. If changes have not been saved, they are discarded.
- Ctrl + R: lets you choose a file to insert its contents into the present file by specifying a full path.
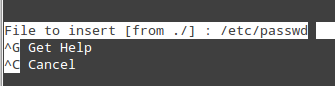
Nano: Insert File Content to Parent File
will insert the contents of /etc/passwd into the current file.
- Ctrl + K: cuts the current line.
- Ctrl + U: paste.
- Ctrl + C: cancels the current operation and places you at the previous screen.
To easily navigate the opened file, nano provides the following features:
- Ctrl + F and Ctrl + B move the cursor forward or backward, whereas Ctrl + P and Ctrl + N move it up or down one line at a time, respectively, just like the arrow keys.
- Ctrl + space and Alt + space move the cursor forward and backward one word at a time.
Finally,
- Ctrl + _ (underscore) and then entering X,Y will take you precisely to Line X, column Y, if you want to place the cursor at a specific place in the document.

Navigate to Line Numbers in Nano
The example above will take you to line 15, column 14 in the current document.
If you can recall your early Linux days, specially if you came from Windows, you will probably agree that starting off with nano is the best way to go for a new user.
Editing Files with Vim Editor
Vim is an improved version of vi, a famous text editor in Linux that is available on all POSIX-compliant *nix systems, such as RHEL 7. If you have the chance and can install vim, go ahead; if not, most (if not all) the tips given in this article should also work.
One of vim’s distinguishing features is the different modes in which it operates:
- Command mode will allow you to browse through the file and enter commands, which are brief and case-sensitive combinations of one or more letters. If you need to repeat one of them a certain number of times, you can prefix it with a number (there are only a few exceptions to this rule). For example, yy (or Y, short for yank) copies the entire current line, whereas 4yy (or 4Y) copies the entire current line along with the next three lines (4 lines in total).
- In ex mode, you can manipulate files (including saving a current file and running outside programs or commands). To enter ex mode, we must type a colon (:) starting from command mode (or in other words, Esc + :), directly followed by the name of the ex-mode command that you want to use.
- In insert mode, which is accessed by typing the letter i, we simply enter text. Most keystrokes result in text appearing on the screen.
- We can always enter command mode (regardless of the mode we’re working on) by pressing the Esc key.
Let’s see how we can perform the same operations that we outlined for nano in the previous section, but now with vim. Don’t forget to hit the Enter key to confirm the vim command!
To access vim’s full manual from the command line, type :help while in command mode and then press Enter:
vim Edito Help Menu
The upper section presents an index list of contents, with defined sections dedicated to specific topics about vim. To navigate to a section, place the cursor over it and press Ctrl + ] (closing square bracket). Note that the bottom section displays the current file.
1. To save changes made to a file, run any of the following commands from command mode and it will do the trick:
:wq! :x! ZZ (yes, double Z without the colon at the beginning)
2. To exit discarding changes, use :q!. This command will also allow you to exit the help menu described above, and return to the current file in command mode.
3. Cut N number of lines: type Ndd while in command mode.
4. Copy M number of lines: type Myy while in command mode.
5. Paste lines that were previously cutted or copied: press the P key while in command mode.
6. To insert the contents of another file into the current one:
:r filename
For example, to insert the contents of /etc/fstab, do:
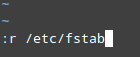
Insert Content of File in vi Editor
7. To insert the output of a command into the current document:
:r! command
For example, to insert the date and time in the line below the current position of the cursor:
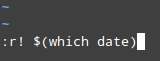
Insert Time an Date in vi Editor
In another article that I wrote for, (Part 2 of the LFCS series), I explained in greater detail the keyboard shortcuts and functions available in vim. You may want to refer to that tutorial for further examples on how to use this powerful text editor.
Analyzing Text with Grep and Regular Expressions
By now you have learned how to create and edit files using nano or vim. Say you become a text editor ninja, so to speak – now what? Among other things, you will also need how to search for regular expressions inside text.
A regular expression (also known as “regex” or “regexp“) is a way of identifying a text string or pattern so that a program can compare the pattern against arbitrary text strings. Although the use of regular expressions along with grep would deserve an entire article on its own, let us review the basics here:
1. The simplest regular expression is an alphanumeric string (i.e., the word “svm”) or two (when two are present, you can use the | (OR) operator):
# grep -Ei 'svm|vmx' /proc/cpuinfo
The presence of either of those two strings indicate that your processor supports virtualization:

Regular Expression Example
2. A second kind of a regular expression is a range list, enclosed between square brackets.
For example, c[aeiou]t matches the strings cat, cet, cit, cot, and cut, whereas [a-z] and [0-9] match any lowercase letter or decimal digit, respectively. If you want to repeat the regular expression X certain number of times, type {X} immediately following the regexp.
For example, let’s extract the UUIDs of storage devices from /etc/fstab:
# grep -Ei '[0-9a-f]{8}-([0-9a-f]{4}-){3}[0-9a-f]{12}' -o /etc/fstab

Extract String from a File
The first expression in brackets [0-9a-f] is used to denote lowercase hexadecimal characters, and {8} is a quantifier that indicates the number of times that the preceding match should be repeated (the first sequence of characters in an UUID is a 8-character long hexadecimal string).
The parentheses, the {4} quantifier, and the hyphen indicate that the next sequence is a 4-character long hexadecimal string, and the quantifier that follows ({3}) denote that the expression should be repeated 3 times.
Finally, the last sequence of 12-character long hexadecimal string in the UUID is retrieved with [0-9a-f]{12}, and the -o option prints only the matched (non-empty) parts of the matching line in /etc/fstab.
3. POSIX character classes.
| Character Class | Matches… |
| [[:alnum:]] | Any alphanumeric [a-zA-Z0-9] character |
| [[:alpha:]] | Any alphabetic [a-zA-Z] character |
| [[:blank:]] | Spaces or tabs |
| [[:cntrl:]] | Any control characters (ASCII 0 to 32) |
| [[:digit:]] | Any numeric digits [0-9] |
| [[:graph:]] | Any visible characters |
| [[:lower:]] | Any lowercase [a-z] character |
| [[:print:]] | Any non-control characters |
| [[:space:]] | Any whitespace |
| [[:punct:]] | Any punctuation marks |
| [[:upper:]] | Any uppercase [A-Z] character |
| [[:xdigit:]] | Any hex digits [0-9a-fA-F] |
| [:word:] | Any letters, numbers, and underscores [a-zA-Z0-9_] |
For example, we may be interested in finding out what the used UIDs and GIDs (refer to Part 2 of this series to refresh your memory) are for real users that have been added to our system. Thus, we will search for sequences of 4 digits in /etc/passwd:
# grep -Ei [[:digit:]]{4} /etc/passwd

Search For a String in File
The above example may not be the best case of use of regular expressions in the real world, but it clearly illustrates how to use POSIX character classes to analyze text along with grep.
Conclusion
In this article we have provided some tips to make the most of nano and vim, two text editors for the command-line users. Both tools are supported by extensive documentation, which you can consult in their respective official web sites (links given below) and using the suggestions given in Part 1 of this series.
Reference Links
http://www.nano-editor.org/
http://www.vim.org/
RHCSA Series: Process Management in RHEL 7: Boot, Shutdown, and Everything in Between – Part 5
We will start this article with an overall and brief revision of what happens since the moment you press the Power button to turn on your RHEL 7 server until you are presented with the login screen in a command line interface.

Linux Boot Process
Please note that:
1. the same basic principles apply, with perhaps minor modifications, to other Linux distributions as well, and
2. the following description is not intended to represent an exhaustive explanation of the boot process, but only the fundamentals.
Linux Boot Process
1. The POST (Power On Self Test) initializes and performs hardware checks.
2. When the POST finishes, the system control is passed to the first stage boot loader, which is stored on either the boot sector of one of the hard disks (for older systems using BIOS and MBR), or a dedicated (U)EFI partition.
3. The first stage boot loader then loads the second stage boot loader, most usually GRUB (GRand Unified Boot Loader), which resides inside /boot, which in turn loads the kernel and the initial RAM–based file system (also known as initramfs, which contains programs and binary files that perform the necessary actions needed to ultimately mount the actual root filesystem).
4. We are presented with a splash screen that allows us to choose an operating system and kernel to boot:

Boot Menu Screen
5. The kernel sets up the hardware attached to the system and once the root filesystem has been mounted, launches process with PID 1, which in turn will initialize other processes and present us with a login prompt.
Note: That if we wish to do so at a later time, we can examine the specifics of this process using the dmesg command and filtering its output using the tools that we have explained in previous articles of this series.

Login Screen and Process PID
In the example above, we used the well-known ps command to display a list of current processes whose parent process (or in other words, the process that started them) is systemd (the system and service manager that most modern Linux distributions have switched to) during system startup:
# ps -o ppid,pid,uname,comm --ppid=1
Remember that the -o flag (short for –format) allows you to present the output of ps in a customized format to suit your needs using the keywords specified in the STANDARD FORMAT SPECIFIERS section in man ps.
Another case in which you will want to define the output of ps instead of going with the default is when you need to find processes that are causing a significant CPU and / or memory load, and sort them accordingly:
# ps aux --sort=+pcpu # Sort by %CPU (ascending) # ps aux --sort=-pcpu # Sort by %CPU (descending) # ps aux --sort=+pmem # Sort by %MEM (ascending) # ps aux --sort=-pmem # Sort by %MEM (descending) # ps aux --sort=+pcpu,-pmem # Combine sort by %CPU (ascending) and %MEM (descending)

Customize ps Command Output
An Introduction to SystemD
Few decisions in the Linux world have caused more controversies than the adoption of systemd by major Linux distributions. Systemd’s advocates name as its main advantages the following facts:
Read Also: The Story Behind ‘init’ and ‘systemd’
1. Systemd allows more processing to be done in parallel during system startup (as opposed to older SysVinit, which always tends to be slower because it starts processes one by one, checks if one depends on another, and then waits for daemons to launch so more services can start), and
2. It works as a dynamic resource management in a running system. Thus, services are started when needed (to avoid consuming system resources if they are not being used) instead of being launched without a valid reason during boot.
3. Backwards compatibility with SysVinit scripts.
Systemd is controlled by the systemctl utility. If you come from a SysVinit background, chances are you will be familiar with:
- the service tool, which -in those older systems- was used to manage SysVinit scripts, and
- the chkconfig utility, which served the purpose of updating and querying runlevel information for system services.
- shutdown, which you must have used several times to either restart or halt a running system.
The following table shows the similarities between the use of these legacy tools and systemctl:
| Legacy tool | Systemctl equivalent | Description |
| service name start | systemctl start name | Start name (where name is a service) |
| service name stop | systemctl stop name | Stop name |
| service name condrestart | systemctl try-restart name | Restarts name (if it’s already running) |
| service name restart | systemctl restart name | Restarts name |
| service name reload | systemctl reload name | Reloads the configuration for name |
| service name status | systemctl status name | Displays the current status of name |
| service –status-all | systemctl | Displays the status of all current services |
| chkconfig name on | systemctl enable name | Enable name to run on startup as specified in the unit file (the file to which the symlink points). The process of enabling or disabling a service to start automatically on boot consists in adding or removing symbolic links inside the /etc/systemd/system directory. |
| chkconfig name off | systemctl disable name | Disables name to run on startup as specified in the unit file (the file to which the symlink points) |
| chkconfig –list name | systemctl is-enabled name | Verify whether name (a specific service) is currently enabled |
| chkconfig –list | systemctl –type=service | Displays all services and tells whether they are enabled or disabled |
| shutdown -h now | systemctl poweroff | Power-off the machine (halt) |
| shutdown -r now | systemctl reboot | Reboot the system |
Systemd also introduced the concepts of units (which can be either a service, a mount point, a device, or a network socket) and targets (which is how systemd manages to start several related process at the same time, and can be considered -though not equal- as the equivalent of runlevels in SysVinit-based systems.
Summing Up
Other tasks related with process management include, but may not be limited to, the ability to:
1. Adjust the execution priority as far as the use of system resources is concerned of a process:
This is accomplished through the renice utility, which alters the scheduling priority of one or more running processes. In simple terms, the scheduling priority is a feature that allows the kernel (present in versions => 2.6) to allocate system resources as per the assigned execution priority (aka niceness, in a range from -20 through 19) of a given process.
The basic syntax of renice is as follows:
# renice [-n] priority [-gpu] identifier
In the generic command above, the first argument is the priority value to be used, whereas the other argument can be interpreted as process IDs (which is the default setting), process group IDs, user IDs, or user names. A normal user (other than root) can only modify the scheduling priority of a process he or she owns, and only increase the niceness level (which means taking up less system resources).

Process Scheduling Priority
2. Kill (or interrupt the normal execution) of a process as needed:
In more precise terms, killing a process entitles sending it a signal to either finish its execution gracefully (SIGTERM=15) or immediately (SIGKILL=9) through the kill or pkill commands.
The difference between these two tools is that the former is used to terminate a specific process or a process group altogether, while the latter allows you to do the same based on name and other attributes.
In addition, pkill comes bundled with pgrep, which shows you the PIDs that will be affected should pkill be used. For example, before running:
# pkill -u gacanepa
It may be useful to view at a glance which are the PIDs owned by gacanepa:
# pgrep -l -u gacanepa
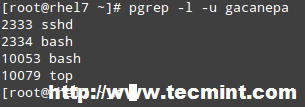
Find PIDs of User
By default, both kill and pkill send the SIGTERM signal to the process. As we mentioned above, this signal can be ignored (while the process finishes its execution or for good), so when you seriously need to stop a running process with a valid reason, you will need to specify the SIGKILL signal on the command line:
# kill -9 identifier # Kill a process or a process group # kill -s SIGNAL identifier # Idem # pkill -s SIGNAL identifier # Kill a process by name or other attributes
Conclusion
In this article we have explained the basics of the boot process in a RHEL 7 system, and analyzed some of the tools that are available to help you with managing processes using common utilities and systemd-specific commands.
Note that this list is not intended to cover all the bells and whistles of this topic, so feel free to add your own preferred tools and commands to this article using the comment form below. Questions and other comments are also welcome.
RHCSA Series: Using ‘Parted’ and ‘SSM’ to Configure and Encrypt System Storage – Part 6
In this article we will discuss how to set up and configure local system storage in Red Hat Enterprise Linux 7using classic tools and introducing the System Storage Manager (also known as SSM), which greatly simplifies this task.

RHCSA: Configure and Encrypt System Storage – Part 6
Please note that we will present this topic in this article but will continue its description and usage on the next one (Part 7) due to vastness of the subject.
Creating and Modifying Partitions in RHEL 7
In RHEL 7, parted is the default utility to work with partitions, and will allow you to:
- Display the current partition table
- Manipulate (increase or decrease the size of) existing partitions
- Create partitions using free space or additional physical storage devices
It is recommended that before attempting the creation of a new partition or the modification of an existing one, you should ensure that none of the partitions on the device are in use (umount /dev/partition), and if you’re using part of the device as swap you need to disable it (swapoff -v /dev/partition) during the process.
The easiest way to do this is to boot RHEL in rescue mode using an installation media such as a RHEL 7installation DVD or USB (Troubleshooting → Rescue a Red Hat Enterprise Linux system) and Select Skip when you’re prompted to choose an option to mount the existing Linux installation, and you will be presented with a command prompt where you can start typing the same commands as shown as follows during the creation of an ordinary partition in a physical device that is not being used.

RHEL 7 Rescue Mode
To start parted, simply type.
# parted /dev/sdb
Where /dev/sdb is the device where you will create the new partition; next, type print to display the current drive’s partition table:
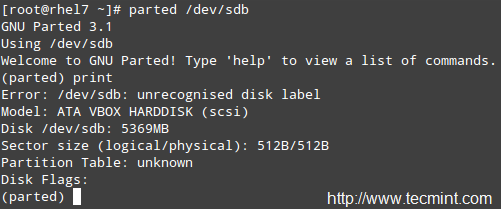
Creat New Partition
As you can see, in this example we are using a virtual drive of 5 GB. We will now proceed to create a 4 GBprimary partition and then format it with the xfs filesystem, which is the default in RHEL 7.
You can choose from a variety of file systems. You will need to manually create the partition with mkpart and then format it with mkfs.fstype as usual because mkpart does not support many modern filesystems out-of-the-box.
In the following example we will set a label for the device and then create a primary partition (p) on /dev/sdb, which starts at the 0% percentage of the device and ends at 4000 MB (4 GB):
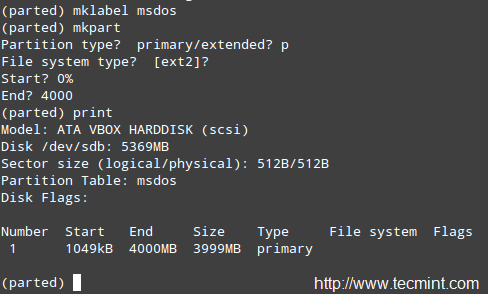
Label Partition Name
Next, we will format the partition as xfs and print the partition table again to verify that changes were applied:
# mkfs.xfs /dev/sdb1 # parted /dev/sdb print

Format Partition as XFS Filesystem
For older filesystems, you could use the resize command in parted to resize a partition. Unfortunately, this only applies to ext2, fat16, fat32, hfs, linux-swap, and reiserfs (if libreiserfs is installed).
Thus, the only way to resize a partition is by deleting it and creating it again (so make sure you have a good backup of your data!). No wonder the default partitioning scheme in RHEL 7 is based on LVM.
To remove a partition with parted:
# parted /dev/sdb print # parted /dev/sdb rm 1

Remove or Delete Partition
The Logical Volume Manager (LVM)
Once a disk has been partitioned, it can be difficult or risky to change the partition sizes. For that reason, if we plan on resizing the partitions on our system, we should consider the possibility of using LVM instead of the classic partitioning system, where several physical devices can form a volume group that will host a defined number of logical volumes, which can be expanded or reduced without any hassle.
In simple terms, you may find the following diagram useful to remember the basic architecture of LVM.

Basic Architecture of LVM
Creating Physical Volumes, Volume Group and Logical Volumes
Follow these steps in order to set up LVM using classic volume management tools. Since you can expand this topic reading the LVM series on this site, I will only outline the basic steps to set up LVM, and then compare them to implementing the same functionality with SSM.
Note: That we will use the whole disks /dev/sdb and /dev/sdc as PVs (Physical Volumes) but it’s entirely up to you if you want to do the same.
1. Create partitions /dev/sdb1 and /dev/sdc1 using 100% of the available disk space in /dev/sdb and /dev/sdc:
# parted /dev/sdb print # parted /dev/sdc print
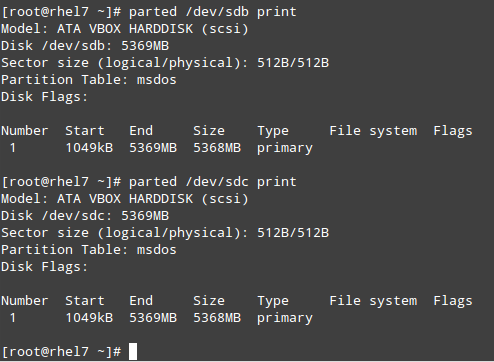
Create New Partitions
2. Create 2 physical volumes on top of /dev/sdb1 and /dev/sdc1, respectively.
# pvcreate /dev/sdb1 # pvcreate /dev/sdc1

Create Two Physical Volumes
Remember that you can use pvdisplay /dev/sd{b,c}1 to show information about the newly created PVs.
3. Create a VG on top of the PV that you created in the previous step:
# vgcreate tecmint_vg /dev/sd{b,c}1

Create Volume Group
Remember that you can use vgdisplay tecmint_vg to show information about the newly created VG.
4. Create three logical volumes on top of VG tecmint_vg, as follows:
# lvcreate -L 3G -n vol01_docs tecmint_vg [vol01_docs → 3 GB] # lvcreate -L 1G -n vol02_logs tecmint_vg [vol02_logs → 1 GB] # lvcreate -l 100%FREE -n vol03_homes tecmint_vg [vol03_homes → 6 GB]

Create Logical Volumes
Remember that you can use lvdisplay tecmint_vg to show information about the newly created LVs on top of VG tecmint_vg.
5. Format each of the logical volumes with xfs (do NOT use xfs if you’re planning on shrinking volumes later!):
# mkfs.xfs /dev/tecmint_vg/vol01_docs # mkfs.xfs /dev/tecmint_vg/vol02_logs # mkfs.xfs /dev/tecmint_vg/vol03_homes
6. Finally, mount them:
# mount /dev/tecmint_vg/vol01_docs /mnt/docs # mount /dev/tecmint_vg/vol02_logs /mnt/logs # mount /dev/tecmint_vg/vol03_homes /mnt/homes
Removing Logical Volumes, Volume Group and Physical Volumes
7. Now we will reverse the LVM implementation and remove the LVs, the VG, and the PVs:
# lvremove /dev/tecmint_vg/vol01_docs
# lvremove /dev/tecmint_vg/vol02_logs
# lvremove /dev/tecmint_vg/vol03_homes
# vgremove /dev/tecmint_vg
# pvremove /dev/sd{b,c}1
8. Now let’s install SSM and we will see how to perform the above in ONLY 1 STEP!
# yum update && yum install system-storage-manager
We will use the same names and sizes as before:
# ssm create -s 3G -n vol01_docs -p tecmint_vg --fstype ext4 /mnt/docs /dev/sd{b,c}1
# ssm create -s 1G -n vol02_logs -p tecmint_vg --fstype ext4 /mnt/logs /dev/sd{b,c}1
# ssm create -n vol03_homes -p tecmint_vg --fstype ext4 /mnt/homes /dev/sd{b,c}1
Yes! SSM will let you:
- initialize block devices as physical volumes
- create a volume group
- create logical volumes
- format LVs, and
- mount them using only one command
9. We can now display the information about PVs, VGs, or LVs, respectively, as follows:
# ssm list dev # ssm list pool # ssm list vol

Check Information of PVs, VGs, or LVs
10. As we already know, one of the distinguishing features of LVM is the possibility to resize (expand or decrease) logical volumes without downtime.
Say we are running out of space in vol02_logs but have plenty of space in vol03_homes. We will resize vol03_homes to 4 GB and expand vol02_logs to use the remaining space:
# ssm resize -s 4G /dev/tecmint_vg/vol03_homes
Run ssm list pool again and take note of the free space in tecmint_vg:
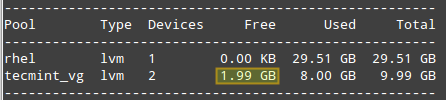
Check Volume Size
Then do:
# ssm resize -s+1.99 /dev/tecmint_vg/vol02_logs
Note: that the plus sign after the -s flag indicates that the specified value should be added to the present value.
11. Removing logical volumes and volume groups is much easier with ssm as well. A simple,
# ssm remove tecmint_vg
will return a prompt asking you to confirm the deletion of the VG and the LVs it contains:

Remove Logical Volume and Volume Group
Managing Encrypted Volumes
SSM also provides system administrators with the capability of managing encryption for new or existing volumes. You will need the cryptsetup package installed first:
# yum update && yum install cryptsetup
Then issue the following command to create an encrypted volume. You will be prompted to enter a passphraseto maximize security:
# ssm create -s 3G -n vol01_docs -p tecmint_vg --fstype ext4 --encrypt luks /mnt/docs /dev/sd{b,c}1
# ssm create -s 1G -n vol02_logs -p tecmint_vg --fstype ext4 --encrypt luks /mnt/logs /dev/sd{b,c}1
# ssm create -n vol03_homes -p tecmint_vg --fstype ext4 --encrypt luks /mnt/homes /dev/sd{b,c}1
Our next task consists in adding the corresponding entries in /etc/fstab in order for those logical volumes to be available on boot. Rather than using the device identifier (/dev/something).
We will use each LV’s UUID (so that our devices will still be uniquely identified should we add other logical volumes or devices), which we can find out with the blkid utility:
# blkid -o value UUID /dev/tecmint_vg/vol01_docs # blkid -o value UUID /dev/tecmint_vg/vol02_logs # blkid -o value UUID /dev/tecmint_vg/vol03_homes
In our case:

Find Logical Volume UUID
Next, create the /etc/crypttab file with the following contents (change the UUIDs for the ones that apply to your setup):
docs UUID=ba77d113-f849-4ddf-8048-13860399fca8 none logs UUID=58f89c5a-f694-4443-83d6-2e83878e30e4 none homes UUID=92245af6-3f38-4e07-8dd8-787f4690d7ac none
And insert the following entries in /etc/fstab. Note that device_name (/dev/mapper/device_name) is the mapper identifier that appears in the first column of /etc/crypttab.
# Logical volume vol01_docs: /dev/mapper/docs /mnt/docs ext4 defaults 0 2 # Logical volume vol02_logs /dev/mapper/logs /mnt/logs ext4 defaults 0 2 # Logical volume vol03_homes /dev/mapper/homes /mnt/homes ext4 defaults 0 2
Now reboot (systemctl reboot) and you will be prompted to enter the passphrase for each LV. Afterwards you can confirm that the mount operation was successful by checking the corresponding mount points:

Verify Logical Volume Mount Points
Conclusion
In this tutorial we have started to explore how to set up and configure system storage using classic volume management tools and SSM, which also integrates filesystem and encryption capabilities in one package. This makes SSM an invaluable tool for any sysadmin.
Let us know if you have any questions or comments – feel free to use the form below to get in touch with us!
RHCSA Series: Using ACLs (Access Control Lists) and Mounting Samba / NFS Shares – Part 7
In the last article (RHCSA series Part 6) we started explaining how to set up and configure local system storage using parted and ssm.

RHCSA Series:: Configure ACL’s and Mounting NFS / Samba Shares – Part 7
We also discussed how to create and mount encrypted volumes with a password during system boot. In addition, we warned you to avoid performing critical storage management operations on mounted filesystems. With that in mind we will now review the most used file system formats in Red Hat Enterprise Linux 7 and then proceed to cover the topics of mounting, using, and unmounting both manually and automatically network filesystems (CIFS and NFS), along with the implementation of access control lists for your system.
Prerequisites
Before proceeding further, please make sure you have a Samba server and a NFS server available (note that NFSv2 is no longer supported in RHEL 7).
During this guide we will use a machine with IP 192.168.0.10 with both services running in it as server, and a RHEL 7 box as client with IP address 192.168.0.18. Later in the article we will tell you which packages you need to install on the client.
File System Formats in RHEL 7
Beginning with RHEL 7, XFS has been introduced as the default file system for all architectures due to its high performance and scalability. It currently supports a maximum filesystem size of 500 TB as per the latest tests performed by Red Hat and its partners for mainstream hardware.
Also, XFS enables user_xattr (extended user attributes) and acl (POSIX access control lists) as default mount options, unlike ext3 or ext4 (ext2 is considered deprecated as of RHEL 7), which means that you don’t need to specify those options explicitly either on the command line or in /etc/fstab when mounting a XFS filesystem (if you want to disable such options in this last case, you have to explicitly use no_acl and no_user_xattr).
Keep in mind that the extended user attributes can be assigned to files and directories for storing arbitrary additional information such as the mime type, character set or encoding of a file, whereas the access permissions for user attributes are defined by the regular file permission bits.
Access Control Lists
As every system administrator, either beginner or expert, is well acquainted with regular access permissions on files and directories, which specify certain privileges (read, write, and execute) for the owner, the group, and “the world” (all others). However, feel free to refer to Part 3 of the RHCSA series if you need to refresh your memory a little bit.
However, since the standard ugo/rwx set does not allow to configure different permissions for different users, ACLs were introduced in order to define more detailed access rights for files and directories than those specified by regular permissions.
In fact, ACL-defined permissions are a superset of the permissions specified by the file permission bits. Let’s see how all of this translates is applied in the real world.
1. There are two types of ACLs: access ACLs, which can be applied to either a specific file or a directory), and default ACLs, which can only be applied to a directory. If files contained therein do not have a ACL set, they inherit the default ACL of their parent directory.
2. To begin, ACLs can be configured per user, per group, or per an user not in the owning group of a file.
3. ACLs are set (and removed) using setfacl, with either the -m or -x options, respectively.
For example, let us create a group named tecmint and add users johndoe and davenull to it:
# groupadd tecmint # useradd johndoe # useradd davenull # usermod -a -G tecmint johndoe # usermod -a -G tecmint davenull
And let’s verify that both users belong to supplementary group tecmint:
# id johndoe # id davenull

Verify Users
Let’s now create a directory called playground within /mnt, and a file named testfile.txt inside. We will set the group owner to tecmint and change its default ugo/rwx permissions to 770 (read, write, and execute permissions granted to both the owner and the group owner of the file):
# mkdir /mnt/playground # touch /mnt/playground/testfile.txt # chmod 770 /mnt/playground/testfile.txt
Then switch user to johndoe and davenull, in that order, and write to the file:
echo "My name is John Doe" > /mnt/playground/testfile.txt echo "My name is Dave Null" >> /mnt/playground/testfile.txt
So far so good. Now let’s have user gacanepa write to the file – and the write operation will fail, which was to be expected.
But what if we actually need user gacanepa (who is not a member of group tecmint) to have write permissions on /mnt/playground/testfile.txt? The first thing that may come to your mind is adding that user account to group tecmint. But that will give him write permissions on ALL files were the write bit is set for the group, and we don’t want that. We only want him to be able to write to /mnt/playground/testfile.txt.
# touch /mnt/playground/testfile.txt # chown :tecmint /mnt/playground/testfile.txt # chmod 777 /mnt/playground/testfile.txt # su johndoe $ echo "My name is John Doe" > /mnt/playground/testfile.txt $ su davenull $ echo "My name is Dave Null" >> /mnt/playground/testfile.txt $ su gacanepa $ echo "My name is Gabriel Canepa" >> /mnt/playground/testfile.txt

Manage User Permissions
Let’s give user gacanepa read and write access to /mnt/playground/testfile.txt.
Run as root,
# setfacl -R -m u:gacanepa:rwx /mnt/playground
and you’ll have successfully added an ACL that allows gacanepa to write to the test file. Then switch to user gacanepa and try to write to the file again:
$ echo "My name is Gabriel Canepa" >> /mnt/playground/testfile.txt
To view the ACLs for a specific file or directory, use getfacl:
# getfacl /mnt/playground/testfile.txt

Check ACLs of Files
To set a default ACL to a directory (which its contents will inherit unless overwritten otherwise), add d: before the rule and specify a directory instead of a file name:
# setfacl -m d:o:r /mnt/playground
The ACL above will allow users not in the owner group to have read access to the future contents of the /mnt/playground directory. Note the difference in the output of getfacl /mnt/playground before and after the change:

Set Default ACL in Linux
Chapter 20 in the official RHEL 7 Storage Administration Guide provides more ACL examples, and I highly recommend you take a look at it and have it handy as reference.
Mounting NFS Network Shares
To show the list of NFS shares available in your server, you can use the showmount command with the -eoption, followed by the machine name or its IP address. This tool is included in the nfs-utils package:
# yum update && yum install nfs-utils
Then do:
# showmount -e 192.168.0.10
and you will get a list of the available NFS shares on 192.168.0.10:
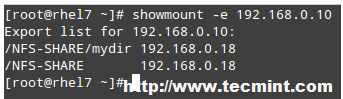
Check Available NFS Shares
To mount NFS network shares on the local client using the command line on demand, use the following syntax:
# mount -t nfs -o [options] remote_host:/remote/directory /local/directory
which, in our case, translates to:
# mount -t nfs 192.168.0.10:/NFS-SHARE /mnt/nfs
If you get the following error message: “Job for rpc-statd.service failed. See “systemctl status rpc-statd.service” and “journalctl -xn” for details.”, make sure the rpcbind service is enabled and started in your system first:
# systemctl enable rpcbind.socket # systemctl restart rpcbind.service
and then reboot. That should do the trick and you will be able to mount your NFS share as explained earlier. If you need to mount the NFS share automatically on system boot, add a valid entry to the /etc/fstab file:
remote_host:/remote/directory /local/directory nfs options 0 0
The variables remote_host, /remote/directory, /local/directory, and options (which is optional) are the same ones used when manually mounting an NFS share from the command line. As per our previous example:
192.168.0.10:/NFS-SHARE /mnt/nfs nfs defaults 0 0
Mounting CIFS (Samba) Network Shares
Samba represents the tool of choice to make a network share available in a network with *nix and Windows machines. To show the Samba shares that are available, use the smbclient command with the -L flag, followed by the machine name or its IP address. This tool is included in the samba-client package:
You will be prompted for root’s password in the remote host:
# smbclient -L 192.168.0.10

Check Samba Shares
To mount Samba network shares on the local client you will need to install first the cifs-utils package:
# yum update && yum install cifs-utils
Then use the following syntax on the command line:
# mount -t cifs -o credentials=/path/to/credentials/file //remote_host/samba_share /local/directory
which, in our case, translates to:
# mount -t cifs -o credentials=~/.smbcredentials //192.168.0.10/gacanepa /mnt/samba
where smbcredentials:
username=gacanepa password=XXXXXX
is a hidden file inside root’s home (/root/) with permissions set to 600, so that no one else but the owner of the file can read or write to it.
Please note that the samba_share is the name of the Samba share as returned by smbclient -L remote_host as shown above.
Now, if you need the Samba share to be available automatically on system boot, add a valid entry to the /etc/fstab file as follows:
//remote_host:/samba_share /local/directory cifs options 0 0
The variables remote_host, /samba_share, /local/directory, and options (which is optional) are the same ones used when manually mounting a Samba share from the command line. Following the definitions given in our previous example:
//192.168.0.10/gacanepa /mnt/samba cifs credentials=/root/smbcredentials,defaults 0 0
Conclusion
In this article we have explained how to set up ACLs in Linux, and discussed how to mount CIFS and NFSnetwork shares in a RHEL 7 client.
I recommend you to practice these concepts and even mix them (go ahead and try to set ACLs in mounted network shares) until you feel comfortable. If you have questions or comments feel free to use the form below to contact us anytime. Also, feel free to share this article through your social networks.
RHCSA Series: Securing SSH, Setting Hostname and Enabling Network Services – Part 8
As a system administrator you will often have to log on to remote systems to perform a variety of administration tasks using a terminal emulator. You will rarely sit in front of a real (physical) terminal, so you need to set up a way to log on remotely to the machines that you will be asked to manage.
In fact, that may be the last thing that you will have to do in front of a physical terminal. For security reasons, using Telnet for this purpose is not a good idea, as all traffic goes through the wire in unencrypted, plain text.
In addition, in this article we will also review how to configure network services to start automatically at boot and learn how to set up network and hostname resolution statically or dynamically.

RHCSA: Secure SSH and Enable Network Services – Part 8
Installing and Securing SSH Communication
For you to be able to log on remotely to a RHEL 7 box using SSH, you will have to install the openssh, openssh-clients and openssh-servers packages. The following command not only will install the remote login program, but also the secure file transfer tool, as well as the remote file copy utility:
# yum update && yum install openssh openssh-clients openssh-servers
Note that it’s a good idea to install the server counterparts as you may want to use the same machine as both client and server at some point or another.
After installation, there is a couple of basic things that you need to take into account if you want to secure remote access to your SSH server. The following settings should be present in the /etc/ssh/sshd_configfile.
1. Change the port where the sshd daemon will listen on from 22 (the default value) to a high port (2000 or greater), but first make sure the chosen port is not being used.
For example, let’s suppose you choose port 2500. Use netstat in order to check whether the chosen port is being used or not:
# netstat -npltu | grep 2500
If netstat does not return anything, you can safely use port 2500 for sshd, and you should change the Port setting in the configuration file as follows:
Port 2500
2. Only allow protocol 2:
Protocol 2
3. Configure the authentication timeout to 2 minutes, do not allow root logins, and restrict to a minimum the list of users which are allowed to login via ssh:
LoginGraceTime 2m PermitRootLogin no AllowUsers gacanepa
4. If possible, use key-based instead of password authentication:
PasswordAuthentication no RSAAuthentication yes PubkeyAuthentication yes
This assumes that you have already created a key pair with your user name on your client machine and copied it to your server as explained here.
Configuring Networking and Name Resolution
1. Every system administrator should be well acquainted with the following system-wide configuration files:
- /etc/hosts is used to resolve names <—> IPs in small networks.
Every line in the /etc/hosts file has the following structure:
IP address - Hostname - FQDN
For example,
192.168.0.10 laptop laptop.gabrielcanepa.com.ar
2. /etc/resolv.conf specifies the IP addresses of DNS servers and the search domain, which is used for completing a given query name to a fully qualified domain name when no domain suffix is supplied.
Under normal circumstances, you don’t need to edit this file as it is managed by the system. However, should you want to change DNS servers, be advised that you need to stick to the following structure in each line:
nameserver - IP address
For example,
nameserver 8.8.8.8
3. 3. /etc/host.conf specifies the methods and the order by which hostnames are resolved within a network. In other words, tells the name resolver which services to use, and in what order.
Although this file has several options, the most common and basic setup includes a line as follows:
order bind,hosts
Which indicates that the resolver should first look in the nameservers specified in resolv.conf and then to the /etc/hosts file for name resolution.
4. /etc/sysconfig/network contains routing and global host information for all network interfaces. The following values may be used:
NETWORKING=yes|no HOSTNAME=value
Where value should be the Fully Qualified Domain Name (FQDN).
GATEWAY=XXX.XXX.XXX.XXX
Where XXX.XXX.XXX.XXX is the IP address of the network’s gateway.
GATEWAYDEV=value
In a machine with multiple NICs, value is the gateway device, such as enp0s3.
5. Files inside /etc/sysconfig/network-scripts (network adapters configuration files).
Inside the directory mentioned previously, you will find several plain text files named.
ifcfg-name
Where name is the name of the NIC as returned by ip link show:

Check Network Link Status
For example:
Network Files
Other than for the loopback interface, you can expect a similar configuration for your NICs. Note that some variables, if set, will override those present in /etc/sysconfig/network for this particular interface. Each line is commented for clarification in this article but in the actual file you should avoid comments:
HWADDR=08:00:27:4E:59:37 # The MAC address of the NIC TYPE=Ethernet # Type of connection BOOTPROTO=static # This indicates that this NIC has been assigned a static IP. If this variable was set to dhcp, the NIC will be assigned an IP address by a DHCP server and thus the next two lines should not be present in that case. IPADDR=192.168.0.18 NETMASK=255.255.255.0 GATEWAY=192.168.0.1 NM_CONTROLLED=no # Should be added to the Ethernet interface to prevent NetworkManager from changing the file. NAME=enp0s3 UUID=14033805-98ef-4049-bc7b-d4bea76ed2eb ONBOOT=yes # The operating system should bring up this NIC during boot
Setting Hostnames
In Red Hat Enterprise Linux 7, the hostnamectl command is used to both query and set the system’s hostname.
To display the current hostname, type:
# hostnamectl status
Check System Hostname
To change the hostname, use
# hostnamectl set-hostname [new hostname]
For example,
# hostnamectl set-hostname cinderella
For the changes to take effect you will need to restart the hostnamed daemon (that way you will not have to log off and on again in order to apply the change):
# systemctl restart systemd-hostnamed

Set System Hostname
In addition, RHEL 7 also includes the nmcli utility that can be used for the same purpose. To display the hostname, run:
# nmcli general hostname
and to change it:
# nmcli general hostname [new hostname]
For example,
# nmcli general hostname rhel7

Set Hostname Using nmcli Command
Starting Network Services on Boot
To wrap up, let us see how we can ensure that network services are started automatically on boot. In simple terms, this is done by creating symlinks to certain files specified in the [Install] section of the service configuration files.
In the case of firewalld (/usr/lib/systemd/system/firewalld.service):
[Install] WantedBy=basic.target Alias=dbus-org.fedoraproject.FirewallD1.service
To enable the service:
# systemctl enable firewalld
On the other hand, disabling firewalld entitles removing the symlinks:
# systemctl disable firewalld

Enable Service at System Boot
Conclusion
In this article we have summarized how to install and secure connections via SSH to a RHEL server, how to change its name, and finally how to ensure that network services are started on boot. If you notice that a certain service has failed to start properly, you can use systemctl status -l [service] and journalctl -xn to troubleshoot it.
Feel free to let us know what you think about this article using the comment form below. Questions are also welcome. We look forward to hearing from you!
RHCSA Series: Installing, Configuring and Securing a Web and FTP Server – Part 9
A web server (also known as a HTTP server) is a service that handles content (most commonly web pages, but other types of documents as well) over to a client in a network.
A FTP server is one of the oldest and most commonly used resources (even to this day) to make files available to clients on a network in cases where no authentication is necessary since FTP uses username and passwordwithout encryption.
The web server available in RHEL 7 is version 2.4 of the Apache HTTP Server. As for the FTP server, we will use the Very Secure Ftp Daemon (aka vsftpd) to establish connections secured by TLS.

RHCSA: Installing, Configuring and Securing Apache and FTP – Part 9
In this article we will explain how to install, configure, and secure a web server and a FTP server in RHEL 7.
Installing Apache and FTP Server
In this guide we will use a RHEL 7 server with a static IP address of 192.168.0.18/24. To install Apache and VSFTPD, run the following command:
# yum update && yum install httpd vsftpd
When the installation completes, both services will be disabled initially, so we need to start them manually for the time being and enable them to start automatically beginning with the next boot:
# systemctl start httpd # systemctl enable httpd # systemctl start vsftpd # systemctl enable vsftpd
In addition, we have to open ports 80 and 21, where the web and ftp daemons are listening, respectively, in order to allow access to those services from the outside:
# firewall-cmd --zone=public --add-port=80/tcp --permanent # firewall-cmd --zone=public --add-service=ftp --permanent # firewall-cmd --reload
To confirm that the web server is working properly, fire up your browser and enter the IP of the server. You should see the test page:

Confirm Apache Web Server
As for the ftp server, we will have to configure it further, which we will do in a minute, before confirming that it’s working as expected.
Configuring and Securing Apache Web Server
The main configuration file for Apache is located in /etc/httpd/conf/httpd.conf, but it may rely on other files present inside /etc/httpd/conf.d.
Although the default configuration should be sufficient for most cases, it’s a good idea to become familiar with all the available options as described in the official documentation.
As always, make a backup copy of the main configuration file before editing it:
# cp /etc/httpd/conf/httpd.conf /etc/httpd/conf/httpd.conf.$(date +%Y%m%d)
Then open it with your preferred text editor and look for the following variables:
- ServerRoot: the directory where the server’s configuration, error, and log files are kept.
- Listen: instructs Apache to listen on specific IP address and / or ports.
- Include: allows the inclusion of other configuration files, which must exist. Otherwise, the server will fail, as opposed to the IncludeOptional directive, which is silently ignored if the specified configuration files do not exist.
- User and Group: the name of the user/group to run the httpd service as.
- DocumentRoot: The directory out of which Apache will serve your documents. By default, all requests are taken from this directory, but symbolic links and aliases may be used to point to other locations.
- ServerName: this directive sets the hostname (or IP address) and port that the server uses to identify itself.
The first security measure will consist of creating a dedicated user and group (i.e. tecmint/tecmint) to run the web server as and changing the default port to a higher one (9000 in this case):
ServerRoot "/etc/httpd" Listen 192.168.0.18:9000 User tecmint Group tecmint DocumentRoot "/var/www/html" ServerName 192.168.0.18:9000
You can test the configuration file with.
# apachectl configtest
and if everything is OK, then restart the web server.
# systemctl restart httpd
and don’t forget to enable the new port (and disable the old one) in the firewall:
# firewall-cmd --zone=public --remove-port=80/tcp --permanent # firewall-cmd --zone=public --add-port=9000/tcp --permanent # firewall-cmd --reload
Note that, due to SELinux policies, you can only use the ports returned by
# semanage port -l | grep -w '^http_port_t'
for the web server.
If you want to use another port (i.e. TCP port 8100), you will have to add it to SELinux port context for the httpdservice:
# semanage port -a -t http_port_t -p tcp 8100

Add Apache Port to SELinux Policies
To further secure your Apache installation, follow these steps:
1. The user Apache is running as should not have access to a shell:
# usermod -s /sbin/nologin tecmint
2. Disable directory listing in order to prevent the browser from displaying the contents of a directory if there is no index.html present in that directory.
Edit /etc/httpd/conf/httpd.conf (and the configuration files for virtual hosts, if any) and make sure that the Options directive, both at the top and at Directory block levels, is set to None:
Options None
3. Hide information about the web server and the operating system in HTTP responses. Edit /etc/httpd/conf/httpd.conf as follows:
ServerTokens Prod ServerSignature Off
Now you are ready to start serving content from your /var/www/html directory.
Configuring and Securing FTP Server
As in the case of Apache, the main configuration file for Vsftpd (/etc/vsftpd/vsftpd.conf) is well commented and while the default configuration should suffice for most applications, you should become acquainted with the documentation and the man page (man vsftpd.conf) in order to operate the ftp server more efficiently (I can’t emphasize that enough!).
In our case, these are the directives used:
anonymous_enable=NO local_enable=YES write_enable=YES local_umask=022 dirmessage_enable=YES xferlog_enable=YES connect_from_port_20=YES xferlog_std_format=YES chroot_local_user=YES allow_writeable_chroot=YES listen=NO listen_ipv6=YES pam_service_name=vsftpd userlist_enable=YES tcp_wrappers=YES
By using chroot_local_user=YES, local users will be (by default) placed in a chroot’ed jail in their home directory right after login. This means that local users will not be able to access any files outside their corresponding home directories.
Finally, to allow ftp to read files in the user’s home directory, set the following SELinux boolean:
# setsebool -P ftp_home_dir on
You can now connect to the ftp server using a client such as Filezilla:

Check FTP Connection
Note that the /var/log/xferlog log records downloads and uploads, which concur with the above directory listing:

Monitor FTP Download and Upload
Read Also: Limit FTP Network Bandwidth Used by Applications in a Linux System with Trickle
Summary
In this tutorial we have explained how to set up a web and a ftp server. Due to the vastness of the subject, it is not possible to cover all the aspects of these topics (i.e. virtual web hosts). Thus, I recommend you also check other excellent articles in this website about Apache.
RHCSA Series: Yum Package Management, Automating Tasks with Cron and Monitoring System Logs – Part 10
In this article we will review how to install, update, and remove packages in Red Hat Enterprise Linux 7. We will also cover how to automate tasks using cron, and will finish this guide explaining how to locate and interpret system logs files with the focus of teaching you why all of these are essential skills for every system administrator.

RHCSA: Yum Package Management, Cron Job Scheduling and Log Monitoring – Part 10
Managing Packages Via Yum
To install a package along with all its dependencies that are not already installed, you will use:
# yum -y install package_name(s)
Where package_name(s) represent at least one real package name.
For example, to install httpd and mlocate (in that order), type.
# yum -y install httpd mlocate
Note: That the letter y in the example above bypasses the confirmation prompts that yum presents before performing the actual download and installation of the requested programs. You can leave it out if you want.
By default, yum will install the package with the architecture that matches the OS architecture, unless overridden by appending the package architecture to its name.
For example, on a 64 bit system, yum install package will install the x86_64 version of package, whereas yum install package.x86 (if available) will install the 32-bit one.
There will be times when you want to install a package but don’t know its exact name. The search all or searchoptions can search the currently enabled repositories for a certain keyword in the package name and/or in its description as well, respectively.
For example,
# yum search log
will search the installed repositories for packages with the word log in their names and summaries, whereas
# yum search all log
will look for the same keyword in the package description and url fields as well.
Once the search returns a package listing, you may want to display further information about some of them before installing. That is when the info option will come in handy:
# yum info logwatch

Search Package Information
You can regularly check for updates with the following command:
# yum check-update
The above command will return all the installed packages for which an update is available. In the example shown in the image below, only rhel-7-server-rpms has an update available:

Check For Package Updates
You can then update that package alone with,
# yum update rhel-7-server-rpms
If there are several packages that can be updated, yum update will update all of them at once.
Now what happens when you know the name of an executable, such as ps2pdf, but don’t know which package provides it? You can find out with yum whatprovides “*/[executable]”:
# yum whatprovides “*/ps2pdf”
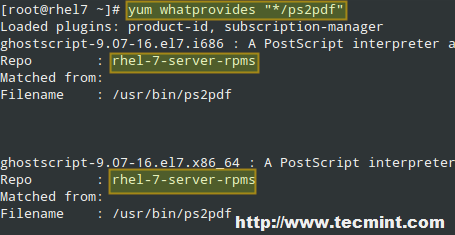
Find Package Belongs to Which Package
Now, when it comes to removing a package, you can do so with yum remove package. Easy, huh? This goes to show that yum is a complete and powerful package manager.
# yum remove httpd
Read Also: 20 Yum Commands to Manage RHEL 7 Package Management
Good Old Plain RPM
RPM (aka RPM Package Manager, or originally RedHat Package Manager) can also be used to install or update packages when they come in form of standalone .rpm packages.
It is often utilized with the -Uvh flags to indicate that it should install the package if it’s not already present or attempt to update it if it’s installed (-U), producing a verbose output (-v) and a progress bar with hash marks (-h) while the operation is being performed. For example,
# rpm -Uvh package.rpm
Another typical use of rpm is to produce a list of currently installed packages with code>rpm -qa (short for query all):
# rpm -qa

Query All RPM Packages
Read Also: 20 RPM Commands to Install Packages in RHEL 7
Scheduling Tasks using Cron
Linux and other Unix-like operating systems include a tool called cron that allows you to schedule tasks (i.e. commands or shell scripts) to run on a periodic basis. Cron checks every minute the /var/spool/cron directory for files which are named after accounts in /etc/passwd.
When executing commands, any output is mailed to the owner of the crontab (or to the user specified in the MAILTO environment variable in the /etc/crontab, if it exists).
Crontab files (which are created by typing crontab -e and pressing Enter) have the following format:

Crontab Entries
Thus, if we want to update the local file database (which is used by locate to find files by name or pattern) every second day of the month at 2:15 am, we need to add the following crontab entry:
15 02 2 * * /bin/updatedb
The above crontab entry reads, “Run /bin/updatedb on the second day of the month, every month of the year, regardless of the day of the week, at 2:15 am”. As I’m sure you already guessed, the star symbol is used as a wildcard character.
After adding a cron job, you can see that a file named root was added inside /var/spool/cron, as we mentioned earlier. That file lists all the tasks that the crond daemon should run:
# ls -l /var/spool/cron

Check All Cron Jobs
In the above image, the current user’s crontab can be displayed either using cat /var/spool/cron/root or,
# crontab -l
If you need to run a task on a more fine-grained basis (for example, twice a day or three times each month), cron can also help you to do that.
For example, to run /my/script on the 1st and 15th of each month and send any output to /dev/null, you can add two crontab entries as follows:
01 00 1 * * /myscript > /dev/null 2>&1 01 00 15 * * /my/script > /dev/null 2>&1
But in order for the task to be easier to maintain, you can combine both entries into one:
01 00 1,15 * * /my/script > /dev/null 2>&1
Following the previous example, we can run /my/other/script at 1:30 am on the first day of the month every three months:
30 01 1 1,4,7,10 * /my/other/script > /dev/null 2>&1
But when you have to repeat a certain task every “x” minutes, hours, days, or months, you can divide the right position by the desired frequency. The following crontab entry has the exact same meaning as the previous one:
30 01 1 */3 * /my/other/script > /dev/null 2>&1
Or perhaps you need to run a certain job on a fixed frequency or after the system boots, for example. You can use one of the following string instead of the five fields to indicate the exact time when you want your job to run:
@reboot Run when the system boots. @yearly Run once a year, same as 00 00 1 1 *. @monthly Run once a month, same as 00 00 1 * *. @weekly Run once a week, same as 00 00 * * 0. @daily Run once a day, same as 00 00 * * *. @hourly Run once an hour, same as 00 * * * *.
Read Also: 11 Commands to Schedule Cron Jobs in RHEL 7
Locating and Checking Logs
System logs are located (and rotated) inside the /var/log directory. According to the Linux Filesystem Hierarchy Standard, this directory contains miscellaneous log files, which are written to it or an appropriate subdirectory (such as audit, httpd, or samba in the image below) by the corresponding daemons during system operation:
# ls /var/log

Linux Log Files Location
Other interesting logs are dmesg (contains all messages from kernel ring buffer), secure (logs connection attempts that require user authentication), messages (system-wide messages) and wtmp (records of all user logins and logouts).
Logs are very important in that they allow you to have a glimpse of what is going on at all times in your system, and what has happened in the past. They represent a priceless tool to troubleshoot and monitor a Linux server, and thus are often used with the tail -f command to display events, in real time, as they happen and are recorded in a log.
For example, if you want to display kernel-related events, type the following command:
# tail -f /var/log/dmesg
Same if you want to view access to your web server:
# tail -f /var/log/httpd/access.log
Summary
If you know how to efficiently manage packages, schedule tasks, and where to look for information about the current and past operation of your system you can rest assure that you will not run into surprises very often. I hope this article has helped you learn or refresh your knowledge about these basic skills.
Don’t hesitate to drop us a line using the contact form below if you have any questions or comments.
RHCSA Series: Firewall Essentials and Network Traffic Control Using FirewallD and Iptables – Part 11
In simple words, a firewall is a security system that controls the incoming and outgoing traffic in a network based on a set of predefined rules (such as the packet destination / source or type of traffic, for example).

RHCSA: Control Network Traffic with FirewallD and Iptables – Part 11
In this article we will review the basics of firewalld, the default dynamic firewall daemon in Red Hat Enterprise Linux 7, and iptables service, the legacy firewall service for Linux, with which most system and network administrators are well acquainted, and which is also available in RHEL 7.
A Comparison Between FirewallD and Iptables
Under the hood, both firewalld and the iptables service talk to the netfilter framework in the kernel through the same interface, not surprisingly, the iptables command. However, as opposed to the iptables service, firewalld can change the settings during normal system operation without existing connections being lost.
Firewalld should be installed by default in your RHEL system, though it may not be running. You can verify with the following commands (firewall-config is the user interface configuration tool):
# yum info firewalld firewall-config

Check FirewallD Information
and,
# systemctl status -l firewalld.service

Check FirewallD Status
On the other hand, the iptables service is not included by default, but can be installed through.
# yum update && yum install iptables-services
Both daemons can be started and enabled to start on boot with the usual systemd commands:
# systemctl start firewalld.service | iptables-service.service # systemctl enable firewalld.service | iptables-service.service
Read Also: Useful Commands to Manage Systemd Services
As for the configuration files, the iptables service uses /etc/sysconfig/iptables (which will not exist if the package is not installed in your system). On a RHEL 7 box used as a cluster node, this file looks as follows:

Iptables Firewall Configuration
Whereas firewalld store its configuration across two directories, /usr/lib/firewalld and /etc/firewalld:
# ls /usr/lib/firewalld /etc/firewalld

FirewallD Configuration
We will examine these configuration files further later in this article, after we add a few rules here and there. By now it will suffice to remind you that you can always find more information about both tools with.
# man firewalld.conf # man firewall-cmd # man iptables
Other than that, remember to take a look at Reviewing Essential Commands & System Documentation – Part 1of the current series, where I described several sources where you can get information about the packages installed on your RHEL 7 system.
Using Iptables to Control Network Traffic
You may want to refer to Configure Iptables Firewall – Part 8 of the Linux Foundation Certified Engineer (LFCE) series to refresh your memory about iptables internals before proceeding further. Thus, we will be able to jump in right into the examples.
Example 1: Allowing both incoming and outgoing web traffic
TCP ports 80 and 443 are the default ports used by the Apache web server to handle normal (HTTP) and secure (HTTPS) web traffic. You can allow incoming and outgoing web traffic through both ports on the enp0s3interface as follows:
# iptables -A INPUT -i enp0s3 -p tcp --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT # iptables -A OUTPUT -o enp0s3 -p tcp --sport 80 -m state --state ESTABLISHED -j ACCEPT # iptables -A INPUT -i enp0s3 -p tcp --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT # iptables -A OUTPUT -o enp0s3 -p tcp --sport 443 -m state --state ESTABLISHED -j ACCEPT
Example 2: Block all (or some) incoming connections from a specific network
There may be times when you need to block all (or some) type of traffic originating from a specific network, say 192.168.1.0/24 for example:
# iptables -I INPUT -s 192.168.1.0/24 -j DROP
will drop all packages coming from the 192.168.1.0/24 network, whereas,
# iptables -A INPUT -s 192.168.1.0/24 --dport 22 -j ACCEPT
will only allow incoming traffic through port 22.
Example 3: Redirect incoming traffic to another destination
If you use your RHEL 7 box not only as a software firewall, but also as the actual hardware-based one, so that it sits between two distinct networks, IP forwarding must have been already enabled in your system. If not, you need to edit /etc/sysctl.conf and set the value of net.ipv4.ip_forward to 1, as follows:
net.ipv4.ip_forward = 1
then save the change, close your text editor and finally run the following command to apply the change:
# sysctl -p /etc/sysctl.conf
For example, you may have a printer installed at an internal box with IP 192.168.0.10, with the CUPS service listening on port 631 (both on the print server and on your firewall). In order to forward print requests from clients on the other side of the firewall, you should add the following iptables rule:
# iptables -t nat -A PREROUTING -i enp0s3 -p tcp --dport 631 -j DNAT --to 192.168.0.10:631
Please keep in mind that iptables reads its rules sequentially, so make sure the default policies or later rules do not override those outlined in the examples above.
Getting Started with FirewallD
One of the changes introduced with firewalld are zones. This concept allows to separate networks into different zones level of trust the user has decided to place on the devices and traffic within that network.
To list the active zones:
# firewall-cmd --get-active-zones
In the example below, the public zone is active, and the enp0s3 interface has been assigned to it automatically. To view all the information about a particular zone:
# firewall-cmd --zone=public --list-all
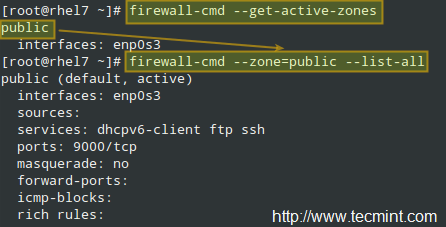
List all FirewallD Zones
Since you can read more about zones in the RHEL 7 Security guide, we will only list some specific examples here.
Example 4: Allowing services through the firewall
To get a list of the supported services, use.
# firewall-cmd --get-services

List All Supported Services
To allow http and https web traffic through the firewall, effective immediately and on subsequent boots:
# firewall-cmd --zone=MyZone --add-service=http # firewall-cmd --zone=MyZone --permanent --add-service=http # firewall-cmd --zone=MyZone --add-service=https # firewall-cmd --zone=MyZone --permanent --add-service=https # firewall-cmd --reload
If code>–zone is omitted, the default zone (you can check with firewall-cmd –get-default-zone) is used.
To remove the rule, replace the word add with remove in the above commands.
Example 5: IP / Port forwarding
First off, you need to find out if masquerading is enabled for the desired zone:
# firewall-cmd --zone=MyZone --query-masquerade
In the image below, we can see that masquerading is enabled for the external zone, but not for public:

Check Masquerading Status
You can either enable masquerading for public:
# firewall-cmd --zone=public --add-masquerade
or use masquerading in external. Here’s what we would do to replicate Example 3 with firewalld:
# firewall-cmd --zone=external --add-forward-port=port=631:proto=tcp:toport=631:toaddr=192.168.0.10
And don’t forget to reload the firewall.
You can find further examples on Part 9 of the RHCSA series, where we explained how to allow or disable the ports that are usually used by a web server and a ftp server, and how to change the corresponding rule when the default port for those services are changed. In addition, you may want to refer to the firewalld wiki for further examples.
Read Also: Useful FirewallD Examples to Configure Firewall in RHEL 7
Conclusion
In this article we have explained what a firewall is, what are the available services to implement one in RHEL 7, and provided a few examples that can help you get started with this task. If you have any comments, suggestions, or questions, feel free to let us know using the form below. Thank you in advance!
RHCSA Series: Automate RHEL 7 Installations Using ‘Kickstart’ – Part 12
Linux servers are rarely standalone boxes. Whether it is in a datacenter or in a lab environment, chances are that you have had to install several machines that will interact one with another in some way. If you multiply the time that it takes to install Red Hat Enterprise Linux 7 manually on a single server by the number of boxes that you need to set up, this can lead to a rather lengthy effort that can be avoided through the use of an unattended installation tool known as kickstart.
In this article we will show what you need to use kickstart utility so that you can forget about babysitting servers during the installation process.

RHCSA: Automatic Kickstart Installation of RHEL 7
Introducing Kickstart and Automated Installations
Kickstart is an automated installation method used primarily by Red Hat Enterprise Linux (and other Fedora spin-offs, such as CentOS, Oracle Linux, etc.) to execute unattended operating system installation and configuration. Thus, kickstart installations allow system administrators to have identical systems, as far as installed package groups and system configuration are concerned, while sparing them the hassle of having to manually install each of them.
Preparing for a Kickstart Installation
To perform a kickstart installation, we need to follow these steps:
1. Create a Kickstart file, a plain text file with several predefined configuration options.
2. Make the Kickstart file available on removable media, a hard drive or a network location. The client will use the rhel-server-7.0-x86_64-boot.iso file, whereas you will need to make the full ISO image (rhel-server-7.0-x86_64-dvd.iso) available from a network resource, such as a HTTP of FTP server (in our present case, we will use another RHEL 7 box with IP 192.168.0.18).
3. Start the Kickstart installation
To create a kickstart file, login to your Red Hat Customer Portal account, and use the Kickstart configuration tool to choose the desired installation options. Read each one of them carefully before scrolling down, and choose what best fits your needs:

Kickstart Configuration Tool
If you specify that the installation should be performed either through HTTP, FTP, or NFS, make sure the firewall on the server allows those services.
Although you can use the Red Hat online tool to create a kickstart file, you can also create it manually using the following lines as reference. You will notice, for example, that the installation process will be in English, using the latin american keyboard layout and the America/Argentina/San_Luis time zone:
lang en_US keyboard la-latin1 timezone America/Argentina/San_Luis --isUtc rootpw $1$5sOtDvRo$In4KTmX7OmcOW9HUvWtfn0 --iscrypted #platform x86, AMD64, or Intel EM64T text url --url=http://192.168.0.18//kickstart/media bootloader --location=mbr --append="rhgb quiet crashkernel=auto" zerombr clearpart --all --initlabel autopart auth --passalgo=sha512 --useshadow selinux --enforcing firewall --enabled firstboot --disable %packages @base @backup-server @print-server %end
In the online configuration tool, use 192.168.0.18 for HTTP Server and /kickstart/tecmint.bin for HTTP Directory in the Installation section after selecting HTTP as installation source. Finally, click the Downloadbutton at the right top corner to download the kickstart file.
In the kickstart sample file above, you need to pay careful attention to.
url --url=http://192.168.0.18//kickstart/media
That directory is where you need to extract the contents of the DVD or ISO installation media. Before doing that, we will mount the ISO installation file in /media/rhel as a loop device:
# mount -o loop /var/www/html/kickstart/rhel-server-7.0-x86_64-dvd.iso /media/rhel
![]()
Mount RHEL ISO Image
Next, copy all the contents of /media/rhel to /var/www/html/kickstart/media:
# cp -R /media/rhel /var/www/html/kickstart/media
When you’re done, the directory listing and disk usage of /var/www/html/kickstart/media should look as follows:

Kickstart Media Files
Now we’re ready to kick off the kickstart installation.
Regardless of how you choose to create the kickstart file, it’s always a good idea to check its syntax before proceeding with the installation. To do that, install the pykickstart package.
# yum update && yum install pykickstart
And then use the ksvalidator utility to check the file:
# ksvalidator /var/www/html/kickstart/tecmint.bin
If the syntax is correct, you will not get any output, whereas if there’s an error in the file, you will get a warning notice indicating the line where the syntax is not correct or unknown.
Performing a Kickstart Installation
To start, boot your client using the rhel-server-7.0-x86_64-boot.iso file. When the initial screen appears, select Install Red Hat Enterprise Linux 7.0 and press the Tab key to append the following stanza and press Enter:
# inst.ks=http://192.168.0.18/kickstart/tecmint.bin

RHEL Kickstart Installation
Where tecmint.bin is the kickstart file created earlier.
When you press Enter, the automated installation will begin, and you will see the list of packages that are being installed (the number and the names will differ depending on your choice of programs and package groups):
Automatic Kickstart Installation of RHEL 7
When the automated process ends, you will be prompted to remove the installation media and then you will be able to boot into your newly installed system:

RHEL 7 Boot Screen
Although you can create your kickstart files manually as we mentioned earlier, you should consider using the recommended approach whenever possible. You can either use the online configuration tool, or the anaconda-ks.cfg file that is created by the installation process in root’s home directory.
This file actually is a kickstart file, so you may want to install the first box manually with all the desired options (maybe modify the logical volumes layout or the file system on top of each one) and then use the resulting anaconda-ks.cfg file to automate the installation of the rest.
In addition, using the online configuration tool or the anaconda-ks.cfg file to guide future installations will allow you to perform them using an encrypted root password out-of-the-box.
Conclusion
Now that you know how to create kickstart files and how to use them to automate the installation of Red Hat Enterprise Linux 7 servers, you can forget about babysitting the installation process. This will give you time to do other things, or perhaps some leisure time if you’re lucky.
Either way, let us know what you think about this article using the form below. Questions are also welcome!
Read Also: Automated Installations of Multiple RHEL/CentOS 7 Distributions using PXE and Kickstart
RHCSA Series: Mandatory Access Control Essentials with SELinux in RHEL 7 – Part 13
During this series we have explored in detail at least two access control methods: standard ugo/rwxpermissions (Manage Users and Groups – Part 3) and access control lists (Configure ACL’s on File Systems – Part 7).

RHCSA Exam: SELinux Essentials and Control FileSystem Access
Although necessary as first level permissions and access control mechanisms, they have some limitations that are addressed by Security Enhanced Linux (aka SELinux for short).
One of such limitations is that a user can expose a file or directory to a security breach through a poorly elaborated chmod command and thus cause an unexpected propagation of access rights. As a result, any process started by that user can do as it pleases with the files owned by the user, where finally a malicious or otherwise compromised software can achieve root-level access to the entire system.
With those limitations in mind, the United States National Security Agency (NSA) first devised SELinux, a flexible mandatory access control method, to restrict the ability of processes to access or perform other operations on system objects (such as files, directories, network ports, etc) to the least permission model, which can be modified later as needed. In few words, each element of the system is given only the access required to function.
In RHEL 7, SELinux is incorporated into the kernel itself and is enabled in Enforcing mode by default. In this article we will explain briefly the basic concepts associated with SELinux and its operation.
SELinux Modes
SELinux can operate in three different ways:
- Enforcing: SELinux denies access based on SELinux policy rules, a set of guidelines that control the security engine.
- Permissive: SELinux does not deny access, but denials are logged for actions that would have been denied if running in enforcing mode.
- Disabled (self-explanatory).
The getenforce command displays the current mode of SELinux, whereas setenforce (followed by a 1 or a 0) is used to change the mode to Enforcing or Permissive, respectively, during the current session only.
In order to achieve persistence across logouts and reboots, you will need to edit the /etc/selinux/configfile and set the SELINUX variable to either enforcing, permissive, or disabled:
# getenforce # setenforce 0 # getenforce # setenforce 1 # getenforce # cat /etc/selinux/config

Set SELinux Mode
Typically you will use setenforce to toggle between SELinux modes (enforcing to permissive and back) as a first troubleshooting step. If SELinux is currently set to enforcing while you’re experiencing a certain problem, and the same goes away when you set it to permissive, you can be confident you’re looking at a SELinux permissions issue.
SELinux Contexts
A SELinux context consists of an access control environment where decisions are made based on SELinux user, role, and type (and optionally a level):
- A SELinux user complements a regular Linux user account by mapping it to a SELinux user account, which in turn is used in the SELinux context for processes in that session, in order to explicitly define their allowed roles and levels.
- The concept of role acts as an intermediary between domains and SELinux users in that it defines which process domains and file types can be accessed. This will shield your system against vulnerability to privilege escalation attacks.
- A type defines an SELinux file type or an SELinux process domain. Under normal circumstances, processes are prevented from accessing files that other processes use, and and from accessing other processes, thus access is only allowed if a specific SELinux policy rule exists that allows it.
Let’s see how all of that works through the following examples.
EXAMPLE 1: Changing the default port for the sshd daemon
In Securing SSH – Part 8 we explained that changing the default port where sshd listens on is one of the first security measures to secure your server against external attacks. Let’s edit the /etc/ssh/sshd_config file and set the port to 9999:
Port 9999
Save the changes, and restart sshd:
# systemctl restart sshd # systemctl status sshd

Restart SSH Service
As you can see, sshd has failed to start. But what happened?
A quick inspection of /var/log/audit/audit.log indicates that sshd has been denied permissions to start on port 9999 (SELinux log messages include the word “AVC” so that they might be easily identified from other messages) because that is a reserved port for the JBoss Management service:
# cat /var/log/audit/audit.log | grep AVC | tail -1

Inspect SSH Logs
At this point you could disable SELinux (but don’t!) as explained earlier and try to start sshd again, and it should work. However, the semanage utility can tell us what we need to change in order for us to be able to start sshd in whatever port we choose without issues.
Run,
# semanage port -l | grep ssh
to get a list of the ports where SELinux allows sshd to listen on.

Semanage Tool
So let’s change the port in /etc/ssh/sshd_config to Port 9998, add the port to the ssh_port_t context, and then restart the service:
# semanage port -a -t ssh_port_t -p tcp 9998 # systemctl restart sshd # systemctl is-active sshd

Semanage Add Port
As you can see, the service was started successfully this time. This example illustrates the fact that SELinux controls the TCP port number to its own port type internal definitions.
EXAMPLE 2: Allowing httpd to send access sendmail
This is an example of SELinux managing a process accessing another process. If you were to implement mod_security and mod_evasive along with Apache in your RHEL 7 server, you need to allow httpd to access sendmail in order to send a mail notification in the wake of a (D)DoS attack. In the following command, omit the -P flag if you do not want the change to be persistent across reboots.
# semanage boolean -1 | grep httpd_can_sendmail # setsebool -P httpd_can_sendmail 1 # semanage boolean -1 | grep httpd_can_sendmail

Allow Apache to Send Mails
As you can tell from the above example, SELinux boolean settings (or just booleans) are true / false rules embedded into SELinux policies. You can list all the booleans with semanage boolean -l, and alternatively pipe it to grep in order to filter the output.
EXAMPLE 3: Serving a static site from a directory other than the default one
Suppose you are serving a static website using a different directory than the default one (/var/www/html), say /websites (this could be the case if you’re storing your web files in a shared network drive, for example, and need to mount it at /websites).
a). Create an index.html file inside /websites with the following contents:
<html> <h2>SELinux test</h2> </html>
If you do,
# ls -lZ /websites/index.html
you will see that the index.html file has been labeled with the default_t SELinux type, which Apache can’t access:
![]()
Check SELinux File Permission
b). Change the DocumentRoot directive in /etc/httpd/conf/httpd.conf to /websites and don’t forget to update the corresponding Directory block. Then, restart Apache.
c). Browse to http://<web server IP address>, and you should get a 503 Forbidden HTTP response.
d). Next, change the label of /websites, recursively, to the httpd_sys_content_t type in order to grant Apache read-only access to that directory and its contents:
# semanage fcontext -a -t httpd_sys_content_t "/websites(/.*)?"
e). Finally, apply the SELinux policy created in d):
# restorecon -R -v /websites
Now restart Apache and browse to http://<web server IP address> again and you will see the html file displayed correctly:

Verify Apache Page
Summary
In this article we have gone through the basics of SELinux. Note that due to the vastness of the subject, a full detailed explanation is not possible in a single article, but we believe that the principles outlined in this guide will help you to move on to more advanced topics should you wish to do so.
If I may, let me recommend two essential resources to start with: the NSA SELinux page and the RHEL 7 SELinux User’s and Administrator’s guide.
Don’t hesitate to let us know if you have any questions or comments.
RHCSA Series: Setting Up LDAP-based Authentication in RHEL 7 – Part 14
We will begin this article by outlining some LDAP basics (what it is, where it is used and why) and show how to set up a LDAP server and configure a client to authenticate against it using Red Hat Enterprise Linux 7 systems.

RHCSA Series: Setup LDAP Server and Client Authentication – Part 14
As we will see, there are several other possible application scenarios, but in this guide we will focus entirely on LDAP-based authentication. In addition, please keep in mind that due to the vastness of the subject, we will only cover its basics here, but you can refer to the documentation outlined in the summary for more in-depth details.
For the same reason, you will note that I have decided to leave out several references to man pages of LDAP tools for the sake of brevity, but the corresponding explanations are at a fingertip’s distance (man ldapadd, for example).
That said, let’s get started.
Our Testing Environment
Our test environment consists of two RHEL 7 boxes:
Server: 192.168.0.18. FQDN: rhel7.mydomain.com Client: 192.168.0.20. FQDN: ldapclient.mydomain.com
If you want, you can use the machine installed in Part 12: Automate RHEL 7 installations using Kickstart as client.
What is LDAP?
LDAP stands for Lightweight Directory Access Protocol and consists in a set of protocols that allows a client to access, over a network, centrally stored information (such as a directory of login shells, absolute paths to home directories, and other typical system user information, for example) that should be accessible from different places or available to a large number of end users (another example would be a directory of home addresses and phone numbers of all employees in a company).
Keeping such (and more) information centrally means it can be more easily maintained and accessed by everyone who has been granted permissions to use it.
The following diagram offers a simplified diagram of LDAP, and is described below in greater detail:
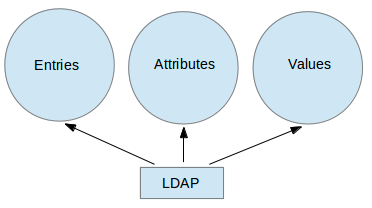
LDAP Diagram
Explanation of above diagram in detail.
- An entry in a LDAP directory represents a single unit or information and is uniquely identified by what is called a Distinguished Name.
- An attribute is a piece of information associated with an entry (for example, addresses, available contact phone numbers, and email addresses).
- Each attribute is assigned one or more values consisting in a space-separated list. A value that is unique per entry is called a Relative Distinguished Name.
That being said, let’s proceed with the server and client installations.
Installing and Configuring a LDAP Server and Client
In RHEL 7, LDAP is implemented by OpenLDAP. To install the server and client, use the following commands, respectively:
# yum update && yum install openldap openldap-clients openldap-servers # yum update && yum install openldap openldap-clients nss-pam-ldapd
Once the installation is complete, there are some things we look at. The following steps should be performed on the server alone, unless explicitly noted:
1. Make sure SELinux does not get in the way by enabling the following booleans persistently, both on the server and the client:
# setsebool -P allow_ypbind=0 authlogin_nsswitch_use_ldap=0
Where allow_ypbind is required for LDAP-based authentication, and authlogin_nsswitch_use_ldap may be needed by some applications.
2. Enable and start the service:
# systemctl enable slapd.service # systemctl start slapd.service
Keep in mind that you can also disable, restart, or stop the service with systemctl as well:
# systemctl disable slapd.service # systemctl restart slapd.service # systemctl stop slapd.service
3. Since the slapd service runs as the ldap user (which you can verify with ps -e -o pid,uname,comm | grep slapd), such user should own the /var/lib/ldap directory in order for the server to be able to modify entries created by administrative tools that can only be run as root (more on this in a minute).
Before changing the ownership of this directory recursively, copy the sample database configuration file for slapd into it:
# cp /usr/share/openldap-servers/DB_CONFIG.example /var/lib/ldap/DB_CONFIG # chown -R ldap:ldap /var/lib/ldap
4. Set up an OpenLDAP administrative user and assign a password:
# slappasswd
as shown in the next image:

Set LDAP Admin Password
and create an LDIF file (ldaprootpasswd.ldif) with the following contents:
dn: olcDatabase={0}config,cn=config
changetype: modify
add: olcRootPW
olcRootPW: {SSHA}PASSWORD
where:
- PASSWORD is the hashed string obtained earlier.
- cn=config indicates global config options.
- olcDatabase indicates a specific database instance name and can be typically found inside /etc/openldap/slapd.d/cn=config.
Referring to the theoretical background provided earlier, the ldaprootpasswd.ldif file will add an entry to the LDAP directory. In that entry, each line represents an attribute: value pair (where dn, changetype, add, and olcRootPW are the attributes and the strings to the right of each colon are their corresponding values).
You may want to keep this in mind as we proceed further, and please note that we are using the same Common Names (cn=) throughout the rest of this article, where each step depends on the previous one.
5. Now, add the corresponding LDAP entry by specifying the URI referring to the ldap server, where only the protocol/host/port fields are allowed.
# ldapadd -H ldapi:/// -f ldaprootpasswd.ldif
The output should be similar to:

LDAP Configuration
and import some basic LDAP definitions from the /etc/openldap/schema directory:
# for def in cosine.ldif nis.ldif inetorgperson.ldif; do ldapadd -H ldapi:/// -f /etc/openldap/schema/$def; done

LDAP Definitions
6. Have LDAP use your domain in its database.
Create another LDIF file, which we will call ldapdomain.ldif, with the following contents, replacing your domain (in the Domain Component dc=) and password as appropriate:
dn: olcDatabase={1}monitor,cn=config
changetype: modify
replace: olcAccess
olcAccess: {0}to * by dn.base="gidNumber=0+uidNumber=0,cn=peercred,cn=external,cn=auth"
read by dn.base="cn=Manager,dc=mydomain,dc=com" read by * none
dn: olcDatabase={2}hdb,cn=config
changetype: modify
replace: olcSuffix
olcSuffix: dc=mydomain,dc=com
dn: olcDatabase={2}hdb,cn=config
changetype: modify
replace: olcRootDN
olcRootDN: cn=Manager,dc=mydomain,dc=com
dn: olcDatabase={2}hdb,cn=config
changetype: modify
add: olcRootPW
olcRootPW: {SSHA}PASSWORD
dn: olcDatabase={2}hdb,cn=config
changetype: modify
add: olcAccess
olcAccess: {0}to attrs=userPassword,shadowLastChange by
dn="cn=Manager,dc=mydomain,dc=com" write by anonymous auth by self write by * none
olcAccess: {1}to dn.base="" by * read
olcAccess: {2}to * by dn="cn=Manager,dc=mydomain,dc=com" write by * read
Then load it as follows:
# ldapmodify -H ldapi:/// -f ldapdomain.ldif
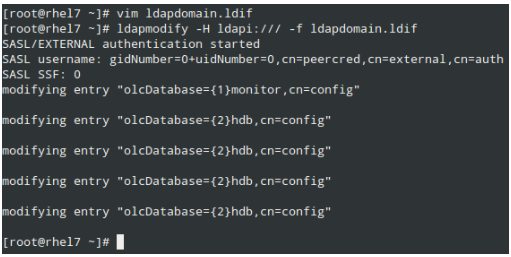
LDAP Domain Configuration
7. Now it’s time to add some entries to our LDAP directory. Attributes and values are separated by a colon (:)in the following file, which we’ll name baseldapdomain.ldif:
dn: dc=mydomain,dc=com objectClass: top objectClass: dcObject objectclass: organization o: mydomain com dc: mydomain dn: cn=Manager,dc=mydomain,dc=com objectClass: organizationalRole cn: Manager description: Directory Manager dn: ou=People,dc=mydomain,dc=com objectClass: organizationalUnit ou: People dn: ou=Group,dc=mydomain,dc=com objectClass: organizationalUnit ou: Group
Add the entries to the LDAP directory:
# ldapadd -x -D cn=Manager,dc=mydomain,dc=com -W -f baseldapdomain.ldif
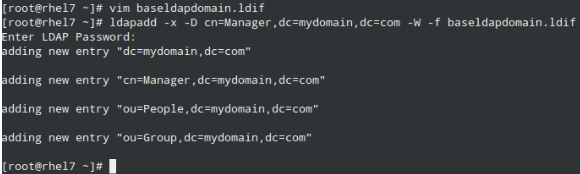
Add LDAP Domain Attributes and Values
8. Create a LDAP user called ldapuser (adduser ldapuser), then create the definitions for a LDAP group in ldapgroup.ldif.
# adduser ldapuser # vi ldapgroup.ldif
Add following content.
dn: cn=Manager,ou=Group,dc=mydomain,dc=com objectClass: top objectClass: posixGroup gidNumber: 1004
where gidNumber is the GID in /etc/group for ldapuser) and load it:
# ldapadd -x -W -D "cn=Manager,dc=mydomain,dc=com" -f ldapgroup.ldif
9. Add a LDIF file with the definitions for user ldapuser (ldapuser.ldif):
dn: uid=ldapuser,ou=People,dc=mydomain,dc=com
objectClass: top
objectClass: account
objectClass: posixAccount
objectClass: shadowAccount
cn: ldapuser
uid: ldapuser
uidNumber: 1004
gidNumber: 1004
homeDirectory: /home/ldapuser
userPassword: {SSHA}fiN0YqzbDuDI0Fpqq9UudWmjZQY28S3M
loginShell: /bin/bash
gecos: ldapuser
shadowLastChange: 0
shadowMax: 0
shadowWarning: 0
and load it:
# ldapadd -x -D cn=Manager,dc=mydomain,dc=com -W -f ldapuser.ldif

LDAP User Configuration
Likewise, you can delete the user entry you just created:
# ldapdelete -x -W -D cn=Manager,dc=mydomain,dc=com "uid=ldapuser,ou=People,dc=mydomain,dc=com"
10. Allow communication through the firewall:
# firewall-cmd --add-service=ldap
11. Last, but not least, enable the client to authenticate using LDAP.
To help us in this final step, we will use the authconfig utility (an interface for configuring system authentication resources).
Using the following command, the home directory for the requested user is created if it doesn’t exist after the authentication against the LDAP server succeeds:
# authconfig --enableldap --enableldapauth --ldapserver=rhel7.mydomain.com --ldapbasedn="dc=mydomain,dc=com" --enablemkhomedir --update

LDAP Client Configuration
Summary
In this article we have explained how to set up basic authentication against a LDAP server. To further configure the setup described in the present guide, please refer to Chapter 13 – LDAP Configuration in the RHEL 7 System administrator’s guide, paying special attention to the security settings using TLS.
Feel free to leave any questions you may have using the comment form below.
RHCSA Series: Essentials of Virtualization and Guest Administration with KVM – Part 15
If you look up the word virtualize in a dictionary, you will find that it means “to create a virtual (rather than actual) version of something”. In computing, the term virtualization refers to the possibility of running multiple operating systems simultaneously and isolated one from another, on top of the same physical (hardware) system, known in the virtualization schema as host.

RHCSA Series: Essentials of Virtualization and Guest Administration with KVM – Part 15
Through the use of the virtual machine monitor (also known as hypervisor), virtual machines (referred to as guests) are provided virtual resources (i.e. CPU, RAM, storage, network interfaces, to name a few) from the underlying hardware.
With that in mind, it is plain to see that one of the main advantages of virtualization is cost savings (in equipment and network infrastructure and in terms of maintenance effort) and a substantial reduction in the physical space required to accommodate all the necessary hardware.
Since this brief how-to cannot cover all virtualization methods, I encourage you to refer to the documentation listed in the summary for further details on the subject.
Please keep in mind that the present article is intended to be a starting point to learn the basics of virtualization in RHEL 7 using KVM (Kernel-based Virtual Machine) with command-line utilities, and not an in-depth discussion of the topic.
Verifying Hardware Requirements and Installing Packages
In order to set up virtualization, your CPU must support it. You can verify whether your system meets the requirements with the following command:
# grep -E 'svm|vmx' /proc/cpuinfo
In the following screenshot we can see that the current system (with an AMD microprocessor) supports virtualization, as indicated by svm. If we had an Intel-based processor, we would see vmx instead in the results of the above command.

Check KVM Support
In addition, you will need to have virtualization capabilities enabled in the firmware of your host (BIOS or UEFI).
Now install the necessary packages:
- qemu-kvm is an open source virtualizer that provides hardware emulation for the KVM hypervisor whereas qemu-img provides a command line tool for manipulating disk images.
- libvirt includes the tools to interact with the virtualization capabilities of the operating system.
- libvirt-python contains a module that permits applications written in Python to use the interface supplied by libvirt.
- libguestfs-tools: miscellaneous system administrator command line tools for virtual machines.
- virt-install: other command-line utilities for virtual machine administration.
# yum update && yum install qemu-kvm qemu-img libvirt libvirt-python libguestfs-tools virt-install
Once the installation completes, make sure you start and enable the libvirtd service:
# systemctl start libvirtd.service # systemctl enable libvirtd.service
By default, each virtual machine will only be able to communicate with the rest in the same physical server and with the host itself. To allow the guests to reach other machines inside our LAN and also the Internet, we need to set up a bridge interface in our host (say br0, for example) by,
1. adding the following line to our main NIC configuration (most likely /etc/sysconfig/network-scripts/ifcfg-enp0s3):
BRIDGE=br0
2. creating the configuration file for br0 (/etc/sysconfig/network-scripts/ifcfg-br0) with these contents (note that you may have to change the IP address, gateway address, and DNS information):
DEVICE=br0 TYPE=Bridge BOOTPROTO=static IPADDR=192.168.0.18 NETMASK=255.255.255.0 GATEWAY=192.168.0.1 NM_CONTROLLED=no DEFROUTE=yes PEERDNS=yes PEERROUTES=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_PEERDNS=yes IPV6_PEERROUTES=yes IPV6_FAILURE_FATAL=no NAME=br0 ONBOOT=yes DNS1=8.8.8.8 DNS2=8.8.4.4
3. finally, enabling packet forwarding by making, in /etc/sysctl.conf,
net.ipv4.ip_forward = 1
and loading the changes to the current kernel configuration:
# sysctl -p
Note that you may also need to tell firewalld that this kind of traffic should be allowed. Remember that you can refer to the article on that topic in this same series (Part 11: Network Traffic Control Using FirewallD and Iptables) if you need help to do that.
Creating VM Images
By default, VM images will be created to /var/lib/libvirt/images and you are strongly advised to not change this unless you really need to, know what you’re doing, and want to handle SELinux settings yourself (such topic is out of the scope of this tutorial but you can refer to Part 13 of the RHCSA series: Mandatory Access Control Essentials with SELinux if you want to refresh your memory).
This means that you need to make sure that you have allocated the necessary space in that filesystem to accommodate your virtual machines.
The following command will create a virtual machine named tecmint-virt01 with 1 virtual CPU, 1 GB (=1024 MB) of RAM, and 20 GB of disk space (represented by /var/lib/libvirt/images/tecmint-virt01.img) using the rhel-server-7.0-x86_64-dvd.iso image located inside /home/gacanepa/ISOs as installation media and the br0 as network bridge:
# virt-install \ --network bridge=br0 --name tecmint-virt01 \ --ram=1024 \ --vcpus=1 \ --disk path=/var/lib/libvirt/images/tecmint-virt01.img,size=20 \ --graphics none \ --cdrom /home/gacanepa/ISOs/rhel-server-7.0-x86_64-dvd.iso --extra-args="console=tty0 console=ttyS0,115200"
If the installation file was located in a HTTP server instead of an image stored in your disk, you will have to replace the –cdrom flag with –location and indicate the address of the online repository.
As for the –graphics none option, it tells the installer to perform the installation in text-mode exclusively. You can omit that flag if you are using a GUI interface and a VNC window to access the main VM console. Finally, with –extra-args we are passing kernel boot parameters to the installer that set up a serial VM console.
The installation should now proceed as a regular (real) server now. If not, please review the steps listed above.
Managing Virtual Machines
These are some typical administration tasks that you, as a system administrator, will need to perform on your virtual machines. Note that all of the following commands need to be run from your host:
1. List all VMs:
# virsh list --all
From the output of the above command you will have to note the Id for the virtual machine (although it will also return its name and current status) because you will need it for most administration tasks related to a particular VM.
2. Display information about a guest:
# virsh dominfo [VM Id]
3. Start, restart, or stop a guest operating system:
# virsh start | reboot | shutdown [VM Id]
4. Access a VM’s serial console if networking is not available and no X server is running on the host:
# virsh console [VM Id]
Note that this will require that you add the serial console configuration information to the /etc/grub.conf file (refer to the argument passed to the –extra-args option when the VM was created).
5. Modify assigned memory or virtual CPUs:
First, shutdown the guest:
# virsh shutdown [VM Id]
Edit the VM configuration for RAM:
# virsh edit [VM Id]
Then modify
<memory>[Memory size here without brackets]</memory>
Restart the VM with the new settings:
# virsh create /etc/libvirt/qemu/tecmint-virt01.xml
Finally, change the memory dynamically:
# virsh setmem [VM Id] [Memory size here without brackets]
For CPU:
# virsh edit [VM Id]
Then modify
<cpu>[Number of CPUs here without brackets]</cpu>
For further commands and details, please refer to table 26.1 in Chapter 26 of the RHEL 5 Virtualization guide (that guide, though a bit old, includes an exhaustive list of virsh commands used for guest administration).
SUMMARY
In this article we have covered some basic aspects of virtualization with KVM in RHEL 7, which is both a vast and a fascinating topic, and I hope it will be helpful as a starting guide for you to later explore more advanced subjects found in the official RHEL virtualization getting started and deployment / administration guides.
In addition, you can refer to the preceding articles in this KVM series in order to clarify or expand some of the concepts explained here.