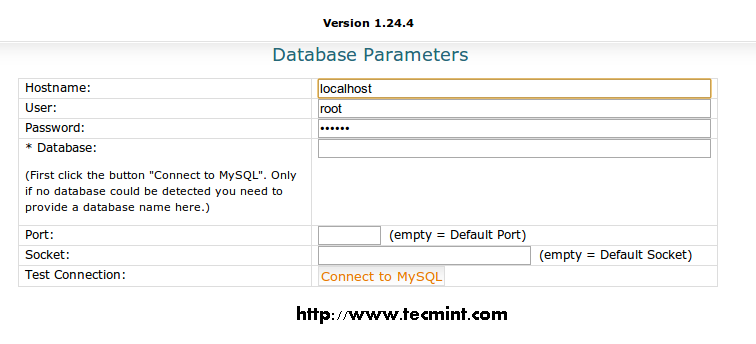
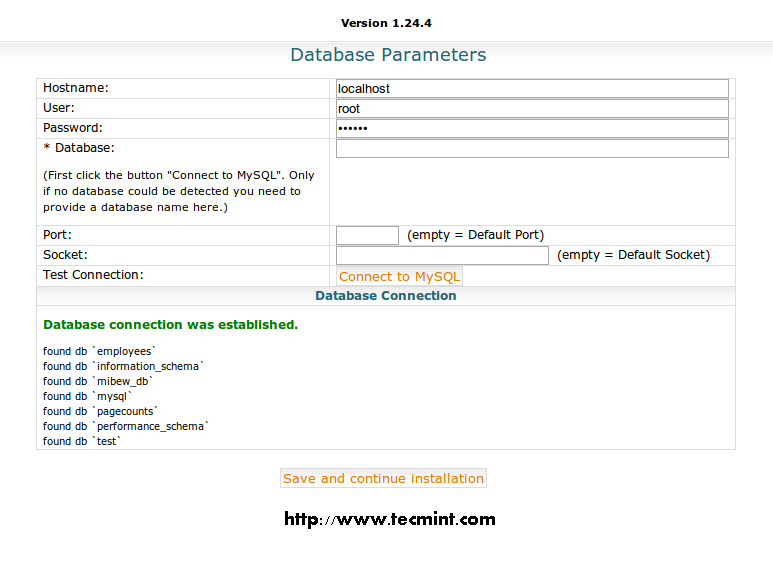
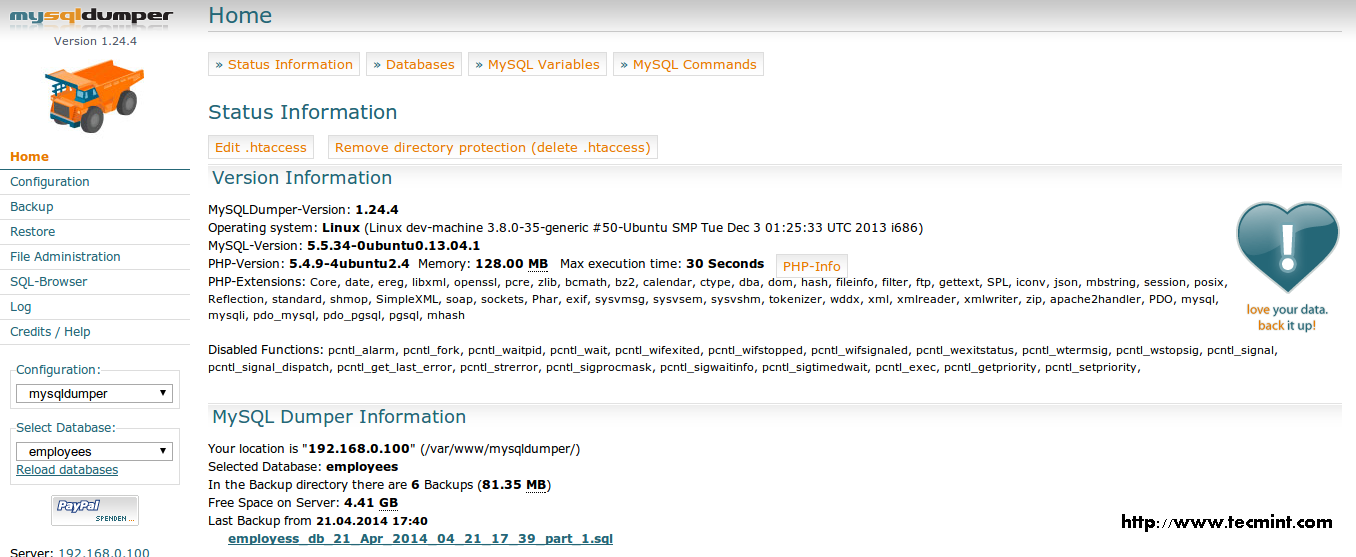
Want a good reason for the smashing success of the Python programming language? Look no further than the massive collection of libraries available for Python, both native and third-party libraries. With so many Python libraries out there, though, it’s no surprise that some don’t get all the attention they deserve. Plus, programmers who work exclusively in one domain don’t always know about the goodies available to them for other kinds of work.Here are 20 Python libraries you may have overlooked but are definitely worth your attention. These gems run the gamut of usefulness, simplifying everything from file system access, database programming, and working with cloud services to building lightweight web apps, creating GUIs, and working with images, ebooks, and Word files—and much more besides. Some are well-known, others lesser-known, but all of these Python libraries deserve a place in your toolbox.
Apache Libcloud
What Libcloud does: Access multiple cloud providers through a single, consistent, unified API.
Why use Libcloud: If the above description of Apache Libcloud doesn’t make you clap your hands for joy, then you haven’t tried working with multiple clouds. Cloud providers all love to do things their way, making a unified mechanism for dealing with dozens of providers a huge timesaver and headache-soother. APIs are available for compute, storage, load balancing, and DNS, with support for Python 2.x and Python 3.x as well as PyPy, the performance-boosting JIT compiler for Python.
Arrow
What Arrow does: Cleaner handling of dates and times in Python.
Why use Arrow: Dealing with time zones, date conversions, date formats, and all the rest is already a headache and a half. Throw in Python’s standard library for date/time work, and you get two headaches and a half.
Arrow provides four big advantages. One, Arrow is a drop-in replacement for Python’s datetime module, meaning that common function calls like .now() and .utcnow() work as expected. Two, Arrow provides methods for common needs like shifting and converting time zones. Three, Arrow provides “humanized” date/time information—such as being able to say something happened “an hour ago” or will happen “in two hours” without much effort. Four, Arrow can localize date/time information without breaking a sweat.
Behold
What Behold does: Robust support for print-style debugging in Python.
Why use Behold: There is one simple way to debug in Python, or almost any programming language for that matter: Insert in-line print statements. But while print-debugging is a no-brainer in small programs, it’s not so easy to get useful results within large, sprawling, multi-module projects.
Behold provides a toolkit for contextual debugging via print statements. It allows you to impose a uniform look on the output, tag the results so they can be sorted via searches or filters, and provide contexts across modules so that functions that originate in one module can be debugged properly in another. Behold handles many common Python-specific scenarios like printing an object’s internal dictionary, unveiling nested attributes, and storing and reusing results for comparison at other points during the debugging process.
Bottle
What Bottle does: Lightweight and fast web apps.
Why use Bottle: When you want to throw together a quick RESTful API or use the bare bones of a web framework to build an app, capable yet tiny Bottle gives you no more than you need. Routing, templates, access to request and response data, support for multiple server types from plain old CGI on up, and support for more advanced features like WebSockets—it’s all here. The amount of work needed to get started is likewise minimal, and Bottle’s design is elegantly extensible when more advanced functions are needed.
EbookLib
What EbookLib does: Read and write .epub files.
Why use EbookLib: Creating ebooks typically requires wrangling one command-line tool or another. EbookLib provides management tools and APIs that simplify the process. It works with EPUB 2 and EPUB 3 files, with Kindle support under development.
Provide the images and the text (the latter in HTML format), and EbookLib can assemble those pieces into an ebook complete with chapters, nested table of contents, images, HTML markup, and so on. Cover, spine, and stylesheet data are all supported, too. A plug-in system allows third parties to extend the library’s behaviors.
If you don’t need everything EbookLib has to offer, try Mkepub. Mkepub packs basic ebook assembly functionality in a library that is only a few kilobytes in size. One minor drawback of Mkepub is that it requires Jinja2, which in turn requires the MarkupSafe library.
Gooey
What Gooey does: Give a console-based Python program a platform-native GUI.
Why use Gooey: Presenting users, especially rank-and-file users, with a command-line interface is among the best ways to discourage use of your application. Few apart from the hardcore geek like figuring out what options to pass in and in what order. Gooey takes arguments expected by the argparse library and presents them to users as a GUI form, by way of the WxPython library. All options are labeled and displayed with appropriate controls (such as a drop-down for a multi-option argument). Very little additional coding—a single include and a single decorator—is needed to make it work, assuming you’re already using argparse.
Invoke
What Invoke does: ”Pythonic remote execution” – i.e., perform admin tasks using a Python library.
Why use Invoke: Using Python as a replacement for common shell scripting tasks makes a world of sense. Invoke provides a high-level API for running shell commands and managing command-line tasks as if they were Python functions, allowing you to embed those tasks in your own code or elegantly build around them.
Nuitka
What Nuitka does: Compile Python into self-contained C executables.
Why use Nuitka: Like Cython, Nuitka compiles Python into C. However, whereas Cython requires its own custom syntax for best results, and focuses mainly on math and statistics applications, Nuitka works with any Python program as-is, compiles it into C, and produces a single-file executable, applying optimizations where it can along the way. Nuitka is still in its early stages, and many of the planned optimizations are still to come. Nevertheless, it’s a convenient way to turn a Python script into a speedy command-line app.
Numba
What Numba does: Selectively speed up math-intensive functions.
Why use Numba: The Python world includes a whole subculture of packages for accelerating math operations. For example, NumPy works by wrapping high-speed C libraries in a Python interface, and Cython compiles Python to C with optional typing for accelerated performance. But Numba is easily the most convenient, as it allows Python functions to be selectively accelerated with nothing more than a decorator. For further speed boosts, you can use common Python idioms to parallelize workloads, or use SIMD or GPU instructions. Note that you can use NumPy with Numba, but in many cases Numba will outperform NumPy many times over.
Peewee
What Peewee does: A tiny ORM (object-relational mapper) that supports SQLite, MySQL, and PostgreSQL, with many extensions.
Why use Peewee: Not everyone loves an ORM; some would rather leave schema modeling on the database side and be done with it. But for developers who don’t want to touch databases, a well-constructed, unobtrusive ORM can be a godsend. And for developers who don’t want an ORM as full-blown as SQL Alchemy, Peewee is a great fit.
Peewee models are easy to construct, connect, and manipulate. Plus, many common query-manipulation functions, such as pagination, are built right in. More features are available as add-ons including extensions for other databases, testing tools, and a schema migration system—a feature even an ORM hater could learn to love. Note that the Peewee 3.x branch (the recommended edition) is not completely backward-compatible with previous versions of Peewee.
Pillow
What Pillow does: Image processing without the pain.
Why use Pillow: Most Pythonistas who have performed image processing ought to be familiar with PIL (Python Imaging Library), but PIL is riddled with shortcomings and limitations, and it’s updated infrequently. Pillowaims to be both easier to use and code-compatible with PIL via minimal changes. Extensions are included for talking to both native Windows imaging functions and Python’s Tcl/Tk-backed Tkinter GUI package. Pillow is available through GitHub or the PyPI repository.
PyFilesystem
What PyFilesystem does: A Pythonic interface to any file system — any file system.
Why use PyFilesystem: The fundamental idea behind PyFilesystem couldn’t be simpler: Just as Python’s file objects abstract a single file, PyFilesystem’s FS objects abstract an entire file system. This doesn’t mean only on-disk file systems, either. PyFilesystem also supports FTP directories, in-memory files ystems, file systems for locations defined by the OS (such as the user directory), and even combinations of the above overlaid onto each other.
In addition to making it easier to write cross-platform code that manipulates files, PyFilesystem obviates the need to cobble together scripts from disparate parts of the standard library, mainly os and io. It also provides utilities that one might otherwise need to create from scratch, like a tool for printing console-friendly tree views of a file system.
Pygame
What Pygame does: Create video games, or game-quality front-ends, in Python.
Why use Pygame: If you think anyone outside of the game development world would ever bother with such a framework, think again. Pygame is a handy way to work with many GUI-oriented behaviors that might otherwise demand a lot of heavy lifting: drawing canvas and sprite graphics, dealing with multichannel sound, handling windows and click events, detecting collisions, and so on. Not every app—or even every GUI app—will benefit from being built with Pygame, but you ought to take a close look at what Pygame provides. You might be surprised!
Pyglet
What Pyglet does: Cross-platform multimedia and window graphics in pure Python.
Why use Pyglet: Pyglet provides handy access to items that are tedious to implement from scratch for a GUI application: window functions, OpenGL graphics, audio and video playback, keyboard and mouse handling, and working with image files. Note that Pyglet doesn’t provide UI widgets like buttons, toolbars, or menus, though.
All of this is done through the native platform capabilities in Windows, OS X, or Linux, so there are no binary dependencies; Pyglet is pure Python. It’s also BSD-licensed, so it can be included in any commercial or open source project.
PyInstaller
What PyInstaller does: Package a Python script as a stand-alone executable.
Why use PyInstaller: A common complaint with Python is that it’s harder than it ought to be to distribute a script to other users. PyInstaller lets you package any Python script—even scripts that include complex third-party modules with binaries, like NumPy—and distribute it as a single-folder or single-file application. PyInstaller tends to pack more into that folder or file than is really needed, so the final results can be bulky. But that tendency can be overcome with practice, and the sheer convenience PyInstaller provides is hard to beat.
PySimpleGUI
What PySimpleGUI does: Creating GUIs in Python with a minimum of fuss.
Why use PySimpleGUI: Python ships with the Tkinter library for creating GUIs, but Tkinter is not known for being easy to work with. PySimpleGUI wraps Tkinter with APIs that are far less exasperating. Many common effects, like a simple dialog box or pop-up menu, can be accomplished in a single line of code. The interfaces still have Tkinter’s trademark look, though. If you want a more sophisticated look and feel you’ll need to look elsewhere.
Python-docx
What Python-docx does: Programmatically manipulate Microsoft Word .docx files.
Why use Python-docx: In theory, it should be easy to write scripts that create and update XML-style Microsoft Word documents. In practice, it is far from simple, due to all of the internal complexities of the .docx format. Python-docx lets you do an end run around all of those complexities, by providing a high-level API for working with .docx files.
Python-docx lets you add or change text, images, tables, styles, document sections, and headers and footers. The library allows you to create new documents or change existing documents. Python-docx is a great way to pull raw text from Word files, or to avoid dealing with Word’s own built-in automation functions.
Scrapy
What Scrapy does: Screen scraping and web crawling.
Why use Scrapy: Scrapy makes scraping simple. Create a class that defines the items you want scraped and write some rules to extract that data from the page. The results can be exported as JSON, XML, CSV, or any number of other formats. The collected data can be saved raw or sanitized as it is imported.
Scrapy can be extended to handle many other tasks, such as logging into a website and handling session cookies. Images, too, can be scraped up by Scrapy and associated with the captured content. The latest versions add direct connections to cloud services for storing scraped data, re-usable proxy connections, and better handling of esoteric HTML and HTTP behaviors.
Sh
What Sh does: Call any external program, in a subprocess, and return the results to a Python program—using the same syntax as if the program in question were a native Python function.
Why use Sh: On any POSIX-compliant system, Sh is a godsend, allowing any command-line program available on that system to be used Pythonically. Not only are you freed from having to reinvent the wheel (why implement ping when it’s right there in the OS?), but you no longer have to struggle with adding that functionality elegantly to your application. However, be forewarned: Sh provides no sanitization of the parameters that are passed through. Be sure never to pass along raw user input.
Splinter
What Splinter does: Test web applications by automating browser actions.
Why you need it: Let’s face it, trying to automate web application testing is no one’s idea of fun. Splinter eliminates the low-level grunt work, invoking the browser, passing URLs, filling out forms, clicking buttons, and so on, automating the whole process from end to end.
Splinter provides drivers to work with Chrome and Firefox, and it can use Selenium Remote to control a browser running elsewhere. You can even manually execute JavaScript in the target browser.
Source