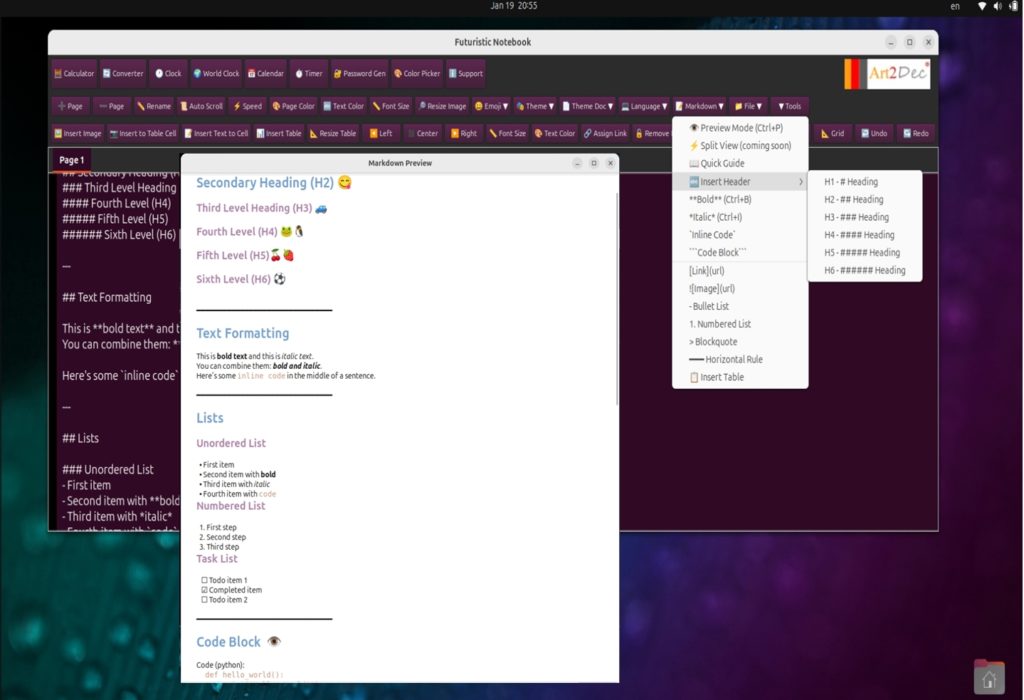
Inline Markdown Editor with Emoji support (January 2026).
What is SUPPORTED:
Headings H1-H6 – all levels are available ✅ Horizontal rules (━━━) ✅ Bold text ✅ Italic text ✅ Inline code ✅ Bulleted lists (•) ✅ ✅ Formatted lists ✅ Checkboxes ☐ (empty) ☑ (checked) ✅ Triple formatting: bold and italic ✅ Code blocks ( ) ✅ Blockquotes (>) ✅ Numbered lists (1. 2. 3.) Everything works with inline formatting and preview. It has full integration with Futuristic Notebook and mshell v.1.4.1 for working with various programming languages. Perfect for creating README.md and other Markdown files on GitHub, in your version control systems and your development packages. Developed and tested on Ubuntu 24.04, Debian, Raspberry PI OS, MacOS Sequoia 15.5, aarch 64 GNU/Linux.
If you are a programmer and use a Linux, macOS, or Raspberry Pi machine as your daily workstation, or even as an occasional tool — this application is exactly what you need. It’s not a single utility but a unified ecosystem of tools designed to simplify your everyday routine.
Instead of juggling dozens of separate apps, Everyday Programmer’s Notebook gives you one clean environment containing everything you constantly need.
What’s inside this unified suite?
Scientific & Programmer Calculator Two complete modes in one tool. Scientific mode supports decimal arithmetic, logarithms, roots, powers, trigonometric functions (in degrees or radians), inverse operations and more. Programmer mode works simultaneously in binary, octal, decimal and hexadecimal, performs logical operations (AND, OR, XOR, NOT, shifts) and standard arithmetic within all four numeral systems.
Unit Converter Instant conversion between metric and imperial systems: length, area, volume, temperature and more. Simple, accurate and always at hand.
Local Digital Clock A clean, elegant digital time display synchronized with your system clock.
World Clock Nine major world cities with automatic time-zone offsets, updated every second.
Timer & Stopwatch Precise timing tools with start/stop/reset controls — perfect for productivity tracking or long-running tasks.
Calendar (25-year range) A lightweight calendar viewer covering decades — ideal for scheduling, planning, or viewing past and future dates.
Password Generator (up to 64 characters) Fully customizable: Uppercase / lowercase letters, digits, symbols — enable or disable any group. Creates strong passwords instantly.
Color Picker (two modes) Digital palette (RGB/HEX/HSL) and analog spectrum mode. Perfect for UI work, design, theming or coding.
Advanced Notebook / Text Reader & Editor A powerful page-based notebook that supports text, images and tables on each page. Key features include: — Auto-scrolling (digital reading mode) — Line numbering — Grid overlays — Page-specific background colors — Per-page text color and font size — Theme switching for the whole application — Unlimited number of pages (limited only by your hardware) — Import from TXT, MD, RTF, DOC, DOCX, PDF — Export to TXT, HTML, Markdown, DOCX, PDF — Image insertion — Searching and Replacement options — Table creation with text and/or images inside cells — Saving & loading notebook files with virtually unlimited pages, limited only by the user’s hardware
This is not a simple notebook — it is a unified environment for writing, reading, organizing, and presenting your information. Contact info about Everyday programmer’s notebook (all versions: MacOS, Linux, Raspberry PI) Igor Lukyanov, Art2Dec SoftLab, igor_lukyanov@appservgrid.com
If you are a programmer and use a Linux, macOS, or Raspberry Pi machine as your daily workstation, or even as an occasional tool — this application is exactly what you need. It’s not a single utility but a unified ecosystem of tools designed to simplify your everyday routine.
Instead of juggling dozens of separate apps, Everyday Programmer’s Notebook gives you one clean environment containing everything you constantly need.
What’s inside this unified suite?
Scientific & Programmer Calculator Two complete modes in one tool. Scientific mode supports decimal arithmetic, logarithms, roots, powers, trigonometric functions (in degrees or radians), inverse operations and more. Programmer mode works simultaneously in binary, octal, decimal and hexadecimal, performs logical operations (AND, OR, XOR, NOT, shifts) and standard arithmetic within all four numeral systems.
Unit Converter
Local Digital Clock
World Clock
Timer & Stopwatch
Infinite Calendar (GTK-powered)
Password Generator (up to 64 characters) Uppercase / lowercase letters, digits, symbols — enable or disable any custom group. Creates strong passwords instantly.
Color Picker (two modes) Digital palette (RGB/HEX/HSL) and analog spectrum mode.
Advanced Notebook / Text Reader & Editor A powerful page-based notebook that supports text, images and tables on each page. — Auto-scrolling (digital reading mode) — Line numbering — Grid overlays — Page-specific background colors — Per-page text color and font size — Theme switching for the whole application — Unlimited number of pages (limited only by your hardware) — Searching and Replacement options — Import from TXT, MD, RTF, DOC, DOCX, PDF — Export to TXT, HTML, Markdown, DOCX, PDF — Image insertion — Table creation with text and/or images inside cells — Saving & loading notebook files with virtually unlimited pages, limited only by the user’s hardware
This is not a simple notebook — it is an unified environment for writing, reading, organizing, and presenting your information. Contact info about Everyday programmer’s notebook: Igor Lukyanov, Art2Dec SoftLab, igor_lukyanov@appservgrid.com
If you are a programmer and use a Linux, macOS, or Raspberry Pi machine as your daily workstation, or even as an occasional tool — this application is exactly what you need. It’s not a single utility but a unified ecosystem of tools designed to simplify your everyday routine.
Instead of juggling dozens of separate apps, Everyday Programmer’s Notebook gives you one clean environment containing everything you constantly need.
What’s inside this unified suite?
Scientific & Programmer Calculator Two complete modes in one tool. Scientific mode supports decimal arithmetic, logarithms, roots, powers, trigonometric functions (in degrees or radians), inverse operations and more. Programmer mode works simultaneously in binary, octal, decimal and hexadecimal, performs logical operations (AND, OR, XOR, NOT, shifts) and standard arithmetic within all four numeral systems.
Unit Converter
Local Digital Clock
World Clock
Timer & Stopwatch
Infinite Calendar (GTK-powered)
Password Generator (up to 64 characters) Uppercase / lowercase letters, digits, symbols — enable or disable any custom group. Creates strong passwords instantly.
Color Picker (two modes) Digital palette (RGB/HEX/HSL) and analog spectrum mode.
Advanced Notebook / Text Reader & Editor A powerful page-based notebook that supports text, images and tables on each page. — Auto-scrolling (digital reading mode) — Line numbering — Grid overlays — Page-specific background colors — Per-page text color and font size — Theme switching for the whole application — Unlimited number of pages (limited only by your hardware) — Searching and Replacement options — Import from TXT, MD, RTF, DOC, DOCX, PDF — Export to TXT, HTML, Markdown, DOCX, PDF — Image insertion — Table creation with text and/or images inside cells — Saving & loading notebook files with virtually unlimited pages, limited only by the user’s hardware
This is not a simple notebook — it is an unified environment for writing, reading, organizing, and presenting your information. Contact info about Everyday programmer’s notebook: Igor Lukyanov, Art2Dec SoftLab, igor_lukyanov@appservgrid.com
Predictive Modeling of Quantum Beating in Hydrogen Atom: Classical and Quantum Visualizations of Coherent State Dynamics (Fundamentals).
This work presents modeling results and prediction of the quantum beating effect in the attosecond time range. The process speed has been proportionally reduced to enable visual observation of electron transitions between states. The fundamental principles do not contradict non-relativistic quantum mechanics and are indirectly supported by its framework. While the exact density movies of the 1s–2p$_z$ beating are not yet directly measured, the underlying frequency scales and coherence phenomena are in close agreement with experimental evidence from ultrafast spectroscopy, Rydberg dynamics, and attosecond experiments.
mshell is a minimalistic Unix shell designed for resource-constrained environments, combining traditional shell functionality with integrated AI capabilities through local LLM models via Ollama or Linux LLM evaluation framework (current version of mshell is 1.4.1), cloud LLMs. The most convenient way to do this is working in two stages. In the first stage, use the latex1.ms script (if the information sources are local) or the latex1inter.ms script (if the information sources are publicly available online). In the second stage, use the latex2.ms script to aggregate and format the article. Information sources can include images, TeX formulas, PDF files, flat files of various formats, and formula descriptions. You can find examples of scripts at the end of the PDF file.