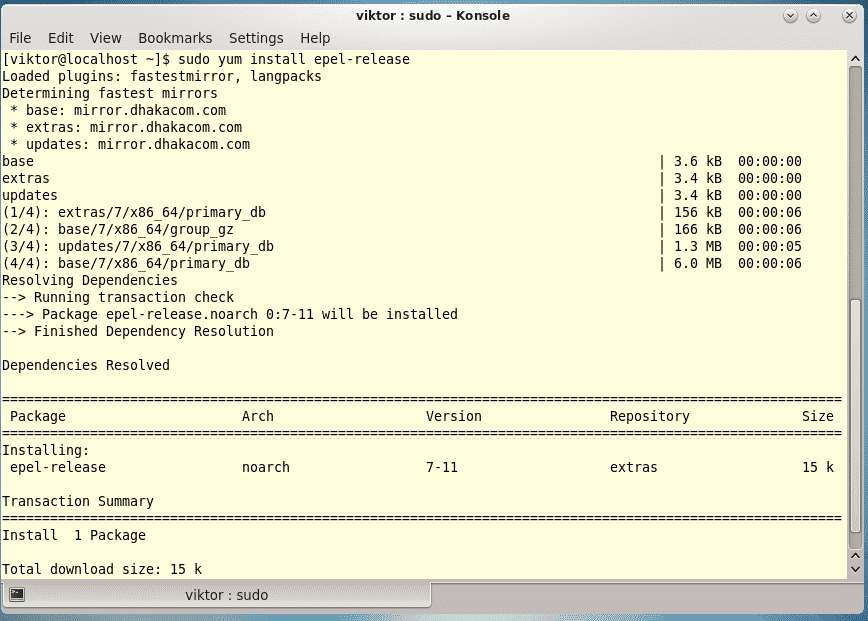
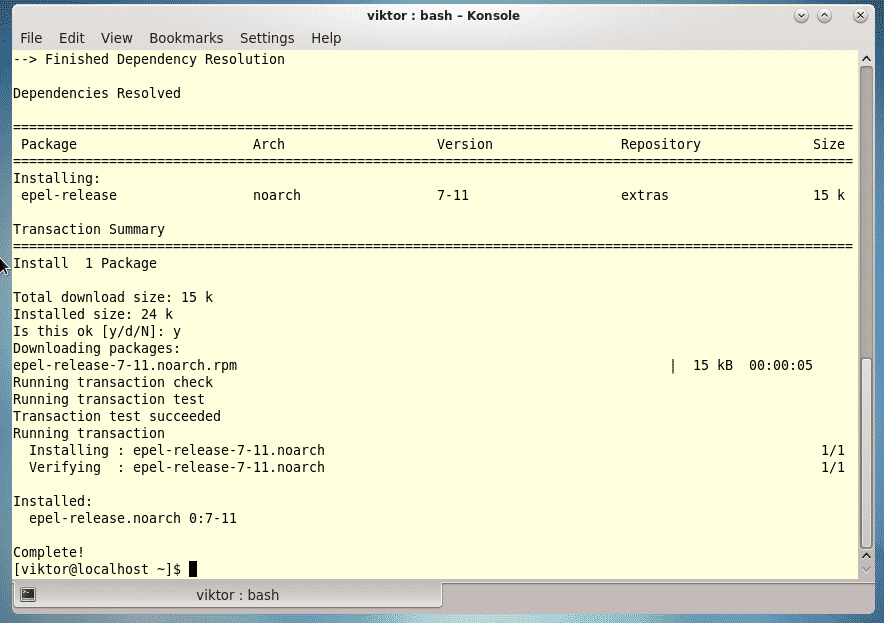
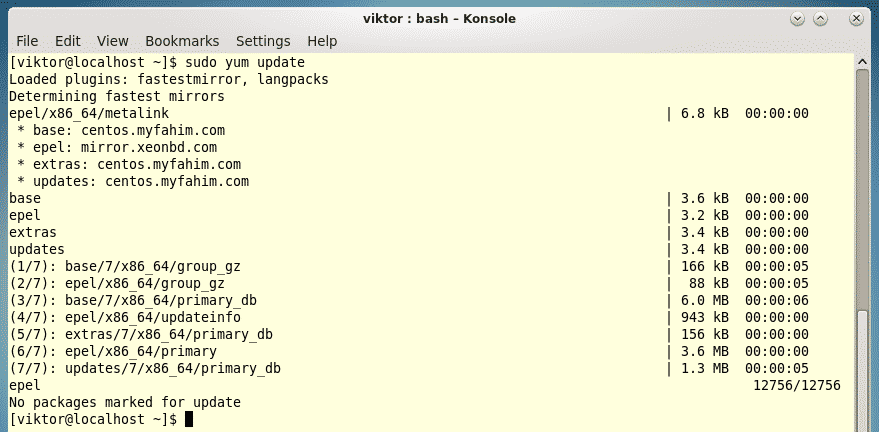
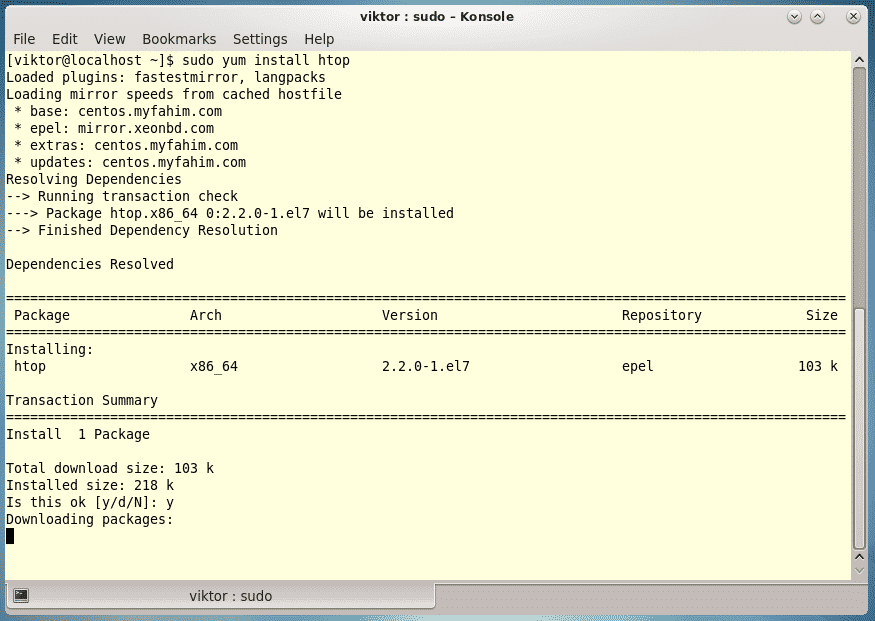
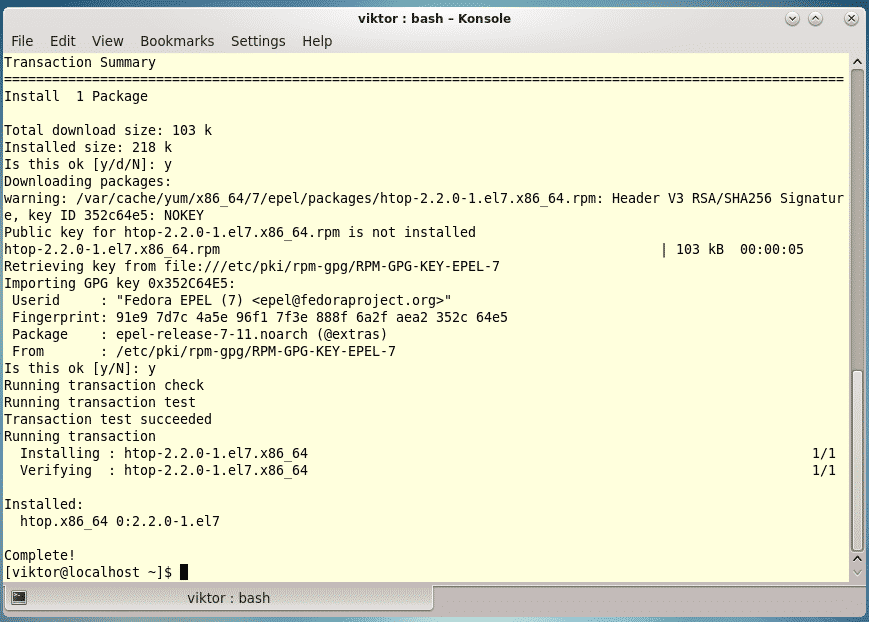
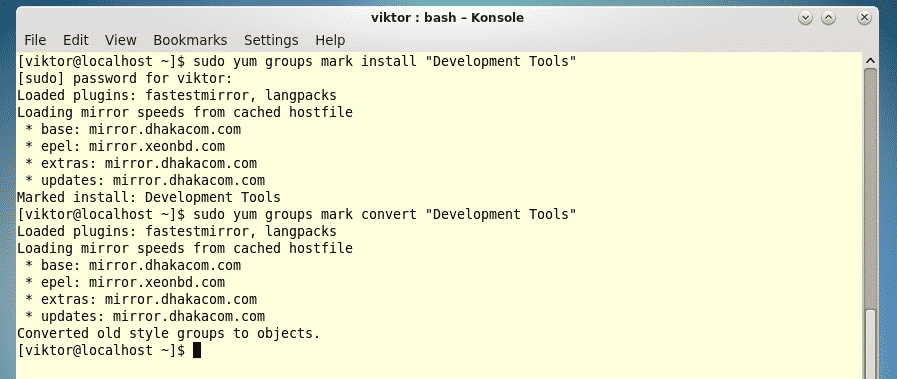
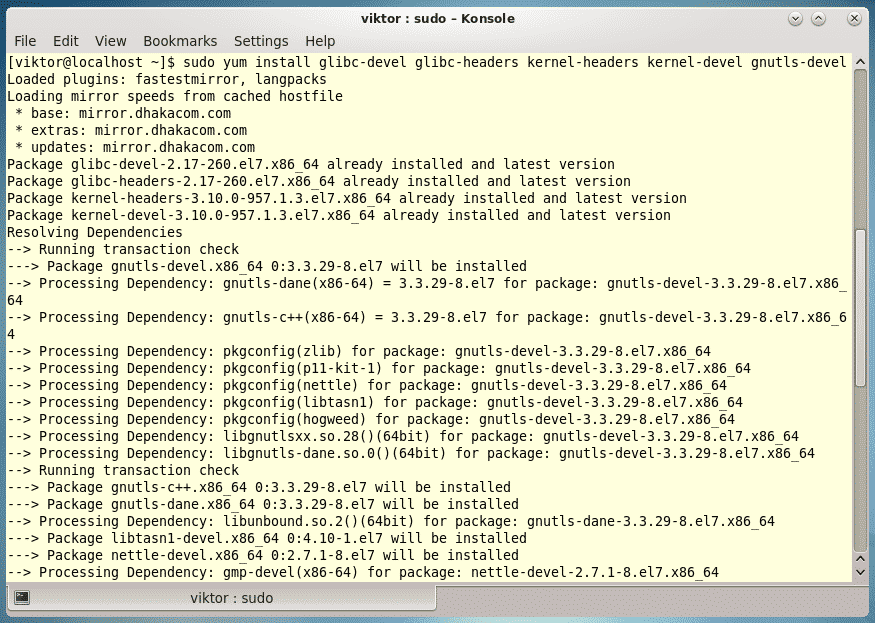
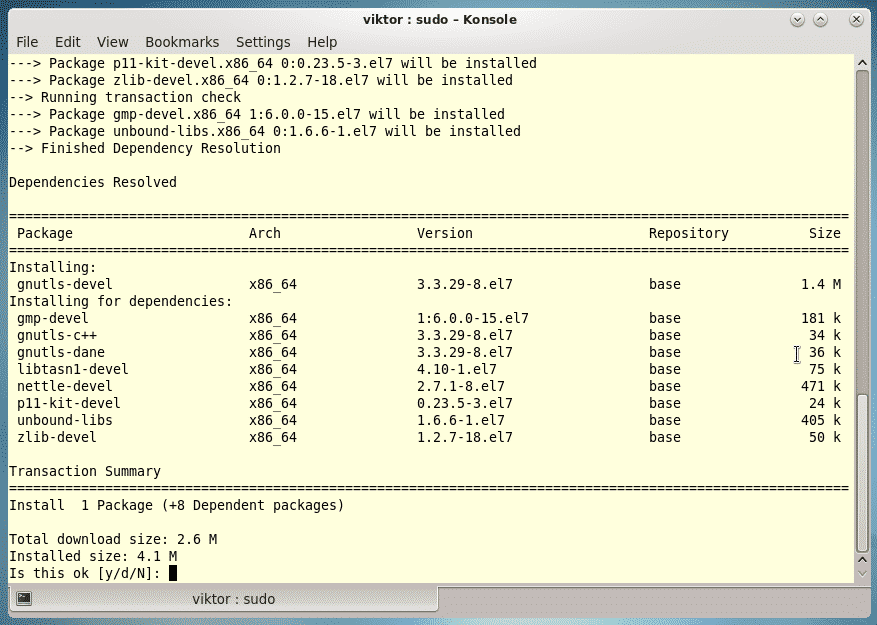
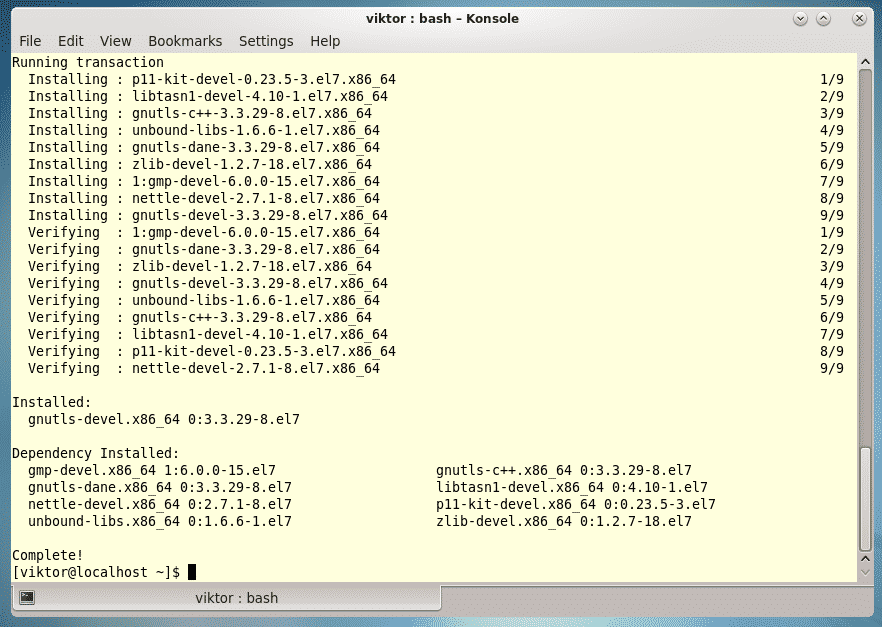
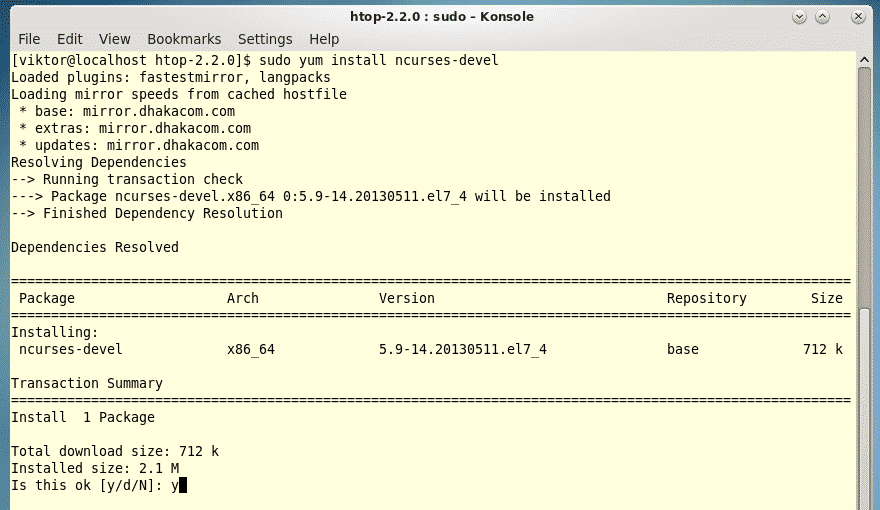
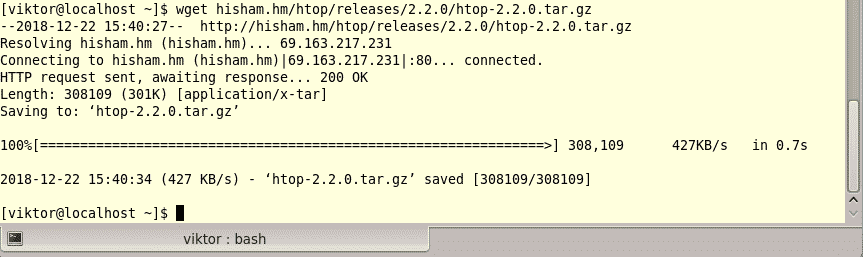
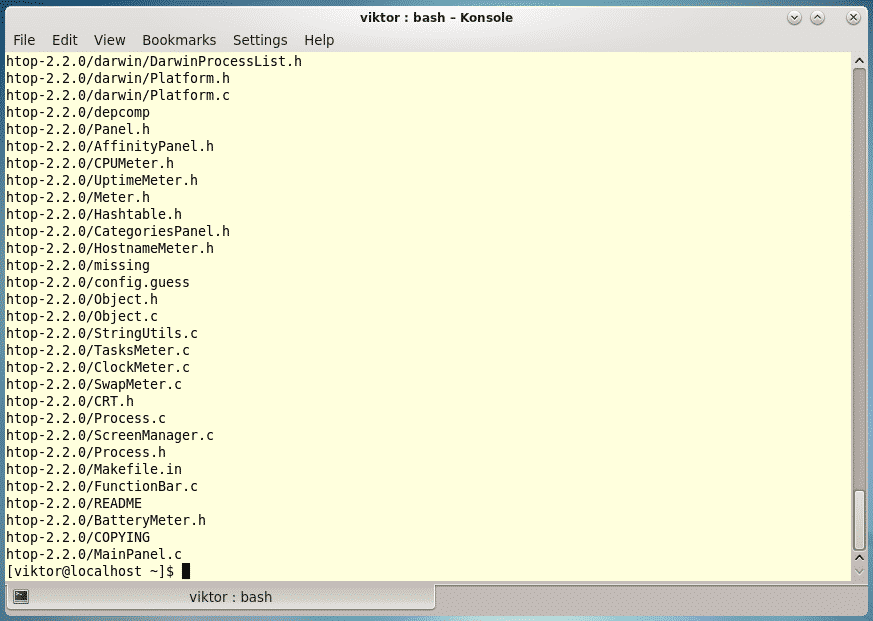
Last year was among the best of times for Linux and open-source. It was also the worst of years. The top five Linux and open-source stories tell it all.
Spectre/Meltdown
First, last January there were a lot of exhausted and angry Linux kernel developers. That’s because a fundamental chip design mistake led to Linux and all Intel-based operating systems having to deal with the Spectre and Meltdown major security problems.
Also: Researchers discover seven new Meltdown and Spectre attacks
Intel’s refusal to let developers work openly with each other led to massive delays in fixing the problems. As Greg Kroah-Hartman, the stable Linux kernel maintainer, explained, “When we get a kernel security bug, it goes to the Linux kernel security team, we drag in the right people, we work with the distributions getting everyone on the same page and push out patches.” Not this time. “Intel siloed SUSE, they siloed Red Hat, they siloed Canonical. They never told Oracle, and they wouldn’t let us talk to each other.”
Linus Torvalds, Linux’s master developer, added, that with the “security issues kept under wraps, we couldn’t do our usual open methods. This made fixing the bugs much more painful than it should be.”
Adding insult to injury Spectre problems persist to this day, and the fixes cause significant slowdowns for both Linux and all other operating systems. We will be stuck with this until a new generation of CPUs fixes the Spectre-family of bugs once and for all.
IBM Buys Red Hat
I didn’t see this coming. IBM made the biggest software company acquisition of all time when it paid $34 billion for Red Hat. This deal wasn’t about Linux. It was about IBM wanting Red Hat’s cloud, container, and Kubernetes expertise.
Also: How the cloud wars forced IBM to buy Red Hat for $34 billion
Will it work? Maybe. IBM is betting the farm on becoming a hybrid-cloud power. On the other hand, had IBM stayed pat with its current offerings, it would have only continued its long slow decline.
To make the deal work, in 2019 IBM must double-down on its Red Hat wager. That means putting Red Hat executives in charge of the merged company. I’ll feel much better about this deal’s future if IBM CEO Ginni Rometty retires and is replaced by Red Hat CEO Jim Whitehurst.
Torvalds steps back from running Linux and Linux developers adopt a new code of conduct
Even now it’s hard to believe that Linus Torvalds took a break from running Linux. For almost 25 years, Torvalds was the benevolent dictator for life of Linux. The only way most people could see him leaving was if he was hit by a bus.
Also: Linus Torvalds and Linux Code of Conduct: 7 myths debunked
It turns out that what could make him step back was realizing his take-no-crap from anyone management style wasn’t working anymore. Torvalds said, “I need to change some of my behavior, and I want to apologize to the people that my personal behavior hurt and possibly drove away from kernel development entirely.”
Torvalds wouldn’t be gone for long. As he came back, a new code of conduct for Linux kernel developers came with him. Despite numerous cries of outrage, mostly from people who weren’t Linux programmers, claiming Linux had been taken over by Social Justice Warriors (SJW)s, Linux development has continued on as always.
Google incorporates Linux into Chrome OS
If you look closely, you can see that Linux is the foundation operating system for Google’s Chrome OS. This makes Chrome OS, I argue, the most successful Linux desktop to date.
Also: Google’s Chrome OS gets new app muscle with built-in Linux CNET
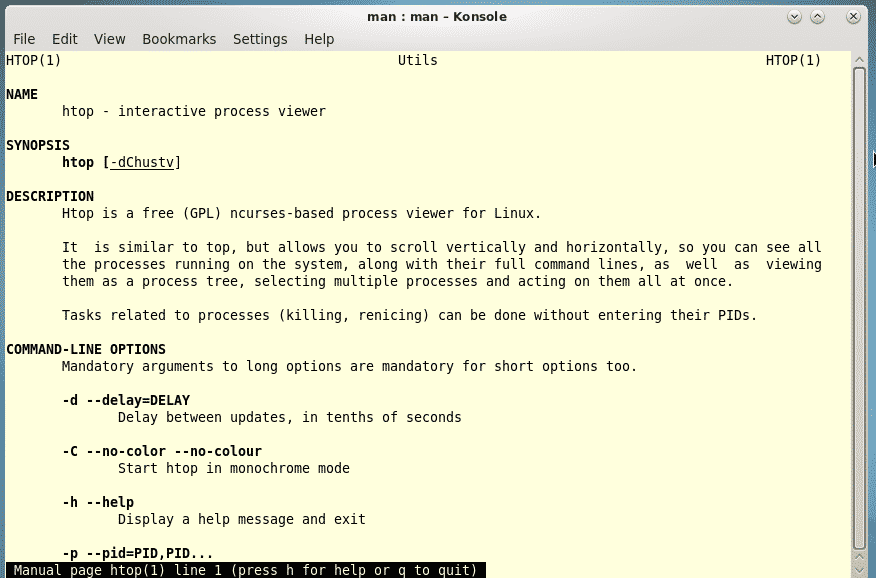
It was only in 2018, however, that Google has made it possible to run native Linux simultaneously with Chrome OS. Curiously, this follows on the heels of Microsoft enabling Windows 10 users to run Linux with Windows Subsystem for Linux (WSL). We may never have a year of Linux on the desktop, but Linux is nevertheless becoming ever more possible as a built-in add-on to other desktop operating systems.
Microsoft buys GitHub and open-sources its patent portfolio
Microsoft buying GitHub, the leading Git-based open-source code collaboration site, was surprising. Microsoft open-sourcing its patent portfolio was shocking.
Also: Pretty much no one quit GitHub over the Microsoft acquisition TechRepublic
By joining the Open Invention Network (OIN), an open-source patent consortium, Microsoft essentially agreed to grant a royalty-free and unrestricted license to its entire patent portfolio to all other OIN members.
This — not Torvalds stepping back from kernel development — was the most surprising Linux news of the year. Years ago, I’d said the one thing Microsoft had to do — to convince everyone in open source that it’s truly an open-source supporter — is stop using its patents against Android vendors. Well, that day finally arrived.
Even now, there are many people who think Microsoft is the Evil Empire, which will stab Linux and open-source in the back. They’re wrong. With this move, Microsoft is putting its own multi-billion dollar intellectual property behind Linux. As unbelievable as it may seem, Microsoft has become a leading open-source and Linux company.
Last year was a heck of a year. While I’m sure there will be many new, major developments for Linux and open-source software in 2019, I find it almost impossible to imagine that 2019 will bring even greater surprises… Well, unless we see MS-Linux. While I think that’s possible, it would also be a real shocker.









 Midori browser is available in Ubuntu Software Center
Midori browser is available in Ubuntu Software Center






 For a full list of BASHing data blog posts, see the
For a full list of BASHing data blog posts, see the