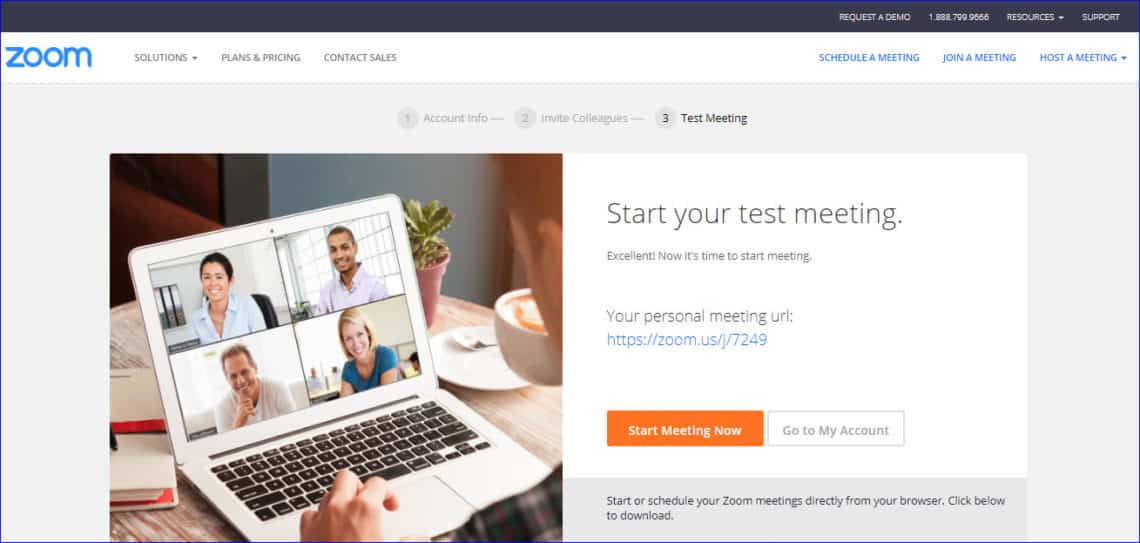
 You don’t have to stick with Windows.Photo: Alex Cranz (Gizmodo)
You don’t have to stick with Windows.Photo: Alex Cranz (Gizmodo)
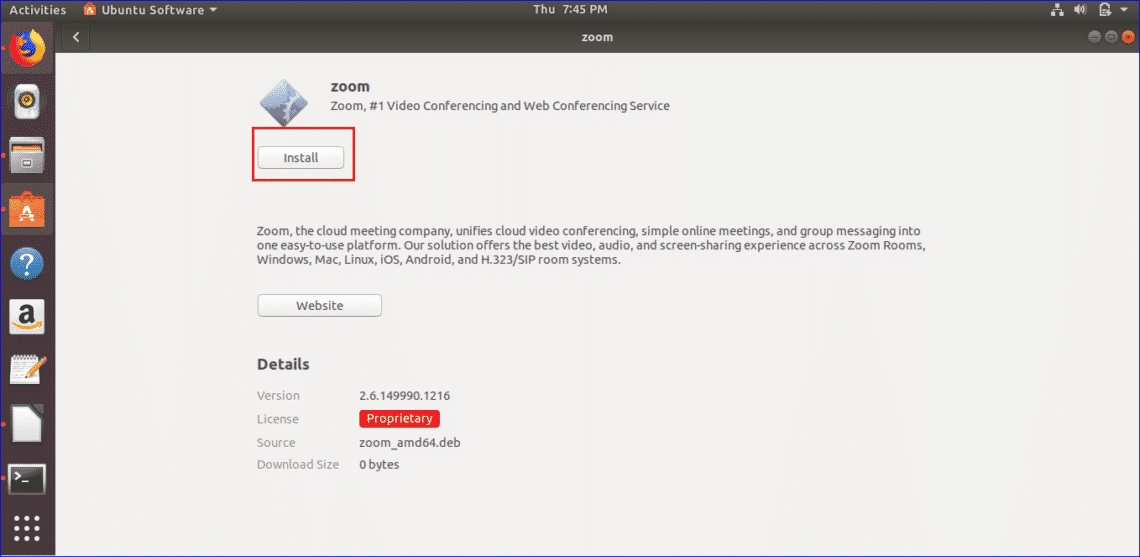
Maybe you’ve grown tired of your current laptop or desktop operating system and you just want to try something different. Or maybe you need to use multiple OSes for work. Either way, the need for a new operating system doesn’t mean you need a whole new computer. There are numerous ways to run other operating systems without going out and buying a new machine. We’ve gathered your options, with the pros and cons for each, below.
While it will be fairly easy to get Linux running on a Windows machine or vice versa you will find it more difficult to get macOS running on a non-Apple computer. You can run Windows and Linux on a Mac, alongside macOS, but you can’t run macOS on a computer built for Windows or Linux—at least not without investing a lot of time and effort.
Creating a Hackintosh (putting macOS on a non-Mac machine) isn’t supported by Apple (Apple would much rather you just bought a Mac). So you’re relying on third-party developers for your digital copy of macOS, and it might be illegal in your country as well. If you’ve confirmed its legal and are still interested in the process, check out this guide.
It’s also worth noting that you shouldn’t attempt any of these procedures without first making sure that all your important files and apps are comprehensively backed up—but you always have backups in place don’t you?
Dual-boot systems
This is the classic method for running two operating systems alongside each other: You essentially split your hard drive in two (a process called partitioning), and then treat drives for each OS. One drive runs one operating system, and one drive runs the other, and you choose which one you want every time you start up the computer.
 Boot Camp is the macOS tool for creating dual-boot systems.Image: Apple
Boot Camp is the macOS tool for creating dual-boot systems.Image: Apple
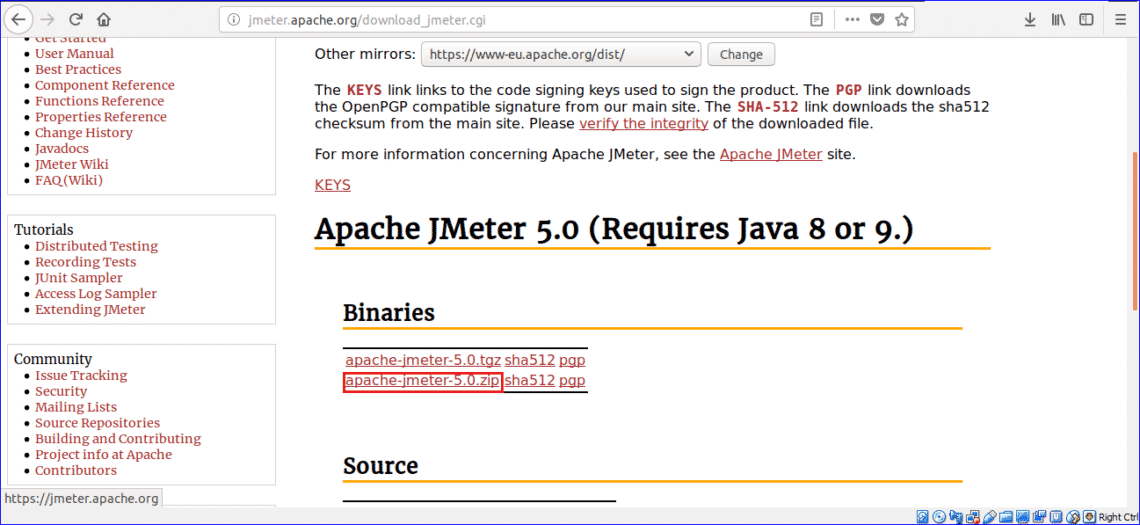
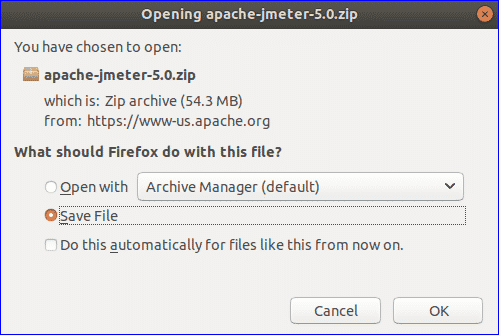
You can add Linux to a Windows computer, or Linux or Windows to a macOS computer—Windows needs to be purchased from Microsoft here, if you want to stay on the right side of the law. For a long time actually putting the new OS on your computer was difficult and risky, but the good news is your current operating system should have everything you need to do the job now.
In macOS, the tool you need is called Boot Camp and you can launch it from the Utilities folder inside Applications. Boot Camp takes care of the partitioning process and readying everything for Windows (or Linux), and Apple has a full guide here.
Disk Management can help you organize partitions on Windows.
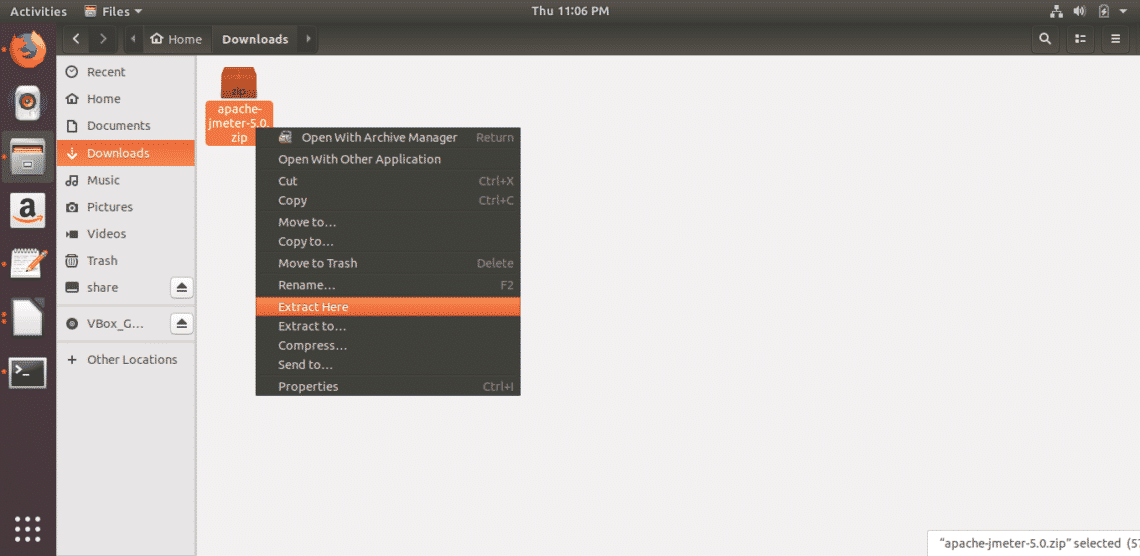
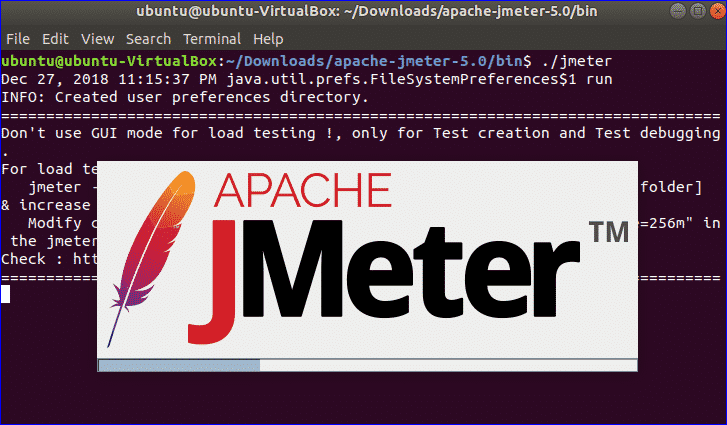
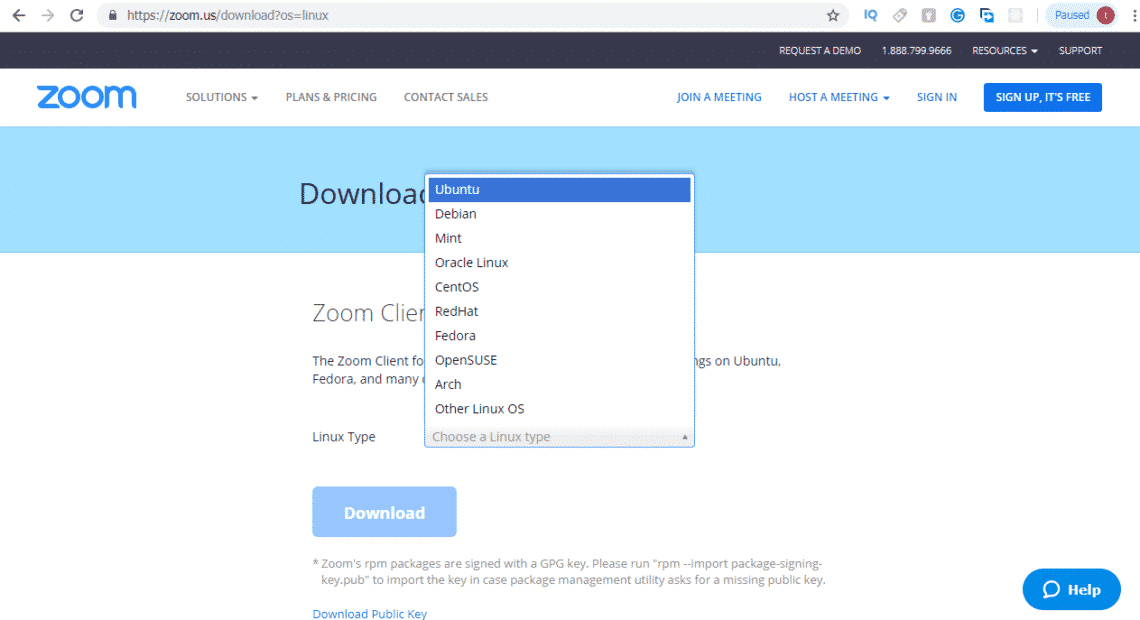
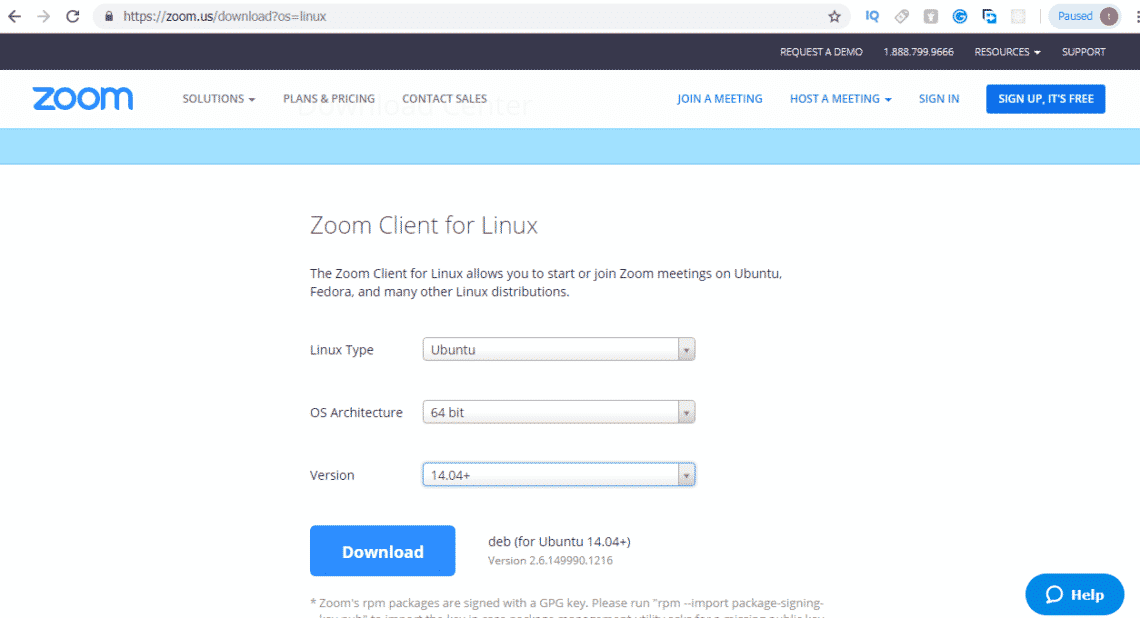
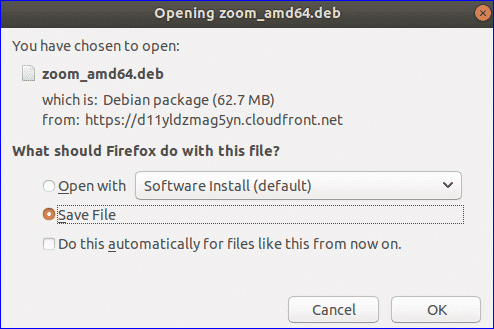
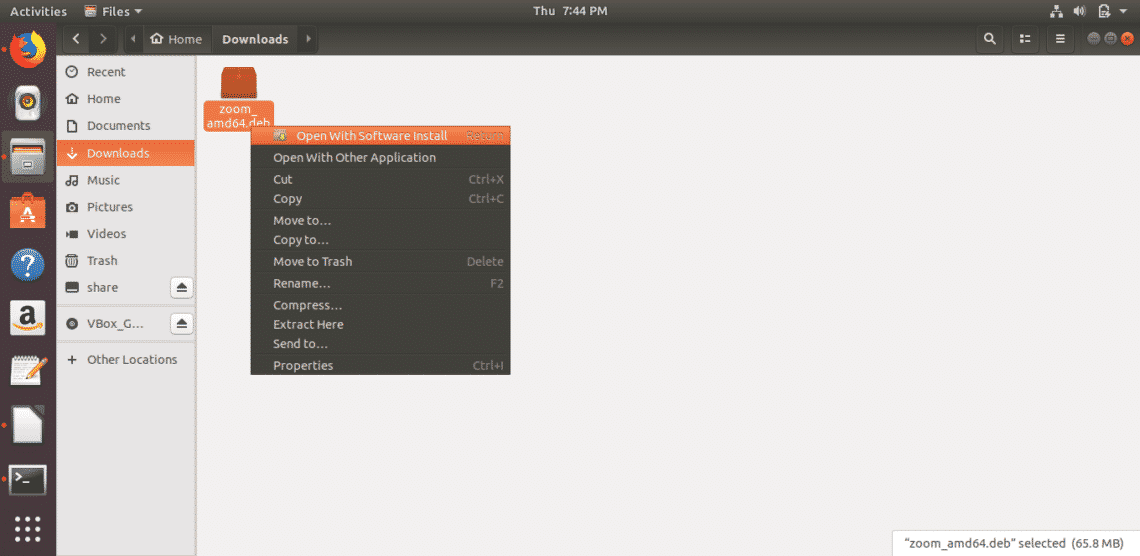
If you’re running Windows and adding Linux in a dual-boot setup, the Linux installer should include tools for partitioning your main hard drive—just make sure you choose to install Linux alongside Windows. You’ll also need to create a Linux installer on a CD, DVD, or USB drive first, then boot from that: There’s an official guide for doing this with Ubuntu here, for example.
If you need another tool, search for the Disk Management utility from the Windows Start menu: Here you can view, edit, and manage disk partitions. One of the disadvantages of this method is that the process is more complicated to reverse if you change your mind.
Alternatively, you can skip the partition and install a second hard drive inside your machine—provided you’re running a desktop computer and have the space. The process isn’t particularly difficult—YouTube is packed with tutorials—but it is more of a serious undertaking than just splitting your current hard drive into two with a few mouse clicks. You have to actually crack open your computer and install the additional drive, as well as much around in the BIOS for your motherboard to confirm the drive is installed correctly to function as a boot drive.
But if that’s still too daunting don’t worry. There’s another way to get operating systems on your computer without partitioning drives (and running the risk of losing data) or installing entirely new drives.
Pros: Best performance. Everything runs natively with few software hiccups.
Cons: Can be difficult to set up if you’re inexperienced. Can potentially destroy data on a current machine so backing everything up before attempting is highly recommended.
Virtual machines
The virtual machine route is the simplest route for installing a new OS. In this scenario you’re running one OS inside another one—it can be set up in minutes, no disk management is required, and the second OS can be removed very easily… but you do need a computer with enough power to handle running two operating systems at once, which means we wouldn’t recommend this route for older computers or low-powered ones.
The exact specs you’re going to need really depend on the operating systems you’re dealing with, but for something like running Windows on top of macOS we’d recommend having at least 8GB of RAM installed. You can always test these tools out and see if the performance is acceptable.
Once you’ve settled on using a virtual machine the next challenge is choosing which virtual machine software you’ll install.
Parallels makes running Windows on macOS straightforward.
VirtualBox is a good choice here—it’s open source and free to use, for a start, and will do the job of getting Linux added to Windows or Linux or Windows added to macOS. That said, it does lack some of the polish and the advanced features you get with the commercial, paid-for software, so it’s worth thinking about the alternatives.
One of the best alternatives for macOS is Parallels (yours from $80): Assuming you have the specs to run it comfortably, it makes adding Linux or Windows to a Mac very easy, and will even point you towards the right downloads (you’ll need to pay for Windows eventually, but you can test it out for free). Switching OSes can be done with a click, and you can even run individual Linux or Windows apps inside the macOS environment.
Another option is VMware Fusion ($80 and up), which offers more advanced tools suitable for developers, IT administrators, and power users. Again, it makes adding Linux or Windows to macOS straightforward, and the software will guide you step-by-step through the process. There’s very little to choose between this and Parallels, from the starting price to the feature set, and Fusion can also run single Windows applications as if they’re running on macOS if needed.
VMware Workstation Player can install Linux or an older version of Windows on Windows.
For Windows users wanting something other than VirtualBox, there’s VMware Workstation Player, which is free for personal use (a paid-for Pro edition is also available). As with the macOS Fusion software, it’s powerful yet simple to use, and will guide you step-by-step through the process of adding a virtual machine to Windows whether you want to run an older Windows version (which you need to purchase a license for) or a Linux distro (which you don’t).
As we’ve said, the big advantage here is ease of use: You don’t need to create bootable USB drives or split disks into partitions, and all these programs make setting up a virtual machine a breeze. Even the paid-for tools we’ve mentioned come with free trials, so you can give them a go and see if they work (and work fast enough) for you.
Pros: Best for beginners. Unlikely to harm any data currently on your PC. Pretty easy to set up.
Cons: Virtualization software can be expensive. Requires a powerful machine for the best performance. Not recommended for lower-end computers.
Live installations
When it comes to adding Linux to a Windows or macOS machine, you’ve got one final option: A live installation. You essentially run Linux from a USB drive or a CD or a DVD, without touching your main hard drive or operating system. It’s really easy to set up, and you don’t have to fiddle with your current OS, but it does limit the performance and features of Linux (because it’s not being run from your main hard drive).
This is a good option to go for if you just want to try an operating system out, or are only going to be using it briefly. Ubuntu has provided an official guide to creating a bootable USB stick here, which is easy to follow, but if you prefer a different flavor of Linux then you should be able to find a similar guide for whatever distro you want to try out.
Ubuntu is one OS you can run straight from a USB stick.
Linux Mint is another lightweight distro you can run from USB or disc: You can find the instructions for finding bootable media for this OS here. Even if you’ve never used Linux before, you shouldn’t have any trouble putting together a bootable memory stick, CD, or DVD, and then it’s just a question of launching the operating system.
To do this, you need to restart your computer and opt to boot from the Linux device rather than your main hard drive. On a Mac, just hold down the Option key after hearing the boot sound; on Windows machines, a key like F12 or Delete is usually used (check for instructions as the computer starts up, or check the instructions that came with it).
You’ll be able to choose the Linux USB drive or disc you’ve created, at which point the operating system starts. Considering most Linux distros come with a smattering of basic apps, you should have everything you need to get going—you can happily run the OS without touching anything on your main system.
Choosing boot options in Linux Mint.
It’s quick and it’s simple to do, so what are the disadvantages? As we’ve mentioned, it’s usually slower (which is why you want to choose a Linux distro that’s as lightweight as possible), and any changes you make to the system aren’t usually saved—you just start again from scratch next time you boot up. We’ve written more about the whole process here.
This is a good option for just testing out Linux, or getting online with a fast, basic, stripped-down OS. If you really want to use Linux seriously to install applications and edit files, you’re better off going with one of the other options mentioned above.
Pros: Super easy. Quick to set up. Keeps your primary data safe. Free apart from the cost of a USB drive.
Cons: You lose every change made to the OS on a restart. Not ideal for repeat use. Running the OS via a USB drive means it can only be as fast as the USB drive itself, which means it will be slower than running directly for your hard drive or SSD.
Source