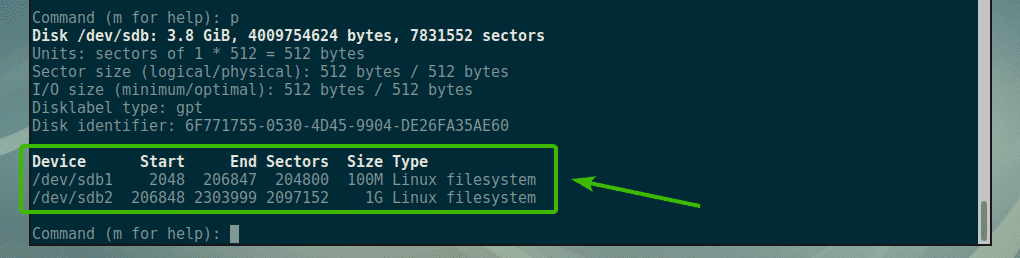
Nagios is one of the most popular open source monitoring systems. Nagios keeps an inventory of your entire IT infrastructure and ensures your networks, servers, applications, services, and processes are up and running. In case of failure or suboptimal performance Nagios will send notification alerts via various methods.
This tutorial describes how to install and configure Nagios Core on a CentOS 7 server.
Prerequisites
Before continuing with this tutorial, make sure you are logged in as a user with sudo privileges.
Disable SELinux or set in permissive mode as instructed here.
Update your CentOS system and install Apache, PHP and all the packages necessary to download and compile the Nagios main application and Nagios plugins:
sudo yum update
sudo yum install httpd php php-cli gcc glibc glibc-common gd gd-devel net-snmp openssl-devel wget
sudo yum install make gettext autoconf net-snmp-utils epel-release perl-Net-SNMP postfix unzip automake
Installing Nagios on CentOS
Perform the following steps to install the latest version of Nagios Core from source.
1. Downloading Nagios
We’ll download Nagios source in the /usr/src directory which is the common location to place source files.
Navigate to the directory with:
Download the latest version of Nagios from the project Github repository using the following wget command:
sudo wget https://github.com/NagiosEnterprises/nagioscore/archive/nagios-4.4.2.tar.gz
Once the download is complete extract the tar file with:
sudo tar zxf nagios-*.tar.gz
Before continuing with the next steps, make sure you change to the Nagios source directory by typing:
2. Compiling Nagios
To start the build process run the configure script which will perform a number of checks to make sure all of the dependencies on your system are present:
Upon successful completion, the following message will be printed on your screen:
*** Configuration summary for nagios 4.4.2 2018-08-16 ***:
General Options:
————————-
Nagios executable: nagios
Nagios user/group: nagios,nagios
Command user/group: nagios,nagios
Event Broker: yes
Install $: /usr/local/nagios
Install $: /usr/local/nagios/include/nagios
Lock file: /run/nagios.lock
Check result directory: /usr/local/nagios/var/spool/checkresults
Init directory: /lib/systemd/system
Apache conf.d directory: /etc/httpd/conf.d
Mail program: /sbin/sendmail
Host OS: linux-gnu
IOBroker Method: epoll
Web Interface Options:
————————
HTML URL: http://localhost/nagios/
CGI URL: http://localhost/nagios/cgi-bin/
Traceroute (used by WAP): /bin/traceroute
Review the options above for accuracy. If they look okay,
type ‘make all’ to compile the main program and CGIs.
Start the compilation process using the make command:
The compilation may take some time, depending on your system. Once the build process is completed, the following message will be printed on your screen:
….
*** Compile finished ***
…
For more information on obtaining support for Nagios, visit:
Nagios Support Home
*************************************************************
Enjoy.
3. Creating Nagios User And Group
Create a new system nagios user and group by issuing:
sudo make install-groups-users
The output will look something like below:
groupadd -r nagios
useradd -g nagios nagios
Add the Apache apache user to the nagios group:
sudo usermod -a -G nagios apache
4. Installing Nagios Binaries
Run the following command to install Nagios binary files, CGIs, and HTML files:
You should see the following output:
…
*** Main program, CGIs and HTML files installed ***
…
5. Creating External Command Directory
Nagios can process commands from external applications. Create the external command directory and set the proper permissions by typing:
sudo make install-commandmode*** External command directory configured ***
6. Install Nagios Configuration Files
Install the sample Nagios configuration files with:
…
*** Config files installed ***
Remember, these are *SAMPLE* config files. You’ll need to read
the documentation for more information on how to actually define
services, hosts, etc. to fit your particular needs.
7. Install Apache Configuration Files
Run the command below to install the Apache web server configuration files:
sudo make install-webconf…
*** Nagios/Apache conf file installed ***
8. Creating Systemd Unit File
The following command installs a systemd unit file and also configure the nagios service to start on boot.
sudo make install-daemoninit…
*** Init script installed ***
9. Creating User Account
To be able to access the Nagios web interface wel’ll create an admin user called nagiosadmin
Run the following htpasswd command to create a user called nagiosadmin
sudo htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin
You will be prompted to enter and confirm the user’s password.
New password:
Re-type new password:
Adding password for user nagiosadmin
Restart the Apache service for changes to take effect:
sudo systemctl restart httpd
Configure the Apache service to start on boot.
sudo systemctl enable httpd
10. Configuring Firewall
The firewall will secure your server against unwanted traffic.
If you don’t have a firewall configured on your server, you can check our guide about how to setup a firewall with firewalld on centos
Open the Apache ports by running the following commands:
sudo firewall-cmd –permanent –zone=public –add-service=http
sudo firewall-cmd –permanent –zone=public –add-service=https
sudo firewall-cmd –reload
Installing Nagios Plugins
Switch back to the /usr/src directory:
Download the latest version of the Nagios Plugins from the project Github repository:
sudo wget -O nagios-plugins.tar.gz https://github.com/nagios-plugins/nagios-plugins/archive/release-2.2.1.tar.gz
When the download is complete extract the tar file:
sudo tar zxf nagios-plugins.tar.gz
Change to the plugins source directory:
cd nagios-plugins-release-2.2.1
Run the following commands one by one to compile and install the Nagios plugins:
sudo ./tools/setup
sudo ./configure
sudo make
sudo make install
Starting Nagios
Now that both Nagios and its plugins are installed, start the Nagios service with:
sudo systemctl start nagios
To verify that Nagios is running, check the service status with the following command:
sudo systemctl status nagios
The output should look something like bellow indicating that Nagios service is active and running.
nagios.service – Nagios Core 4.4.2
Loaded: loaded (/usr/lib/systemd/system/nagios.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2018-12-08 14:33:35 UTC; 3s ago
Docs: https://www.nagios.org/documentation
Process: 22217 ExecStart=/usr/local/nagios/bin/nagios -d /usr/local/nagios/etc/nagios.cfg (code=exited, status=0/SUCCESS)
Process: 22216 ExecStartPre=/usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg (code=exited, status=0/SUCCESS)
Main PID: 22219 (nagios)
CGroup: /system.slice/nagios.service
Accessing the Nagios Web Interface
To access the Nagios web interface open your favorite browser and type your server’s domain name or public IP address followed by /nagios:
http(s)://your_domain_or_ip_address/nagios
Enter the nagiosadmin user login credentials and you will be redirected to the default Nagios home page as shown on the image below:

Conclusion
You have successfully installed the latest Nagios version from source on your CentOS system.
You should now check the Nagios Documentation and learn more about how to configure and use Nagios.
If you hit a problem or have a feedback, leave a comment below.
Source