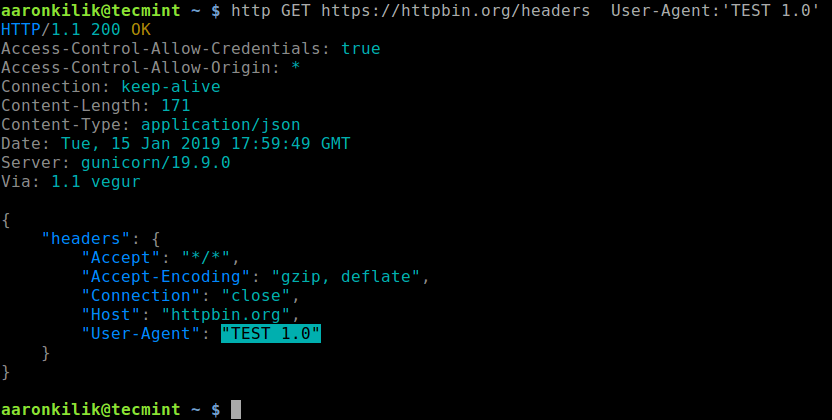
Use the Python Netmiko module to automate switches, routers and firewalls from multiple vendors.
I frequently find myself in the position of confronting “hostile” networks. By hostile, I mean that there is no existing documentation, or if it does exist, it is hopelessly out of date or being hidden deliberately. With that in mind, in this article, I describe the tools I’ve found useful to recover control, audit, document and automate these networks. Note that I’m not going to try to document any of the tools completely here. I mainly want to give you enough real-world examples to prove how much time and effort you could save with these tools, and I hope this article motivates you to explore the official documentation and example code.
In order to save money, I wanted to use open-source tools to gather information from all the devices on the network. I haven’t found a single tool that works with all the vendors and OS versions that typically are encountered. SNMP could provide a lot the information I need, but it would have to be configured on each device manually first. In fact, the mass enablement of SNMP could be one of the first use cases for the network automation tools described in this article.
Most modern devices support REST APIs, but companies typically are saddled with lots of legacy devices that don’t support anything fancier than Telnet and SSH. I settled on SSH access as the lowest common denominator, as every device must support this in order to be managed on the network.
My preferred automation language is Python, so the next problem was finding a Python module that abstracted the SSH login process, making it easy to run commands and gather command output.
Why Netmiko?
I discovered the Paramiko SSH module quite a few years ago and used it to create real-time inventories of Linux servers at multiple companies. It enabled me to log in to hosts and gather the output of commands, such as lspci, dmidecode and lsmod.
The command output populated a database that engineers could use to search for specific hardware. When I then tried to use Paramiko to inventory network switches, I found that certain switch vendor and OS combinations would cause Paramiko SSH sessions to hang. I could see that the SSH login itself was successful, but the session would hang right after the login. I never was able to determine the cause, but I discovered Netmiko while researching the hanging problem. When I replaced all my Paramiko code with Netmiko code, all my session hanging problems went away, and I haven’t looked back since. Netmiko also is optimized for the network device management task, while Paramiko is more of a generic SSH module.
Programmatically Dealing with the Command-Line Interface
People familiar with the “Expect” language will recognize the technique for sending a command and matching the returned CLI prompts and command output to determine whether the command was successful. In the case of most network devices, the CLI prompts change depending on whether you’re in an unprivileged mode, in “enable” mode or in “config” mode.
For example, the CLI prompt typically will be the device hostname followed by specific characters.
Unprivileged mode:
sfo03-r7r9-sw1>
Privileged or “enable” mode:
sfo03-r7r9-sw1#
“Config” mode:
sfo03-r7r9-sw1(config)#
These different prompts enable you to make transitions programmatically from one mode to another and determine whether the transitions were successful.
Abstraction
Netmiko abstracts many common things you need to do when talking to switches. For example, if you run a command that produces more than one page of output, the switch CLI typically will “page” the output, waiting for input before displaying the next page. This makes it difficult to gather multipage output as single blob of text. The command to turn off paging varies depending on the switch vendor. For example, this might be terminal length 0 for one vendor and set cli pager off for another. Netmiko abstracts this operation, so all you need to do is use the disable_paging() function, and it will run the appropriate commands for the particular device.
Dealing with a Mix of Vendors and Products
Netmiko supports a growing list of network vendor and product combinations. You can find the current list in the documentation. Netmiko doesn’t auto-detect the vendor, so you’ll need to specify that information when using the functions. Some vendors have product lines with different CLI commands. For example, Dell has two types: dell_force10 and dell_powerconnect; and Cisco has several CLI versions on the different product lines, including cisco_ios, cisco_nxos and cisco_asa.
Obtaining Netmiko
The official Netmiko code and documentation is at https://github.com/ktbyers/netmiko, and the author has a collection of helpful articles on his home page.
If you’re comfortable with developer tools, you can clone the GIT repo directly. For typical end users, installing Netmiko using pip should suffice:
# pip install netmiko
A Few Words of Caution
Before jumping on the network automation bandwagon, you need to sort out the following:
- Mass configuration: be aware that the slowness of traditional “box-by-box” network administration may have protected you somewhat from massive mistakes. If you manually made a change, you typically would be alerted to a problem after visiting only a few devices. With network automation tools, you can render all your network devices useless within seconds.
- Configuration backup strategy: this ideally would include a versioning feature, so you can roll back to a specific “known good” point in time. Check out the RANCID package before you spend a lot of money on this capability.
- Out-of-band network management: almost any modern switch or network device is going to have a dedicated OOB port. This physically separate network permits you to recover from configuration mistakes that potentially could cut you off from the very devices you’re managing.
- A strategy for testing: for example, have a dedicated pool of representative equipment permanently set aside for testing and proof of concepts. When rolling out a change on a production network, first verify the automation on a few devices before trying to do hundreds at once.
Using Netmiko without Writing Any Code
Netmiko’s author has created several standalone scripts called Netmiko Tools that you can use without writing any Python code. Consult the official documentation for details, as I offer only a few highlights here.
At the time of this writing, there are three tools:
netmiko-show
Run arbitrary “show” commands on one or more devices. By default, it will display the entire configuration, but you can supply an alternate command with the --cmd option. Note that “show” commands can display many details that aren’t stored within the actual device configurations.
For example, you can display Spanning Tree Protocol (STP) details from multiple devices:
% netmiko-show --cmd "show spanning-tree detail" arista-eos |
↪egrep "(last change|from)"
sfo03-r1r12-sw1.txt: Number of topology changes 2307 last
↪change occurred 19:14:09 ago
sfo03-r1r12-sw1.txt: from Ethernet1/10/2
sfo03-r1r12-sw2.txt: Number of topology changes 6637 last
↪change occurred 19:14:09 ago
sfo03-r1r12-sw2.txt: from Ethernet1/53
This information can be very helpful when tracking down the specific switch and switch port responsible for an STP flapping issue. Typically, you would be looking for a very high count of topology changes that is rapidly increasing, with a “last change time” in seconds. The “from” field gives you the source port of the change, enabling you to narrow down the source of the problem.
The “old-school” method for finding this information would be to log in to the top-most switch, look at its STP detail, find the problem port, log in to the switch downstream of this port, look at its STP detail and repeat this process until you find the source of the problem. The Netmiko Tools allow you to perform a network-wide search for all the information you need in a single operation.
netmiko-cfg
Apply snippets of configurations to one or more devices. Specify the configuration command with the --cmd option or read configuration from a file using --infile. This could be used for mass configurations. Mass changes could include DNS servers, NTP servers, SNMP community strings or syslog servers for the entire network. For example, to configure the read-only SNMP community on all of your Arista switches:
$ netmiko-cfg --cmd "snmp-server community mysecret ro"
↪arista-eos
You still will need to verify that the commands you’re sending are appropriate for the vendor and OS combinations of the target devices, as Netmiko will not do all of this work for you. See the “groups” mechanism below for how to apply vendor-specific configurations to only the devices from a particular vendor.
netmiko-grep
Search for a string in the configuration of multiple devices. For example, verify the current syslog destination in your Arista switches:
$ netmiko-grep --use-cache "logging host" arista-eos
sfo03-r2r7-sw1.txt:logging host 10.7.1.19
sfo03-r3r14-sw1.txt:logging host 10.8.6.99
sfo03-r3r16-sw1.txt:logging host 10.8.6.99
sfo03-r4r18-sw1.txt:logging host 10.7.1.19
All of the Netmiko tools depend on an “inventory” of devices, which is a YAML-formatted file stored in “.netmiko.yml” in the current directory or your home directory.
Each device in the inventory has the following format:
sfo03-r1r11-sw1:
device_type: cisco_ios
ip: sfo03-r1r11-sw1
username: netadmin
password: secretpass
port: 22
Device entries can be followed by group definitions. Groups are simply a group name followed by a list of devices:
cisco-ios:
- sfo03-r1r11-sw1
cisco-nxos:
- sfo03-r1r12-sw2
- sfo03-r3r17-sw1
arista-eos:
- sfo03-r1r10-sw2
- sfo03-r6r6-sw1
For example, you can use the group name “cisco-nxos” to run Cisco Nexus NX-OS-unique commands, such as feature:
% netmiko-cfg --cmd "feature interface-vlan" cisco-nxos
Note that the device type example is just one type of group. Other groups could indicate physical location (“SFO03”, “RKV02”), role (“TOR”, “spine”, “leaf”, “core”), owner (“Eng”, “QA”) or any other categories that make sense to you.
As I was dealing with hundreds of devices, I didn’t want to create the YAML-formatted inventory file by hand. Instead, I started with a simple list of devices and the corresponding Netmiko “device_type”:
sfo03-r1r11-sw1,cisco_ios
sfo03-r1r12-sw2,cisco_nxos
sfo03-r1r10-sw2,arista_eos
sfo03-r4r5-sw3,arista_eos
sfo03-r1r12-sw1,cisco_nxos
sfo03-r5r15-sw2,dell_force10
I then used standard Linux commands to create the YAML inventory file:
% grep -v '^#' simplelist.txt | awk -F, '{printf("%s:\n
↪device_type:
%s\n ip: %s\n username: netadmin\n password:
↪secretpass\n port:
22\n",$1,$2,$1)}' >> .netmiko.yml
I’m using a centralized authentication system, so the user name and password are the same for all devices. The command above yields the following YAML-formatted file:
sfo03-r1r11-sw1:
device_type: cisco_ios
ip: sfo03-r1r11-sw1
username: netadmin
password: secretpass
port: 22
sfo03-r1r12-sw2:
device_type: cisco_nxos
ip: sfo03-r1r12-sw2
username: netadmin
password: secretpass
port: 22
sfo03-r1r10-sw2:
device_type: arista_eos
ip: sfo03-r1r10-sw2
username: netadmin
password: secretpass
port: 22
Once you’ve created this inventory, you can use the Netmiko Tools against individual devices or groups of devices.
A side effect of creating the inventory is that you now have a master list of devices on the network; you also have proven that the device names are resolvable via DNS and that you have the correct login credentials. This is actually a big step forward in some environments where I’ve worked.
Note that netmiko-grep caches the device configs locally. Once the cache has been built, you can make subsequent search operations run much faster by specifying the --use-cache option.
It now should be apparent that you can use Netmiko Tools to do a lot of administration and automation without writing any Python code. Again, refer to official documentation for all the options and more examples.
Start Coding with Netmiko
Now that you have a sense of what you can do with Netmiko Tools, you’ll likely come up with unique scenarios that require actual coding.
For the record, I don’t consider myself an advanced Python programmer at this time, so the examples here may not be optimal. I’m also limiting my examples to snippets of code rather than complete scripts. The example code is using Python 2.7.
My Approach to the Problem
I wrote a bunch of code before I became aware of the Netmiko Tools commands, and I found that I’d duplicated a lot of their functionality. My original approach was to break the problem into two separate phases. The first phase was the “scanning” of the switches and storing their configurations and command output locally, The second phase was processing and searching across the stored data.
My first script was a “scanner” that reads a list of switch hostnames and Netmiko device types from a simple text file, logs in to each switch, runs a series of CLI commands and then stores the output of each command in text files for later processing.
Reading a List of Devices
My first task is to read a list of network devices and their Netmiko “device type” from a simple text file in the CSV format. I include the csv module, so I can use the csv.Dictreader function, which returns CSV fields as a Python dictionary. I like the CSV file format, as anyone with limited UNIX/Linux skills likely knows how to work with it, and it’s a very common file type for exporting data if you have an existing database of network devices.
For example, the following is a list of switch names and device types in CSV format:
sfo03-r1r11-sw1,cisco_ios
sfo03-r1r12-sw2,cisco_nxos
sfo03-r1r10-sw2,arista_eos
sfo03-r4r5-sw3,arista_eos
sfo03-r1r12-sw1,cisco_nxos
sfo03-r5r15-sw2,dell_force10
The following Python code reads the data filename from the command line, opens the file and then iterates over each device entry, calling the login_switch() function that will run the actual Netmiko code:
import csv
import sys
import logging
def main():
# get data file from command line
devfile = sys.argv[1]
# open file and extract the two fields
with open(devfile,'rb') as devicesfile:
fields = ['hostname','devtype']
hosts = csv.DictReader(devicesfile,fieldnames=fields,
↪delimiter=',')
# iterate through list of hosts, calling "login_switch()"
# for each one
for host in hosts:
hostname = host['hostname']
print "hostname = ",hostname
devtype = host['devtype']
login_switch(hostname,devtype)
The login_switch() function runs any number of commands and stores the output in separate text files under a directory based on the name of the device:
# import required module
from netmiko import ConnectHandler
# login into switch and run command
def login_switch(host,devicetype):
# required arguments to ConnectHandler
device = {
# device_type and ip are read from data file
'device_type': devicetype,
'ip':host,
# device credentials are hardcoded in script for now
'username':'admin',
'password':'secretpass',
}
# if successful login, run command on CLI
try:
net_connect = ConnectHandler(**device)
commands = "show version"
output = net_connect.send_command(commands)
# construct directory path based on device name
path = '/root/login/scan/' + host + "/"
make_dir(path)
filename = path + "show_version"
# store output of command in file
handle = open (filename,'w')
handle.write(output)
handle.close()
# if unsuccessful, print error
except Exception as e:
print "RAN INTO ERROR "
print "Error: " + str(e)
This code opens a connection to the device, executes the show version command and stores the output in /root/login/scan/<devicename>/show_version.
The show version output is incredible useful, as it typically contains the vendor, model, OS version, hardware details, serial number and MAC address. Here’s an example from an Arista switch:
Arista DCS-7050QX-32S-R
Hardware version: 01.31
Serial number: JPE16292961
System MAC address: 444c.a805.6921
Software image version: 4.17.0F
Architecture: i386
Internal build version: 4.17.0F-3304146.4170F
Internal build ID: 21f25f02-5d69-4be5-bd02-551cf79903b1
Uptime: 25 weeks, 4 days, 21 hours and 32
minutes
Total memory: 3796192 kB
Free memory: 1230424 kB
This information allows you to create all sorts of good stuff, such as a hardware inventory of your network and a software version report that you can use for audits and planned software updates.
My current script runs show lldp neighbors, show run, show interface status and records the device CLI prompt in addition to show version.
The above code example constitutes the bulk of what you need to get started with Netmiko. You now have a way to run arbitrary commands on any number of devices without typing anything by hand. This isn’t Software-Defined Networking (SDN) by any means, but it’s still a huge step forward from the “box-by-box” method of network administration.
Next, let’s try the scanning script on the sample network:
$ python scanner.py devices.csv
hostname = sfo03-r1r15-sw1
hostname = sfo03-r3r19-sw0
hostname = sfo03-r1r16-sw2
hostname = sfo03-r3r8-sw2
RAN INTO ERROR
Error: Authentication failure: unable to connect dell_force10
↪sfo03-r3r8-sw2:22
Authentication failed.
hostname = sfo03-r3r10-sw2
hostname = sfo03-r3r11-sw1
hostname = sfo03-r4r14-sw2
hostname = sfo03-r4r15-sw1
If you have a lot of devices, you’ll likely experience login failures like the one in the middle of the scan above. These could be due to multiple reasons, including the device being down, being unreachable over the network, the script having incorrect credentials and so on. Expect to make several passes to address all the problems before you get a “clean” run on a large network.
This finishes the “scanning” portion of process, and all the data you need is now stored locally for further analysis in the “scan” directory, which contains subdirectories for each device:
$ ls scan/
sfo03-r1r10-sw2 sfo03-r2r14-sw2 sfo03-r3r18-sw1 sfo03-r4r8-sw2
↪sfo03-r6r14-sw2
sfo03-r1r11-sw1 sfo03-r2r15-sw1 sfo03-r3r18-sw2 sfo03-r4r9-sw1
↪sfo03-r6r15-sw1
sfo03-r1r12-sw0 sfo03-r2r16-sw1 sfo03-r3r19-sw0 sfo03-r4r9-sw2
↪sfo03-r6r16-sw1
sfo03-r1r12-sw1 sfo03-r2r16-sw2 sfo03-r3r19-sw1 sfo03-r5r10-sw1
↪sfo03-r6r16-sw2
sfo03-r1r12-sw2 sfo03-r2r2-sw1 sfo03-r3r4-sw2 sfo03-r5r10-sw2
↪sfo03-r6r17- sw1
You can see that each subdirectory contains separate files for each command output:
$ ls sfo03-r1r10-sw2/
show_lldp prompt show_run show_version show_int_status
Debugging via Logging
Netmiko normally is very quiet when it’s running, so it’s difficult to tell where things are breaking in the interaction with a network device. The easiest way I have found to debug problems is to use the logging module. I normally keep this disabled, but when I want to turn on debugging, I uncomment the line starting with logging.basicConfig line below:
import logging
if __name__ == "__main__":
# logging.basicConfig(level=logging.DEBUG)
main()
Then I run the script, and it produces output on the console showing the entire SSH conversation between the netmiko module and the remote device (a switch named “sfo03-r1r10-sw2” in this example):
DEBUG:netmiko:In disable_paging
DEBUG:netmiko:Command: terminal length 0
DEBUG:netmiko:write_channel: terminal length 0
DEBUG:netmiko:Pattern is: sfo03\-r1r10\-sw2
DEBUG:netmiko:_read_channel_expect read_data: terminal
↪length 0
DEBUG:netmiko:_read_channel_expect read_data: Pagination
disabled.
sfo03-r1r10-sw2#
DEBUG:netmiko:Pattern found: sfo03\-r1r10\-sw2 terminal
↪length 0
Pagination disabled.
sfo03-r1r10-sw2#
DEBUG:netmiko:terminal length 0
Pagination disabled.
sfo03-r1r10-sw2#
DEBUG:netmiko:Exiting disable_paging
In this case, the terminal length 0 command sent by Netmiko is successful. In the following example, the command sent to change the terminal width is rejected by the switch CLI with the “Authorization denied” message:
DEBUG:netmiko:Entering set_terminal_width
DEBUG:netmiko:write_channel: terminal width 511
DEBUG:netmiko:Pattern is: sfo03\-r1r10\-sw2
DEBUG:netmiko:_read_channel_expect read_data: terminal
↪width 511
DEBUG:netmiko:_read_channel_expect read_data: % Authorization
denied for command 'terminal width 511'
sfo03-r1r10-sw2#
DEBUG:netmiko:Pattern found: sfo3\-r1r10\-sw2 terminal
↪width 511
% Authorization denied for command 'terminal width 511'
sfo03-r1r10-sw2#
DEBUG:netmiko:terminal width 511
% Authorization denied for command 'terminal width 511'
sfo03-r1r10-sw2#
DEBUG:netmiko:Exiting set_terminal_width
The logging also will show the entire SSH login and authentication sequence in detail. I had to deal with one switch that was using a depreciated SSH cypher that was disabled by default in the SSH client, causing the SSH session to fail when trying to authenticate. With logging, I could see the client rejecting the cypher being offered by the switch. I also discovered another type of switch where the Netmiko connection appeared to hang. The logging revealed that it was stuck at the more? prompt, as the paging was never disabled successfully after login. On this particular switch, the commands to disable paging had to be run in a privileged mode. My quick fix was add a disable_paging() function after the “enable” mode was entered.
Analysis Phase
Now that you have all the data you want, you can start processing it.
A very simple example would be an “audit”-type of check, which verifies that hostname registered in DNS matches the hostname configured in the device. If these do not match, it will cause all sorts of confusion when logging in to the device, correlating syslog messages or looking at LLDP and CPD output:
import os
import sys
directory = "/root/login/scan"
for filename in os.listdir(directory):
prompt_file = directory + '/' + filename + '/prompt'
try:
prompt_fh = open(prompt_file,'rb')
except IOError:
"Can't open:", prompt_file
sys.exit()
with prompt_fh:
prompt = prompt_fh.read()
prompt = prompt.rstrip('#')
if (filename != prompt):
print 'switch DNS hostname %s != configured
↪hostname %s' %(filename, prompt)
This script opens the scan directory, opens each “prompt” file, derives the configured hostname by stripping off the “#” character, compares it with the subdirectory filename (which is the hostname according to DNS) and prints a message if they don’t match. In the example below, the script finds one switch where the DNS switch name doesn’t match the hostname configured on the switch:
$ python name_check.py
switch DNS hostname sfo03-r1r12-sw2 != configured hostname
↪SFO03-R1R10-SW1-Cisco_Core
It’s a reality that most complex networks are built up over a period of years by multiple people with different naming conventions, work styles, skill sets and so on. I’ve accumulated a number of “audit”-type checks that find and correct inconsistencies that can creep into a network over time. This is the perfect use case for network automation, because you can see everything at once, as opposed going through each device, one at a time.
Performance
During the initial debugging, I had the “scanning” script log in to each switch in a serial fashion. This worked fine for a few switches, but performance became a problem when I was scanning hundreds at a time. I used the Python multiprocessing module to fire off a bunch of “workers” that interacted with switches in parallel. This cut the processing time for the scanning portion down to a couple minutes, as the entire scan took only as long as the slowest switch took to complete. The switch scanning problem fits quite well into the multiprocessing model, because there are no events or data to coordinate between the individual workers. The Netmiko Tools also take advantage of multiprocessing and use a cache system to improve performance.
Future Directions
The most complicated script I’ve written so far with Netmiko logs in to every switch, gathers the LLDP neighbor info and produces a text-only topology map of the entire network. For those that are unfamiliar with LLDP, this is the Link Layer Discovery Protocol. Most modern network devices are sending LLDP multicasts out every port every 30 seconds. The LLDP data includes many details, including the switch hostname, port name, MAC address, device model, vendor, OS and so on. It allows any given device to know about all its immediate neighbors.
For example, here’s a typical LLDP display on a switch. The “Neighbor” columns show you details on what is connected to each of your local ports:
sfo03-r1r5-sw1# show lldp neighbors
Port Neighbor Device ID Neighbor Port ID TTL
Et1 sfo03-r1r3-sw1 Ethernet1 120
Et2 sfo03-r1r3-sw2 Te1/0/2 120
Et3 sfo03-r1r4-sw1 Te1/0/2 120
Et4 sfo03-r1r6-sw1 Ethernet1 120
Et5 sfo03-r1r6-sw2 Te1/0/2 120
By asking all the network devices for their list of LLDP neighbors, it’s possible to build a map of the network. My approach was to build a list of local switch ports and their LLDP neighbors for the top-level switch, and then recursively follow each switch link down the hierarchy of switches, adding each entry to a nested dictionary. This process becomes very complex when there are redundant links and endless loops to avoid, but I found it a great way to learn more about complex Python data structures.
The following output is from my “mapper” script. It uses indentation (from left to right) to show the hierarchy of switches, which is three levels deep in this example:
sfo03-r1r5-core:Et6 sfo03-r1r8-sw1:Ethernet1
sfo03-r1r8-sw1:Et22 sfo03-r6r8-sw3:Ethernet48
sfo03-r1r8-sw1:Et24 sfo03-r6r8-sw2:Te1/0/1
sfo03-r1r8-sw1:Et25 sfo03-r3r7-sw2:Te1/0/1
sfo03-r1r8-sw1:Et26 sfo03-r3r7-sw1:24
It prints the port name next to the switch hostname, which allows you to see both “sides” of the inter-switch links. This is extremely useful when trying to orient yourself on the network. I’m still working on this script, but it currently produces a “real-time” network topology map that can be turned into a network diagram.
I hope this information inspires you to investigate network automation. Start with Netmiko Tools and the inventory file to get a sense of what is possible. You likely will encounter a scenario that requires some Python coding, either using the output of Netmiko Tools or perhaps your own standalone script. Either way, the Netmiko functions make automating a large, multivendor network fairly easy.