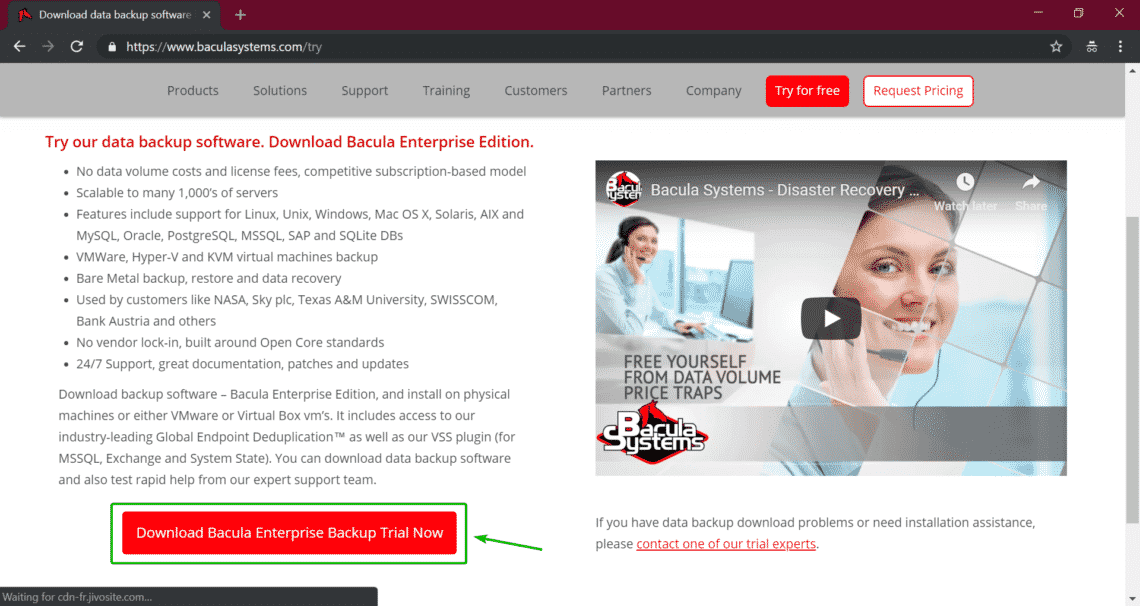
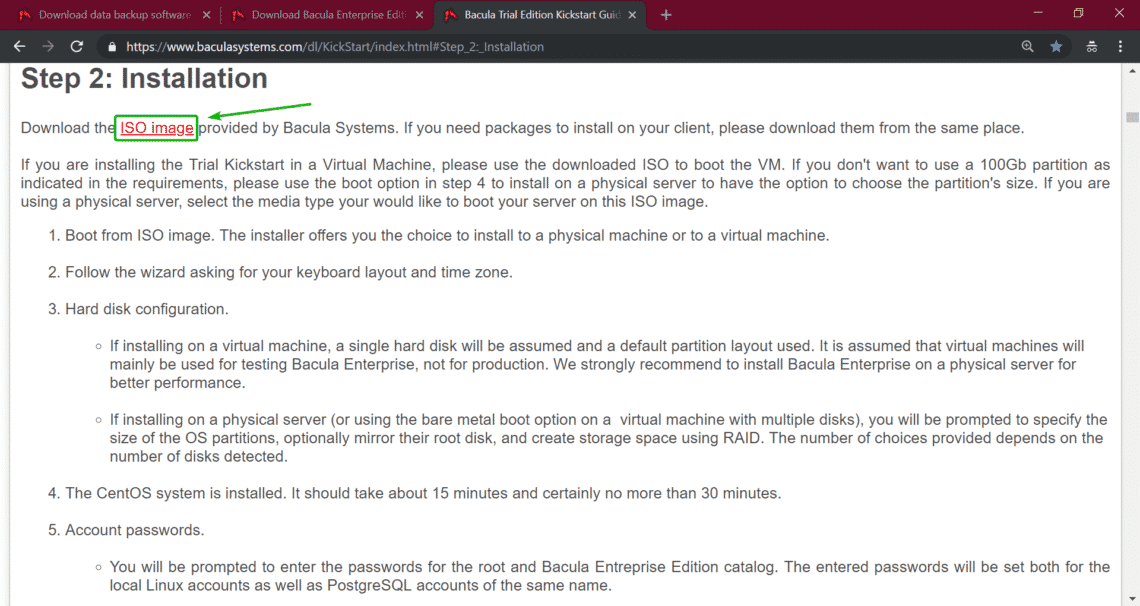
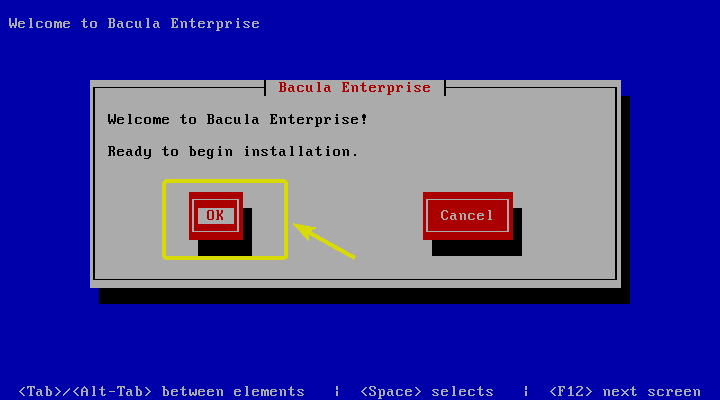
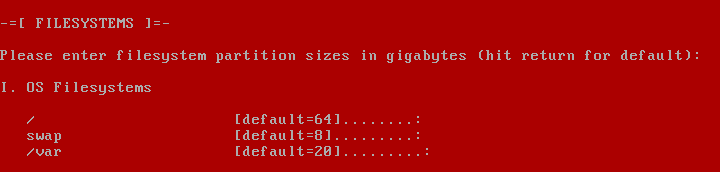
Bash 5.0 Released with New Features
Last updated January 9, 2019
The mailing list confirmed the release of Bash-5.0 recently. And, it is exciting to know that it comes baked with new features and variable.
Well, if you’ve been using Bash 4.4.XX, you will definitely love the fifth major release of Bash.
The fifth release focuses on new shell variables and a lot of major bug fixes with an overhaul. It also introduces a couple of new features along with some incompatible changes between bash-4.4 and bash-5.0.
![]()
What about the new features?
The mailing list explains the bug fixed in this new release:
This release fixes several outstanding bugs in bash-4.4 and introduces several new features. The most significant bug fixes are an overhaul of how nameref variables resolve and a number of potential out-of-bounds memory errors discovered via fuzzing. There are a number of changes to the expansion of [email protected] and $* in various contexts where word splitting is not performed to conform to a Posix standard interpretation, and additional changes to resolve corner cases for Posix conformance.
It also introduces some new features. As per the release note, these are the most notable new features are several new shell variables:
The BASH_ARGV0, EPOCHSECONDS, and EPOCHREALTIME. The ‘history’ builtin can remove ranges of history entries and understands negative arguments as offsets from the end of the history list. There is an option to allow local variables to inherit the value of a variable with the same name at a preceding scope. There is a new shell option that, when enabled, causes the shell to attempt to expand associative array subscripts only once (this is an issue when they are used in arithmetic expressions). The ‘globasciiranges‘ shell option is now enabled by default; it can be set to off by default at configuration time.
What about the changes between Bash-4.4 and Bash-5.0?
The update log mentioned about the incompatible changes and the supported readline version history. Here’s what it said:
There are a few incompatible changes between bash-4.4 and bash-5.0. The changes to how nameref variables are resolved means that some uses of namerefs will behave differently, though I have tried to minimize the compatibility issues. By default, the shell only sets BASH_ARGC and BASH_ARGV at startup if extended debugging mode is enabled; it was an oversight that it was set unconditionally and caused performance issues when scripts were passed large numbers of arguments.
Bash can be linked against an already-installed Readline library rather than the private version in lib/readline if desired. Only readline-8.0 and later versions are able to provide all of the symbols that bash-5.0 requires; earlier versions of the Readline library will not work correctly.
I believe some of the features/variables added are very useful. Some of my favorites are:
- There is a new (disabled by default, undocumented) shell option to enable and disable sending history to syslog at runtime.
- The shell doesn’t automatically set BASH_ARGC and BASH_ARGV at startup unless it’s in debugging mode, as the documentation has always said, but will dynamically create them if a script references them at the top level without having enabled debugging mode.
- The ‘history’ can now delete ranges of history entries using ‘-d start-end’.
- If a non-interactive shell with job control enabled detects that a foreground job died due to SIGINT, it acts as if it received the SIGINT.
- BASH_ARGV0: a new variable that expands to $0 and sets $0 on assignment.
To check the complete list of changes and features you should refer to the Mailing list post.
Wrapping Up
You can check your current Bash version, using this command:
bash –version
It’s more likely that you’ll have Bash 4.4 installed. If you want to get the new version, I would advise waiting for your distribution to provide it.
With Bash-5.0 available, what do you think about it? Are you using any alternative to bash? If so, would this update change your mind?
Let us know your thoughts in the comments below.