In this lesson on Python
Matplotlib library, we will look at various aspects of this data visualisation library which we can use with Python to generate beautiful and intuitive graphs which can visualise data in a form which business wants from a platform. To make this lesson complete, we will cover the following sections:
- What is Python Matplotlib?
- Types of Plots we can construct, like Bar Graph, Histogram, Scatter Plot, Area Plot and Pe Chart
- Working with Multiple plots
- Some alternatives for Python Matplotlib
What is Python Matplotlib?
The matplotlib.pyplot is a graph plotting package which can be used to construct 2-dimensional graphics using Python programming language. Due to its pluggable nature, this package can be used in any GUI applications, Web application servers or simple Python scripts. Some toolkits which extend the functionality of Python Matplotlib are:
- Basemap is a map plotting library that provides features to create map projects, coastlines and political boundaries
- Natgrid can be used to grid irregular data into spaced data
- Excel tools can be used to exchange data between MS Excel and Matplotlib
- Cartopy is a much complex mapping library which even provides image transformation features apart from point, line & polygon projections
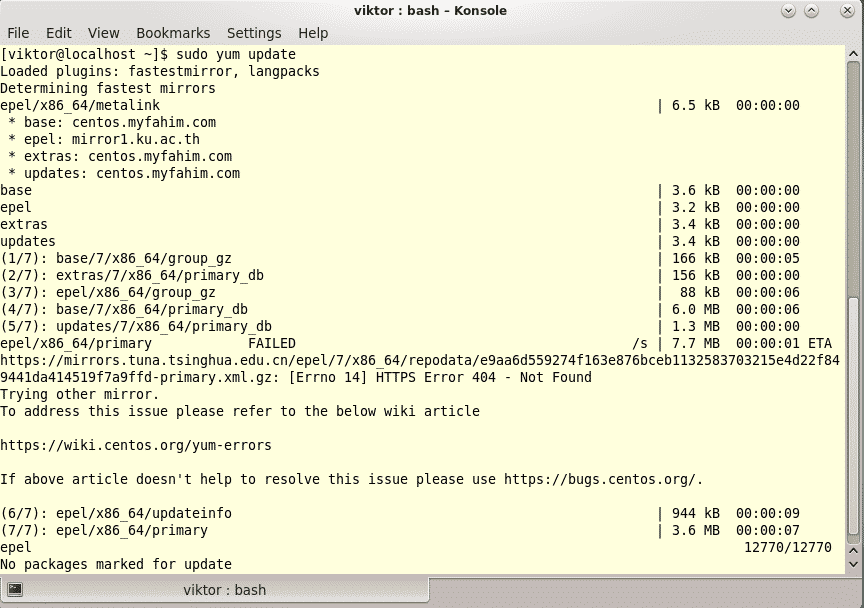
Just a note before starting is that we use a virtual environment for this lesson which we made with the following command:
python -m virtualenv matplotlib
source matplotlib/bin/activate
Once the virtual environment is active, we can install matplotlib library within the virtual env so that examples we create next can be executed:
We see something like this when we execute the above command:
You can use Anaconda as well to run these examples which is easier. If you want to install it on your machine, look at the lesson which describes “How to Install Anaconda Python on Ubuntu 18.04 LTS” and share your feedback. Now, let us move forward to various types of plots which can be constructed with Python Matplotlib.
Types of Plots
Here, we demonstrate the types of plots which can be drawn with Python Matplotlib.
Simple Graph
The first example we will see will be of a simple graph plot. This example is used as a demonstration of how simple it is to construct a graph plot along with simple customisations that come with it. We start by importing matplotlib and defining the x and y coordinates we want to plot:
from matplotlib import pyplot as plt
x = [3, 6, 9]
y = [2, 4, 6]
After this, we can plot these coordinates on the graph and show it:
plt.plot(x, y)
plt.show()
When we run this, we will see the following graph:
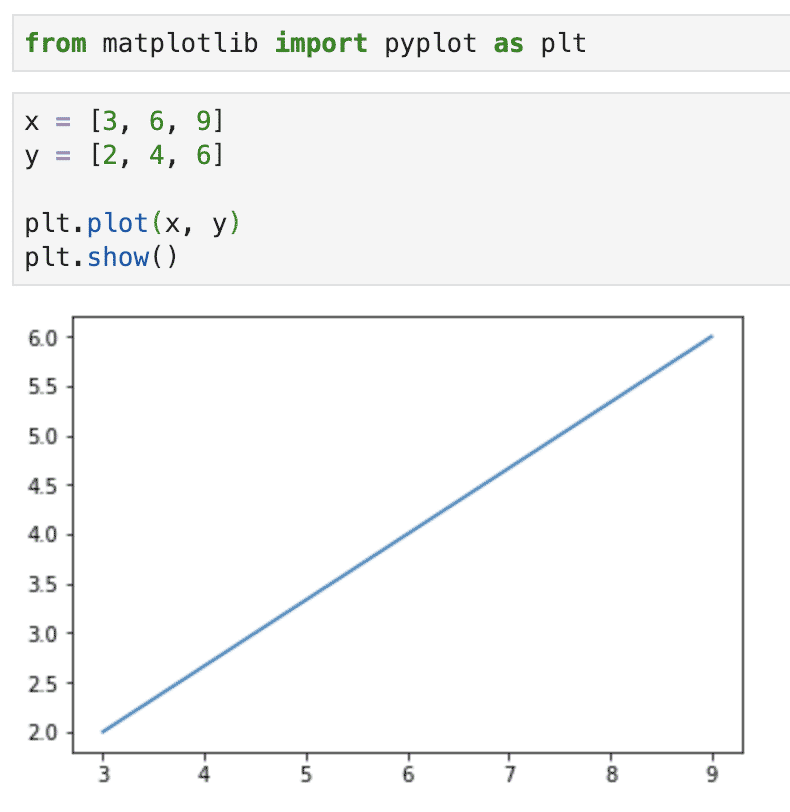
With just few lines of code, we were able to plot a graph. Let us add a few customisations to make this graph a little more expressive:
plt.title(‘LH Plot’)
plt.ylabel(‘Y axis’)
plt.xlabel(‘X axis’)
Add above lines of code just before you show the plot and graph will now have labels:

We will give one more attempt in customising this graph to make it intuitive with the following lines of code before we show the plot:
x1
= [3, 6, 9]
y1
= [2, 4, 6]
x2 = [2, 7, 9]
y2 = [4, 5, 8]
plt.title(‘Info’)
plt.ylabel(‘Y axis’)
plt.xlabel(‘X axis’)
plt.plot(x1 ,y1 , ‘g’, label=‘Quarter 1’, linewidth=5)
plt.plot(x2, y2, ‘r’, label=‘Quarter 2’, linewidth=5)
plt.legend()
plt.grid(True,color=‘k’)
plt.show()
We will see the following plot when we run the above code snippet:
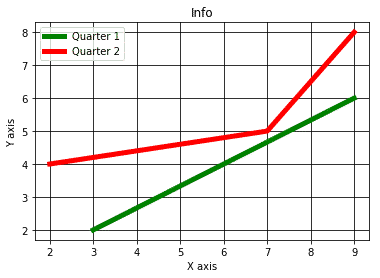
Notice what we started with and what we ended up with, a very intuitive and attractive graph which you can use in your presentations and it is made with pure Python code, definitely something to be proud of !
Making a Bar Graph
A bar graph is specifically useful when we want to platform a comparison with specific and limited measures. For example, comparing the average marks of students with a single subject is a good use-case. Let us construct a bar graph for the same use-case here, the code snippet for this will be:
avg_marks
= [81, 92, 55, 79]
physics
= [68, 77, 62, 74]
plt.bar([0.25, 1.25, 2.25, 3.25], avg_marks, label=“Average”, width=.5)
plt.bar([.75, 1.75, 2.75, 3.75], physics, label=“Physics”, color=‘r’, width=.5)
plt.legend()
plt.xlabel(‘Range’)
plt.ylabel(‘Marks’)
plt.title(‘Comparison’)
plt.show()
The bar graph created with the above sample data will look like the following:

There are multiple bars present here to establish a comparison. Please note that we have provided the width of each bar as a first parameters and bar is shifted 0.5 values from the previous one.
We can combine this bar graph construction with Pandas library to customise this more but we will cover it in a different lesson on Pandas.
Distributions with Histograms
Histograms are often confused with Bar charts. The most basic difference lies in their use-case. Bar charts are used to establish comparisons between data whereas histograms are used to describe data distribution.
For example, let us apply the example for student marks again but this time, we will only look at the average marks of students and look at how are they distributed. Here is the code snippet, very similar to the previous example:
bins
= [0,10,20,30,40,50,60,70,80,90,100]
avg_marks
= [81, 77, 55, 88, 81, 66, 51, 66, 81, 92, 55, 51]
plt.hist(avg_marks, bins, histtype=‘bar’, rwidth=0.8)
plt.xlabel(‘Range’)
plt.ylabel(‘Marks’)
plt.title(‘Comparison’)
plt.show()
The histogram created with above sample data will look like the following:

The Y-axis show here that how many students have got the same marks which were provided as the data for the construction.
Making a Scatter Plot
When it comes to comparing multiple variables and establish their effect on each other, Scatter plot is a good way to present the same. In this, data is represented as points with value of one variable reflected by horizontal axis and the value of second variable determines the position of the point on the vertical axis.
Let us look at a simple code snippet to describe the same:
x
= [1,1.5,2,2.5,3,3.5,3.6]
y
= [75,8,85,9,95,10,75]
x1=[8,8.5,9,9.5,10,10.5,11]
y1=[3,35,3.7,4,45,5,52]
plt.scatter(x,y, label=’10 High scoring students’,color=‘r’)
plt.scatter(x1,y1,label=’10 Low scoring students’,color=‘b’)
plt.xlabel(‘Marks’)
plt.ylabel(‘Student count’)
plt.title(‘Scatter Plot’)
plt.legend()
plt.show()
The scatter plot created with above sample data will look like the following:

Area Plots
The area plots are used mainly to track changes in data over time. They are also termed as stack plots in various texts. For example, if we want to establish a representation of time invested by a student to each subject in a single day, here is the code with which we can do the same:
days
= [1,2,3,4,5]
physics =[2,8,6,5,7]
python = [5,4,6,4,1]
r =[7,9,4,3,1]
math = [8,5,7,8,13]
plt.plot([],[],color=‘m’, label=‘Physics’, linewidth=5)
plt.plot([],[],color=‘c’, label=‘Python’, linewidth=5)
plt.plot([],[],color=‘r’, label=‘R’, linewidth=5)
plt.plot([],[],color=‘k’, label=‘Math’, linewidth=5)
plt.stackplot(days, physics, python, r, math, colors=[‘g’,‘k’,‘r’,‘b’])
plt.xlabel(‘x’)
plt.ylabel(‘y’)
plt.title(‘Stack Plot’)
plt.legend()
plt.show()
The area plot created with above sample data will look like the following:

The above output clearly establish a difference in time spent by a student in each subject with a clear way of providing the difference and the distribution.
Pie Charts
When we want to break whole part into multiple parts and describe the amount each part occupies, a pie chart is a good way to make this presentation. It is used to show the percentage of data in complete data set. Here is a basic code snippet to make a simple pie chart:
labels
= ‘Python’, ‘C++’, ‘Ruby’, ‘Java’
sizes
= [225, 130, 245, 210]
colors
= [‘r’, ‘b’, ‘g’, ‘c’]
explode
= (0.1, 0, 0, 0) # explode 1st slice
# Plot
plt.pie(sizes, explode=explode, labels=labels, colors=colors,
autopct=‘%1.1f%%’, shadow=True, startangle=140)
plt.axis(‘equal’)
plt.show()
The pie chart created with above sample data will look like the following:

In above sections, we looked at various graphical components we can construct with Matplotlib library to represent our data in various forms and establish differences in an intuitive manner while being statistical.
Features and Alternatives for Matplotlib
One of the best features for matplotlib is that it can work on many operating systems and graphical backends. It supports dozens of Operating systems and graphical output which we looked at in this lesson. This means we can count on it when it comes to providing an output in a way we need.
There are various other libraries present which can compete with matplotlib like:
- Seahorn
- Plotly
- Ggplot2
Even though above mentioned libraries might present some advanced ways to describe and present data in graphical manner but there no denial in the simplicity and effective nature of the matplotlib library.
Conclusion
In this lesson, we looked at various aspects of this data visualisation library which we can use with Python to generate beautiful and intuitive graphs which can visualise data in a form which business wants from a platform. The Matplotlib is one of the most important visualisation library when it comes to data engineering and presenting data in most visual forms, definitely a skill we need to have under our belt.