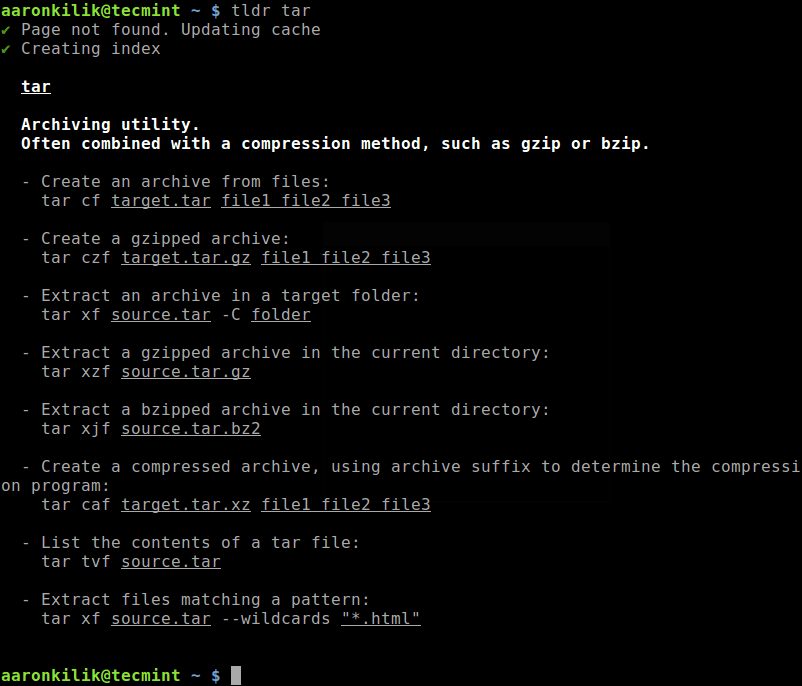
Linux Operating System comes with Kill command to terminate a process. The command makes it possible to continue running the server without the need of reboot after a major change/update. Here comes the great power of Linux and this is one of the reasons, why Linux is running on 90% of servers, on the planet.

Kill, Pkill and Killall Commands Examples
Kill command send a signal, a specified signal to be more perfect to a process. The kill command can be executed in a number of ways, directly or from a shell script.
Using kill command from /usr/bin provide you some extra feature to kill a process by process name using pkill. The common syntax for kill command is:
# kill [signal or option] PID(s)
For a kill command a Signal Name could be:
Signal Name Signal Value Behaviour SIGHUP 1 Hangup SIGKILL 9 Kill Signal SIGTERM 15 Terminate
Clearly from the behaviour above SIGTERM is the default and safest way to kill a process. SIGHUP is less secure way of killing a process as SIGTERM. SIGKILL is the most unsafe way among the above three, to kill a process which terminates a process without saving.
In order to kill a process, we need to know the Process ID of a process. A Process is an instance of a program. Every-time a program starts, automatically an unique PID is generated for that process. Every Process in Linux, have a pid. The first process that starts when Linux System is booted is – init process, hence it is assigned a value of ‘1‘ in most of the cases.
Init is the master process and can not be killed this way, which insures that the master process don’t gets killed accidentally. Init decides and allows itself to be killed, where kill is merely a request for a shutdown.
To know all the processes and correspondingly their assigned pid, run.
# ps -A
Sample Output
PID TTY TIME CMD
1 ? 00:00:01 init
2 ? 00:00:00 kthreadd
3 ? 00:00:00 migration/0
4 ? 00:00:00 ksoftirqd/0
5 ? 00:00:00 migration/0
6 ? 00:00:00 watchdog/0
7 ? 00:00:01 events/0
8 ? 00:00:00 cgroup
9 ? 00:00:00 khelper
10 ? 00:00:00 netns
11 ? 00:00:00 async/mgr
12 ? 00:00:00 pm
13 ? 00:00:00 sync_supers
14 ? 00:00:00 bdi-default
15 ? 00:00:00 kintegrityd/0
16 ? 00:00:00 kblockd/0
17 ? 00:00:00 kacpid
18 ? 00:00:00 kacpi_notify
19 ? 00:00:00 kacpi_hotplug
20 ? 00:00:00 ata/0
21 ? 00:00:00 ata_aux
22 ? 00:00:00 ksuspend_usbd
How about Customising the above output using syntax as ‘pidof process‘.
# pidof mysqld
Sample Output
1684
Another way to achieve the above goal is to follow the below syntax.
# ps aux | grep mysqld
Sample Output
root 1582 0.0 0.0 5116 1408 ? S 09:49 0:00 /bin/sh /usr/bin/mysqld_safe --datadir=/var/lib/mysql --socket=/var/lib/mysql/mysql.sock --pid-file=/var/run/mysqld/mysqld.pid --basedir=/usr --user=mysql mysql 1684 0.1 0.5 136884 21844 ? Sl 09:49 1:09 /usr/libexec/mysqld --basedir=/usr --datadir=/var/lib/mysql --user=mysql --log-error=/var/log/mysqld.log --pid-file=/var/run/mysqld/mysqld.pid --socket=/var/lib/mysql/mysql.sock root 20844 0.0 0.0 4356 740 pts/0 S+ 21:39 0:00 grep mysqld
Before we step ahead and execute a kill command, some important points to be noted:
- A user can kill all his process.
- A user can not kill another user’s process.
- A user can not kill processes System is using.
- A root user can kill System-level-process and the process of any user.
Another way to perform the same function is to execute ‘pgrep‘ command.
# pgrep mysq
Sample Output
3139
To kill the above process PID, use the kill command as shown.
kill -9 3139
The above command will kill the process having pid=3139, where PID is a Numerical Value of process.
Another way to perform the same function, can be rewritten as.
# kill -SIGTERM 3139
Similarly ‘kill -9 PID‘ is similar to ‘kill -SIGKILL PID‘ and vice-versa.
How about killing a process using process name
You must be aware of process name, before killing and entering a wrong process name may screw you.
# pkill mysqld
Kill more than one process at a time.
# kill PID1 PID2 PID3 or # kill -9 PID1 PID2 PID3 or # kill -SIGKILL PID1 PID2 PID3
What if a process have too many instances and a number of child processes, we have a command ‘killall‘. This is the only command of this family, which takes process name as argument in-place of process number.
Syntax:
# killall [signal or option] Process Name
To kill all mysql instances along with child processes, use the command as follow.
# killall mysqld
You can always verify the status of the process if it is running or not, using any of the below command.
# service mysql status # pgrep mysql # ps -aux | grep mysql
That’s all for now, from my side.