
Howdy! I have a good news for non-native English speakers. Now, you can improve your English vocabulary and find the meaning of English words, right from your Terminal. Say hello to Pyvoc, a cross-platform, open source, command line dictionary and vocabulary building tool written in Python programming language. Using this tool, you can brush up some English words meanings, test or improve your vocabulary skill or simply use it as a CLI dictionary on Unix-like operating systems.
Installing Pyvoc
Since Pyvoc is written using Python language, you can install it using Pip3 package manager.
$ pip3 install pyvoc
Once installed, run the following command to automatically create necessary configuration files in your $HOME directory.
$ pyvoc word
Sample output:
|Creating necessary config files
/getting api keys. please handle with care!
|
word
Noun: single meaningful element of speech or writing
example: I don't like the word ‘unofficial’
Verb: express something spoken or written
example: he words his request in a particularly ironic way
Interjection: used to express agreement or affirmation
example: Word, that's a good record, man
Done! Let us go ahead and brush the English skills.
Use Pyvoc as a command line Dictionary tool
Pyvoc fetches the word meaning from Oxford Dictionary API.
Let us say, you want to find the meaning of a word ‘digression’. To do so, run:
$ pyvoc digression

Find a word meaning using Pyvoc
See? Pyvoc not only displays the meaning of word ‘digression’, but also an example sentence which shows how to use that word in practical.
Let us see an another example.
$ pyvoc subterfuge
|
subterfuge
Noun: deceit used in order to achieve one's goal
example: he had to use subterfuge and bluff on many occasions
It also shows the word classes as well. As you already know, English has four major word classes:
- Nouns,
- Verbs,
- Adjectives,
- Adverbs.
Take a look at the following example.
$ pyvoc welcome
/
welcome
Noun: instance or manner of greeting someone
example: you will receive a warm welcome
Interjection: used to greet someone in polite or friendly way
example: welcome to the Wildlife Park
Verb: greet someone arriving in polite or friendly way
example: hotels should welcome guests in their own language
Adjective: gladly received
example: I'm pleased to see you, lad—you're welcome
As you see in the above output, the word ‘welcome’ can be used as a verb, noun, adjective and interjection. Pyvoc has given example for each class.
If you misspell a word, it will inform you to check the spelling of the given word.
$ pyvoc wlecome
\
No definition found. Please check the spelling!!
Useful, isn’t it?
Create vocabulary groups
A vocabulary group is nothing but a collection words added by the user. You can later revise or take quiz from these groups. 100 groups of 60 words are reserved for the user.
To add a word (E.g sporadic) to a group, just run:
$ pyvoc sporadic -a
-
sporadic
Adjective: occurring at irregular intervals or only in few places
example: sporadic fighting broke out
writing to vocabulary group...
word added to group number 51
As you can see, I didn’t provide any group number and pyvoc displayed the meaning of given word and automatically added that word to group number 51. If you don’t provide the group number, Pyvoc will incrementally add words to groups 51-100.
Pyvoc also allows you to specify a group number if you want to. You can specify a group from 1-50 using -goption. For example, I am going to add a word to Vocabulary group 20 using the following command.
$ pyvoc discrete -a -g 20
/
discrete
Adjective: individually separate and distinct
example: speech sounds are produced as a continuous sound signal rather
than discrete units
creating group Number 20...
writing to vocabulary group...
word added to group number 20
See? The above command displays the meaning of ‘discrete’ word and adds it to the vocabulary group 20. If the group doesn’t exists, Pyvoc will create it and add the word.
By default, Pyvoc includes three predefined vocabulary groups (101, 102, and 103). These custom groups has 800 words of each. All words in these groups are taken from GRE and SAT preparation websites.
To view the user-generated groups, simply run:
$ pyvoc word -l
-
word
Noun: single meaningful element of speech or writing
example: I don't like the word ‘unofficial’
Verb: express something spoken or written
example: he words his request in a particularly ironic way
Interjection: used to express agreement or affirmation
example: Word, that's a good record, man
USER GROUPS
Group no. No. of words
20 1
DEFAULT GROUP
Group no. No. of words
51 1
As you see, I have created one group (20) including the default group (51).
Test and improve English vocabulary
As I already said, you can use the Vocabulary groups to revise or take quiz from them.
For instance, to revise the group no. 101, use -r option like below.
$ pyvoc 101 -r
You can now revise the meaning of all words in the Vocabulary group 101 in random order. Just hit ENTER to go through next questions. Once done, hit CTRL+C to exit.

Revise Vocabulary group
Also, you take quiz from the existing groups to brush up your vocabulary. To do so, use -q option like below.
$ pyvoc 103 -q 50
This command allows you to take quiz of 50 questions from vocabulary group 103. Choose the correct answer from the list by entering the appropriate number. You will get 1 point for every correct answer. The more you score the more your vocabulary skill will be.
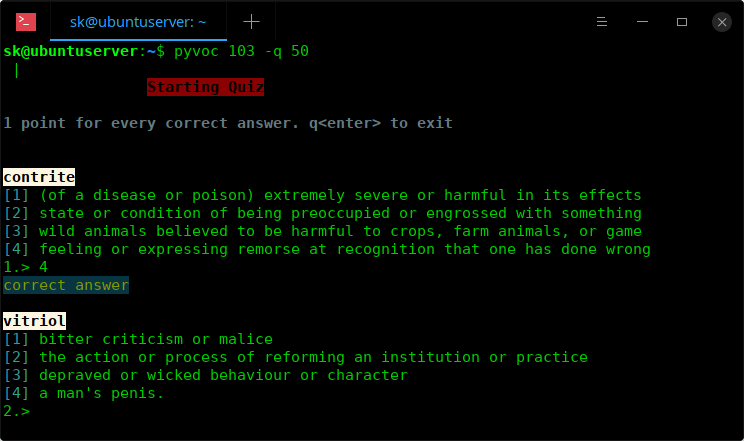
Take quiz using Pyvoc
Pyvoc is in the early-development stage. I hope the developer will improve it and add more features in the days to come.
As a non-native English speaker, I personally find it useful to test and learn new word meanings in my free time. If you’re a heavy command line user and wanted to quickly check the meaning of a word, Pyvoc is the right tool. You can also test your English Vocabulary at your free time to memorize and improve your English language skill. Give it a try. You won’t be disappointed.
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
Cheers!
Resource:
Source






 A graphical installer that allows you to install MyBB on top of a Bitnami LAMP Stack
A graphical installer that allows you to install MyBB on top of a Bitnami LAMP Stack






 An easy-to-install, ready-to-run binary distribution of Apache, PosgreSQL, PHP, and Python/mod_python
An easy-to-install, ready-to-run binary distribution of Apache, PosgreSQL, PHP, and Python/mod_python

