The DRBD (stands for Distributed Replicated Block Device) is a distributed, flexible and versatile replicated storage solution for Linux. It mirrors the content of block devices such as hard disks, partitions, logical volumes etc. between servers. It involves a copy of data on two storage devices, such that if one fails, the data on the other can be used.
You can think of it somewhat like a network RAID 1 configuration with the disks mirrored across servers. However, it operates in a very different way from RAID and even network RAID.
Originally, DRBD was mainly used in high availability (HA) computer clusters, however, starting with version 9, it can be used to deploy cloud storage solutions.
In this article, we will show how to install DRBD in CentOS and briefly demonstrate how to use it to replicate storage (partition) on two servers. This is the perfect article to get your started with using DRBD in Linux.
Testing Environment
For the purpose of this article, we are using two nodes cluster for this setup.
- Node1: 192.168.56.101 – tecmint.tecmint.lan
- Node2: 192.168.10.102 – server1.tecmint.lan
Step 1: Installing DRBD Packages
DRBD is implemented as a Linux kernel module. It precisely constitutes a driver for a virtual block device, so it’s established right near the bottom of a system’s I/O stack.
DRBD can be installed from the ELRepo or EPEL repositories. Let’s start by importing the ELRepo package signing key, and enable the repository as shown on both nodes.
# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org # rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
Then we can install the DRBD kernel module and utilities on both nodes by running:
# yum install -y kmod-drbd84 drbd84-utils
If you have SELinux enabled, you need to modify the policies to exempt DRBD processes from SELinux control.
# semanage permissive -a drbd_t
In addition, if your system has a firewall enabled (firewalld), you need to add the DRBD port 7789 in the firewall to allow synchronization of data between the two nodes.
Run these commands on the first node:
# firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="192.168.56.102" port port="7789" protocol="tcp" accept' # firewall-cmd --reload
Then run these commands on second node:
# firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="192.168.56.101" port port="7789" protocol="tcp" accept' # firewall-cmd --reload
Step 2: Preparing Lower-level Storage
Now that we have DRBD installed on the two cluster nodes, we must prepare a roughly identically sized storage area on both nodes. This can be a hard drive partition (or a full physical hard drive), a software RAID device, an LVM Logical Volume or a any other block device type found on your system.
For the purpose of this article, we will create a dummy block device of size 2GB using the dd command.
# dd if=/dev/zero of=/dev/sdb1 bs=2024k count=1024
We will assume that this is an unused partition (/dev/sdb1) on a second block device (/dev/sdb) attached to both nodes.
Step 3: Configuring DRBD
DRBD’s main configuration file is located at /etc/drbd.conf and additional config files can be found in the /etc/drbd.d directory.
To replicate storage, we need to add the necessary configurations in the /etc/drbd.d/global_common.conf file which contains the global and common sections of the DRBD configuration and we can define resources in .resfiles.
Let’s make a backup of the original file on both nodes, then then open a new file for editing (use a text editor of your liking).
# mv /etc/drbd.d/global_common.conf /etc/drbd.d/global_common.conf.orig # vim /etc/drbd.d/global_common.conf
Add the following lines in in both files:
global {
usage-count yes;
}
common {
net {
protocol C;
}
}
Save the file, and then close the editor.
Let’s briefly shade more light on the line protocol C. DRBD supports three distinct replication modes (thus three degrees of replication synchronicity) which are:
- protocol A: Asynchronous replication protocol; it’s most often used in long distance replication scenarios.
- protocol B: Semi-synchronous replication protocol aka Memory synchronous protocol.
- protocol C: commonly used for nodes in short distanced networks; it’s by far, the most commonly used replication protocol in DRBD setups.
Important: The choice of replication protocol influences two factors of your deployment: protection and latency. And throughput, by contrast, is largely independent of the replication protocol selected.
Step 4: Adding a Resource
A resource is the collective term that refers to all aspects of a particular replicated data set. We will define our resource in a file called /etc/drbd.d/test.res.
Add the following content to the file, on both nodes (remember to replace the variables in the content with the actual values for your environment).
Take note of the hostnames, we need to specify the network hostname which can be obtained by running the command uname -n.
resource test {
on tecmint.tecmint.lan {
device /dev/drbd0;
disk /dev/sdb1;
meta-disk internal;
address 192.168.56.101:7789;
}
on server1.tecmint.lan {
device /dev/drbd0;
disk /dev/sdb1;
meta-disk internal;
address 192.168.56.102:7789;
}
}
}
where:
- on hostname: the on section states which host the enclosed configuration statements apply to.
- test: is the name of the new resource.
- device /dev/drbd0: specifies the new virtual block device managed by DRBD.
- disk /dev/sdb1: is the block device partition which is the backing device for the DRBD device.
- meta-disk: Defines where DRBD stores its metadata. Using Internal means that DRBD stores its meta data on the same physical lower-level device as the actual production data.
- address: specifies the IP address and port number of the respective node.
Also note that if the options have equal values on both hosts, you can specify them directly in the resource section.
For example the above configuration can be restructured to:
resource test {
device /dev/drbd0;
disk /dev/sdb1;
meta-disk internal;
on tecmint.tecmint.lan {
address 192.168.56.101:7789;
}
on server1.tecmint.lan {
address 192.168.56.102:7789;
}
}
Step 4: Initializing and Enabling Resource
To interact with DRBD, we will use the following administration tools which communicate with the kernel module in order to configure and administer DRBD resources:
- drbdadm: a high-level administration tool of the DRBD.
- drbdsetup: a lower-level administration tool for to attach DRBD devices with their backing block devices, to set up DRBD device pairs to mirror their backing block devices, and to inspect the configuration of running DRBD devices.
- Drbdmeta:is the meta data management tool.
After adding all the initial resource configurations, we must bring up the resource on both nodes.
# drbdadm create-md test
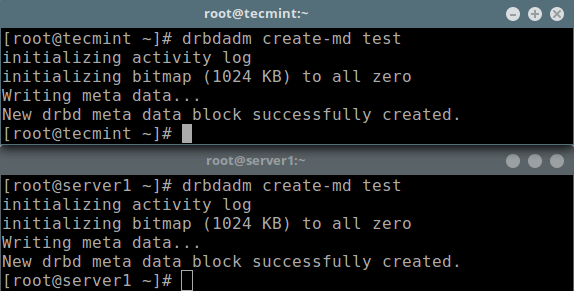
Initialize Meta Data Storage
Next, we should enable the resource, which will attach the resource with its backing device, then it sets replication parameters, and connects the resource to its peer:
# drbdadm up test
Now if you run the lsblk command, you will notice that the DRBD device/volume drbd0 is associated with the backing device /dev/sdb1:
# lsblk
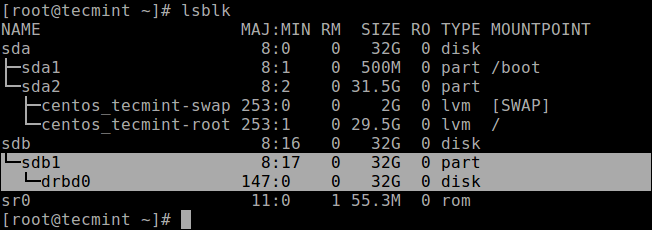
List Block Devices
To disable the resource, run:
# drbdadm down test
To check the resource status, run the following command (note that the Inconsistent/Inconsistent disk state is expected at this point):
# drbdadm status test OR # drbdsetup status test --verbose --statistics #for a more detailed status
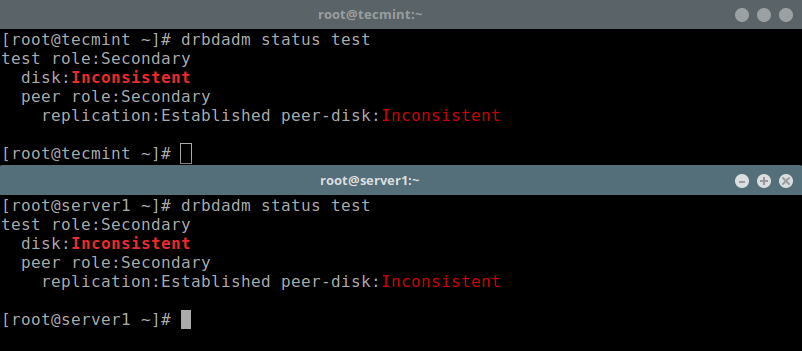
Check Resource Status on Nodes
Step 5: Set Primary Resource/Source of Initial Device Synchronization
At this stage, DRBD is now ready for operation. We now need to tell it which node should be used as the source of the initial device synchronization.
Run the following command on only one node to start the initial full synchronization:
# drbdadm primary --force test # drbdadm status test
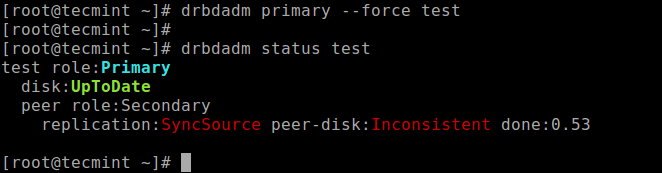
Set Primary Node for Initial Device
Once the synchronization is complete, the status of both disks should be UpToDate.
Step 6: Testing DRBD Setup
Finally, we need to test if the DRBD device will work well for replicated data storage. Remember, we used an empty disk volume, therefore we must create a filesystem on the device, and mount it, to test if we can use it for replicated data storage.
We can create a filesystem on the device with the following command, on the node where we started the initial full synchronization (which has the resource with primary role):
# mkfs -t ext4 /dev/drbd0
Make Filesystem on Drbd Volume
Then mount it as shown (you can give the mount point an appropriate name):
# mkdir -p /mnt/DRDB_PRI/ # mount /dev/drbd0 /mnt/DRDB_PRI/
Now copy or create some files in the above mount point and do a long listing using ls command:
# cd /mnt/DRDB_PRI/ # ls -l

List Contents of Drbd Primary Volume
Next, unmount the the device (ensure that the mount is not open, change directory after unmounting it to prevent any errors) and change the role of the node from primary to secondary:
# umount /mnt/DRDB_PRI/ # cd # drbdadm secondary test
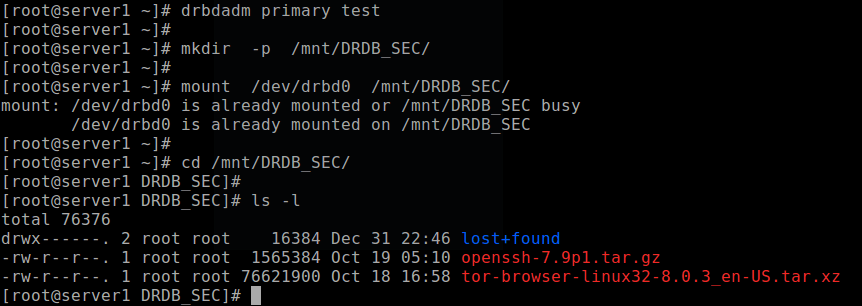
On the other node (which has the resource with a secondary role), make it primary, then mount the device on it and perform a long listing of the mount point. If the setup is working fine, all the files stored in the volume should be there:
# drbdadm primary test # mkdir -p /mnt/DRDB_SEC/ # mount /dev/drbd0 /mnt/DRDB_SEC/ # cd /mnt/DRDB_SEC/ # ls -l
Test DRBD Setup Working on Secondary Node
For more information, see the man pages of the user space administration tools:
# man drbdadm # man drbdsetup # man drbdmeta
Reference: The DRBD User’s Guide.
Summary
DRBD is extremely flexible and versatile, which makes it a storage replication solution suitable for adding HA to just about any application. In this article, we have shown how to install DRBD in CentOS 7 and briefly demonstrated how to use it to replicate storage.