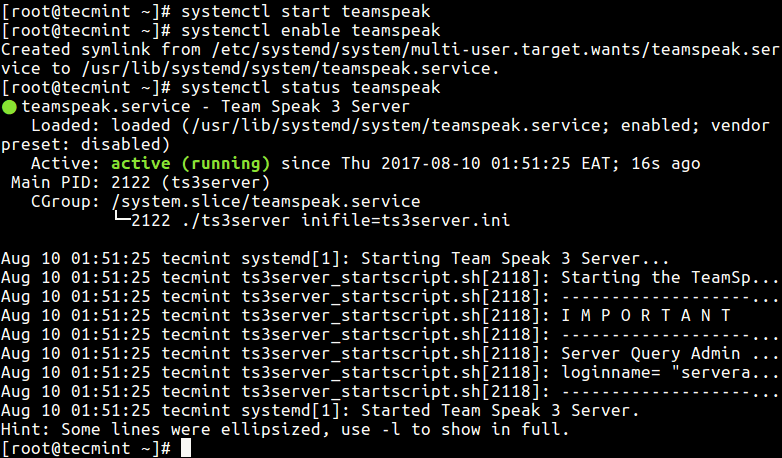
rsnapshot is an open source local / remote filesystem backup utility was written in Perl language that advantage the power of Rsync and SSH program to create, scheduled incremental backups of Linux/Unixfilesystems, while only taking up the space of one single full backup plus differences and keep those backups on local drive to different hard drive, an external USB stick, an NFS mounted drive or simply over the network to another machine via SSH.

Install Rsnapshot Backup Tool
This article will demonstrate how to install, setup and use rsnapshot to create incremental hourly, daily, weeklyand monthly local backups, as well as remote backups. To perform all the steps in this article, you must be rootuser.
Step 1: Installing Rsnapshot Backup in Linux
Installation of rsnapshot using Yum and APT may differs slightly, if you’re using Red Hat and Debian based distributions.
On RHEL/CentOS
First you will have to install and enable third-party repository called EPEL. Please follow below link to install and enable under your RHEL/CentOS systems. Fedora users don’t require any special repository configurations.
- Install and Enable EPEL Repository in RHEL/CentOS 6/5/4
Once you get things setup, install rsnapshot from the command line as shown.
# yum install rsnapshot
On Debian/Ubuntu/Linux Mint
By default, rsnapshot included in Ubuntu’s repositories, so you can install it using apt-get command as shown.
# apt-get install rsnapshot
Step 2: Setting up SSH Password-less Login
To backup remote Linux servers, your rsnapshot backup server will be able to connect through SSH without a password. To accomplish this, you will need to create an SSH public and private keys to authenticate on the rsnapshot server. Please follow below link to generate a public and private keys on your rsnapshot backup server.
- Create SSH Passwordless Login Using SSH Keygen
Step 3: Configuring Rsnapshot
Now you will need to edit and add some parameters to rsnapshot configuration file. Open rsnapshot.conf file with vi or nano editor.
# vi /etc/rsnapshot.conf
Next create a backup directory, where you want to store all your backups. In my case my backup directory location is “/data/backup/”. Search for and edit the following parameter to set the backup location.
snapshot_root /data/backup/
Also uncomment the “cmd_ssh” line to allow to take remote backups over SSH. To uncomment the line remove the “#” in-front of the following line so that rsnapshot can securely transfer your data to a backup server.
cmd_ssh /usr/bin/ssh
Next, you need to decide how many old backups you would like to keep, because rsnapshot had no idea how often you want to take snapshots. You need to specify how much data to save, add intervals to keep, and how many of each.
Well, the default settings are good enough, but still I would like you to enable “monthly” interval so that you could also have longer term backups in place. Please edit this section to look similar to below settings.
#########################################
# BACKUP INTERVALS #
# Must be unique and in ascending order #
# i.e. hourly, daily, weekly, etc. #
#########################################
interval hourly 6
interval daily 7
interval weekly 4
interval monthly 3
One more thing you need to edit is “ssh_args” variable. If you have changed the default SSH Port (22) to something else, you need to specify that port number of your remote backing up server.
ssh_args -p 7851
Finally, add your local and remote backup directories that you want to backup.
Backup Local Directories
If you’ve decided to backup your directories locally to the same machine, the backup entry would look like this. For example, I am taking backup of my /tecmint and /etc directories.
backup /tecmint/ localhost/
backup /etc/ localhost/
Backup Remote Directories
If you would like to backup up a remote server directories, then you need to tell the rsnapshot where the server is and which directories you want to backup. Here I am taking a backup of my remote server “/home” directory under “/data/backup” directory on rsnapshot server.
backup root@example.com:/home/ /data/backup/
Read Also:
- How to Backup/Sync Directories Using Rsync (Remote Sync) Tool
- How to Transfer Files/Folders Using SCP Command
Exclude Files and Directories
Here, I’m going to exclude everything, and then only specifically define what I want to backed up. To do this, you need to create a exclude file.
# vi /data/backup/tecmint.exclude
First get the list of directories that you want to backed up and add ( – * ) to exclude everything else. This will only backup what you listed in the file. My exclude file looks like similar to below.
+ /boot
+ /data
+ /tecmint
+ /etc
+ /home
+ /opt
+ /root
+ /usr
- /usr/*
- /var/cache
+ /var
- /*
Using exclude file option can be very tricky due to use of rsync recursion. So, my above example may not be what you are looking. Next add the exclude file to rsnapshot.conf file.
exclude_file /data/backup/tecmint.exclude
Finally, you are almost finished with the initial configuration. Save the “/etc/rsnapshot.conf” configuration file before moving further. There are many options to explain, but here is my sample configuration file.
config_version 1.2
snapshot_root /data/backup/
cmd_cp /bin/cp
cmd_rm /bin/rm
cmd_rsync /usr/bin/rsync
cmd_ssh /usr/bin/ssh
cmd_logger /usr/bin/logger
cmd_du /usr/bin/du
interval hourly 6
interval daily 7
interval weekly 4
interval monthly 3
ssh_args -p 25000
verbose 2
loglevel 4
logfile /var/log/rsnapshot/
exclude_file /data/backup/tecmint.exclude
rsync_long_args --delete --numeric-ids --delete-excluded
lockfile /var/run/rsnapshot.pid
backup /tecmint/ localhost/
backup /etc/ localhost/
backup root@example.com:/home/ /data/backup/
All the above options and argument explanations are as follows:
- config_version 1.2 = Configuration file version
- snapshot_root = Backup Destination to store snapshots
- cmd_cp = Path to copy command
- cmd_rm = Path to remove command
- cmd_rsync = Path to rsync
- cmd_ssh = Path to SSH
- cmd_logger = Path to shell command interface to syslog
- cmd_du = Path to disk usage command
- interval hourly = How many hourly backups to keep.
- interval daily = How many daily backups to keep.
- interval weekly = How many weekly backups to keep.
- interval monthly = How many monthly backups to keep.
- ssh_args = Optional SSH arguments, such as a different port (-p )
- verbose = Self-explanatory
- loglevel = Self-explanatory
- logfile = Path to logfile
- exclude_file = Path to the exclude file (will be explained in more detail)
- rsync_long_args = Long arguments to pass to rsync
- lockfile = Self-explanatory
- backup = Full path to what to be backed up followed by relative path of placement.
Step 4: Verify Rsnapshot Configuration
Once you’ve done with your all configuration, its time to verify that everything works as expected. Run the following command to verify that your configuration has the correct syntax.
# rsnapshot configtest
Syntax OK
If everything configured correctly, you will receive a “Syntax OK” message. If you get any error messages, that means you need to correct those errors before running rsnapshot.
Next, do a test run on one of the snapshot to make sure that we are generating correct results. We take the “hourly” parameter to do a test run using -t (test) argument. This below command will display a verbose list of the things it will do, without actually doing them.
# rsnapshot -t hourly
Sample Output
echo 2028 > /var/run/rsnapshot.pid
mkdir -m 0700 -p /data/backup/
mkdir -m 0755 -p /data/backup/hourly.0/
/usr/bin/rsync -a --delete --numeric-ids --relative --delete-excluded /home \
/backup/hourly.0/localhost/
mkdir -m 0755 -p /backup/hourly.0/
/usr/bin/rsync -a --delete --numeric-ids --relative --delete-excluded /etc \
/backup/hourly.0/localhost/
mkdir -m 0755 -p /data/backup/hourly.0/
/usr/bin/rsync -a --delete --numeric-ids --relative --delete-excluded \
/usr/local /data/backup/hourly.0/localhost/
touch /data/backup/hourly.0/
Note: The above command tells rsnapshot to create an “hourly” backup. It actually prints out the commands that it will perform when we execute it really.
Step 5: Running Rsnapshot Manually
After verifying your results, you can remove the “-t” option to run the command really.
# rsnapshot hourly
The above command will run the backup script with all the configuration that we added in the rsnapshot.conffile and creates a “backup” directory and then creates the directory structure under it that organizes our files. After running above command, you can verify the results by going to the backup directory and list the directory structure using ls -l command as shown.
# cd /data/backup
# ls -l
total 4
drwxr-xr-x 3 root root 4096 Oct 28 09:11 hourly.0
Step 6: Automating the Process
To automate the process, you need to schedule rsnapshot to be run at certain intervals from Cron. By default, rsnapshot comes with cron file under “/etc/cron.d/rsnapshot“, if it’s doesn’t exists create one and add the following lines to it.
By default rules are commented, so you need to remove the “#” from in front of the scheduling section to enable these values.
# This is a sample cron file for rsnapshot.
# The values used correspond to the examples in /etc/rsnapshot.conf.
# There you can also set the backup points and many other things.
#
# To activate this cron file you have to uncomment the lines below.
# Feel free to adapt it to your needs.
0 */4 * * * root /usr/bin/rsnapshot hourly
30 3 * * * root /usr/bin/rsnapshot daily
0 3 * * 1 root /usr/bin/rsnapshot weekly
30 2 1 * * root /usr/bin/rsnapshot monthly
Let me explain exactly, what above cron rules does:
- Runs every 4 hours and creates an hourly directory under /backup directory.
- Runs daily at 3:30am and create a daily directory under /backup directory.
- Runs weekly on every Monday at 3:00am and create a weekly directory under /backup directory.
- Runs every monthly at 2:30am and create a monthly directory under /backup directory.
To better understand on how cron rules works, I suggest you read our article that describes.
- 11 Cron Scheduling Examples
Step 7: Rsnapshot Reports
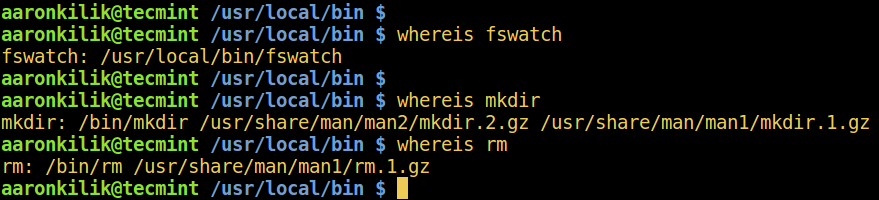
The rsnapshot provides a nifty small reporting Perl script that sends you an email alert with all the details as to what occurred during your data backup. To setup this script, you need to copy the script somewhere under “/usr/local/bin” and make it executable.
# cp /usr/share/doc/rsnapshot-1.3.1/utils/rsnapreport.pl /usr/local/bin
# chmod +x /usr/local/bin/rsnapreport.pl
Next, add “–stats” parameter in your “rsnapshot.conf” file to the rsync’s long arguments section.
vi /etc/rsnapshot.conf
rsync_long_args --stats --delete --numeric-ids --delete-excluded
Now edit the crontab rules that were added earlier and call the rsnapreport.pl script to pass the reports to specified email address.
# This is a sample cron file for rsnapshot.
# The values used correspond to the examples in /etc/rsnapshot.conf.
# There you can also set the backup points and many other things.
#
# To activate this cron file you have to uncomment the lines below.
# Feel free to adapt it to your needs.
0 */4 * * * root /usr/bin/rsnapshot hourly 2>&1 | \/usr/local/bin/rsnapreport.pl | mail -s "Hourly Backup" yourname@email.com
30 3 * * * root /usr/bin/rsnapshot daily 2>&1 | \/usr/local/bin/rsnapreport.pl | mail -s "Daily Backup" yourname@email.com
0 3 * * 1 root /usr/bin/rsnapshot weekly 2>&1 | \/usr/local/bin/rsnapreport.pl | mail -s "Weekly Backup" yourname@email.com
30 2 1 * * root /usr/bin/rsnapshot monthly 2>&1 | \/usr/local/bin/rsnapreport.pl | mail -s "Montly Backup" yourname@email.com
Once you’ve added above entries correctly, you will get a report to your e-mail address similar to below.
SOURCE TOTAL FILES FILES TRANS TOTAL MB MB TRANS LIST GEN TIME FILE XFER TIME
--------------------------------------------------------------------------------------------------------
localhost/ 185734 11853 2889.45 6179.18 40.661 second 0.000 seconds
Reference Links
- rsnapshot homepage
That’s it for now, if any problems occur during installation do drop me a comment. Till then stay tuned to TecMint for more interesting articles on the Open source world.
Source