Learn how to move files with Linux commands in this tutorial from our archives.
There are certain tasks that are done so often, users take for granted just how simple they are. But then, you migrate to a new platform and those same simple tasks begin to require a small portion of your brain’s power to complete. One such task is moving files from one location to another. Sure, it’s most often considered one of the more rudimentary actions to be done on a computer. When you move to the Linux platform, however, you may find yourself asking “Now, how do I move files?”
If you’re familiar with Linux, you know there are always many routes to the same success. Moving files is no exception. You can opt for the power of the command line or the simplicity of the GUI – either way, you will get those files moved.
Let’s examine just how you can move those files about. First we’ll examine the command line.
Command line moving
One of the issues so many users, new to Linux, face is the idea of having to use the command line. It can be somewhat daunting at first. Although modern Linux interfaces can help to ensure you rarely have to use this “old school” tool, there is a great deal of power you would be missing if you ignored it all together. The command for moving files is a perfect illustration of this.
The command to move files is mv. It’s very simple and one of the first commands you will learn on the platform. Instead of just listing out the syntax and the usual switches for the command – and then allowing you to do the rest – let’s walk through how you can make use of this tool.
The mv command does one thing – it moves a file from one location to another. This can be somewhat misleading, because mv is also used to rename files. How? Simple. Here’s an example. Say you have the file testfile in /home/jack/ and you want to rename it to testfile2 (while keeping it in the same location). To do this, you would use the mv command like so:
mv /home/jack/testfile /home/jack/testfile2
or, if you’re already within /home/jack:
mv testfile testfile2
The above commands would move /home/jack/testfile to /home/jack/testfile2 – effectively renaming the file. But what if you simply wanted to move the file? Say you want to keep your home directory (in this case /home/jack) free from stray files. You could move that testfile into /home/jack/Documents with the command:
mv /home/jack/testfile /home/jack/Documents/
With the above command, you have relocated the file into a new location, while retaining the original file name.
What if you have a number of files you want to move? Luckily, you don’t have to issue the mv command for every file. You can use wildcards to help you out. Here’s an example:
You have a number of .mp3 files in your ~/Downloads directory (~/ – is an easy way to represent your home directory – in our earlier example, that would be /home/jack/) and you want them in ~/Music. You could quickly move them with a single command, like so:
mv ~/Downloads/*.mp3 ~/Music/
That command would move every file that ended in .mp3 from the Downloads directory, and move them into the Music directory.
Should you want to move a file into the parent directory of the current working directory, there’s an easy way to do that. Say you have the file testfile located in ~/Downloads and you want it in your home directory. If you are currently in the ~/Downloads directory, you can move it up one folder (to ~/) like so:
mv testfile ../
The “../” means to move the folder up one level. If you’re buried deeper, say ~/Downloads/today/, you can still easily move that file with:
mv testfile ../../
Just remember, each “../” represents one level up.
As you can see, moving files from the command line, isn’t difficult at all.
GUI
There are a lot of GUIs available for the Linux platform. On top of that, there are a lot of file managers you can use. The most popular file managers are Nautilus (GNOME) and Dolphin (KDE). Both are very powerful and flexible. I want to illustrate how files are moved using the Nautilus file manager (on the Ubuntu 13.10 distribution, with Unity as the interface).
Nautilus has probably the most efficient means of moving files about. Here’s how it’s done:
- Open up the Nautilus file manager.
- Locate the file you want to move and right-click said file.
- From the pop-up menu (Figure 1) select the “Move To” option.
- When the Select Destination window opens, navigate to the new location for the file.
- Once you’ve located the destination folder, click Select.
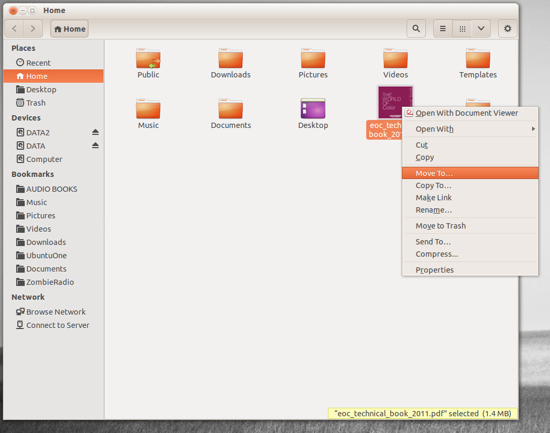
This context menu also allows you to copy the file to a new location, move the file to the Trash, and more.
If you’re more of a drag and drop kind of person, fear not – Nautilus is ready to serve. Let’s say you have a file in your home directory and you want to drag it to Documents. By default, Nautilus will have a few bookmarks in the left pane of the window. You can drag the file into the Document bookmark without having to open a second Nautilus window. Simply click, hold, and drag the file from the main viewing pane to the Documents bookmark.
If, however, the destination for that file is not listed in your bookmarks (or doesn’t appear in the current main viewing pane), you’ll need to open up a second Nautilus window. Side by side, you can then drag the file from the source folder in the original window to the the destination folder in the second window.
If you need to move multiple files, you’re still in luck. Similar to nearly every modern user interface, you can do multi-select of files by holding down the Ctrl button as you click each file. After you have selected each file (Figure 2), you can either right-click one of the selected files and the choose the Move To option, or just drag and drop them into a new location.
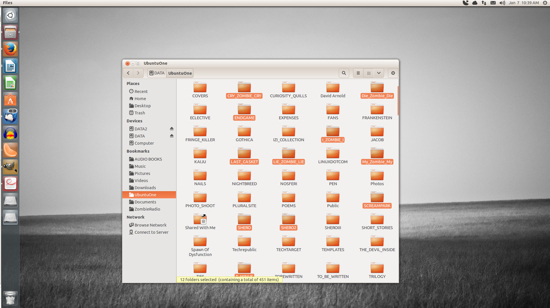
The selected files (in this case, folders) will each be highlighted.
Moving files on the Linux desktop is incredibly easy. Either with the command line or your desktop of choice, you have numerous routes to success – all of which are user-friendly and quick to master.
Source

