Environment Variables are some special variables that are defined in shell and are needed by programs while execution. They can be system defined or user defined. System defined variables are those which are set by system and are used by system level programs.

Set and Unset Linux Environment Variables
For e.g. PWD command is a very common system variable which is used to store the present working directory. User defined variables are typically set by user, either temporarily for the current shell or permanently. The whole concept of setting and un-setting environment variables revolves around some set of files and few commands and different shells.
In Broader terms, an environment variable can be in three types:
1. Local Environment Variable
One defined for the current session. These environment variables last only till the current session, be it remote login session, or local terminal session. These variables are not specified in any configuration files and are created, and removed by using a special set of commands.
2. User Environment Variable
These are the variables which are defined for a particular user and are loaded every time a user logs in using a local terminal session or that user is logged in using remote login session. These variables are typically set in and loaded from following configuration files: .bashrc, .bash_profile, .bash_login, .profile files which are present in user’s home directory.
3. System wide Environment Variables
These are the environment variables which are available system-wide, i.e. for all the users present on that system. These variables are present in system-wide configuration files present in following directories and files: /etc/environment, /etc/profile, /etc/profile.d/, /etc/bash.bashrc. These variables are loaded every time system is powered on and logged in either locally or remotely by any user.
Understanding User-Wide and System-wide Configuration files
Here, we briefly describe various configuration files listed above that hold Environment Variables, either system wide or user specific.
.bashrc
This file is user specific file that gets loaded each time user creates a new local session i.e. in simple words, opens a new terminal. All environment variables created in this file would take effect every time a new local session is started.
.bash_profile
This file is user specific remote login file. Environment variables listed in this file are invoked every time the user is logged in remotely i.e. using ssh session. If this file is not present, system looks for either .bash_login or .profile files.
/etc/environment
This file is system wide file for creating, editing or removing any environment variables. Environment variables created in this file are accessible all throughout the system, by each and every user, both locally and remotely.
/etc/bash.bashrc
System wide bashrc file. This file is loaded once for every user, each time that user opens a local terminal session. Environment variables created in this file are accessible for all users but only through local terminal session. When any user on that machine is accessed remotely via a remote login session, these variables would not be visible.
/etc/profile
System wide profile file. All the variables created in this file are accessible by every user on the system, but only if that user’s session is invoked remotely, i.e. via remote login. Any variable in this file will not be accessible for local login session i.e. when user opens a new terminal on his local system.
Note: Environment variables created using system-wide or user-wide configuration files can be removed by removing them from these files only. Just that after each change in these files, either log out and log in again or just type following command on the terminal for changes to take effect:
$ source <file-name>
Set or Unset Local or Session-wide Environment Variables in Linux
Local Environment Variables can be created using following commands:
$ var=value
OR
$ export var=value
These variables are session wide and are valid only for current terminal session. To Clear these session-wide environment variables following commands can be used:
1. Using env
By default, "env" command lists all the current environment variables. But, if used with '-i' switch, it temporarily clears out all the environment variables and lets user execute a command in current session in absence of all the environment variables.
$ env –i [Var=Value]… command args…
Here, var=value corresponds to any local environment variable that you want to use with this command only.
$ env –i bash
Will give bash shell which temporarily would not have any of the environment variable. But, as you exit from the shell, all the variables would be restored.
2. Using unset
Another way to clear local environment variable is by using unset command. To unset any local environment variable temporarily,
$ unset <var-name>
Where, var-name is the name of local variable which you want to un-set or clear.
3. Set the variable name to ”
Another less common way would be to set the name of the variable which you want to clear, to '' (Empty). This would clear the value of the local variable for current session for which it is active.
NOTE – YOU CAN EVEN PLAY WITH AND CHANGE THE VALUES OF SYSTEM OR USER ENVIRONMENT VARIABLES, BUT CHANGES WOULD REFLECT IN CURRENT TERMINAL SESSION ONLY AND WOULD NOT BE PERMANENT.
Learn How to Create, User-Wide and System-Wide Environment Variables in Linux
In section, we will going to learn how to set or unset local, user and system wide environment variables in Linux with below examples:
1. Set and Unset Local Variables in Linux
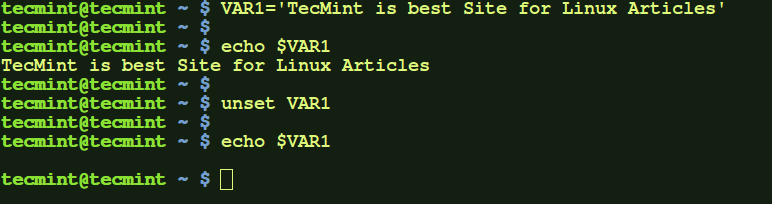
a.) Here, we create a local variable VAR1 and set it to any value. Then, we use unset to remove that local variable, and at the end that variable is removed.
$ VAR1='TecMint is best Site for Linux Articles'
$ echo $VAR1
$ unset VAR1
$ echo $VAR1
Set Unset Local Environment Variables
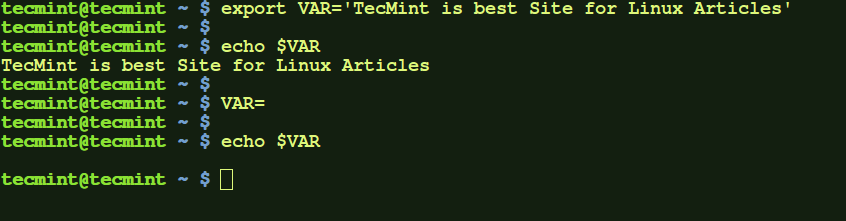
b.) Another way of creating a local variable is by using export command. The local variable created will be available for current session. To unset the variable simply set the value of variable to ''.
$ export VAR='TecMint is best Site for Linux Articles'
$ echo $VAR
$ VAR=
$ echo $VAR
Export Local Environment Variables in Linux
c.) Here, we created a local variable VAR2 and set it to a value. Then in-order to run a command temporarily clearing out all local and other environment variables, we executed 'env –i' command. This command here executed bash shell by clearing out all other environment variables. After entering 'exit' on the invoked bash shell, all variables would be restored.
$ VAR2='TecMint is best Site for Linux Articles'
$ echo $VAR2
$ env -i bash
$ echo $VAR2
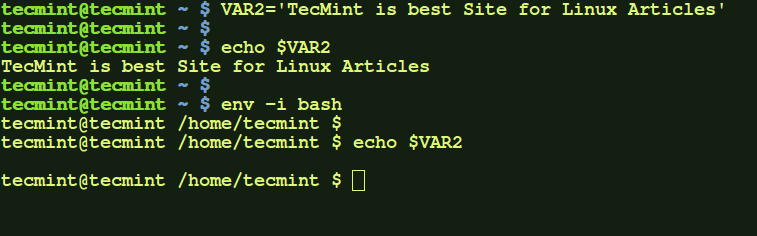
Use Env Command to Unset Variables
2. Set and Unset User-Wide Environment Variables in Linux
a.) Modify .bashrc file in your home directory to export or set the environment variable you need to add. After that source the file, to make the changes take effect. Then you would see the variable ('CD' in my case), taking effect. This variable will be available every time you open a new terminal for this user, but not for remote login sessions.
$ vi .bashrc
Add the following line to .bashrc file at the bottom.
export CD='This is TecMint Home'
Now run the following command to take new changes and test it.
$ source .bashrc
$ echo $CD
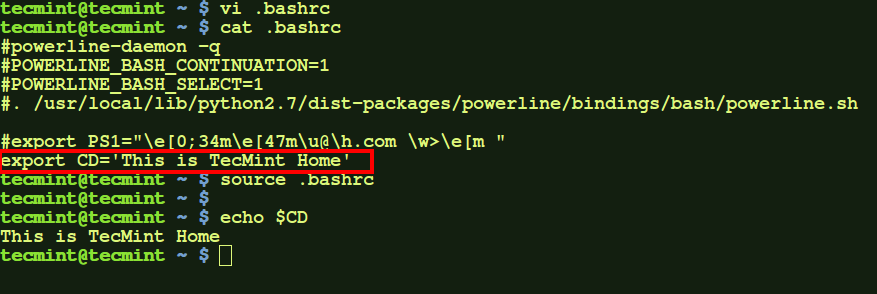
Set User-Wide Environment Variables in Linux
To remove this variable, just remove the following line in .bashrc file and re-source it:
b.) To add a variable which will be available for remote login sessions (i.e. when you ssh to the user from remote system), modify .bash_profile file.
$ vi .bash_profile
Add the following line to .bash_profile file at the bottom.
export VAR2='This is TecMint Home'
When on sourcing this file, the variable will be available when you ssh to this user, but not on opening any new local terminal.
$ source .bash_profile
$ echo $VAR2
Here, VAR2 is not initially available but, on doing ssh to user on localhost, the variable becomes available.
$ ssh tecmint@localhost
$ echo $VAR2
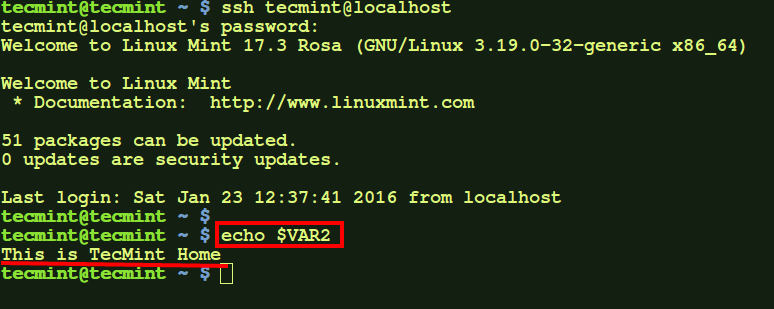
Export User Wide Variables in Bash Profile
To remove this variable, just remove the line in .bash_profile file which you added, and re-source the file.
NOTE: These variables will be available every time you are logged in to current user but not for other users.
3. Set and Unset System-Wide Environment Variables in Linux
a.) To add system wide no-login variable (i.e. one which is available for all users when any of them opens new terminal but not when any user of machine is remotely accessed) add the variable to /etc/bash.bashrc file.
export VAR='This is system-wide variable'

Add System Wide Environment Variables
After that, source the file.
$ source /etc/bash.bashrc
Now this variable will be available for every user when he opens any new terminal.
$ echo $VAR
$ sudo su
$ echo $VAR
$ su -
$ echo $VAR
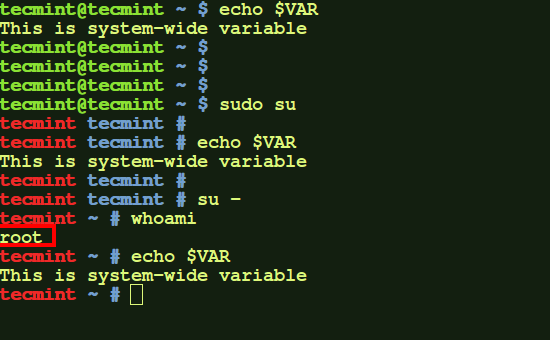
Check System Wide Variables
Here, same variable is available for root user as well as normal user. You can verify this by logging in to other user.
b.) If you want any environment variable to be available when any of the user on your machine is remotely logged in, but not on opening any new terminal on local machine, then you need to edit the file – '/etc/profile'.
export VAR1='This is system-wide variable for only remote sessions'
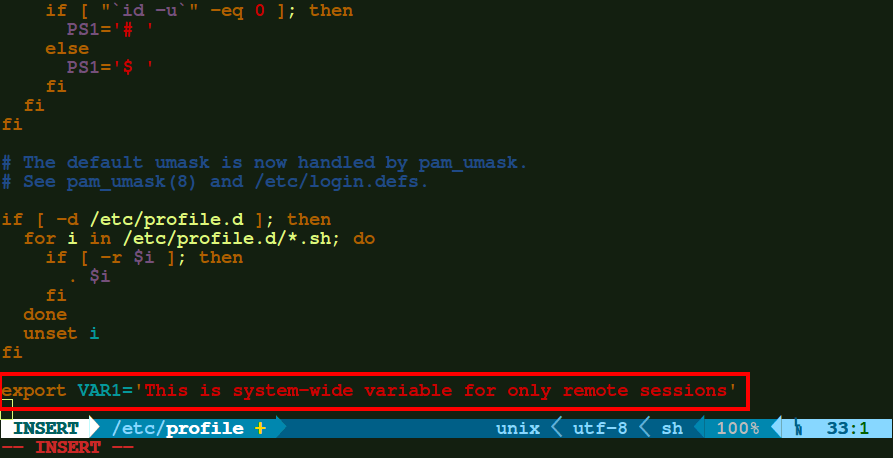
Add System Wide Variables in Profile
After adding the variable, just re-source the file. Then the variable would be available.
$ source /etc/profile
$ echo $VAR1
To remove this variable, remove the line from /etc/profile file and re-source it.
c.) However, if you want to add any environment which you want to be available all throughout the system, on both remote login sessions as well as local sessions( i.e. opening a new terminal window) for all users, just export the variable in /etc/environment file.
export VAR12='I am available everywhere'
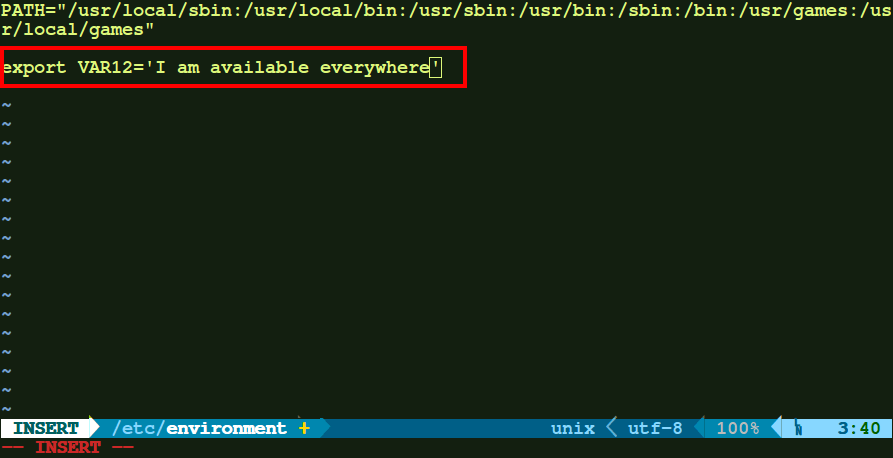
Add System Variable in Environment File
After that just source the file and the changes would take effect.
$ source /etc/environment
$ echo $VAR12
$ sudo su
$ echo $VAR12
$ exit
$ ssh localhost
$ echo $VAR12
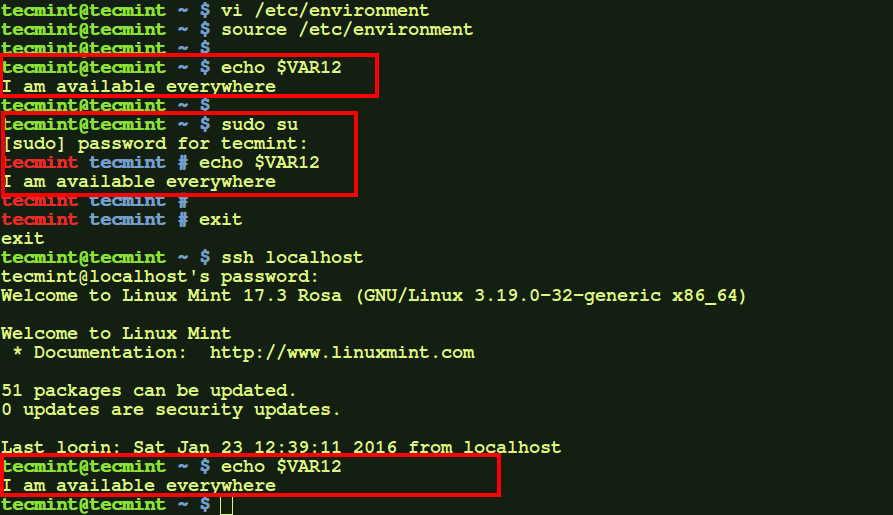
Check Environment Variable for All Users
Here, as we see the environment variable is available for normal user, root user, as well as on remote login session (here, to localhost).
To clear out this variable, just remove the entry in the /etc/environment file and re-source it or login again.
NOTE: Changes take effect when you source the file. But, if not then you might need to log out and log in again.
Conclusion
Thus, these are few ways we can modify the environment variables. If you find any new and interesting tricks for the same do mention in your comments.
Source