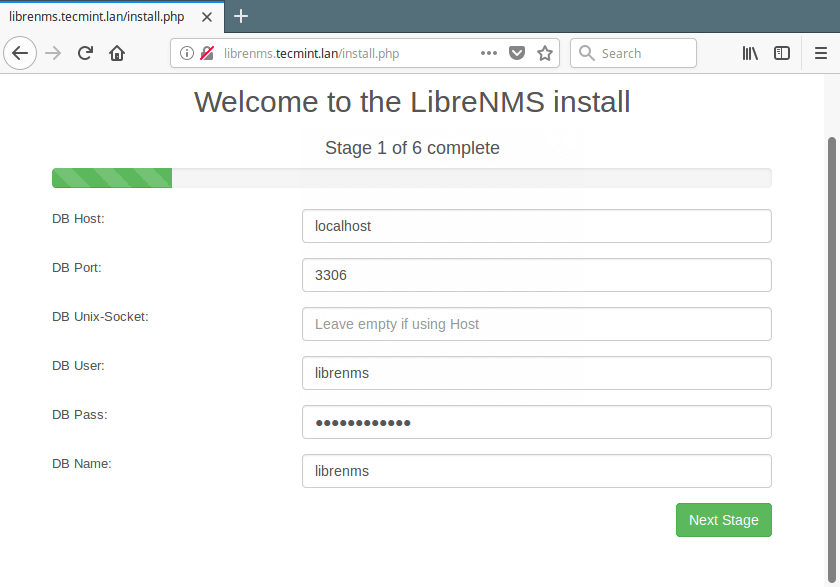
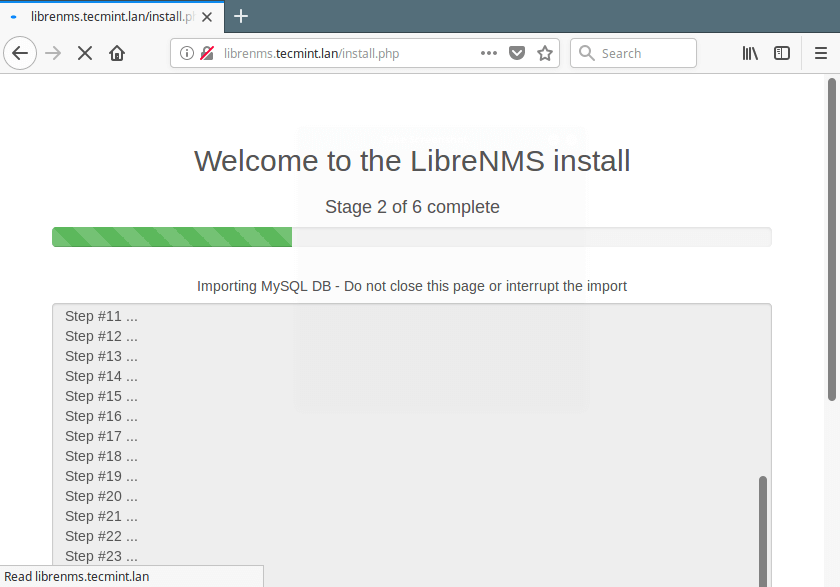
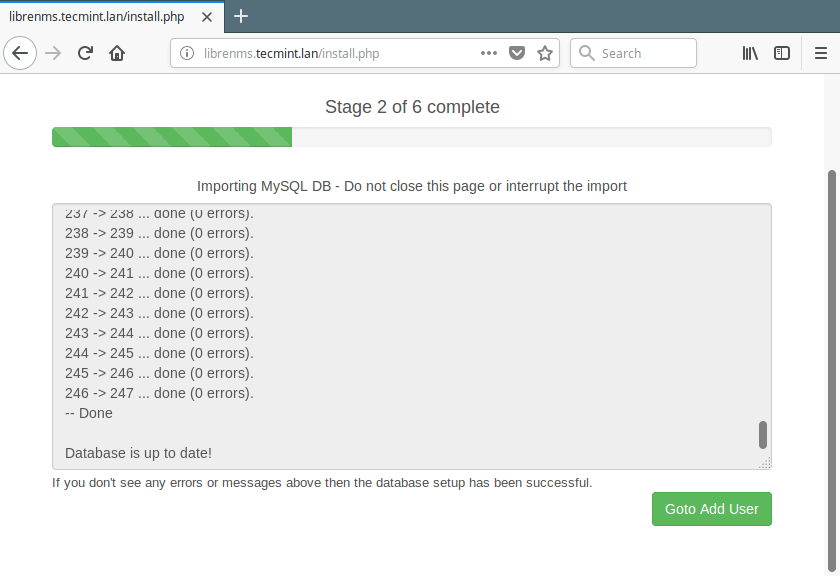
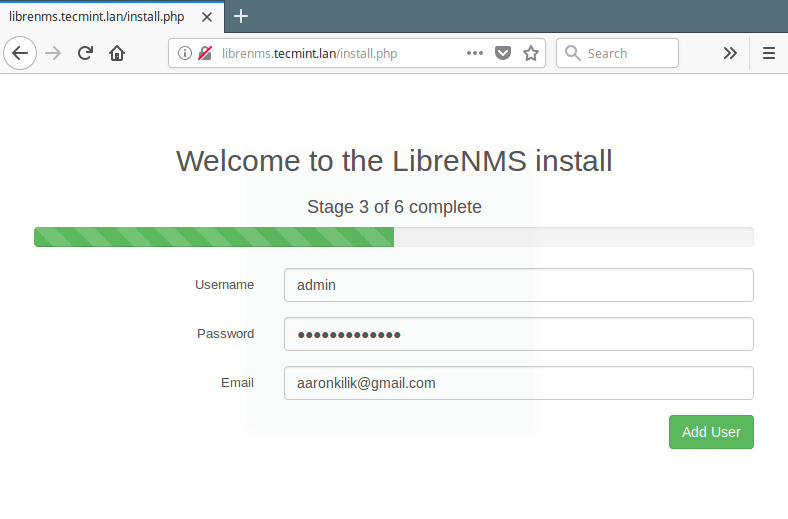
Nagios is an awesome Open Source monitoring tool, its provides you more comprehensive monitoring environment to always keep an eye on your all machines / networks whether you are in a your data center or just your small labs.
With Nagios, you can monitor your remote hosts and their services remotely on a single window. It shows warnings and indicates if something goes wrong in your servers which eventually helps us to detect some problems before they occur. It helps us to reduce downtime and business losses.
Recently, Nagios released its latest versions Nagios Core 4.3.4 and its latest stable release of Nagios plugins 2.2.1 on April 19, 2017.
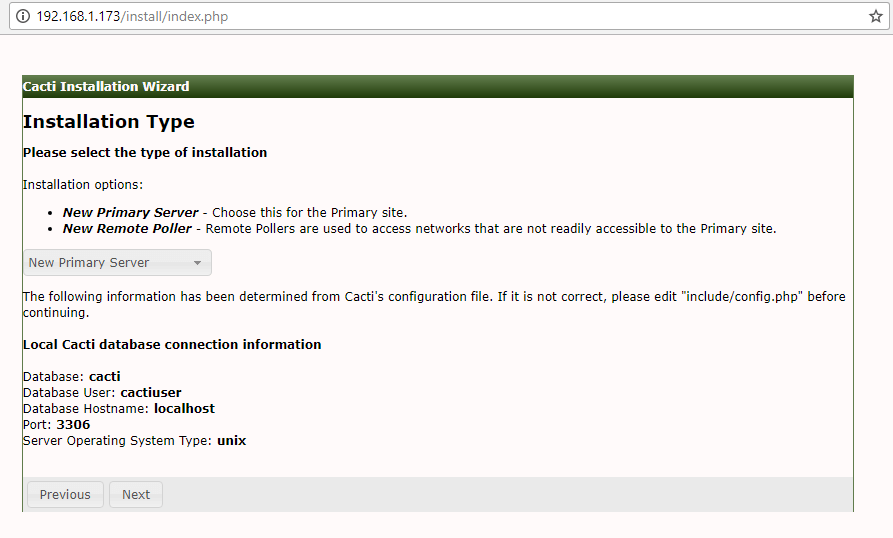
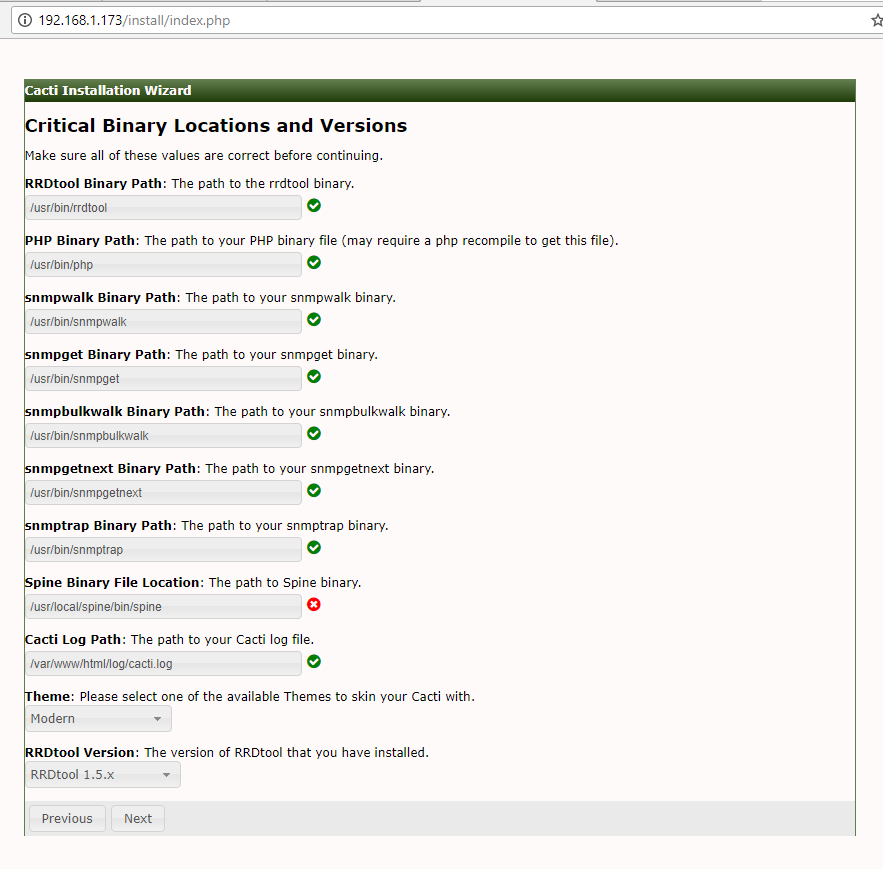
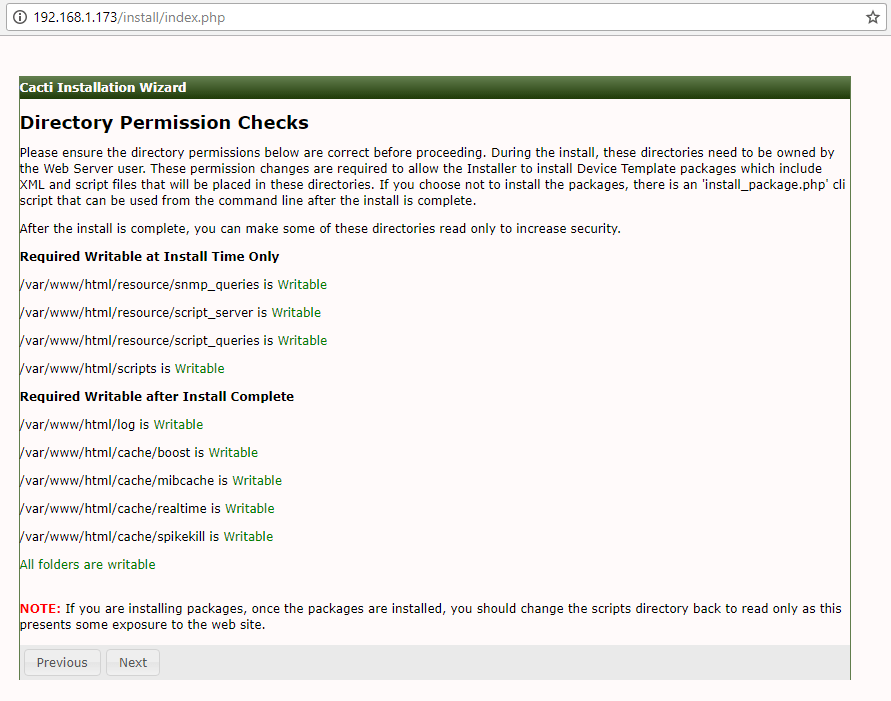
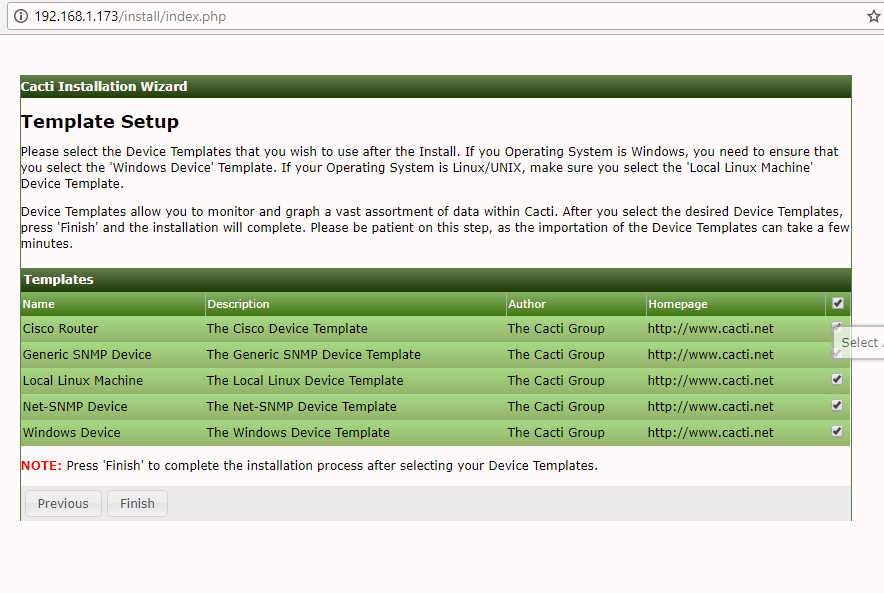
This article is intended to guide you with easy instructions on how to install latest Nagios Core 4.3.4 from source (tarball) on RHEL 7.x/6.x/5.x, CentOS 7.x/6.x/5.x and Fedora 26-20 distributions.
Within 30 minutes you will be monitoring your local machine, no any advanced installation procedure only basic installation that will work 100% on most of the today’s Linux servers.
Please Note: The installation instructions were shown in here are written based on CentOS 7.2 Linux distribution.
Installing Nagios 4.3.4 and Nagios Plugin 2.2.1
If you follow these instructions correctly, you will end up with following information.
- Nagios and its plugins will be installed under /usr/local/nagios directory.
- Nagios will be configured to monitor few services of your local machine (Disk Usage, CPU Load, Current Users, Total Processes, etc.)
- Nagios web interface will be available at http://localhost/nagios
Step 1: Install Required Dependencies
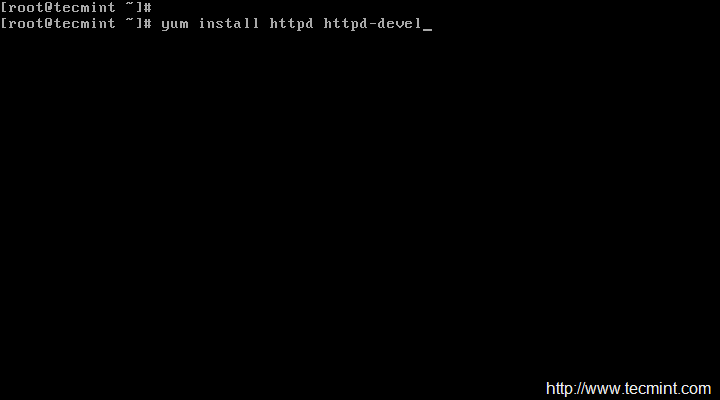
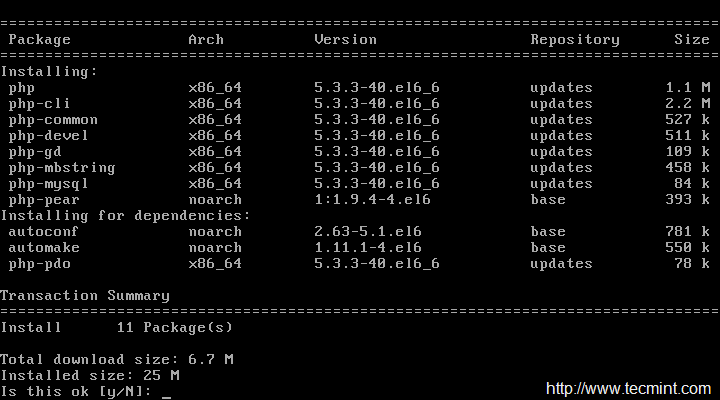
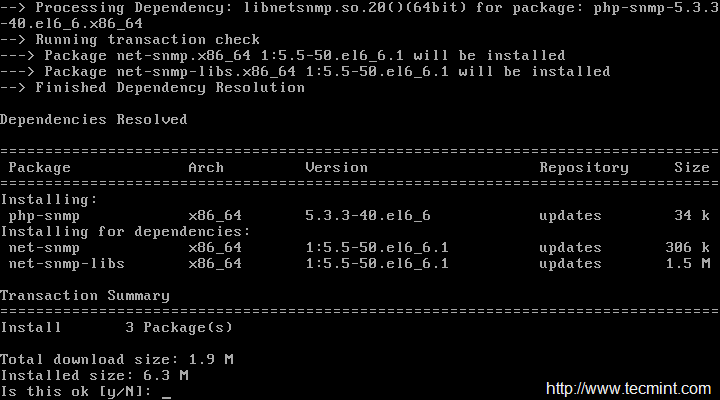
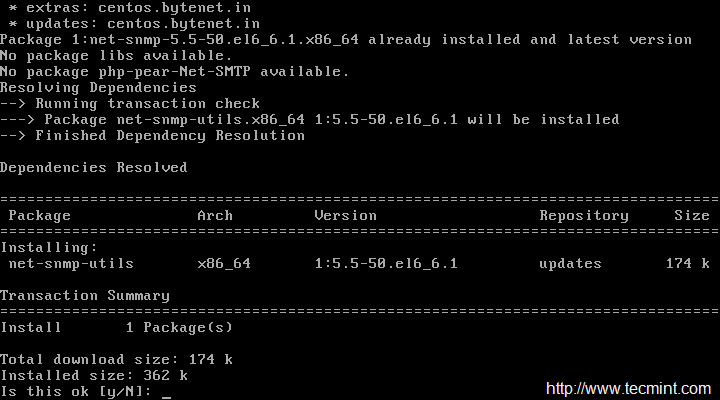
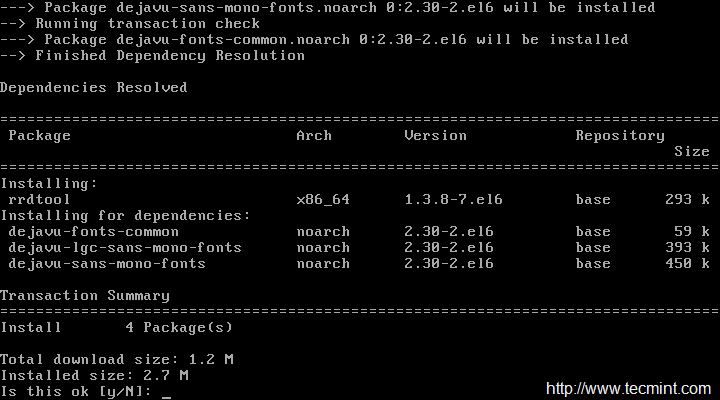
We need to install Apache, PHP and some libraries like gcc, glibc, glibc-common and GD libraries and its development libraries before installing Nagios 4.3.4 with source. And to do so, we can use yum default package installer.
[root@tecmint]# yum install -y httpd httpd-tools php gcc glibc glibc-common gd gd-devel make net-snmp -------------- On Fedora 22+ Onwards -------------- [root@tecmint]# dnf install -y httpd httpd-tools php gcc glibc glibc-common gd gd-devel make net-snmp
Step 2: Create Nagios User and Group
Create a new nagios user and nagcmd group account and set a password.
[root@tecmint]# useradd nagios [root@tecmint]# groupadd nagcmd
Next, add both the nagios user and the apache user to the nagcmd group.
[root@tecmint]# usermod -G nagcmd nagios [root@tecmint]# usermod -G nagcmd apache
Step 3: Download Nagios Core 4.3.4 and Nagios Plugin 2.2.1
Create a directory for your Nagios installation and all its future downloads.
[root@tecmint]# mkdir /root/nagios [root@tecmint]# cd /root/nagios
Now download latest Nagios Core 4.3.4 and Nagios plugins 2.2.1 packages with wget command.
[root@tecmint nagios~]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.3.4.tar.gz [root@tecmint nagios~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
Step 4: Extract Nagios Core and its Plugins
We need to extract downloaded package with tar command as follows.
[root@tecmint nagios~]# tar -xvf nagios-4.3.4.tar.gz [root@tecmint nagios~]# tar -xvf nagios-plugins-2.2.1.tar.gz
When you extract these tarballs with tar command, two new folders will appear in that directory.
[root@tecmint nagios ~]# ls -l total 13520 drwxrwxr-x 18 root root 4096 Aug 24 17:43 nagios-4.3.4 -rw-r--r-- 1 root root 11101966 Aug 24 17:48 nagios-4.3.4.tar.gz drwxr-xr-x 15 root root 4096 Apr 19 12:04 nagios-plugins-2.2.1 -rw-r--r-- 1 root root 2728818 Apr 19 12:04 nagios-plugins-2.2.1.tar.gz
Configure Nagios Core
Now, first we will configure Nagios Core and to do so we need to go to Nagios directory and run configure file and if everything goes fine, it will show the output in the end as sample output. Please see below.
[root@tecmint nagios~]# cd nagios-4.3.4/ [root@tecmint nagios-4.3.4 ]# ./configure --with-command-group=nagcmd
Sample output:
Creating sample config files in sample-config/ ...
*** Configuration summary for nagios 4.3.4 2017-08-24 ***:
General Options:
-------------------------
Nagios executable: nagios
Nagios user/group: nagios,nagios
Command user/group: nagios,nagcmd
Event Broker: yes
Install ${prefix}: /usr/local/nagios
Install ${includedir}: /usr/local/nagios/include/nagios
Lock file: /run/nagios.lock
Check result directory: ${prefix}/var/spool/checkresults
Init directory: /etc/rc.d/init.d
Apache conf.d directory: /etc/httpd/conf.d
Mail program: /usr/bin/mail
Host OS: linux-gnu
IOBroker Method: epoll
Web Interface Options:
------------------------
HTML URL: http://localhost/nagios/
CGI URL: http://localhost/nagios/cgi-bin/
Traceroute (used by WAP): /usr/bin/traceroute
Review the options above for accuracy. If they look okay,
type 'make all' to compile the main program and CGIs.
After configuring, we need to compile and install all the binaries with make all and make install command, it will install all the needed libraries in your machine and we can proceed further.
[root@tecmint nagios-4.3.4 ]# make all [root@tecmint nagios-4.3.4 ]# make install
Sample output:
*** Exfoliation theme installed ***
NOTE: Use 'make install-classicui' to revert to classic Nagios theme
make[1]: Leaving directory `/root/nagios/nagios-4.3.4'
make install-basic
make[1]: Entering directory `/root/nagios/nagios-4.3.4'
/usr/bin/install -c -m 775 -o nagios -g nagios -d /usr/local/nagios/libexec
/usr/bin/install -c -m 775 -o nagios -g nagios -d /usr/local/nagios/var
/usr/bin/install -c -m 775 -o nagios -g nagios -d /usr/local/nagios/var/archives
/usr/bin/install -c -m 775 -o nagios -g nagcmd -d /usr/local/nagios/var/spool/checkresults
chmod g+s /usr/local/nagios/var/spool/checkresults
*** Main program, CGIs and HTML files installed ***
You can continue with installing Nagios as follows (type 'make'
without any arguments for a list of all possible options):
make install-init
- This installs the init script in /etc/rc.d/init.d
make install-commandmode
- This installs and configures permissions on the
directory for holding the external command file
make install-config
- This installs sample config files in /usr/local/nagios/etc
make[1]: Leaving directory `/root/nagios/nagios-4.3.4'
Following command will install the init scripts for Nagios.
[root@tecmint nagios-4.3.4 ]# make install-init
To make nagios work from command line we need to install command-mode.
[root@tecmint nagios-4.3.4 ]# make install-commandmode
Next, install sample nagios files, please run following command.
[root@tecmint nagios-4.3.4 ]# make install-config
Sample output:
/usr/bin/install -c -m 775 -o nagios -g nagios -d /usr/local/nagios/etc /usr/bin/install -c -m 775 -o nagios -g nagios -d /usr/local/nagios/etc/objects /usr/bin/install -c -b -m 664 -o nagios -g nagios sample-config/nagios.cfg /usr/local/nagios/etc/nagios.cfg /usr/bin/install -c -b -m 664 -o nagios -g nagios sample-config/cgi.cfg /usr/local/nagios/etc/cgi.cfg /usr/bin/install -c -b -m 660 -o nagios -g nagios sample-config/resource.cfg /usr/local/nagios/etc/resource.cfg /usr/bin/install -c -b -m 664 -o nagios -g nagios sample-config/template-object/templates.cfg /usr/local/nagios/etc/objects/templates.cfg /usr/bin/install -c -b -m 664 -o nagios -g nagios sample-config/template-object/commands.cfg /usr/local/nagios/etc/objects/commands.cfg /usr/bin/install -c -b -m 664 -o nagios -g nagios sample-config/template-object/contacts.cfg /usr/local/nagios/etc/objects/contacts.cfg /usr/bin/install -c -b -m 664 -o nagios -g nagios sample-config/template-object/timeperiods.cfg /usr/local/nagios/etc/objects/timeperiods.cfg /usr/bin/install -c -b -m 664 -o nagios -g nagios sample-config/template-object/localhost.cfg /usr/local/nagios/etc/objects/localhost.cfg /usr/bin/install -c -b -m 664 -o nagios -g nagios sample-config/template-object/windows.cfg /usr/local/nagios/etc/objects/windows.cfg /usr/bin/install -c -b -m 664 -o nagios -g nagios sample-config/template-object/printer.cfg /usr/local/nagios/etc/objects/printer.cfg /usr/bin/install -c -b -m 664 -o nagios -g nagios sample-config/template-object/switch.cfg /usr/local/nagios/etc/objects/switch.cfg *** Config files installed *** Remember, these are *SAMPLE* config files. You'll need to read the documentation for more information on how to actually define services, hosts, etc. to fit your particular needs.
Step 5: Customizing Nagios Configuration
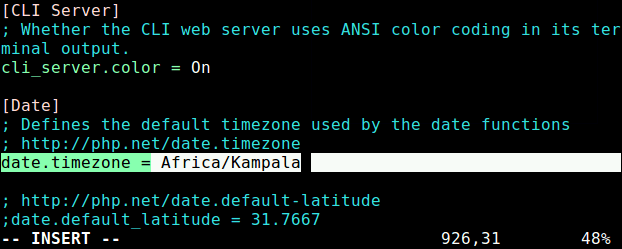
Open the “contacts.cfg” file with your choice of editor and set the email address associated with the nagiosadmin contact definition to receiving email alerts.
# vi /usr/local/nagios/etc/objects/contacts.cfg
Sample Output
###############################################################################
###############################################################################
#
# CONTACTS
#
###############################################################################
###############################################################################
# Just one contact defined by default - the Nagios admin (that's you)
# This contact definition inherits a lot of default values from the 'generic-contact'
# template which is defined elsewhere.
define contact{
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Nagios Admin ; Full name of user
email admin@tecmint.com ; *** CHANGE THIS TO YOUR EMAIL ADDRESS ****
}
Step 6: Install and Configure Web Interface for Nagios
We are done with all configuration in the backend, now we will configure Web Interface For Nagios with following command. The below command will Configure Web interface for Nagios and a web admin user will be created “nagiosadmin”.
[root@tecmint nagios-4.3.4 ]# make install-webconf
In this step, we will be creating a password for “nagiosadmin”. After executing this command, please provide a password twice and keep it remember because this password will be used when you login in the Nagios Web interface.
[root@tecmint nagios-4.3.4]# htpasswd -s -c /usr/local/nagios/etc/htpasswd.users nagiosadmin New password: Re-type new password: Adding password for user nagiosadmin
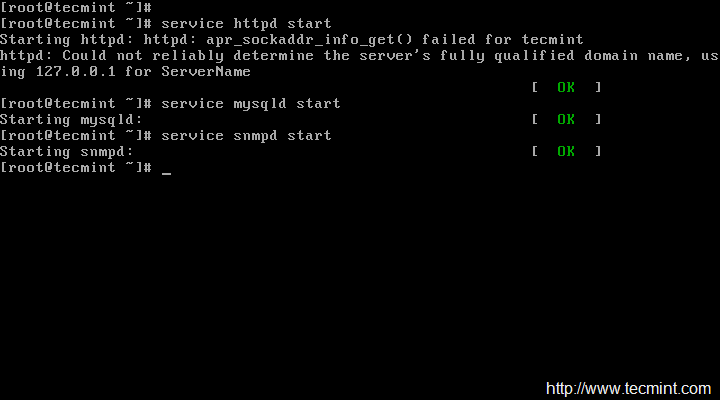
Restart Apache to make the new settings take effect.
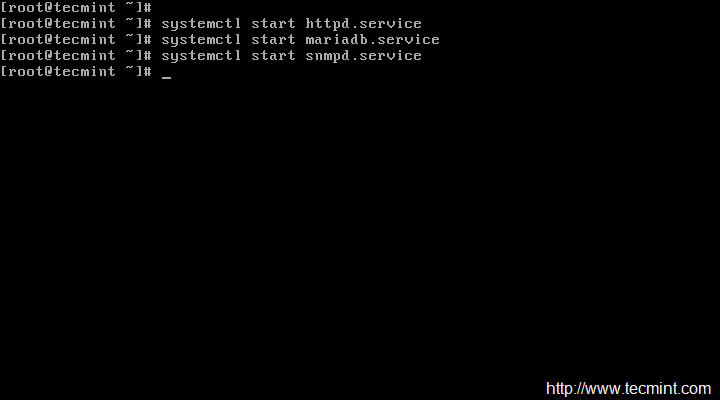
[root@tecmint ]# service httpd start [On RHEL/CentOS 6/5 and Fedora] [root@tecmint ]# systemctl start httpd.service [On RHEL/CentOS 7 and Fedora 19 Onwards]
Step 7: Compile and Install Nagios Plugin
We have downloaded nagios plugins in /root/nagios, Go there and configure and install it as directed below.
[root@tecmint nagios]# cd /root/nagios [root@tecmint nagios]# cd nagios-plugins-2.2.1/ [root@tecmint nagios]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios [root@tecmint nagios]# make [root@tecmint nagios]# make install
Step 8: Verify Nagios Configuration Files
Now we are all done with Nagios configuration and its time to verify it and to do so please insert following command. If everything goes smooth it will show up similar to below output.
[root@tecmint nagios]# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Sample Output
Nagios Core 4.3.4 Copyright (c) 2009-present Nagios Core Development Team and Community Contributors Copyright (c) 1999-2009 Ethan Galstad Last Modified: 2017-08-24 License: GPL Website: https://www.nagios.org Reading configuration data... Read main config file okay... Read object config files okay... Running pre-flight check on configuration data... Checking objects... Checked 8 services. Checked 1 hosts. Checked 1 host groups. Checked 0 service groups. Checked 1 contacts. Checked 1 contact groups. Checked 24 commands. Checked 5 time periods. Checked 0 host escalations. Checked 0 service escalations. Checking for circular paths... Checked 1 hosts Checked 0 service dependencies Checked 0 host dependencies Checked 5 timeperiods Checking global event handlers... Checking obsessive compulsive processor commands... Checking misc settings... Total Warnings: 0 Total Errors: 0 Things look okay - No serious problems were detected during the pre-flight check
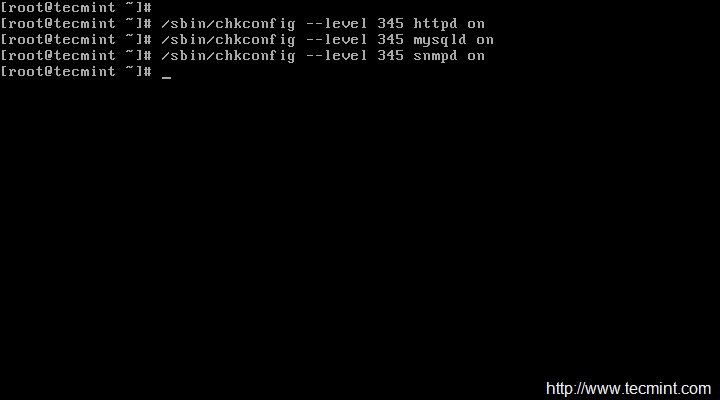
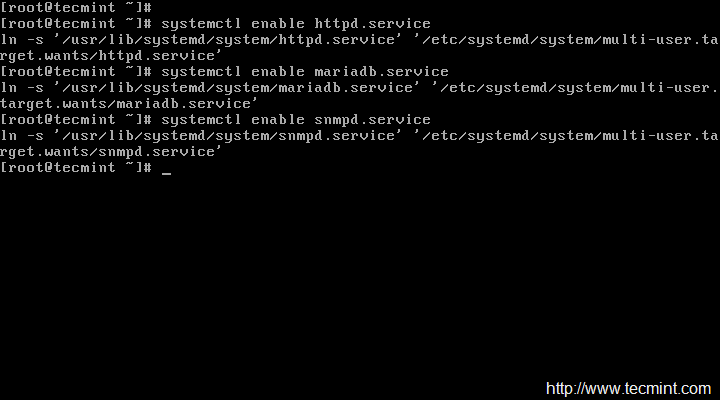
Step 9: Add Nagios Services to System Startup
To make Nagios work across reboots, we need to add nagios and httpd with chkconfig and systemctlcommand.
On RHEL/CentOS 6/5 and Fedora
[root@tecmint ]# chkconfig --add nagios [root@tecmint ]# chkconfig --level 35 nagios on [root@tecmint ]# chkconfig --add httpd [root@tecmint ]# chkconfig --level 35 httpd on
On RHEL/CentOS 7 and Fedora 19-26
[root@tecmint ]# systemctl enable nagios [root@tecmint ]# systemctl enable httpd
Restart Nagios to make the new settings take effect.
[root@tecmint ]# service nagios start [On RHEL/CentOS 6/5 and Fedora] [root@tecmint ]# systemctl start nagios.service [On RHEL/CentOS 7 and Fedora 19-24]
Step 10: Login to the Nagios Web Interface
Your nagios is ready to work, please open it in your browser with “http://Your-server-IP-address/nagios” or “http://FQDN/nagios” and Provide the username “nagiosadmin” and password.
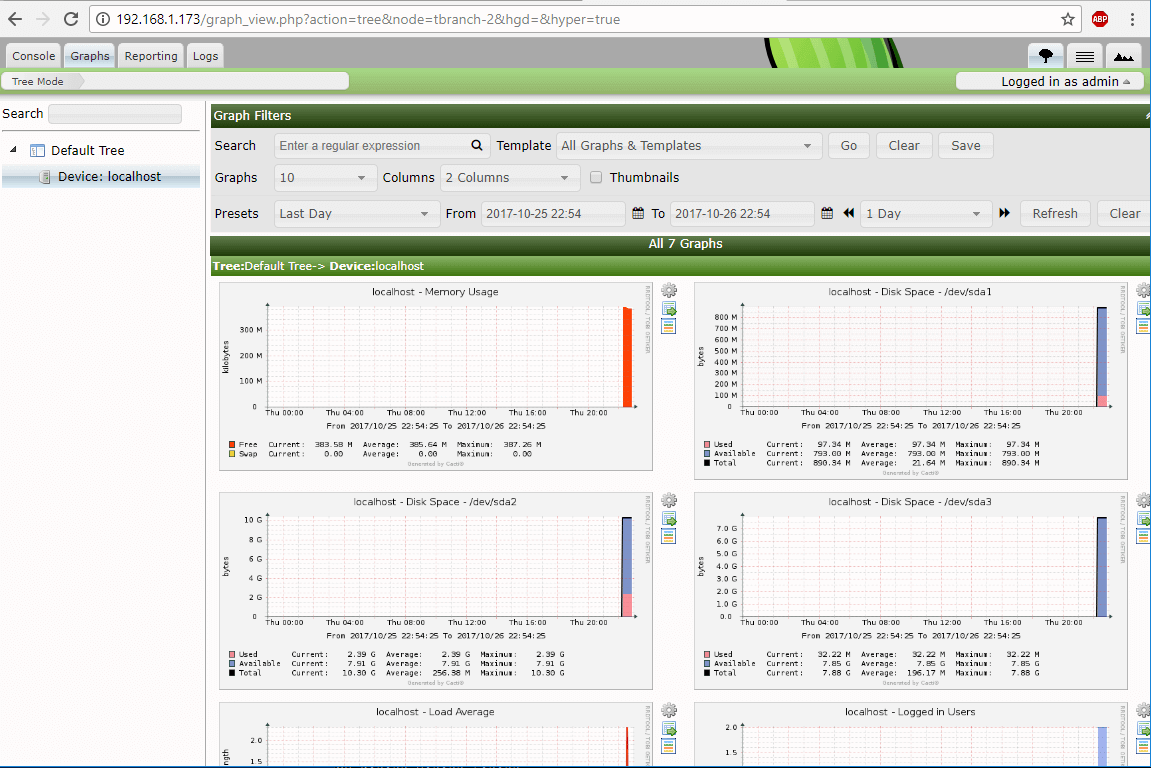
Nagios Web Dashboard
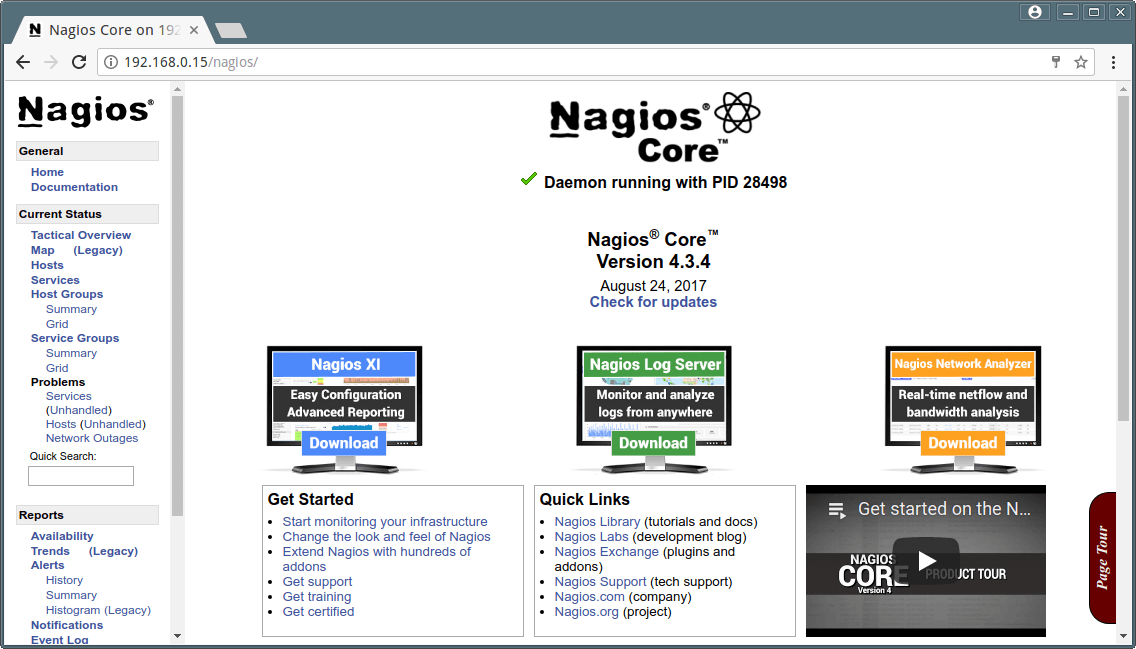
Nagios Core Running on CentOS 7.2
Host View
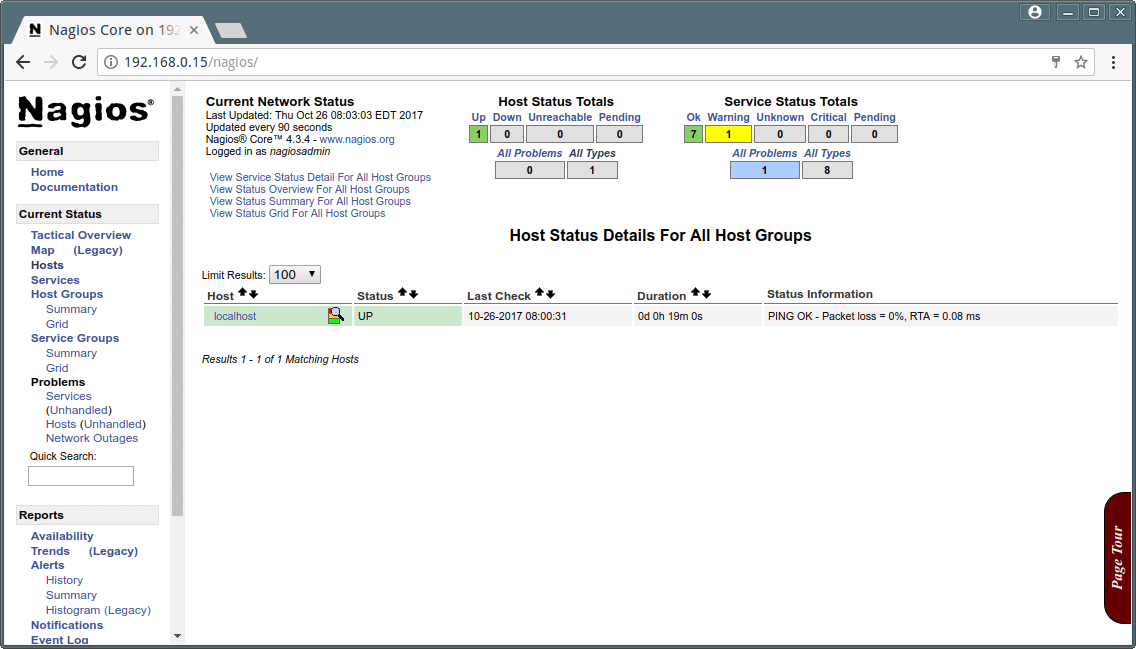
Nagios Host View
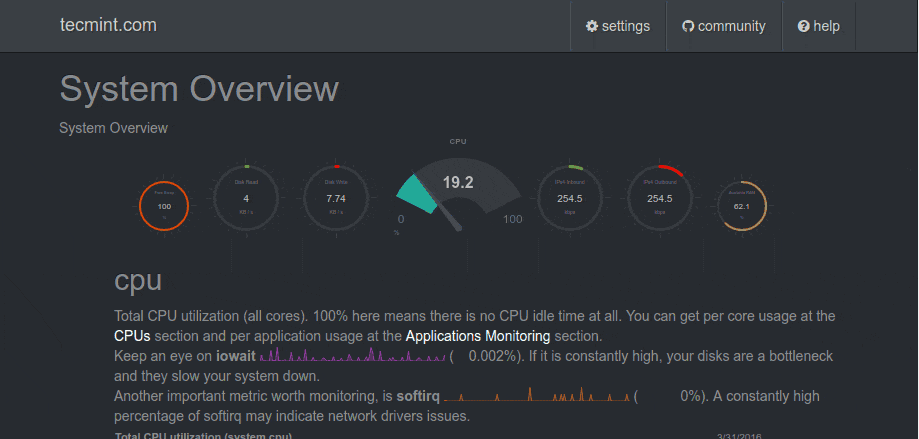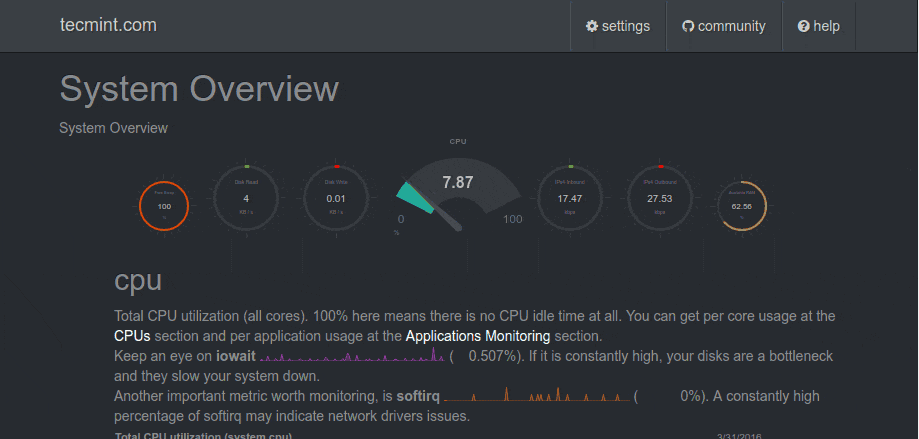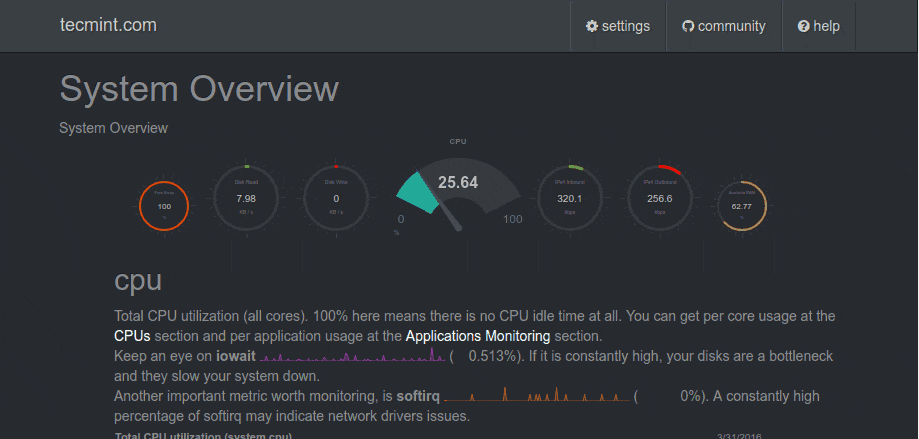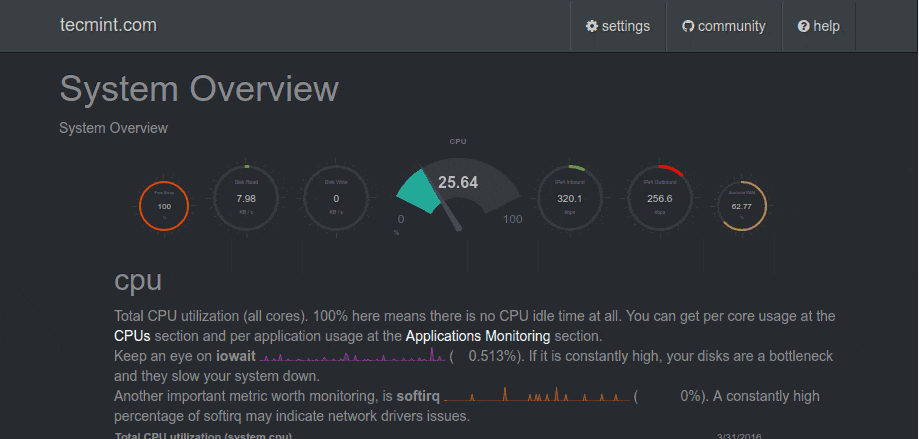
Nagios Overview
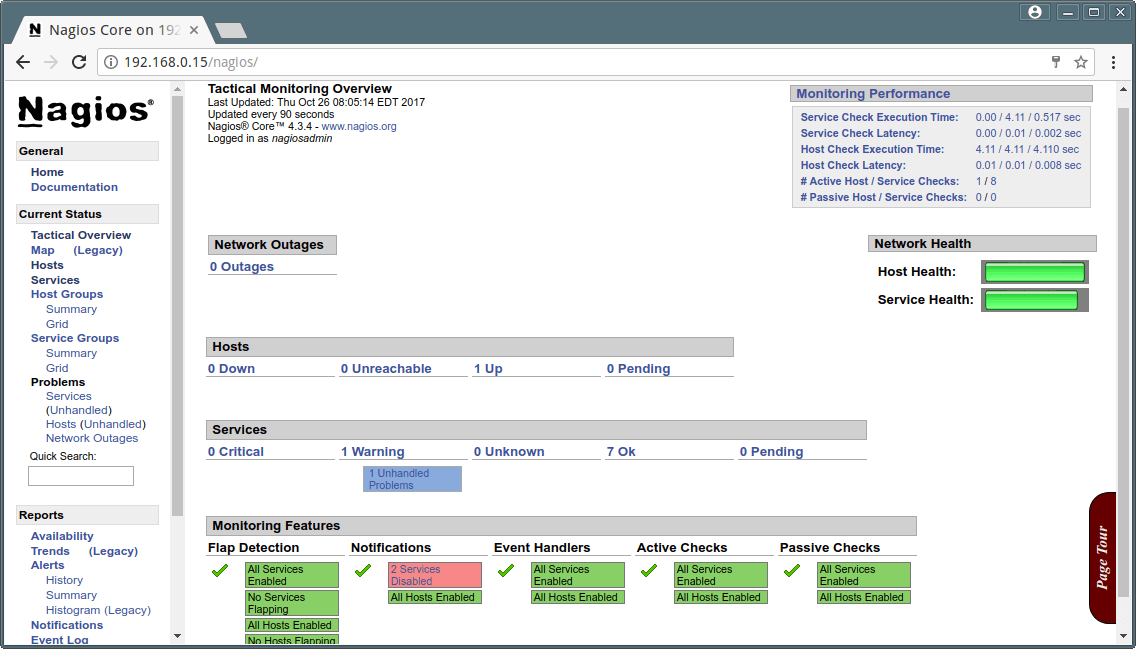
Nagios Monitoring Overview
Service View
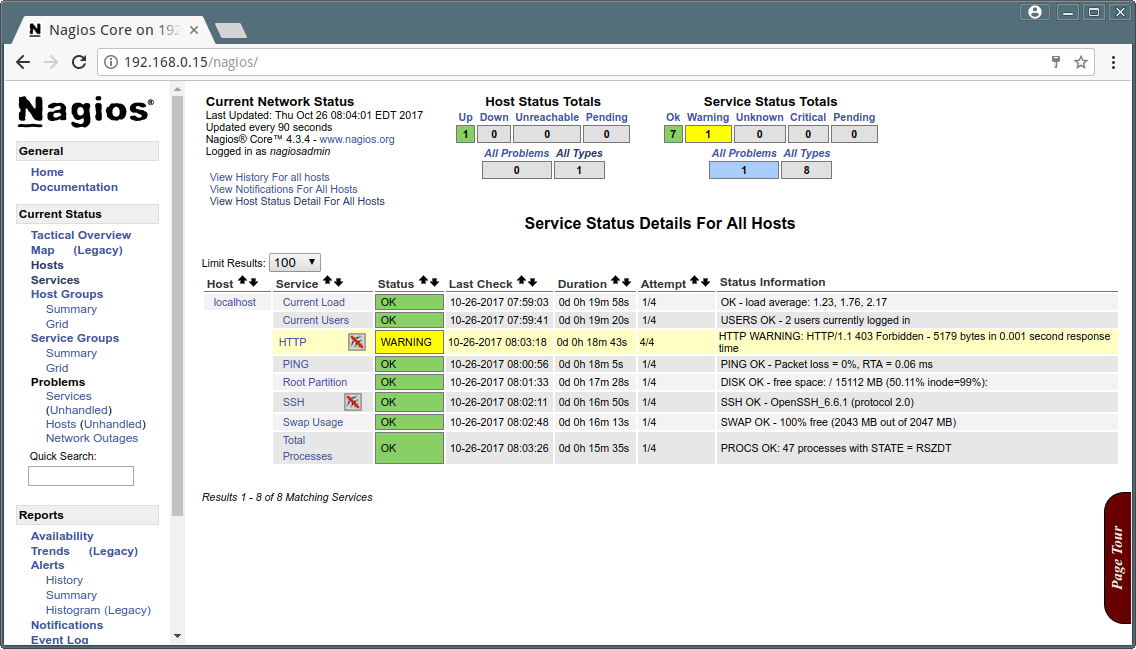
Nagios Hos Services Monitoring
Process View
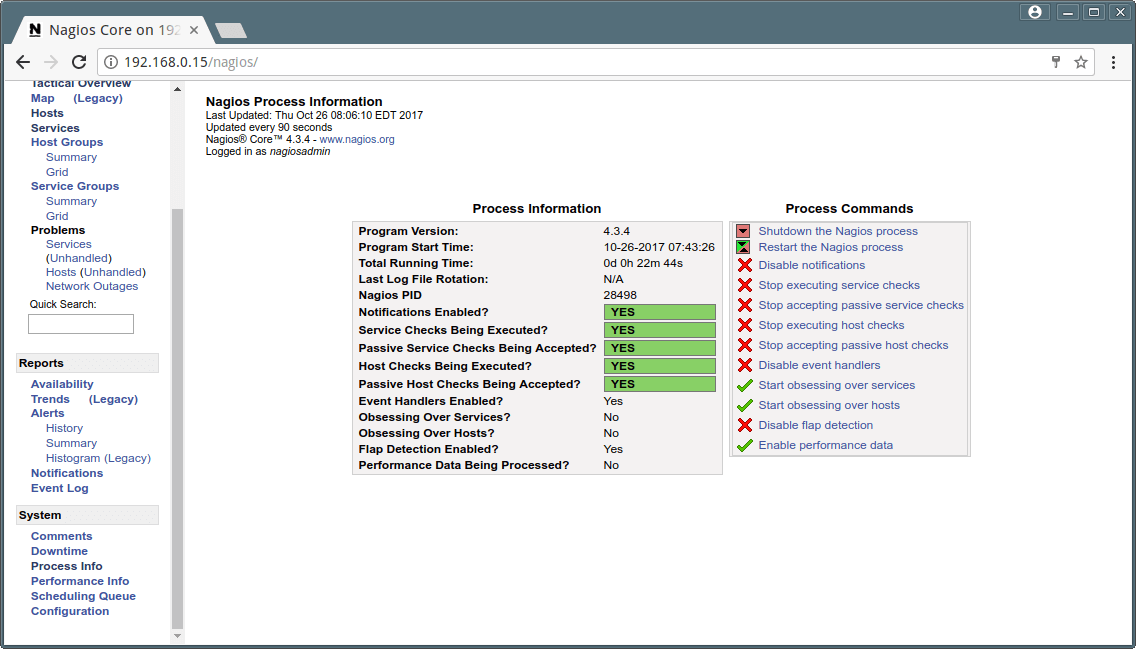
Nagios Core Process Information
Congratulations! You’ve successfully installed and configured Nagios and its Plugins. You’ve just begin your journey into monitoring.
Upgrade Nagios 3.x to Nagios 4.3.4
If you are already running an older version of Nagios, you can upgrade it anytime. To do so, you just need to download the latest tar archive of it and configure it as shown below.
[root@tecmint ]# service nagios stop [root@tecmint ]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.3.4.tar.gz [root@tecmint ]# tar -zxvf nagios-4.3.4.tar.gz [root@tecmint ]# cd nagios-4.3.4 [root@tecmint ]# ./configure [root@tecmint ]# make all [root@tecmint ]# make install [root@tecmint ]# service nagios start
That’s it for now, in my upcoming articles, I will show you how to add Linux, Windows, Printers, Switches and Devices to Nagios monitoring Server. If you’re having any trouble while installing, please do contact us via comments. Till then stay tuned and connected to Tecmint and don’t forget to Like and Share us to spread around.
Read Also: