The API landscape is constantly evolving, with some protocols rising in popularity while others fade. Postman’s latest State of the API report, which is based on a survey of over 40,000 developers, offers a snapshot of these shifts—and reveals which API protocols are capturing the most attention and adoption right now. In this article, we’ll explore these API protocols in detail, analyze why they are attracting so much interest, and dive into the key strengths and limitations of each one.
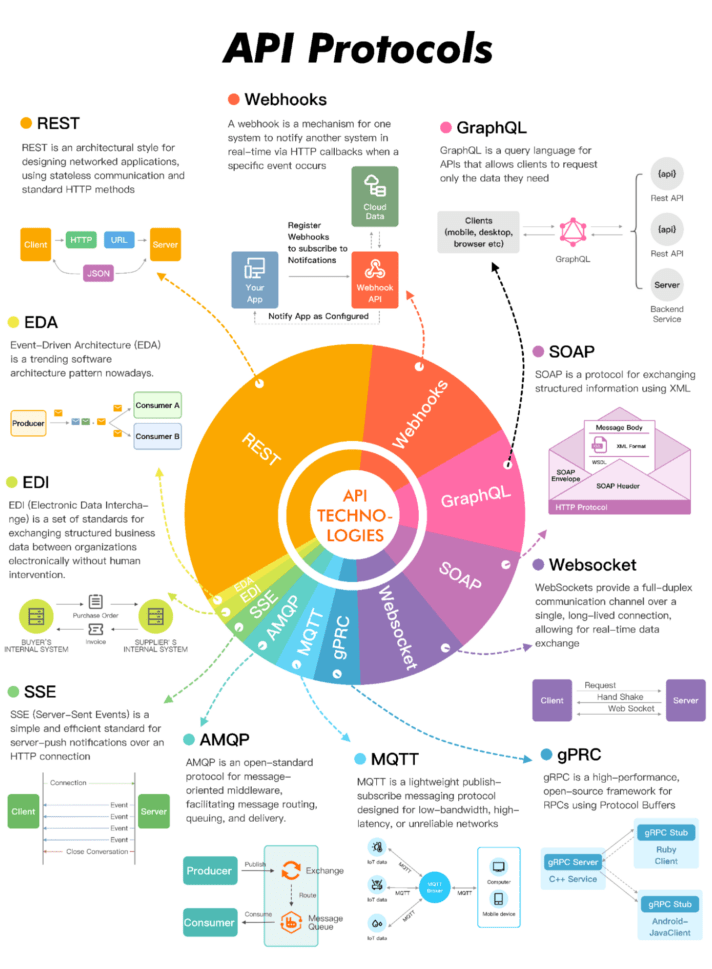
An overview of the API protocols in use today.
REST
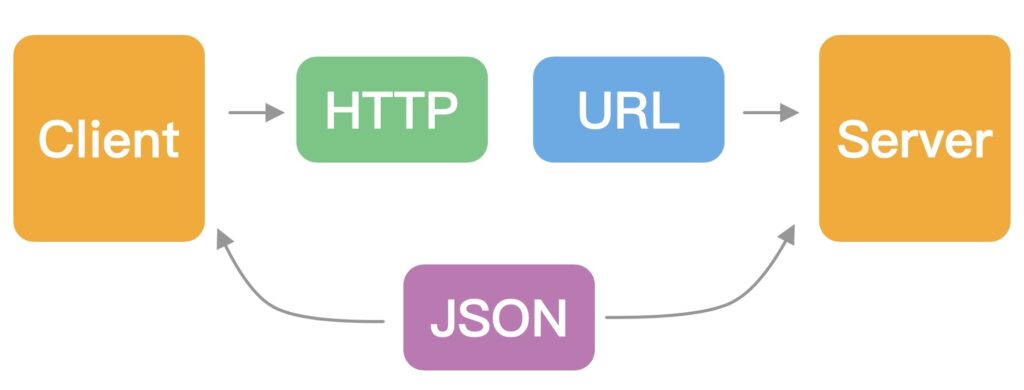
Representational State Transfer (REST) remains the most popular architectural style for web APIs. Although its usage among survey respondents has declined slightly—from 92% to 86% over the past two years—its simplicity, scalability, and ease of integration with web services cement its position at the top.
Benefits of REST
- Simplicity and standardization: By leveraging standard HTTP methods, REST enables straightforward adoption for developers who are already versed in HTTP. This simplicity promotes rapid learning and integration.
- Scalability: REST’s stateless nature ensures that servers do not need to store session data between requests. This facilitates horizontal scaling by adding instances without a shared server state.
- Performance: Statelessness and cacheable responses yield faster execution and fewer requests.
- Modularity: RESTful services can be developed as modular components. This localized functionality enables independent updates and improves maintainability.
- Platform-agnostic: Platform-agnostic HTTP support allows for consumption by diverse clients. The resulting interoperability promotes API integration across systems.
- Mature tooling and community support: REST’s longevity has led to the extensive proliferation of tools, libraries, best practices, troubleshooting guidance, and community resources.
Challenges of REST
- Over-fetching and under-fetching: REST runs the risk of over-fetching or under-fetching data, as clients may only need a subset of resources. This drawback can cause performance issues and waste bandwidth.
- Chatty interfaces: Retrieving related data may require multiple requests, which increases latency. This waterfall of calls becomes especially problematic as applications scale.
- Versioning challenges: Creating new versions of a REST API can be cumbersome, especially when there are changes to the data structure or service functionality. This often leads to backward compatibility issues.
- Stateless overhead: While statelessness supports scalability, it also means that all the necessary context must be provided with every request. This requirement can introduce overhead, especially when clients must send large amounts of repetitive data.
- Lack of real-time functionality: REST is not optimized for real-time apps like chat or live feeds. WebSockets and Server-Sent Events often better suit such use cases.
Webhooks
Webhooks are user-defined HTTP callbacks that are triggered by events in a source application. When an event occurs, the source application sends an HTTP request (usually POST) to a URI specified by the target application, which enables near real-time event-based communication without repeated polling. Webhooks are becoming increasingly popular, with 36% of developers using them to create seamless integrations between diverse systems.
For example, if you wanted to get notified every time there’s a new comment on your blog post, instead of repeatedly asking (polling) the server, “Is there a new comment?”, the server would notify you (via webhook) when a new comment has been posted.
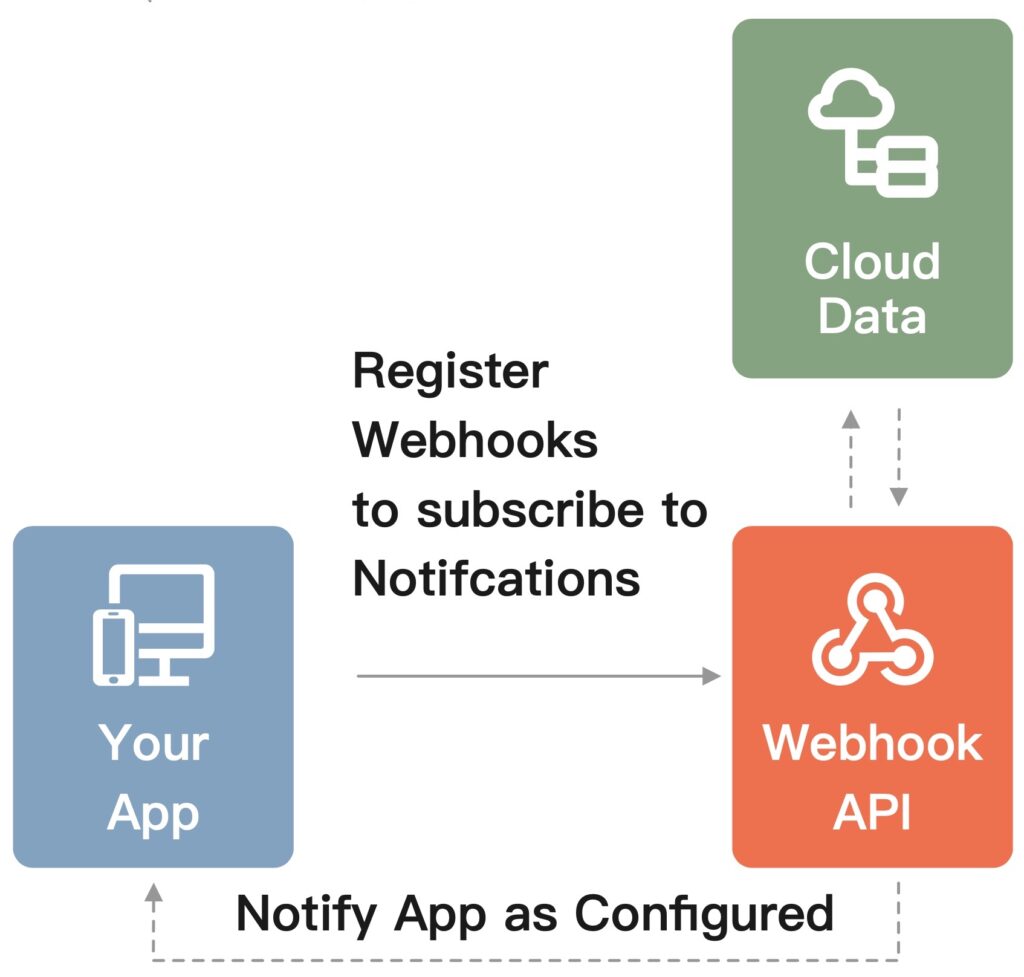
Benefits of webhooks
- Real-time communication: Webhooks enable real-time data transmission. The corresponding data is sent when an event is triggered, ensuring up-to-date synchronization between systems.
- Efficiency: Webhooks eliminate resource-intensive polling, saving computing power and bandwidth.
- Flexibility: Webhooks can be configured to respond to specific events, allowing you to customize which actions or triggers in one application will send data to another.
- Simplified integration: HTTP methods enable easy consumption by most applications.
- Support for decoupled architectures: Since webhooks operate based on events, they naturally support event-driven or decoupled architectures, enhancing modularity and scalability.
Challenges of webhooks
- Error handling: If the receiving end of a webhook is down or there’s an error in processing the callback, there’s a risk of data loss. Systems that use webhooks must have robust error-handling mechanisms, including retries or logs.
- Security concerns: Webhooks transmit data over the internet, making them vulnerable to interceptions or malicious attacks. API security measures, such as the use of HTTPS and payload signatures, are essential.
- Managing multiple webhooks: Managing and monitoring webhooks can be complex—especially as applications grow and begin to rely on multiple webhooks. Ensuring all webhooks function correctly and track various endpoints requires diligence.
- Potential for overload: High volumes of concurrent callbacks can overwhelm receiving applications, but rate limiting or batching may help manage surges.
GraphQL
GraphQL is a query language for APIs and a server-side runtime for executing queries using a type system you define for your data. Developed by Facebook in 2012 and released as an open source project in 2015, GraphQL provides a more flexible and efficient alternative to the traditional REST API. GraphQL has a growing adoption rate of 29% among developers, indicating its importance in today’s API landscape.
Unlike REST, where you must hit multiple API endpoints to fetch related data, GraphQL lets you get all the data you need in a single query. This is particularly useful for frontend developers, as it gives them more control over the data retrieval process and allows them to create more dynamic and responsive user interfaces.
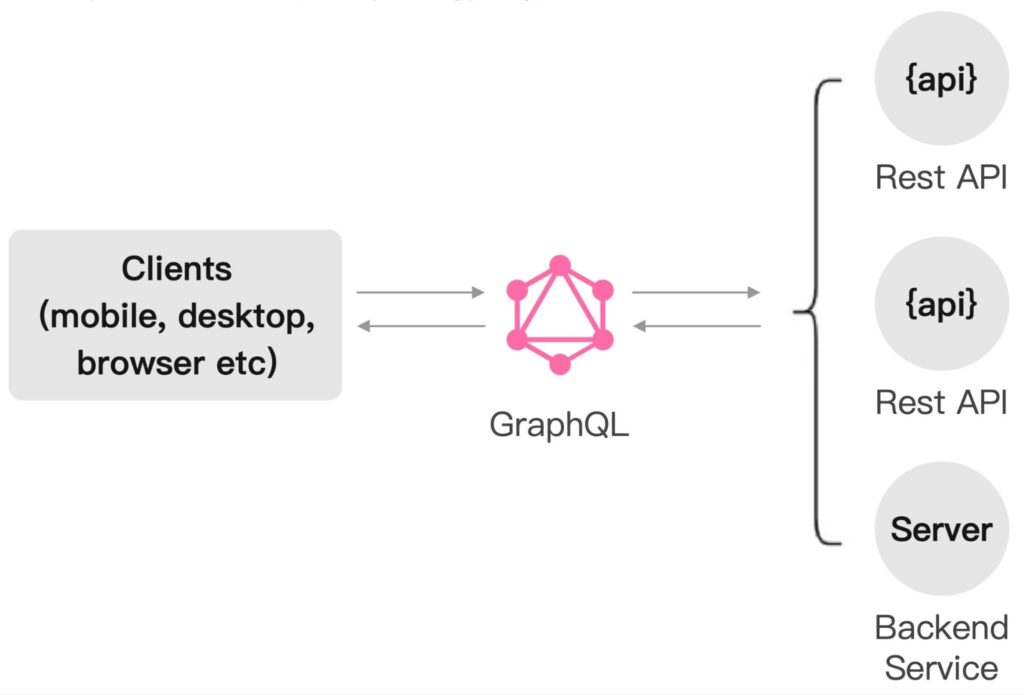
Benefits of GraphQL
- Strongly typed schema: GraphQL APIs have strongly typed schemas, which allow developers to know exactly what data and types are available to query.
- Precise data retrieval: Clients can request the precise data they need, which solves the problems of over-fetching and under-fetching and, by extension, improves performance and lowers costs.
- Query complexity and multiple resources: GraphQL supports querying multiple data types in one request, which reduces the number of network requests for complex, inter-related data.
- Real-time updates with subscriptions: GraphQL enables real-time syncing through subscriptions, which keep the client updated in real time.
- Introspection: GraphQL’s self-documenting schema enables easier development through introspection.
Challenges of GraphQL
- Query complexity: The flexibility that GraphQL gives to the client comes with drawbacks, as overly complex or nested queries can negatively impact performance.
- Learning curve: GraphQL has a steeper learning curve than REST due to new concepts like mutations and subscriptions.
- Versioning: The flexible nature of queries means that changes in the schema can break existing queries, complicating version management.
- Potential overuse of resources: Since clients can request multiple resources in one query, there’s a risk of overloading servers by fetching more data than necessary.
- Security concerns: Malicious users could exploit GraphQL’s flexibility to overload servers with complex queries.
SOAP
Simple Object Access Protocol (SOAP) is a protocol for exchanging structured information to implement web services. It uses XML for its message format and usually employs HTTP or SMTP as the message negotiation and transmission layer. Unlike REST and GraphQL, SOAP has strict standards and built-in features like ACID-compliant transactions, security, and messaging patterns.
Despite its reduced usage—down to just 26% of developers—SOAP is a reliable choice for certain applications. Let’s explore what makes SOAP unique and where it shines compared to other API design approaches.
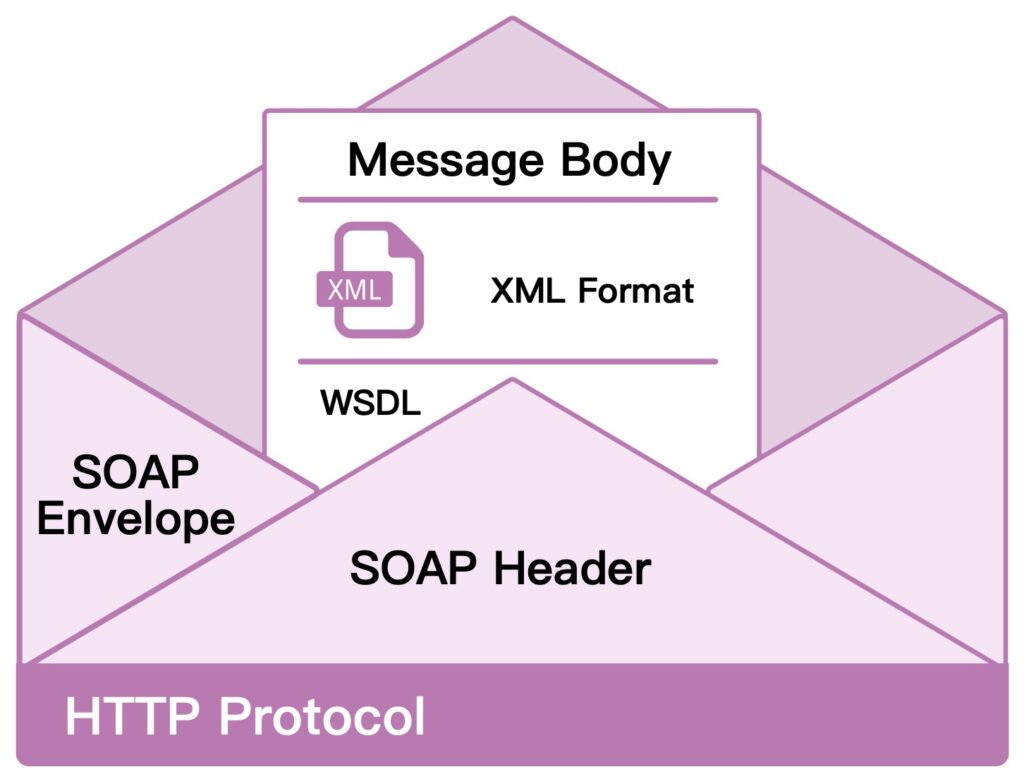
Benefits of SOAP
- Strong typing and contracts: SOAP APIs have strong typing and a strict contract that is defined in a Web Services Description Language (WDSL) document.
- Built-in security features: SOAP provides comprehensive security with authentication, authorization, and encryption baked in via the WS-Security standard. This makes SOAP a preferred choice for enterprise applications.
- ACID transactions: SOAP supports ACID transactions, which are essential for applications where data integrity is crucial, such as financial or healthcare systems.
- Reliable messaging: SOAP ensures reliable message delivery and handles failures well, which makes it a great fit for systems in which guaranteed message delivery is critical.
- Language, platform, and transport neutrality: Similar to REST, SOAP services can be consumed by any client that understands XML, regardless of its underlying programming language, platform, or transport protocol.
Challenges of SOAP
- Complexity and learning curve: SOAP can be more complex to implement due to its strict standards and use of XML, making the learning curve steeper than that of alternatives like REST or GraphQL.
- Verbose messages: SOAP message headers carry a lot of overhead, which results in larger payloads than in REST and GraphQL’s JSON. This can affect performance and bandwidth usage.
- Limited community support: SOAP is losing ground, which means that community support and available libraries are declining.
- Less flexibility: Any change in the contract may require both the client and server to update their respective implementations, which can be a downside.
- Firewall issues: SOAP may use different transport protocols than HTTP/HTTPS, which means it can face firewall restrictions. This makes SOAP less versatile for some deployment environments.
WebSocket
WebSocket provides a persistent, low-latency, bidirectional connection between client and server, enabling real-time data transfer. Unlike HTTP’s request-response cycle, WebSocket allows the server to send data to clients any time after the initial handshake. This facilitates instant data updates for chat applications, online games, trading platforms, and more.
Survey results indicate that 25% of developers use WebSocket. Let’s explore its advantages, challenges, and use cases.

Benefits of WebSocket
- Real-time bidirectional communication: Real-time bidirectional communication has less latency than HTTP connections that must be re-established for each exchange.
- Lower overhead: The connection remains open after the initial handshake, which lowers the overhead of headers that come with traditional HTTP requests.
- Efficient use of resources: Persistent connections use server resources more efficiently than long polling.
Challenges of WebSocket
- Implementation complexityImplementing WebSocket can be more complex and time-consuming than other API architectures—especially when you take into account the need for fallbacks in environments where WebSocket is not supported.
- Lack of built-in featuresUnlike SOAP, which comes with built-in features for security and transactions, WebSocket is more bare-bones. It requires developers to implement these features themselves.
- Resource consumptionAlthough open WebSocket connections are generally more efficient than long-polling techniques, they still consume server resources and can become a concern at scale.
- Network limitationsSome proxies and firewalls do not support WebSocket, leading to potential connectivity issues in certain network environments.
gRPC
gRPC, which stands for “Google Remote Procedure Call,” is a modern, high-performance protocol that facilitates communication between services. It is built on top of HTTP/2 and leverages Protocol Buffers to define service methods and message formats. In contrast to REST APIs, which rely on standard HTTP verbs like GET and POST, gRPC enables services to expose custom methods that are similar to functions in a programming language.
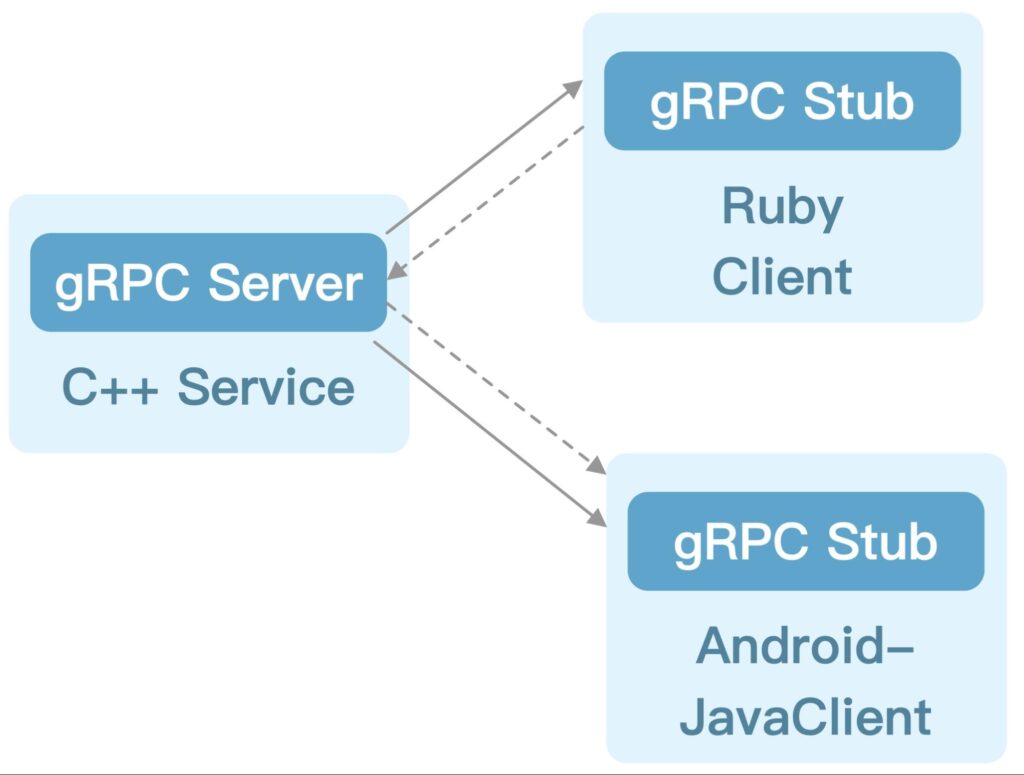
Benefits of gRPC
- Performance: HTTP/2 and Protocol Buffers enable gRPC to achieve low latency and high throughput.
- Strong typing: Like SOAP and GraphQL, gRPC is strongly typed. This results in fewer bugs as types are validated at compile time.
- Multi-language support: gRPC has first-class support for many programming languages, including Go, Java, C#, and Node.js.
- Streaming: gRPC handles streaming requests and responses out-of-the-box, which unlocks complex use cases like long-lived connections and real-time updates.
- Battery included: gRPC directly supports critical functionality like load balancing, retries, and timeouts.
Challenges of gRPC
- Browser support: Native gRPC support in browsers is still limited, making it less suitable for direct client-to-server communication in web applications.
- Learning curve: Developers need to learn how to work with Protocol Buffers, custom service definitions, and other gRPC features, which can slow initial productivity.
- Debugging complexity: Protocol Buffers are not human-readable, making it harder to debug and test gRPC APIs than JSON APIs.
Other API protocols
While the previously discussed protocols are the most widely adopted in the API landscape today, Postman’s State of the API report also highlights a few other approaches that serve specific use cases:
- MQTT is a lightweight messaging protocol optimized for low-bandwidth networks like IoT. It allows clients to publish and subscribe to messages through a broker, but it lacks some security and scalability features.
- AMQP is a more robust enterprise messaging standard that ensures reliable delivery and flexible routing of messages. However, it can be complex and has more overhead than lightweight protocols.
- SSE enables uni-directional server-to-client communication over HTTP. It is great for real-time updates, but it lacks bidirectional capabilities.
- EDI automates B2B communications by standardizing electronic documents like purchase orders and invoices, but it also requires complex infrastructure with high initial costs.
- EDA promotes an event-driven architecture where components react to events, enabling real-time systems that are scalable yet complex to debug.
These protocols are not as ubiquitous, but they enable specialized applications in IoT, enterprise messaging, B2B transactions, and event-driven systems. By selecting the right approach for their specific needs, developers can build optimized API solutions that go beyond the common standards.
Conclusion
The API landscape continues to evolve as developers adopt new architectures, protocols, and tools. While REST remains dominant due to its simplicity and ubiquity, alternatives like GraphQL and gRPC are gaining traction by solving pain points like over-fetching and chatty interfaces. Developers are also increasingly valuing real-time communication, with webhooks and WebSockets rising to meet this demand.
For many common API use cases, REST remains a solid foundational approach given its scalability, interoperability, and ease of adoption. It also still benefits from community maturity. Still, every protocol presents trade-offs, and as applications grow more complex, developers are wisely expanding their API protocol toolkit to include specialized solutions like GraphQL and gRPC.
Rather than a one-size-fits-all panacea, the modern API developer is best served by understanding the strengths and weaknesses of multiple protocols. By architecting systems that combine REST, webhooks, WebSockets, GraphQL, and other approaches where each uniquely shines, developers can build robust, efficient, and maintainable APIs. While the popularity of individual protocols will continue to fluctuate, the overarching trend is towards increased diversity in the API landscape. Developers should embrace this multi-protocol philosophy to craft optimal API solutions.