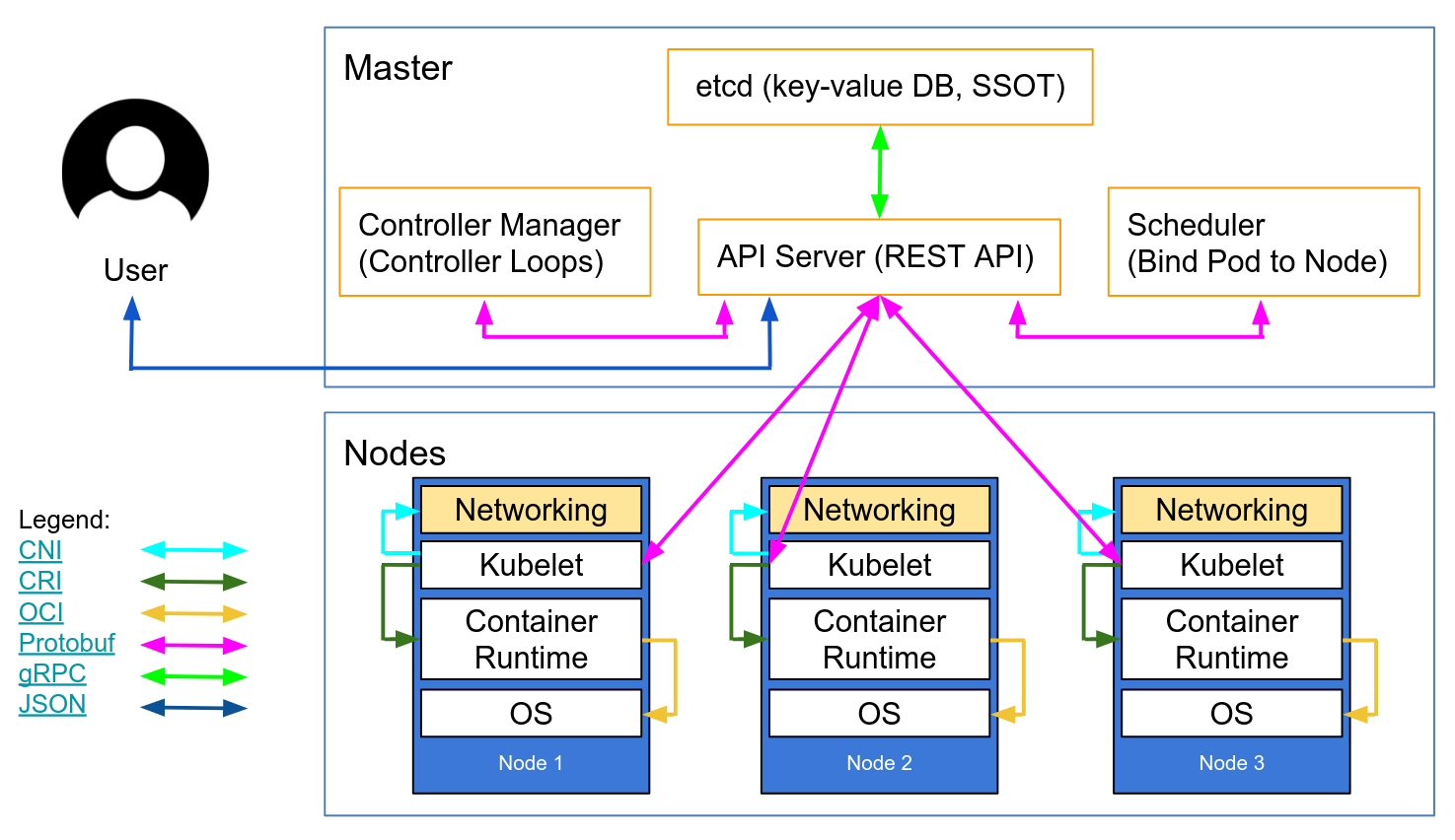
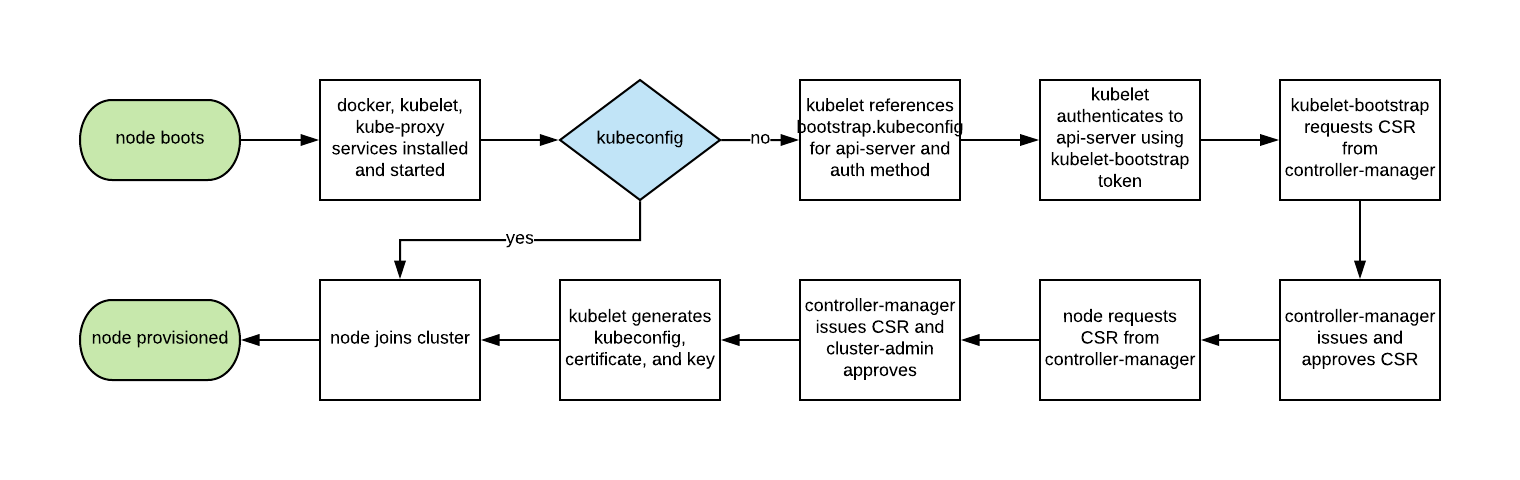
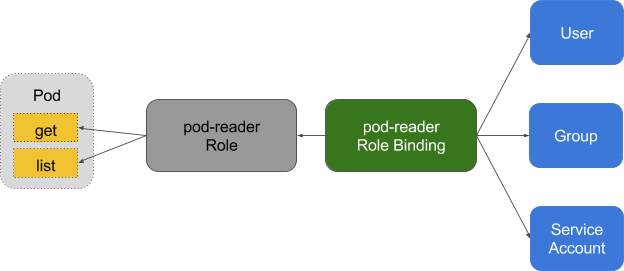
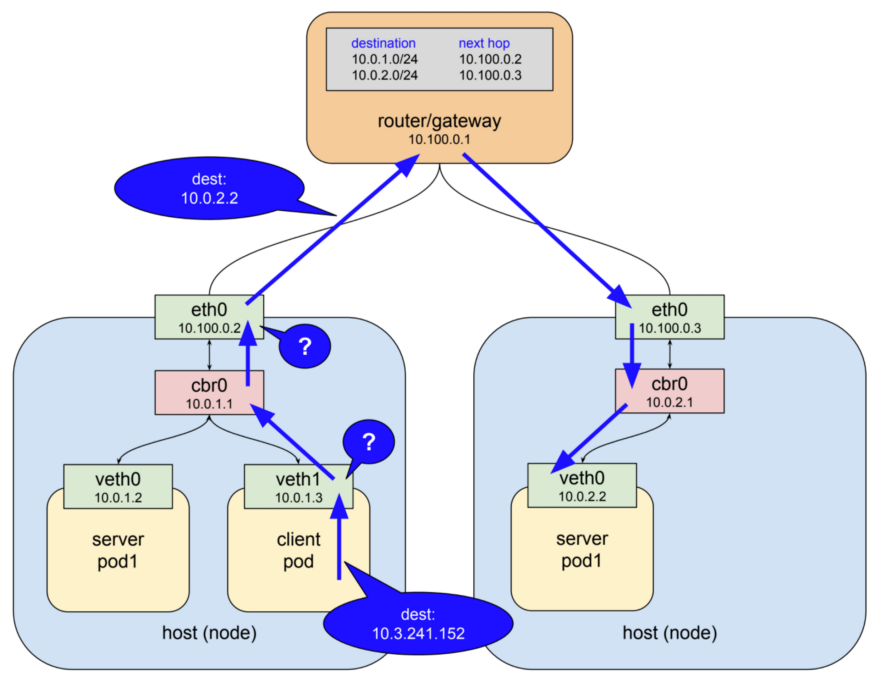
Author: Craig Box (Google)
At KubeCon EU, my colleague Adam Glick and I were pleased to announce the Kubernetes Podcast from Google. In this weekly conversation, we focus on all the great things that are happening in the world of Kubernetes and Cloud Native. From the news of the week, to interviews with people in the community, we help you stay up to date on everything Kubernetes.
We recently had the pleasure of speaking to the release manager for Kubernetes 1.11, Josh Berkus from Red Hat, and the release manager for the upcoming 1.12, Tim Pepper from VMware.
In this conversation we learned about the release process, the impact of quarterly releases on end users, and how Kubernetes is like baking.
I encourage you to listen to the podcast version if you have a commute, or a dog to walk. If you like what you hear, we encourage you to subscribe! In case you’re short on time, or just want to browse quickly, we are delighted to share the transcript with you.
CRAIG BOX: First of all, congratulations both, and thank you.
JOSH BERKUS: Well, thank you. Congratulations for me, because my job is done.
[LAUGHTER]
Congratulations and sympathy for Tim.
[LAUGH]
TIM PEPPER: Thank you, and I guess thank you?
[LAUGH]
ADAM GLICK: For those that don’t know a lot about the process, why don’t you help people understand — what is it like to be the release manager? What’s the process that a release goes through to get to the point when everyone just sees, OK, it’s released — 1.11 is available? What does it take to get up to that?
JOSH BERKUS: We have a quarterly release cycle. So every three months, we’re releasing. And ideally and fortunately, this is actually now how we are doing things. Somewhere around two, three weeks before the previous release, somebody volunteers to be the release lead. That person is confirmed by SIG Release. So far, we’ve never had more than one volunteer, so there hasn’t been really a fight about it.
And then that person starts working with others to put together a team called the release team. Tim’s just gone through this with Stephen Augustus and picking out a whole bunch of people. And then after or a little before— probably after, because we want to wait for the retrospective from the previous release— the release lead then sets a schedule for the upcoming release, as in when all the deadlines will be.
And this is a thing, because we’re still tinkering with relative deadlines, and how long should code freeze be, and how should we track features? Because we don’t feel that we’ve gotten down that sort of cadence perfectly yet. I mean, like, we’ve done pretty well, but we don’t feel like we want to actually set [in stone], this is the schedule for each and every release.
Also, we have to adjust the schedule because of holidays, right? Because you can’t have the code freeze deadline starting on July 4 or in the middle of design or sometime else when we’re going to have a large group of contributors who are out on vacation.
TIM PEPPER: This is something I’ve had to spend some time looking at, thinking about 1.12. Going back to early June as we were tinkering with the code freeze date, starting to think about, well, what are the implications going to be on 1.12? When would these things start falling on the calendar? And then also for 1.11, we had one complexity. If we slipped the release past this week, we start running into the US 4th of July holiday, and we’re not likely to get a lot done.
So much of a slip would mean slipping into the middle of July before we’d really know that we were successfully triaging things. And worst case maybe, we’re quite a bit later into July.
So instead of quarterly with a three-month sort of cadence, well, maybe we’ve accidentally ended up chopping out one month out of the next release or pushing it quite a bit into the end of the year. And that made the deliberation around things quite complex, but thankfully this week, everything’s gone smoothly in the end.
CRAIG BOX: All the releases so far have been one quarter — they’ve been a 12-week release cycle, give or take. Is that something that you think will continue going forward, or is the release team thinking about different ways they could run releases?
TIM PEPPER: The whole community is thinking about this. There are voices who’d like the cadence to be faster, and there are voices who’d like it to be shorter. And there’s good arguments for both.
ADAM GLICK: Because it’s interesting. It sounds like it is a date-driven release cycle versus a feature-driven release cycle.
JOSH BERKUS: Yeah, certainly. I really honestly think everybody in the world of software recognizes that feature-driven release cycles just don’t work. And a big part of the duties of the release team collectively— several members of the team do this— is yanking things out of the release that are not ready. And the hard part of that is figuring out which things aren’t ready, right? Because the person who’s working on it tends to be super optimistic about what they can get done and what they can get fixed before the deadline.
ADAM GLICK: Of course.
TIM PEPPER: And this is one of the things I think that’s useful about the process we have in place on the release team for having shadows who spend some time on the release team, working their way up into more of a lead position and gaining some experience, starting to get some exposure to see that optimism and see the processes for vetting.
And it’s even an overstatement to say the process. Just see the way that we build the intuition for how to vet and understand and manage the risk, and really go after and chase things down proactively and early to get resolution in a timely way versus continuing to just all be optimistic and letting things maybe languish and put a release at risk.
CRAIG BOX: I’ve been reading this week about the introduction of feature branches to Kubernetes. The new server-side apply feature, for example, is being built in a branch so that it didn’t have to be half-built in master and then ripped out again as the release approached, if the feature wasn’t ready. That seems to me like something that’s a normal part of software development? Is there a reason it’s taken so long to bring that to core Kubernetes?
JOSH BERKUS: I don’t actually know the history of why we’re not using feature branches. I mean, the reason why we’re not using feature branches pervasively now is that we have to transition from a different system. And I’m not really clear on how we adopted that linear development system. But it’s certainly something we discussed on the release team, because there were issues of features that we thought were going to be ready, and then developed major problems. And we’re like, if we have to back this out, that’s going to be painful. And we did actually have to back one feature out, which involved not pulling out a Git commit, but literally reversing the line changes, which is really not how you want to be doing things.
CRAIG BOX: No.
TIM PEPPER: The other big benefit, I think, to the release branches if they are well integrated with the CI system for continuous integration and testing, you really get the feedback, and you can demonstrate, this set of stuff is ready. And then you can do deferred commitment on the master branch. And what comes in to a particular release on the timely cadence that users are expecting is stuff that’s ready. You don’t have potentially destabilizing things, because you can get a lot more proof and evidence of readiness.
ADAM GLICK: What are you looking at in terms of the tool chain that you’re using to do this? You mentioned a couple of things, and I know it’s obviously run through GitHub. But I imagine you have a number of other tools that you’re using in order to manage the release, to make sure that you understand what’s ready, what’s not. You mentioned balancing between people who are very optimistic about the feature they’re working on making it in versus the time-driven deadline, and balancing those two. Is that just a manual process, or do you have a set of tools that help you do that?
JOSH BERKUS: Well, there’s code review, obviously. So just first of all, process was somebody wants to actually put in a feature, commit, or any kind of merge really, right? So that has to be assigned to one of the SIGs, one of these Special Interest Groups. Possibly more than one, depending on what areas it touches.
And then two generally overlapping groups of people have to approve that. One would be the SIG that it’s assigned to, and the second would be anybody represented in the OWNERS files in the code tree of the directories which get touched.
Now sometimes those are the same group of people. I’d say often, actually. But sometimes they’re not completely the same group of people, because sometimes you’re making a change to the network, but that also happens to touch GCP support and OpenStack support, and so they need to review it as well.
So the first part is the human part, which is a bunch of other people need to look at this. And possibly they’re going to comment “Hey. This is a really weird way to do this. Do you have a reason for it?”
Then the second part of it is the automated testing that happens, the automated acceptance testing that happens via webhook on there. And actually, one of the things that we did that was a significant advancement in this release cycle— and by we, I actually mean not me, but the great folks at SIG Scalability did— was add an additional acceptance test that does a mini performance test.
Because one of the problems we’ve had historically is our major performance tests are large and take a long time to run, and so by the time we find out that we’re failing the performance tests, we’ve already accumulated, you know, 40, 50 commits. And so now we’re having to do git bisect to find out which of those commits actually caused the performance regression, which can make them very slow to address.
And so adding that performance pre-submit, the performance acceptance test really has helped stabilize performance in terms of new commits. So then we have that level of testing that you have to get past.
And then when we’re done with that level of testing, we run a whole large battery of larger tests— end-to-end tests, performance tests, upgrade and downgrade tests. And one of the things that we’ve added recently and we’re integrating to the process something called conformance tests. And the conformance test is we’re testing whether or not you broke backwards compatibility, because it’s obviously a big deal for Kubernetes users if you do that when you weren’t intending to.
One of the busiest roles in the release team is a role called CI Signal. And it’s that person’s job just to watch all of the tests for new things going red and then to try to figure out why they went red and bring it to people’s attention.
ADAM GLICK: I’ve often heard what you’re referring to kind of called a breaking change, because it breaks the existing systems that are running. How do you identify those to people so when they see, hey, there’s a new version of Kubernetes out there, I want to try it out, is that just going to release notes? Or is there a special way that you identify breaking changes as opposed to new features?
JOSH BERKUS: That goes into release notes. I mean, keep in mind that one of the things that happens with Kubernetes’ features is we go through this alpha, beta, general availability phase, right? So a feature’s alpha for a couple of releases and then becomes beta for a release or two, and then it becomes generally available. And part of the idea of having this that may require a feature to go through that cycle for a year or more before its general availability is by the time it’s general availability, we really want it to be, we are not going to change the API for this.
However, stuff happens, and we do occasionally have to do those. And so far, our main way to identify that to people actually is in the release notes. If you look at the current release notes, there are actually two things in there right now that are sort of breaking changes.
One of them is the bit with priority and preemption in that preemption being on by default now allows badly behaved users of the system to cause trouble in new ways. I’d actually have to look at the release notes to see what the second one was…
TIM PEPPER: The JSON capitalization case sensitivity.
JOSH BERKUS: Right. Yeah. And that was one of those cases where you have to break backwards compatibility, because due to a library switch, we accidentally enabled people using JSON in a case-insensitive way in certain APIs, which was never supposed to be the case. But because we didn’t have a specific test for that, we didn’t notice that we’d done it.
And so for three releases, people could actually shove in malformed JSON, and Kubernetes would accept it. Well, we have to fix that now. But that does mean that there are going to be users out in the field who have malformed JSON in their configuration management that is now going to break.
CRAIG BOX: But at least the good news is Kubernetes was always outputting correct formatted JSON during this period, I understand.
JOSH BERKUS: Mm-hmm.
TIM PEPPER: I think that also kind of reminds of one of the other areas— so kind of going back to the question of, well, how do you share word of breaking changes? Well, one of the ways you do that is to have as much quality CI that you can to catch these things that are important. Give the feedback to the developer who’s making the breaking change, such that they don’t make the breaking change. And then you don’t actually have to communicate it out to users.
So some of this is bound to happen, because you always have test escapes. But it’s also a reminder of the need to ensure that you’re also really building and maintaining your test cases and the quality and coverage of your CI system over time.
ADAM GLICK: What do you mean when you say test escapes?
TIM PEPPER: So I guess it’s a term in the art, but for those who aren’t familiar with it, you have intended behavior that wasn’t covered by test, and as a result, an unintended change happens to that. And instead of your intended behavior being shipped, you’re shipping something else.
JOSH BERKUS: The JSON change is a textbook example of this, which is we were testing that the API would continue to accept correct JSON. We were not testing adequately that it wouldn’t accept incorrect JSON.
TIM PEPPER: A test escape, another way to think of it as you shipped a bug because there was not a test case highlighting the possibility of the bug.
ADAM GLICK: It’s the classic, we tested to make sure the feature worked. We didn’t test to make sure that breaking things didn’t work.
TIM PEPPER: It’s common for us to focus on “I’ve created this feature and I’m testing the positive cases”. And this also comes to thinking about things like secure by default and having a really robust system. A harder piece of engineering often is to think about the failure cases and really actively manage those well.
JOSH BERKUS: I had a conversation with a contributor recently where it became apparent that contributor had never worked on a support team, because their conception of a badly behaved user was, like, a hacker, right? An attacker who comes from outside.
And I’m like, no, no, no. You’re stable of badly behaved users is your own staff. You know, they will do bad things, not necessarily intending to do bad things, but because they’re trying to take a shortcut. And that is actually your primary concern in terms of preventing breaking the system.
CRAIG BOX: Josh, what was your preparation to be release manager for 1.11?
JOSH BERKUS: I was on the release team for two cycles, plus I was kind of auditing the release team for half a cycle before that. So in 1.9, I originally joined to be the shadow for bug triage, except I ended up not being the shadow, because the person who was supposed to be the lead for bug triage then dropped out. Then I ended up being the bug triage lead, and had to kind of improvise it because there wasn’t documentation on what was involved in the role at the time.
And then I was bug triage lead for a second cycle, for the 1.10 cycle, and then took over as release lead for the cycle. And one of the things on my to-do list is to update the requirements to be release lead, because we actually do have written requirements, and to say that the expectation now is that you spend at least two cycles on the release team, one of them either as a lead or as a shadow to the release lead.
CRAIG BOX: And is bug triage lead just what it sounds like?
JOSH BERKUS: Yeah. Pretty much. There’s more tracking involved than triage. Part of it is just deficiencies in tooling, something we’re looking to address. But things like GitHub API limitations make it challenging to build automated tools that help us intelligently track issues. And we are actually working with GitHub on that. Like, they’ve been helpful. It’s just, they have their own scaling problems.
But then beyond that, you know, a lot of that, it’s what you would expect it to be in terms of what triage says, right? Which is looking at every issue and saying, first of all, is this a real issue? Second, is it a serious issue? Third, who needs to address this?
And that’s a lot of the work, because for anybody who is a regular contributor to Kubernetes, the number of GitHub notifications that they receive per day means that most of us turn our GitHub notifications off.
CRAIG BOX: Indeed.
JOSH BERKUS: Because it’s just this fire hose. And as a result, when somebody really needs to pay attention to something right now, that generally requires a human to go and track them down by email or Slack or whatever they prefer. Twitter in some cases. I’ve done that. And say, hey. We really need you to look at this issue, because it’s about to hold up the beta release.
ADAM GLICK: When you look at the process that you’re doing now, what are the changes that are coming in the future that will make the release process even better and easier?
JOSH BERKUS: Well, we just went through this whole retro, and I put in some recommendations for things. Obviously, some additional automation, which I’m going to be looking at doing now that I’m cycling off of the release team for a quarter and can actually look at more longer term goals, will help, particularly now that we’ve addressed actually some of our GitHub data flow issues.
Beyond that, I put in a whole bunch of recommendations in the retro, but it’s actually up to Tim which recommendations he’s going to try to implement. So I’ll let him [comment].
TIM PEPPER: I think one of the biggest changes that happened in the 1.11 cycle is this emphasis on trying to keep our continuous integration test status always green. That is huge for software development and keeping velocity. If you have this more, I guess at this point antiquated notion of waterfall development, where you do feature development for a while and are accepting of destabilization, and somehow later you’re going to come back and spend a period on stabilization and fixing, that really elongates the feedback loop for developers.
And they don’t realize what was broken, and the problems become much more complex to sort out as time goes by. One, developers aren’t thinking about what it was that they’d been working on anymore. They’ve lost the context to be able to efficiently solve the problem.
But then you start also getting interactions. Maybe a bug was introduced, and other people started working around it or depending on it, and you get complex dependencies then that are harder to fix. And when you’re trying to do that type of complex resolution late in the cycle, it becomes untenable over time. So I think continuing on that and building on it, I’m seeing a little bit more focus on test cases and meaningful test coverage. I think that’s a great cultural change to have happening.
And maybe because I’m following Josh into this role from a bug triage position and in his mentions earlier of just the communications and tracking involved with that versus triage, I do have a bit of a concern that at times, email and Slack are relatively quiet. Some of the SIG meeting notes are a bit sparse or YouTube videos slow to upload. So the general artifacts around choice making I think is an area where we need a little more rigor. So I’m hoping to see some of that.
And that can be just as subtle as commenting on issues like, hey, this commit doesn’t say what it’s doing. And for that reason on the release team, we can’t assess its risk versus value. So could you give a little more information here? Things like that give more information both to the release team and the development community as well, because this is open source. And to collaborate, you really do need to communicate in depth.
CRAIG BOX: Speaking of cultural changes, professional baker to Kubernetes’ release lead sounds like quite a journey.
JOSH BERKUS: There was a lot of stuff in between.
CRAIG BOX: Would you say there are a lot of similarities?
JOSH BERKUS: You know, believe it or not, there actually are similarities. And here’s where it’s similar, because I was actually thinking about this earlier. So when I was a professional baker, one of the things that I had to do was morning pastry. Like, I was actually in charge of doing several other things for custom orders, but since I had to come to work at 3:00 AM anyway— which also distressingly has similarities with some of this process. Because I had to come to work at 3:00 AM anyway, one of my secondary responsibilities was traying the morning pastry.
And one of the parts of that is you have this great big gas-fired oven with 10 rotating racks in it that are constantly rotating. Like, you get things in and out in the oven by popping them in and out while the racks are moving. That takes a certain amount of skill. You get burn marks on your wrists for your first couple of weeks of work. And then different pastries require a certain number of rotations to be done.
And there’s a lot of similarities to the release cadence, because what you’re doing is you’re popping something in the oven or you’re seeing something get kicked off, and then you have a certain amount of time before you need to check on it or you need to pull it out. And you’re doing that in parallel with a whole bunch of other things. You know, with 40 other trays.
CRAIG BOX: And with presumably a bunch of colleagues who are all there at the same time.
JOSH BERKUS: Yeah. And the other thing is that these deadlines are kind of absolute, right? You can’t say, oh, well, I was reading a magazine article, and I didn’t have time to pull that tray out. It’s too late. The pastry is burned, and you’re going to have to throw it away, and they’re not going to have enough pastry in the front case for the morning rush. And the customers are not interested in your excuses for that.
So from that perspective, from the perspective of saying, hey, we have a bunch of things that need to happen in parallel, they have deadlines and those deadlines are hard deadlines, there it’s actually fairly similar.
CRAIG BOX: Tim, do you have any other history that helped get you to where you are today?
TIM PEPPER: I think in some ways I’m more of a traditional journey. I’ve got a computer engineering bachelor’s degree. But I’m also maybe a bit of an outlier. In the late ‘90s, I found a passion for open source and Linux. Maybe kind of an early adopter, early believer in that.
And was working in the industry in the Bay Area for a while. Got involved in the Silicon Valley and Bay Area Linux users groups a bit, and managed to find work as a Linux sysadmin, and then doing device driver and kernel work and on up into distro. So that was all kind of standard in a way. And then I also did some other work around hardware enablement, high-performance computing, non-uniform memory access. Things that are really, really systems work.
And then about three years ago, my boss was really bending my ear and trying to get me to work on this cloud-related project. And that just felt so abstract and different from the low-level bits type of stuff that I’d been doing.
But kind of grudgingly, I eventually came around to the realization that the cloud is interesting, and it’s so much more complex than local machine-only systems work, the type of things that I’d been doing before. It’s massively distributed and you have a high-latency, low-reliability interconnect on all the nodes in the distributed network. So it’s wildly complex engineering problems that need solved.
And so that got me interested. Started working then on this open source orchestrator for virtual machines and containers. It was written in Go and was having a lot of fun. But it wasn’t Kubernetes, and it was becoming clear that Kubernetes was taking off. So about a year ago, I made the deliberate choice to move over to Kubernetes work.
ADAM GLICK: Previously, Josh, you spoke a little bit about your preparation for becoming a release manager. For other folks that are interested in getting involved in the community and maybe getting involved in release management, should they follow the same path that you did? Or what are ways that would be good for them to get involved? And for you, Tim, how you’ve approached the preparation for taking on the next release.
JOSH BERKUS: The great thing with the release team is that we have this formal mentorship path. And it’s fast, right? That’s the advantage of releasing quarterly, right? Is that within six months, you can go from joining the team as a shadow to being the release lead if you have the time. And you know, by the time you work your way up to release time, you better have support from your boss about this, because you’re going to end up spending a majority of your work time towards the end of the release on release management.
So the answer is to sign up to look when we’re getting into the latter half of release cycle, to sign up as a shadow. Or at the beginning of a release cycle, to sign up as a shadow. Some positions actually can reasonably use more than one shadow. There’s some position that just require a whole ton of legwork like release notes. And as a result, could actually use more than one shadow meaningfully. So there’s probably still places where people could sign up for 1.12. Is that true, Tim?
TIM PEPPER: Definitely. I think— gosh, right now we have 34 volunteers on the release team, which is—
ADAM GLICK: Wow.
JOSH BERKUS: OK. OK. Maybe not then.
[LAUGH]
TIM PEPPER: It’s potentially becoming a lot of cats to herd. But I think even outside of that formal volunteering to be a named shadow, anybody is welcome to show up to the release team meetings, follow the release team activities on Slack, start understanding how the process works. And really, this is the case all across open source. It doesn’t even have to be the release team. If you’re passionate about networking, start following what SIG Network is doing. It’s the same sort of path, I think, into any area on the project.
Each of the SIGs [has] a channel. So it would be #SIG-whatever the name is. [In our] case, #SIG-Release.
I’d also maybe give a plug for a talk I did at KubeCon in Copenhagen this spring, talking about how the release team specifically can be a path for new contributors coming in. And had some ideas and suggestions there for newcomers.
CRAIG BOX: There’s three questions in the Google SRE postmortem template that I really like. And I’m sure you will have gone through these in the retrospective process as you released 1.11, so I’d like to ask them now one at a time.
First of all, what went well?
JOSH BERKUS: Two things, I think, really improved things, both for contributors and for the release team. Thing number one was putting a strong emphasis on getting the test grid green well ahead of code freeze.
TIM PEPPER: Definitely.
JOSH BERKUS: Now partly that went well because we had a spectacular CI lead, Aish Sundar, who’s now in training to become the release lead.
TIM PEPPER: And I’d count that partly as one of the “Where were you lucky?” areas. We happened upon a wonderful person who just popped up and volunteered.
JOSH BERKUS: Yes. And then but part of that was also that we said, hey. You know, we’re not going to do what we’ve done before which is not really care about these tests until code slush. We’re going to care about these tests now.
And importantly— this is really important to the Kubernetes community— when we went to the various SIGs, the SIG Cluster Lifecycle and SIG Scalability and SIG Node and the other ones who were having test failures, and we said this to them. They didn’t say, get lost. I’m busy. They said, what’s failing?
CRAIG BOX: Great.
JOSH BERKUS: And so that made a big difference. And the second thing that was pretty much allowed by the first thing was to shorten the code freeze period. Because the code freeze period is frustrating for developers, because if they don’t happen to be working on a 1.11 feature, even if they worked on one before, and they delivered it early in the cycle, and it’s completely done, they’re kind of paralyzed, and they can’t do anything during code freeze. And so it’s very frustrating for them, and we want to make that period as short as possible. And we did that this time, and I think it helped everybody.
CRAIG BOX: What went poorly?
JOSH BERKUS: We had a lot of problems with flaky tests. We have a lot of old tests that are not all that well maintained, and they’re testing very complicated things like upgrading a cluster that has 40 nodes. And as a result, these tests have high failure rates that have very little to do with any change in the code.
And so one of the things that happened, and the reason we had a one-day delay in the release is, you know, we’re a week out from release, and just by random luck of the draw, a bunch of these tests all at once got a run of failures. And it turned out that run of failures didn’t actually mean anything, having anything to do with Kubernetes. But there was no way for us to tell that without a lot of research, and we were not going to have enough time for that research without delaying the release.
So one of the things we’re looking to address in the 1.12 cycle is to actually move some of those flaky tests out. Either fix them or move them out of the release blocking category.
TIM PEPPER: In a way, I think this also highlights one of the things that Josh mentioned that went well, the emphasis early on getting the test results green, it allows us to see the extent to which these flakes are such a problem. And then the unlucky occurrence of them all happening to overlap on a failure, again, highlights that these flakes have been called out in the community for quite some time. I mean, at least a year. I know one contributor who was really concerned about them.
But they became a second order concern versus just getting things done in the short term, getting features and proving that the features worked, and kind of accepting in a risk management way on the release team that, yes, those are flakes. We don’t have time to do something about them, and it’s OK. But because of the emphasis on keeping the test always green now, we have the luxury maybe to focus on improving these flakes, and really get to where we have truly high quality CI signal, and can really believe in the results that we have on an ongoing basis.
JOSH BERKUS: And having solved some of the more basic problems, we’re now seeing some of the other problems like coordination between related features. Like we right now have a feature where— and this is one of the sort of backwards compatibility release notes— where the feature went into beta, and is on by default.
And the second feature that was supposed to provide access control for the first feature did not go in as beta, and is not on by default. And the team for the first feature did not realize the second feature was being held up until two days before the release. So it’s going to result in us actually patching something in 11.1.
And so like, we put that into something that didn’t go well. But on the other hand, as Tim points out, a few release cycles ago, we wouldn’t even have identified that as a problem, because we were still struggling with just individual features having a clear idea well ahead of the release of what was going in and what wasn’t going in.
TIM PEPPER: I think something like this also is a case that maybe advocates for the use of feature branches. If these things are related, we might have seen it and done more pre-testing within that branch and pre-integration, and decide maybe to merge a couple of what initially had been disjoint features into a single feature branch, and really convince ourselves that together they were good. And cross all the Ts, dot all the Is on them, and not have something that’s gated on an alpha feature that’s possibly falling away.
CRAIG BOX: And then the final question, which I think you’ve both touched on a little. Where did you get lucky, or unlucky perhaps?
JOSH BERKUS: I would say number one where I got lucky is truly having a fantastic team. I mean, we just had a lot of terrific people who were very good and very energetic and very enthusiastic about taking on their release responsibilities including Aish and Tim and Ben and Nick and Misty who took over Docs four weeks into the release. And then went crazy with it and said, well, I’m new here, so I’m going to actually change a bunch of things we’ve been doing that didn’t work in the first place. So that was number one. I mean, that really made honestly all the difference.
And then the second thing, like I said, is that we didn’t have sort of major, unexpected monkey wrenches thrown at us. So in the 1.10 cycle, we actually had two of those, which is why I still count Jace as heroic for pulling off a release that was only a week late.
You know, number one was having the scalability tests start failing for unrelated reasons for a long period, which then masked the fact that they were actually failing for real reasons when we actually got them working again. And as a result, ending up debugging a major and super complicated scalability issue within days of what was supposed to be the original release date. So that was monkey wrench number one for the 1.10 cycle.
Monkey wrench number two for the 1.10 cycle was we got a security hole that needed to be patched. And so again, a week out from what was supposed to be the original release date, we were releasing a security update, and that security update required patching the release branch. And it turns out that patch against the release branch broke a bunch of incoming features. And we didn’t get anything of that magnitude in the 1.11 release, and I’m thankful for that.
TIM PEPPER: Also, I would maybe argue in a way that a portion of that wasn’t just luck. The extent to which this community has a good team, not just the release team but beyond, some of this goes to active work that folks all across the project, but especially in the contributor experience SIG are doing to cultivate a positive and inclusive culture here. And you really see that. When problems crop up, you’re seeing people jump on and really try to constructively tackle them. And it’s really fun to be a part of that.
Thanks to Josh Berkus and Tim Pepper for talking to the Kubernetes Podcast from Google.
Josh Berkus hangs out in #sig-release on the Kubernetes Slack. He maintains a newsletter called “Last Week in Kubernetes Development”, with Noah Kantrowitz. You can read him on Twitter at @fuzzychef, but he does warn you that there’s a lot of politics there as well.
Tim Pepper is also on Slack – he’s always open to folks reaching out with a question, looking for help or advice. On Twitter you’ll find him at @pythomit, which is “Timothy P” backwards. Tim is an avid soccer fan and season ticket holder for the Portland Timbers and the Portland Thorns, so you’ll get all sorts of opinions on soccer in addition to technology!
You can find the Kubernetes Podcast from Google at @kubernetespod on Twitter, and you can subscribe so you never miss an episode.
Source