So last week I finally got out from my “tech” comfort zone, and tried
to set up a Node.js application which uses a MongoDB database, and to
add an extra layer of fun I used Rancher to set up the
whole application stack using Docker containers.
I designed a small application with Node, its only function is to
calculate the number of hits on the website, you can find the code at
Github
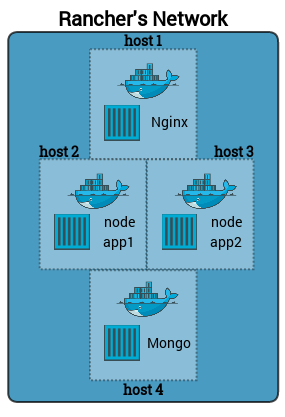
The setup was to add an Nginx container as a load balancer at the
front-end to serve two back-end Node application containers, and then
have the two Node servers connect to a MongoDB database container. In
this setup I will use 5 machines from Digital Ocean, 4 to build the
application stack with the highest availability, and the 5th as a
Rancher server.
[]Set Up A Rancher Server
On a Digital Ocean machine with Docker 1.4 installed we will apply the
following command to set up a Rancher platform on the port 8000:
root@Rancher-Mngmt:~# docker run -d –name rancher-server -p 8080:8080 rancher/server
The previous command will run a docker instance with rancher platform,
and proxy the port 8080 on the instance to the same port on the Digital
Ocean machine. To make sure that the server is running type this
command:
root@Rancher-io-Mngmt:~# docker logs rancher-server
You should see something like the following output:
20:02:41.943 [main] INFO ConsoleStatus – [DONE ] [68461ms] Startup Succeeded, Listening on port 8080
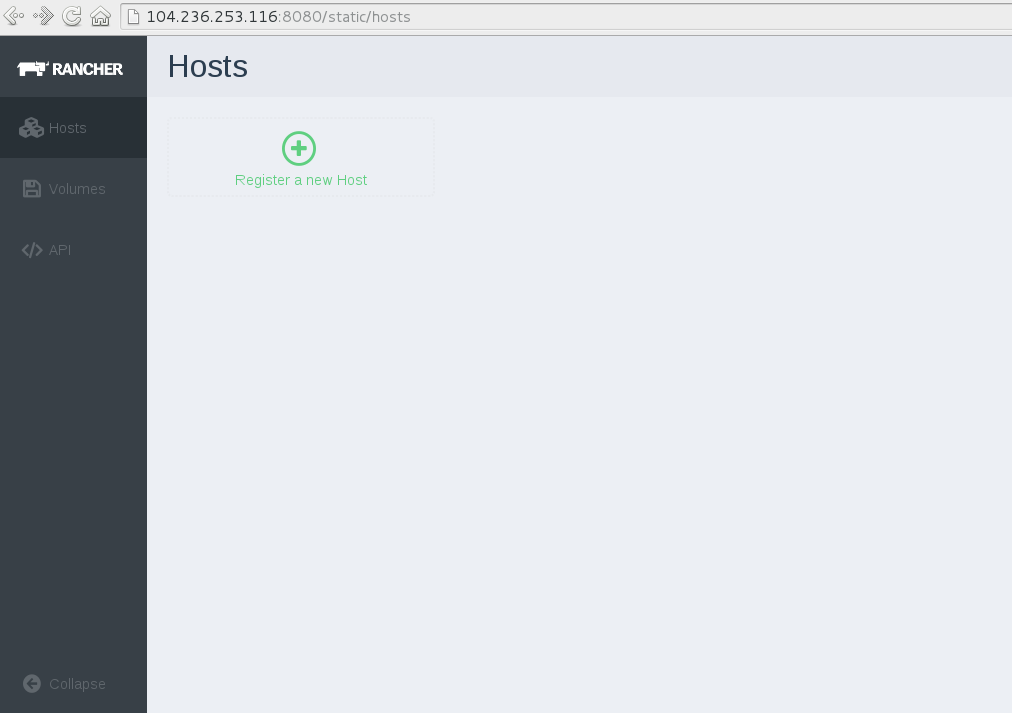
To access Rancher now, type the following url in your browser:
http://DO-ip-address:8080/
you should see something like the following:
[]Register Digital Ocean’s instances With Rancher
To register the Digital Ocean machines with docker 1.4 installed with
Rancher, type the following on each machine:
root@Rancher-Test-Instance-X# docker run -it –privileged -v /var/run/docker.sock:/var/run/docker.sock rancher/agent http://rancher-server-ip:8080
where rancher-server-ip is the ip address of the
Rancher server we just installed, or you can click on “Register a New
Host “ on Rancher platform and copy the command shown.

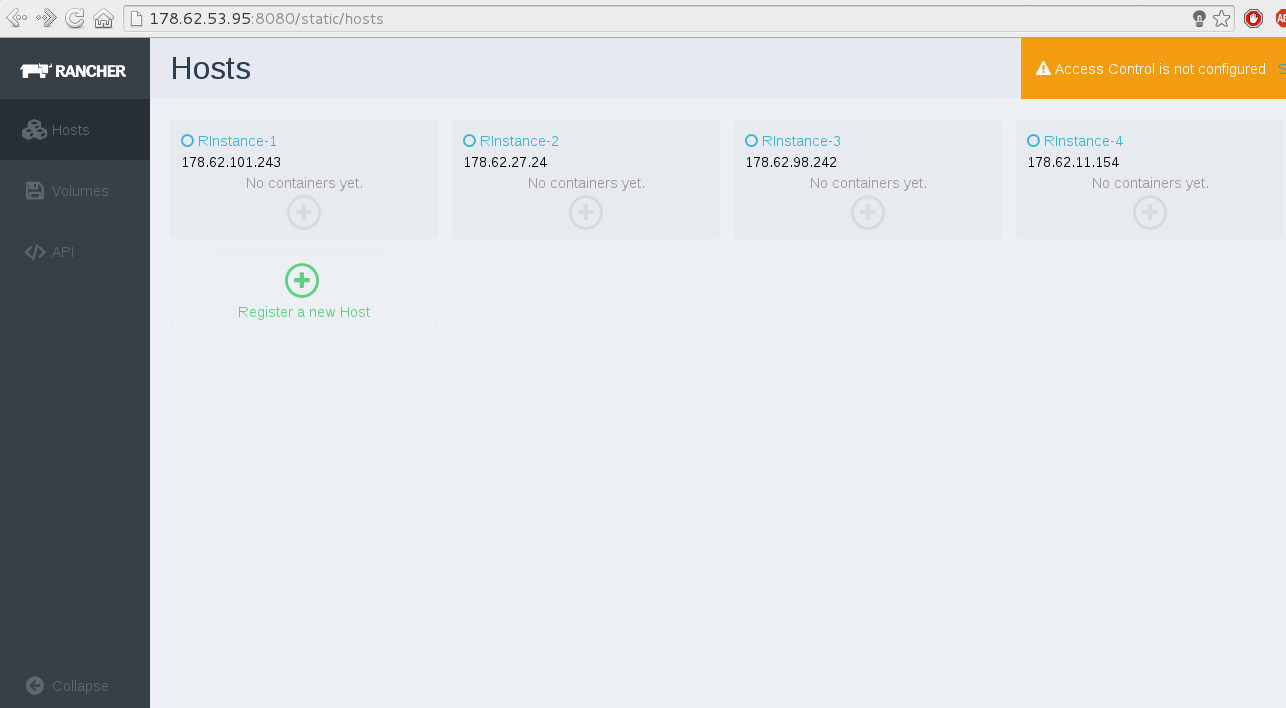
After applying the previous command on each machine you should see
something like the following when you access the Rancher management
server:
If you are familiar with Ansible as a configuration management
tool, you can use it to register the Digital Ocean machines with Rancher
in one command:
- First, add the ips of the Digital Ocean machines in
/etc/ansible/hosts under one group name:
[DO]
178.62.101.243
178.62.27.24
178.62.98.242
178.62.11.154
- Now, run the following command to register all machines at
once:
$ ansible DO -u root -a “docker run -it –privileged -v /var/run/docker.sock:/var/run/docker.sock rancher/agent http://rancher-server-ip:8080”
MongoDB Docker Container
After Registering the 4 machines with Rancher, its time to start
building our application stack.
The node.js application will calculate the number of hits on a
website, so it needs to store this data somewhere. I will use MongoDB
container to store the number of hits.
The Dockerfile will be like the following:
FROM ubuntu:14.04
MAINTAINER hussein.galal.ahmed.11@gmail.com
ENV chached_FLAG 0
RUN apt-get -qq update && apt-get -yqq upgrade
RUN apt-key adv –keyserver hkp://keyserver.ubuntu.com:80 –recv 7F0CEB10
RUN echo ‘deb http://downloads-distro.mongodb.org/repo/ubuntu-upstart dist 10gen’ | tee /etc/apt/sources.list.d/10gen.list
RUN apt-get update && apt-get install -yqq mongodb-org
RUN mkdir -p /data/db
EXPOSE 27017
ADD run.sh /tmp/run.sh
ADD init.json /tmp/init.json
ENTRYPOINT [“/bin/bash”, “/tmp/run.sh”]
The previous Docker file is really simple, lets explain it line by
line:
- First update the apt cache and install latest updates:
RUN apt-get -qq update && apt-get -yqq upgrade
- Add the key and the mongodb repo to apt sources.list:
RUN apt-key adv –keyserver hkp://keyserver.ubuntu.com:80 –recv 7F0CEB10
RUN echo ‘deb http://downloads-distro.mongodb.org/repo/ubuntu-upstart dist 10gen’ | tee /etc/apt/sources.list.d/10gen.list
- Install the MongoDB package which installs the server and the
client:
RUN apt-get update && apt-get install -yqq mongodb-org
- Create the directory which will store the MongoDB files:
- Expose the port 27017, which is the default port to connect to
MongoDB:
- Add two files to the container:
- init.json: the initial database to start the
application.
- run.sh: will import the init.json database to the
MongoDB server and ran the server.
ADD run.sh /tmp/run.sh
ADD init.json /tmp/init.json
- Finally, it will add entrypoint to the container to be started with
executing the run.sh file:
ENTRYPOINT [“/bin/bash”, “/tmp/run.sh”]
Let’s take a look at the run.sh file:
#!/bin/bash
/usr/bin/mongod &
sleep 3
mongoimport –db countdb –collection hits –type json –file /tmp/init.json
/usr/bin/mongod –shutdown
sleep 3
/usr/bin/mongod
The server started first to be able to import the init.json database to
the countdb database and hits collection, then shutdown the server and
start it up again but in the foreground this time.
The init.json database file:
Node.js Application Container
The Node.js container will install node.js and git packages, and
then will run a simple script to update the /etc/hosts file with the ip of the MongoDB container provided by the
environment variable: $MONGO_IP.
FROM ubuntu:14.04
MAINTAINER hussein.galal.ahmed.11@gmail.com
ENV CACHED_FLAG 1
# Install node
RUN apt-get update -qq && apt-get -y upgrade
RUN apt-get install -yqq nodejs git git-core
VOLUME [ “/var/www/nodeapp” ]
ADD ./run.sh /tmp/run.sh# Install Dependencies
WORKDIR /var/www/nodeapp
# Run The App
ENTRYPOINT [“/bin/bash”, “/tmp/run.sh”]
The ENTRYPOINT of the Docker container is executing the
/tmp/run.sh script:
MONGO_DN=mongo
if [ -n “$MONGO_IP” ]
then
echo “$MONGO_IP $MONGO_DN” >> /etc/hosts
fi
# Fetch the application
git clone https://github.com/galal-hussein/hitcntr-nodejs.git
mv hitcntr-nodejs/* .
rm -rf hitcntr-nodejs
# Run the Application
nodejs index.js
The previous script will check for the MONGO_IP environment variable and if it is set, it will add the content of
this variable to /etc/hosts, then pull the code from
Github Repo, and finally run the node application.
Nginx Container
The Dockerfile of the Nginx container will install nginx webserver and
add the configuration files, and ran a script to update /etc/hosts file
like the Node.js container, and finally run the web server.
Nginx Dockerfile:
#dockerfile for nginx/nodejs
FROM ubuntu:14.04
MAINTAINER hussein.galal.ahmed.11@gmail.com
ENV CACHED_FLAG 0
# Install nginx
RUN apt-get update -qq && apt-get -y upgrade
RUN apt-get -y -qq install nginx
# Adding the configuration files
ADD conf/nginx.conf /etc/nginx/nginx.conf
ADD conf/default /etc/nginx/conf.d/default
ADD ./run.sh /tmp/run.sh
# Expose the port 80
EXPOSE 80
# Run nginx
ENTRYPOINT [ “/bin/bash”, “/tmp/run.sh” ]
The Dockerfile is very simple and use the same commands like the
previous images.
run.sh:
NODE_1_DN=node_app1
NODE_2_DN=node_app2
if [ -n “$NODE_APP1_IP” ]
then
echo “$NODE_APP1_IP $NODE_1_DN” >> /etc/hosts
fi
if [ -n “$NODE_APP2_IP” ]
then
echo “$NODE_APP2_IP $NODE_2_DN” >> /etc/hosts
fi
# Run Nginx
/usr/sbin/nginx
Since we are using two Node application servers, we need to proxy the
http requests received by Nginx to those servers and to do that we need
to add the ips of the Node.js containers to the hosts file.
The ips of the Node.js containers are defined by the two environment
variables (NODE_APP1_IP, and NODE_APP2_IP).
Build And Push The Images
Now for the final step, build and then push the images to Docker
hup:
~/rancher_vm# docker build -t husseingalal/nodeapp_mongo mongo/
~/rancher_vm# docker build -t husseingalal/nodeapp_node node/
~/rancher_vm# docker build -t husseingalal/nodeapp_nginx nginx/
~/rancher_vm# docker push husseingalal/nodeapp_mongo
~/rancher_vm# docker push husseingalal/nodeapp_node
~/rancher_vm# docker push husseingalal/nodeapp_nginx
Now Docker will ask you for your account credentials, then the images
will be pushed to the Docker hub to be used later with Rancher.
Set Up The Application Stack
- At Rancher platform, create at the first host a Docker container
using the MongoDB image we just created:

Note that the option “Manage Network on docker0“
was chosen to make sure that we will enable one of the unique features
of Rancher which is cross container networking, this feature enables
Docker containers on different hosts to communicate in a virtual private
network.
After clicking Create, you should see that the machine is started to
download the image and install it along with another docker instance
called Network Agent which is used to create the virtual private network
we just talked about.

- The second step is to add the the two Node.js Application servers
which are connected to the MongoDB database:
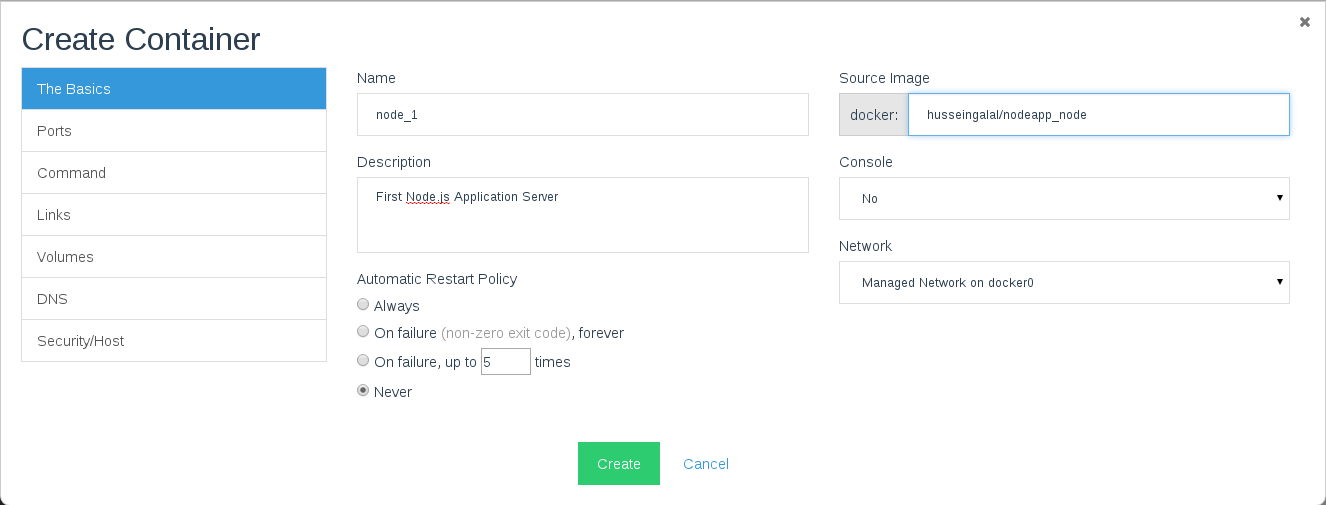
Note that we used the Node.js image we just created, before creating
the container make sure to add the MONGO_IP environment variable to add the ip of the MongoDB server, you can
get the private ip of the MongoDB server from the Rancher panel:

After that click Create to begin the creation process of the Node.js
container. On the second host create the second Node.js Application
container using the same steps.
- The final step is to create the Nginx webserver container on the
last host:
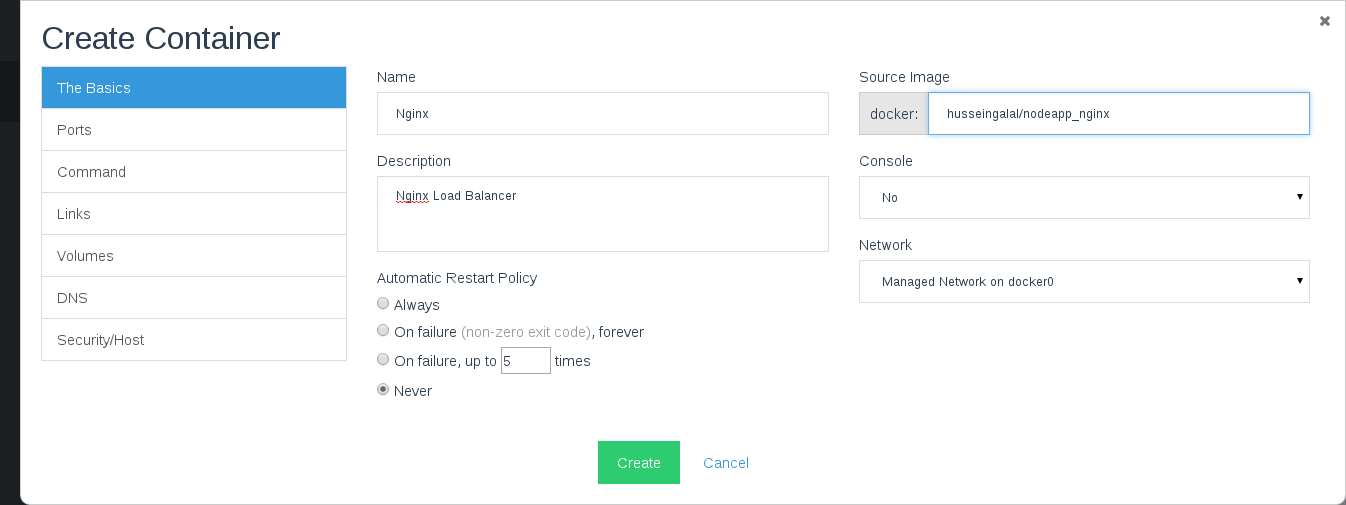
Since the nginx instance will be facing the internet, we should proxy
the port 80 from inside the container to the port 80 of the Digital
Ocean machine:
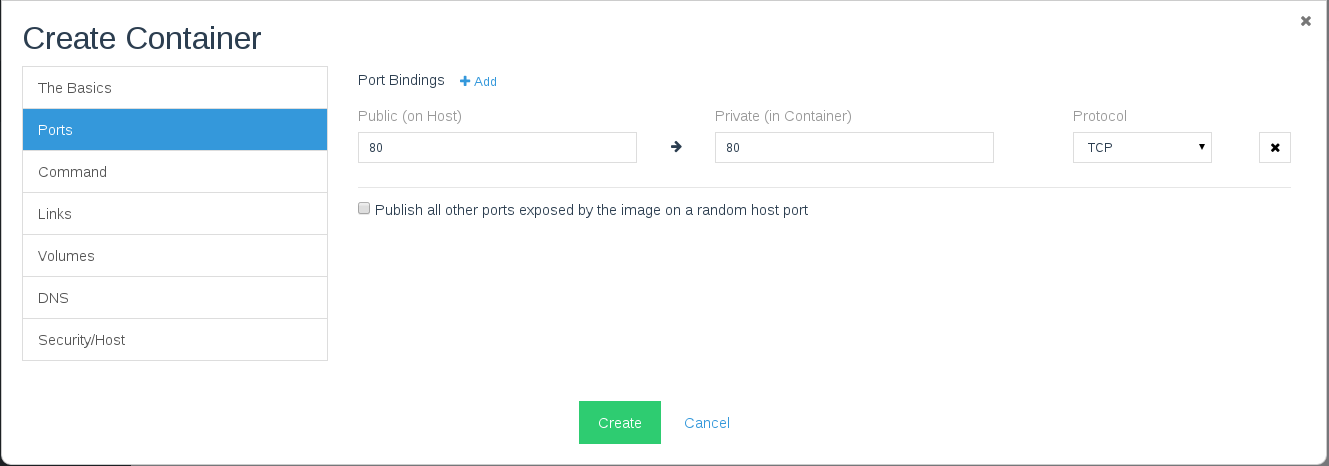
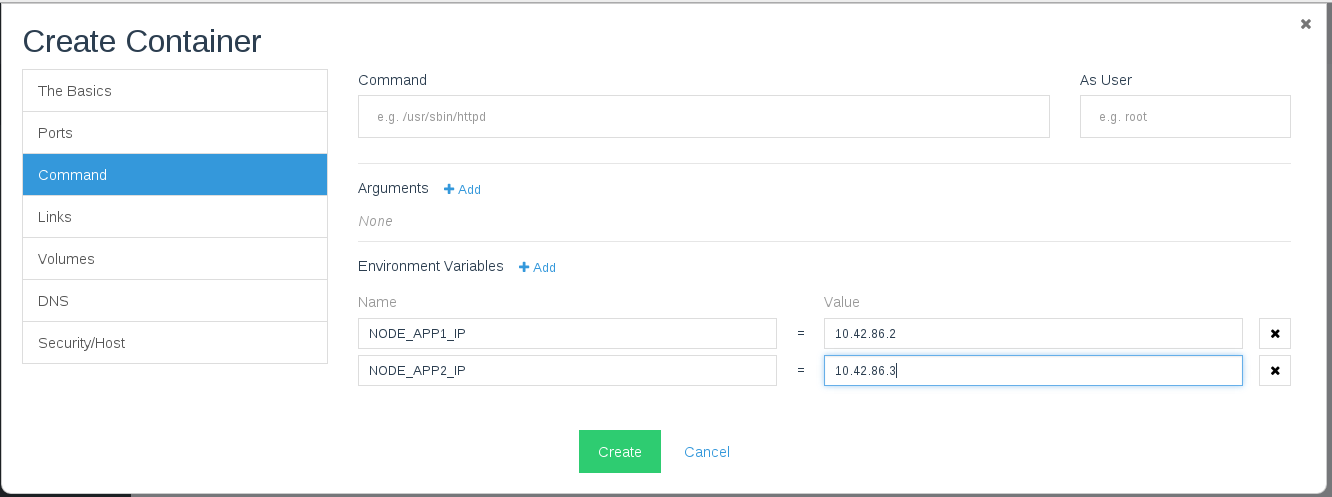
We need also to add the ips of the two Node.js application servers
which are connected to Nginx, you can add the ips through creating two
environment variables (NODE_APP1_IP, NODE_APP2_IP):
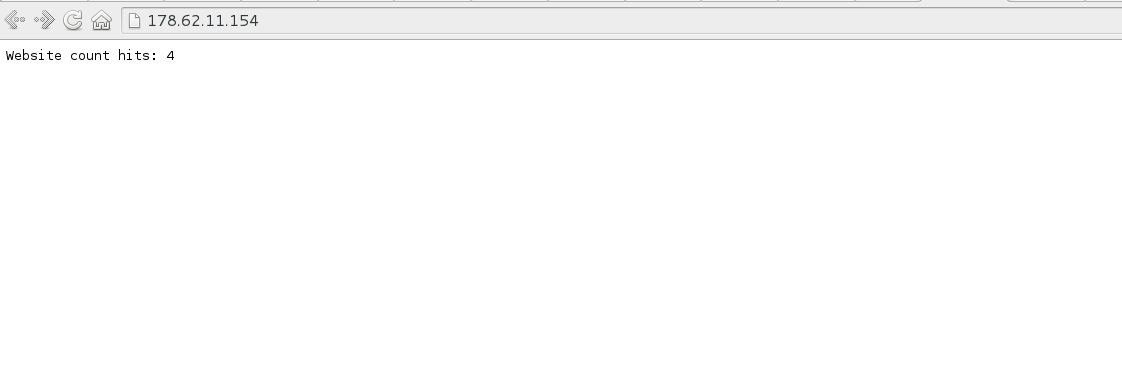
Now wecan access the application using the ip address of the Host
machine http://<the-ip-address>.
Conclusion
In part 1 of this series, I created a Node.js application stack using
Docker containers and Rancher platform. The stack consists of Nginx
container which balances the load between two Node.js application
containers and using MongoDB as our database.
In part 2
I introduce one of the newest features of Rancher: Github
Authentication, also I will use Github WebHooks feature for automatic deployment of the web application.
If you’d like to learn more about Rancher, please schedule a
demo:
Hussein Galal is a Linux System Administrator, with experience in
Linux, Unix, Networking, and open source technologies like Nginx,
Apache, PHP-FPM, Passenger, MySQL, LXC, and Docker. You can follow
Hussein
on Twitter @galal_hussein.*
Source