Kubernetes Containerd Integration Goes GA
Authors: Lantao Liu, Software Engineer, Google and Mike Brown, Open Source Developer Advocate, IBM
In a previous blog – Containerd Brings More Container Runtime Options for Kubernetes, we introduced the alpha version of the Kubernetes containerd integration. With another 6 months of development, the integration with containerd is now generally available! You can now use containerd 1.1 as the container runtime for production Kubernetes clusters!
Containerd 1.1 works with Kubernetes 1.10 and above, and supports all Kubernetes features. The test coverage of containerd integration on Google Cloud Platform in Kubernetes test infrastructure is now equivalent to the Docker integration (See: test dashboard).
We’re very glad to see containerd rapidly grow to this big milestone. Alibaba Cloud started to use containerd actively since its first day, and thanks to the simplicity and robustness emphasise, make it a perfect container engine running in our Serverless Kubernetes product, which has high qualification on performance and stability. No doubt, containerd will be a core engine of container era, and continue to driving innovation forward.
— Xinwei, Staff Engineer in Alibaba Cloud
The Kubernetes containerd integration architecture has evolved twice. Each evolution has made the stack more stable and efficient.
Containerd 1.0 – CRI-Containerd (end of life)
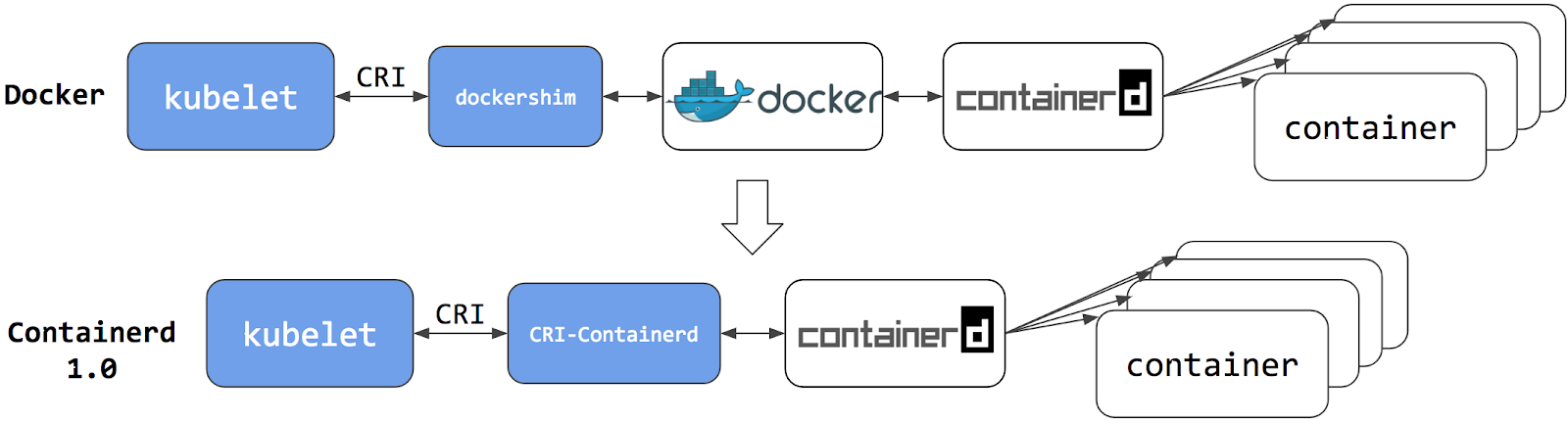
For containerd 1.0, a daemon called cri-containerd was required to operate between Kubelet and containerd. Cri-containerd handled the Container Runtime Interface (CRI) service requests from Kubelet and used containerd to manage containers and container images correspondingly. Compared to the Docker CRI implementation (dockershim), this eliminated one extra hop in the stack.
However, cri-containerd and containerd 1.0 were still 2 different daemons which interacted via grpc. The extra daemon in the loop made it more complex for users to understand and deploy, and introduced unnecessary communication overhead.
Containerd 1.1 – CRI Plugin (current)
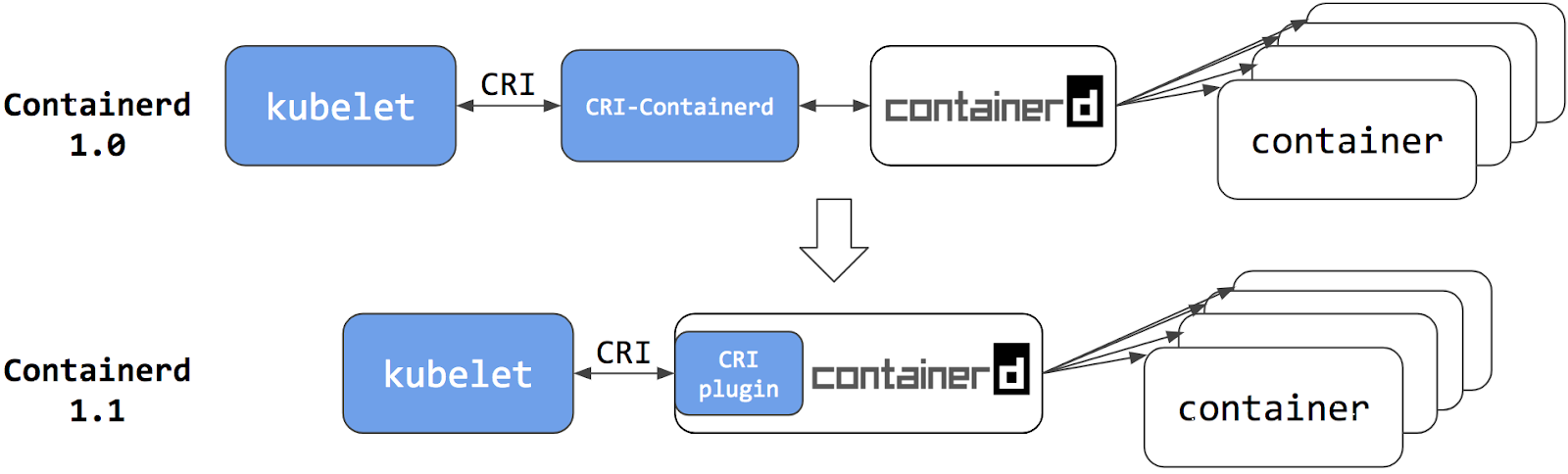
In containerd 1.1, the cri-containerd daemon is now refactored to be a containerd CRI plugin. The CRI plugin is built into containerd 1.1, and enabled by default. Unlike cri-containerd, the CRI plugin interacts with containerd through direct function calls. This new architecture makes the integration more stable and efficient, and eliminates another grpc hop in the stack. Users can now use Kubernetes with containerd 1.1 directly. The cri-containerd daemon is no longer needed.
Improving performance was one of the major focus items for the containerd 1.1 release. Performance was optimized in terms of pod startup latency and daemon resource usage.
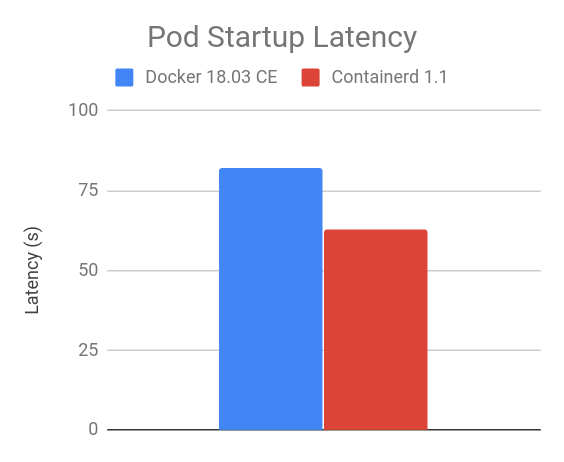
The following results are a comparison between containerd 1.1 and Docker 18.03 CE. The containerd 1.1 integration uses the CRI plugin built into containerd; and the Docker 18.03 CE integration uses the dockershim.
The results were generated using the Kubernetes node performance benchmark, which is part of Kubernetes node e2e test. Most of the containerd benchmark data is publicly accessible on the node performance dashboard.
Pod Startup Latency
The “105 pod batch startup benchmark” results show that the containerd 1.1 integration has lower pod startup latency than Docker 18.03 CE integration with dockershim (lower is better).
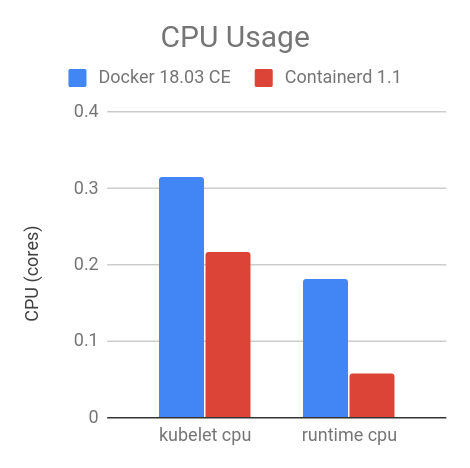
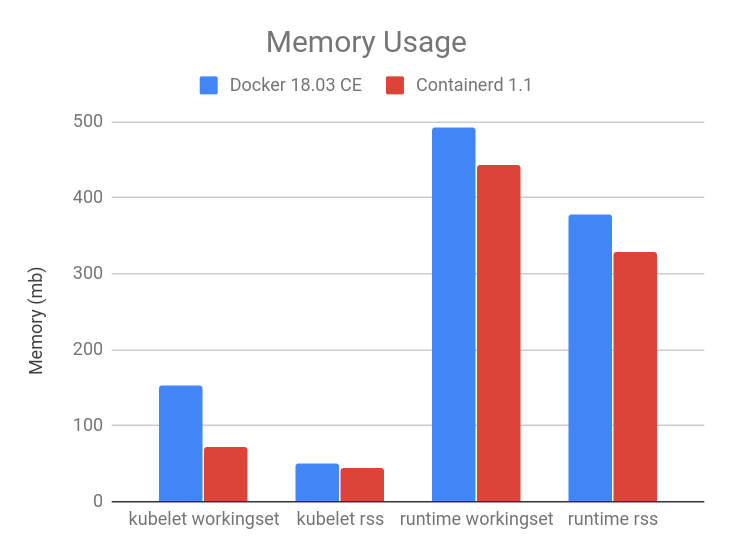
CPU and Memory
At the steady state, with 105 pods, the containerd 1.1 integration consumes less CPU and memory overall compared to Docker 18.03 CE integration with dockershim. The results vary with the number of pods running on the node, 105 is chosen because it is the current default for the maximum number of user pods per node.
As shown in the figures below, compared to Docker 18.03 CE integration with dockershim, the containerd 1.1 integration has 30.89% lower kubelet cpu usage, 68.13% lower container runtime cpu usage, 11.30% lower kubelet resident set size (RSS) memory usage, 12.78% lower container runtime RSS memory usage.
Container runtime command-line interface (CLI) is a useful tool for system and application troubleshooting. When using Docker as the container runtime for Kubernetes, system administrators sometimes login to the Kubernetes node to run Docker commands for collecting system and/or application information. For example, one may use docker ps and docker inspect to check application process status, docker images to list images on the node, and docker info to identify container runtime configuration, etc.
For containerd and all other CRI-compatible container runtimes, e.g. dockershim, we recommend using crictl as a replacement CLI over the Docker CLI for troubleshooting pods, containers, and container images on Kubernetes nodes.
crictl is a tool providing a similar experience to the Docker CLI for Kubernetes node troubleshooting and crictl works consistently across all CRI-compatible container runtimes. It is hosted in the kubernetes-incubator/cri-tools repository and the current version is v1.0.0-beta.1. crictl is designed to resemble the Docker CLI to offer a better transition experience for users, but it is not exactly the same. There are a few important differences, explained below.
The scope of crictl is limited to troubleshooting, it is not a replacement to docker or kubectl. Docker’s CLI provides a rich set of commands, making it a very useful development tool. But it is not the best fit for troubleshooting on Kubernetes nodes. Some Docker commands are not useful to Kubernetes, such as docker network and docker build; and some may even break the system, such as docker rename. crictl provides just enough commands for node troubleshooting, which is arguably safer to use on production nodes.
Kubernetes Oriented
crictl offers a more kubernetes-friendly view of containers. Docker CLI lacks core Kubernetes concepts, e.g. pod and namespace, so it can’t provide a clear view of containers and pods. One example is that docker ps shows somewhat obscure, long Docker container names, and shows pause containers and application containers together:

However, pause containers are a pod implementation detail, where one pause container is used for each pod, and thus should not be shown when listing containers that are members of pods.
crictl, by contrast, is designed for Kubernetes. It has different sets of commands for pods and containers. For example, crictl pods lists pod information, and crictl ps only lists application container information. All information is well formatted into table columns.


As another example, crictl pods includes a –namespace option for filtering pods by the namespaces specified in Kubernetes.

For more details about how to use crictl with containerd:
“Does switching to containerd mean I can’t use Docker Engine anymore?” We hear this question a lot, the short answer is NO.
Docker Engine is built on top of containerd. The next release of Docker Community Edition (Docker CE) will use containerd version 1.1. Of course, it will have the CRI plugin built-in and enabled by default. This means users will have the option to continue using Docker Engine for other purposes typical for Docker users, while also being able to configure Kubernetes to use the underlying containerd that came with and is simultaneously being used by Docker Engine on the same node. See the architecture figure below showing the same containerd being used by Docker Engine and Kubelet:
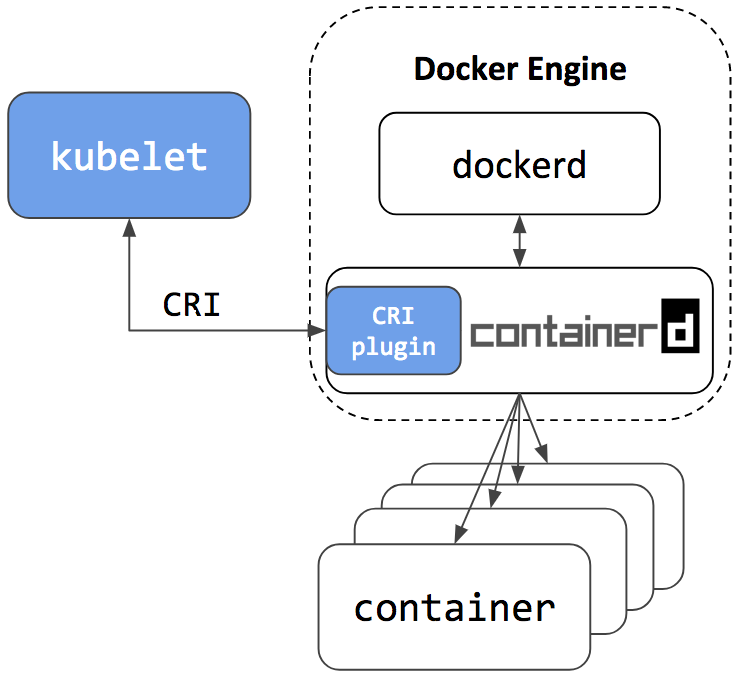
Since containerd is being used by both Kubelet and Docker Engine, this means users who choose the containerd integration will not just get new Kubernetes features, performance, and stability improvements, they will also have the option of keeping Docker Engine around for other use cases.
A containerd namespace mechanism is employed to guarantee that Kubelet and Docker Engine won’t see or have access to containers and images created by each other. This makes sure they won’t interfere with each other. This also means that:
- Users won’t see Kubernetes created containers with the docker ps command. Please use crictl ps instead. And vice versa, users won’t see Docker CLI created containers in Kubernetes or with crictl ps command. The crictl create and crictl runp commands are only for troubleshooting. Manually starting pod or container with crictl on production nodes is not recommended.
- Users won’t see Kubernetes pulled images with the docker images command. Please use the crictl images command instead. And vice versa, Kubernetes won’t see images created by docker pull, docker load or docker build commands. Please use the crictl pull command instead, and ctr cri load if you have to load an image.
- Containerd 1.1 natively supports CRI. It can be used directly by Kubernetes.
- Containerd 1.1 is production ready.
- Containerd 1.1 has good performance in terms of pod startup latency and system resource utilization.
- crictl is the CLI tool to talk with containerd 1.1 and other CRI-conformant container runtimes for node troubleshooting.
- The next stable release of Docker CE will include containerd 1.1. Users have the option to continue using Docker for use cases not specific to Kubernetes, and configure Kubernetes to use the same underlying containerd that comes with Docker.
We’d like to thank all the contributors from Google, IBM, Docker, ZTE, ZJU and many other individuals who made this happen!
For a detailed list of changes in the containerd 1.1 release, please see the release notes here: https://github.com/containerd/containerd/releases/tag/v1.1.0
To setup a Kubernetes cluster using containerd as the container runtime:
- For a production quality cluster on GCE brought up with kube-up.sh, see here.
- For a multi-node cluster installer and bring up steps using ansible and kubeadm, see here.
- For creating a cluster from scratch on Google Cloud, see Kubernetes the Hard Way.
- For a custom installation from release tarball, see here.
- To install using LinuxKit on a local VM, see here.
The containerd CRI plugin is an open source github project within containerd https://github.com/containerd/cri. Any contributions in terms of ideas, issues, and/or fixes are welcome. The getting started guide for developers is a good place to start for contributors.
The project is developed and maintained jointly by members of the Kubernetes SIG-Node community and the containerd community. We’d love to hear feedback from you. To join the communities:
- sig-node community site
- Slack:
- #sig-node channel in kubernetes.slack.com
- #containerd channel in https://dockr.ly/community
- Mailing List: https://groups.google.com/forum/#!forum/kubernetes-sig-node