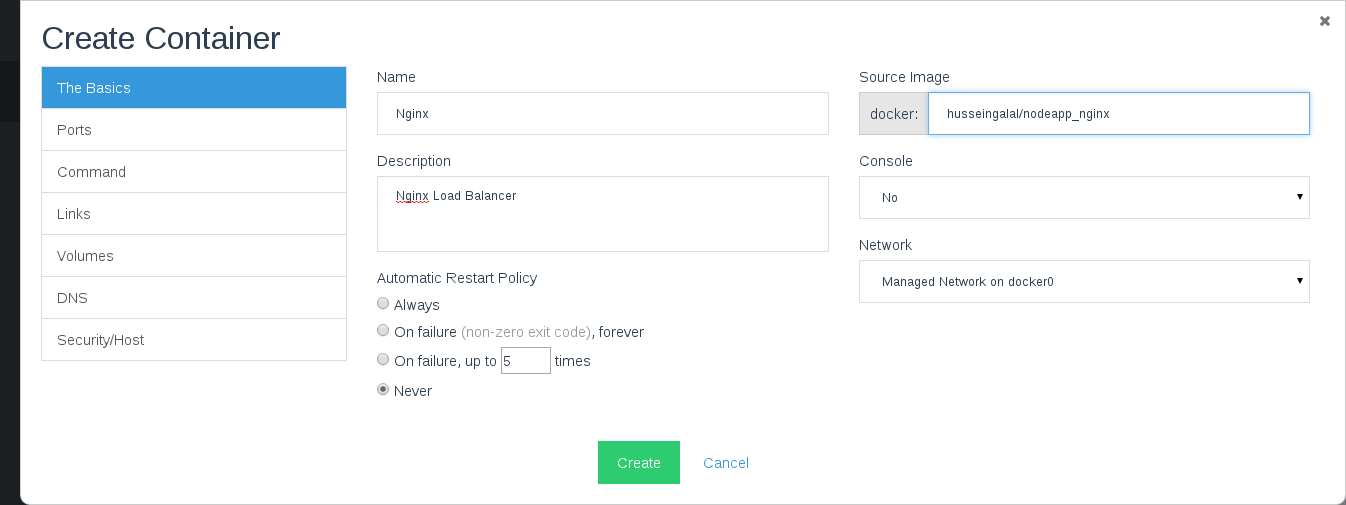
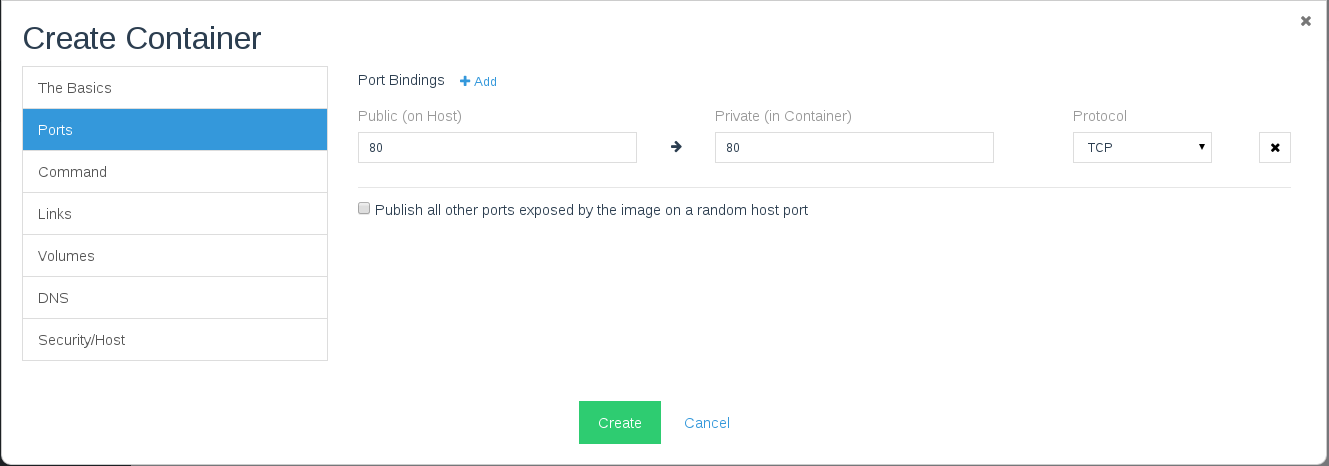
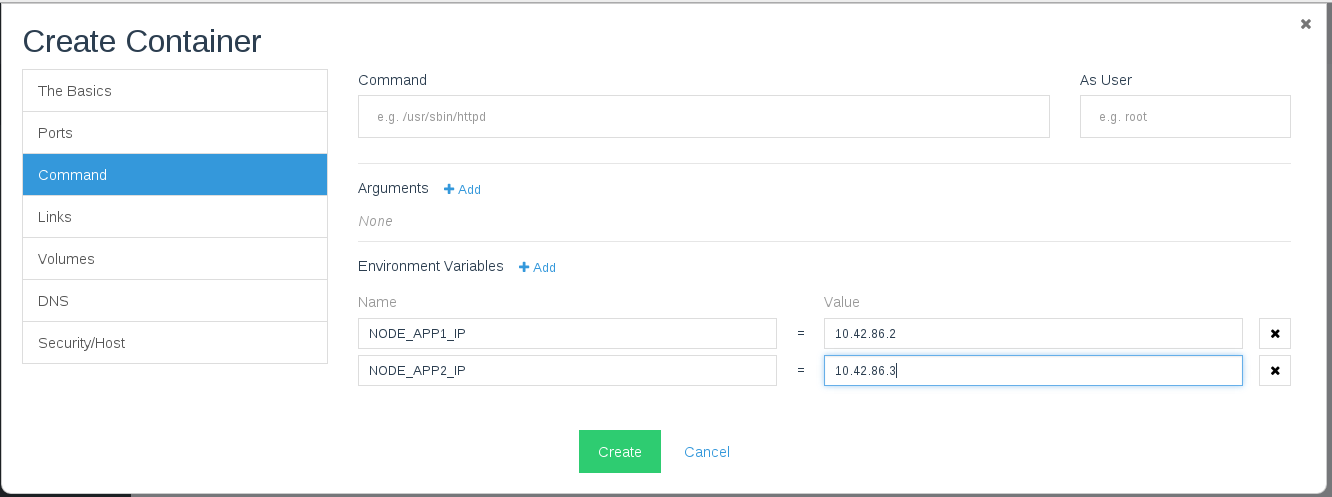
A Detailed Overview of Rancher’s Architecture
This newly-updated, in-depth guidebook provides a detailed overview of the features and functionality of the new Rancher: an open-source enterprise Kubernetes platform.
Get the eBook
Update (October 2017): Gord Sissons revisited this topic and compared
the top 10 container-monitoring solutions for Rancher in a recent blog
post.
*Update (October 2016): Our October online meetup demonstrated and
compared Sysdig, Datadog, and Prometheus in one go. Check
out
the recording. *
As Docker is used for larger deployments it becomes more important to
get visibility into the status and health of docker environments. In
this article, I aim to go over some of the common tools used to monitor
containers. I will be evaluating these tools based on the following
criteria:
- ease of deployment,
- level of detail of information presented,
- level of aggregation of information from entire deployment,
- ability to raise alerts from the data,
- ability to monitor non-docker resources, and
- cost. This list is by no means comprehensive however I have tried to highlight the most common tools and tools that optimize our six evaluation criteria.
A Detailed Overview of Rancher’s Architecture
This newly-updated, in-depth guidebook provides a detailed overview of the features and functionality of the new Rancher: an open-source enterprise Kubernetes platform.
Get the eBook
Docker Stats
All commands in this article have been specifically tested on
a RancherOS instance running on Amazon Web Services EC2. However, all
tools presented today should be usable on any Docker deployment.
The first tool I will talk about is Docker itself, yes you may not be
aware that docker client already provides a rudimentary command line
tool to inspect containers’ resource consumption. To look at the
container stats run docker stats with the name(s) of the running
container(s) for which you would like to see stats. This will present
the CPU utilization for each container, the memory used and total memory
available to the container. Note that if you have not limited memory for
containers this command will post total memory of your host. This does
not mean each of your container has access to that much memory. In
addition you will also be able to see total data sent and received over
the network by the container.
$ docker stats determined_shockley determined_wozniak prickly_hypatia
CONTAINER CPU % MEM USAGE/LIMIT MEM % NET I/O
determined_shockley 0.00% 884 KiB/1.961 GiB 0.04% 648 B/648 B
determined_wozniak 0.00% 1.723 MiB/1.961 GiB 0.09% 1.266 KiB/648 B
prickly_hypatia 0.00% 740 KiB/1.961 GiB 0.04% 1.898 KiB/648 B
For a more detailed look at container stats you may also use the Docker
Remote API via netcat (See below). Send an http get request for
/containers/[CONTAINER_NAME]/stats where CONTAINER_NAME is name of
the container for which you want to see stats. You can see an example of
the complete response for a container stats request
here. This
will present details of the metrics shown above for example you will get
details of caches, swap space and other details about memory. You may
want to peruse the Run
Metrics section of the
Docker documentation to get an idea of what the metrics mean.
echo -e “GET /containers/[CONTAINER_NAME]/stats HTTP/1.0rn” | nc -U /var/run/docker.sock
Score Card:
- Easy of deployment: *****
- Level of detail: *****
- Level of aggregation: none
- Ability to raise alerts: none
- Ability to monitor non-docker resources: none
- Cost: Free
CAdvisor
The docker stats command and the remote API are useful for getting
information on the command line, however, if you would like to access
the information in a graphical interface you will need a tool such as
CAdvisor. CAdvisor provides a
visual representation of the data shown by the docker stats command
earlier. Run the docker command below and go to
http://<your-hostname>:8080/ in the browser of your choice to see
the CAdvisor interface. You will be shown graphs for overall CPU usage,
Memory usage, Network throughput and disk space utilization. You can
then drill down into the usage statistics for a specific container by
clicking the Docker Containers link at the top of the page and then
selecting the container of your choice. In addition to these statistics
CAdvisor also shows the limits, if any, that are placed on container,
using the Isolation section.
docker run
–volume=/:/rootfs:ro
–volume=/var/run:/var/run:rw
–volume=/sys:/sys:ro
–volume=/var/lib/docker/:/var/lib/docker:ro
–publish=8080:8080
–detach=true
–name=cadvisor
google/cadvisor:latest

CAdvisor is a useful tool that is trivially easy to setup, it saves us
from having to ssh into the server to look at resource consumption and
also produces graphs for us. In addition the pressure gauges provide a
quick overview of when a your cluster needs additional resources.
Furthermore, unlike other options in this article CAdvisor is free as it
is open source and also it runs on hardware already provisioned for your
cluster, other than some processing resources there is no additional
cost of running CAdvisor. However, it has it limitations; it can only
monitor one docker host and hence if you have a multi-node deployment
your stats will be disjoint and spread though out your cluster. Note
that you can use
heapster to monitor
multiple nodes if you are running Kubernetes. The data in the charts is
a moving window of one minute only and there is no way to look at longer
term trends. There is no mechanism to kick-off alerting if the resource
usage is at dangerous levels. If you currently do not have any
visibility in to the resource consumption of your docker node/cluster
then CAdvisor is a good first step into container monitoring however, if
you intend to run any critical tasks on your containers a more robust
tool or approach is needed. Note that
Rancher runs CAdvisor on
each connected host, and exposes a limited set of stats through the UI,
and all of the system stats through the API.
Score Card (Ignoring heapster because only supported on Kubernetes):
- Easy of deployment: *****
- Level of detail: **
- Level of aggregation: *
- Ability to raise alerts: none
- Ability to monitor non-docker resources: none
- Cost: Free
Scout
The next approach for docker monitoring is Scout and it addresses
several of limitations of CAdvisor. Scout is a hosted monitoring service
which can aggregate metrics from many hosts and containers and present
the data over longer time-scales. It can also create alerts based on
those metrics. The first step to getting scout running is to sign up
for a Scout account at https://scoutapp.com/, the free trial account
should be suitable for testing out integration. Once you have created
your account and logged in, click on your account name in the top right
corner and then Account Basics and take note of your Account Key as
you will need this to send metrics from our docker server.
 Now
Now
on your host, create a file called scoutd.yml and copy the following
text into the the file, replacing the account_key with the key you
took note of earlier. You can specify any values that make sense for the
host, display_name, environment and roles properties. These will be
used to separate out the metrics when they are presented in the scout
dashboard. I am assuming an array of web-servers is run on docker so
will use the values shown below.
# account_key is the only required value
account_key: YOUR_ACCOUNT_KEY
hostname: web01-host
display_name: web01
environment: production
roles: web
You can now bring up your scout agent with the scout configuration file
by using the docker scout plugin.
docker run -d –name scout-agent
-v /proc:/host/proc:ro
-v /etc/mtab:/host/etc/mtab:ro
-v /var/run/docker.sock:/host/var/run/docker.sock:ro
-v `pwd`/scoutd.yml:/etc/scout/scoutd.yml
-v /sys/fs/cgroup/:/host/sys/fs/cgroup/
–net=host –privileged
soutapp/docker-scout
Now go back to the Scout web view and you should see an entry for your
agent which will be keyed by the display_name parameter (web01) that
you specified in your scoutd.yml earlier.
 If
If
you click the display name it will display detailed metrics for the
host. This includes the process count, CPU usage and memory utilization
for everything running on your host. Note these are not limited to
processes running inside docker.

To add docker monitoring to your servers click the Roles tab and then
select All Servers. Now click the + Plugin Template Button and then
Docker Monitor from the following screen to load the details view.
Once you have the details view up select Install Plugin to add the
plugin to your hosts. In the following screen give a name to the plugin
installation and specify which containers you want to monitor. If you
leave the field blank the plugin will monitor all of the containers on
the host. Click complete installation and after a minute or so you can
go to [Server Name] > Plugins to see details from the docker monitor
plugin. The plugin shows the CPU usage, memory usage network throughput
and the number of containers for each host.

 If
If
you click on any of the graphs you can pull a detailed view of the
metrics and this view allows you to see the trends in the metric values
across a longer time span. This view also allows you to filter the
metrics based on environment and server role. In addition you can create
“Triggers” or alerts to send emails to you if metrics go above or
below a configured threshold. This allows you to setup automated alerts
to notify you if for example some of your containers die and the
container count falls below a certain number. You can also setup alerts
for average CPU utilization so if for example if your containers are
running hot you will get an alert and you can launch more add more hosts
to your docker cluster. To create a trigger select  Roles
Roles
> All Servers from the top menu and then docker monitor from the
plugins section. Then select triggers from the Plugin template
Administration menu on the right hand side of the screen. You should
now see an option to ”Add a Trigger” which will apply to the entire
deployment. Below is an example of a trigger which will send out an
alert if the number of containers in the deployment falls below 3. The
alert was created for “All Servers” however you could tag your hosts
with different roles using the scoutd.yml created on the server. Using
the roles you can apply triggers to a sub-set of the servers on your
deployment. For example you could setup an alert for when the number of
containers on your web nodes falls below a certain number. Even with the
role based triggers I still feel that Scout alerting could be better.
This is because many docker deployments have heterogeneous containers on
the same host. In such a scenario it would be impossible to setup
triggers for specific types of containers as roles are applied to all
containers on the host.

Another advantage of using Scout over CAdvisor is that it has a large
set of plugins which can pull in
other data about your deployment in addition to docker information. This
allows Scout to be your one stop monitoring system instead of having a
different monitoring system for various resources in your system.
One drawback of Scout is that it does not present detailed information
about individual containers on each host like CAdvisor can. This is
problematic, if your are running heterogeneous containers on the same
server. For example if you want a trigger to alert you about issues in
your web containers but not about your Jenkins containers Scout will not
be able to support that use case. Despite the drawbacks Scout is a
significantly more useful tool for monitoring your docker deployments.
However this does come at a cost, ten dollars per monitored host. The
cost could be a factor if you are running a large deployment with many
hosts.
Score Card:
- Easy of deployment: ****
- Level of detail: **
- Level of aggregation: ***
- Ability to raise alerts: ***
- Ability to monitor non-docker resources: Supported
- Cost: $10 / host
Data Dog
From Scout lets move to another monitoring service, DataDog, which
addresses several of the short-comings of Scout as well as all of the
limitations of CAdvisor. To get started with DataDog, first sign up for
a DataDog account at https://www.datadoghq.com/. Once you are signed
into your account you will be presented with list of supported
integrations with instructions for each type. Select docker from the
list and you will be given a docker run command (show below) to copy
into your host. The command will have your API key preconfigured and
hence can be run the command as listed. After about 45 seconds your
agent will start reporting metrics to the DataDog system.
docker run -d –privileged –name dd-agent
-h `hostname`
-v /var/run/docker.sock:/var/run/docker.sock
-v /proc/mounts:/host/proc/mounts:ro
-v /sys/fs/cgroup/:/host/sys/fs/cgroup:ro
-e API_KEY=YOUR_API_KEY datadog/docker-dd-agent
Now that your containers are connected you can go to the Events tab in
the DataDog web console and see all events pertaining to your cluster.
All container launches and terminations will be part of this event
stream.

You can also click the Dashboards tab and hit create dashboards to
aggregate metrics across your entire cluster. Datadog collects metrics
about CPU usage, memory and I/O for all containers running in the
system. In addition you get counts of running and stopped containers as
well as counts of docker images. The dashboard view allows you to create
graphs for any metric or set of metrics across the entire deployment or
grouped by host or container image. For example the graph below shows
the number of running containers broken down by the image type, I am
running 9 ubuntu:14.04 containers in my cluster at the moment.

You could also split the same data by Hosts, as the second graph shows,
7 of the containers are running on my Rancher host and the remaining
ones on my local laptop.

Data Dog also supports alerting using a feature called *Monitors. *A
monitor is DataDog’s equivalent to a Scout trigger and allows you to
define thresholds for various metrics. DataDog’s alerting system is a
lot more flexible and detailed then Scout’s. The example below shows
how to specify that you are concerned about Ubuntu containers
terminating hence you would monitor the docker.containers.running metric
for containers created from the ubuntu:14.04 docker image.

Then specify the alert conditions to say that if there are fewer than
ten ubuntu containers in our deployment (on average) for the last 5
minutes, you would like to be alerted. Although not shown here you will
also be asked to specify the text of the message which is sent out when
this alert is triggered as well as the target audience for this alert.
In the current example I am using a simple absolute threshold. You can
also specify a delta based alert which triggers if say the avg stopped
container count was four over the last five minutes raise an alert.

Lastly, using the Metrics Explorer tab you can make ad-hoc
aggregations over your metrics to help debug issues or extract specific
information from your data. This view allows your to graph any metric
over a slice based on container image or host. You may combine output
into a single graph or generate a set of graphs by grouping across
images or hosts.

DataDog is a significant improvement over scout in terms feature set,
easy of use and user friendly design. However this level of polish comes
with additional cost as each DataDog agent costs $15.
Score Card:
- Easy of deployment: *****
- Level of detail: *****
- Level of aggregation: *****
- Ability to raise alerts: Supported
- Ability to monitor non-docker resources: *****
- Cost: $15 /
host
Sensu Monitoring Framework
Scout and Datadog provide centralized monitoring and alerting however
both are hosted services that can get expensive for large deployments.
If you need a self-hosted, centralized metrics service, you may
consider the sensu open source monitoring
framework. To run the Sensu server you can use
the hiroakis/docker-sensu-server
container. This container installs sensu-server, the uchiwa web
interface, redis, rabbitmq-server, and the sensu-api. Unfortunately
sensu does not have any docker support out of the box. However, using
the plugin system you can configure support for both container metrics
as well as status checks.
Before launch your sensu server container you must define a check that
you can load into the server. Create a file called check-docker.json
and add the following contents into the file. In this file you are
telling the Sensu server to run a script called load-docker-metrics.sh
every ten seconds on all clients which are subscribed to the docker tag.
You will define this script a little later.
{
“checks”: {
“load_docker_metrics”: {
“type”: “metric”,
“command”: “load-docker-metrics.sh”,
“subscribers”: [
“docker”
],
“interval”: 10
}
}
}
Now you can run the sensu server docker container with our check
configuration file using the command below. Once you run the command you
should be able to launch the uchiwa dashboard at
http://YOUR_SERVER_IP:3000 in your browser.
docker run -d –name sensu-server
-p 3000:3000
-p 4567:4567
-p 5671:5671
-p 15672:15672
-v $PWD/check-docker.json:/etc/sensu/conf.d/check-docker.json
hiroakis/docker-sensu-server
Now that the sensu server is up you can launch sensu clients on each of
the hosts running our docker containers. You told the server that the
containers will have a script called load-docker-metrics.sh so lets
create the script and insert it into our client containers. Create the
file and add the text shown below into the file, replacing HOST_NAME
with a logical name for your host . The script below is using the
Docker Remote
APIto
pull in the meta data for running containers, all containers and all
images on the host. It then prints the values out using sensu’s key
value notation. The sensu server will read the output values from the
STDOUT and collect those metrics. This example only pulls these three
values but you could make the script as detailed as required. Note that
you could also add multiple check scripts such as thos, as long as you
reference them in the server configuration file you created earlier. You
can also define that you want the check to fail if the number of running
containers ever falls below three. You can make a check fail by
returning a non-zero value from the check script.
#!/bin/bash
set -e
# Count all running containers
running_containers=$(echo -e “GET /containers/json HTTP/1.0rn” | nc -U /var/run/docker.sock
| tail -n +5
| python -m json.tool
| grep “Id”
| wc -l)
# Count all containers
total_containers=$(echo -e “GET /containers/json?all=1 HTTP/1.0rn” | nc -U /var/run/docker.sock
| tail -n +5
| python -m json.tool
| grep “Id”
| wc -l)
# Count all images
total_images=$(echo -e “GET /images/json HTTP/1.0rn” | nc -U /var/run/docker.sock
| tail -n +5
| python -m json.tool
| grep “Id”
| wc -l)
echo “docker.HOST_NAME.running_containers $”
echo “docker.HOST_NAME.total_containers $”
echo “docker.HOST_NAME.total_images $”
if [ $ -lt 3 ]; then
exit 1;
fi
Now that you have defined your load docker metrics check you need to to
start the sensu client using the
usman/sensu-client
container I defined for this purpose. You can use the command shown
below to launch sensu client. Note that the container must run as
privileged in order to be able to access unix sockets, it must have the
docker socket mounted in as a volume as well as the
load-docker-metrics.sh script you defined above. Make sure the
load-docker-metrics.sh script is marked as executable in your host
machine as the permissions carry through into the container. The
container also takes in SENSU_SERVER_IP, RABIT_MQ_USER,
RABIT_MQ_PASSWORD, CLIENT_NAME and CLIENT_IP as parameters, please
specify the value of these parameters for your setup. The default values
for the RABIT_MQ_USER RABIT_MQ_PASSWORD are sensu and password.
docker run -d –name sensu-client –privileged
-v $PWD/load-docker-metrics.sh:/etc/sensu/plugins/load-docker-metrics.sh
-v /var/run/docker.sock:/var/run/docker.sock
usman/sensu-client SENSU_SERVER_IP RABIT_MQ_USER RABIT_MQ_PASSWORD CLIENT_NAME CLIENT_IP

A few seconds after running this command you should see the client
count increase to 1 in the uchiwa dashboard. If you click the clients
icon you should see a list of your clients including the client that you
just added. I named my client client-1 and specified the host IP as
192.168.1.1.

If you click on the client name your should get further details of the
checks. You can see that the load_docker_metrics check was run at
10:22 on the 28th of March.
 If
If
you Click on the check name you can see further details of check runs.
The zeros indicate that there were no errors, if the script had failed
(if for example your docker Daemon dies) you would see an error code
(non zero) value. Although it is not covered this in the current article
you can also setup sensu to alert you when these checks fail using
Handlers. Furthermore,
uchiwa only shows the values of checks and not the metrics collected.
Note that sensu does not store the collected metrics, they have to be
forwarded to a time series database such as InfluxDB or Graphite. This
is also done through Handlers. Please find details of how to configure
metric forwarding to graphite
here.

Sensu ticks all the boxes in our evaluation criteria; you can collect as
much detail about our docker containers and hosts as ypu want. In
addition you are able to aggregate the values of all of out hosts in one
place and raise alerts over those checks. The alerting is not as
advanced as DataDog or Scout, as you are only able to alert on checks
failing on individual hosts. However, the big drawback of Sensu is
difficulty of deployment. Although I have automated many steps in the
deployment using docker containers, Sensu remains a complicated system
requiring us to install, launch and maintain separate processes for
Redis, RabitMQ, Sensu API, uchiwa and Sensu Core. Furthermore, you would
require still more tools such as Graphite to present metric values and a
production deployment would require customizing the containers I have
used today for secure passwords and custom ssl certificates. In addition
were you to add more checks after launching the container you would have
to restart the Sensu server as that is the only way for it start
collecting new metrics. For these reasons I rate Sensu fairly low for
ease of deployment.
Easy of deployment: * Level of detail: **** Level of aggregation:
**** Ability to raise alerts: Supported but limited Ability to
monitor non-docker resources: ***** Cost: $Free
I also evaluated two other monitoring services, Prometheus and Sysdig
Cloud in a
second article,
and have included them in this post for simplicity.
Prometheus
First lets take a look at Prometheus; it is a self-hosted set of tools
which collectively provide metrics storage, aggregation, visualization
and alerting. Most of the tools and services we have looked at so far
have been push based, i.e. agents on the monitored servers talk to a
central server (or set of servers) and send out their metrics.
Prometheus on the other hand is a pull based server which expects
monitored servers to provide a web interface from which it can scrape
data. There are several exporters
available for
Prometheus which will capture metrics and then expose them over http for
Prometheus to scrape. In addition there are
libraries which
can be used to create custom exporters. As we are concerned with
monitoring docker containers we will use the
container_exporter
capture metrics. Use the command shown below to bring up the
container-exporter docker container and browse to
http://MONITORED_SERVER_IP:9104/metrics to see the metrics it has
collected for you. You should launch exporters on all servers in your
deployment. Keep track of the respective *MONITORED_SERVER_IP*s as we
will be using them later in the configuration for Prometheus.
docker run -p 9104:9104 -v /sys/fs/cgroup:/cgroup -v /var/run/docker.sock:/var/run/docker.sock prom/container-exporter
Once we have got all our exporters running we are can launch Prometheus
server. However, before we do we need to create a configuration file for
Prometheus that tells the server where to scrape the metrics from.
Create a file called prometheus.conf and then add the following text
inside it.
global:
scrape_interval: 15s
evaluation_interval: 15s
labels:
monitor: exporter-metrics
rule_files:
scrape_configs:
– job_name: prometheus
scrape_interval: 5s
target_groups:
# These endpoints are scraped via HTTP.
– targets: [‘localhost:9090′,’MONITORED_SERVER_IP:9104’]
In this file there are two sections, global and job(s). In the global
section we set defaults for configuration properties such as data
collection interval (scrape_interval). We can also add labels which
will be appended to all metrics. In the jobs section we can define one
or more jobs that each have a name, an optional override scraping
interval as well as one or more targets from which to scrape metrics. We
are adding two targets, one is the Prometheus server itself and the
second is the container-exporter we setup earlier. If you setup more
than one exporter your can setup additional targets to pull metrics from
all of them. Note that the job name is available as a label on the
metric hence you may want to setup separate jobs for your various types
of servers. Now that we have a configuration file we can start a
Prometheus server using the
prom/prometheus
docker image.
docker run -d –name prometheus-server -p 9090:9090 -v $PWD/prometheus.conf:/prometheus.conf prom/prometheus -config.file=/prometheus.conf
After launching the container, Prometheus server should be available in
your browser on the port 9090 in a few moments. Select Graph from the
top menu and select a metric from the drop down box to view its latest
value. You can also write queries in the expression box which can find
matching metrics. Queries take the form
METRIC_NAME. You can find more
details of the query syntax here.

We are able to drill down into the data using queries to filter out data
from specific server types (jobs) and containers. All metrics from
containers are labeled with the image name, container name and the host
on which the container is running. Since metric names do not encompass
container or server name we are able to easily aggregate data across
our deployment. For example we can filter for the
container_memory_usage_bytes to get
information about the memory usage of all ubuntu containers in our
deployment. Using the built in functions we can also aggregate the
resulting set of of metrics. For example
average_over_time(container_memory_usage_bytes
[5m]) will show the memory used by ubuntu
containers, averaged over the last five minutes. Once you are happy with
with a query you can click over to the Graph tab and see the variation
of the metric over time.

Temporary graphs are great for ad-hoc investigations but you also need
to have persistent graphs for dashboards. For this you can use the
Prometheus Dashboard
Builder. To launch
Prometheus Dashboard Builder you need access to an SQL database which
you can create using the official MySQL Docker
image. The command to launch
the MySQL container is shown below, note that you may select any value
for database name, user name, user password and root password however
keep track of these values as they will be needed later.
docker run -p 3306:3306 –name promdash-mysql
-e MYSQL_DATABASE=<database-name>
-e MYSQL_USER=<database-user>
-e MYSQL_PASSWORD=<user-password>
-e MYSQL_ROOT_PASSWORD=<root-password>
-d mysql
Once you have the database setup, use the rake installation inside the
promdash container to initialize the database. You can then run the
Dashboard builder by running the same container. The command to
initialize the database and bring up the Prometheus Dashboard Builder
are shown below.
# Initialize Database
docker run –rm -it –link promdash-mysql:db
-e DATABASE_URL=mysql2://<database-user>:<user-password>@db:3306/<database-name> prom/promdash ./bin/rake db:migrate
# Run Dashboard
docker run -d –link promdash-mysql:db -p 3000:3000 –name prometheus-dash
-e DATABASE_URL=mysql2://<database-user>:<user-password>@db:3306/<database-name> prom/promdash

Once your container is running you can browse to port 3000 and load up
the dashboard builder UI. In the UI you need to click Servers in the
top menu and New Server to add your Prometheus Server as a datasource
for the dashboard builder. Add http://PROMETHEUS_SERVER_IP:9090 to
the list of servers and hit Create Server.
Now click Dashboards in the top menu, here you can create
Directories (Groups of Dashboards) and Dashboards. For example we
created a directory for Web Nodes and one for Database Nodes and in each
we create a dashboard as shown below.

Once you have created a dashboard you can add metrics by mousing over
the title bar of a graph and selecting the data sources icon (Three
Horizontal lines with an addition sign following them ). You can then
select the server which you added earlier, and a query expression which
you tested in the Prometheus Server UI. You can add multiple data
sources into the same graph in order to see a comparative view.

You can add multiple graphs (each with possibly multiple data sources)
by clicking the Add Graph button. In addition you may select the
time range over which your dashboard displays data as well as a refresh
interval for auto-loading data. The dashboard is not as polished as the
ones from Scout and DataDog, for example there is no easy way to explore
metrics or build a query in the dashboard view. Since the dashboard runs
independently of the Prometheus server we can’t ‘pin’ graphs
generated in the Prometheus server into a dashboard. Furthermore several
times we noticed that the UI would not update based on selected data
until we refreshed the page. However, despite its issues the dashboard
is feature competitive with DataDog and because Prometheus is under
heavy development, we expect the bugs to be resolved over time. In
comparison to other self-hosted solutions Prometheus is a lot more user
friendly than Sensu and allows you present metric data as graphs without
using third party visualizations. It also is able to provide much better
analytical capabilities than CAdvisor.
Prometheus also has the ability to apply alerting rules over the input
data and displaying those on the UI. However, to be able to do something
useful with alerts such send emails or notify
pagerduty we need to run the the Alert
Manager. To run
the Alert Manager you first need to create a configuration file. Create
a file called alertmanager.conf and add the following text into it:
notification_config {
name: “ubuntu_notification”
pagerduty_config {
service_key: “<PAGER_DUTY_API_KEY>”
}
email_config {
email: “<TARGET_EMAIL_ADDRESS>”
}
hipchat_config {
auth_token: “<HIPCHAT_AUTH_TOKEN>”
room_id: 123456
}
}
aggregation_rule {
filter {
name_re: “image”
value_re: “ubuntu:14.04”
}
repeat_rate_seconds: 300
notification_config_name: “ubuntu_notification”
}
In this configuration we are creating a notification configuration
called ubuntu_notification, which specifies that alerts must go to
the PagerDuty, Email and HipChat. We need to specify the relevant API
keys and/or access tokens for the HipChat and PagerDutyNotifications to
work. We are also specifying that the alert configuration should only
apply to alerts on metrics where the label image has the value
ubuntu:14.04. We specify that a triggered alert should not retrigger
for at least 300 seconds after the first alert is raised. We can bring
up the Alert Manager using the docker image by volume mounting our
configuration file into the container using the command shown below.
docker run -d -p 9093:9093 -v $PWD:/alertmanager prom/alertmanager -logtostderr -config.file=/alertmanager/alertmanager.conf
Once the container is running you should be able to point your browser
to port 9093 and load up the Alarm Manger UI. You will be able to see
all the alerts raised here, you can ‘silence’ them or delete them once
the issue is resolved. In addition to setting up the Alert Manager we
also need to create a few alerts. Add rule_file:
“/prometheus.rules” in a new line into the global section of the
prometheus.conf file you created earlier. This line tells Prometheus
to look for alerting rules in the prometheus.rules file. We now need
to create the rules file and load it into our server container. To do so
create a file called prometheus.rules in the same directory where you
created prometheus.conf. and add the following text to it:
ALERT HighMemoryAlert
IF container_memory_usage_bytes > 1000000000
FOR 1m
WITH {}
SUMMARY “High Memory usage for Ubuntu container”
DESCRIPTION “High Memory usage for Ubuntu container on {{$labels.instance}} for container {{$labels.name}} (current value: {{$value}})”
In this configuration we are telling Prometheus to raise an alert called
HighMemoryAlert if the container_memory_usage_bytes metric
for containers using the Ubuntu:14.04 image goes above 1 GB for 1
minute. The summary and the description of the alerts is also specified
in the rules file. Both of these fields can contain placeholders for
label values which are replaced by Prometheus. For example our
description will specify the server instance (IP) and the container name
for metric raising the alert. After launching the Alert Manager and
defining your Alert rules, you will need to re-run your Prometheus
server with new parameters. The commands to do so are below:
# stop and remove current container
docker stop prometheus-server && docker rm prometheus-server
# start new container
docker run -d –name prometheus-server -p 9090:9090
-v $PWD/prometheus.conf:/prometheus.conf
-v $PWD/prometheus.rules:/prometheus.rules
prom/prometheus
-config.file=/prometheus.conf
-alertmanager.url=http://ALERT_MANAGER_IP:9093
Once the Prometheus Server is up again you can click Alerts in the top
menu of the Prometheus Server UI to bring up a list of alerts and their
statuses. If and when an alert is fired you will also be able to see it
in the Alert Manager UI and any external service defined in the
alertmanager.conf file.

Collectively the Prometheus tool-set’s feature set is on par with
DataDog which has been our best rated Monitoring tool so far. Prometheus
uses a very simple format for input data and can ingest from any web
endpoint which presents the data. Therefore we can monitor more or less
any resource with Prometheus, and there are already several libraries
defined to monitor common resources. Where Prometheus is lacking is in
level of polish and ease of deployment. The fact that all components are
dockerized is a major plus however, we had to launch 4 different
containers each with their own configuration files to support the
Prometheus server. The project is also lacking detailed, comprehensive
documentation for these various components. However, in caparison to
self-hosted services such as CAdvisor and Sensu, Prometheus is a much
better toolset. It is significantly easier setup than sensu and has the
ability to provide visualization of metrics without third party tools.
It is able has much more detailed metrics than CAdvisor and is also able
to monitor non-docker resources. The choice of using pull based metric
aggregation rather than push is less than ideal as you would have to
restart your server when adding new data sources. This could get
cumbersome in a dynamic environment such as cloud based deployments.
Prometheus does offer the Push
Gateway to bridge the
disconnect. However, running yet another service will add to the
complexity of the setup. For these reasons I still think DataDog is
probably easier for most users, however, with some polish and better
packaging Prometheus could be a very compelling alternative, and out of
self-hosted solutions Prometheus is my pick.
Score Card:
- Easy of deployment: **
- Level of detail: *****
- Level of aggregation: *****
- Ability to raise alerts: ****
- Ability to monitor non-docker resources: Supported
- Cost: Free
Sysdig Cloud
Sysdig cloud is a hosted service that provides metrics storage,
aggregation, visualization and alerting. To get started with sysdig sign
up for a trial account at https://app.sysdigcloud.com. and complete
the registration form. Once you complete the registration form and log
in to the account, you will be asked to Setup your Environment and be
given a curl command similar to the shown below. Your command will have
your own secret key after the -s switch. You can run this command on the
host running docker and which you need to monitor. Note that you should
replace the [TAGS] place holder with tags to group your metrics. The
tags are in the format TAG_NAME:VALUE so you may want to add a tag
role:web or deployment:production. You may also use the containerized
sysdig agent.
# Host install of sysdig agent
curl -s https://s3.amazonaws.com/download.draios.com/stable/install-agent | sudo bash -s 12345678-1234-1234-1234-123456789abc [TAGS]
# Docker based sysdig agent
docker run –name sysdig-agent –privileged –net host
-e ACCESS_KEY=12345678-1234-1234-1234-123456789abc
-e TAGS=os:rancher
-v /var/run/docker.sock:/host/var/run/docker.sock
-v /dev:/host/dev -v /proc:/host/proc:ro
-v /boot:/host/boot:ro
-v /lib/modules:/host/lib/modules:ro
-v /usr:/host/usr:ro sysdig/agent
Even if you use docker you will still need to install Kernel headers in
the host OS. This goes against Docker’s philosophy of isolated micro
services. However, installing kernel headers is fairly benign.
Installing the headers and getting sysdig running is trivial if you are
using a mainstream kernel such us CentOS, Ubuntu or Debian. Even the
Amazon’s custom kernels are supported however RancherOS’s custom
kernel presented problems for sysdig as did the tinycore kernel. So be
warned if you would like to use Sysdig cloud on non-mainstream kernels
you may have to get your hands dirty with some system hacking.
After you run the agent you should see the Host in the Sysdig cloud
console in the Explore tab. Once you launch docker containers on the
host those will also be shown. You can see basic stats about the CPU
usage, memory consumption, network usage. The metrics are aggregated for
the host as well as broken down per container.
 By
By
selecting one of the hosts or containers you can get a whole host of
other metrics including everything provided by the docker stats API. Out
of all the systems we have seen so far sysdig certainly has the most
comprehensive set of metrics out of the box. You can also select from
several pre-configured dashboards which present a graphical or tabular
representation of your deployment.

You can see live metrics, by selecting Real-time Mode (Target Icon)
or select a window of time over which to average values. Furthermore,
you can also setup comparisons which will highlight the delta of current
values and values at a point in the past. For example the table below
shows values compared with those from ten minutes ago. If the CPU usage
is significantly higher than 10 minutes ago you may be experiencing load
spikes and need to scale out. The UI is at par with, if not better than
DataDog for identifying and exploring trends in the data.
In addition to exploring data on an ad-hoc basis you can also create
persistent dashboards. Simply click the pin icon on any graph in the
explore view and save it to a named dashboard. You can view all the
dashboards and their associated graphs by clicking the Dashboards
tab. You can also select the bell icon on any graph and create an
alert from the data. The Sysdig cloud supports detailed alerting
criteria and is again one of the best we have seen. The example below
shows an alert which triggers if the count of containers labeled web
falls below three on average for the last ten minutes. We are also
segmenting the data by the region tag, so there will be a separate
check for web nodes in North America and Europe. Lastly, we also specify
a Name, description and Severity for the alerts. You can control where
alerts go by going to Settings (Gear Icon) > Notifications and add
email addresses or SNS Topics to send alerts too. Note all alerts go to
all notification endpoints which may be problematic if you want to wake
up different people for different alerts.
I am very impressed with Sysdig cloud as it was trivially easy to setup,
provides detailed metrics with great visualization tools for real-time
and historical data. The requirement to install kernel headers on the
host OS is troublesome though and lack of documentation and support for
non-standard kernels could be problematic in some scenarios. The
alerting system in the Sysdig cloud is among the best we have seen so
far, however, the inability to target different email addresses for
different alerts is problematic. In a larger team for example you would
want to alert a different team for database issues vs web server issues.
Lastly, since it is in beta the pricing for Sysdig cloud is not easily
available. I have reached out to their sales team and will update this
article if and when they get back to me. If sysdig is price competitive
then Datadog has serious competition in the hosted service category.
Score Card:
- Easy of deployment: ***
- Level of detail: *****
- Level of aggregation: *****
- Ability to raise alerts: ****
- Ability to monitor non-docker resources: Supported
- Cost: Must Contact Support
Conclusion
Today’s article has covered several options for monitoring docker
containers, ranging from free options; docker stats, CAdvisor,
Prometheus or Sensu to paid services such as Scout, Sysdig Cloud and
DataDog. From my research so far DataDog seems to be the best-in-class
system for monitoring docker deployments. The setup was complete in
seconds with a one-line command, all hosts were reporting metrics in one
place, historical trends were apparent in the UI and Datadog supports
deep diving into metrics as well as alerting. However, at $15 per host
the system can get expensive for large deployments. For larger scale,
self-hosted deployments Sensu is able to fulfill most requirements
however the complexity in setting up and managing a Sensu cluster may be
prohibitive. Obviously, there are plenty of other self-hosted options,
such as Nagios or Icinga, which are similar to Sensu.
Hopefully this gives you an idea of some of the options for monitoring
containers available today. I am continuing to investigate other
options, including a more streamlined self-managed container monitoring
system using CollectD, Graphite or InfluxDB and Grafana. Stay tuned for
more details.
ADDITIONAL INFORMATION: After publishing this article I had some
suggestions to also evaluate Prometheus and Sysdig Cloud, two other very
good options for monitoring Docker. We’ve now included them in this
article, for ease of discovery. You can find the original second part
of my
posthere.
To learn more about monitoring and managing Docker, please join us for
our next Rancher online meetup.
Usman is a server and infrastructure engineer, with experience in
building large scale distributed services on top of various cloud
platforms. You can read more of his work at
techtraits.com, or follow him on twitter
@usman_ismailor
onGitHub.
Source