

After reading the O’Reilly book “Foundations for Architecting Data Solutions”, by Ted Malaska and Jonathan Seidman, I reflected on how I chose software/tools/solutions in the past and how I should choose them going forward.
As a bioinformatician you need to be able to quickly discern whether a publication/tool is really a major advancement or just marginally better. I’m not just talking about the newest single-cell RNA-seq technique or another file format, but for every problem case you have. Whether that be data visualization tools, presentation tools, distributed storage systems etc.
It’s not just about how useful the tool may be, it also depends on the quality of the documentation, how simple it is to install, where it sits in the open-source life cycle, etc.

Xkcd is funny but competing standards aren’t. Don’t believe me? Just look at how many pipeline tools exist!
When faced with so many options how can one choose the solutions that fit their need?
Why open source?
I’ve worked with a few licensed software solutions in the past; for example, BLAST2GO (plug: use dammit from Camille Scott instead!), Matlab, and an image stitching software called Autopano Giga (now defunct). One of my greatest frustrations was learning these tools only to later change roles and no longer have them available. As a consultant for the Department of Fisheries and Oceans the prohibitive cost of a Matlab was what pushed me over the edge into learning another high-level programming language — R. FWIW:
“[Matlab] They obfuscate their source code in many cases, meaning bugs are much harder to spot and impossible to edit ourselves without risking court action. Moreover, using Matlab for science results in paywalling our code. We are by definition making our computational science closed.” — excerpt from I Hate Matlab: How an IDE, a Language, and a Mentality Harm
Most companies eschew third party solutions or build their product as a hybrid of proprietary and open-source to keep their costs lower. For example, Amazon Web Services (AWS) offers it’s Simple Storage Service (Amazon S3) for a fee but is built upon open source software like Apache Hadoop. I’m not saying not to use AWS (or any other cloud provider) because sometimes you are constrained to having to; I actually used AWS for a project (transcriptome assembly of a coral species) with Docker. Currently I’m working with sensitive information that must be kept on-site, under lock-and-key, so alternative solutions are used.
Most of the newer big data platforms, and successful open-source projects began as internal projects at companies or universities for the first couple years before going through an external incubation phase. For example:
- LinkedIn — “Apache Kafka”
- University of California at Berkeley — “Apache Spark”
- Cloudera — “Impala”
- Yahoo! — “Apache Hadoop”
- Google — “Kubernetes”
- Facebook — “Apache Hive”
There are benefits to choosing open-source projects backed by solid sponsors with good reputation, solid devs, and track record of sponsoring successful projects. You can be fairly confident that these projects have a solid codebase, great documentation, received session time at conferences, and considerable public recognition (through blog posts and articles surrounding it).
When considering open-source solutions it’s also important to gauge where they are in the open-source life cycle. According to Malaska and Seidman, there are nine (potential) stages in the project life cycle based on the Garnter Hype Cycle; however, I think only a few are relevant to discuss here:
Which Cycle Should You Choose?

Don’t believe the hype
This stage of the cycle is referred to as the “curing cancer” stage. The hype at this stage is important for attracting committers and contributors but unless you’re looking to help out in a major way you should steer clear. Unless you’re trying to be on the cutting edge (risk tolerance), or take on an active role as a contributor, it’s best to wait 6–12 months before trying any new technology. By letting others hit walls first you’ll encounter fewer bugs and have access to better documentation and blog posts.
A broken promise is not a lie
After the “curing cancer” stage is the broken promises stage. At this point people are using the project and are finding issues or limitations. For example, a solution may not integrate nicely with other existing systems or there may be problems with scaleability. You should treat any open source project at this stage with cautious optimism.
Go for dependable solutions whenever possible
Projects in the hardening or enterprise stage have become mature technologies. The amount of commits will signal the level of investment in a project. Tthe type of commits tell a story, telling where the author(s) are trying to go with the code, revealing what they want to do by signalling interest in different features of the project. By now the initial excitement has died down and there is more demand for stability than new features. The initial development team may be working on other projects as it has developed a solid community — this is often a good sign of success of a project.
Obviously recent activity signals that the project is alive and maintained. Remember that there are many dead and abandoned projects living on Github. That being said, activity doesn’t always need to be very recent! One prolific, “Rockstar Dev”, put it this way:
Context-switching is expensive, so if I worked on many packages at the same time, I’d never get anything done. Instead, at any point in time, most of my packages are lying fallow, steadily accumulating issues and ideas for new feature. Once a critical mass has accumulated, I’ll spend a couple of days on the package. — Hadley Wickham
Eventually projects enter the decline stage and no one wants to adopt or contribute to a dead or dying project.
Can i trust you?

I use R mostly so let me talk about where a project is hosted for a few moments. Code is often hosted on Github, ROpenSci, Bioconductor or CRAN. The Comprehensive R Archive Network (CRAN) was the main repository for R packages.
“As R users, we are spoiled. Early in the history of R, Kurt Hornik and Friedrich Leisch built support for packages right into R, and started the Comprehensive R Archive Network (CRAN). And R and CRAN had a fantastic run with. Roughly twenty years later, we are looking at over 12,000 packages which can (generally) be installed with absolute ease and no suprises. No other (relevant) open source language has anything of comparable rigour and quality.” — excerpt from Dirk Eddelbuettel
On CRAN packages of almost any type are welcome (as long as strict policies are met) and packages are tested daily (on multiple systems). rOpenSci is the perfect antithesis of CRAN. CRAN can be notoriously opaque, inconsistent, and aloof. It cannot deal with the volume of automation of CRAN but markets itself in terms of quality.
For the field of Bioinformatics Bioconductor is where a package will end up. Projects that exist solely on Github should be viewed with more caution as they have no checklists or peer-review.
Let’s talk about dependencies (a loaded topic — no pun intended)
Installing dependencies sucks! How often have you installed one package only to have a boatload pulled-in? You should try and avoid packages with many (changing) packages as this will be prohibitive to establish if your work is correct (hence ensuring reproducibility) because dependencies are hard to manage risks.
“More dependencies means more edges between more nodes. Which eventually means more breakage.”
Proponents of the tinyverse tend to stay away from bloated dependencies, no one wants to spend time in hell!
If you’re a developer remember:
You can also include a badge for your repo showing the number of dependencies your package relies on
Transparency is good

When looking at projects on Github you should look for people/packages with many stars, watchers, forks, contributors, etc. These visible cues of community support indicate the community cares about a person, project, or action and that many others would benefit from it.
Remember that the amount of commits, issues and pull-requests (PRs) can be a signal of investment and commitment to a project. Are the issues and PRs being dealt with? The latter is literally an offer of code that is being ignored rather than accepted, rejected or commented upon.
By following the actions on code, you can determine who founded the project, what happened across different releases and make inferences about the structure of the project and collaborator roles (who had expertise on which pieces of the system). Linked commits and issues communicates the reasoning behind a change to the code.
You can also gauge community interest by looking at the number of meetups,and conferences (and their attendance levels) , or at email lists, user groups, community forums etc.
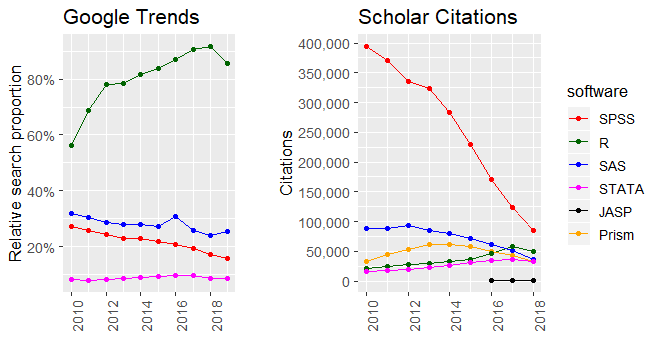
Google trends can also be a good measure of the level of interest in projects or technologies.
Things to look for

- Easy to install
- Easy to run
- Are there issues and PR raised
Is the owner taking care of them (fixing bugs, helping users, adding features)? or was it abandoned?
Does it list hardware requirements (RAM and disk size), example commands, toy data, example output, screenshots/recordit’s
- Continuous integration status
- Does it have a LICENSE
- Does it have a CONTRIBUTING doc
- Does it have tests
- Does it have a
Dockerfile - Does it have badges
For other things to look for see here and here.
Bench-marking
If you’re a software developer and considering incorporating one of a number of competing technologies you can perform internal benchmarks with your use cases and data.
If you’re using R there is different levels of magnification that a benchmark can provide. For a macro analysis (when computation is more intensive) you should use the rbenchmark package. For microscopic timing comparisons (e.g. nanoseconds elapsed) use the microbenchmark package
Sometimes other consortium’s will have already done the bench-marking for you (for example “The Assemblathon”) . Nonetheless, one should be aware of hidden, or motivated biases trying to make unfair comparisons (use cases for which one tool clearly has an advantage). Also understand that testers could have been making an honest attempt at a fair test but made misunderstandings which lead to invalid results. Therefore it’s important to perform your own internal benchmarking and hold others benchmarks to an open standard of repeatability and verification.
Final words
Ultimately choosing a software solution comes down to the requirements of your project (the timeline, budget, and so forth), how willing are you to be on the cutting-edge (risk tolerance), and how capable team-members will be able to master these solutions based on their skill levels (internal skill set). Then, test out the solutions before fully committing. This job can be given to the prototyper role on your team; the person who likes experimenting/investigating new software.