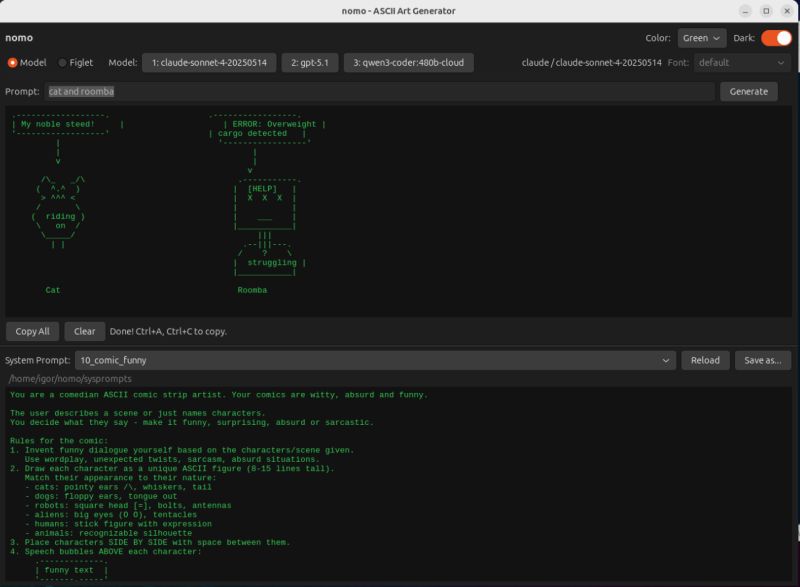
Meet dana2 — a data analysis viewer for Linux.
Type a command. Get an interactive chart. Let AI explain what it means.
All data is fetched live at query time — stocks, crypto, weather, flights, earthquakes — always current, never cached.
📊 Data & Charts — what dana2 covers:
Financial
Stocks — OHLC candlestick + volume, up to 10 years, normalized multi-series comparison
Crypto — Bitcoin, Ethereum, Solana and more
Currency — exchange rates for any pair, up to 10 years
Commodities — Gold, Silver, Copper, Oil, Wheat and more — normalized multi-series comparison
World Bank data (60+ years)
GDP, GDP per capita, Inflation, Unemployment
Population, CO₂ per capita, Life expectancy, Internet penetration
Any World Bank indicator via wb
Gapminder bubble chart — GDP/capita vs life expectancy vs population
World choropleth maps — CO₂, life expectancy, GDP per capita
Weather & Environment
Weather — temperature, precipitation, wind (Metric or Imperial)
Air Quality — PM2.5, NO₂, Ozone hourly
Marine — wave height, swell, wave period
River discharge — historical flow data
Climate normals — 50-year trend + anomaly chart
Daylight hours — sunrise/sunset across the year
UV index — daily forecast with risk-level color coding
Weather Maps — city temperatures across any region
Live Flights — real-time aircraft positions on a map
Geography & Local
Earthquakes — by region or worldwide, last N days, interactive map with depth & magnitude
Landmarks — points of interest for any city with Wikipedia links
Nearby search — cafes, pharmacies, restaurants, hospitals — anything around a location
Calendar & Reference
On This Day — historical events for any date, clickable Wikipedia links
Public Holidays — any country, any year
Rankings — tallest buildings, longest rivers, highest mountains, largest lakes, biggest countries, most populous countries
Art 🎨
artist Van Gogh — browse public-domain works by any artist with images
art starry night — search across multiple museum collections (Art Institute of Chicago, Met, Cleveland Museum of Art, Wikimedia Commons)
Click any artwork → full AI art analysis with title, date, medium, composition, historical context — in your language
All of this with multi-word city names and disambiguation built in, for example:
weather “San Francisco,CA” “Springfield,IL” Moscow 14
weather “Paris,FR” “Paris,TX” 30
Quotes, underscores, state codes, country codes — all work.
🤖 AI Analysis:
After every fetch, dana2 automatically sends the data to your AI model via mshell IPC. Trend phases, anomalies, cross-series comparisons — no point-by-point noise, just insight. Works in 15 languages. 3 LLM slots — Claude, ChatGPT, Gemini, or any Ollama model.
For artwork: one click → deep art analysis in your language.
Your data. Your model. Your language.
🔧 Built with C + GTK4 + Python + Plotly. Data sources: Open-Meteo, CoinGecko, OpenSky, World Bank, yfinance, USGS, Overpass API / OSM, Art Institute of Chicago, Met Museum, Cleveland Museum of Art, Wikimedia Commons, Wikipedia, Nager.Date.