In this guide I’ll set up a Kubernetes cluster with DigitalOcean’s new Kubernetes Engine using CLI tooling and then work out the cost of the cluster running a Cloud Native workload – OpenFaaS. OpenFaaS brings portable Serverless Functions to Kubernetes for any programming language.
Kubernetes is everywhere
Since James Governor from RedMonk declared that Kubernetes had won the container orchestration battle we’ve seen cloud and service providers scramble to ship their own managed Kubernetes services – to win mindshare and to get their share of the pie.
Kubernetes won – so now what? https://t.co/JeZwBEWNHy
— RedMonk (@redmonk) May 25, 2018
One of the earliest and most complete Kubernetes services is probably Google Kubernetes Engine (GKE), followed by a number of newer offerings like:
Kubernetes services coming soon:
Kubernetes engines
The point of a managed Kubernetes service or engine as I see it is to abstract away the management of servers and the day to day running of the cluster such as requesting, joining and configuring nodes. In some senses – Kubernetes delivered as a Service is a type of serverless and each product gives a varying level of control and visibility over the nodes provisioned.
For instance with VMware’s Cloud PKS you have no way to even see the server inventory and the cluster is sized dynamically based upon usage. spotinst released a product called Ocean last week which also focuses on hiding the visibility of the servers backing your workloads. The Azure team at Microsoft is combining their Azure Container Instances (ACI) with Virtual Kubelet to provide a “node-less” experience.
The areas I would score a Kubernetes Engine are around:
- Ease of use – what is the installation experience, bootstrap time and tooling like?
- Reliability – does it work and stand up to testing?
- Documentation – is it clear what to do when things go wrong?
- Management interface – are a CLI and UI available, can I automate them?
- Effective cost – is this cost effective and good value for money?
Anything else I count as a bonus such as node auto-scaling and native LoadBalancer support within Kubernetes.
Certification is also important for running in production, but if the above points are covered some divergence may be acceptable.
Get Kubernetes
At the time of writing the Kubernetes support is only by invitation only and is in beta. We saw a similar pattern with other Kubernetes services, so this seems to be normal.
Note: please bear in mind that this post is looking at pre-release beta product. Some details may change between now and GA including the CLI which is an early version.
Use the UI
To provision the cluster we can pick between the CLI or the familiar UI dashboard which gains a Kubernetes tab.
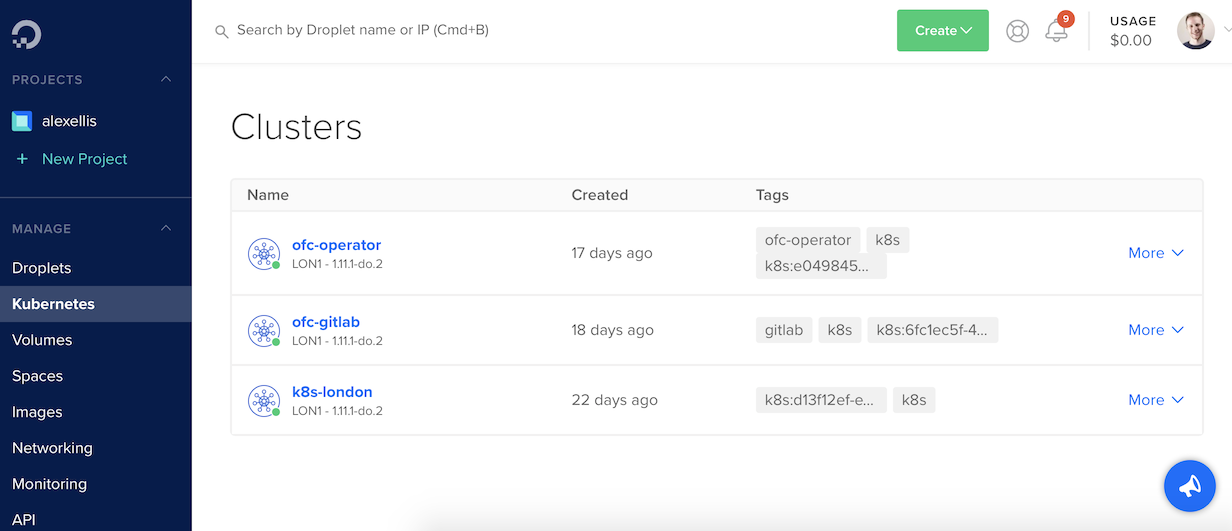
Here you can see three clusters I provisioned for testing OpenFaaS with my team at VMware and for a demo at Serverless Computing London.
From here we can create a new cluster using the UI.
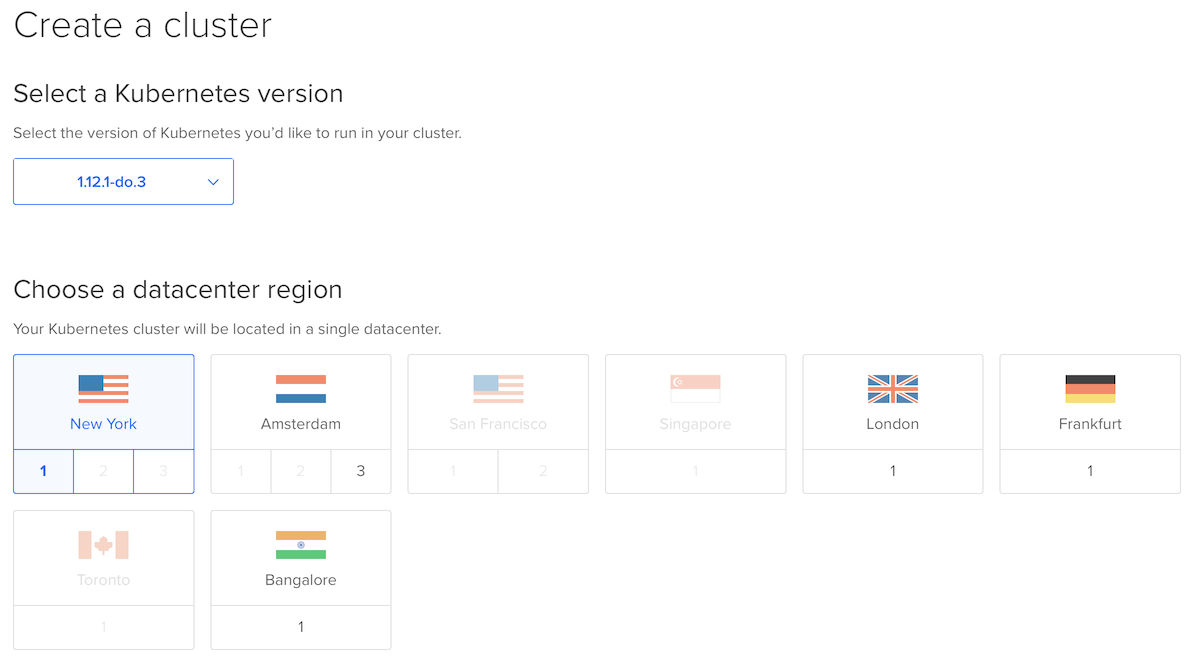
Initially you must pick a Region and a name for the cluster.

Then pick the price you want to pay per month by configuring one or many Kubernetes Node pools. The suggestion is 3 nodes at 5USD / month working out at 15USD per month. This may be suitable for a simple workload, but for anyone who has used Kubernetes for real work will know – 1Gb is not enough to be productive.
2Gb RAM with 1 vCPU costs 10 USD month (3×10=30USD) and 4Gb RAM with 2 vCPU will come in at (3×20=60USD). This is probably the minimum cost you want to go with to run a serious application.
Each node gets a public IPv4 IP address, so an IngressController could be run on each node then load-balanced via DNS for free, or we could opt to use a DO load-balancer (not a Kubernetes-native one) at an additional fee.
Effective cost: 3/5
It is possible to create multiple node pools, so if you have lighter workloads you could assign them to cheaper machines.
As well as Standard Nodes we can pick from Optimized Nodes (best in class) and Flexible Nodes. For an Optimized Node with best in class 2x vCPU and 4Gb RAM you’ll be set back (2×40=80USD). This seems to compare favourably with the other services mentioned, but could be off-putting to newcomers. It also doesn’t seem like there is cost for the master node.
Within a minute or two of hitting the blue button we can already download the .kube/config file from the UI and connect to our cluster to deploy code.
The Kubernetes service from @digitalocean is looking to be one of the easiest and quickest I’ve used so far. Looking forward to writing some guides on this and seeing what you all make of it too. pic.twitter.com/0FsMIzEzwF
— Alex Ellis (@alexellisuk) November 16, 2018
Ease of use for the UI: 5/5
Use the CLI
Up to now the doctl CLI could be used to do most of what you could do in the console – apart from provision Kubernetes clusters.
The @DigitalOcean CLI (doctl) now supports their managed Kubernetes Service -> https://t.co/r2muCj8EHz 🎉👨💻💻👩💻
— Alex Ellis (@alexellisuk) December 3, 2018
Well that all changed today and now in v1.12.0 you can turn on an experimental flag and manage those clusters.
The typical flow for using the doctl CLI involves downloading a static binary, unpacking it yourself, placing it in the right place, logging into the UI and generating an access token and then running doctl auth init. Google Cloud does this better by opening a web-browser to get an access token over OAuth.
Create the cluster with the following command:
Usage:
doctl kubernetes create [flags]
Aliases:
create, c
Flags:
–name string cluster name (required)
–node-pools value cluster node pools in the form “name=your-name;size=droplet_size;count=5;tag=tag1;tag=tag2” (required) (default [])
–region string cluster region location, example value: nyc1 (required)
–tag-names value cluster tags (default [])
–version string cluster version (required)
Global Flags:
-t, –access-token string API V2 Access Token
-u, –api-url string Override default API V2 endpoint
-c, –config string config file (default is $HOME/.config/doctl/config.yaml)
–context string authentication context name
-o, –output string output format [text|json] (default “text”)
–trace trace api access
-v, –verbose verbose output
The –node-pools flag may be better split out into multiple individual flags rather than separated with ;. When it came to picking the slug size I found that bit cryptic too. The only ways I could find them listed were through the API and a release announcement, which may or may not be the most recent. This could be improved for GA.
I also had to enter –version but didn’t know what format the string should be in. I copied the exact value from the UI. This is early days for the team so I would expect this to improve before GA.
$ doctl kubernetes create –name ae-openfaas
–node-pools=”name=main;size=s-2vcpu-4gb;count=3;tag=tutorial”
–region=”lon1″
–tag-names=”tutorial”
–version=”1.11.1-do.2″
ID Name Region Version Status Endpoint IPv4 Cluster Subnet Service Subnet Tags Created At Updated At Node Pools
82f33a60-02af-4e94-a550-dd5afd06cf0e ae-openfaas lon1 1.11.1-do.2 provisioning 10.244.0.0/16 10.245.0.0/16 tutorial,k8s,k8s:82f33a60-02af-4e94-a550-dd5afd06cf0e 2018-12-03 19:38:27 +0000 UTC 2018-12-03 19:38:27 +0000 UTC main
The result is asynchronous and not blocking so now we need to poll / check the CLI for completion.
We can type in doctl kubernetes list or doctl kubernetes get ae-openfaas.
Once we see the Running state then type in: doctl kubernetes kubeconfig ae-openfaas and save the contents into a file.
In the future I’d like to see this config merged optionally into .kube/config like we see with Minikube or VMware’s Cloud PKS CLI.
$ doctl kubernetes kubeconfig ae-openfaas > config
$ export KUBECONFIG=config
$ kubectl get node
NAME STATUS ROLES AGE VERSION
kind-knuth-3o9d Ready <none> 32s v1.11.1
kind-knuth-3o9i Ready <none> 1m v1.11.1
kind-knuth-3o9v Ready <none> 1m v1.11.1
We now have a config on the local computer and we’re good to go!
Ease of use for the CLI: 3/5
Total ease of use: 4/5
I would give GKE’s Management interface 5/5 – DO would have got 2/5 without the CLI. Now that the CLI is available and we can use it to automate clusters I think this goes up to 3/5 leaving room to grow.
Deploying a workload
In order to figure out a Reliability score we need to deploy an application and run it for some time. I deployed OpenFaaS live during a demo at Serverless Computing London and ran the Colorizer from the Function Store – this was on one of the cheaper nodes so ran slower than I would have expected, but was feature complete on a budget.
I then set up OpenFaaS Cloud with GitLab – this is a more demanding task as it means running a container builder and responding to events from GitLab to clone, build and deploy new OpenFaaS functions to the cluster. Again this held up really well using 3x4Gb 2vCPU nodes with no noticeable slow-down.
Reliability 4/5
You can deploy OpenFaaS with helm here: OpenFaaS helm chart
In this Tweet from my talk at goto Copenhagen you can see the conceptual architecture for OpenFaaS on Kubernetes which bundles a Serverless Function CRD & Operator along with NATS Streaming for asynchronous execution and Prometheus for built-in metrics and auto-scaling.
Serverless beyond the hype by @alexellisuk. Donating to @Bornecancerfond in the live demo 💰💸 #serverless pic.twitter.com/n1rzcqRByd
— Martin Jensen (@mrjensens) November 19, 2018
Steps:
- Install helm and tiller.
- Create the OpenFaaS namespaces
- Generate a password for the API gateway and install OpenFaaS the helm chart passing the option –set serviceType=LoadBalancer
- Install OpenFaaS CLI and log into the API gateway
This is the point at which a “normal” Kubernetes engine would give us a LoadBalancer in the openfaas namespace. We would then query its state to find a public IP address. DigitalOcean gets full marks here because it will respond to this event and provision a load balancer which is around 10 USD / month – cheaper than a traditional cloud provider.
Type in the following and look for a public IP for gateway-external in the EXTERNAL-IP field.
$ kubectl get svc -n openfaas
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager ClusterIP 10.245.45.200 <none> 9093/TCP 1m
gateway ClusterIP 10.245.83.10 <none> 8080/TCP 1m
gateway-external LoadBalancer 10.245.16.17 188.166.136.202 8080:32468/TCP 1m
nats ClusterIP 10.245.208.70 <none> 4222/TCP 1m
prometheus ClusterIP 10.245.105.120 <none> 9090/TCP 1m
Now set your OPENFAAS_URL as follows: export OPENFAAS_URL=http://188.166.136.202:8080 and do the login step:
$ echo -n $PASSWORD | faas-cli login –username admin –password-stdin
Note you can also add the export command to your bash profile ~/.bash_profile file to have it set automatically on every session.
You’ll now be able to open the UI using the address above or deploy a function using the CLI.
Deploy certinfo which can check a TLS certificate for a domain:
$ faas-cli store deploy certinfo
Check the status:
$ faas-cli list -v
$ faas-cli describe certinfo
Invoke the function and check a TLS certificate:
$ echo -n www.openfaas.com | faas-cli invoke certinfo
For me this seemed to take less than 10 seconds from deployment to getting a successful response from the function.
We can even scale the function to zero and see it come back to life:
$ kubectl scale deploy/certinfo -n openfaas-fn –replicas=0
Give it a few seconds for the function to be torn-down, then invoke it again. You’ll see it block – scale up and then serve the request:
$ echo -n cli.openfaas.com | faas-cli invoke certinfo
The function itself will take 1-2 seconds to execute since it works with a remote website. You can try it out with one of your own functions or find out how to enable the OpenFaaS idler component by reading the docs.
Earlier in the year in August Richard Gee wrote up a guide and supporting automation with Ansible to create up a single-node development cluster with Kubernetes and OpenFaaS. What I like about the new service is that we we can now get the same result, but better with just a few CLI commands.
TLS with LetsEncrypt
This is the point at which I’d usually tell you to follow the instructions for LetsEncrypt and cert-manager to setup HTTPS/TLS for your OpenFaaS gateway. I’m not going to need to go there because DigitalOcean can automate all of this for us if we let them take control of our domain.
The user-experience for cert-manager is in my opinion firmly set at expert level, so this kind of automation will be welcomed by developers. It does come at a cost of automation however.
Tear down the cluster
A common use-case for Kubernetes services is running CI and other automation testing. We can now tear down the whole cluster in the UI or CLI:
$ doctl kubernetes delete ae-openfaas –force
That’s it – we’ve now removed the cluster completely.
Wrapping up
As a maintainer, developer, architect and operator – it’s great to see strong Kubernetes offerings appearing. Your team or company may not be able to pick the best fit if you already take all your services from a single vendor, but I hope that the current level of choice and quality will drive down price and drive up usability wherever you call home in the cloud.
If you have the choice to run your workloads wherever you like, or are an aspiring developer then the Kubernetes service from DigitalOcean provides a strong option with additional value adds and some high scores against my rating system. I hope to see the score go up even more with some minor refinements around the CLI ready for the GA.
If taken in isolation then my overall rating for this new Kubernetes service from DigitalOcean would be 4/5, but when compared to the much more mature, feature-rich services Kubernetes engines we have to take this rating in context.
Source





 Next, create a
Next, create a Verify that the
Verify that the Test that the
Test that the Once it’s been
Once it’s been












