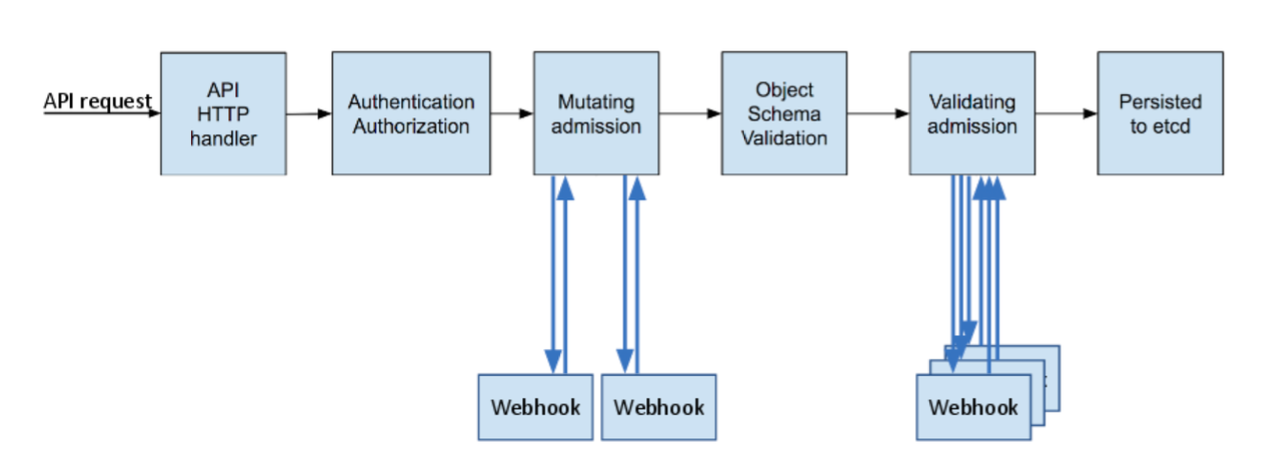
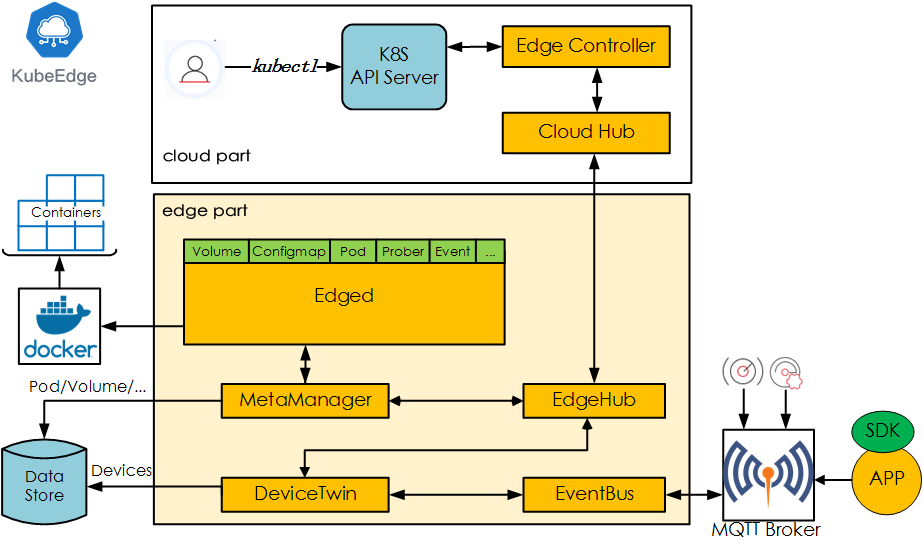
- We’re pleased to announce the delivery of Kubernetes 1.14, our first release of 2019!
Kubernetes 1.14 consists of 31 enhancements: 10 moving to stable, 12 in beta, and 7 net new. The main themes of this release are extensibility and supporting more workloads on Kubernetes with three major features moving to general availability, and an important security feature moving to beta.
More enhancements graduated to stable in this release than any prior Kubernetes release. This represents an important milestone for users and operators in terms of setting support expectations. In addition, there are notable Pod and RBAC enhancements in this release, which are discussed in the “additional notable features” section below.
Let’s dive into the key features of this release:
Production-level Support for Windows Nodes
Up until now Windows Node support in Kubernetes has been in beta, allowing many users to experiment and see the value of Kubernetes for Windows containers. Kubernetes now officially supports adding Windows nodes as worker nodes and scheduling Windows containers, enabling a vast ecosystem of Windows applications to leverage the power of our platform. Enterprises with investments in Windows-based applications and Linux-based applications don’t have to look for separate orchestrators to manage their workloads, leading to increased operational efficiencies across their deployments, regardless of operating system.
Some of the key features of enabling Windows containers in Kubernetes include:
- Support for Windows Server 2019 for worker nodes and containers
- Support for out of tree networking with Azure-CNI, OVN-Kubernetes, and Flannel
- Improved support for pods, service types, workload controllers, and metrics/quotas to closely match the capabilities offered for Linux containers
Notable Kubectl Updates
New Kubectl Docs and Logo
The documentation for kubectl has been rewritten from the ground up with a focus on managing Resources using declarative Resource Config. The documentation has been published as a standalone site with the format of a book, and it is linked from the main k8s.io documentation (available at https://kubectl.docs.kubernetes.io).
The new kubectl logo and mascot (pronounced kubee-cuddle) are shown on the new docs site logo.
Kustomize Integration
The declarative Resource Config authoring capabilities of kustomize are now available in kubectl through the
-kflag (e.g. for commands likeapply, get) and thekustomizesubcommand. Kustomize helps users author and reuse Resource Config using Kubernetes native concepts. Users can now apply directories withkustomization.yamlto a cluster usingkubectl apply -k dir/. Users can also emit customized Resource Config to stdout without applying them viakubectl kustomize dir/. The new capabilities are documented in the new docs at https://kubectl.docs.kubernetes.ioThe kustomize subcommand will continue to be developed in the Kubernetes owned kustomize repo. The latest kustomize features will be available from a standalone kustomize binary (published to the kustomize repo) at a frequent release cadence, and will be updated in kubectl prior to each Kubernetes releases.
kubectl Plugin Mechanism Graduating to Stable
The kubectl plugin mechanism allows developers to publish their own custom kubectl subcommands in the form of standalone binaries. This may be used to extend kubectl with new higher-level functionality and with additional porcelain (e.g. adding a
set-nscommand).Plugins must have the
kubectl-name prefix and exist on the user’s $PATH. The plugin mechanics have been simplified significantly for GA, and are similar to the git plugin system.Persistent Local Volumes are Now GA
This feature, graduating to stable, makes locally attached storage available as a persistent volume source. Distributed file systems and databases are the primary use cases for persistent local storage due performance and cost. On cloud providers, local SSDs give better performance than remote disks. On bare metal, in addition to performance, local storage is typically cheaper and using it is a necessity to provision distributed file systems.
PID Limiting is Moving to Beta
Process IDs (PIDs) are a fundamental resource on Linux hosts. It is trivial to hit the task limit without hitting any other resource limits and cause instability to a host machine. Administrators require mechanisms to ensure that user pods cannot induce PID exhaustion that prevents host daemons (runtime, kubelet, etc) from running. In addition, it is important to ensure that PIDs are limited among pods in order to ensure they have limited impact to other workloads on the node.
Administrators are able to provide pod-to-pod PID isolation by defaulting the number of PIDs per pod as a beta feature. In addition, administrators can enable node-to-pod PID isolation as an alpha feature by reserving a number of allocatable PIDs to user pods via node allocatable. The community hopes to graduate this feature to beta in the next release.
Additional Notable Feature Updates
Pod priority and preemption enables Kubernetes scheduler to schedule more important Pods first and when cluster is out of resources, it removes less important pods to create room for more important ones. The importance is specified by priority.
Pod Readiness Gates introduce an extension point for external feedback on pod readiness.
Harden the default RBAC discovery clusterrolebindings removes discovery from the set of APIs which allow for unauthenticated access by default, improving privacy for CRDs and the default security posture of default clusters in general.
Availability
Kubernetes 1.14 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials. You can also easily install 1.14 using kubeadm.
Features Blog Series
If you’re interested in exploring these features more in depth, check back next week for our 5 Days of Kubernetes series where we’ll highlight detailed walkthroughs of the following features:
- Day 1 – Windows Server Containers
- Day 2 – Harden the default RBAC discovery clusterrolebindings
- Day 3 – Pod Priority and Preemption in Kubernetes
- Day 4 – PID Limiting
- Day 5 – Persistent Local Volumes
Release Team
This release is made possible through the efforts of hundreds of individuals who contributed both technical and non-technical content. Special thanks to the release team led by Aaron Crickenberger, Senior Test Engineer at Google. The 43 individuals on the release team coordinated many aspects of the release, from documentation to testing, validation, and feature completeness.
As the Kubernetes community has grown, our release process represents an amazing demonstration of collaboration in open source software development. Kubernetes continues to gain new users at a rapid clip. This growth creates a positive feedback cycle where more contributors commit code creating a more vibrant ecosystem. Kubernetes has had over 28,000 individual contributors to date and an active community of more than 57,000 people.
Project Velocity
The CNCF has continued refining DevStats, an ambitious project to visualize the myriad contributions that go into the project. K8s DevStats illustrates the breakdown of contributions from major company contributors, as well as an impressive set of preconfigured reports on everything from individual contributors to pull request lifecycle times. On average over the past year, 381 different companies and over 2,458 individuals contribute to Kubernetes each month. Check out DevStats to learn more about the overall velocity of the Kubernetes project and community.
User Highlights
Established, global organizations are using Kubernetes in production at massive scale. Recently published user stories from the community include:
- NetEase moving to Kubernetes has increased their R&D efficiency by more than 100% and deployment efficiency by 280%.
- VSCO found that moving to continuous integration, containerization, and Kubernetes, velocity was increased dramatically. The time from code-complete to deployment in production on real infrastructure went from 1-2 weeks to 2-4 hours for a typical service.
- NAV’s move to Kubernetes saved the company 50% in infrastructure costs, deployments increased 5x from 10 a day to 50 a day and resource utilization increased from 1% to 40%.
Is Kubernetes helping your team? Share your story with the community.
Ecosystem Updates
- Kubernetes is participating in GSoC 2019 under the CNCF. Check out the full list of project ideas for 2019 on CNCF’s GitHub page.
- The CNCF Annual report 2018 provides a look back at the growth of the Kubernetes and the foundation, community engagement, ecosystem tools, test conformance projects, KubeCon and more.
- Out of 8,000 attendees at KubeCon + CloudNativeCon North America 2018, 73% were first-time KubeCon-ers, highlighting massive growth and new interest in Kubernetes and cloud native technologies. Conference transparency report.
KubeCon
The world’s largest Kubernetes gathering, KubeCon + CloudNativeCon is coming to Barcelona from May 20-23, 2019 and Shanghai (co-located with Open Source Summit) from June 24-26, 2019. These conferences will feature technical sessions, case studies, developer deep dives, salons, and more! Register today!
Webinar
Join members of the Kubernetes 1.14 release team on April 23rd at 10am PDT to learn about the major features in this release. Register here.
Get Involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below.
Thank you for your continued feedback and support.
- Post questions (or answer questions) on Stack Overflow
- Join the community discussion on Discuss
- Follow us on Twitter @Kubernetesio for latest updates
- Join the community on Slack
- Share your Kubernetes story