

As the year comes to a close, Kubernetes contributors, our engineers included, have been hard at work to bring you the final release of 2018: Kubernetes 1.13. In recognition of the achievements the community has made this year, and the looming holiday season, we shift our focuses towards presenting this work to the world at large. KubeCon Shanghai was merely weeks ago and KubeCon NA (Seattle) kicks off next week!
That said, the Kubernetes 1.13 release cycle has been significantly shorter. Given the condensed timeline to plan, document, and deliver enhancements to the Kubernetes ecosystem, efforts were dedicated to minimizing new functionality and instead optimizing existing APIs, graduating major features, improving documentation, and strengthening the test suites within core Kubernetes and the associated components. So yet again, the common theme is stability. Let’s dive into some of the highlights of the release!
Storage
One of the major highlights in this release is CSI (Container Storage Interface), which was first introduced as alpha in January. CSI support in Kubernetes is now Generally Available.
In its infancy, Kubernetes was primarily geared towards running stateless applications. Since then, we’ve seen the evolution of constructs like PetSets evolve into StatefulSets, to build more robust support for running stateful applications. In keeping with that evolution, the Storage Special Interest Group (SIG) has made consistent improvements to the way Kubernetes interfaces with storage subsystems. These developments strengthen the community’s ability to provide storage guarantees to applications running within Kubernetes, which is of paramount importance, especially for Enterprise customers using technologies like Ceph and Gluster.
Making Declarative Changes Safer
At the risk of providing a simplistic explanation, Kubernetes is a set of APIs that receive declarative information from operators / other systems, process and store that information in a key-value store (etcd), and then query and act on the stored information to achieve some desired state. There are then reconciliation loops spread across multiple controllers to enable that the desired state is always maintained. It is important that the changes made to these systems are made in a safe way, as consequences can ripple out to multiples places in a Kubernetes environment.
To that end, we’d like to highlight two enhancements: APIServer DryRun and kubectl diff.
If flags like –dry-run or –apply=false in CLI tools sound familiar, then APIServer DryRun will too. APIServer DryRun is an enhancement which allows cluster operators to understand what would’ve happened with common operations (POST, PUT, PATCH, DELETE) on Kubernetes objects, without persisting the data of the proposed change. This brings an opportunity to better introspect on desired changes, without the burden of having to potentially rollback errors. DryRun has moved to beta in Kubernetes 1.13.
Similarly, kubectl diff provides a similar experience to using the diff utility. Prior to the introduction of this enhancement, operators would have to carefully compare objects to interpolate what the results of the change would be. Moving to beta in Kubernetes 1.13, users can now inspect a local declared Kubernetes object and compare that to the state of a running in-cluster object, or a previously applied object, or what the merging of two objects would result in.
Plugin Systems
As the Kubernetes ecosystem expands, the community has embraced separating the core codebase into new projects, which improve developer velocity, as well as help to minimize the size of the binaries that are delivered. A direct effect of this has been the requirement to extend the way Kubernetes core discovers and gains visibility into external components. This can include a wide gamut of components, like CRI (Container Runtime Interface) and GPU-enabled devices.
To make this happen, an enhancement called Kubelet Device Plugin Registration was introduced in 1.11 and graduates to GA in Kubernetes 1.13. Device plugin registration provides a common and consistent interface which plugins can register against in the kubelet.
Once new device plugins are integrated into the system, it becomes yet another vector that we want to gain visibility into. Third-party device monitoring is now in alpha for Kubernetes 1.13, and it seeks to solve that need. With this new enhancement, third-party device makers can route their custom information to the Kubernetes monitoring systems. This means GPU compute can now be monitored in a similar way as standard cluster resources like RAM and CPU are already monitored.
Collaboration is Key
The community has worked hard on this release, and it caps off a year that could best be summed up by a single word: Cooperation. More consistent, open source tools have emerged, like CNI, CRI, CSI, kubeadm, and CoreDNS to name a few.
Expect 2019 to see a continued push to enable the community through better interfaces, APIs and plugins.
To get started with the latest Kubernetes release you can find it on GitHub at https://github.com/kubernetes/kubernetes/releases.
 This simple
This simple We’ve created each
We’ve created each

































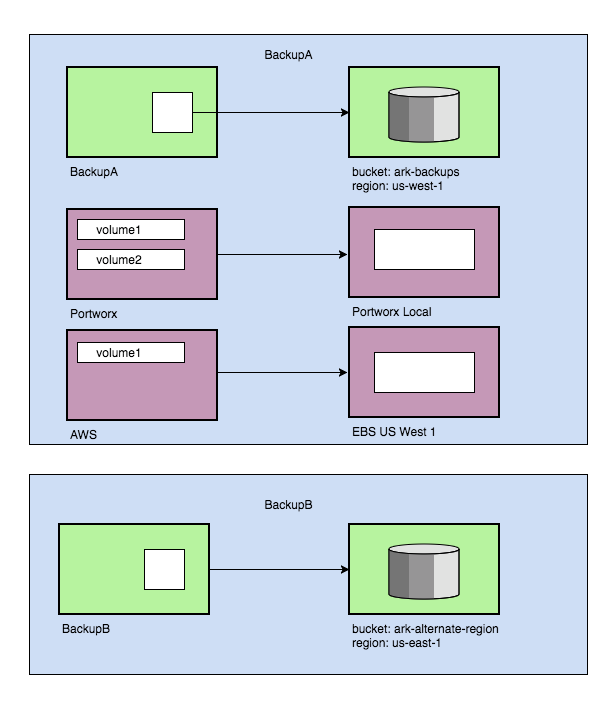 Multiple Volume Snapshots
Multiple Volume Snapshots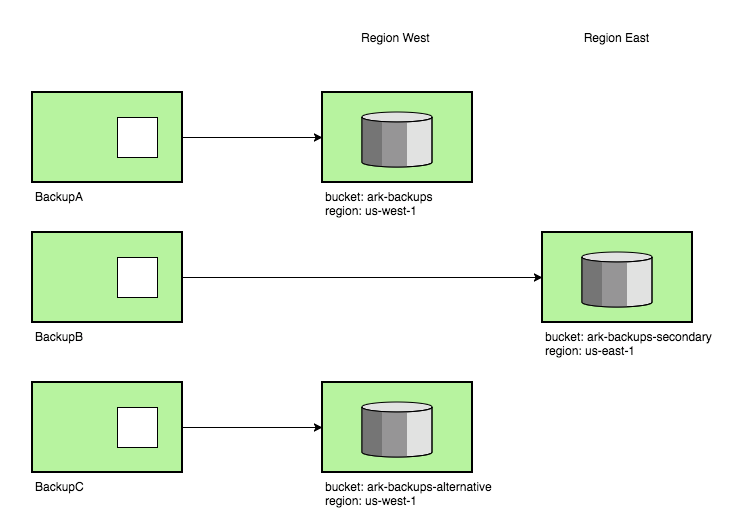 Multiple backup locations
Multiple backup locations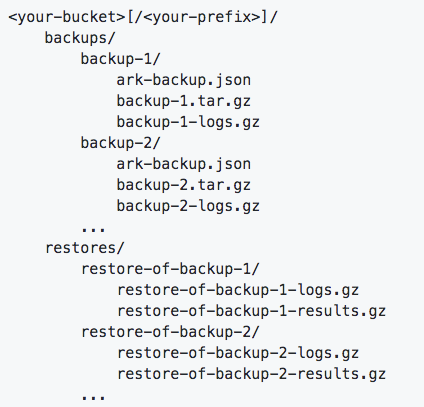 New backup storage organization
New backup storage organization
