
We’re excited to announce the release of Heptio Ark v0.10! This release includes features that give you greater flexibility in migrating applications and organizing cluster backups, along with some usability improvements. Most critically, Ark v0.10 introduces the ability to specify multiple volume snapshot locations, so that if you’re using more than one provider for volume storage within a cluster, you can now snapshot and fully back up every volume.

We know that today, most Ark users tend to have one volume provider within a cluster, like Portworx or Amazon EBS. However, this can pose challenges for application portability, or if you need faster access speeds for certain workloads. Being able to specify more than one location for backing up data volumes gives you more flexibility within a cluster and, in particular, makes it easier to migrate more complex applications from one Kubernetes environment to another.
Down the road, this feature will also become critical for supporting full backup replication. Imagine a world where you could define a replication policy that specifies the additional locations for where you can replicate a backup or a volume snapshot, easily solving for redundancy and cluster restoration across regions.
Read on for more details about this feature and other benefits of Ark v0.10.
Support for multiple volume snapshot locations from multiple providers
In Ark versions prior to v0.10, you can snapshot volumes only from a single provider. For example, if you are running on AWS and using EBS and Rook, you could snapshot volumes from only one of those two persistent volume providers. With Ark v0.10 you can now specify multiple volume snapshot locations from multiple providers..
Let’s say you have an application that you have deployed all in one pod. It has a database, which is kept on an Amazon EBS volume. It also holds user uploaded photos on a Portworx volume. There’s a third volume for generated reports, also stored in Portworx. You can now snapshot all three.
Every persistent volume to be backed up needs to be created with one associated volume snapshot location. This is also a two-step process: first, you create the VolumeSnapshotLocation CRDs for the locations you want (this only needs to be done once). Then, when creating a backup with a persistent volume, you select the location where you want the volume to be stored, by using the –snapshot-location flag and the name of one of the locations you created with the CRD.
Note that even though multiple volume snapshot locations can be created for each provider, when you create the backup, only one volume snapshot location per provider per backup can be used.
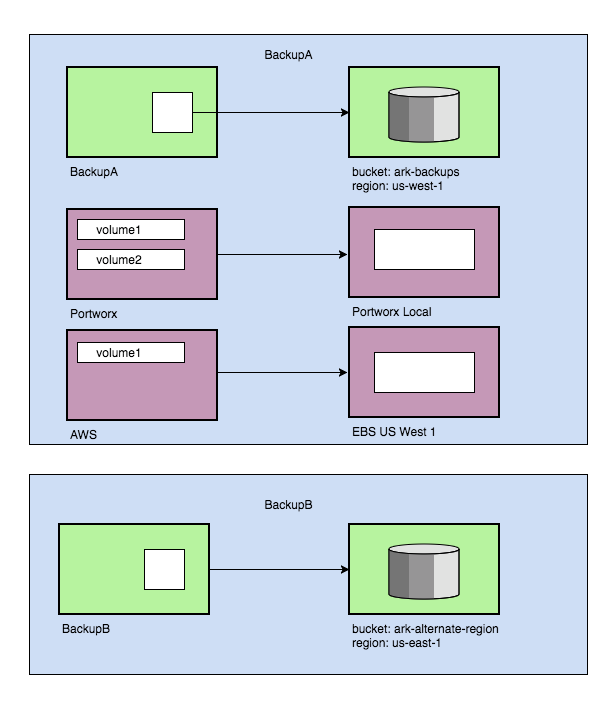
As with regular backup storage locations, the volume snapshot locations can have a default associated with each of them so at backup creation time you don’t have to specify it. Unlike regular backups, however, the names of those locations must be specified as flags to the Ark server. They are not set up front.
Also as with the new BackupStorageLocation, the new VolumeSnapshotLocation CRD takes the place of the persistent volume setting in the previous Config CRD.
Ability to specify multiple backup locations
Backups now can be stored in different locations. You might want some backups to go for example to a bucket named full-cluster-backups in us-east-1, and other backups to be stored in a bucket named namespace-backups in us-east-2. As you can see, backup locations can now be in different regions.
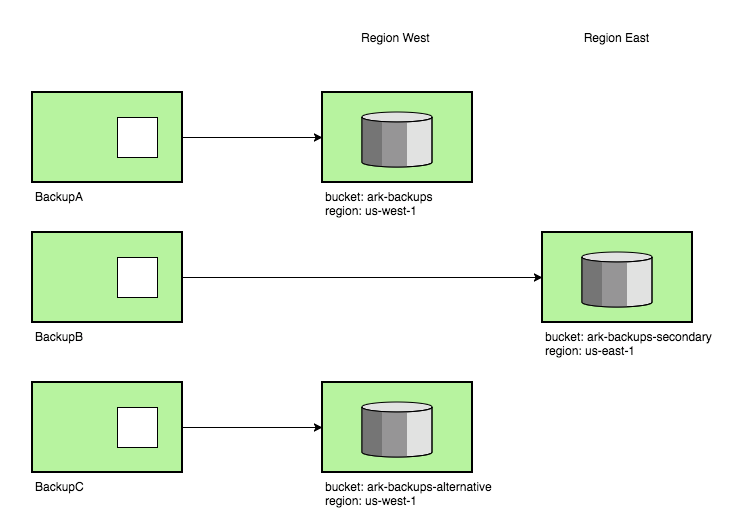 Multiple backup locations
Multiple backup locations
Every backup now needs to be created with one associated backup storage location. This is a two-step process: first, you create the BackupStorageLocation CRDs for the locations you want. Then, when creating a backup, you select the location where you want the backup to be stored by using the –backup-location flag and the name of one of the locations you created with the CRD.
The exception to having to specify the name of a backup storage location is if you want to use the default location feature. In this case, you create the BackupStorageLocation CRD as expected, with the name default. Then, when you create a backup and don’t specify a location, the backup is stored in the default location. You can also rename the default location when you create the CRD, but you must then be sure to specify the –default-backup-storage-location flag when you create the Ark server deployment.
The BackupStorageLocation CRD replaces the previous Config CRD (now deprecated), which was where you defined the name of your backup, bucket and region
Streamlined backup storage
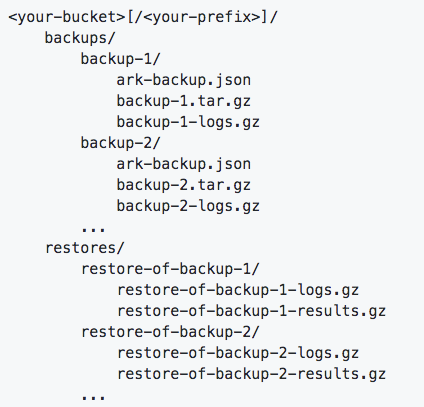
This version also introduces the ability to store backups under prefixes in an object storage bucket. Prior to v0.10, Ark stored all backups from a cluster at the root of the bucket. This meant if you wanted to organize the backup of each of your clusters separately, you’d have to create a bucket for each. As of version 0.10, you can organize backups from each cluster in the same bucket, using different prefixes. The new storage layout and instructions for migrating can be found in our documentation.
Stronger plugin system
Ark’s plugin system has been significantly refactored to improve robustness and ease of development:
- Plugin processes are now automatically restarted if they unexpectedly terminate.
- Plugin binaries can now contain more than one plugin implementation (for example, an object store and a block store, or many backup item actions).
- Prefixes in object storage are now supported.
Plugin authors must update their code to be compatible with v0.10. Plugin users will need to update the plugin image tags and/or image pull policy to ensure they have the latest plugins.
For details, see the GitHub repository for plugins. We’ve updated it with new examples for v0.10, and we continue to provide a v0.9.x branch that refers to the older APIs.
The Ark team would like to thank plugin authors who have been collaborating with us leading up to the v0.10 launch. The following community Ark Plugins have already been updated to use the new plugin system:
Additional usability improvements
- The sync process, which ensures that Backup custom resources exist for each backup in object storage, has been revamped to run much more frequently (once per minute rather than once per hour), to use significantly fewer cloud provider API calls, and to not generate spurious Kubernetes API errors.
- Restic backup data is now automatically stored in the same bucket/prefix as the rest of the Ark data. A separate bucket is no longer required (or allowed).
- Ark resources (backups, restores, schedules) can now be bulk-deleted with the Ark CLI, using the –all or –selector flags, or by specifying multiple resource names as arguments to the delete commands.
- The Ark CLI now supports waiting for backups and restores to complete, with the–wait flag for –ark backup create and –ark restore create.
- Restores can be created directly from the most recent backup for a schedule, using –ark restore create –from-schedule SCHEDULE_NAME.
Get involved!
We are in a phase of evaluating the implementation for replication and would love to have input from the community, especially about how to handle provider-specific issues.
With this in mind, we have started holding Heptio Ark design sessions. These are public meetings (open to all!) focused on a technical design discussion around whatever Ark feature the team is working on at that moment.
The next design session will be live streamed here: https://www.youtube.com/watch?v=Ml5lN4cV1Yk
If you’d like to request that we cover a particular feature feel free to make that request in our Ark Community repo. Video recording of all our sessions can be found under our Heptio Ark YouTube playlist.
Other than that, you can also reach us through these channels: