In the previous articles of the series, we have seen the local Kubernetes solutions for Windows and Linux. In this article, we talk about MacOS and take a look at Docker Desktop and Minikube.
Similar to the Windows version, Docker for Mac provides an out of the box solution using a native virtualization system. Docker for Mac is very easy to install, but it also comes with limited configuration options.
On the other hand, Minikube has more complete Kubernetes support with multiple add-ons and driver support (e.g. VirtualBox) at the cost of a more complicated configuration.
Docker on Mac with Kubernetes support
Kubernetes is available in Docker for Mac for 18.06 Stable or higher and includes a Kubernetes server and client, as well as integration with the Docker executable. The Kubernetes server runs locally within your Docker instance and it is similar to the Docker on Windows solution. Notice that Docker on Mac uses a native MacOS virtualization system called Hyperkit.
When Kubernetes support is enabled, you can deploy new workloads not only on Kubernetes but also on Swarm and as standalone containers, without affecting any of your existing workloads.
Installation
As mentioned already, Kubernetes is included in the Docker on Mac binary so it installed automatically with it. You can download and install Docker for Mac from the Docker Store.
 Installing Docker Desktop
Installing Docker Desktop
Note: If you already use a previous version of Docker (e.g. docker toolbox ), or an older version of Docker on Mac, we strongly recommend upgrading to the newer version, instead of having multiple docker installations versions active. If for some reason you cannot upgrade, you should be able to use Minikube instead.
After a successful installation, you need to explicitly enable Kubernetes support. Click the Docker icon in the status bar, go to “Preferences”, and on the “Kubernetes” tab check “Enable Kubernetes” as shown in the figure below.
 Docker Desktop preferences
Docker Desktop preferences
This will start a single node Kubernetes cluster for you and install the kubectl command line utility as well. This might take a while, but the dialog will let you know once the Kubernetes cluster is ready.
 Enabling Kubernetes
Enabling Kubernetes
Management
Now you are ready to deploy your workloads similar to Windows. If you are working with multiple Kubernetes clusters and different environments you should already be familiar with switching contexts. You can view contexts using the kubectl config command:
| kubectl config get-contexts |
Set the context to use as docker-for-desktop:
| kubectl config use-context docker-for-desktop |
Unfortunately, (as was the case with the Windows version), the bundled Kubernetes distribution does not come with its dashboard enabled. You need to enable it with the following command:
| kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/alternative/kubernetes-dashboard.yaml |
To view the dashboard in your web browser run:
And navigate to your Kubernetes Dashboard at: http://localhost:8001/api/v1/namespaces/kube-system/services/kubernetes-dashboard/proxy
Deployment
Deploying an application it is very straightforward. In the following example, we install a cluster of nginx servers using the commands:
| kubectl run nginx –image nginx
kubectl expose deployment nginx –port 80 –target-port 80 –name nginx |
Once Kubernetes completed downloading the containers, you can see the containers running by using the command:
You can view the dashboard, as mentioned before, to verify that nginx was indeed installed and your cluster is in working mode.
Kubernetes on Mac using Minikube
As another alternative to Docker-for-Mac, we can also use Minikube to set up and operate a single node Kubernetes cluster as a local development environment. Minikube for Mac supports multiple hypervisors such as VirtualBox, VMWare, and Hyperkit. In this tutorial, we are talking about the installation mode that uses VirtualBox. (If Hyperkit is available then Docker-for-Mac is easier to install.)
Installation
Instead of manually installing all the needed packages for Minikube, it is easier to install all prerequisites using the Homebrew package manager. If you don’t have the Homebrew package manager already installed, you can easily install it using the following command in the terminal application:
| /usr/bin/ruby -e “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)” |
This will also include prerequisites such as Xcode command line tools.
To install Minikube itself including the prerequisites, we execute the following command:
| brew update && brew install kubectl && brew cask install docker minikube virtualbox |
After completion, the following packages will be installed in your machine:
| docker –version # Docker version 18.06.1-ce, build e68fc7a
docker-compose –version # docker-compose version 1.22.0, build f46880f docker-machine –version # docker-machine version 0.15.0, build b48dc28d minikube version # minikube version: v0.30.0 kubectl version –client # Client Version: version.Info{Major:”1″, ….. |
Management
After successful installation, you can start Minikube by executing the following command in your terminal:
Now Minikube is started and you have created a Kubernetes context called “minikube”, which is set by default during startup. You can switch between contexts using the command:
| kubectl config use-context minikube |
Furthermore, to access the Kubernetes dashboard, you need to execute/run the following command:
Additional information, on how to configure and manage the Kubernetes cluster can be found in the official documentation.
Deployment
Deploying an application is the same for all drivers supported in Minikube. For example, you can deploy, expose, and scale a service using the usual kubectl commands, as provided in the Minikube Tutorial.
| kubectl run my-nginx –image=nginx –port=80
kubectl expose deployment my-nginx –type=NodePort Kubectl scale –replicas=3 deployment/my-nginx |
You can view the workloads of your Minikube cluster either through the Kubernetes dashboard or using the command line interface – kubectl. For example, to see the deployed pods you can use the command:
Conclusion
After looking at both solutions, here are our results…
Minikube is a mature solution available for all major operating systems. Its main advantage is that it provides a unified way of working with a local Kubernetes cluster regardless of the operating system. It is perfect for people that are using multiple OS machines and have some basic familiarity with Kubernetes and Docker.
Pros:
- Mature solution
- Works on Windows (any version and edition), Mac, and Linux
- Multiple drivers that can match any environment
- Installs several plugins (such as dashboard) by default
- Very flexible on installation requirements and upgrades
Cons:
- Installation and removal not as streamlined as other solutions
- Does not integrate into the MacOS UI
Docker Desktoop for Mac is a very user-friendly solution with good integration for the MacOS UI.
Pros:
- Very easy installation for beginners
- All-in-one Docker and Kubernetes solution
- Configurable via UI
Cons:
- Relatively new, possibly unstable
- Limited configuration options (i.e. driver support)
Let us know in the comments which local Kubernetes solution you are using and why.





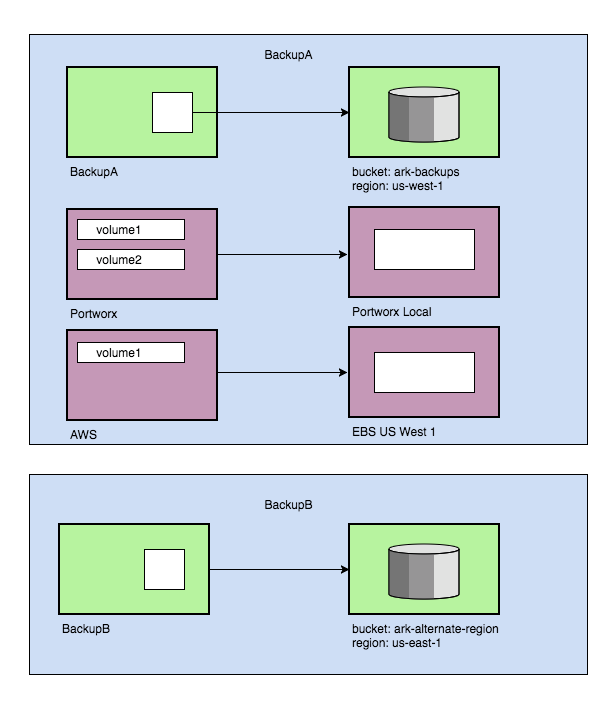 Multiple Volume Snapshots
Multiple Volume Snapshots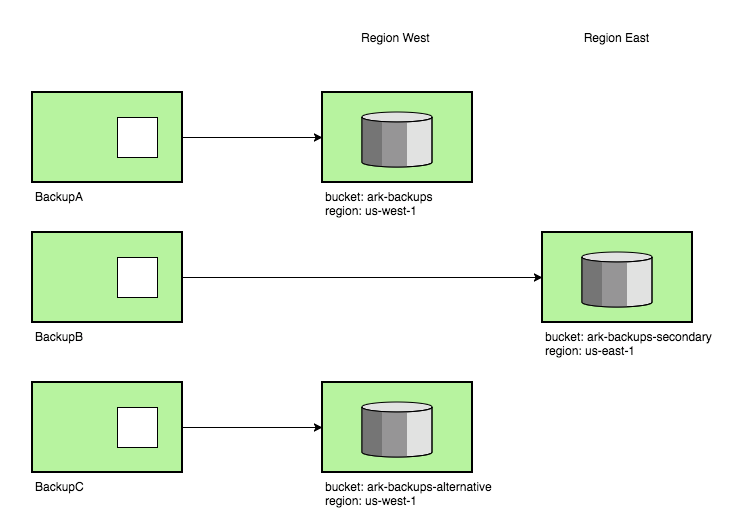 Multiple backup locations
Multiple backup locations New backup storage organization
New backup storage organization